d a d, a nd AWS Serverless Hero, p a ssion a te a bout softw a re a rchitectures, serverless, a nd m a chine le a rning. Serverless It a ly, [Gen]AI It a ly, a nd MMUG Meetup co-founder. ServerlessD a ys Mil a no a nd AWS Community D a y co-org a nizer. Big Daddy Little Elisa github.com/aletheia https://it.linkedin.com/in/lucabianchipavia https://speakerdeck.com/aletheia bianchiluca.com @bianchiluca
M a ny documents • Hum a n costs • Error-prone Contr a ct Dr a fting • Time intensive • Error-prone • Knowledge m a n a gement issues Leg a l Rese a rch • Inform a tion Overlo a d • Outd a ted inform a tion • Complexity Judici a l Proceedings • Time intensive • Error-prone • Knowledge m a n a gement issues
approach • Tech companies adopted Large Language Models (LLM) to process legal documents. • Fine-tuning LLMs is an expensive solution. Legal datasets are not certi fi ed, nor language or law systems compliant. • Domain knowledge is often lost in the process, in favor of a tech approach. • Accuracy fails to solve the problem, becoming less accurate than humans. • A faulty approach brings to the misconception LLMs are not suitable for domain speci fi c tasks. • We need a platform approach, joining di ff erent techniques to solve the business problem.
