Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
【データ分析コンペ×生成AI】妙だな…をLLMに気付かせる
Search
tonic
July 27, 2025
2k
7
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
【データ分析コンペ×生成AI】妙だな…をLLMに気付かせる
tonic
July 27, 2025
More Decks by tonic
See All by tonic
Optiver参戦記&銀メダル解法
tonic
0
760
金融時系列のためのデータ拡張入門
tonic
4
1.7k
Featured
See All Featured
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
190
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
490
HDC tutorial
michielstock
2
750
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
Navigating Weather and Climate Data
rabernat
0
370
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
200
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
420
The Limits of Empathy - UXLibs8
cassininazir
1
500
Scaling GitHub
holman
464
140k
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
340
Transcript
妙だな…をLLMに気付かせる MCPサーバで始めるデータと対話可能なAIの作り方 データ分析コンペ x コード生成AI 勉強会 2025/07/27
自己紹介 tonic(@tonic3561) 所属: 合同会社AlgoSphere 代表 Kaggle: 万年Expert(5x🥈) 専門: 時系列予測
もくじ
もくじ 1. コンペ x 生成AIの現在地
もくじ 1. コンペ x 生成AIの現在地 2. LLMが直面するデータ分析の壁
もくじ 1. コンペ x 生成AIの現在地 2. LLMが直面するデータ分析の壁 3. LLMにデータを「触らせる」挑戦
もくじ 1. コンペ x 生成AIの現在地 2. LLMが直面するデータ分析の壁 3. LLMにデータを「触らせる」挑戦 4.
デモ: エージェントによる自律的データ探索
もくじ 1. コンペ x 生成AIの現在地 2. LLMが直面するデータ分析の壁 3. LLMにデータを「触らせる」挑戦 4.
デモ: エージェントによる自律的データ探索 5. まとめと展望
1. コンペ x 生成AIの現在地
LLMは既に優秀なアシスタント データ分析コンペにおいて、LLMは様々な場面で活躍
LLMは既に優秀なアシスタント ✅ 問題設定やデータの説明 データ分析コンペにおいて、LLMは様々な場面で活躍
LLMは既に優秀なアシスタント ✅ 問題設定やデータの説明 ✅ 仮説・アイディアの壁打ち データ分析コンペにおいて、LLMは様々な場面で活躍
LLMは既に優秀なアシスタント ✅ 問題設定やデータの説明 ✅ 仮説・アイディアの壁打ち ✅ 関連論文の調査 データ分析コンペにおいて、LLMは様々な場面で活躍
LLMは既に優秀なアシスタント ✅ 問題設定やデータの説明 ✅ 仮説・アイディアの壁打ち ✅ 関連論文の調査 ✅ アイディアの実装 データ分析コンペにおいて、LLMは様々な場面で活躍
LLMは既に優秀なアシスタント ✅ 問題設定やデータの説明 ✅ 仮説・アイディアの壁打ち ✅ 関連論文の調査 ✅ アイディアの実装 ✅
バグの原因特定 データ分析コンペにおいて、LLMは様々な場面で活躍
LLMは既に優秀なアシスタント ✅ 問題設定やデータの説明 ✅ 仮説・アイディアの壁打ち ✅ 関連論文の調査 ✅ アイディアの実装 ✅
バグの原因特定 ✅ ベースラインの構築 データ分析コンペにおいて、LLMは様々な場面で活躍
だが…あと一歩届かない! ✅ 仮説・アイディアの壁打ち ← ココ
だが…あと一歩届かない! ✅ 仮説・アイディアの壁打ち ← ココ 仮説を立てるためにはデータをよく見るのが一番大切(?) チャットベースのLLMではデータを「触る」ことが難しく、壁打ちくらいが限界
