Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データ品質を守り続けるための データ基盤の考え方
Search
tenajima
March 18, 2025
1.7k
4
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
データ品質を守り続けるための データ基盤の考え方
https://findy.connpass.com/event/347279/
tenajima
March 18, 2025
More Decks by tenajima
See All by tenajima
ビジネスプロセスから始めるデータモデリング ファクトとディメンションの前に考えること
tenajima
2
150
data vaultを用いたマルチプロダクトのためのデータ基盤開発
tenajima
1
1.2k
仮名加工化の実践 データ分析基盤における挑戦と学び
tenajima
12
4.9k
dbtとLookerにたどり着いたデータ基盤 ~混ざり合う境界線を考える~
tenajima
1
1.3k
dbtとLookerにたどり着いたデータ基盤 ~しくじり先生俺みたいになるなを添えて~
tenajima
2
1.5k
gokart導入のきっかけと運用の現状
tenajima
2
6.4k
VS codeとPyrightで始める型のある生活
tenajima
3
7.4k
Featured
See All Featured
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
750
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
730
Accessibility Awareness
sabderemane
1
160
What's in a price? How to price your products and services
michaelherold
247
13k
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
64
56k
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
420
Why Your Marketing Sucks and What You Can Do About It - Sophie Logan
marketingsoph
0
290
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
550
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3.3k
[SF Ruby Conf 2025] Rails X
palkan
2
1.2k
4 Signs Your Business is Dying
shpigford
187
22k
Transcript
©2023 10X, Inc. データ品質を守り続けるための データ基盤の考え方 2025/03/18 データ品質どう担保する?複雑化を乗り越える品質管理のリアル
©2023 10X, Inc. 自己紹介 • 水谷優斗 ◦ 各種id: @tenajima •
株式会社10X データ基盤チーム ◦ 2023年2月入社 ◦ 小売企業様へのダッシュボードの提供、社内データ基盤の運用 ◦ データプロダクトの開発 • 経歴 ◦ Fringe81(現Unipos) にデータサイエンティストとして新卒入社 ◦ データサイエンティストとして広告基盤の改善に取り組んだり、 HR SaaSのデータ活用に取り組ん だり ◦ 2021年4月頃からデータ分析基盤の作成、社内のデータ活用に取り組むようになる • 趣味 ◦ 野球とワンピース はじめに
