Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Firestore → Spanner 移行 を成功させた段階的移行プロセス
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
a-thug
September 08, 2025
Technology
930
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Firestore → Spanner 移行 を成功させた段階的移行プロセス
データベースの負債解消への道のりLunch Talk
https://findy.connpass.com/event/365313/
a-thug
September 08, 2025
More Decks by a-thug
See All by a-thug
全PRの83%がAIレビューだけでマージできるようになった開発組織はその後どうなったか
athug
0
1k
Other Decks in Technology
See All in Technology
オートロックマンションなのに、各部屋は施錠なし!? 攻撃者が組織内ネットワークで大暴れする理由 / The Front Door Is Locked, but the Rooms Are Wide Open: Why Attackers Move Freely Inside Enterprise Networks
nttcom
0
650
なぜ、あなたのAPIは使われないのか? AX時代の設計原則、ガードレール、運用体制
yokawasa
1
1.2k
CloudWatchから始めるAWS監視
butadora
0
310
現場で使える AWS DevOps Agent 活用ノウハウ - Release Management 機能の検証結果を添えて / AWS DevOps Agent Release Management and Know-How
kinunori
5
840
20260724 情シスAI #1 「全従業員をAIネイティブにする」ために情シスがやっていること(公開版)
frtckty
0
150
AI時代の強いチームの作り方
yuukiyo
23
13k
20260608_Codexの可能性_ノンプログラマー向け_大城追記
doradora09
PRO
0
720
「待ち時間」の消滅と「自我消耗」の加速:生成AI時代のエンジニアを救うメンタル・リソース管理
poropinai1966
0
400
組織にどうSREを根付かせるか?〜IVRyの場合〜
abnoumaru
0
240
BigQuery を検索ソースとした AI Agent の作り方って 〇〇 通りあんねん
satohjohn
0
150
MCPをつなげて作る組織横断のAIエージェント基盤
tsubakimoto_s
0
530
AI研修(Day1)【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
3.2k
Featured
See All Featured
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
230
The Cult of Friendly URLs
andyhume
79
7k
Optimizing for Happiness
mojombo
378
71k
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
600
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
