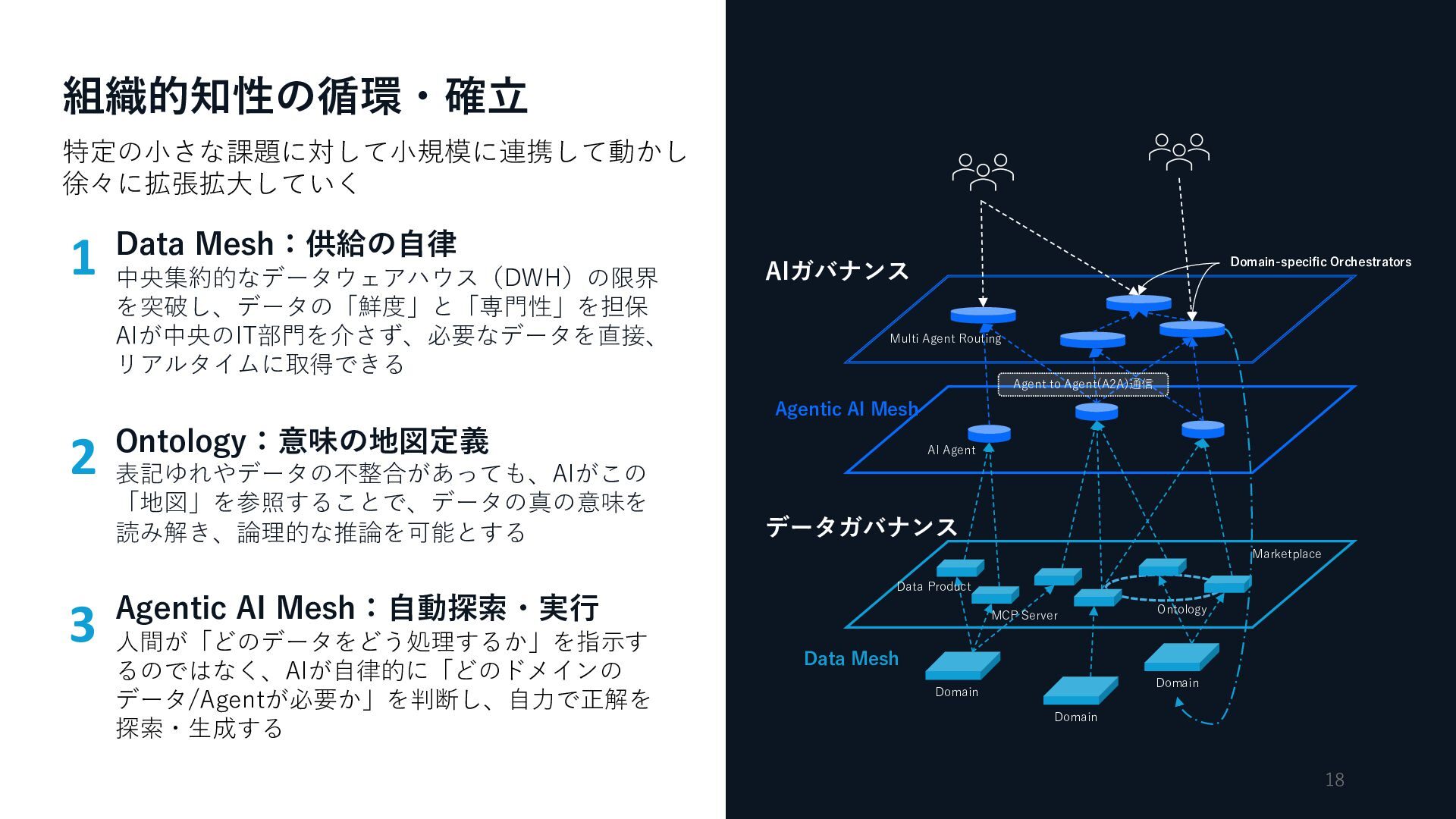
Agentic AI Mesh:⾃動探索・実⾏ ⼈間が「どのデータをどう処理するか」を指⽰す るのではなく、AIが⾃律的に「どのドメインの データ/Agentが必要か」を判断し、⾃⼒で正解を 探索・⽣成する