Architecture”, https://pages.cs.wisc.edu/~sinclair/courses/cs758/fall2019/handouts/lecture/cs758-fall19- gpu_uarch2.pdf n M. Lee et al., "Improving GPGPU resource utilization through alternative thread block scheduling," 2014 IEEE 20th International Symposium on High Performance Computer Architecture (HPCA), Orlando, FL, USA, 2014, n Xiaodan Serina Tan, Pavel Golikov, Nandita Vijaykumar, and Gennady Pekhimenko. 2023. GPUPool: A Holistic Approach to Fine-Grained GPU Sharing in the Cloud. In Proceedings of the International Conference on Parallel Architectures and Compilation Techniques (PACT ʻ22) n H. Zhao et al., "Tacker: Tensor-CUDA Core Kernel Fusion for Improving the GPU Utilization while Ensuring QoS," 2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA), 23 参考⽂献
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
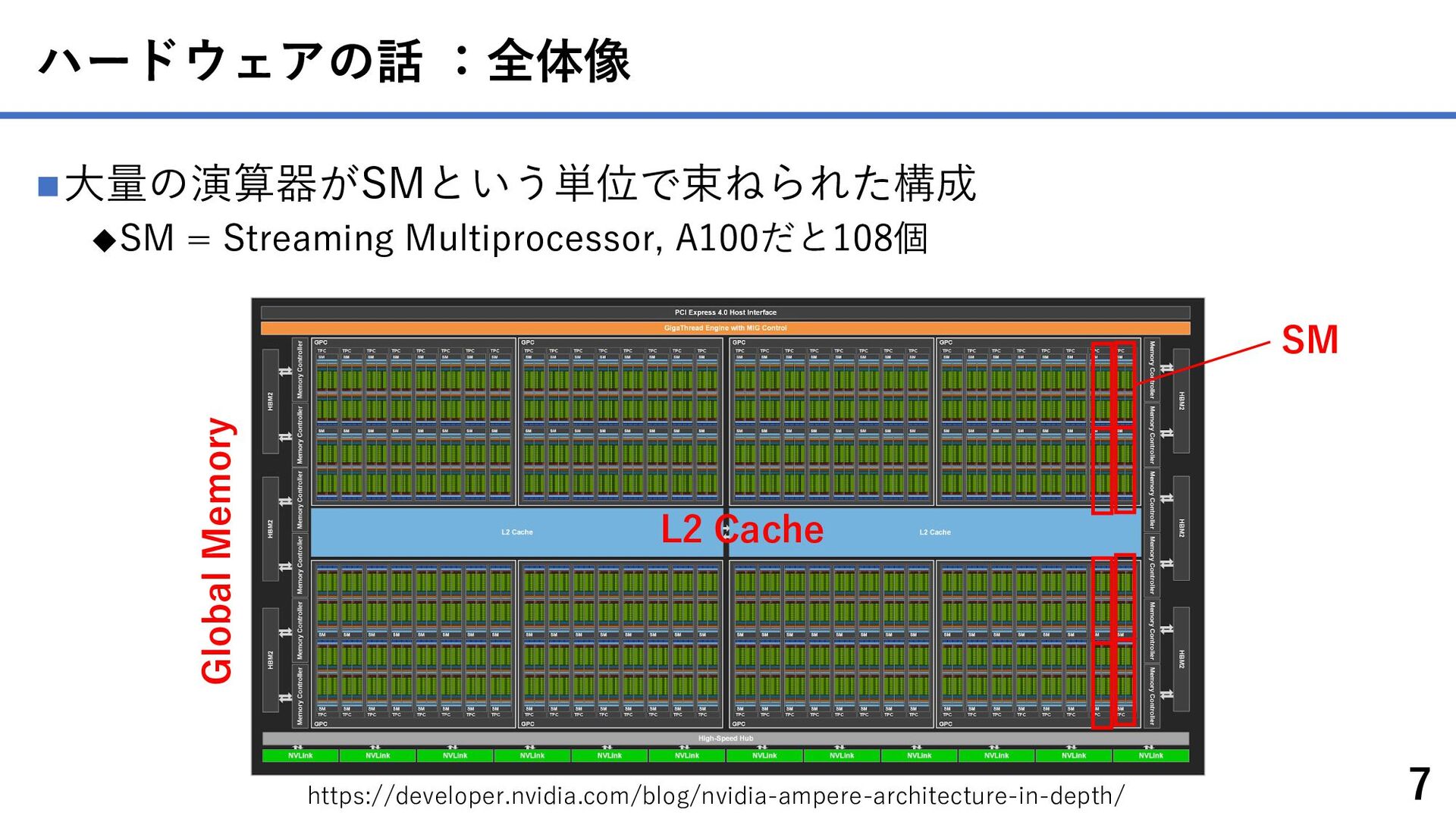{kind=link}
{kind=link}
{kind=link}
{kind=link}