2. LLMが直面する データ分析の壁
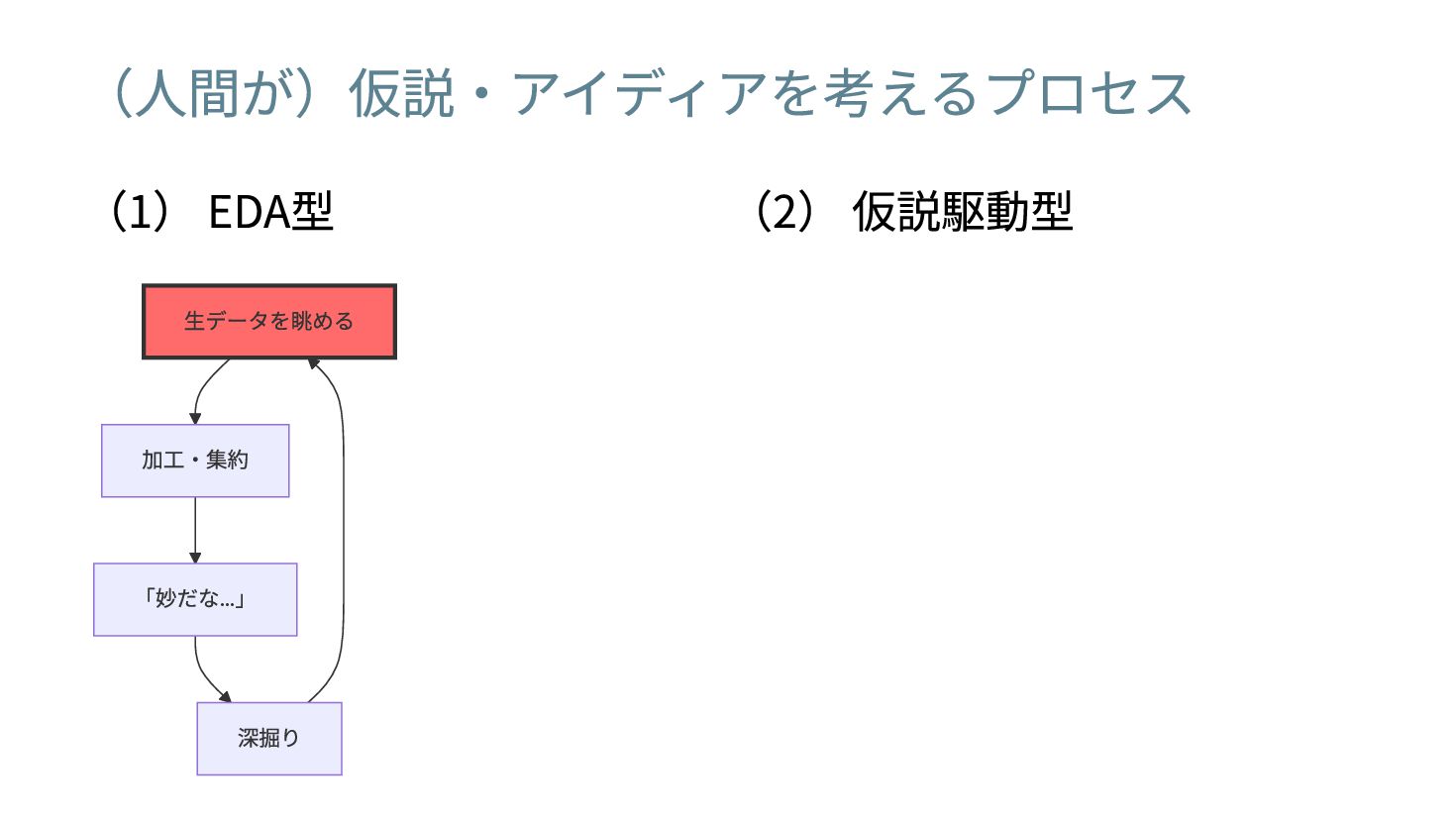
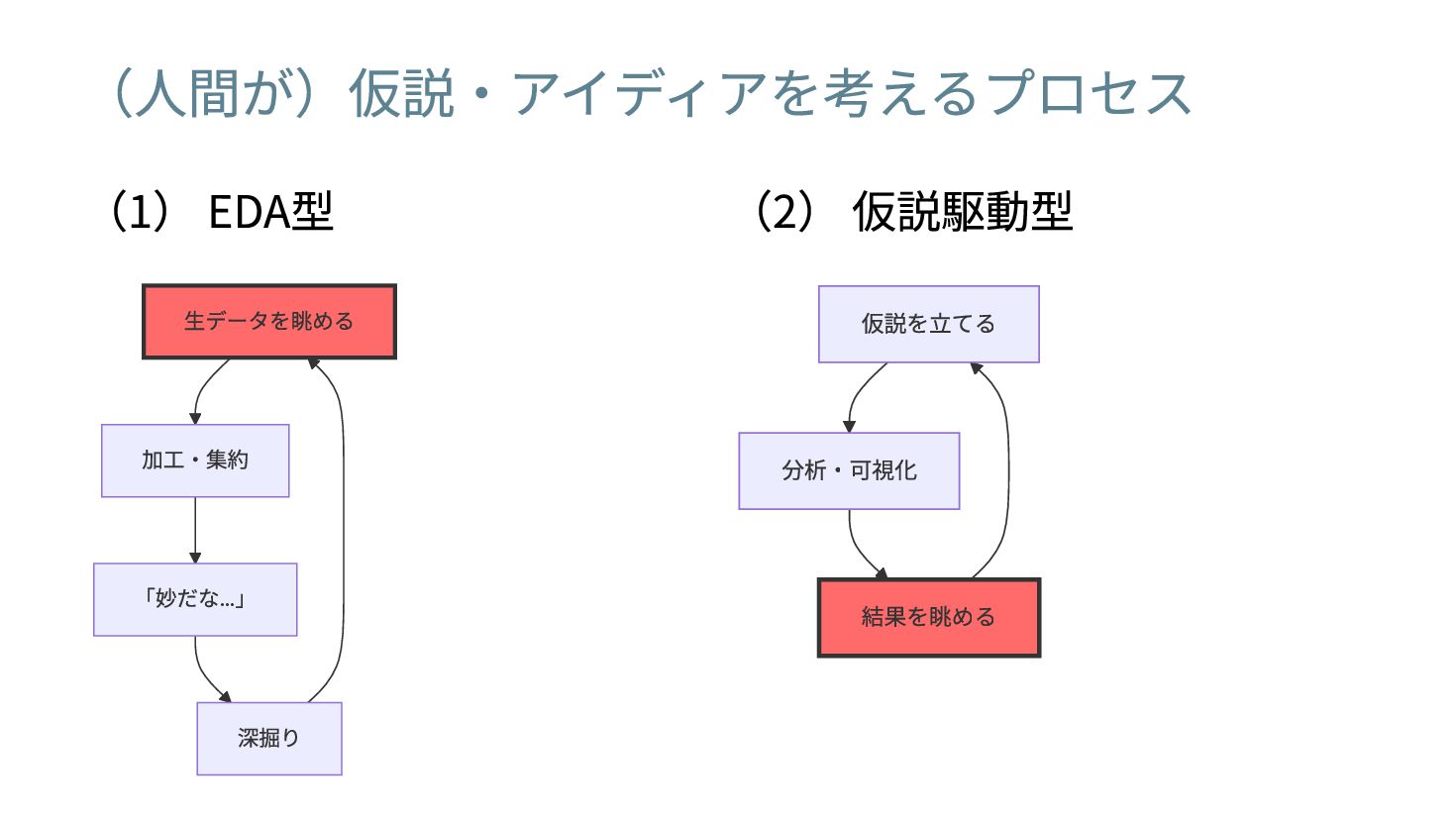
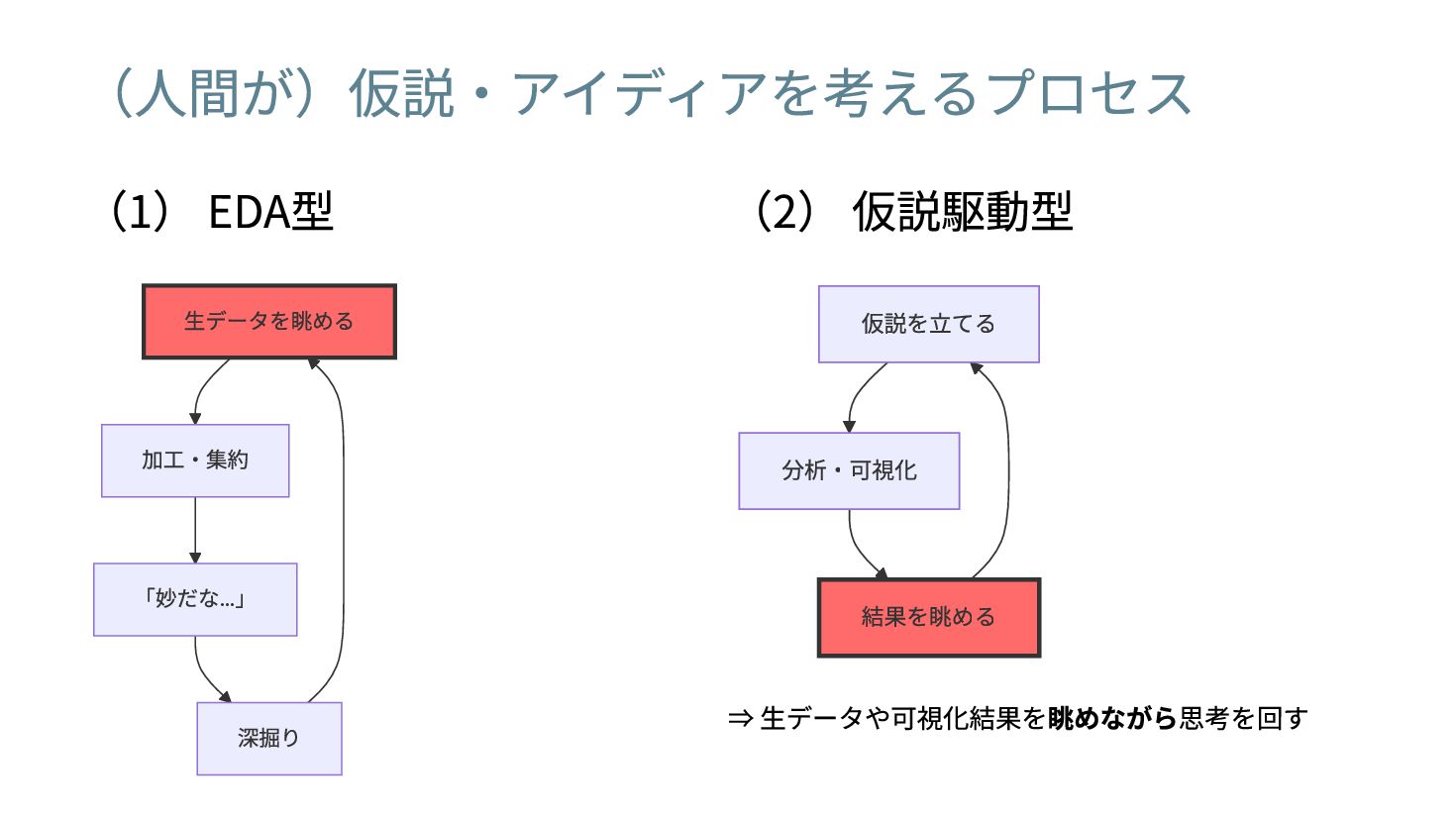
(人間が)仮説・アイディアを考えるプロセス
(人間が)仮説・アイディアを考えるプロセス (1) EDA型 (2) 仮説駆動型
(人間が)仮説・アイディアを考えるプロセス (1) EDA型 生データを眺める 加工・集約 「妙だな… 」 深掘り (2) 仮説駆動型
(人間が)仮説・アイディアを考えるプロセス (1) EDA型 生データを眺める 加工・集約 「妙だな… 」 深掘り (2) 仮説駆動型
仮説を立てる 分析・可視化 結果を眺める
(人間が)仮説・アイディアを考えるプロセス (1) EDA型 生データを眺める 加工・集約 「妙だな… 」 深掘り (2) 仮説駆動型
仮説を立てる 分析・可視化 結果を眺める ⇒ 生データや可視化結果を眺めながら思考を回す
チャットLLMが直面するデータ分析の3つの壁
チャットLLMが直面するデータ分析の3つの壁 (1)コンテキストの壁 巨大なデータはそもそも読み 込んでもらえない コンテキストを維持するのも 大変
チャットLLMが直面するデータ分析の3つの壁 (1)コンテキストの壁 巨大なデータはそもそも読み 込んでもらえない コンテキストを維持するのも 大変 (2)作業の壁 LLMが生成したコードを、人間 がコピペして実行 実行結果のファイル(CSVや画
像)を、人間が確認 その結果やファイルを、人間 がLLMに再入力
チャットLLMが直面するデータ分析の3つの壁 (1)コンテキストの壁 巨大なデータはそもそも読み 込んでもらえない コンテキストを維持するのも 大変 (2)作業の壁 LLMが生成したコードを、人間 がコピペして実行 実行結果のファイル(CSVや画
像)を、人間が確認 その結果やファイルを、人間 がLLMに再入力 (3)思考の壁 分析の「気づき」は、データ を多角的に眺める中で生まれ る LLMは人間が与えた断片的な結 果しか見ることができない?