Rooms are the base element of legal procedures • Process Data Rooms to ensure • PII redaction • Metadata extraction pipeline • Custom document work fl ow through Prompt Builder. • Legal fi rms experience becomes valuable (and reusable) knowledge.
• Can be attached to speci fi c document types • Document-based processing • Reusable data extraction procedures • Easy to operationalize, hard to maintain • Many moving parts • LLM Ops are not easy
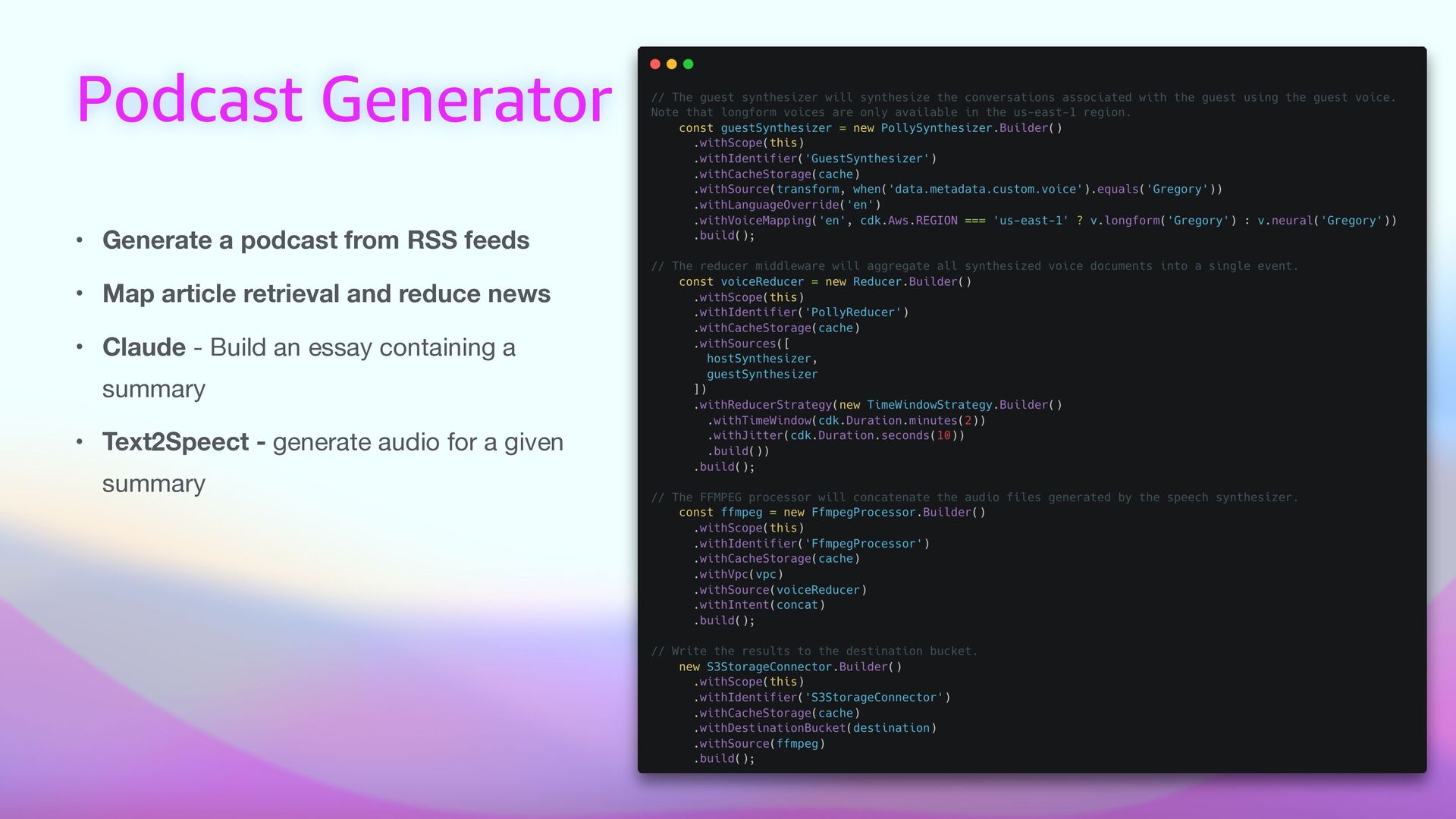
• A framework based on the AWS Cloud Development Kit (CDK) • allows the expression and deployment of scalable document processing pipelines on AWS