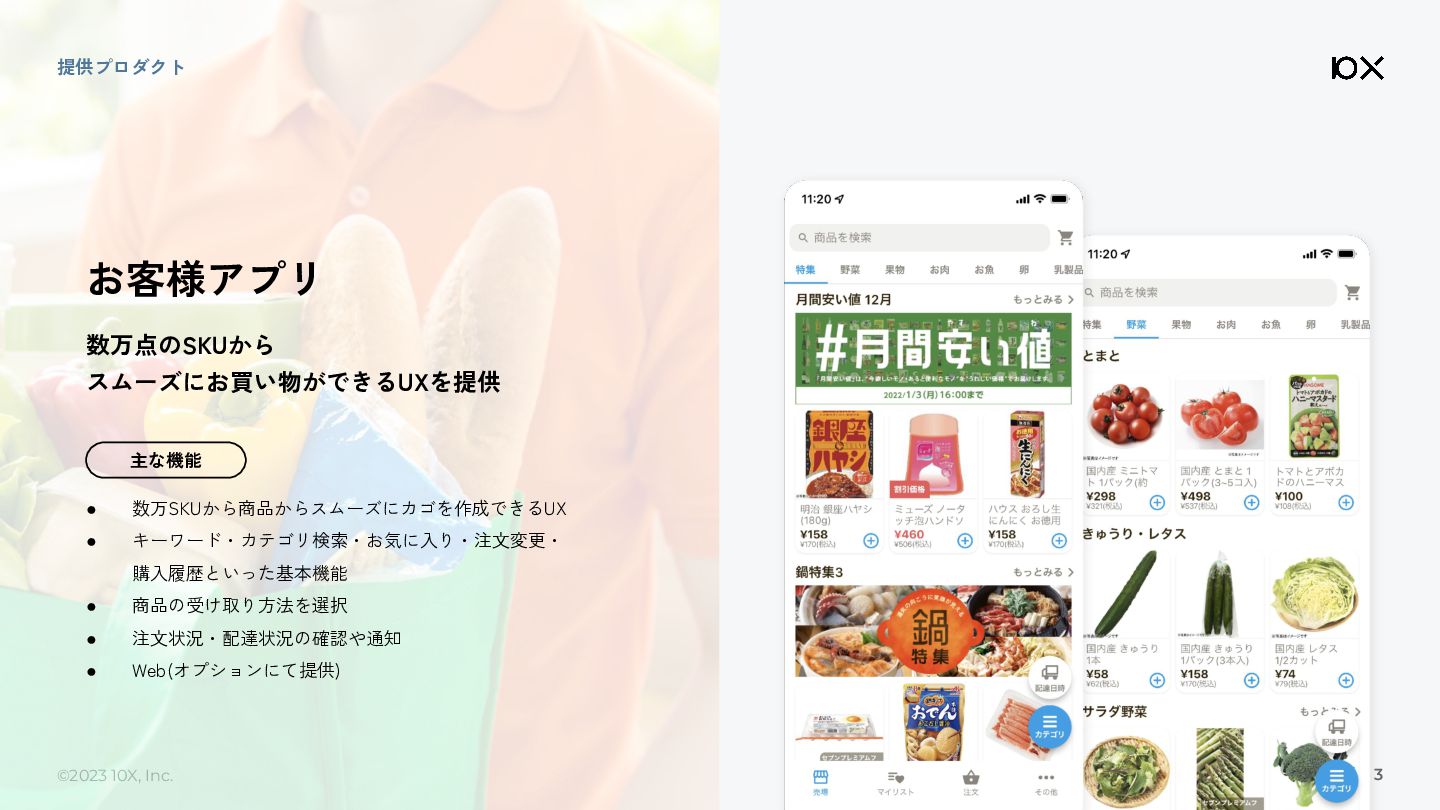
©2023 10X, Inc. 提供プロダクト お客様アプリ • 数万SKUから商品からスムーズにカゴを作成できるUX • キーワード・カテゴリ検索・お気に入り・注文変更・ 購入履歴といった基本機能
• 商品の受け取り方法を選択 • 注文状況・配達状況の確認や通知 • Web(オプションにて提供) 数万点のSKUから スムーズにお買い物ができるUXを提供 主な機能 3
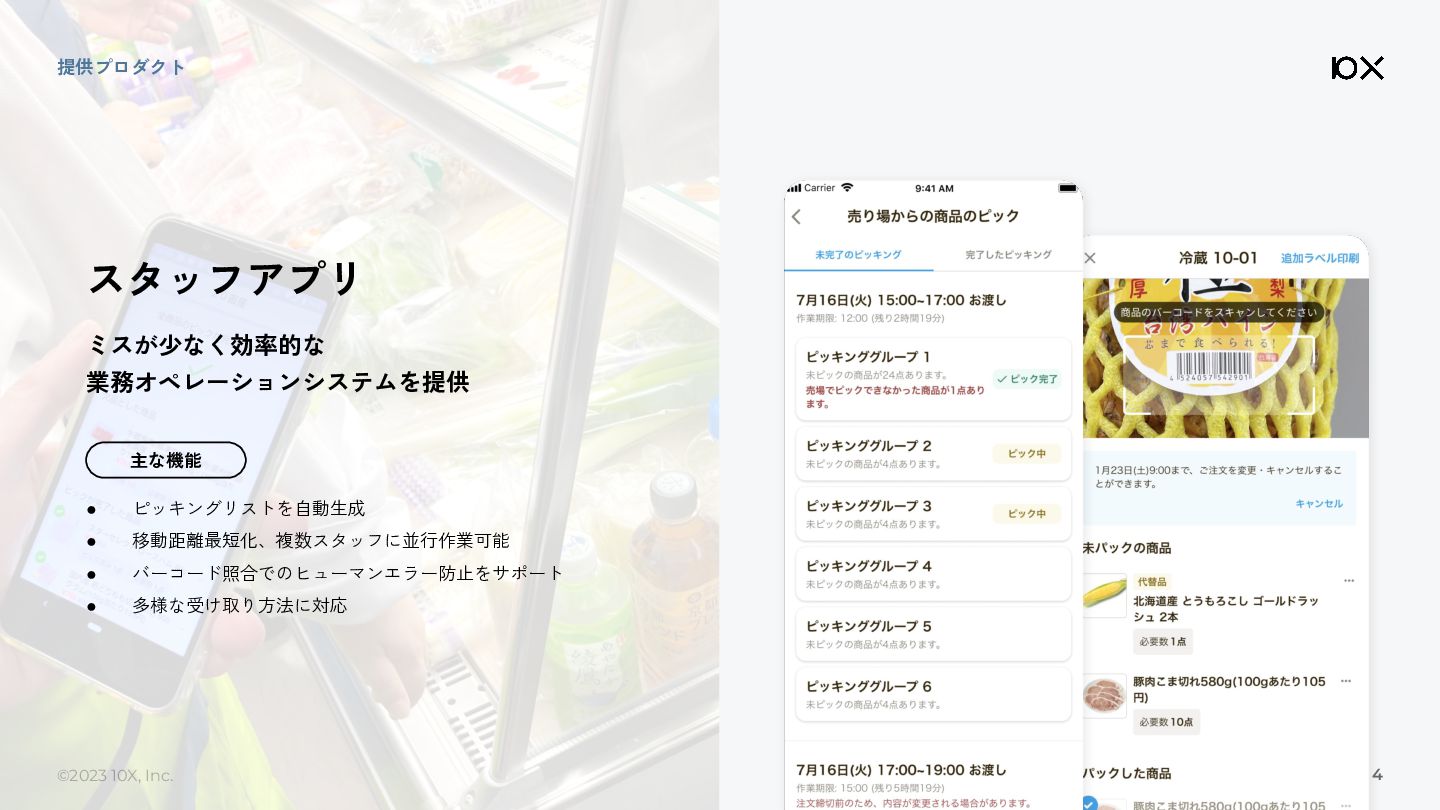
©2023 10X, Inc. 提供プロダクト スタッフアプリ • ピッキングリストを自動生成 • 移動距離最短化、複数スタッフに並行作業可能 •
バーコード照合でのヒューマンエラー防止をサポート • 多様な受け取り方法に対応 ミスが少なく効率的な 業務オペレーションシステムを提供 主な機能 4
©2023 10X, Inc. 10Xにおけるデータ品質の定義 • あるデータが実際にある現象をどれだけ正確に再現できているか ◦ 正確性: データが実際にある現象を表現できているか ◦
可用性: データ利用者が、利用したいときにデータを利用できるか ◦ 信頼性: そのデータはどのように作られ、どのような処理を経てできているかが明瞭か ◦ 利用性: 任意のデータを使うときに、そのデータの場所を特定し、理解し、使えるようになっている か ◦ 参照: Elementaryを用いたデータ品質の可視化とデータ基盤の運用改善
©2023 10X, Inc. データ品質を担保しやすい状態にありますか? • データ品質、自信を持って担保できていると言えますか? • 皆さんのデータ基盤、モデルはどれだけありますか? • レイヤーが持つ責務はどのように定義され、どのような制約によって守られていま
すか?