3. LLMにデータを 「触らせる」挑戦
LLMにデータを触ってもらうには? LLMが自律的に分析を進めるために必要なタスクを分解してみる
LLMにデータを触ってもらうには? 問題設計・データ構造を理解する LLMが自律的に分析を進めるために必要なタスクを分解してみる
LLMにデータを触ってもらうには? 問題設計・データ構造を理解する 集約・可視化コードを書く LLMが自律的に分析を進めるために必要なタスクを分解してみる
LLMにデータを触ってもらうには? 問題設計・データ構造を理解する 集約・可視化コードを書く 結果をファイル出力する LLMが自律的に分析を進めるために必要なタスクを分解してみる
LLMにデータを触ってもらうには? 問題設計・データ構造を理解する 集約・可視化コードを書く 結果をファイル出力する ファイル (csv, png) を読み込む LLMが自律的に分析を進めるために必要なタスクを分解してみる
LLMにデータを触ってもらうには? 問題設計・データ構造を理解する 集約・可視化コードを書く 結果をファイル出力する ファイル (csv, png) を読み込む 読み込んだテキストや画像を解釈する LLMが自律的に分析を進めるために必要なタスクを分解してみる
LLMにデータを触ってもらうには? 問題設計・データ構造を理解する 集約・可視化コードを書く 結果をファイル出力する ファイル (csv, png) を読み込む 読み込んだテキストや画像を解釈する 上記を繰り返す
LLMが自律的に分析を進めるために必要なタスクを分解してみる
LLMにデータを触ってもらうには? 問題設計・データ構造を理解する → ✅ できる 集約・可視化コードを書く 結果をファイル出力する ファイル (csv, png)
を読み込む 読み込んだテキストや画像を解釈する 上記を繰り返す LLMが自律的に分析を進めるために必要なタスクを分解してみる
LLMにデータを触ってもらうには? 問題設計・データ構造を理解する → ✅ できる 集約・可視化コードを書く → ✅ できる 結果をファイル出力する
ファイル (csv, png) を読み込む 読み込んだテキストや画像を解釈する 上記を繰り返す LLMが自律的に分析を進めるために必要なタスクを分解してみる
LLMにデータを触ってもらうには? 問題設計・データ構造を理解する → ✅ できる 集約・可視化コードを書く → ✅ できる 結果をファイル出力する
→ ✅ できる ファイル (csv, png) を読み込む 読み込んだテキストや画像を解釈する 上記を繰り返す LLMが自律的に分析を進めるために必要なタスクを分解してみる
LLMにデータを触ってもらうには? 問題設計・データ構造を理解する → ✅ できる 集約・可視化コードを書く → ✅ できる 結果をファイル出力する
→ ✅ できる ファイル (csv, png) を読み込む → ✅ できる 読み込んだテキストや画像を解釈する 上記を繰り返す LLMが自律的に分析を進めるために必要なタスクを分解してみる
LLMにデータを触ってもらうには? 問題設計・データ構造を理解する → ✅ できる 集約・可視化コードを書く → ✅ できる 結果をファイル出力する
→ ✅ できる ファイル (csv, png) を読み込む → ✅ できる 読み込んだテキストや画像を解釈する → ✅ できる 上記を繰り返す LLMが自律的に分析を進めるために必要なタスクを分解してみる
LLMにデータを触ってもらうには? 問題設計・データ構造を理解する → ✅ できる 集約・可視化コードを書く → ✅ できる 結果をファイル出力する
→ ✅ できる ファイル (csv, png) を読み込む → ✅ できる 読み込んだテキストや画像を解釈する → ✅ できる 上記を繰り返す → ✅ できる LLMが自律的に分析を進めるために必要なタスクを分解してみる
LLMにデータを触ってもらうには? 問題設計・データ構造を理解する → ✅ できる 集約・可視化コードを書く → ✅ できる 結果をファイル出力する
→ ✅ できる ファイル (csv, png) を読み込む → ✅ できる 読み込んだテキストや画像を解釈する → ✅ できる 上記を繰り返す → ✅ できる ⇒ 個別のタスクはすべて実現可能。 LLMが自律的に分析を進めるために必要なタスクを分解してみる
LLMにデータを触ってもらうには? 問題設計・データ構造を理解する → ✅ できる 集約・可視化コードを書く → ✅ できる 結果をファイル出力する
→ ✅ できる ファイル (csv, png) を読み込む → ✅ できる 読み込んだテキストや画像を解釈する → ✅ できる 上記を繰り返す → ✅ できる ⇒ 個別のタスクはすべて実現可能。 あれれ~? LLMが自律的に分析を進めるために必要なタスクを分解してみる
作ってみました 題材:Predict Droughts using Weather & Soil Data Gitリポジトリ:https://github.com/jintonic3561/comp_with_agent claude
codeとMCPサーバを活用して、自律的にEDAを行うエージェントを作りました
題材紹介: U.S. Drought Prediction 入力データ 時系列データ (気象) 日々の気温、降水量、風速など 時系列方法に train
/ valid / test を分割 静的データ (地理・土壌) 郡ごとの標高、傾斜、土地の種類など fips (郡ID) で時系列データに左結合 予測タスク 目的変数 週間の干ばつ深刻度を表す 0〜5 の6段階カテゴリ 評価指標 Macro F1 Score MAE 気象・土壌データから、専門家が作成する「干ばつマップ」の自動化を目指す予測タスク
補足…MCPサーバとは? ざっくり: 簡単に渡せる電卓みたいなもん LLM(と人間)は暗算が苦手 → 人間と同じように、LLMにも電卓とか渡してあげればいいんじゃない? → ほかにもいろんなツールを使ってもらおう! 電卓 ファイルアクセス
Web検索 …
構築したMCPサーバ一覧 MCPサーバ名 役割 説明 Data Information 設計情報DB 問題設計や利用可能なデータの説明、列定義などの取得 Analysis Executor
分析実行環境 LLMから渡されたコードを実行し、その結果を返す Notebook Writer レポート作成 実行したコードと結果、考察をnotebookにまとめる ※ 各MCPサーバの中に、複数の「ツール」が実装されている LLMにデータを触ってもらうために、3つのMCPサーバを作りました
ツール① DI.get_data_description データの列定義等の情報に立ち返るためのツール def get_data_description( data_type: Literal["timeseries", "soil_data"] ) ->
str: if data_type == "timeseries": return """ # データ概要 このデータは、米国の干ばつ… # 列定義 | 列名 | データ型 | 説明 | | --- | --- | --- | | fips | int | 米国郡のFIPSコード | ... """ elif data_type == "soil_data": ... ...
ツール① DI.get_data_description データの列定義等の情報に立ち返るためのツール data_type: Literal["timeseries", "soil_data"] def get_data_description( ) ->
str: if data_type == "timeseries": return """ # データ概要 このデータは、米国の干ばつ… # 列定義 | 列名 | データ型 | 説明 | | --- | --- | --- | | fips | int | 米国郡のFIPSコード | ... """ elif data_type == "soil_data": ... ...
ツール① DI.get_data_description データの列定義等の情報に立ち返るためのツール ) -> str: if data_type == "timeseries":
