우리 조직 안에서 작성한 컴포넌트·서비스끼리의 의존 관계 외부 의존성 : 우리 조직 바깥에서 작성한 컴포넌트·서비스로의 의존 관계 • 선언적 의존성 관리 사람의 실수나 사람에 의한 차이를 가능한 한 줄이려면 어떻게 해야 하는가? • 재현 가능한 빌드 configuration이 같다면 누구의 컴퓨터에서 실행해도 같은 결과가 나와야 함 • 자동화 및 캐싱 Linting, Test, Build & Deploy와 같은 CI/CD 전 과정 자동화를 지원해야 함 매 commit마다 변경된 범위를 자동 추출하고 기존 결과 재활용하여 필요한 작업만 수행
pipenv, go get, ... • 핵심 기능 의존성 해결 ✓ 예) A → C, B → C 의존 관계가 있을 때 A와 B 모두와 호환되는 C 버전이 존재하는가? ✓ 1차 의존성의 n차 의존성을 몽땅 개별 샌드박스 vs. 호환 버전 모두 맞추기 (NP-complete[1]) 의존성 잠그기 : 공급망 공격 및 예측되지 않은 버전 업데이트로 인한 오류 예방 자동화 ✓ 의존성의 개수와 상호 의존 관계의 숫자가 조금만 늘어도 사람이 관리하는 것이 불가능함 ✓ 의존성의 버전 업데이트 자동 탐지 및 패키지 metadata에 자동 적용 등 [1] https://research.swtch.com/version-sat
B → C 의존 관계가 있을 때 C는 단 하나의 버전만 존재해야 하며, A와 B의 모든 코드베이스도 그 단 하나의 C 버전에 맞도록 항상 유지보수되어야 함 • Mono-repo를 도입하면 좋은 점? 전체 코드베이스에서 중복을 쉽게 발견할 수 있음 C의 API가 바뀌었을 때 전체 코드베이스에서 한번에 수정(리팩토링)할 수 있음 내부 의존성을 모두 선언적 빌드 설정으로 표현 가능 ✓ 적절한 도구가 있다면 의존 관계 추론 자체를 자동화해버릴 수도 있음
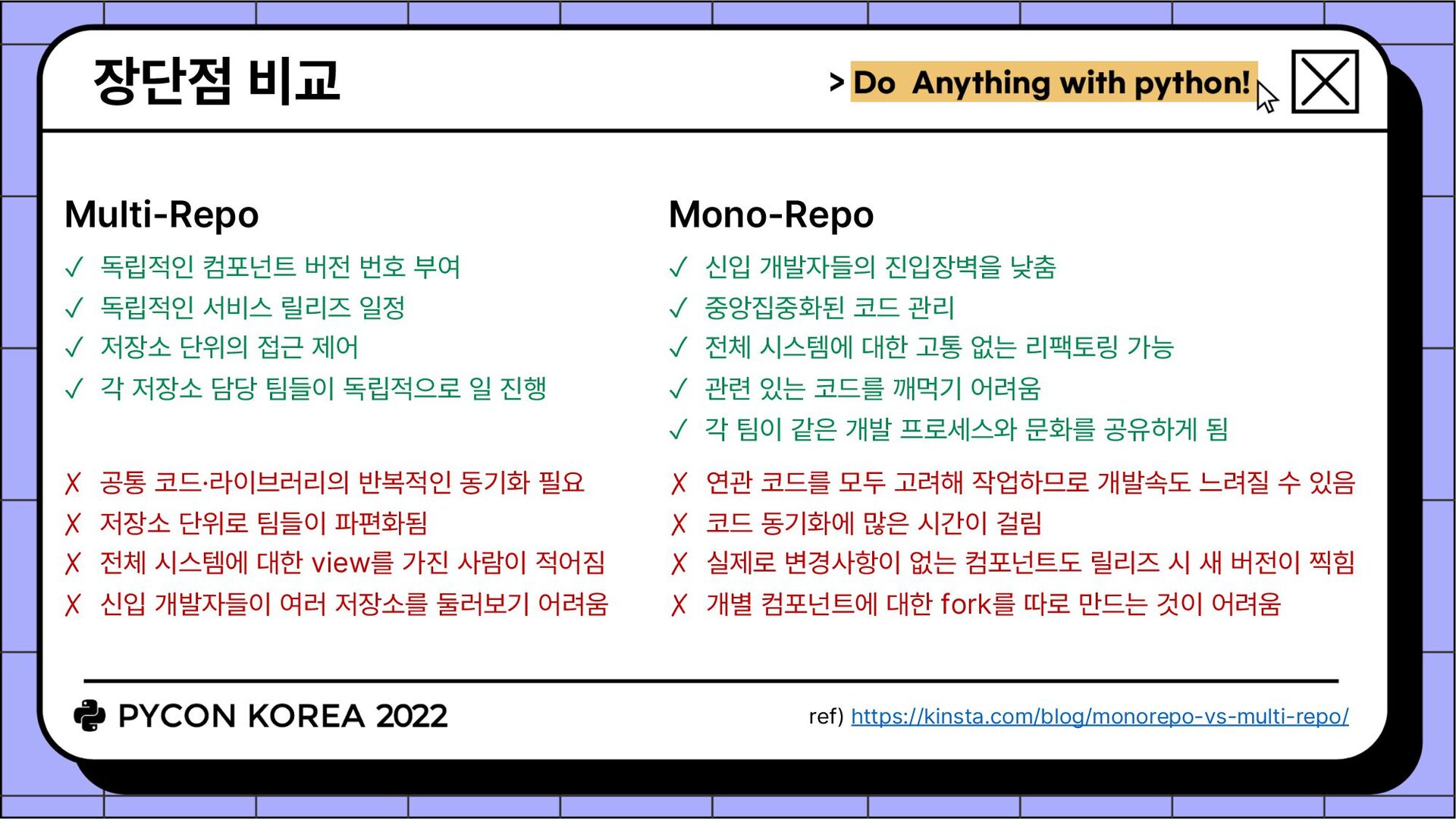