©2023 10X, Inc. データ品質を担保しやすい状態にありますか? • データ品質、自信を持って担保できていると言えますか? • 皆さんのデータ基盤、モデルはどれだけありますか? • レイヤーが持つ責務はどのように定義され、どのような制約によって守られていま
すか? • ちなみに1年半前の私がこの問いかけを突きつけられたら膝から崩れ落ちること でしょう
©2023 10X, Inc. 1年半前の10Xのデータ基盤の状況 • dbt のモデル数: 1,800 • ネットスーパーの多様な指標
(お客様側、小売事業者側) • SQL に長けた人材が多く、結果として様々な指標が dbt パイプライン上に存在 ◦ 分析をするために必要な SQL の考え方とデータ基盤を作っていくのに必要な SQL の考え方は 違う (データ基盤のためのリーダブル SQL)
©2023 10X, Inc. 1年半前の10Xのデータ基盤の状況 • dbt のモデル数: 1,800 • ネットスーパーの多様な指標
(お客様側、小売事業者側) • SQL に長けた人材が多く、結果として様々な指標が dbt パイプライン上に存在 ◦ 分析をするために必要な SQL の考え方とデータ基盤を作っていくのに必要な SQL の考え方は 違う (データ基盤のためのリーダブル SQL) • 今回の発表内容: データ品質問題の実例とその原因を明らかにし、このような設 計だったらスムーズに改善が進んだ・このような設計だったから改善するのに骨 が折れたを提示していきます
©2023 10X, Inc. 目次 10 1. データ品質問題の実例と原因 2. 変更容易性が低かった設計と 高かった設計
3. 今0からデータ基盤を作るなら? 4. まとめ
©2023 10X, Inc. 11 データ品質問題の実例と原因
©2023 10X, Inc. 実例1: join ミスによるデータの不整合 • 実例 ◦ 店舗は
store_id で join できると思って使っていたが、実際には retaile_id と組み合わせて使わな いといけなかった • 原因 ◦ surrogate_key の設計不足 ◦ テスト不足 データ品質問題の実例と原因
©2023 10X, Inc. 実例2: 根本原因および影響範囲特定の遅延 • 実例 ◦ 怪しい数字の特定自体に時間がかかる ◦
どこかの数字を修正したら、想定外の影響が他の mart で生じる • 原因 ◦ レイヤーの責務分割が不十分 ▪ 中間層が他の mart 層のモデルを参照していたり、 mart 層が 他のmart を参照していたり データ品質問題の実例と原因
©2023 10X, Inc. 実例3: 指標の横展開の困難さ • 実例 ◦ 特定の小売業者に出していた指標を他の小売業者に展開するときに、 mart
の内容をコピペして 作る → 修正があるとパートナー数分修正が必要になる ◦ 仮名加工化という、全テーブルに対して共通の処理をかけるときにすごく大変だった ▪ 仮名加工化の実践: データ分析基盤における挑戦と学び • 原因 ◦ 特定パートナーから小さく試してみるものと、全パートナーに展開する指標の境目が曖昧 ▪ 試してみて、良さそうなのであれば全パートナー向けにどの品質で作り直すかが定まってい なかった ◦ 指標やビジネスロジックの SSoT が表現されていない ◦ レイヤーの責務分割が不十分 データ品質問題の実例と原因
©2023 10X, Inc. 15 変更容易性が低かった設計と 高かった設計
©2023 10X, Inc. 変更容易性が低かった設計と高かった設計 変更容易性が低かった設計と高かった設計 低かった設計 ・モデルの参照ルールが不明瞭 ・mart が mart
を参照する構造 ・社外向けのモデルが社内向けのモデルを参照する構造 ・共通化が不足している 高かった設計 ・各レイヤーの役割と責任を明確にし、レイヤー間の依存関係がシンプル ・上記に制約を設ける ・データモデリングの意図が明確 ・テストによって守られている
©2023 10X, Inc. 変更容易性が低かった設計 • モデルの参照ルールが不明瞭 ◦ リネージが複雑に絡み合っていて、どこでなんの処理をしているのかを理解するのがとても大変 になる ◦
バグが発生していた際に、どこにバグが潜んでいるのかを特定するのが難しい ◦ リファクタリングが困難 • mart が mart を参照する構造 ◦ 依存関係の複雑化に繋がる ◦ 依存元の要件が変更になった際に、別の mart にも影響がでてしまい、要件を調整し続ける必要 がでてきてしまう ◦ リファクタリングが困難 変更容易性が低かった設計と高かった設計
©2023 10X, Inc. 変更容易性が低かった設計 • 社外向けのモデルが社内向けのモデルを参照する構造 ◦ 10X では dimensional
