Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
フロントエンドとバックエンドで「1文字」を揃えよう
Search
てきめん tekimen
PRO
June 04, 2026
Programming
810
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
フロントエンドとバックエンドで「1文字」を揃えよう
てきめん tekimen
PRO
June 04, 2026
More Decks by てきめん tekimen
See All by てきめん tekimen
ChatGPTを使ってRaspberry Pi Picoの処理系を書いた
youkidearitai
PRO
0
91
PHP Internals わいわい #3 PIEを使ってみよう
youkidearitai
PRO
0
70
grapheme_strrev関数が採択されました(あと雑感)
youkidearitai
PRO
1
340
Limit of code point for grapheme cluster in programming language side.
youkidearitai
PRO
0
93
Unicodeどうしてる? PHPから見たUnicode対応と他言語での対応についてのお伺い
youkidearitai
PRO
2
3.6k
PHP 8.5の裏話
youkidearitai
PRO
0
150
CJK and Unicode From a PHP Committer
youkidearitai
PRO
0
340
PHP Internals わいわい #3 mb_*関数を作ってみよう
youkidearitai
PRO
0
170
Windows版php-srcデバッグ方法
youkidearitai
PRO
1
130
Other Decks in Programming
See All in Programming
初めてのKubernetes 本番運用でハマった話
oku053
0
130
壊れたパーサから始める関数型設計と構成的なパーサ #fp_matsuri
raiga0310
2
230
【やさしく解説 設計編 #1】「ドメイン駆動」と「実装駆動」ってなに? 〜設計の考え方を、たとえ話で学ぼう〜
panda728
PRO
1
120
AI時代、エンジニアはどう育つのか -未経験エンジニアの成長を間近で見て考えたこと-
thasu0123
0
110
20260623_Loop Engineeringで自分の分身の問い合わせBotを作る
ryugen04
0
220
自作OSでスライド発表する
uyuki234
1
3.8k
LLMによるContent Moderationの本番運用の裏側と品質担保への挑戦
suikabar
3
850
アルゴリズムは何を圧縮しているのか ─ Haskell から育った「圧縮代数」というメンタルモデル
naoya
16
3.5k
『コードを書く以外の』エンジニアリング〜課金基盤移行プロジェクト推進のためのTips4選
yuriko1211
0
500
AWS CDK を「作」ってみた 〜フルスクラッチで見えた CDK の裏側〜 / aws-cdk-from-scratch
gotok365
3
420
Apache Hive: Toward a Cloud Native Lakehouse
okumin
0
130
任せる範囲はこう広がった / How the Scope of AI Delegation Has Expanded
nrslib
1
260
Featured
See All Featured
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.8k
Darren the Foodie - Storyboard
khoart
PRO
3
3.4k
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
220
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
290
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
750
HDC tutorial
michielstock
2
750
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