return """ # データ概要 このデータは、米国の干ばつ… # 列定義 | 列名 | データ型 | 説明 | | --- | --- | --- | | fips | int | 米国郡のFIPSコード | ... """ def get_data_description( data_type: Literal["timeseries", "soil_data"] elif data_type == "soil_data": ... ...
ツール① DI.get_data_description データの列定義等の情報に立ち返るためのツール data_type: Literal["timeseries", "soil_data"] def get_data_description( ) ->
str: if data_type == "timeseries": return """ # データ概要 このデータは、米国の干ばつ… # 列定義 | 列名 | データ型 | 説明 | | --- | --- | --- | | fips | int | 米国郡のFIPSコード | ... """ elif data_type == "soil_data": ... ...
ツール① DI.get_data_description データの列定義等の情報に立ち返るためのツール elif data_type == "soil_data": ... ... def
get_data_description( data_type: Literal["timeseries", "soil_data"] ) -> str: if data_type == "timeseries": return """ # データ概要 このデータは、米国の干ばつ… # 列定義 | 列名 | データ型 | 説明 | | --- | --- | --- | | fips | int | 米国郡のFIPSコード | ... """
ツール① DI.get_data_description データの列定義等の情報に立ち返るためのツール def get_data_description( data_type: Literal["timeseries", "soil_data"] ) ->
str: if data_type == "timeseries": return """ # データ概要 このデータは、米国の干ばつ… # 列定義 | 列名 | データ型 | 説明 | | --- | --- | --- | | fips | int | 米国郡のFIPSコード | ... """ elif data_type == "soil_data": ... ...
ツール② AE.execute_timeseries_analysis LLMが生成した関数を実行し、結果を返すためのツール def execute_timeseries_analysis( func_string: str, data_type: Literal["train", "validation",
"test"] ) -> List[str]: """ 関数定義は以下の要件を満たすように実装すること: - 引数として `df: pd.DataFrame` のみを取ること - dfには `{data_type}_timeseries.csv` の内容が格納される - csvまたはpng形式の分析結果を関数内でファイル保存すること - 関数の返り値は保存した分析結果のpath、またはそのリストとすること このツールを呼び出した後は、分析結果を必ず読み込んで考察を行うこと """ # 実行する関数に渡すデータを読み込む df = load_data(data_type) # LLMが生成した関数を実行し、結果を返却 return _execute_function(func_string, df)
ツール② AE.execute_timeseries_analysis LLMが生成した関数を実行し、結果を返すためのツール func_string: str, def execute_timeseries_analysis( data_type: Literal["train", "validation",
"test"] ) -> List[str]: """ 関数定義は以下の要件を満たすように実装すること: - 引数として `df: pd.DataFrame` のみを取ること - dfには `{data_type}_timeseries.csv` の内容が格納される - csvまたはpng形式の分析結果を関数内でファイル保存すること - 関数の返り値は保存した分析結果のpath、またはそのリストとすること このツールを呼び出した後は、分析結果を必ず読み込んで考察を行うこと """ # 実行する関数に渡すデータを読み込む df = load_data(data_type) # LLMが生成した関数を実行し、結果を返却 return _execute_function(func_string, df)
ツール② AE.execute_timeseries_analysis LLMが生成した関数を実行し、結果を返すためのツール data_type: Literal["train", "validation", "test"] def execute_timeseries_analysis( func_string:
str, ) -> List[str]: """ 関数定義は以下の要件を満たすように実装すること: - 引数として `df: pd.DataFrame` のみを取ること - dfには `{data_type}_timeseries.csv` の内容が格納される - csvまたはpng形式の分析結果を関数内でファイル保存すること - 関数の返り値は保存した分析結果のpath、またはそのリストとすること このツールを呼び出した後は、分析結果を必ず読み込んで考察を行うこと """ # 実行する関数に渡すデータを読み込む df = load_data(data_type) # LLMが生成した関数を実行し、結果を返却 return _execute_function(func_string, df)
ツール② AE.execute_timeseries_analysis LLMが生成した関数を実行し、結果を返すためのツール """ 関数定義は以下の要件を満たすように実装すること: - 引数として `df: pd.DataFrame` のみを取ること
- dfには `{data_type}_timeseries.csv` の内容が格納される - csvまたはpng形式の分析結果を関数内でファイル保存すること - 関数の返り値は保存した分析結果のpath、またはそのリストとすること このツールを呼び出した後は、分析結果を必ず読み込んで考察を行うこと """ def execute_timeseries_analysis( func_string: str, data_type: Literal["train", "validation", "test"] ) -> List[str]: # 実行する関数に渡すデータを読み込む df = load_data(data_type) # LLMが生成した関数を実行し、結果を返却 return _execute_function(func_string, df)
ツール② AE.execute_timeseries_analysis LLMが生成した関数を実行し、結果を返すためのツール 関数定義は以下の要件を満たすように実装すること: def execute_timeseries_analysis( func_string: str, data_type: Literal["train",
"validation", "test"] ) -> List[str]: """ - 引数として `df: pd.DataFrame` のみを取ること - dfには `{data_type}_timeseries.csv` の内容が格納される - csvまたはpng形式の分析結果を関数内でファイル保存すること - 関数の返り値は保存した分析結果のpath、またはそのリストとすること このツールを呼び出した後は、分析結果を必ず読み込んで考察を行うこと """ # 実行する関数に渡すデータを読み込む df = load_data(data_type) # LLMが生成した関数を実行し、結果を返却 return _execute_function(func_string, df)