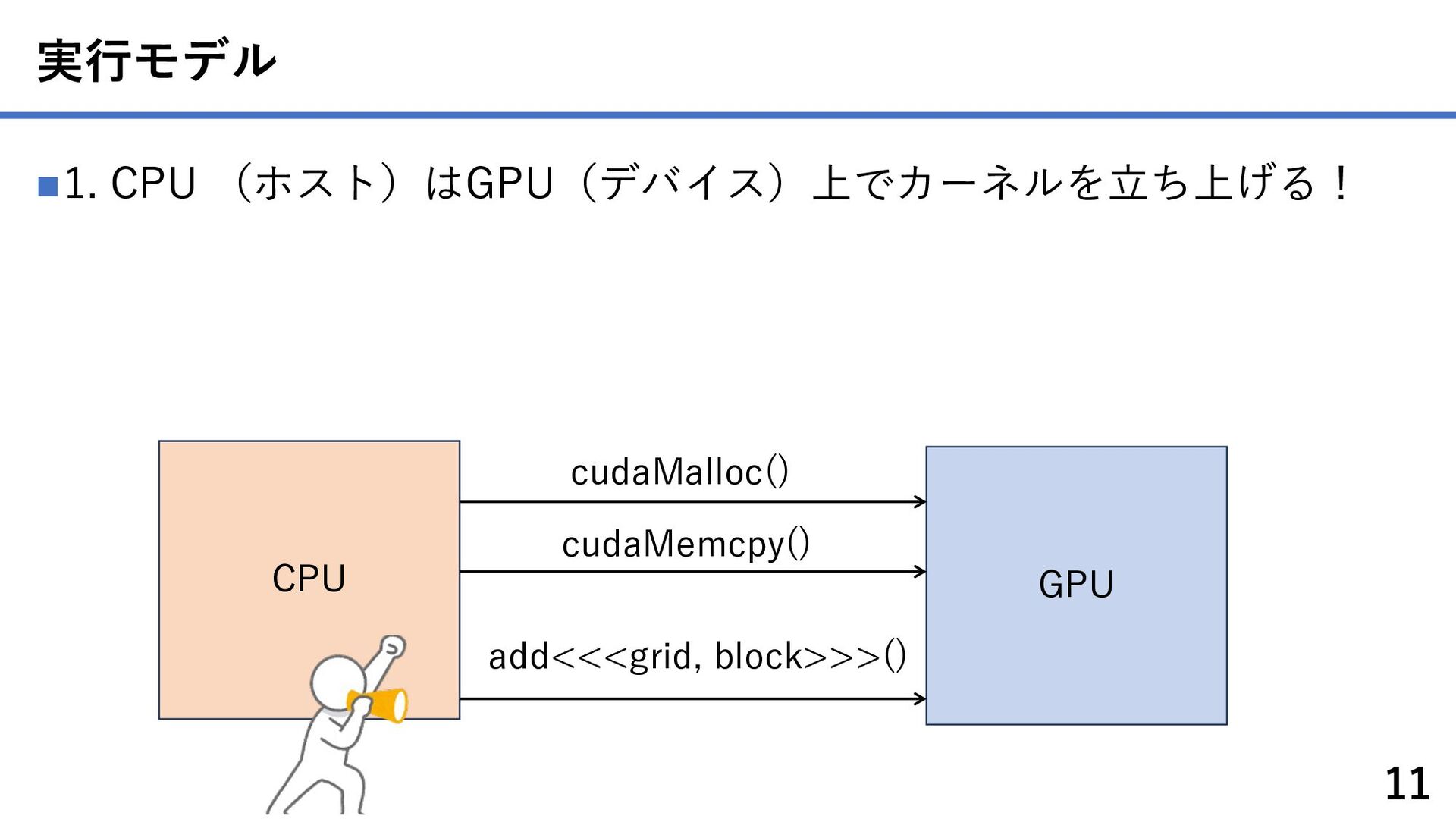{kind=link}
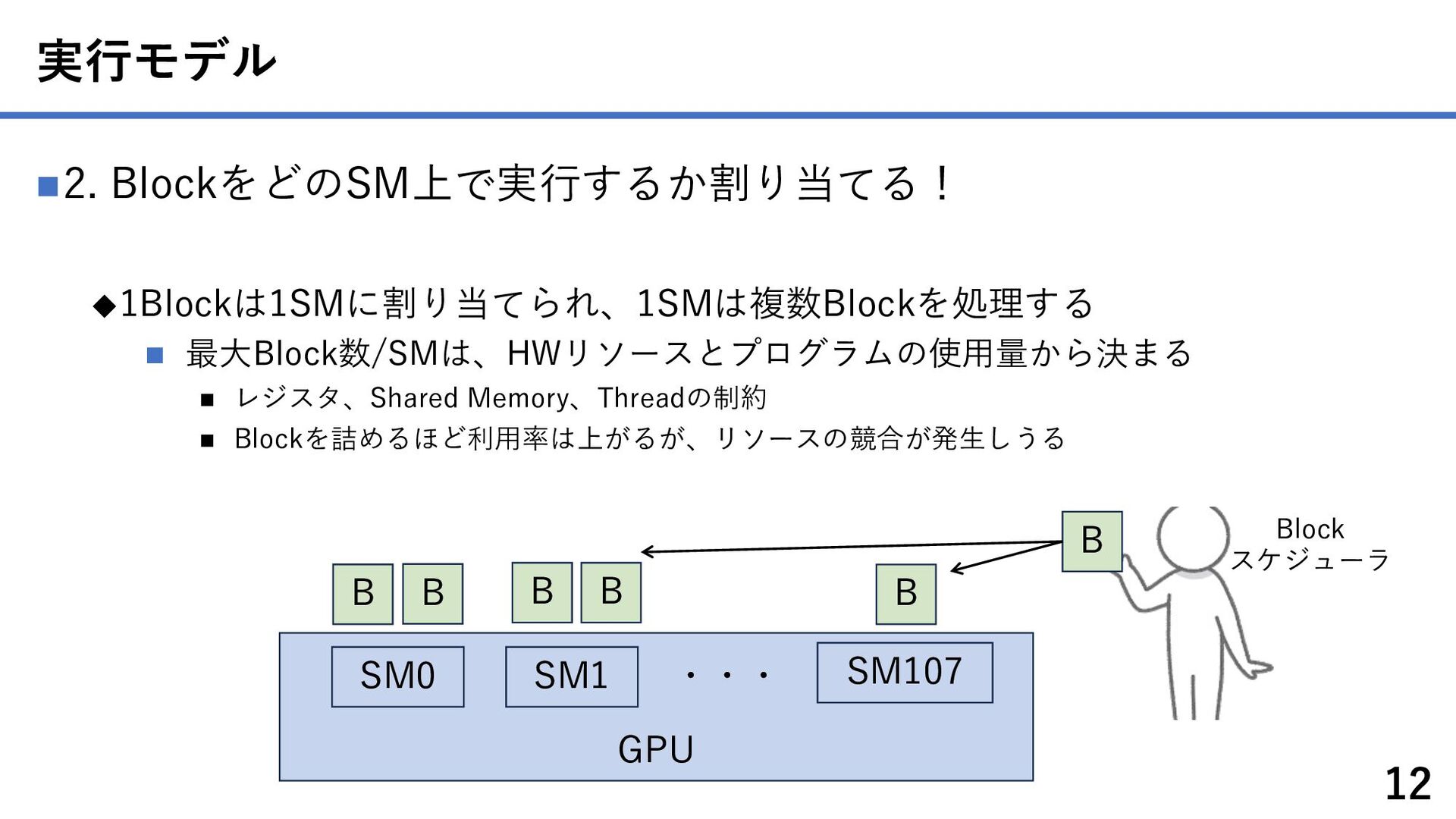{kind=link}
{kind=link}
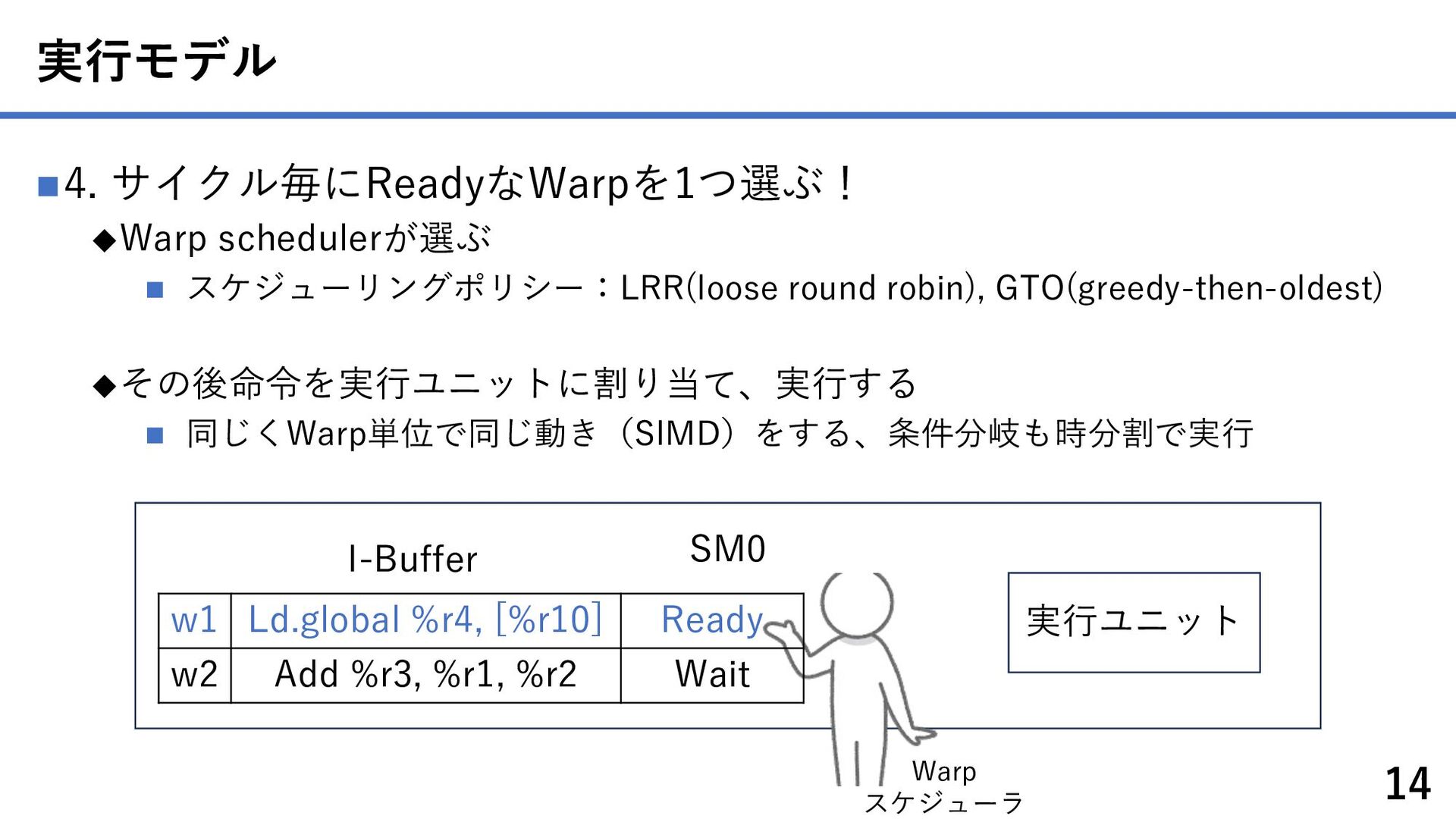{kind=link}
{kind=link}
{kind=link}
{kind=link}
