Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Kibanaを用いたアクセスログ調査と解析 / Access Log Analysis Us...
Search
alpicola
August 02, 2018
1k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Kibanaを用いたアクセスログ調査と解析 / Access Log Analysis Using Kibana
alpicola
August 02, 2018
More Decks by alpicola
See All by alpicola
[AEON TECH HUB #24] お客様の長期的興味の理解に向けて
alpicola
0
210
商品レコメンドでのexplicit negative feedbackの活用
alpicola
2
1k
Recommending What Video to Watch Next: A Multitask Ranking System
alpicola
1
970
Offline A/B testing for Recommender Systems
alpicola
0
2.2k
Featured
See All Featured
The Invisible Side of Design
smashingmag
301
52k
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
23k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
1.9k
RailsConf 2023
tenderlove
30
1.5k
Navigating Team Friction
lara
192
16k
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
480
How STYLIGHT went responsive
nonsquared
100
6.2k
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
240
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
350
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
380
Transcript
を用いた アクセスログ調査と解析 勉強会
あるぴこら • 株式会社はてな • アプリケーションエンジニア • はてなブックマークチーム 最近
サービスの稼働状況・アプリケーションの状態 をどうやって把握するか
はてなのサーバー監視 • ◦ 自社サービス
None
• 状態の記録・監視 ◦ ホストの稼働状態 ▪ やミドルウェアのメトリック ◦ サービスの稼働状態 ▪ サービス全体のアクセス状況
レイテンシ • 障害対応など が起点
アクセスログのユースケース • リクエストにフォーカスしたいとき ◦ エンドポイント ユーザー 応答時間 • 例 ◦
障害の原因となるエンドポイントの特定 ◦ アプリケーションのパフォーマンス分析
アクセスログの形式 • ベース ◦ 時刻 time リクエスト uri 応答時間 reqtime
ステータ スコード status ユーザーエージェント ua • その他 ◦ エンドポイントの識別子 dispatch ◦ ログが生成されたホスト名 hostname
アクセスログの配送 • で へ送る • 流量は数億 くらい ◦ リクエスト数とは異なる サンプリングもしてる
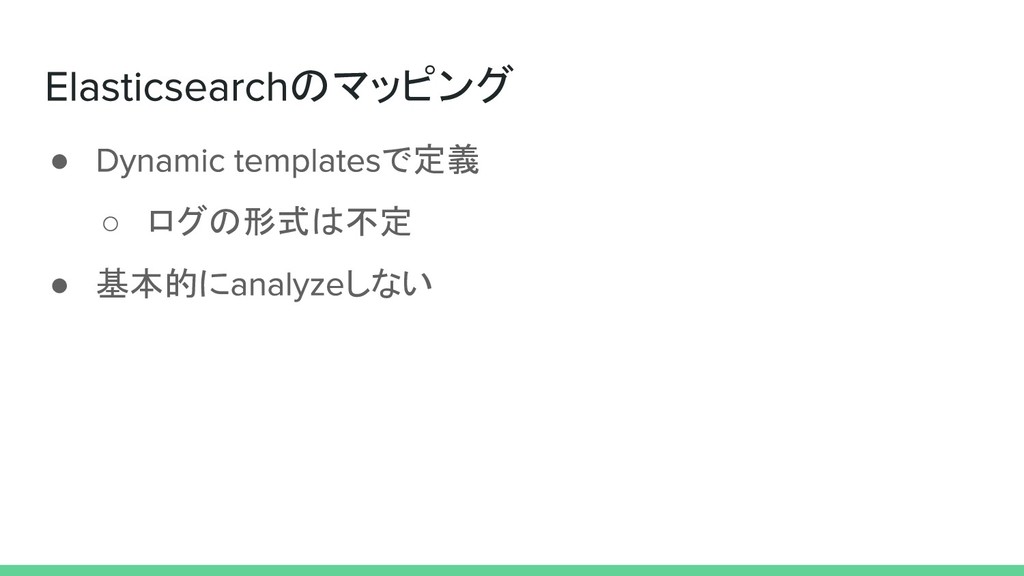
のマッピング • で定義 ◦ ログの形式は不定 • 基本的に しない
ケーススタディ
障害対応時 • のアラートで異常に気づく • で細かい状況把握と原因調査 ◦ で異常を示したメトリクスが手がかり
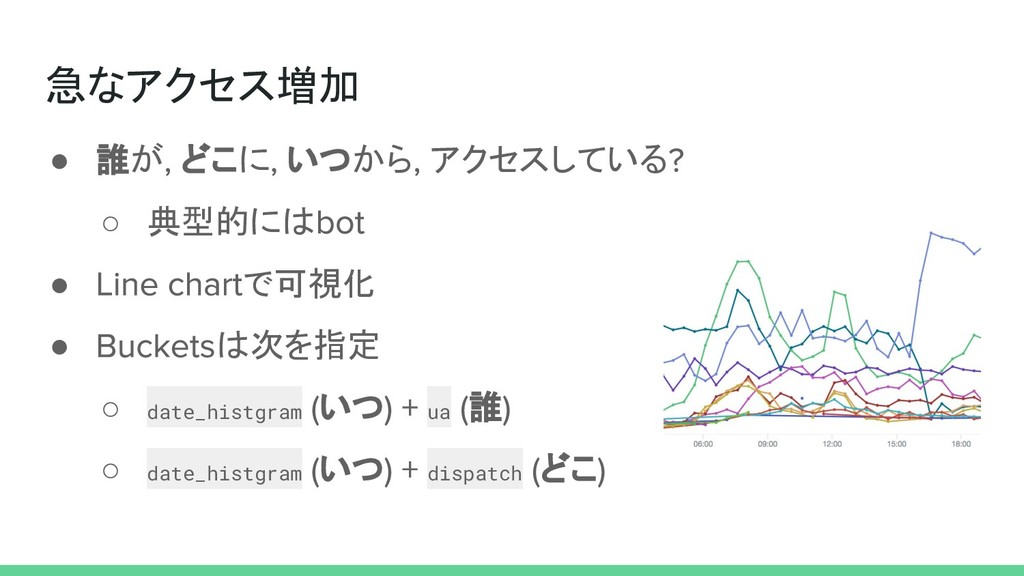
急なアクセス増加 • 誰が どこに いつから アクセスしている ◦ 典型的には • で可視化
• は次を指定 ◦ date_histgram いつ ua 誰 ◦ date_histgram いつ dispatch どこ
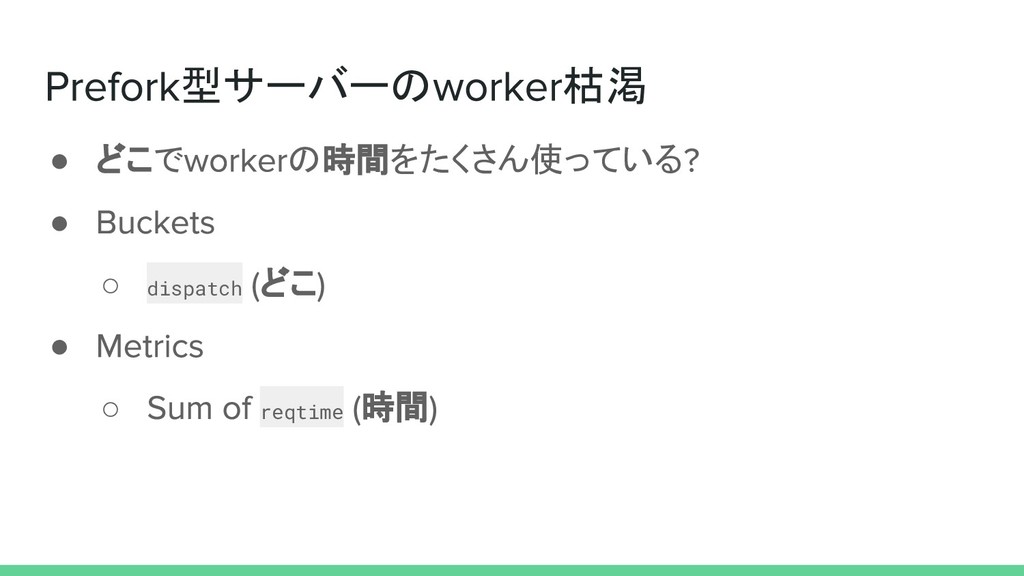
型サーバーの 枯渇 • どこで の時間をたくさん使っている • ◦ dispatch どこ •
◦ reqtime 時間
レスポンスの増加 • タブで status: [500 TO inf] • で値の偏りがないか見る ◦