WENDY [Excerpt]
tessaabrams
11
38k
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
450
Bash Introduction
62gerente
615
220k
The Cult of Friendly URLs
andyhume
79
6.9k
Transcript
フロントエンドとバックエン ドで「1文字」を揃えよう
自己紹介 てきめん • https://tekitoh-memdhoi.info • https://github.com/youkideari tai • https://phpc.social/@youkide aritai
• PHP コミッター – Mbstring – Unicode オレ
皆に質問です • 1文字とはなんでしょう?
1文字とは • 1バイト • 1コードポイント – 基本多言語面(BMP) – 追加多言語面(1面) –
追加漢字面(2面) – など • 1書記素クラスター
1バイト • ASCIIコードは7ビットを使う • ISO-2022-JPは7ビットを切り替えて使う • 8ビットはISO-8859シリーズで使われたりする
1コードポイント • ここで言うコードポイントとは、Unicodeのコー ドポイント – U+0000 〜 U+10FFFF までの21ビットが入る –
16進数4桁のことを基本多言語面(Basic Multilingual Plane:BMP)という – U+10000〜U+1FFFFのことを「追加多言語面」という – U+20000〜U+2FFFFのことを「追加漢字面」という
なぜ21ビットなのか • Unicodeは最初、16ビットで世界中の字を入れられるとしていたが、その目 論見が見事に失敗したことで、1面以降に文字を追加する羽目になった (Unicode 2.0) • UTF-16ではBMPの中にサロゲートペアを作って対処した – 前16ビット(ハイサロゲート):
U+D800〜U+DBFF (1024(2^10)コードポイント分) – 後ろ16ビット(ローサロゲート): U+DC00〜U+DFFF (1024(2^10)コードポイント 分) – この組み合わせが1048576文字(2^20)分であり、U+10000〜U+10FFFFまでの範 囲となった – なお、サロゲートペアはUTF-16のみの概念で、他文字コードで扱えない (UTF-8、UTF-32) • 結果として21ビットの範囲となった。
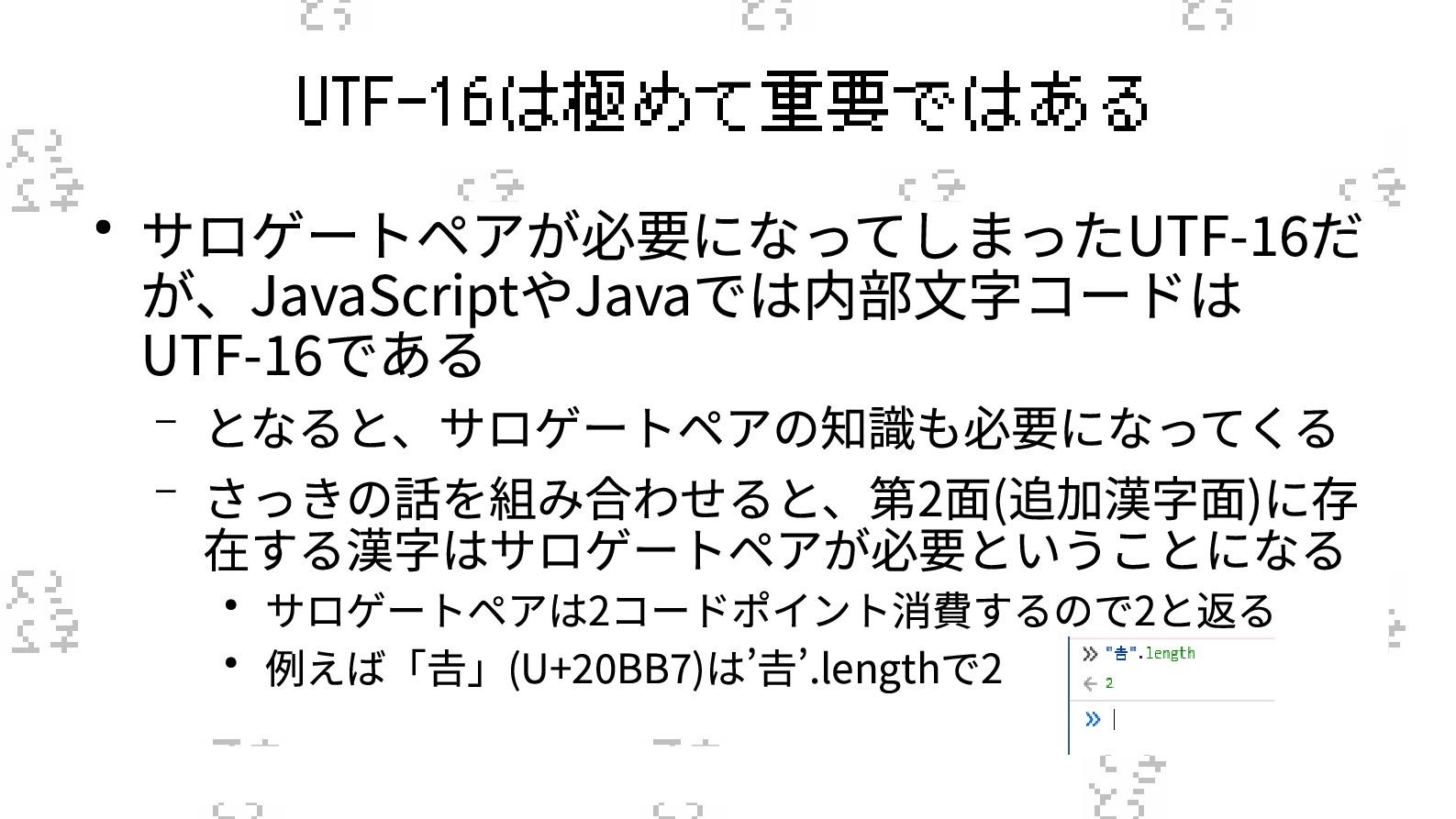
UTF-16は極めて重要ではある • サロゲートペアが必要になってしまったUTF-16だ が、JavaScriptやJavaでは内部文字コードは UTF-16である – となると、サロゲートペアの知識も必要になってくる – さっきの話を組み合わせると、第2面(追加漢字面)に存 在する漢字はサロゲートペアが必要ということになる
• サロゲートペアは2コードポイント消費するので2と返る • 例えば「𠮷」(U+20BB7)は’𠮷’.lengthで2
21ビットを丸ごと収録したUTF-32 • 32ビットあれば21ビットまるごと収録できると したのがUTF-32 • 可変長でなくなったので解決したように見える • 短所は21ビットに対して32ビットも使うため、 無駄が多いところ
絵文字の登場 • Unicodeに絵文字が搭載されることになった • まあ、良かったですよ • 1面(追加多言語面)にも入るようになった • それどころの話でもなくなった
複数コードポイント • 🇯🇵 – 国旗は一つのコードポイントではない – 日本の国旗は U+1F1EF U+1F1F5の組み合わせ •
👨👨👦👦 – 家族も同じく複数のコードポイント(+ZWJ)で成り立ってい る – 複数パターンが考えられる(この例では男×4の家族)ので コードポイントの説明は割愛
Zalgo text • ウムラウト(¨)などの発音記号は無限にくっつけら れる – 正規化D(NKD、NKFD)を行うとアルファベットと発音 記号が分離する • Zalgo
textと言う、発音記号を無限にくっつける文 化がある – H̵̛͕̞̦̰̜͍̰̥̟͆̏͂̌͑ͅ ä̷͔̟͓̬̯̟͍̭͉͈̮͙̣̯̬͚̞̭̍̀̾͠m̴̡̧̛̝̯̹̗̹̤̲̺̟̥̈̏͊̔̑̍͆̌̀̚͝͝b̴̢̢̫̝̠̗̼̬̻̮̺̭͔̘͑̆̎̚ ư̵̧̡̥̙̭̿̈̀̒̐̊͒͑ r̷̡̡̲̼̖͎̫̮̜͇̬͌͘g̷̹͍͎̬͕͓͕̐̃̈́̓̆̚͝ẻ̵̡̼̬̥̹͇̭͔̯̉͛̈́̕r̸̮̖̻̮̣̗͚͖̝̂͌̾̓̀̿̔̀͋̈́͌̈́̋͜ • https://en.wikipedia.org/wiki/Zalgo_text