수 있음 ✗ 코드 동기화에 많은 시간이 걸림 ✗ 실제로 변경사항이 없는 컴포넌트도 릴리즈 시 새 버전이 찍힘 ✗ 개별 컴포넌트에 대한 fork를 따로 만드는 것이 어려움 ✓ 신입 개발자들의 진입장벽을 낮춤 ✓ 중앙집중화된 코드 관리 ✓ 전체 시스템에 대한 고통 없는 리팩토링 가능 ✓ 관련 있는 코드를 깨먹기 어려움 ✓ 각 팀이 같은 개발 프로세스와 문화를 공유하게 됨 ✓ 독립적인 컴포넌트 버전 번호 부여 ✓ 독립적인 서비스 릴리즈 일정 ✓ 저장소 단위의 접근 제어 ✓ 각 저장소 담당 팀들이 독립적으로 일 진행 ✗ 공통 코드·라이브러리의 반복적인 동기화 필요 ✗ 저장소 단위로 팀들이 파편화됨 ✗ 전체 시스템에 대한 view를 가진 사람이 적어짐 ✗ 신입 개발자들이 여러 저장소를 둘러보기 어려움 Multi-Repo Mono-Repo ref) https://kinsta.com/blog/monorepo-vs-multi-repo/
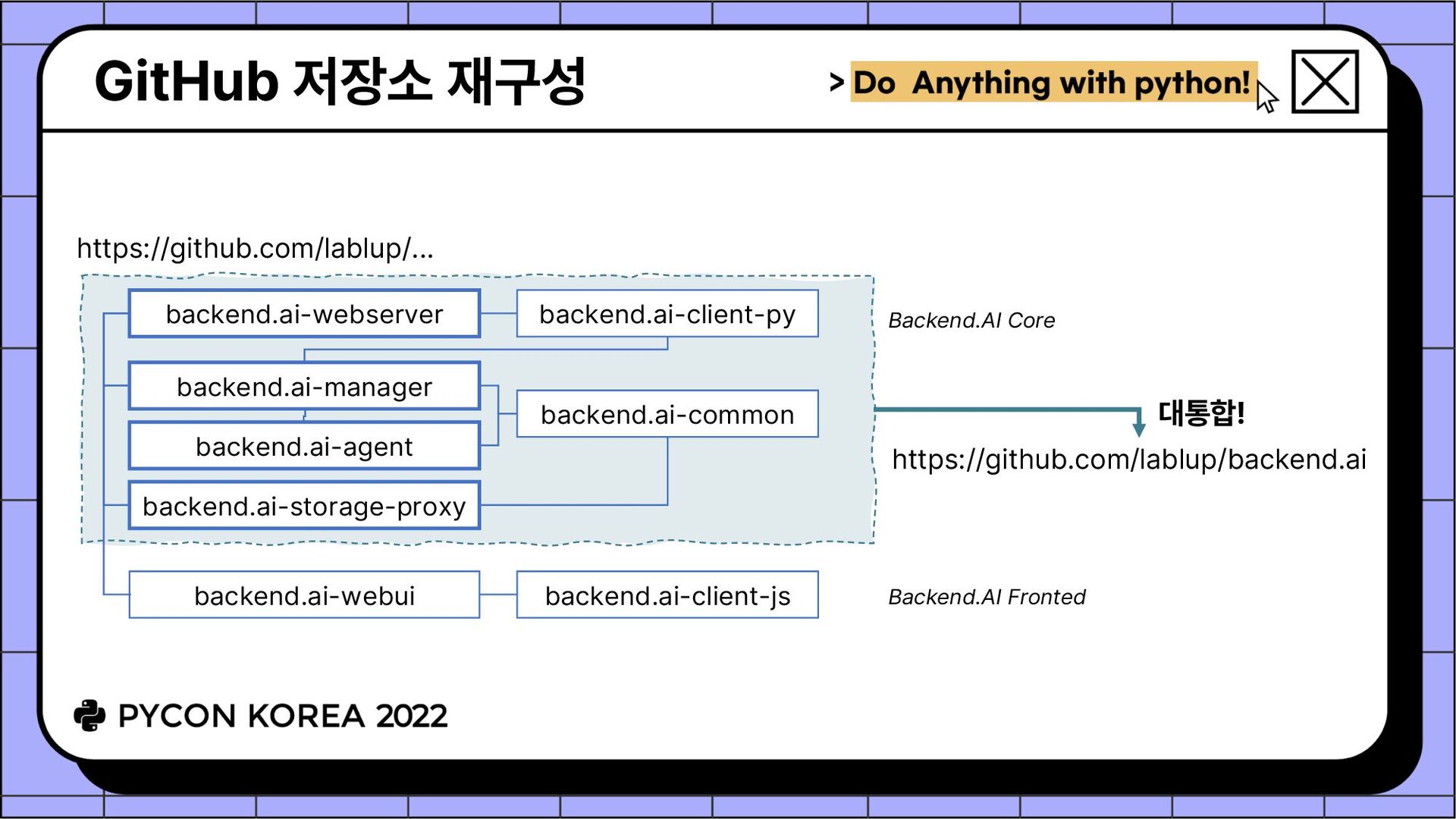
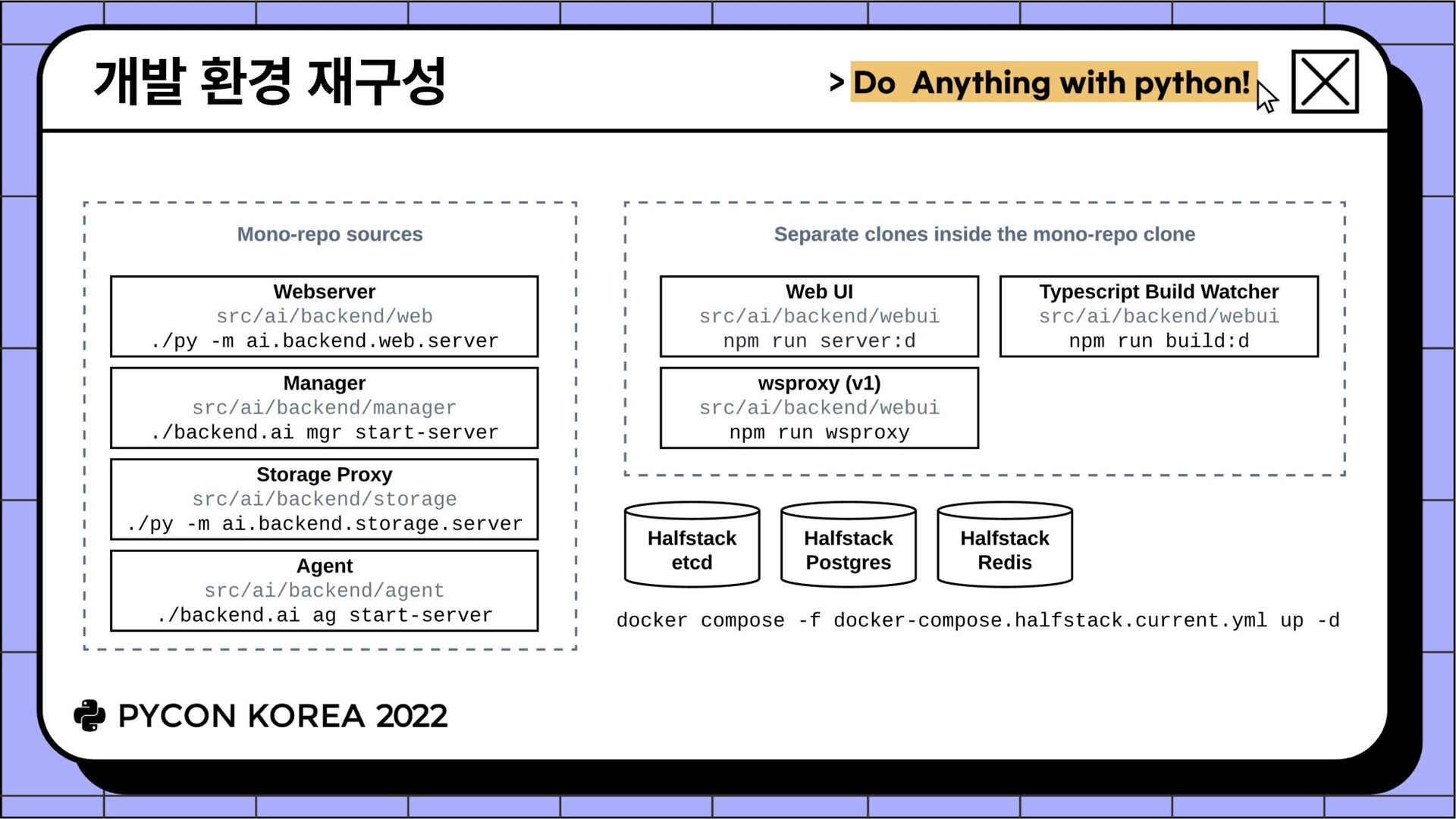
1개당 저장소 1개 패키지별 CI/CD 워크플로우 작성 용이 & 패키지별 개별 릴리즈 가능 • Backend.AI 개발환경 설정 방법 서버측 개발 환경 설치를 위한 최소 컴포넌트 집합 (6개) ✓ manager, agent, common, client-py, webserver, storage-proxy ✓ 프론트엔드는 또 다른 이야기... 개발환경 자동설정 스크립트 (install-dev.sh) ✓ docker-compose 기반 데이터베이스 컨테이너 설치 ("halfstack") ✓ 컴포넌트별 저장소 클론, venv 생성, editable install 수행