Domain Domain Domain Data Product Marketplace Data Mesh Agentic AI Mesh AI Agent Multi Agent Routing Domain-specific Orchestrators データガバナンス AIガバナンス Agent to Agent(A2A)通信 MCP Server Ontology 特定の⼩さな課題に対して⼩規模に連携して動かし 徐々に拡張拡⼤していく 1 2 3 組織的知性の循環・確⽴ 18
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
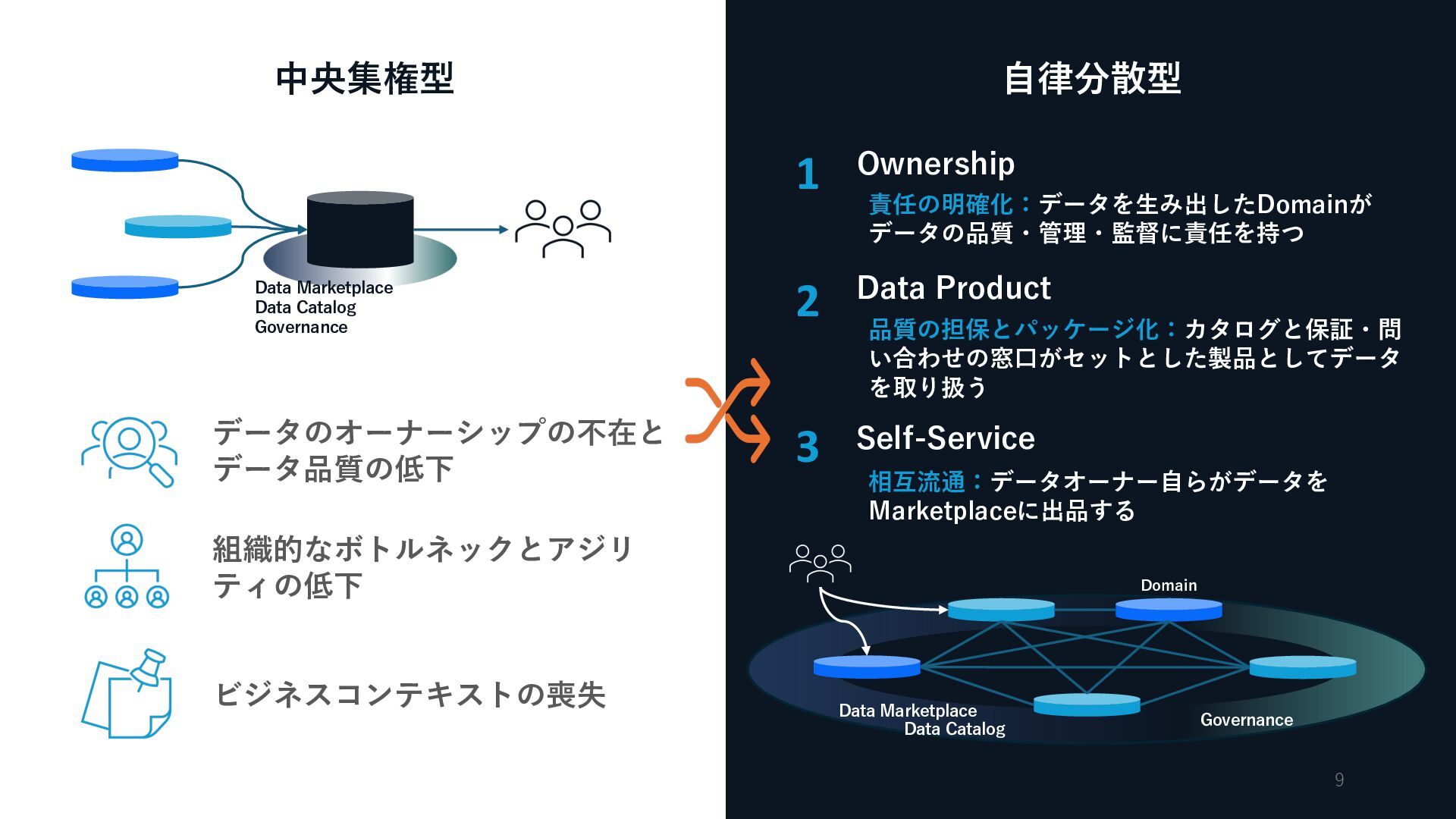{kind=link}
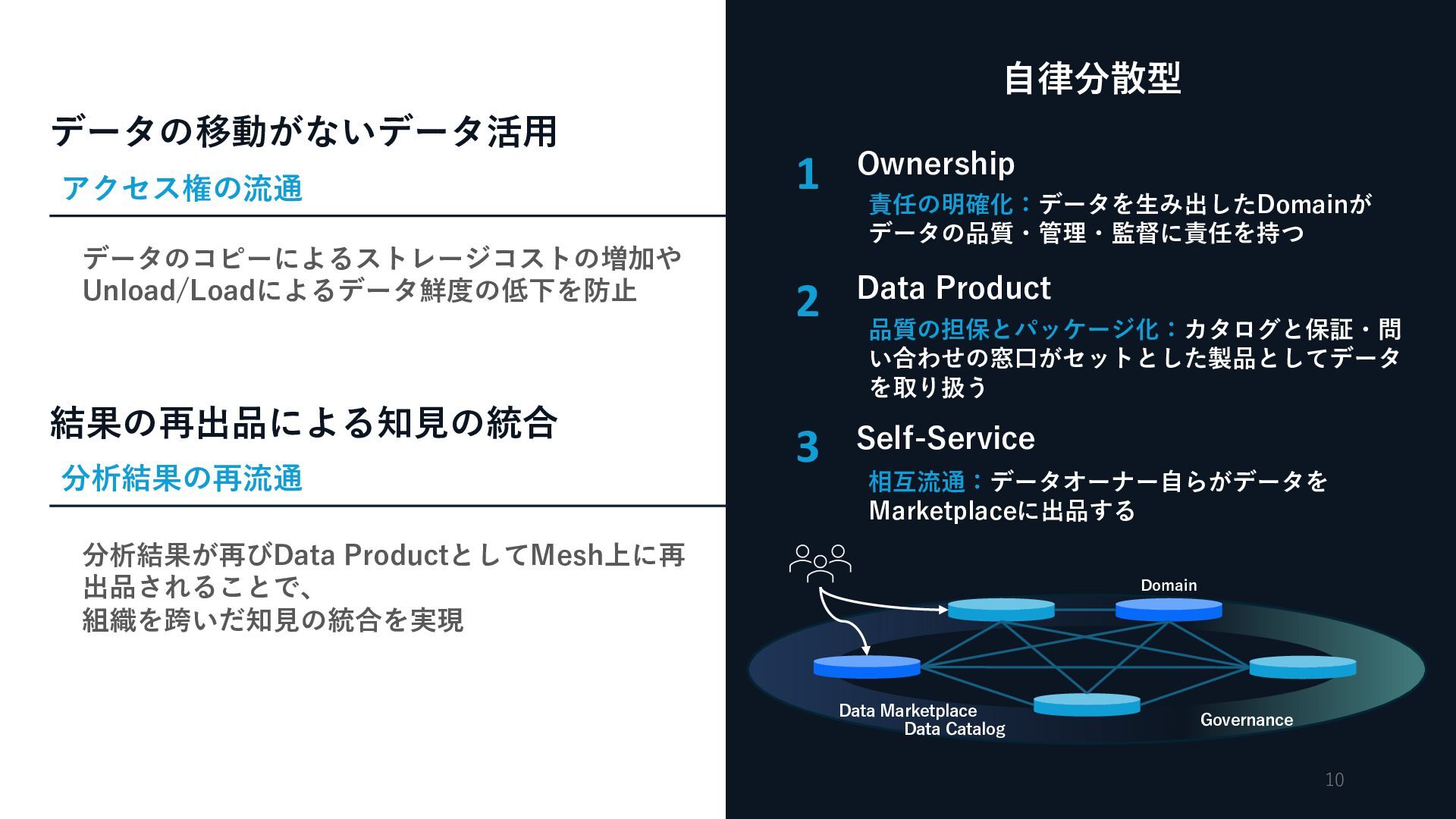{kind=link}
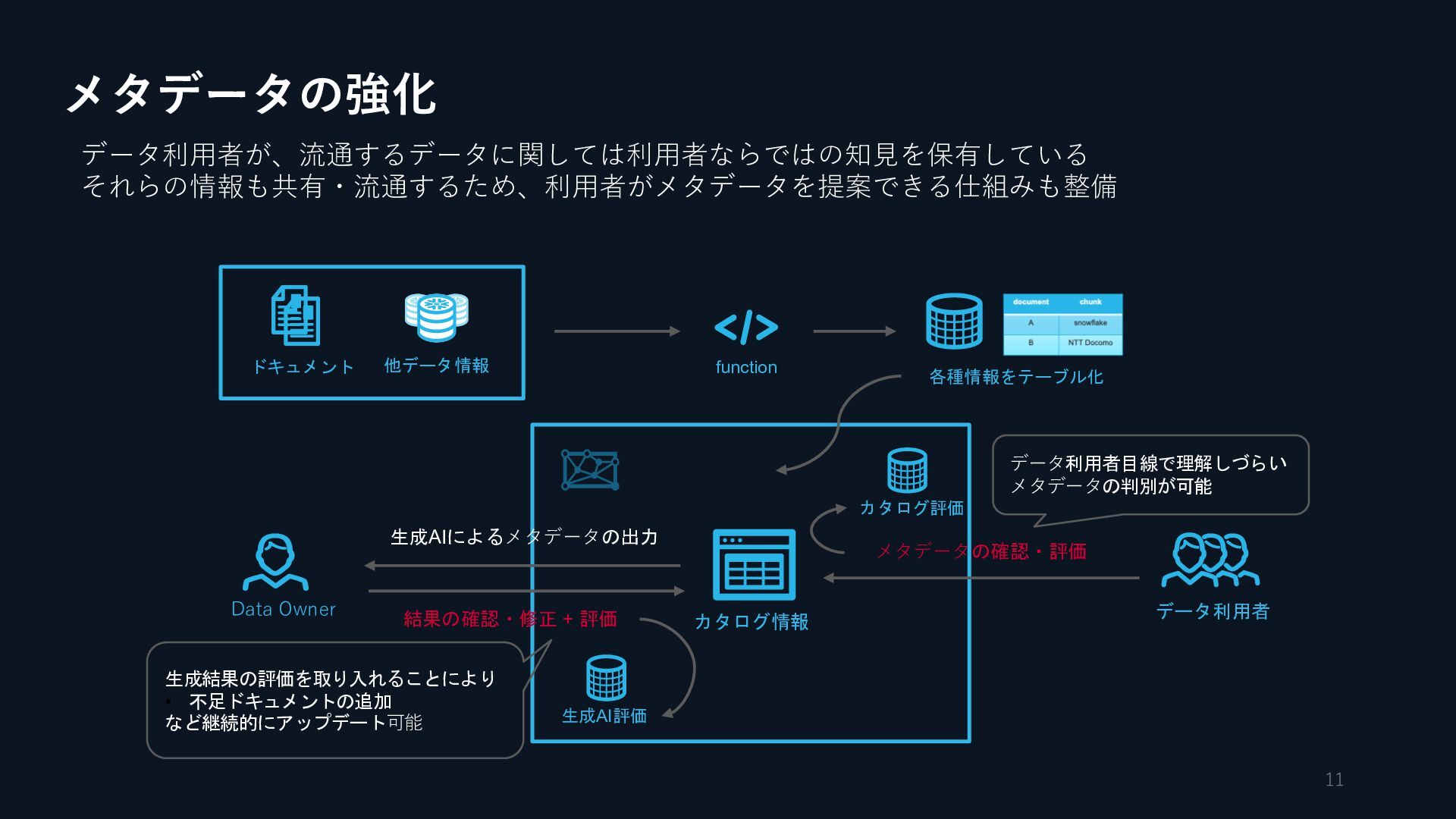