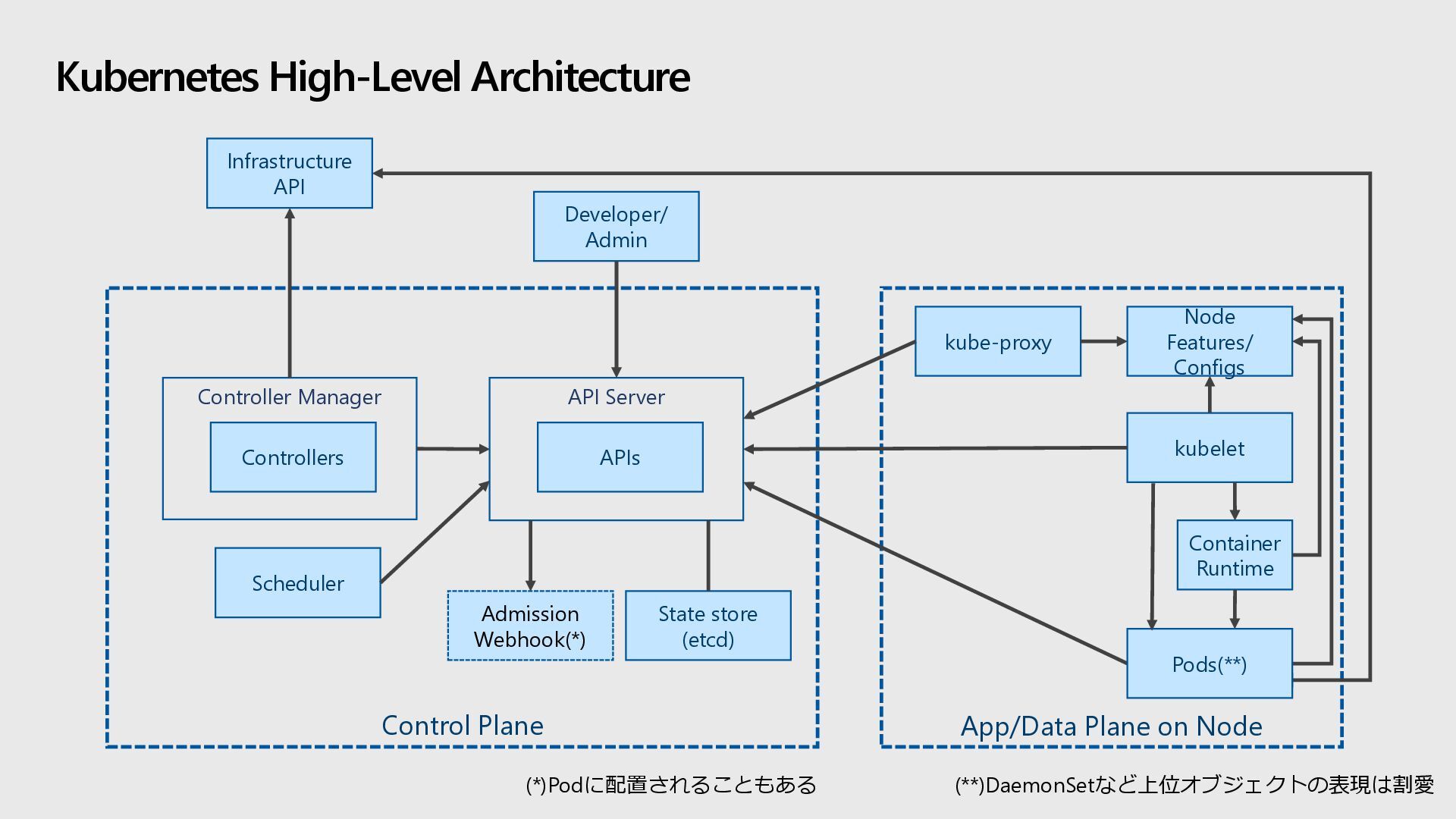
Kubernetes restarts containers that fail, replaces containers, kills containers that don’t respond to your user-defined health check, and doesn’t advertise them to clients until they are ready to serve. What is Kubernetes? – kubernetes.io
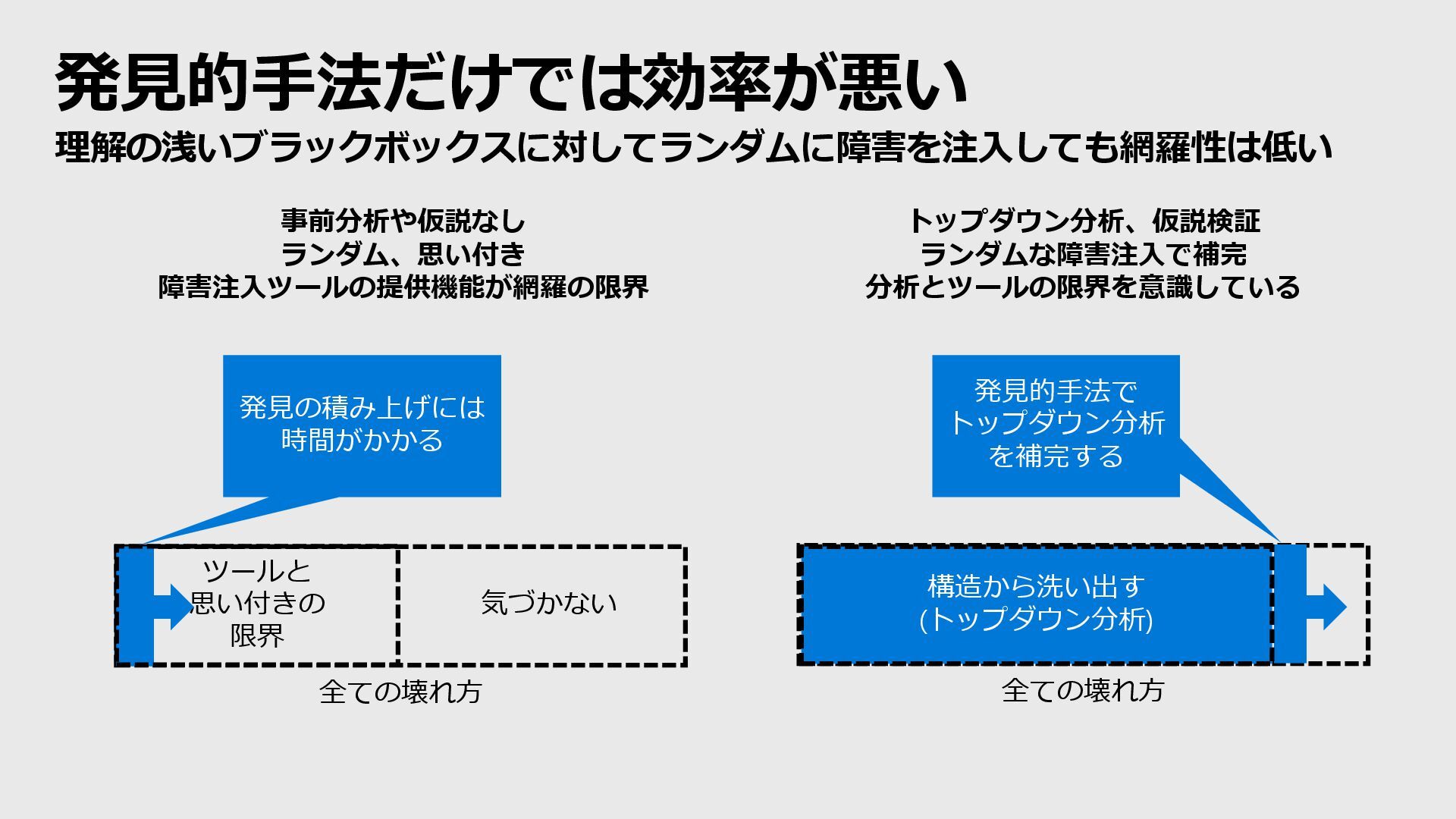
while programmer-guided approaches are only as good as the intuition of a programmer and only scale with human