개발하다가 git switch를 n번 해야 하는데 중간에 하나 빼먹으면... • 하나의 이슈에 여러 개의 PR을 작성·리뷰해야 함 대표적 실수 사례 : manager에 API를 추가했는데 client에 대응 명령어 추가하는 걸 까먹는 경우 ✓ 리뷰어도 종종 까먹음... GitHub Issue & PR 기능과 어울리지 않음 ✓ 하나의 이슈에 여러 개의 PR이 연결되면 하나의 PR만 병합해도 이슈 완료로 처리됨 (OR 조건) GitHub Project v2 나왔지만 (아직) 여러 저장소에 걸쳐 label, milestone을 통합 관리 불가 PR 작성자도 헷갈리고 PR 리뷰어도 헷갈리고... 🤯 • 신입 개발자들의 어려움 여러 저장소에 걸친 CI 동작을 위해 PR branch 이름을 맞춰야 하는 암묵적 규칙 존재
참조하는 common 패키지의 무언가를 바꾸면 manager, agent 저장소에도 PR을 생성해야 함 common 패키지를 다른 컴포넌트에서 재활용하려 해도 점점 더 귀찮아질 것이 걱정되어 소극적이게 됨 새로운 패키지를 추가하는 것이 관리 포인트를 늘리게 되므로 공통으로 사용할 코드를 목적이나 의도와 상관 없이 common 패키지 안에 전부 다 때려박게 됨 • 릴리즈 과정의 어려움 common 버전을 먼저 릴리즈하고 PyPI 업로드 확인 후 manager, agent 버전을 릴리즈해야 CI가 깨지지 않으므로 사람이 기다리는 시간이 발생 6개의 패키지를 똑같은 명령어를 반복해서 릴리즈하다보면 현타가 옴... (가끔 실수도 발생) ✓ changelog로부터 release note 추출하는 부분이 자동화되어 있지 않았음 ✓ 자동화하려고 해도 6개 저장소에 똑같은 설정과 커밋을 반복해야 하니 안 하게 됨
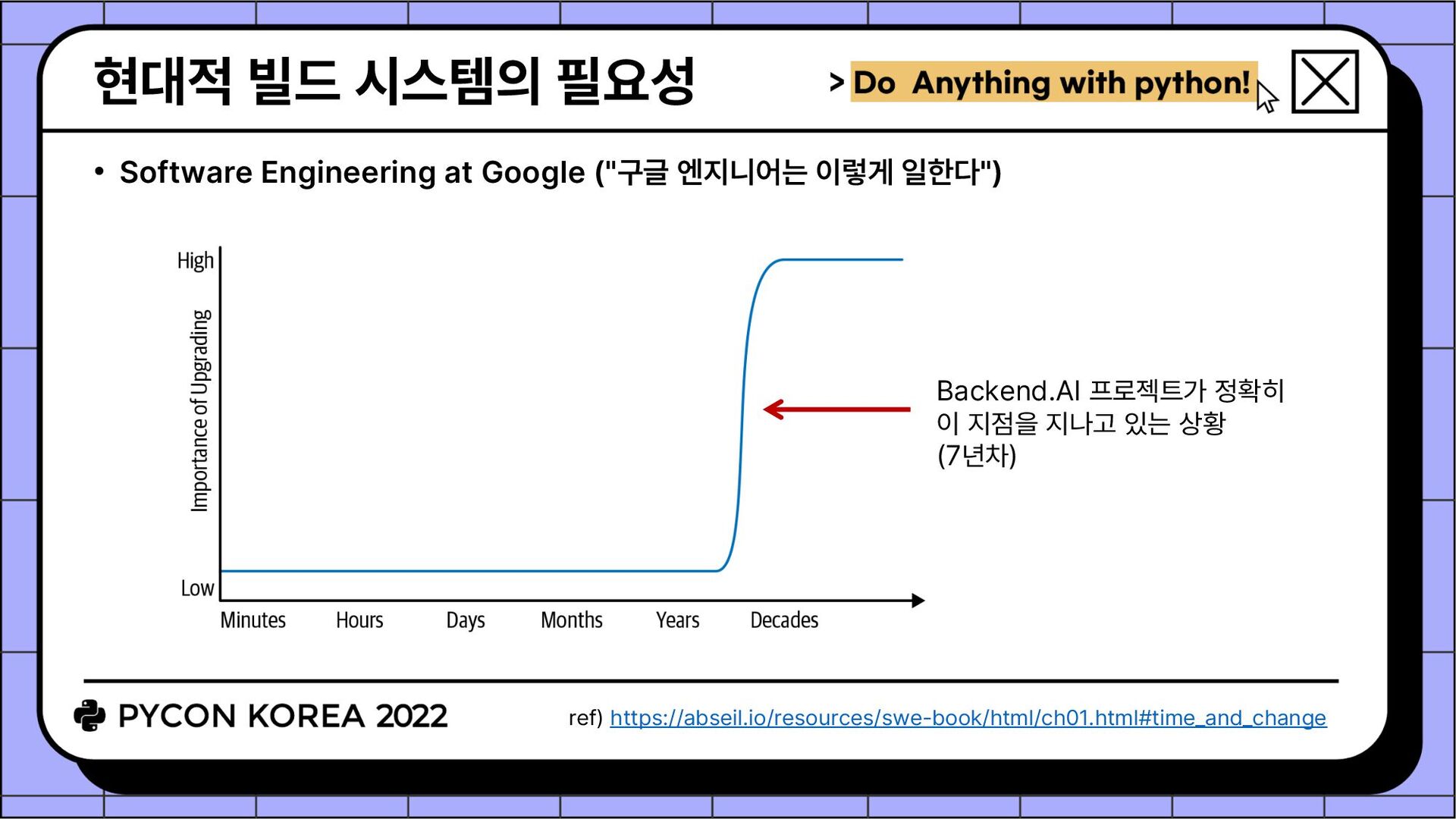
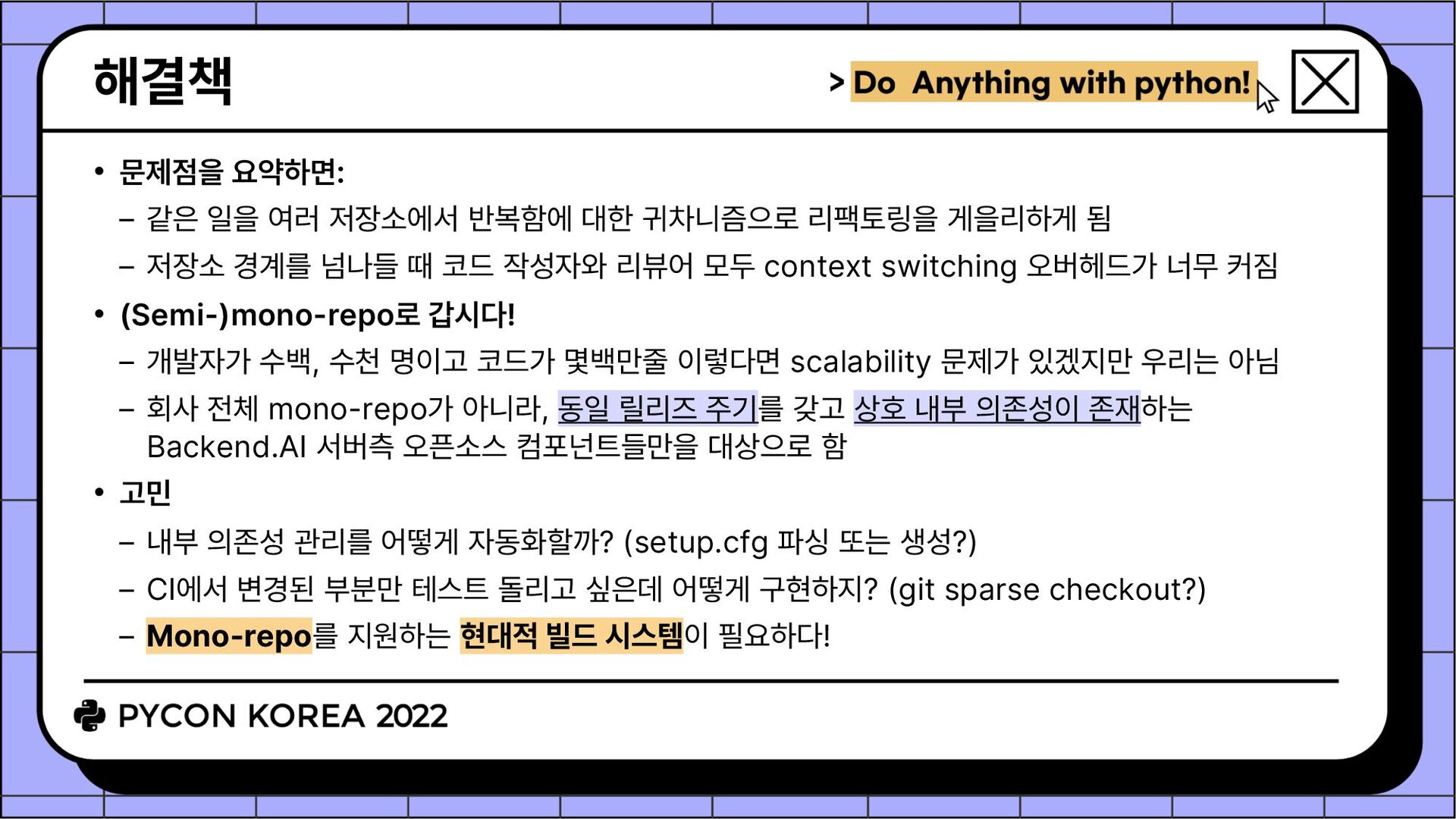
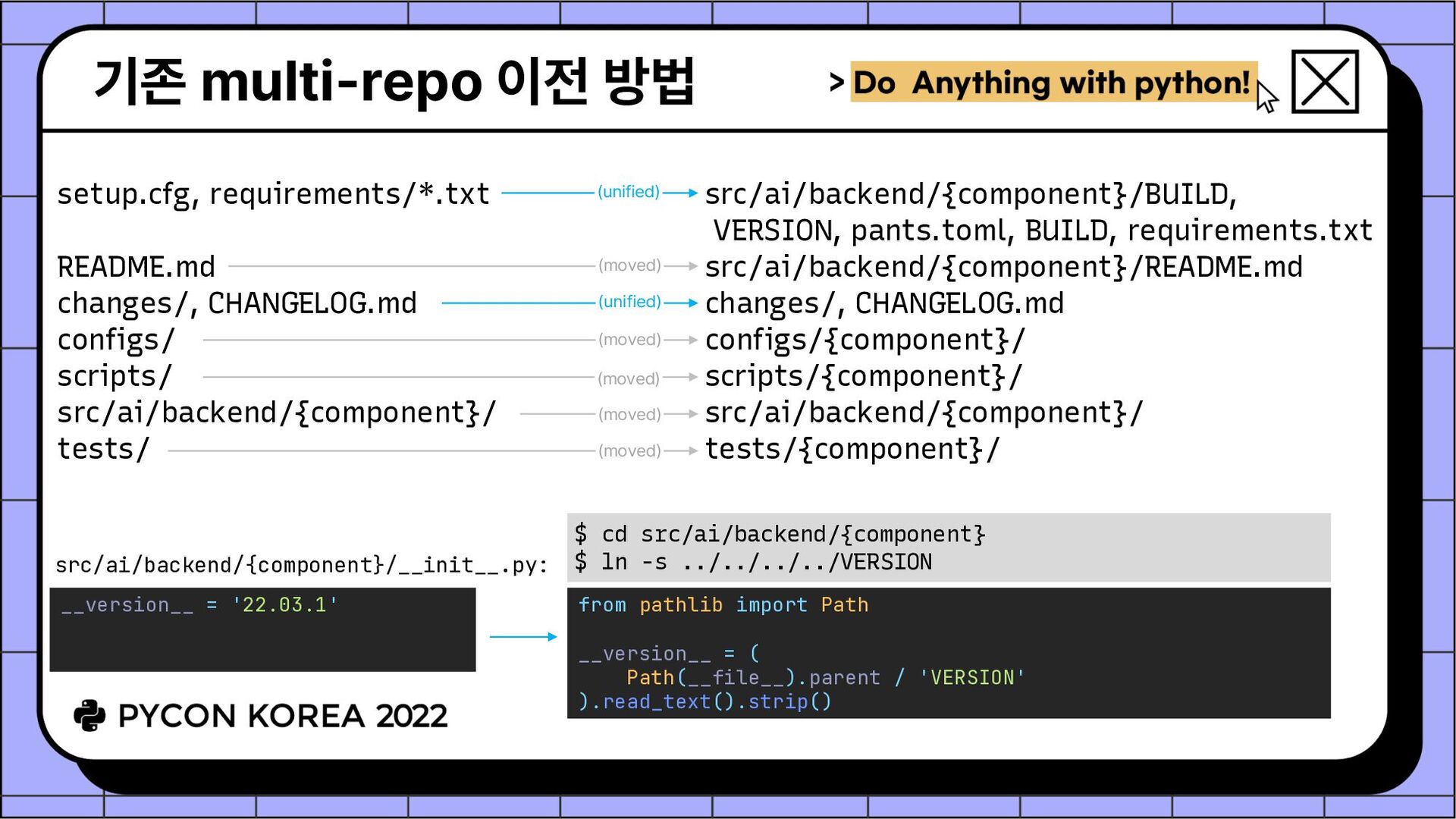