modeling 層から社外向けの mart を参照する構造を指す ◦ 社内向けにシュッと改善したいものも、社外への影響を調査しなければいけなかったり、「気にし ないといけない」状態になっている • 共通化が不足している ◦ 類似の指標が複数存在し、メンテナンスコストが増加 ◦ 指標の定義が曖昧になり、データの解釈に齟齬が生じる 変更容易性が低かった設計と高かった設計
©2023 10X, Inc. 変更容易性が高かった設計 • 各レイヤーの役割と責任を明確にし、レイヤー間の依存関係がシンプル • 上記に制約を設ける ◦ staging
ではビジネスキーの定義しか行わない ◦ その次のレイヤーでは履歴を考慮したモデルを一定のルール (data vault) に従って生成する、こ こに SQL を書く自由度はない ◦ その次のレイヤーでソフトビジネスルール (変わりうるビジネス要件 )を実装する、積み重なるリ ネージの上限は設定されていて、機械的にチェックされる ◦ dimensional modeling の層は社内向けの adhoc な分析のためのレイヤーとする ◦ 社外向けに提供する BI は mart 経由しか許さない ◦ その mart は社内向けの dimensional modeling 層に依存してはいけない 変更容易性が低かった設計と高かった設計
©2023 10X, Inc. 変更容易性が高かった設計 • データモデリングの意図が明確 ◦ ビジネスプロセスを明確にすることから始める ◦ 共通化できるビジネスルールを共通化する
▪ ビジネスルールを司るレイヤーを意識する ▪ mart で同じロジックが散見され始めたらそのレイヤーにビジネスルールを固める • テストによって守られている ◦ dbt のテスト、constraints を利用しながら自動テストを入れる ◦ レイヤー及びモデルの責務が分割された上で進めていくとテストするものが明確になりやすい 変更容易性が低かった設計と高かった設計
©2023 10X, Inc. 21 今0からデータ基盤を作るなら?
©2023 10X, Inc. 今0からデータパイプラインを作るなら? • data vault は必ずしも初期から採用しない ◦ 時間に余裕があって、ビジネスキーが明確になっていれば採用してもいいかも
• データモデリング自体を意識する ◦ ビジネスキーとして何を用いるのが適切なのかを考えること ◦ 自分たちが取り扱うサービスにはどのようなビジネスプロセスがあり、それらはどのようなビジネス イベントとして表現されるかを考えること • テスト ◦ dbt test、constraints を用いて「ここまではテストや制約が保証してくれている」というアンカーポイ ントを打っていく ◦ どのレイヤーでどのようなテストを書くべきかを明確にすること 今0からデータパイプラインを作るなら?
©2023 10X, Inc. 今0からデータパイプラインを作るなら? • 「撤退日、撤退条件、品質担保して作り直す条件」を握らないまま adhoc なモデル を作り続けない ◦
データモデリングが整って、あらゆるケースに迅速に対応できるにはそれなりに時間がかかること もある、その中でより短い時間軸でモデルが必要になることもある ◦ そのような時にあらゆる制約を無視したモデルを提供することもでてきうる ◦ そのような例外的な状況を許容することも必要だが、例外的な状況を許し続けないことを握ってお く ◦ dbt の deprecation_date を使いながら機械的にチェックしておく • 「この塊であると便利」な大福帳中間テーブルを作らない ◦ そのテーブルが参照の集合体となりモンスターになる ◦ 作るのも大変だと思うので、これを作るくらいならそのレイヤーにおけるそのモデルの持つべき役 割を考える方が良いと考える 今0からデータパイプラインを作るなら?
©2023 10X, Inc. 24 まとめ
©2023 10X, Inc. まとめ • データ基盤のデータ品質を守り続けるには、変更容易性が高くモデリングを磨い ていけることが重要と考える • 「変更容易性」を高める上で重要になってくるのは「データモデリング」と「制約」で ある
• データモデリングを怠ると、変更容易性が低いモデルが積み重なっていく ◦ 要件ができたから、このモデルを作らないといけなくなる、その影響ははじめのレイヤーまで及ぶ ことがある • 制約を怠ると、実装者によって何をどこで書くかの違いが生まれてしまう ◦ ただビジネスイベントを記録する部分、ただ履歴を保存する部分に創造性はさほどいらない
©2023 10X, Inc. 26 ご清聴ありがとうございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}