190
Optimising Largest Contentful Paint
csswizardry
37
3.9k
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.5k
Six Lessons from altMBA
skipperchong
29
4.4k
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
280
The Art of Programming - Codeland 2020
erikaheidi
57
14k
Transcript
Firestore → Spanner 移⾏ を成功させた段階的移⾏プロセス Shingo Ichijima (@shinichiji)
⾃⼰紹介 • 名前 ◦ 市島 慎吾 (Shingo Ichijima) • 会社
◦ 富⼠ゼロックス (2016/04 ~ 2018/08) ◦ バイセルテクノロジーズ (2018/09 ~ 2019/12) ◦ ラクスル (2020/01 ~ 2023/01) ◦ カウシェ (2023/02 ~ ) • 役割 ◦ Engineering Manager (Backend) • アカウント ◦ X: @shinichiji ◦ GitHub: @a-thug
会社紹介
プロダクト 野菜がもらえる お買い物アプリ
今⽇お話しすること • 🔥 なぜFirestore→Spanner移行が必要だったのか • 🪜 どうやって移行したか • 🌟 移行にあたって幸運だった点
• ⚠ トラブル及び解決策 • 🎉 結果とまとめ 具体の実装例などの詳細はZennの記事で! https://zenn.dev/kauche/articles/1e733da3748ee1
🔥 なぜ移⾏が必要になったのか
🔥 なぜFirestore→Spanner移⾏が必要になったのか 主な課題 • 🏢 事業フェーズの変化 ◦ データモデルが安定してきたため、スキーマレスの必要性が低下 ◦ NoSQLよりもRDBへの経験があるバックエンドエンジニアの⽅が多くなった
• 🐌 Firestore固有の制限 ◦ クエリの制約 ◦ 複雑な検索の困難さ • 💰 コスト問題 ◦ 読み取り/書き込み従量課⾦で費⽤が急増 ◦ 2024年4⽉段階ではFirestoreにCUD(Committed Use Discount)は無かった
なぜ移⾏を決断したのか • ⭕ Firestoreは初期選択として適切だった ◦ サービス開始した2020年当初、Spannerはnode単位でインスタンスを⽴てる必要があり⾼額 だった ◦ 成功するかもサービス⽅向性が定まるかも全く⾒えていない状況下で、当時は運⽤コストも抑 えたかった
• 📊 事業成⻑でコスト問題が深刻化 ◦ 事業ピボットを経て、よりユーザのアクセスが増えるビジネスモデルへと変化した結果、コスト 問題の顕在化がかなり早くなった ◦ 「重要だけど緊急ではない」が「重要かつ緊急」となった • 🎯 コストや各種KPIの伸び⽅を考えると、今ここで着⼿するしかないとなった ◦ キャッシュするなど、⼀時的な対応をしていたが焼け⽯に⽔だった ◦ 根本的な解決が必要なタイミングとなった
🪜 どうやって移⾏したか
どうやって移⾏するか 移行にあたっての制約 • メンテナンスに入れることなく安全に移行したい • 今かかっているコストは早く下げたい • 移行に関する開発作業をやっている間であっても、機能開発は止めたくない 選択肢の⽐較 •