귀차니즘으로 리팩토링을 게을리하게 됨 저장소 경계를 넘나들 때 코드 작성자와 리뷰어 모두 context switching 오버헤드가 너무 커짐 • (Semi-)mono-repo로 갑시다! 개발자가 수백, 수천 명이고 코드가 몇백만줄 이렇다면 scalability 문제가 있겠지만 우리는 아님 회사 전체 mono-repo가 아니라, 동일 릴리즈 주기를 갖고 상호 내부 의존성이 존재하는 Backend.AI 서버측 오픈소스 컴포넌트들만을 대상으로 함 • 고민 내부 의존성 관리를 어떻게 자동화할까? (setup.cfg 파싱 또는 생성?) CI에서 변경된 부분만 테스트 돌리고 싶은데 어떻게 구현하지? (git sparse checkout?) Mono-repo를 지원하는 현대적 빌드 시스템이 필요하다!
자동 추론 Python 생태계에 대한 first-class support 작업 그래프를 강력한 캐싱과 함께 비동기 병렬 실행 플러그인 API를 제공하여 기능 확장이 가능함 • 톺아보기 https://www.pantsbuild.org/docs/how-does-pants-work https://blog.pantsbuild.org/pycon-us-2022-talk/ Pants 2 is a fast, scalable, user-friendly build system for codebases of all sizes. It's currently focused on Python, Go, Java, Scala, Shell, and Docker, with support for other languages and frameworks coming soon. ref) https://www.pantsbuild.org/
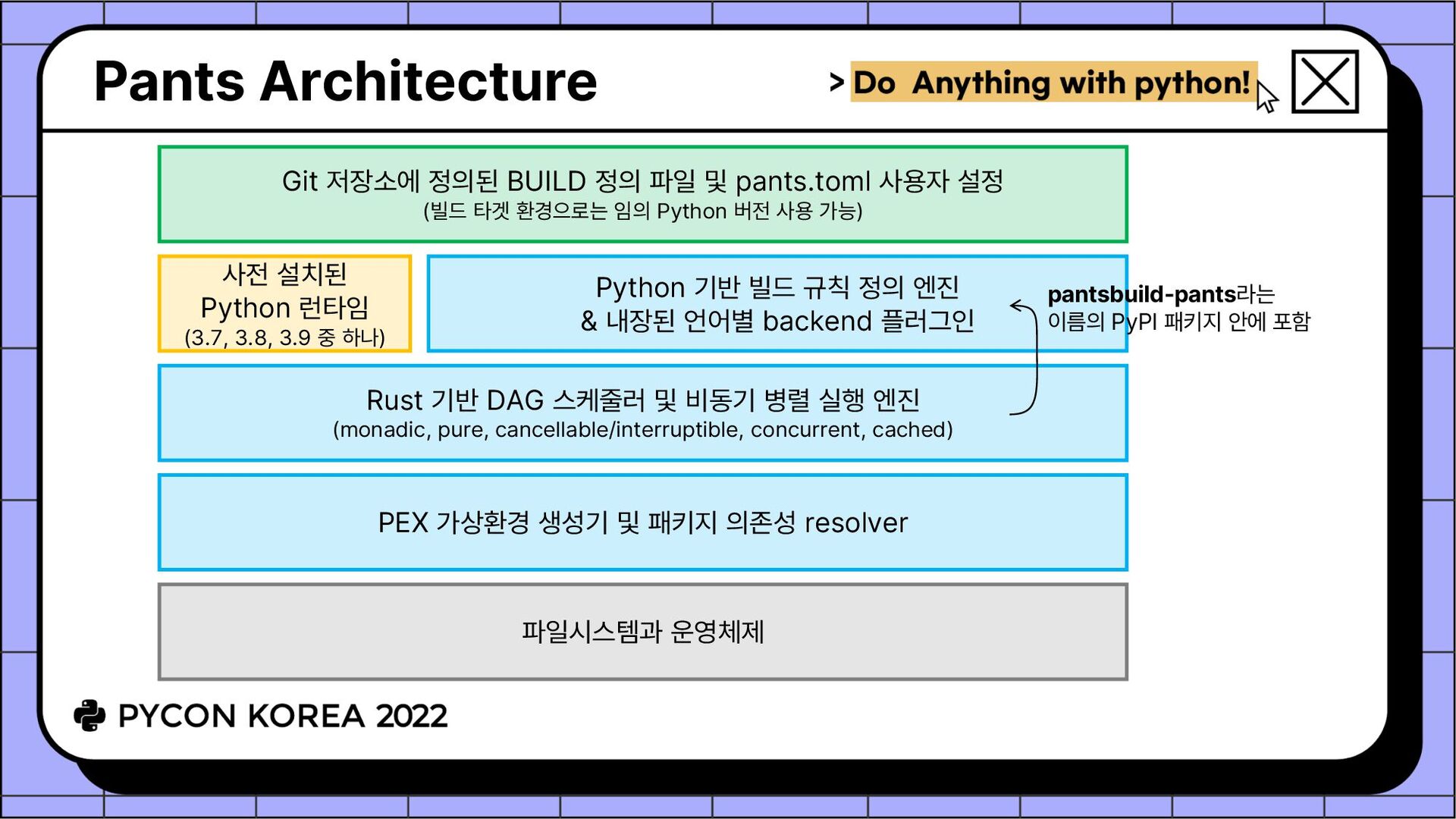
엔진 (monadic, pure, cancellable/interruptible, concurrent, cached) Python 기반 빌드 규칙 정의 엔진 & 내장된 언어별 backend 플러그인 파일시스템과 운영체제 Git 저장소에 정의된 BUILD 정의 