エンドポイント dispatch uri ◦ クライアント ua client_ip ◦ ホスト hostname • 怪しい要素でフィルタして原因特定まで絞り込む
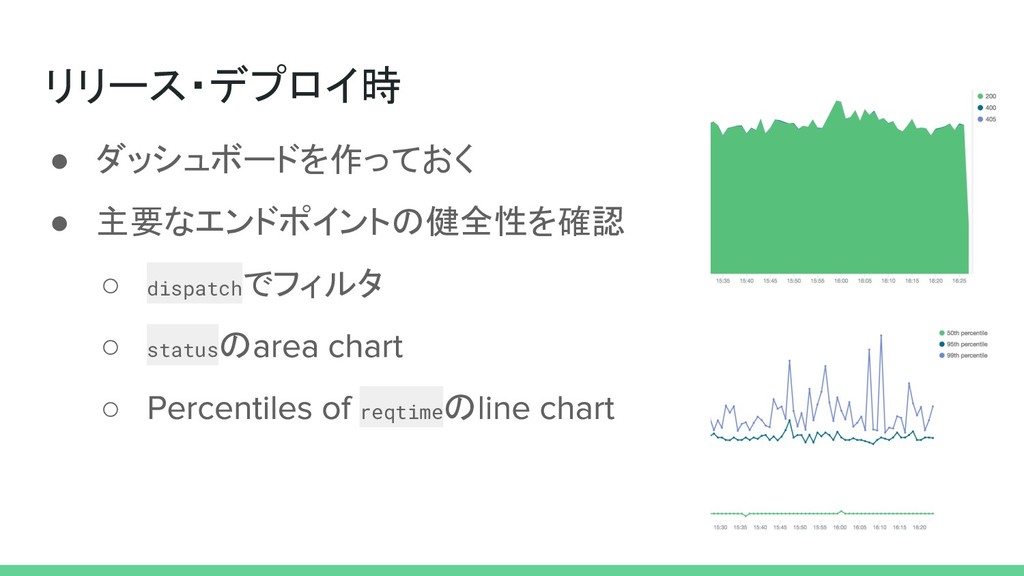
リリース・デプロイ時 • ダッシュボードを作っておく • 主要なエンドポイントの健全性を確認 ◦ dispatchでフィルタ ◦ statusの ◦
reqtimeの
パフォーマンス振り返り • エンドポイント dispatch ごとに表にする ◦ reqtime ◦ reqtime の時間の利用
◦ size 帯域の利用
課題/今後の展望
「クソクエリ」問題 • 実行に長時間かかる • 大量のリソースを消費 • クラスタ全体の応答時間が悪化 ◦ ログの投入も遅延
先頭のワイルドカード • ua:*GoogleBot* • あらゆる を考慮することになるので遅い • 対策 allow_leading_wildcardをfalse にする
な の集計 • の生成で に比例した計算量 • な の集計を行う意義は少ない • ダッシュボードを作った後で
が高くなることも
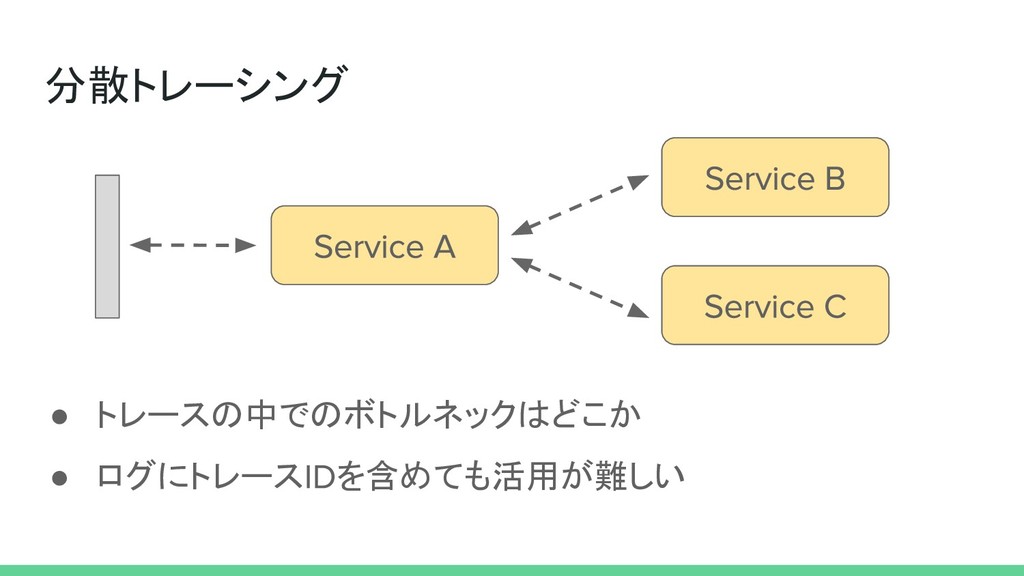
分散トレーシング • トレースの中でのボトルネックはどこか • ログにトレース を含めても活用が難しい
モニタリング • エンドポイントごとのモニタリングがしたい ◦ 異常があれば自動でアラートをあげたい • ダッシュボードだけではモニタリングではない
アイデア • の を使う ◦ クエリの実行結果を外部に通知できる機能 ◦ 任意のトリガ・整形方法 • のサービスメトリックを投稿
を使ってみて • サービスの運用に役立っている ◦ 探索的なログ調査 ◦ ダッシュボードによる観測 • のモニタリングと組み合わせる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![レスポンスの増加 • タブで status: [500 TO inf] • で値の偏りがないか見る ◦](https://files.speakerdeck.com/presentations/6347356c44ba4d1684bfede5ee867ea2/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}