全コレクション⼀気に移⾏ ◦ 移⾏⾃体は短期間で終わるが影響範囲が巨⼤でリスク⼤ ◦ リリースにあたっての予⾏演習やSpannerのウォームアップが必要 • ⭐ コレクション単位で段階的移⾏ ◦ ちょっとずつトラフィックを流していくのでリスクを分散できる ◦ Firestore, SpannerのTransactionが被ったときの扱いが難しい
コレクション単位での段階的移⾏を選んだ理由 段階的移⾏のメリット • 🛡 影響範囲の限定 : 問題が起きても移行対象のコレクションのみ • 📈 段階的な効果実感
: コスト削減を徐々に確認 • 📊 優先順位付けが可能 : 移行効果の高いもの、移行難易度が低いものから着手 • 🔄 ノウハウの蓄積 : 小さく移行を繰り返すことで、不確実性を減らす 優先順位の考え⽅ 1. 読み書きが低頻度 (例: 社内の管理画面からしかアクセスされない) 2. TransactionがSpannerのみで完結できて、移行がしやすい 3. 移行するとコストが大きく下がる 4. ユーザや注文データなど、サービスの根幹に近い
4段階の移⾏プロセス 1. Double Write(両DB書き込み) • FirestoreとSpanner両方に書き込み開始 • 先にFirestoreに書き込み、エラーがなければSpannerにも書き込む 2. データ移行
• 既存データをスクリプトでFirestore→Spannerへ移行 3. Read切り替え • 読み取りをSpannerに切り替え ◦ FirestoreのKey VisualizerでReadがなくなっていることを確認する • 書き込みはFirestore, Spanner両方継続 • 2 → 4は一足飛びで可能といえば可能だが、瞬間的に古いCloud Runインスタンスへのトラフィッ クが残っている場合を考慮し、両方に書き込んでいた 4. Write切り替え • 書き込みをSpannerのみに変更 • これにてコレクションの移行を完了とする
🌟 移行にあたって幸運だった点
🔥 当時(2024年5⽉)のカウシェの技術スタック及びチーム状況 • マイクロサービスとしては3サービス ◦ 最初に作られたECを担当するサービスがFirestoreを使っていた ◦ 残り2サービスは後発で、Spannerを使っていた • バックエンドはGoで書かれており、Cloud
Runでホスティング • バックエンドエンジニアは⾃分含めて4⼈ • 移⾏作業専任として 0.5⼈/⽇ ◦ メインの移行作業は柴田芳樹さん(@yoshiki_shibata) ▪ Go言語 100Tips ▪ Web API設計実践入門 ◦ 改修箇所とオーバーラップしたり、コストの兼ね合いで早く移⾏したいコレクションは別 のメンバーで移⾏したりもあった
移⾏するにあたって幸運だったこと (1) • 切り戻しがしやすい環境だった ◦ Cloud Runでホスティングしていたため、Read切り替えを⾏ってエラーが出ていた場合 は⼀瞬で前のrevisionに切り戻すことができた • 移⾏作業がRepositoryレイヤーだけで済むようなコードベースのアーキテクチャ
になっていた ◦ カウシェのコードベースではクリーンアーキテクチャを採⽤していた ◦ SpannerリポジトリがFirestoreリポジトリを内包し、メソッド単位で段階的に移行できる仕組みを採 用することができた • APIレベルでのE2Eテストがしっかり書かれていた ◦ 振る舞いが変わっておらず、移⾏によるデグレがないことを確認しやすかった ◦ テスト⽤データは正規のAPI経由で作ることが原則で、DB実装に依存する箇所はほぼ無 かったためテストがpassしてるなら問題ないよね、という判断がしやすかった