파일 및 pants.toml 사용자 설정 (빌드 타겟 환경으로는 임의 Python 버전 사용 가능) pantsbuild-pants라는 이름의 PyPI 패키지 안에 포함 사전 설치된 Python 런타임 (3.7, 3.8, 3.9 중 하나) PEX 가상환경 생성기 및 패키지 의존성 resolver
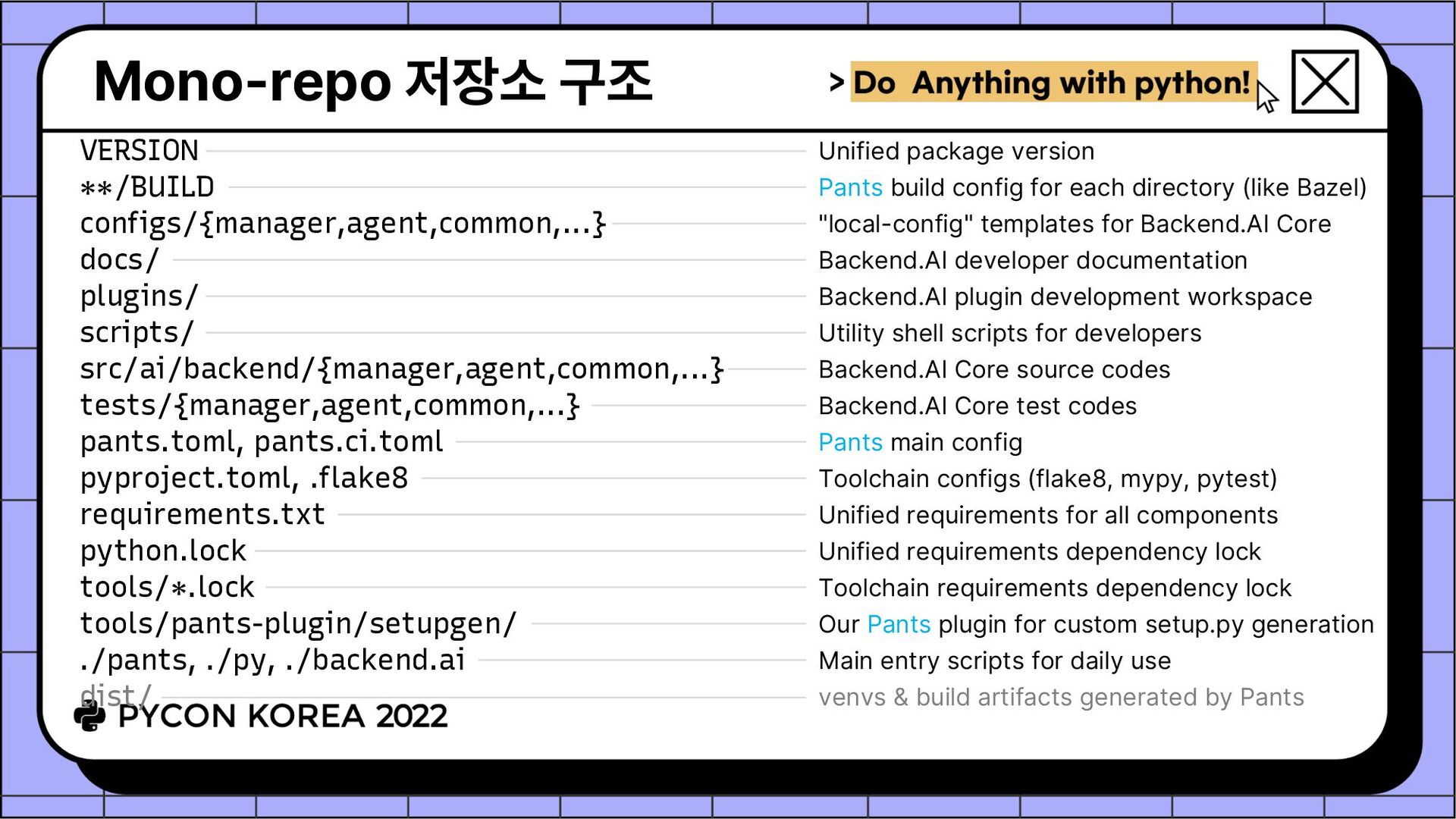
요소들: ./pants 스크립트 (다운로드 받아서 복사해둠) pants.toml 및 pants.ci.toml **/BUILD 파일들 ✓ 빌드 대상(소스 파일, 리소스 파일 등)과 의존 관계 선언 • ./pants [global-options] {goal} [goal-options] [targets] Pants 본체를 ~/.cache/pants/ 및 ./.pants.d 안에 자동 설치 BUILD 파일로부터 타겟과 의존 관계를 DAG 형태로 생성 병렬 실행이 가능한 경우 병렬화하면서 DAG 작업 그래프 실행 ref) https://docs.backend.ai/en/latest/dev/daily-workflows.html
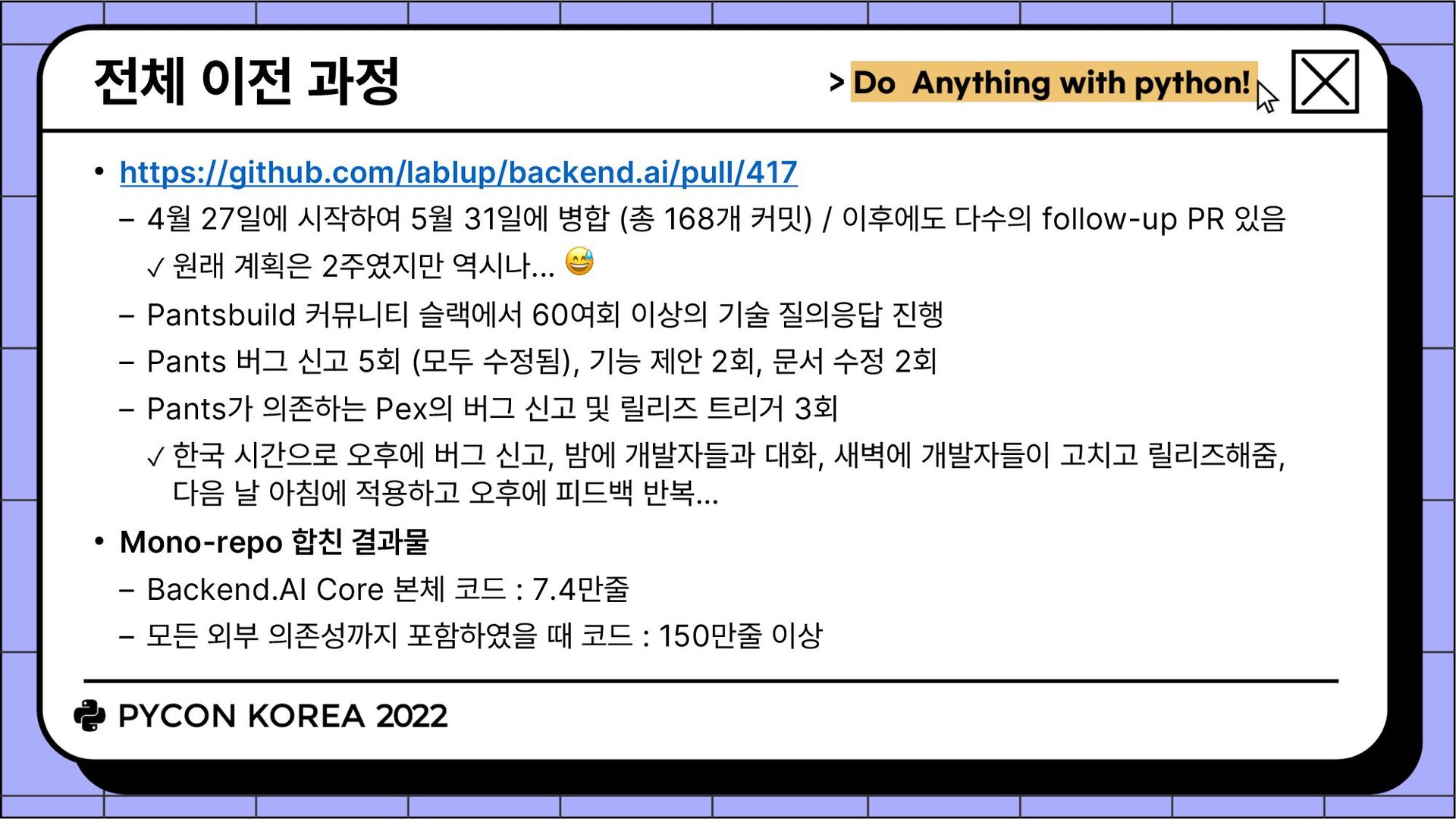
병합 (총 168개 커밋) / 이후에도 다수의 follow-up PR 있음 ✓ 원래 계획은 2주였지만 역시나... 😅 Pantsbuild 커뮤니티 슬랙에서 60여회 이상의 기술 질의응답 진행 Pants 버그 신고 5회 (모두 수정됨), 기능 제안 2회, 문서 수정 2회 Pants가 의존하는 Pex의 버그 신고 및 릴리즈 트리거 3회 ✓ 한국 시간으로 오후에 버그 신고, 밤에 개발자들과 대화, 새벽에 개발자들이 고치고 릴리즈해줌, 다음 날 아침에 적용하고 오후에 피드백 반복... • Mono-repo 합친 결과물 Backend.AI Core 본체 코드 : 7.4만줄 모든 외부 의존성까지 포함하였을 때 코드 : 150만줄 이상