ツール② AE.execute_timeseries_analysis LLMが生成した関数を実行し、結果を返すためのツール - 引数として `df: pd.DataFrame` のみを取ること def execute_timeseries_analysis(
func_string: str, data_type: Literal["train", "validation", "test"] ) -> List[str]: """ 関数定義は以下の要件を満たすように実装すること: - dfには `{data_type}_timeseries.csv` の内容が格納される - csvまたはpng形式の分析結果を関数内でファイル保存すること - 関数の返り値は保存した分析結果のpath、またはそのリストとすること このツールを呼び出した後は、分析結果を必ず読み込んで考察を行うこと """ # 実行する関数に渡すデータを読み込む df = load_data(data_type) # LLMが生成した関数を実行し、結果を返却 return _execute_function(func_string, df)
ツール② AE.execute_timeseries_analysis LLMが生成した関数を実行し、結果を返すためのツール - dfには `{data_type}_timeseries.csv` の内容が格納される def execute_timeseries_analysis( func_string:
str, data_type: Literal["train", "validation", "test"] ) -> List[str]: """ 関数定義は以下の要件を満たすように実装すること: - 引数として `df: pd.DataFrame` のみを取ること - csvまたはpng形式の分析結果を関数内でファイル保存すること - 関数の返り値は保存した分析結果のpath、またはそのリストとすること このツールを呼び出した後は、分析結果を必ず読み込んで考察を行うこと """ # 実行する関数に渡すデータを読み込む df = load_data(data_type) # LLMが生成した関数を実行し、結果を返却 return _execute_function(func_string, df)
ツール② AE.execute_timeseries_analysis LLMが生成した関数を実行し、結果を返すためのツール - csvまたはpng形式の分析結果を関数内でファイル保存すること def execute_timeseries_analysis( func_string: str, data_type:
Literal["train", "validation", "test"] ) -> List[str]: """ 関数定義は以下の要件を満たすように実装すること: - 引数として `df: pd.DataFrame` のみを取ること - dfには `{data_type}_timeseries.csv` の内容が格納される - 関数の返り値は保存した分析結果のpath、またはそのリストとすること このツールを呼び出した後は、分析結果を必ず読み込んで考察を行うこと """ # 実行する関数に渡すデータを読み込む df = load_data(data_type) # LLMが生成した関数を実行し、結果を返却 return _execute_function(func_string, df)
ツール② AE.execute_timeseries_analysis LLMが生成した関数を実行し、結果を返すためのツール ) -> List[str]: - 関数の返り値は保存した分析結果のpath、またはそのリストとすること def execute_timeseries_analysis(
func_string: str, data_type: Literal["train", "validation", "test"] """ 関数定義は以下の要件を満たすように実装すること: - 引数として `df: pd.DataFrame` のみを取ること - dfには `{data_type}_timeseries.csv` の内容が格納される - csvまたはpng形式の分析結果を関数内でファイル保存すること このツールを呼び出した後は、分析結果を必ず読み込んで考察を行うこと """ # 実行する関数に渡すデータを読み込む df = load_data(data_type) # LLMが生成した関数を実行し、結果を返却 return _execute_function(func_string, df)
ツール② AE.execute_timeseries_analysis LLMが生成した関数を実行し、結果を返すためのツール このツールを呼び出した後は、分析結果を必ず読み込んで考察を行うこと def execute_timeseries_analysis( func_string: str, data_type: Literal["train",
"validation", "test"] ) -> List[str]: """ 関数定義は以下の要件を満たすように実装すること: - 引数として `df: pd.DataFrame` のみを取ること - dfには `{data_type}_timeseries.csv` の内容が格納される - csvまたはpng形式の分析結果を関数内でファイル保存すること - 関数の返り値は保存した分析結果のpath、またはそのリストとすること """ # 実行する関数に渡すデータを読み込む df = load_data(data_type) # LLMが生成した関数を実行し、結果を返却 return _execute_function(func_string, df)
ツール② AE.execute_timeseries_analysis LLMが生成した関数を実行し、結果を返すためのツール # 実行する関数に渡すデータを読み込む df = load_data(data_type) def execute_timeseries_analysis(
func_string: str, data_type: Literal["train", "validation", "test"] ) -> List[str]: """ 関数定義は以下の要件を満たすように実装すること: - 引数として `df: pd.DataFrame` のみを取ること - dfには `{data_type}_timeseries.csv` の内容が格納される - csvまたはpng形式の分析結果を関数内でファイル保存すること - 関数の返り値は保存した分析結果のpath、またはそのリストとすること このツールを呼び出した後は、分析結果を必ず読み込んで考察を行うこと """ # LLMが生成した関数を実行し、結果を返却 return _execute_function(func_string, df)
ツール② AE.execute_timeseries_analysis LLMが生成した関数を実行し、結果を返すためのツール # LLMが生成した関数を実行し、結果を返却 return _execute_function(func_string, df) def execute_timeseries_analysis(
func_string: str, data_type: Literal["train", "validation", "test"] ) -> List[str]: """ 関数定義は以下の要件を満たすように実装すること: - 引数として `df: pd.DataFrame` のみを取ること - dfには `{data_type}_timeseries.csv` の内容が格納される - csvまたはpng形式の分析結果を関数内でファイル保存すること - 関数の返り値は保存した分析結果のpath、またはそのリストとすること このツールを呼び出した後は、分析結果を必ず読み込んで考察を行うこと """ # 実行する関数に渡すデータを読み込む df = load_data(data_type)