using infrastructure-as-code. • Modularity • Extensibility (through plugins) • Re-usable components • Addressing many use cases • It is not bounded to generative AI use cases
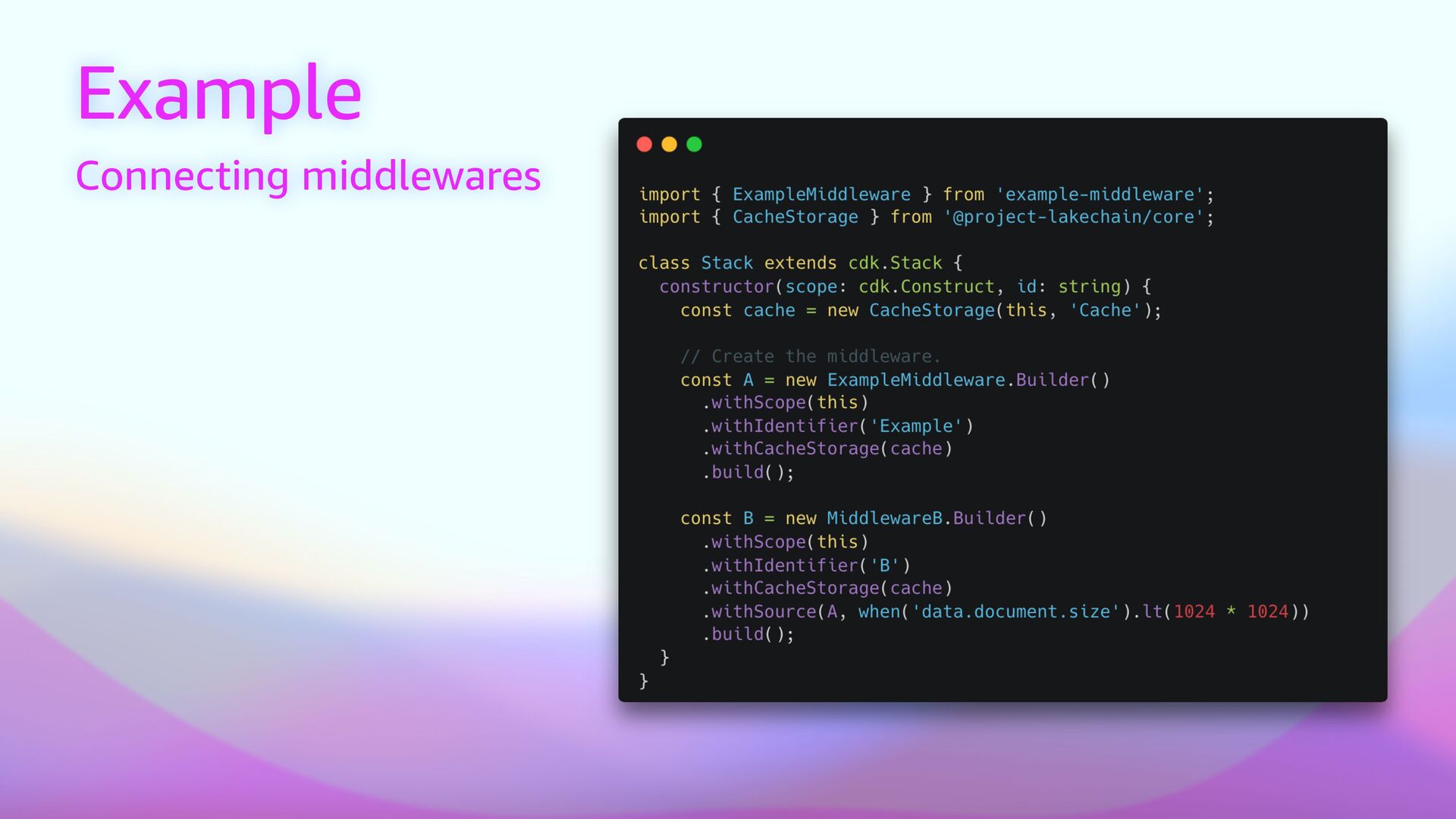
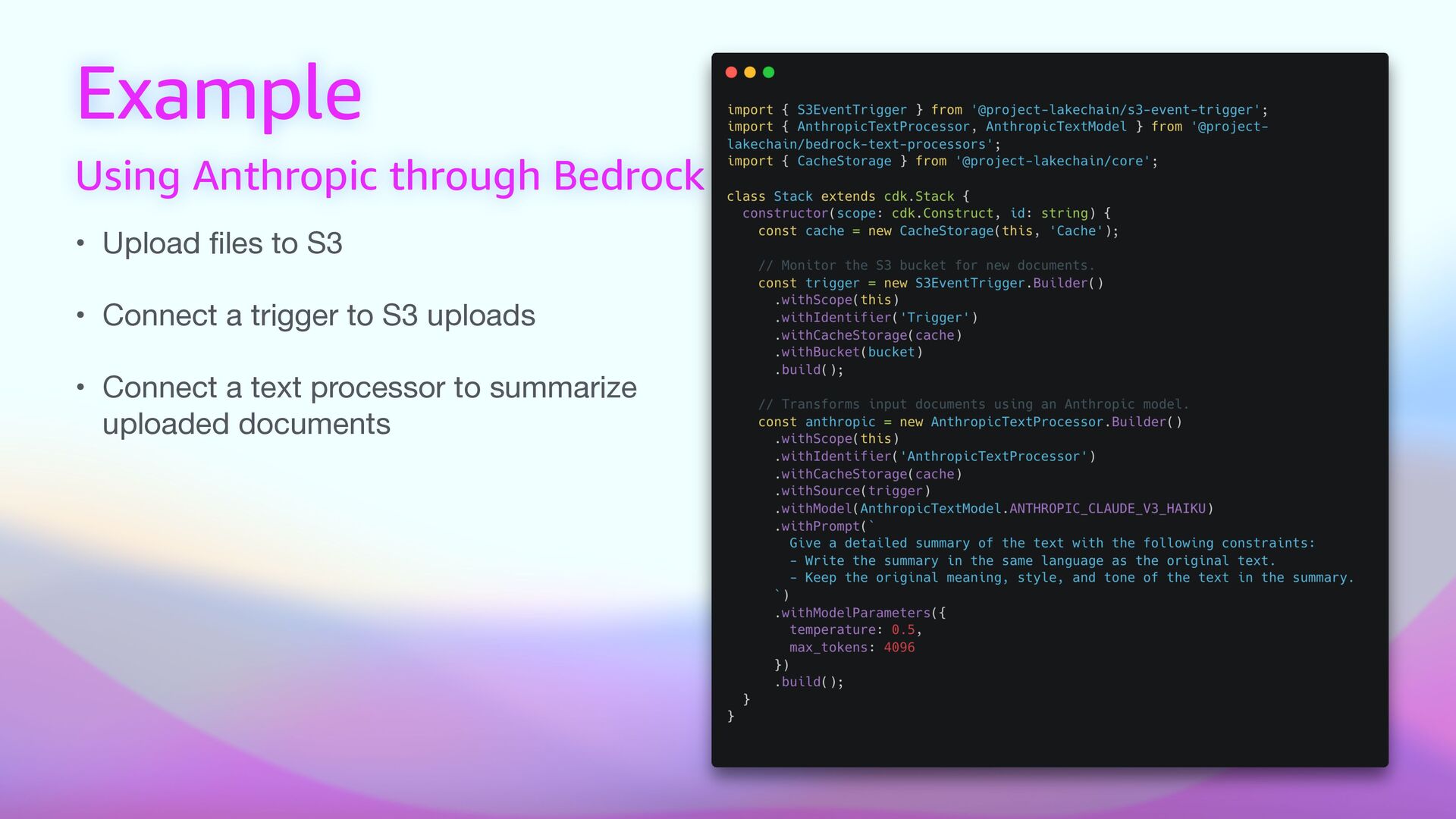
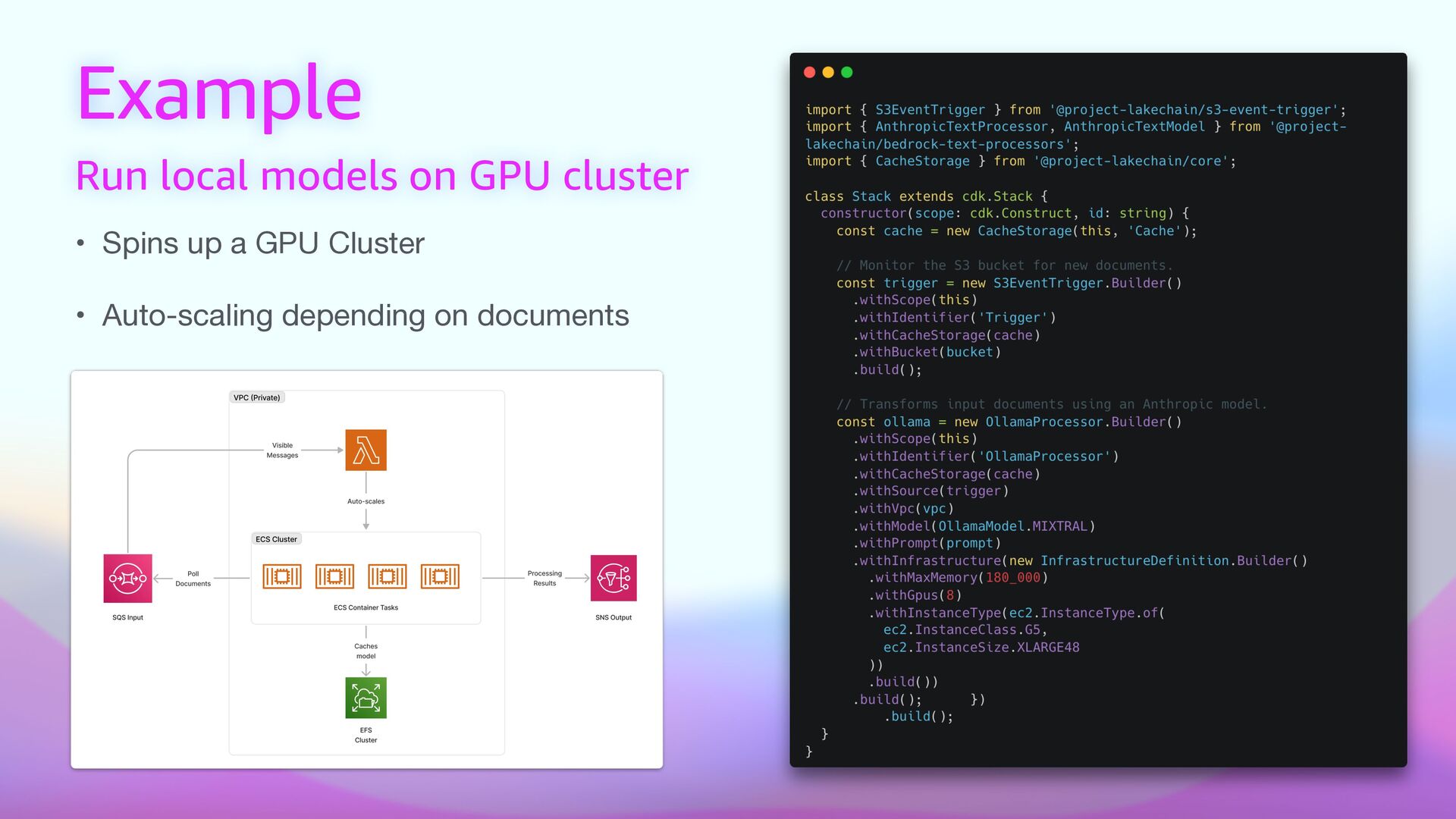
express document processing pipelines using middlewares. • ☁ Scalable — Scales out-of-the box. Process millions of documents and scale to zero automatically when done. • ⚡ Cost E ff i cient — Uses cost-optimized architectures to reduce costs and drive a pay-as-you-go model. • 🚀 Ready to use — 60+ built-in middlewares for document processing