{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
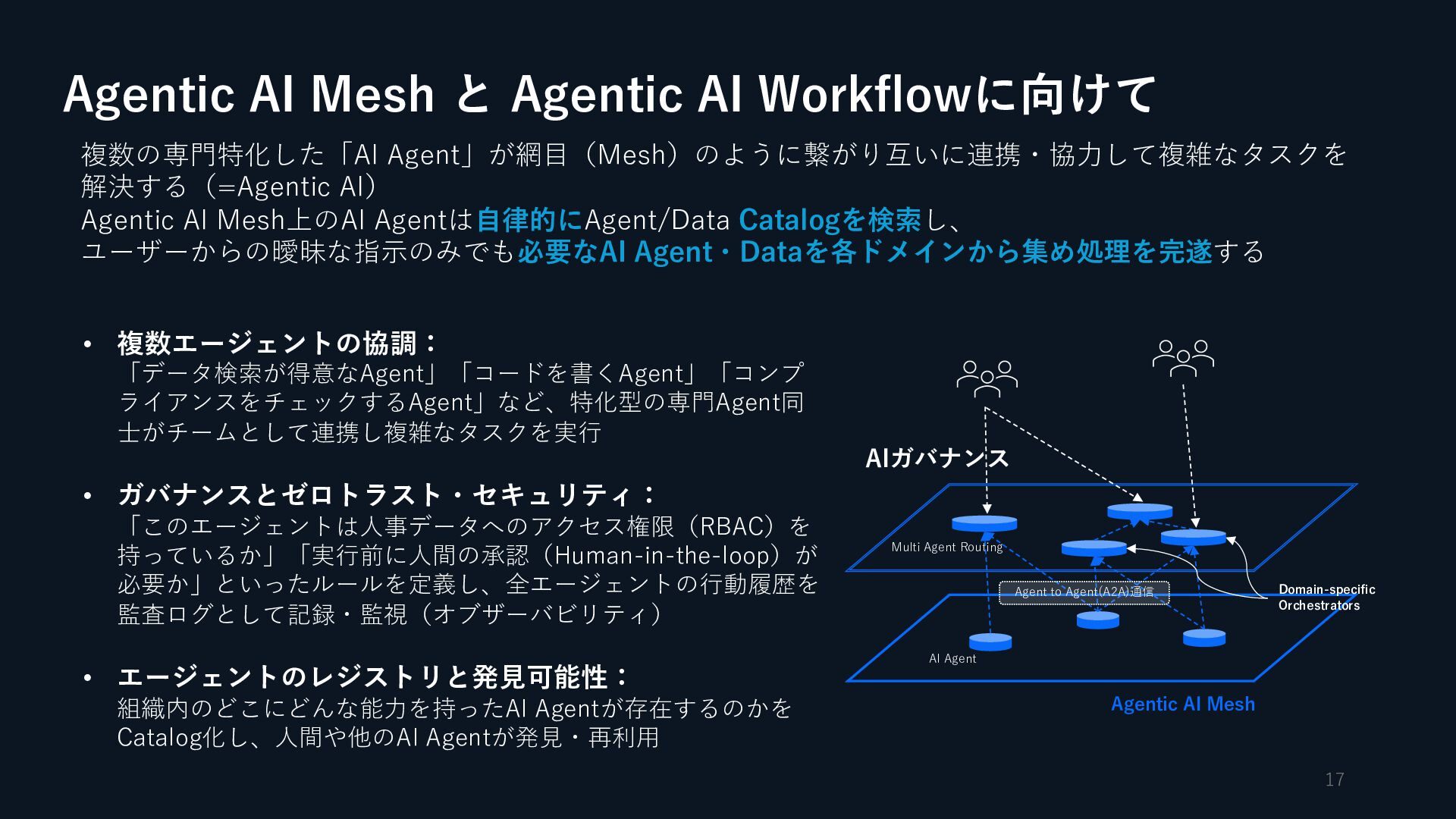{kind=link}
{kind=link}
{kind=link}
{kind=link}