effort. Automating Failure Testing Research at Internet Scale. Alvaro, P et al. ACM Conference Proceedings 2016 pp: 17-28
of a system that indicates normal behavior. 2. Hypothesize that this steady state will continue in both the control group and the experimental group. 3. Introduce variables that reflect real world events like servers that crash, hard drives that malfunction, network connections that are severed, etc. 4. Try to disprove the hypothesis by looking for a difference in steady state between the control group and the experimental group. CHAOS IN PRACTICE - PRINCIPLES OF CHAOS
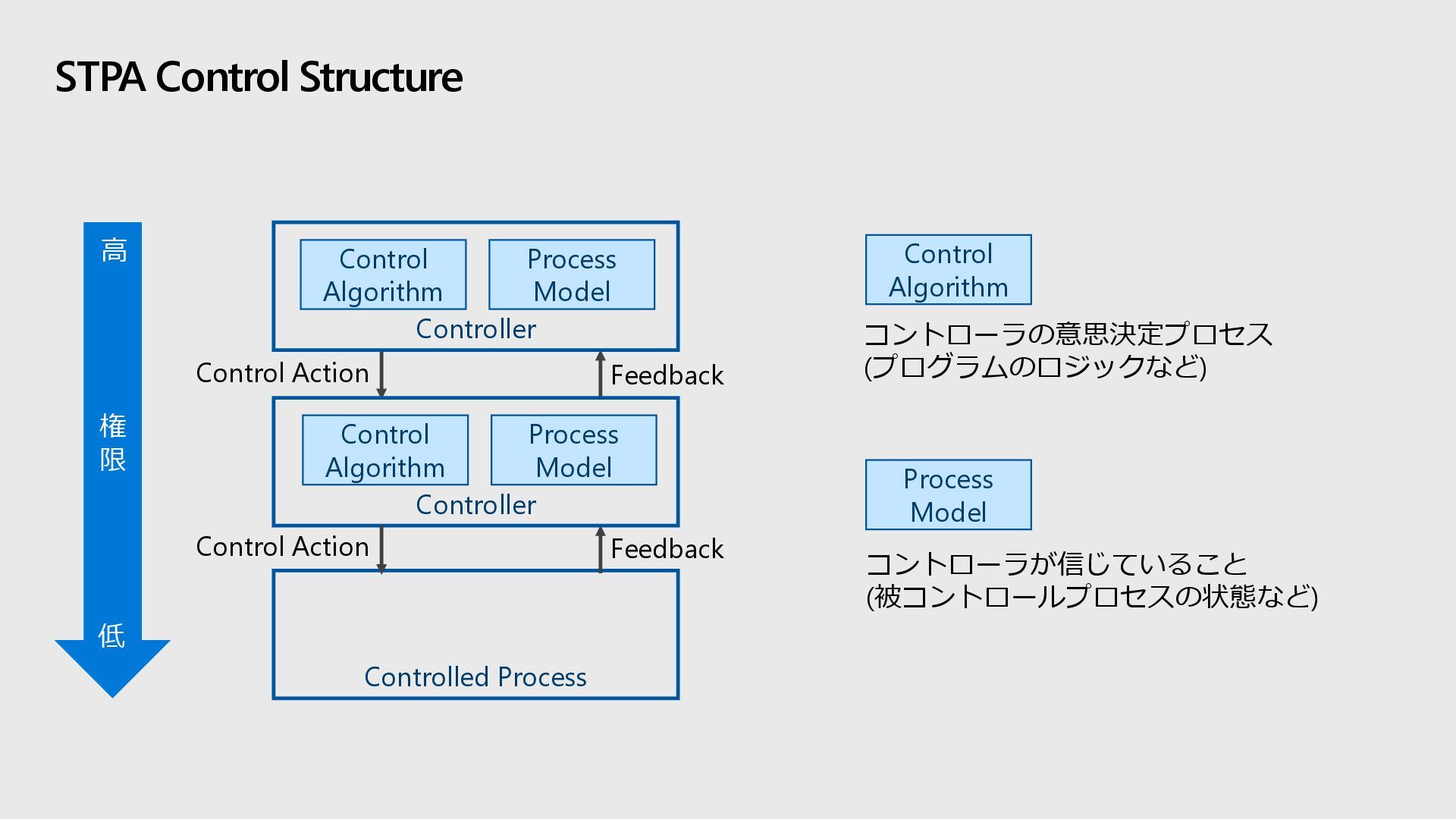
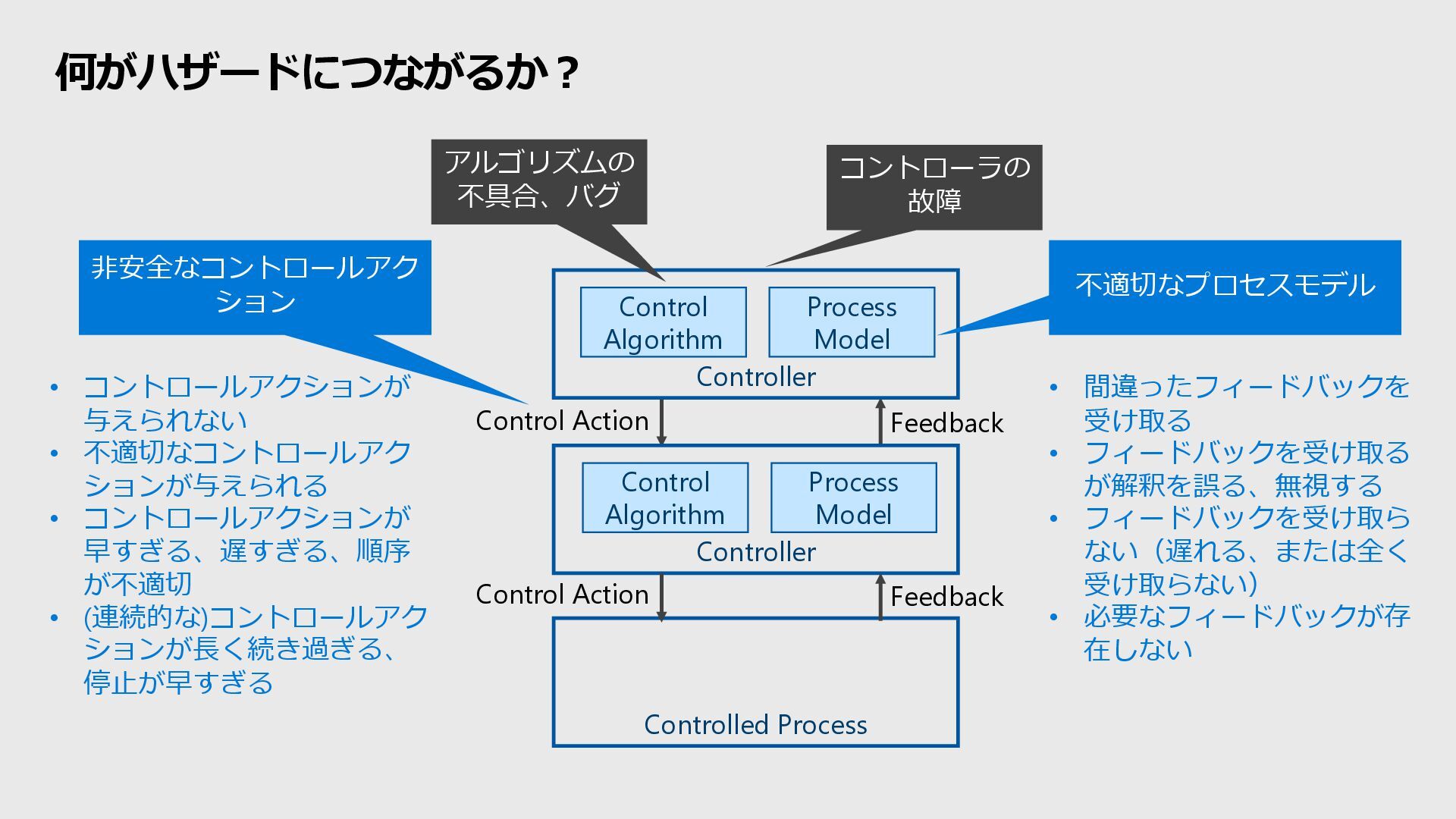
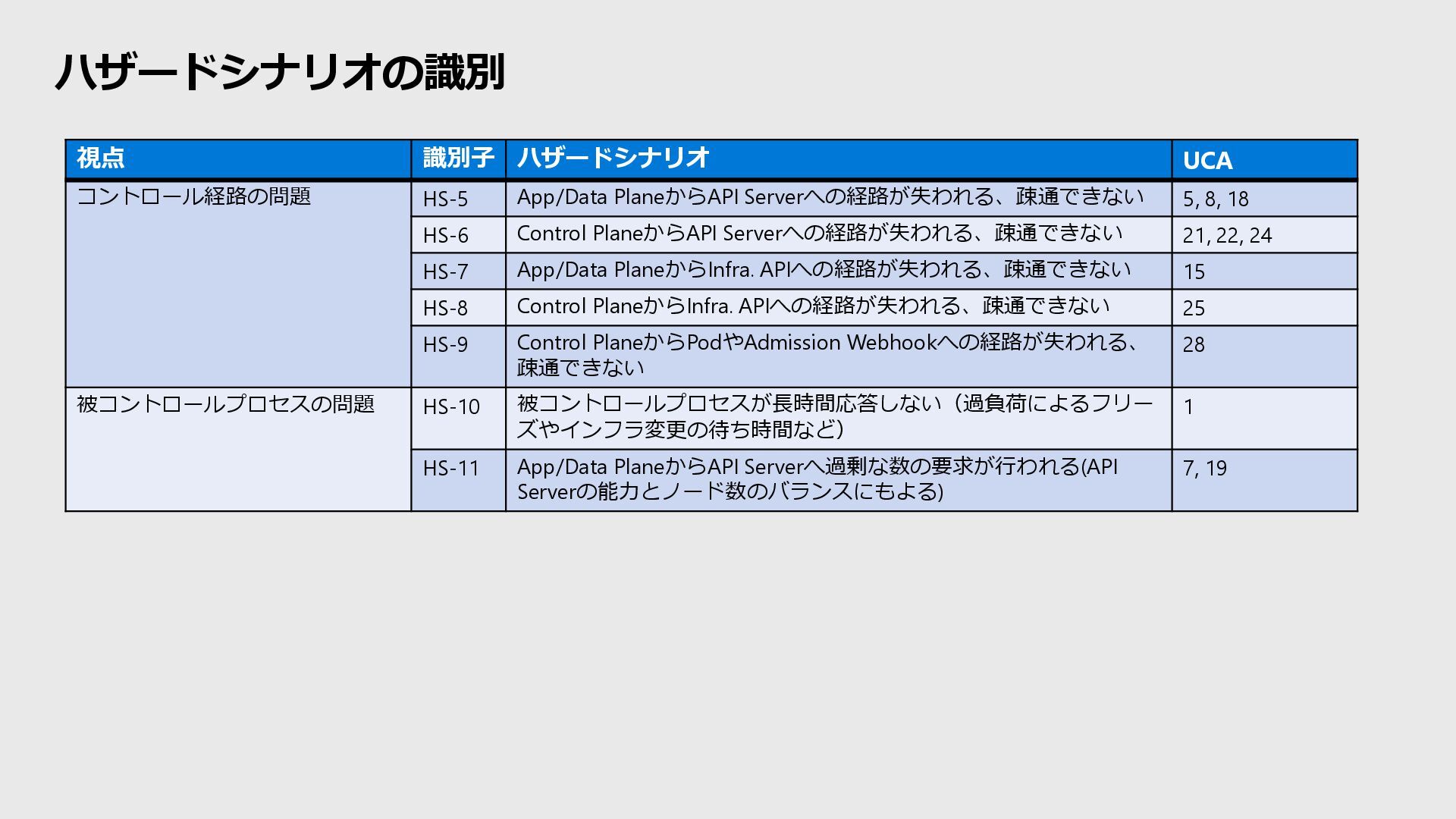
Model Control Algorithm Process Model Control Action Feedback Control Action Feedback 権 限 高 低 Control Algorithm Process Model コントローラの意思決定プロセス (プログラムのロジックなど) コントローラが信じていること (被コントロールプロセスの状態など)