移⾏するにあたって幸運だったこと (2) • ⼤半の処理が冪等に作られていた ◦ FirestoreとSpannerではclient libraryがtransactionのAbortや競合を検知すると自動でリトライす る ◦ 冪等かどうかを検証するE2Eテストが存在していた
• あまりFirestoreに依存していなかった ◦ コレクションの階層は深くて3階層だったので、NoSQLから乗り換えるにあたって頭を悩 ますべきことが少なかった ◦ 使われ⽅としてもNoSQLをフルに活⽤しているというよりも、RDBライクな使われ⽅をし ていた • Coding Agentの発達 ◦ 移⾏後半になると簡単なコレクションの移⾏作業は型化されて、Coding Agentでもでき るようになった
⚠ トラブル及び解決策
⚠ それでも移⾏中に直⾯したトラブル/課題と解決策 • ⚖ 1つのAPIの処理の中で、トランザクションを2回に分けてコミットしている箇 所があった ◦ 両DBのロールバックが難しい ◦ 特別な制御フローを実装
▪ 1回目のFirestoreトランザクションコミット時はSpannerへのコミットをスキップ ▪ 2回目のFirestoreトランザクションが成功してからSpannerに書き込みを行う • 🔍 Write切り替え後にデータの⽋損が発覚 ◦ ⾃分がCoding Agentでガンガン移⾏させていたコレクションで発覚 ▪ 全て完全に冪等にできていたわけではなかった... ◦ ビジネスロジック側でも冪等性を保つため、処理に使用するいくつかの値をハッシュ化してIDとし て使うことで一意性を担保 ◦ BQに残っているデータをかき集めて突合し、データ復旧
🎉 結果とまとめ
結果:1年間かけたDB移⾏で達成できたこと • 💰 DB費⽤93%削減 ◦ Firestoreと⽐較して⼤幅なコスト削減 ◦ 稼働は0.5⼈/⽇なので、実質半年分の⼯数で出来たとも⾔える • ⚡
パフォーマンス‧開発効率向上 ◦ 複雑なクエリの実⾏時間短縮 ◦ SQLの表現⼒による実装の簡素化 • 📊 分析クエリの効率化 ◦ 外部データセットが使えるのでBigQueryとの連携による効率化 ◦ Extensionsで使われていたCloud Run Functionsも不要になり、そのコストも浮いた
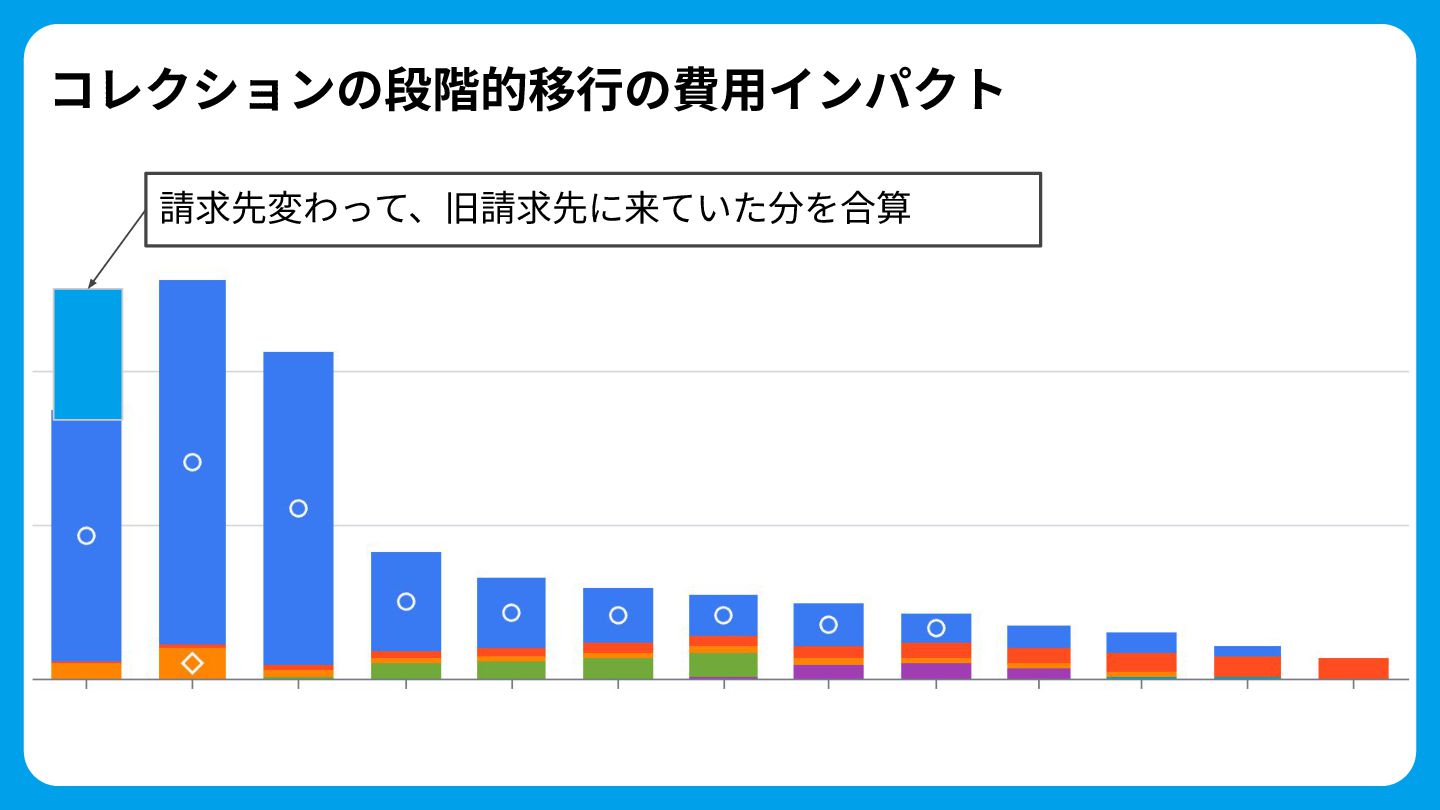
コレクションの段階的移⾏の費⽤インパクト 請求先変わって、旧請求先に来ていた分を合算
重要な学び ⼟台が⼤事! • 今回は移⾏にあたって、幸運な要素が多かった ◦ 切り戻しやすさ ◦ クリーンアーキテクチャによるDBの⼊れ替えやすさ ◦ E2Eテストというガードレール
◦ Firestoreへの依存度⼩ • これらの要素が⽋けていると、困難だった ◦ これらは移⾏を⾒据えたからやっていたわけではなく、インフラの初期選択の良さや開発効率 や品質を上げる取り組みとして根付いていた⽂化だった ◦ 逆に⾔えば脱Firestoreするならこれらをやっておくと良い、ということ ▪ 何かを変える変えないに関わらず、⼟台をちゃんと作っておくのは本当に⼤事
まとめ 今⽇覚えて欲しいこと • 🔄 「重要だけど緊急ではない」は、いきなり「重要かつ緊急」になる ◦ 課題の認識が⼤事 ◦ 重要な問題については、緊急でなくとも⾝構えておく •
🛡 不確実性を無くしていくプロセスでやっていこう ◦ やってみなくちゃ分からないというのは「それはそう」なので、少しずつやって分かる部 分を増やしていく • 🎯 ⼟台が最も⼤事 ◦ アーキテクチャ設計‧テスト‧依存の少なさが成功の鍵 皆さんの移行プロジェクトの参考になれば幸いです!
None
ご静聴ありがとうございました!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}