日本語の漢字 • 日本語における漢字は、苗字や地名がバラバラ – 名前は2999文字(2026年現在)しか使えない • MJ文字といって、文字情報基盤によって一応標準化された – Unicodeでは16.0にて収録された –
表意文字たる漢字の難しいところ – 文字は交換可能であるべきだが、字自体にアイデンティティがあ る人もいる • 苗字の漢字の細かいところが違うとなる(縮退) • 正確な形自体は画像などで戸籍に保存されている – 詳細は https://www.digital.go.jp/policies/local_governments/c haracter-specification
異体字セレクタ • 渡邉さんの邉のように、書体が違うものを収録 – 邉 邉 邉󠄁 邉󠄂 邉󠄃 邉󠄄
邉󠄅 邉󠄆 邉󠄈 邉󠄉 邉󠄊 邉󠄋 邉󠄌 邉󠄍 邉󠄎 – 異体字セレクタ(Variable Sequence)という • U+E0100〜U+E01EFまでの範囲 – 葛󠄀城市(かつらぎし:奈良県)と葛飾区(かつしか く:東京都)のように、基底文字の葛は一緒で、違う のは異体字セレクタの番号(葛󠄀: U+845B U+E0100)
これらを何文字と扱うのか • これらを何文字として扱うのか • 書記素クラスターという概念がある – 書記素がもともとの概念で、見た目の1文字 – 絵文字も異体字セレクタも扱える –
Zalgo textは微妙 • 発音記号を無限に被せられるため、書記素クラスターで数えるのは 難しいのではないか? • 絵文字も、家族の絵文字のように無限に被せられる – こっちはまだ絵文字のリストが存在する • https://unicode.org/emoji/charts/full-emoji-list.html
JavaScriptでの扱い方 • Intl.Segmenterを使う – 第二引数に’grapheme’を指定、イテレーターが使 える
コードポイントの測り方 • JavaScriptでBMP外もコードポイントごとに測る場 合 for...of文や[...variable]構文が使える
PHPなど、バックエンドで扱う • PHPではgrapheme_*関数が簡単 – grapheme_str_split関数を追加したので、arrayで書 記素クラスターを扱える
書記素クラスターの弱点 • 弱点というか、考慮しないといけないこと – 1書記素クラスターにはコードポイントの上限はない • 将来的な制限を作りたくないらしい – 書記素クラスターをWebアプリケーションとして使う場合 には入力の長さを測る必要がある
• コードポイント数 • バイト数 – さもないと、「1書記素クラスター、200MBの 」「さっき 👨👨👧👦 のZalgo textのような無限に続く発音記号「ä̈̈̈̈̈̈̈̈̈̈̈̈̈̈̈̈̈̈̈̈̈̈̈̈̈̈̈̈̈ 」」などとい う「1文字」を入力可能にしてしまう
1文字をどう扱うか • このように多様なので、アプリケーションによって1文字の要件を決めるべき • 人の名前が重要な場合や絵文字を扱う場合には書記素クラスターが重要 – 戸籍には外字が含まれるので、Unicodeのコードポイントでも扱えない場合もある • 行政事務標準文字の概念が出てくるところ •
ここまで来ると詳しくないので詳しい人が出てきてほしいところ • パフォーマンスなどを考えたときにはコードポイントで数えるよう妥協する – 私の名前の「邉」は「邉󠄂」ですはできませんと妥協する • つまり、IVSの対応まではできませんということ – ただし「𠮷」を始めとした追加多言語面ができないのは流石に頑張ったほうがいい • サロゲートペアが必要だが、コードポイントでなんとかできる場面はなんとかする
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![コードポイントの測り方 • JavaScriptでBMP外もコードポイントごとに測る場 合 for...of文や[...variable]構文が使える](https://files.speakerdeck.com/presentations/80745dc791c6434c903358db04b86b79/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}