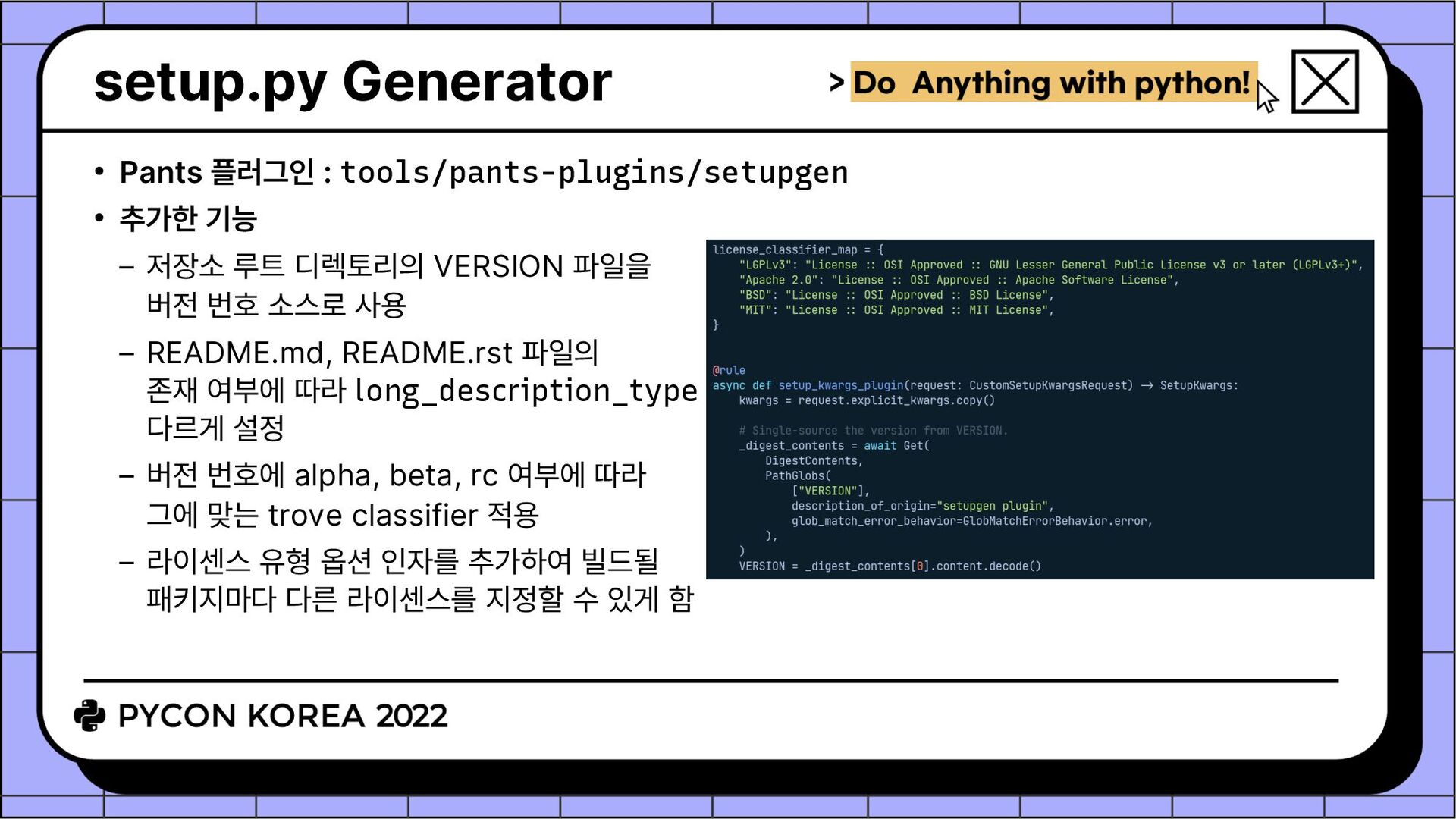
저장소 루트 디렉토리의 VERSION 파일을 버전 번호 소스로 사용 README.md, README.rst 파일의 존재 여부에 따라 long_description_type 다르게 설정 버전 번호에 alpha, beta, rc 여부에 따라 그에 맞는 trove classifier 적용 라이센스 유형 옵션 인자를 추가하여 빌드될 패키지마다 다른 라이센스를 지정할 수 있게 함
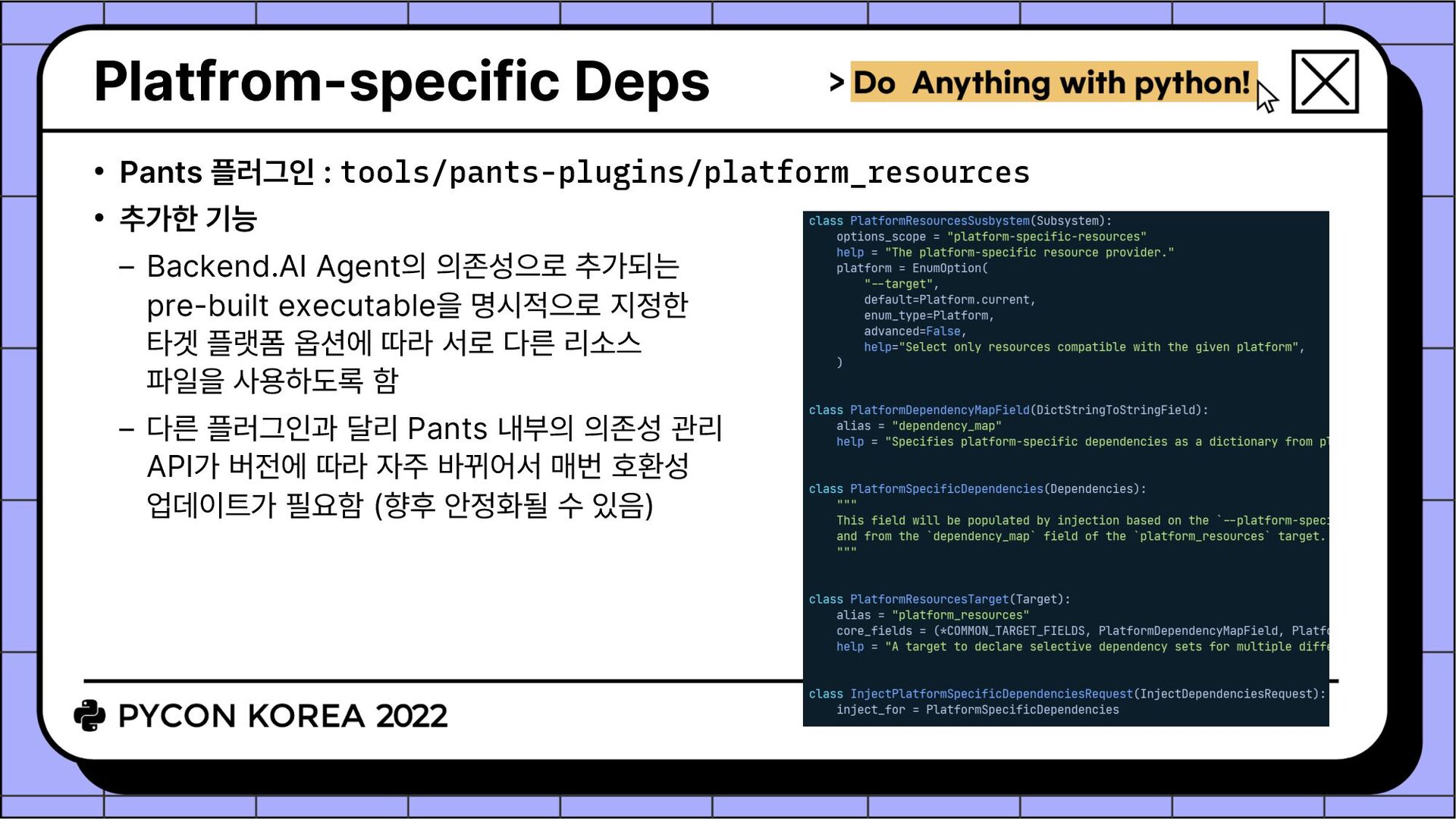
Backend.AI Agent의 의존성으로 추가되는 pre-built executable을 명시적으로 지정한 타겟 플랫폼 옵션에 따라 서로 다른 리소스 파일을 사용하도록 함 다른 플러그인과 달리 Pants 내부의 의존성 관리 API가 버전에 따라 자주 바뀌어서 매번 호환성 업데이트가 필요함 (향후 안정화될 수 있음)
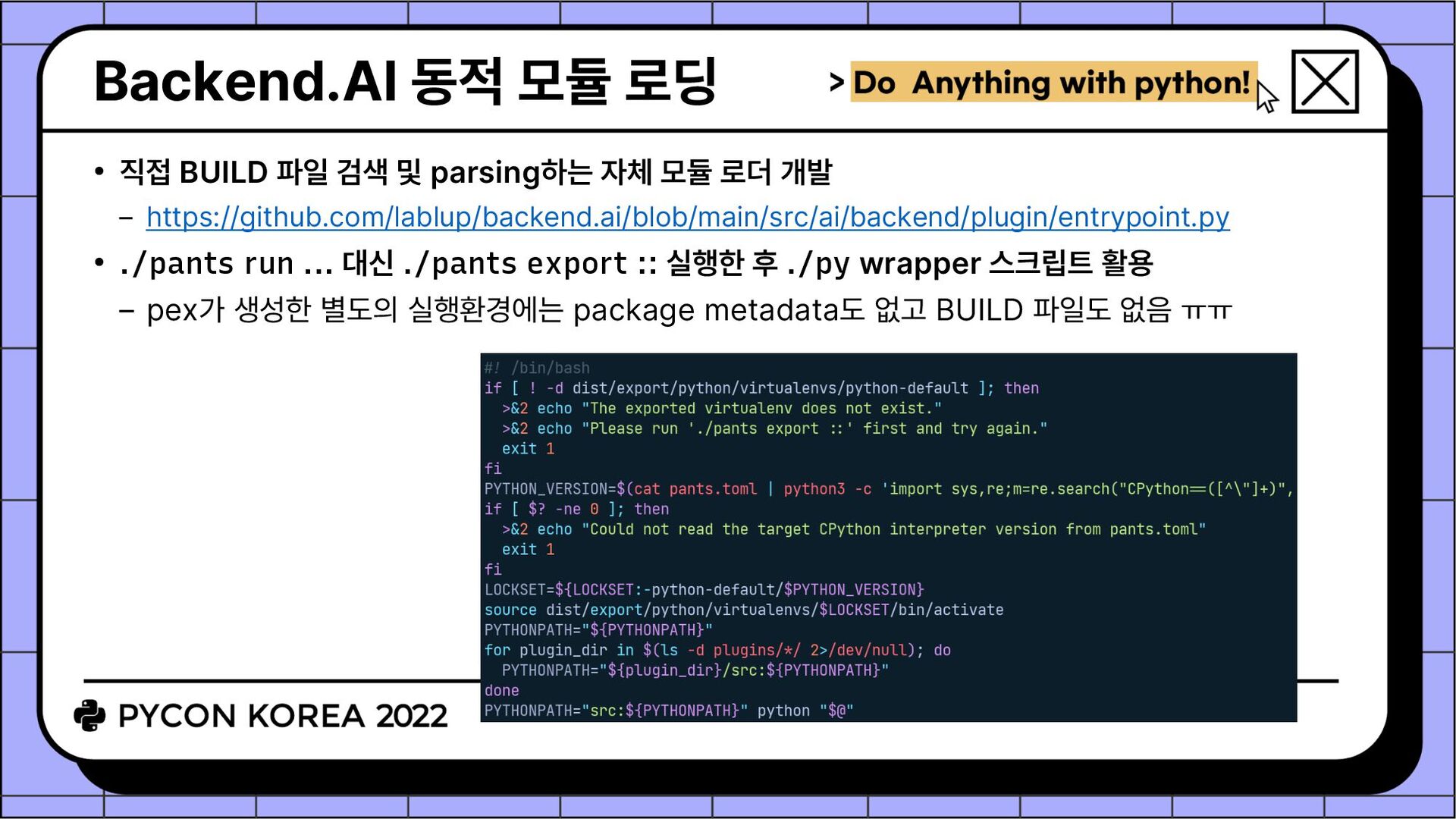
parsing하는 자체 모듈 로더 개발 https://github.com/lablup/backend.ai/blob/main/src/ai/backend/plugin/entrypoint.py • ./pants run ... 대신 ./pants export :: 실행한 후 ./py wrapper 스크립트 활용 pex가 생성한 별도의 실행환경에는 package metadata도 없고 BUILD 파일도 없음 ㅠㅠ
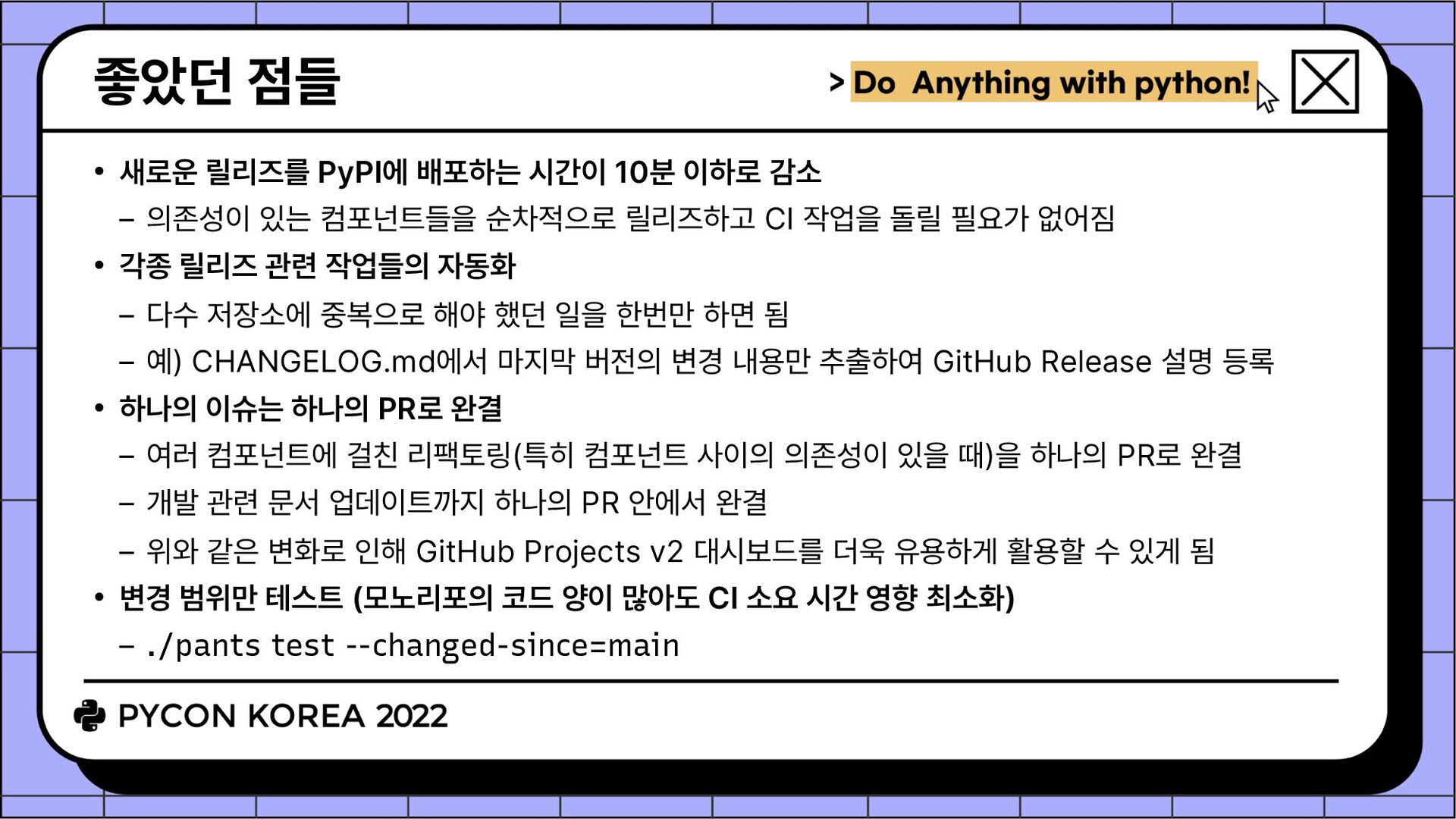
감소 의존성이 있는 컴포넌트들을 순차적으로 릴리즈하고 CI 작업을 돌릴 필요가 없어짐 • 각종 릴리즈 관련 작업들의 자동화 다수 저장소에 중복으로 해야 했던 일을 한번만 하면 됨 예) CHANGELOG.md에서 마지막 버전의 변경 내용만 추출하여 GitHub Release 설명 등록 • 하나의 이슈는 하나의 PR로 