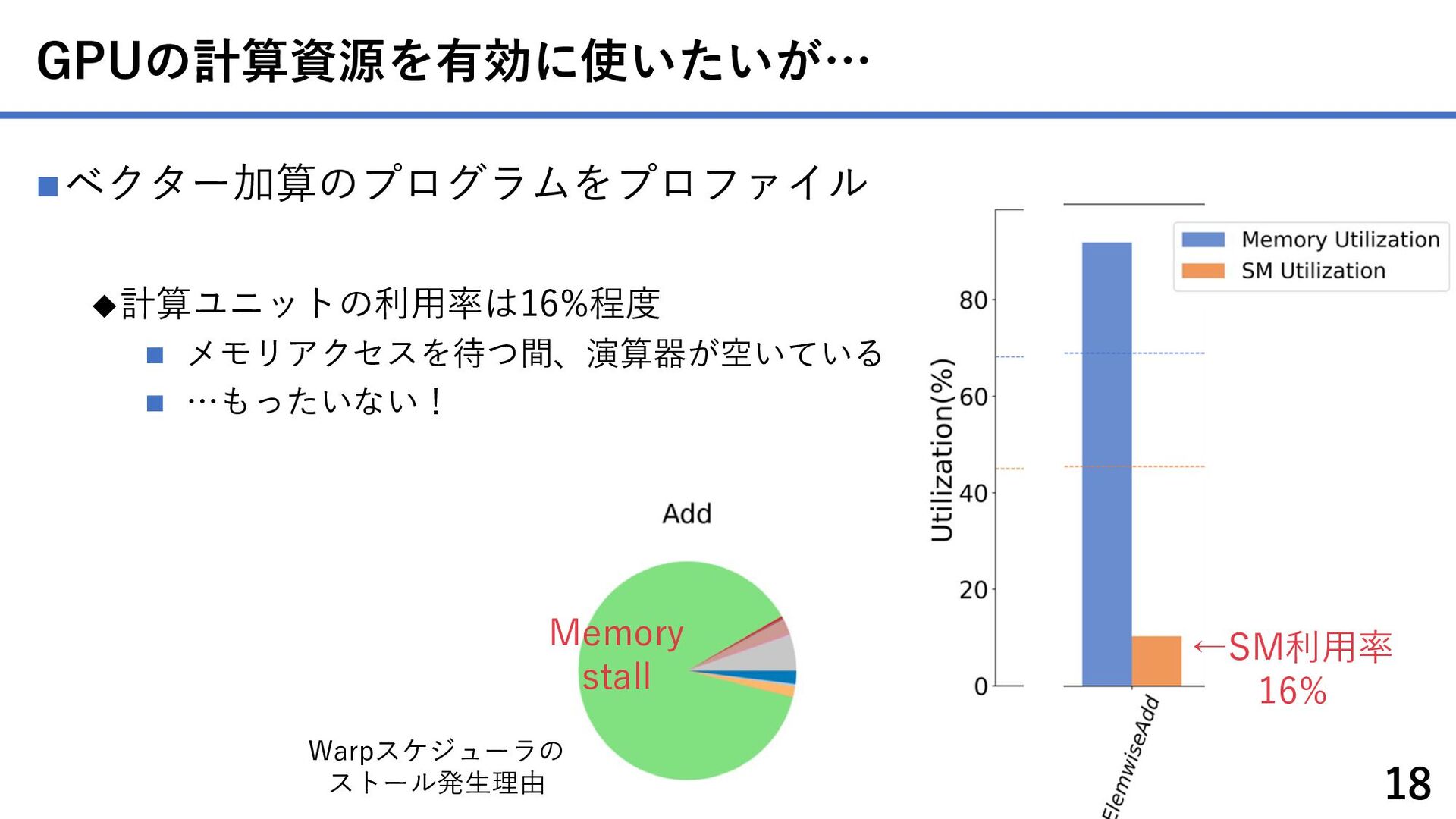{kind=link}
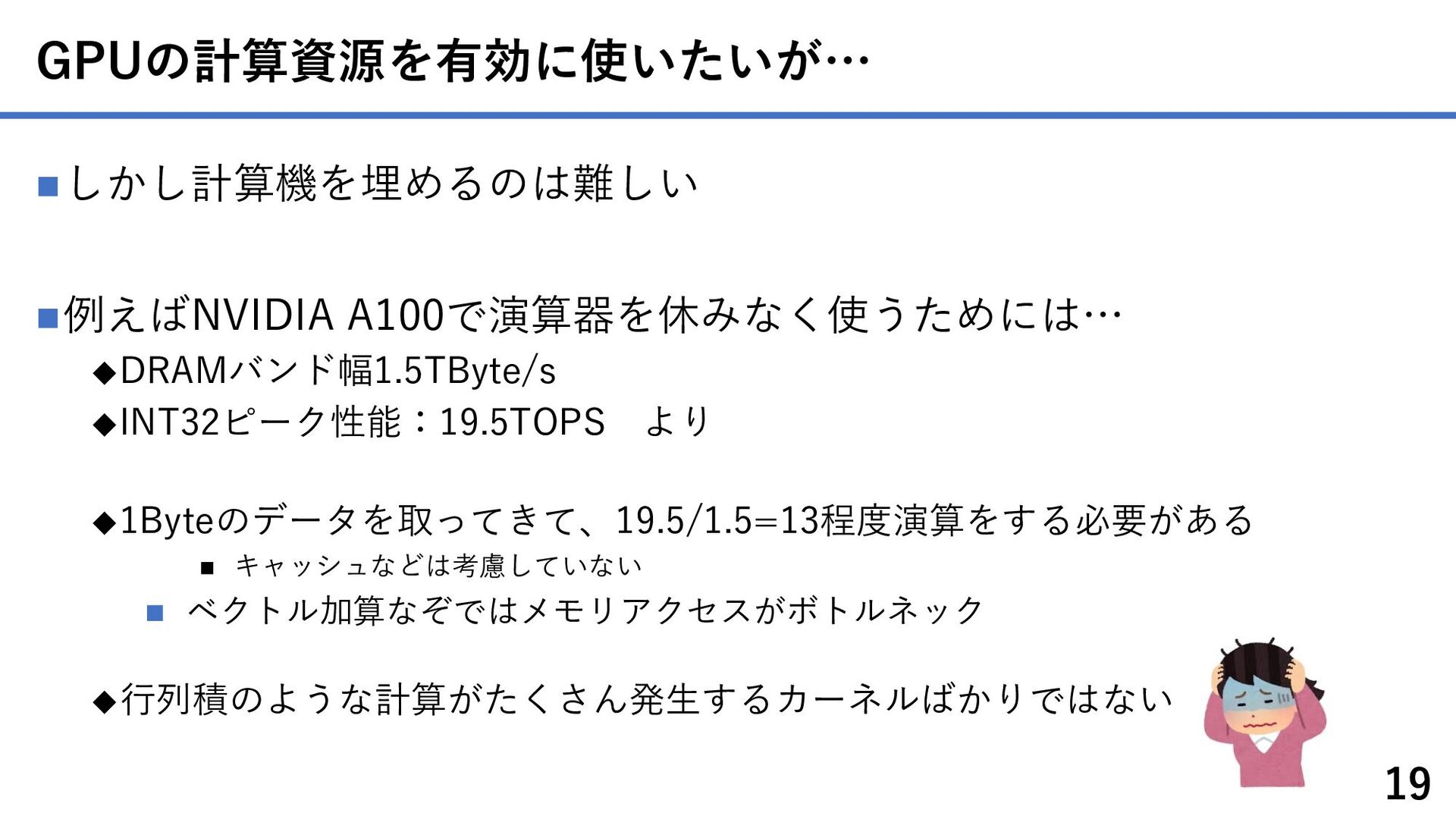{kind=link}
{kind=link}
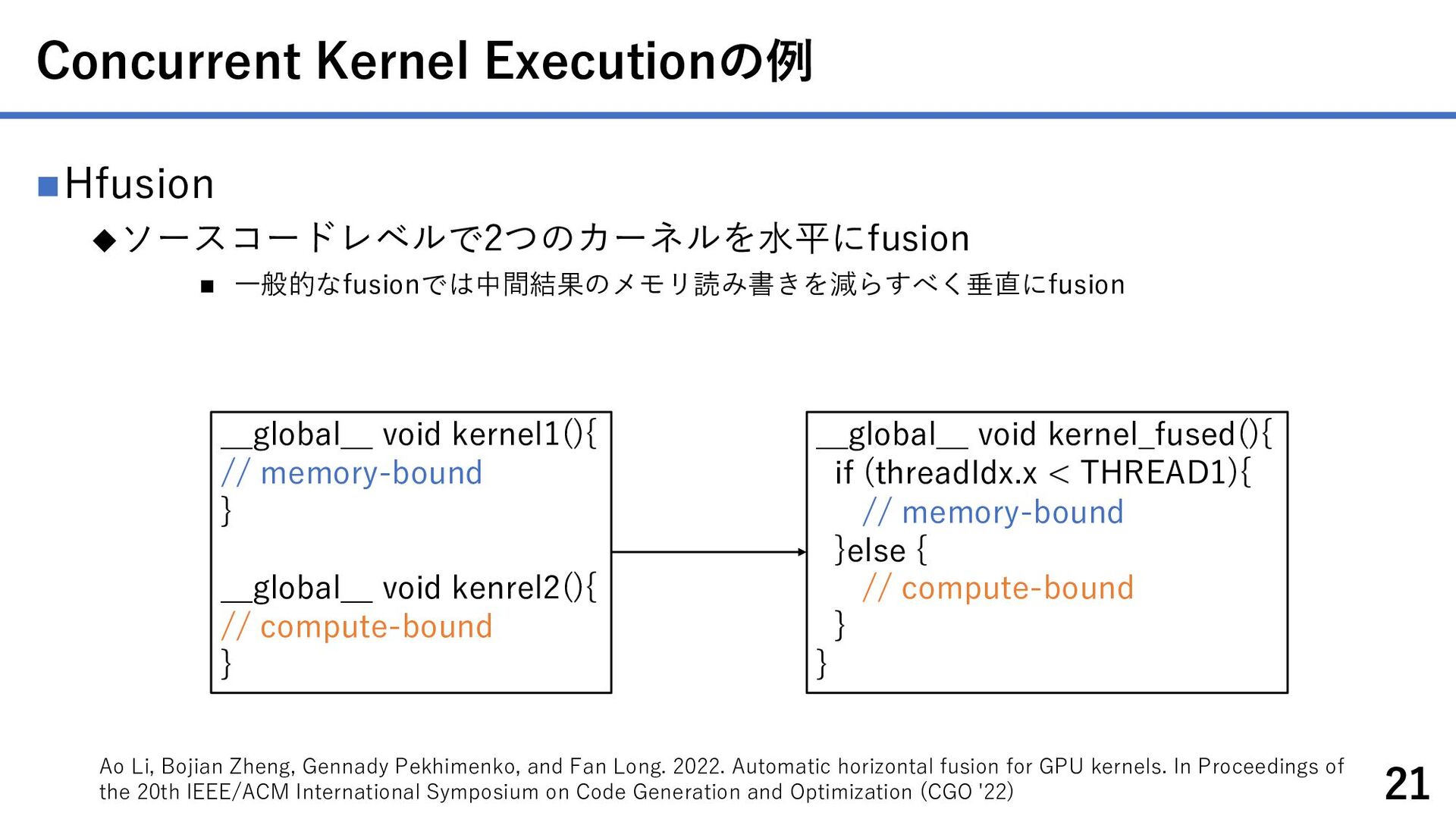{kind=link}
{kind=link}
{kind=link}