ツール② AE.execute_timeseries_analysis LLMが生成した関数を実行し、結果を返すためのツール def execute_timeseries_analysis( func_string: str, data_type: Literal["train", "validation",
"test"] ) -> List[str]: """ 関数定義は以下の要件を満たすように実装すること: - 引数として `df: pd.DataFrame` のみを取ること - dfには `{data_type}_timeseries.csv` の内容が格納される - csvまたはpng形式の分析結果を関数内でファイル保存すること - 関数の返り値は保存した分析結果のpath、またはそのリストとすること このツールを呼び出した後は、分析結果を必ず読み込んで考察を行うこと """ # 実行する関数に渡すデータを読み込む df = load_data(data_type) # LLMが生成した関数を実行し、結果を返却 return _execute_function(func_string, df)
ツール③ NW.add_cell_to_notebook 分析のコードや結果をJupyter Notebookに逐次記録するツール def add_cell_to_notebook( content: str, cell_type: Literal["code",
"markdown"], artifact_paths: List[str] ): # セルを追加する nb = load_or_create_notebook() cell = create_cell(content, cell_type) nb.cells.append(cell) # 出力ファイルを表示する for path in artifact_paths: # テキストを表示 if path.endswith(".csv"): display_csv(path) # 画像を表示 elif path.endswith(".png"): display_image(path)
ツール③ NW.add_cell_to_notebook 分析のコードや結果をJupyter Notebookに逐次記録するツール content: str, def add_cell_to_notebook( cell_type: Literal["code",
"markdown"], artifact_paths: List[str] ): # セルを追加する nb = load_or_create_notebook() cell = create_cell(content, cell_type) nb.cells.append(cell) # 出力ファイルを表示する for path in artifact_paths: # テキストを表示 if path.endswith(".csv"): display_csv(path) # 画像を表示 elif path.endswith(".png"): display_image(path)
ツール③ NW.add_cell_to_notebook 分析のコードや結果をJupyter Notebookに逐次記録するツール cell_type: Literal["code", "markdown"], def add_cell_to_notebook( content:
str, artifact_paths: List[str] ): # セルを追加する nb = load_or_create_notebook() cell = create_cell(content, cell_type) nb.cells.append(cell) # 出力ファイルを表示する for path in artifact_paths: # テキストを表示 if path.endswith(".csv"): display_csv(path) # 画像を表示 elif path.endswith(".png"): display_image(path)
ツール③ NW.add_cell_to_notebook 分析のコードや結果をJupyter Notebookに逐次記録するツール artifact_paths: List[str] def add_cell_to_notebook( content: str,
cell_type: Literal["code", "markdown"], ): # セルを追加する nb = load_or_create_notebook() cell = create_cell(content, cell_type) nb.cells.append(cell) # 出力ファイルを表示する for path in artifact_paths: # テキストを表示 if path.endswith(".csv"): display_csv(path) # 画像を表示 elif path.endswith(".png"): display_image(path)
ツール③ NW.add_cell_to_notebook 分析のコードや結果をJupyter Notebookに逐次記録するツール # セルを追加する nb = load_or_create_notebook() cell
= create_cell(content, cell_type) nb.cells.append(cell) def add_cell_to_notebook( content: str, cell_type: Literal["code", "markdown"], artifact_paths: List[str] ): # 出力ファイルを表示する for path in artifact_paths: # テキストを表示 if path.endswith(".csv"): display_csv(path) # 画像を表示 elif path.endswith(".png"): display_image(path)
ツール③ NW.add_cell_to_notebook 分析のコードや結果をJupyter Notebookに逐次記録するツール # 出力ファイルを表示する for path in artifact_paths:
def add_cell_to_notebook( content: str, cell_type: Literal["code", "markdown"], artifact_paths: List[str] ): # セルを追加する nb = load_or_create_notebook() cell = create_cell(content, cell_type) nb.cells.append(cell) # テキストを表示 if path.endswith(".csv"): display_csv(path) # 画像を表示 elif path.endswith(".png"): display_image(path)
ツール③ NW.add_cell_to_notebook 分析のコードや結果をJupyter Notebookに逐次記録するツール # テキストを表示 if path.endswith(".csv"): display_csv(path) def
add_cell_to_notebook( content: str, cell_type: Literal["code", "markdown"], artifact_paths: List[str] ): # セルを追加する nb = load_or_create_notebook() cell = create_cell(content, cell_type) nb.cells.append(cell) # 出力ファイルを表示する for path in artifact_paths: # 画像を表示 elif path.endswith(".png"): display_image(path)