완결 여러 컴포넌트에 걸친 리팩토링(특히 컴포넌트 사이의 의존성이 있을 때)을 하나의 PR로 완결 개발 관련 문서 업데이트까지 하나의 PR 안에서 완결 위와 같은 변화로 인해 GitHub Projects v2 대시보드를 더욱 유용하게 활용할 수 있게 됨 • 변경 범위만 테스트 (모노리포의 코드 양이 많아도 CI 소요 시간 영향 최소화) ./pants test --changed-since=main
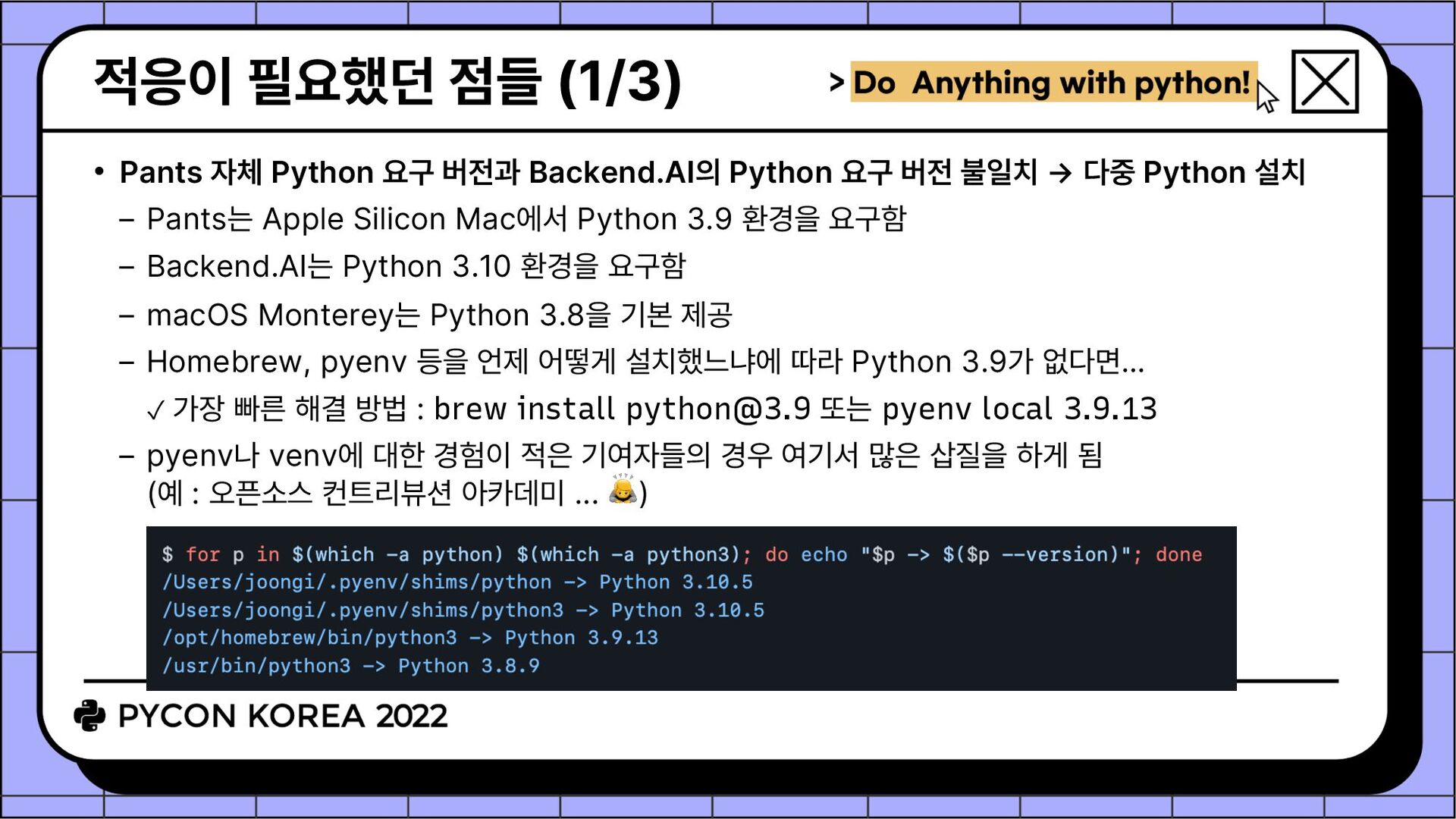
Backend.AI의 Python 요구 버전 불일치 → 다중 Python 설치 Pants는 Apple Silicon Mac에서 Python 3.9 환경을 요구함 Backend.AI는 Python 3.10 환경을 요구함 macOS Monterey는 Python 3.8을 기본 제공 Homebrew, pyenv 등을 언제 어떻게 설치했느냐에 따라 Python 3.9가 없다면... ✓ 가장 빠른 해결 방법 : brew install [email protected] 또는 pyenv local 3.9.13 pyenv나 venv에 대한 경험이 적은 기여자들의 경우 여기서 많은 삽질을 하게 됨 (예 : 오픈소스 컨트리뷰션 아카데미 ... 🙇)
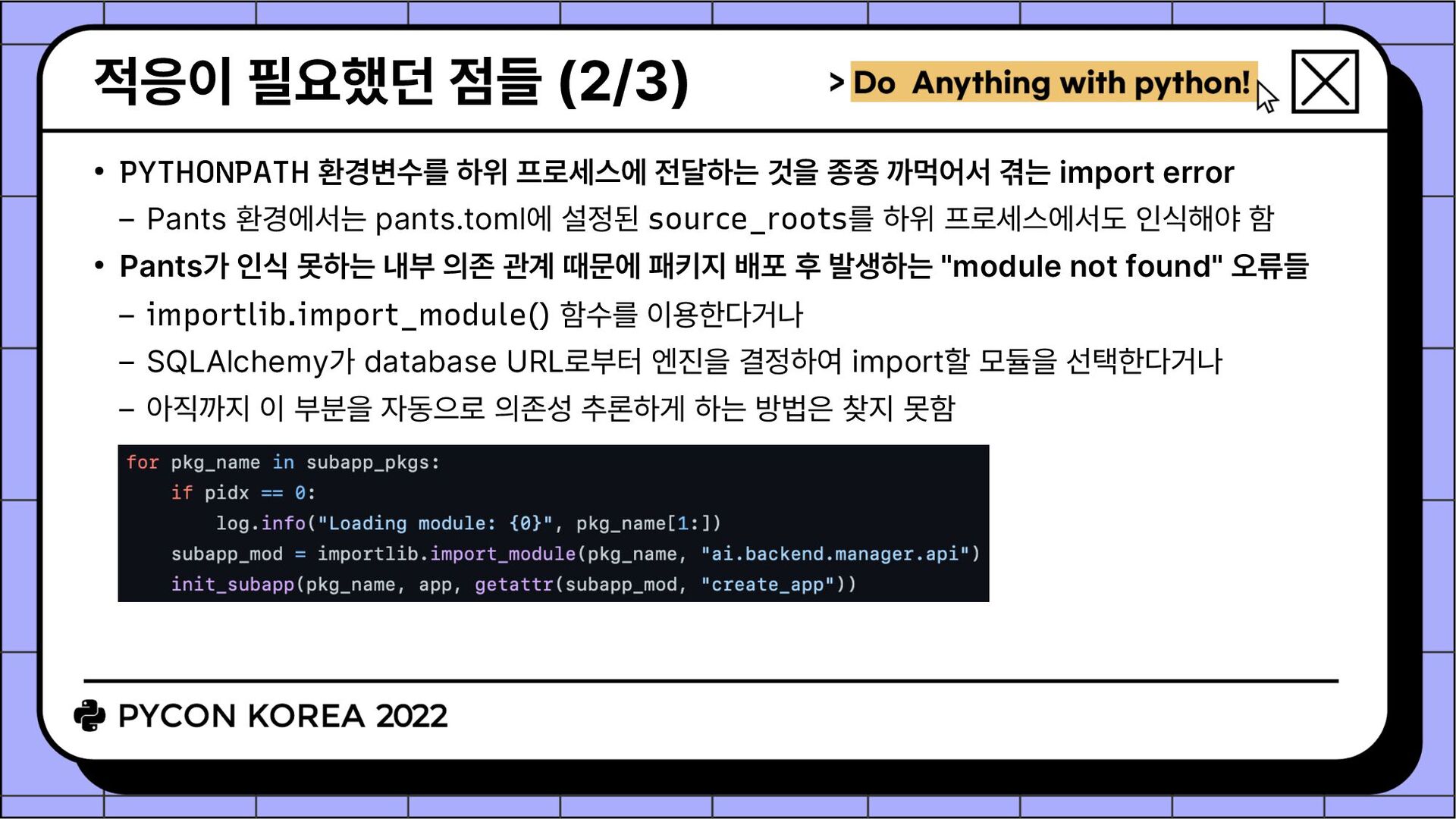
것을 종종 까먹어서 겪는 import error Pants 환경에서는 pants.toml에 설정된 source_roots를 하위 프로세스에서도 인식해야 함 • Pants가 인식 못하는 내부 의존 관계 때문에 패키지 배포 후 발생하는 "module not found" 오류들 importlib.import_module() 함수를 이용한다거나 SQLAlchemy가 database URL로부터 엔진을 결정하여 import할 모듈을 선택한다거나 아직까지 이 부분을 자동으로 의존성 추론하게 하는 방법은 찾지 못함