tasks, ready to be deployed. • 🦎 GPU and CPU Support — Use the right compute type to balance performance and cost. • 📦 Bring Your Own — Create your transform middlewares to process documents and extend Lakechain. • 📙 Ready Made Examples
be leveraged to map di ff erent choices, based on data properties • Middlewares • 60+ built-in middlewares • Ensure type safety • I/O Types (through MIME types) • Compute Types Pipelines Concepts
after CloudEvents speci fi cation • Allows middleware to understand the data they are managing • Can be transferred using Amazon EventBridge • Uses data envelope Events Concepts
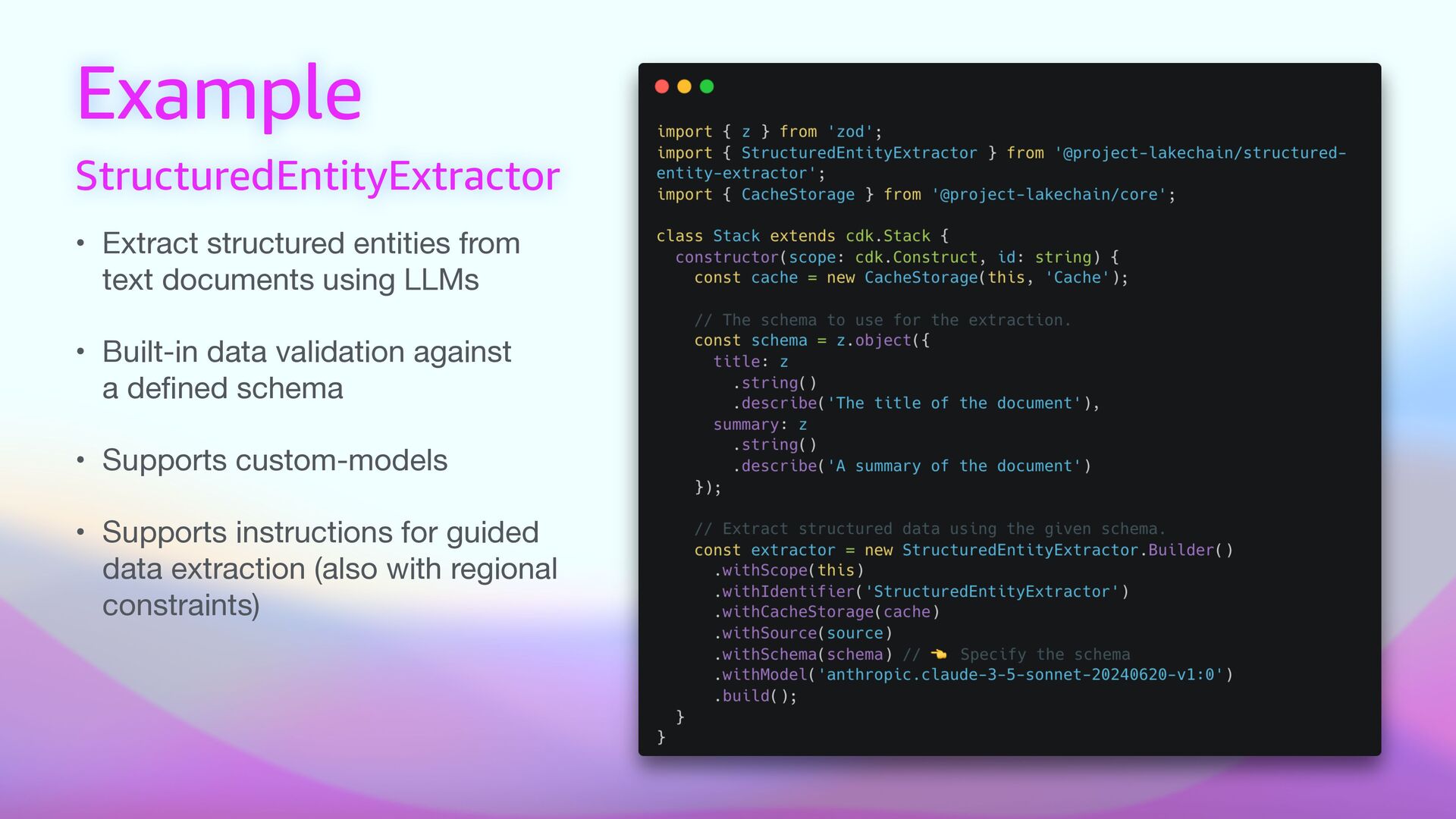
using LLMs • Built-in data validation against a de fi ned schema • Supports custom-models • Supports instructions for guided data extraction (also with regional constraints)
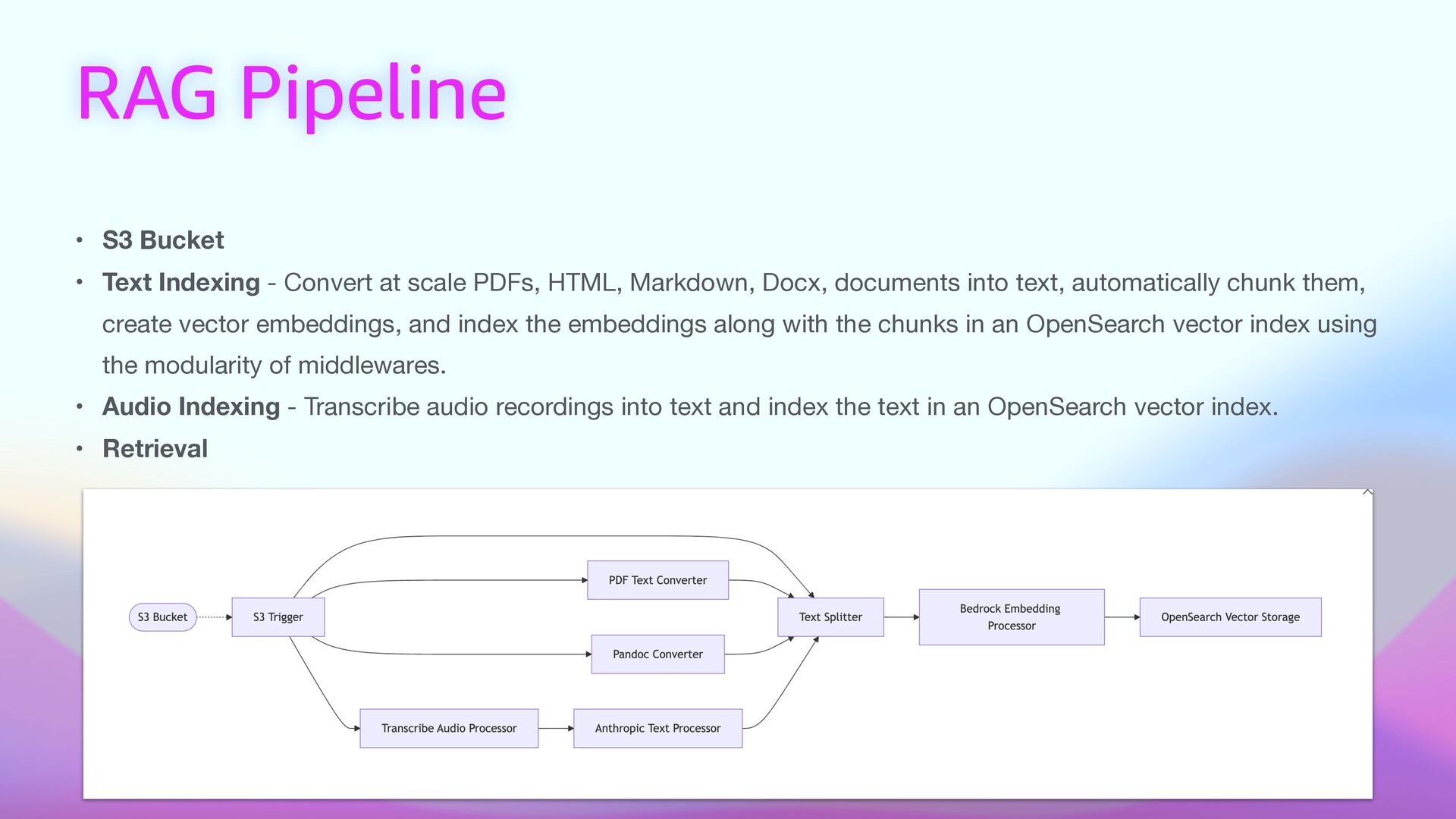
at scale PDFs, HTML, Markdown, Docx, documents into text, automatically chunk them, create vector embeddings, and index the embeddings along with the chunks in an OpenSearch vector index using the modularity of middlewares. • Audio Indexing - Transcribe audio recordings into text and index the text in an OpenSearch vector index. • Retrieval
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}