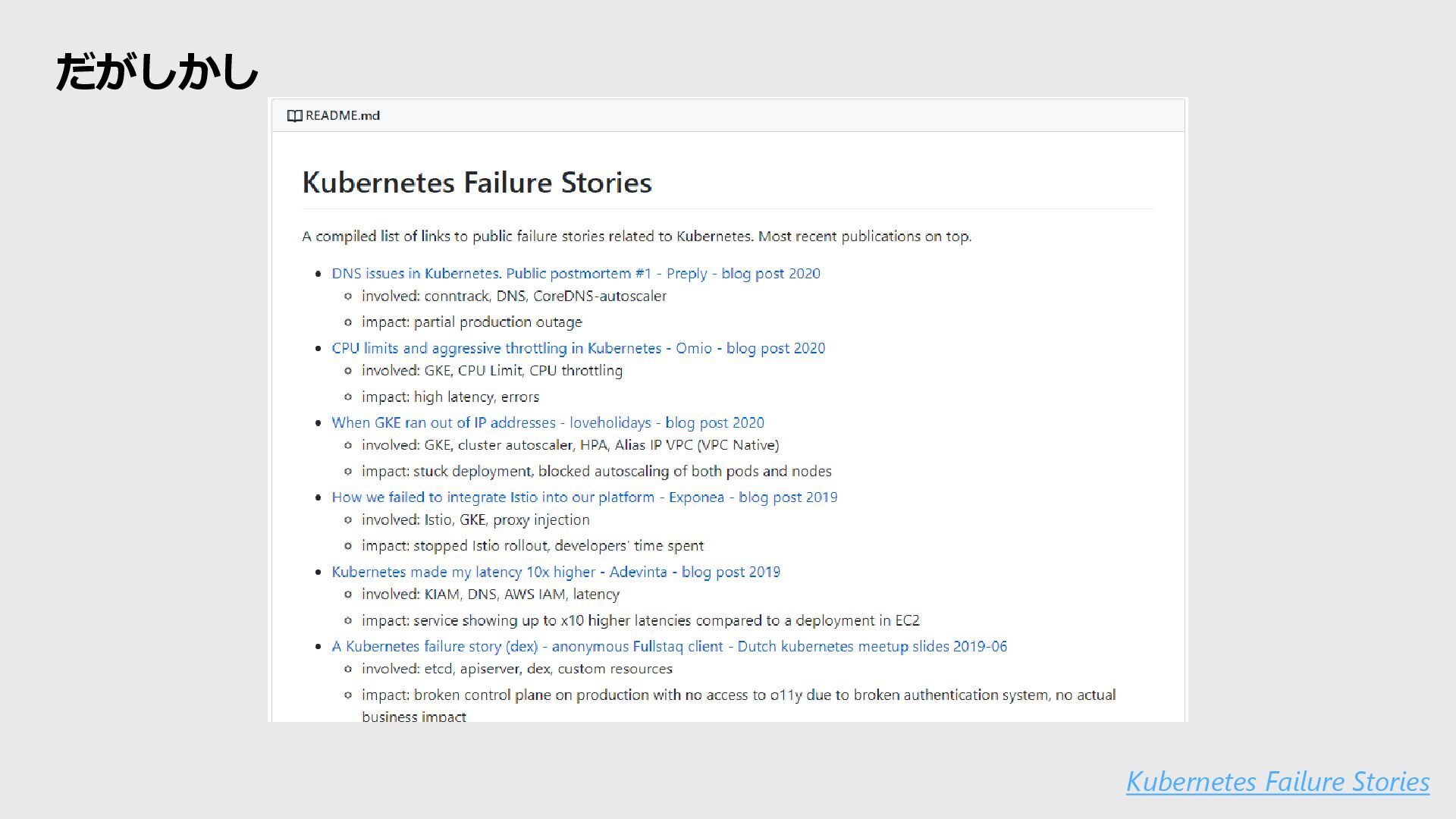
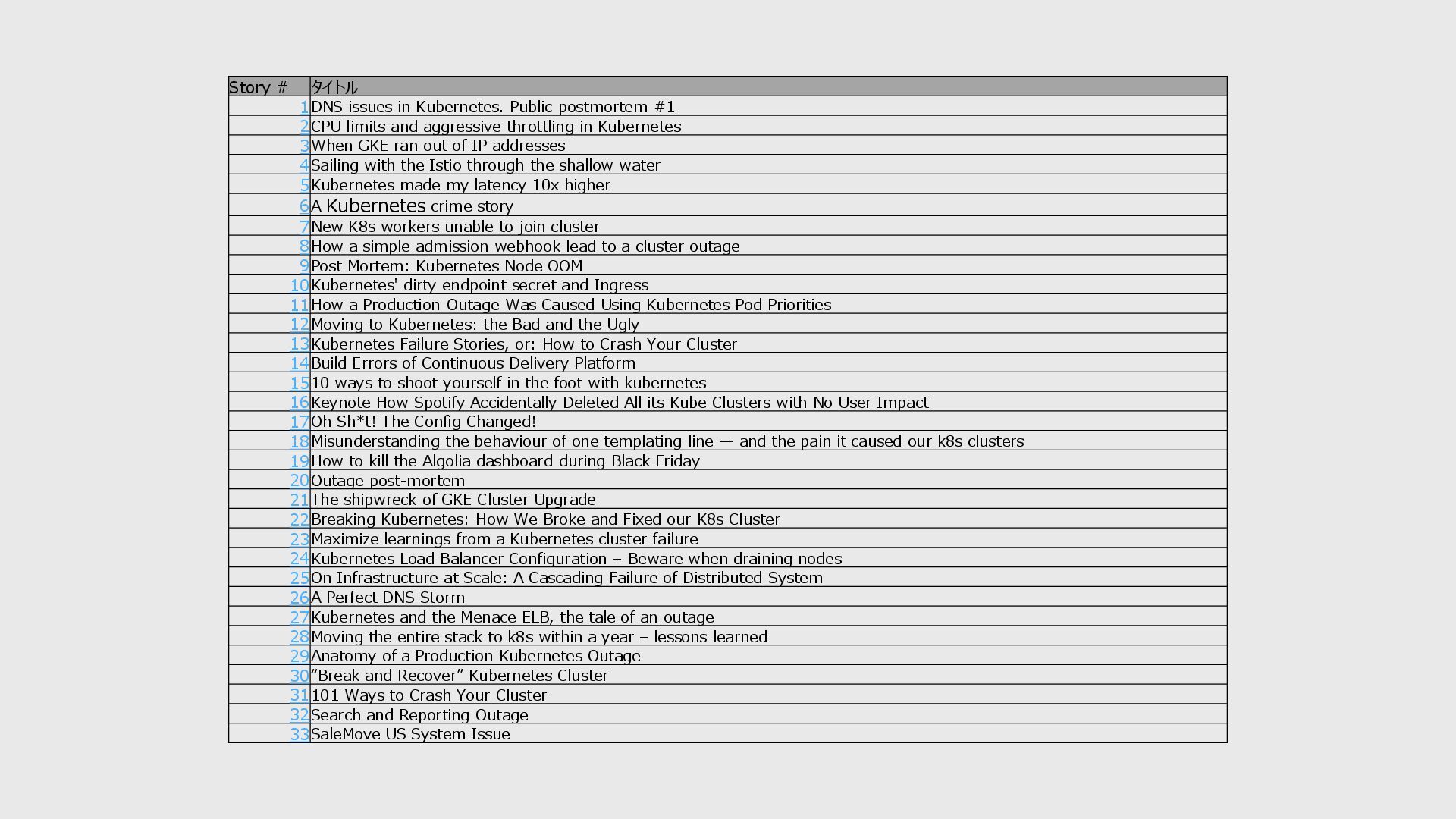
2CPU limits and aggressive throttling in Kubernetes 3When GKE ran out of IP addresses 4Sailing with the Istio through the shallow water 5Kubernetes made my latency 10x higher 6A Kubernetes crime story 7New K8s workers unable to join cluster 8How a simple admission webhook lead to a cluster outage 9Post Mortem: Kubernetes Node OOM 10Kubernetes' dirty endpoint secret and Ingress 11How a Production Outage Was Caused Using Kubernetes Pod Priorities 12Moving to Kubernetes: the Bad and the Ugly 13Kubernetes Failure Stories, or: How to Crash Your Cluster 14Build Errors of Continuous Delivery Platform 1510 ways to shoot yourself in the foot with kubernetes 16Keynote How Spotify Accidentally Deleted All its Kube Clusters with No User Impact 17Oh Sh*t! The Config Changed! 18Misunderstanding the behaviour of one templating line — and the pain it caused our k8s clusters 19How to kill the Algolia dashboard during Black Friday 20Outage post-mortem 21The shipwreck of GKE Cluster Upgrade 22Breaking Kubernetes: How We Broke and Fixed our K8s Cluster 23Maximize learnings from a Kubernetes cluster failure 24Kubernetes Load Balancer Configuration – Beware when draining nodes 25On Infrastructure at Scale: A Cascading Failure of Distributed System 26A Perfect DNS Storm 27Kubernetes and the Menace ELB, the tale of an outage 28Moving the entire stack to k8s within a year – lessons learned 29Anatomy of a Production Kubernetes Outage 30“Break and Recover” Kubernetes Cluster 31101 Ways to Crash Your Cluster 32Search and Reporting Outage 33SaleMove US System Issue
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}