실행되도록 하기까지 많은 노력 필요 특히 database 컨테이너를 고정 포트 번호로 띄우는 경우 충돌 발생 ✓ pants.toml 설정 : [pytest].execution_slot_var = "BACKEND_TEST_EXEC_SLOT" ✓ 컨테이너 생성 fixture에서 이 환경변수 값을 포트 번호에 더하여 중복 사용 방지 • Ubuntu 22.04 + Snap + Docker + /tmp Docker가 Snap을 통해 설치된 경우 host /tmp 대신 가상 private /tmp를 사용하도록 강제됨 각종 테스트 코드에서 /tmp 디렉토리에 임시 생성한 파일을 컨테이너가 못 읽어서 한참 동안 삽질 사실 이건 Pants 자체의 문제는 아니지만, 컨테이너에 의존하는 테스트 코드 병렬 실행 가능하도록 변환하는 과정에서 fixture들이 각 테스트 모듈마다 서로 다른 임시디렉토리를 사용하게 하다보면 거의 필연적으로 겪는 문제 ✓ /tmp 대신 ./.tmp를 사용하는 방식으로 우회
꼬박 한달 넘게...) • 하지만 이후의 개발 프로세스 경험을 고려하면 충분히 가치있는 일이었음. 강력한 캐싱 기능과 의존성 기반 변경사항 탐지 기능으로 모노리포로 합친 후에도 기본적인 작업 프로세스가 크게 느려지지 않음 ✓ black + isort + git hook 도입, release note 생성 자동화, 변경 영향 범위만 테스트 실행 테스트 병렬화로 향후 GitHub Action Runner 사양을 높였을 때 큰 이득을 볼 수 있는 길이 열림 • 이전 작업 과정에서 Pantsbuild 커뮤니티 슬랙에서 매우 많은 도움을 받음 친절한 코어 커뮤니티의 중요성 체감 문서 수정, 버그 보고, PyCon 발표 등으로 최대한 되돌려주기 위해 노력 • Python 기반 mono-repo를 고민한다면 Pants 고려해봅시다!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}