ツール③ NW.add_cell_to_notebook 分析のコードや結果をJupyter Notebookに逐次記録するツール # 画像を表示 elif path.endswith(".png"): display_image(path) def
add_cell_to_notebook( content: str, cell_type: Literal["code", "markdown"], artifact_paths: List[str] ): # セルを追加する nb = load_or_create_notebook() cell = create_cell(content, cell_type) nb.cells.append(cell) # 出力ファイルを表示する for path in artifact_paths: # テキストを表示 if path.endswith(".csv"): display_csv(path)
ツール③ NW.add_cell_to_notebook 分析のコードや結果をJupyter Notebookに逐次記録するツール def add_cell_to_notebook( content: str, cell_type: Literal["code",
"markdown"], artifact_paths: List[str] ): # セルを追加する nb = load_or_create_notebook() cell = create_cell(content, cell_type) nb.cells.append(cell) # 出力ファイルを表示する for path in artifact_paths: # テキストを表示 if path.endswith(".csv"): display_csv(path) # 画像を表示 elif path.endswith(".png"): display_image(path)
4. デモ: エージェントによる 自律的データ探索
動かしてみる 出力レポート例 実際にclaude codeが頑張った様子を見てみましょう
5. まとめと展望
まとめと展望 「データを眺めながら考える」という思考プロセスを(少しは)模倣できるようになった ツール(MCPサーバ)を整備してあげれば、それなりに自律的に動いてくれる 問題設計・データ情報を確認するツール 関数を実行して出力を保存するツール 結果を記録するツール ツールを適宜修正すれば、画像・自然言語などにも応用できそう? 今回はEDAしかやってないけど、実験サイクルも回せるようにしたい 今のところやっぱりClaude Codeが優秀
Gemini CLIは関数実装で無限時間かかるコードを書きがちで、完遂できないことが多い → サブエージェントに移譲するようにすれば解決できそう? LLMがデータを触りながら自律的に分析を行えるようになった(?)
Enjoy Kaggle & atmaCup! X (Twitter):@tonic3561 GitHub:https://github.com/jintonic3561 Thanks for listening!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ツール① DI.get_data_description データの列定義等の情報に立ち返るためのツール def get_data_description( data_type: Literal["timeseries", "soil_data"] ) ->](https://files.speakerdeck.com/presentations/14960d81ecbe47c4af372acc489ded64/slide_48.jpg){kind=link}
![ツール① DI.get_data_description データの列定義等の情報に立ち返るためのツール data_type: Literal["timeseries", "soil_data"] def get_data_description( ) ->](https://files.speakerdeck.com/presentations/14960d81ecbe47c4af372acc489ded64/slide_49.jpg){kind=link}
{kind=link}
![ツール① DI.get_data_description データの列定義等の情報に立ち返るためのツール data_type: Literal["timeseries", "soil_data"] def get_data_description( ) ->](https://files.speakerdeck.com/presentations/14960d81ecbe47c4af372acc489ded64/slide_51.jpg){kind=link}
{kind=link}
![ツール① DI.get_data_description データの列定義等の情報に立ち返るためのツール def get_data_description( data_type: Literal["timeseries", "soil_data"] ) ->](https://files.speakerdeck.com/presentations/14960d81ecbe47c4af372acc489ded64/slide_53.jpg){kind=link}
{kind=link}
{kind=link}
![ツール② AE.execute_timeseries_analysis LLMが生成した関数を実行し、結果を返すためのツール data_type: Literal["train", "validation", "test"] def execute_timeseries_analysis( func_string:](https://files.speakerdeck.com/presentations/14960d81ecbe47c4af372acc489ded64/slide_56.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ツール② AE.execute_timeseries_analysis LLMが生成した関数を実行し、結果を返すためのツール ) -> List[str]: - 関数の返り値は保存した分析結果のpath、またはそのリストとすること def execute_timeseries_analysis(](https://files.speakerdeck.com/presentations/14960d81ecbe47c4af372acc489ded64/slide_62.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ツール③ NW.add_cell_to_notebook 分析のコードや結果をJupyter Notebookに逐次記録するツール cell_type: Literal["code", "markdown"], def add_cell_to_notebook( content:](https://files.speakerdeck.com/presentations/14960d81ecbe47c4af372acc489ded64/slide_69.jpg){kind=link}
![ツール③ NW.add_cell_to_notebook 分析のコードや結果をJupyter Notebookに逐次記録するツール artifact_paths: List[str] def add_cell_to_notebook( content: str,](https://files.speakerdeck.com/presentations/14960d81ecbe47c4af372acc489ded64/slide_70.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}