Generative AI has transformed how we think about building software – but the next major shift is already underway: intelligence is moving out of the cloud and onto our own devices. Across industries such as healthcare, manufacturing, automotive, finance, energy and the public sector, organisations are discovering that cloud-dependent AI cannot meet critical requirements around privacy, latency, reliability, regulation or cost. At the same time, the economics and physics of computation are shifting: local inference reduces operational cost, avoids network round-trips, is dramatically more energy-efficient, and aligns with the natural principle of data gravity – processing data where it is created instead of continuously shipping it elsewhere.
After years shaped by cloud-centric AI from OpenAI, Microsoft, Google and Amazon, the industry is now shifting toward on-device intelligence – powered by hardware from Apple, Qualcomm, Intel, AMD and NVIDIA, and by the corresponding local inference runtimes. Meanwhile, modern Small Language Models, Vision-Language Models, multimodal systems and specialised AI agents have become efficient enough to run locally on servers, desktops, laptops, phones, browsers and even edge hardware – enabled by a new hardware renaissance of GPUs, NPUs, unified memory architectures and optimised runtimes. Local AI is steadily becoming the technical baseline for intelligent, domain-specific applications.
This keynote explores why this shift is happening now – and what it means for developers and architects. Christian will show how local AI delivers fast response times, offline resilience and true data sovereignty; how hybrid local–cloud architectures are evolving to combine on-device intelligence with cloud-scale capabilities; and how lightweight fine-tuning and model adaptation techniques enable teams to specialise models for their own domains, workflows and compliance needs – often directly on their own hardware. He also highlights how Local AI brings back model ownership and lifecycle control, allowing teams to treat models as part of their core engineering assets rather than external APIs. The result is AI that finally fits the real-world constraints of vertical industries instead of forcing them to adapt to cloud limitations.
With practical examples, architectural clarity and a forward-looking perspective, Christian presents a grounded vision of the emerging Post-Cloud era of AI – one where intelligence runs where data is created, where systems remain robust even offline, where regulatory demands are met by design, where cost and energy consumption become sustainable, and where developers regain the power to build truly intelligent and sovereign software systems.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![embeddings.search(query) tools=[sql_query, calc] plan → step → step → answer](https://files.speakerdeck.com/presentations/a7dd9ebcbae84e0e8a8b2f5defafae2a/slide_15.jpg){kind=link}
{kind=link}
![# finetune/train_qwen35_toolcalling.py peft_config = LoraConfig( r=16, lora_alpha=32, target_modules=["q_proj", "v_proj"], lora_dropout=0.05,](https://files.speakerdeck.com/presentations/a7dd9ebcbae84e0e8a8b2f5defafae2a/slide_17.jpg){kind=link}
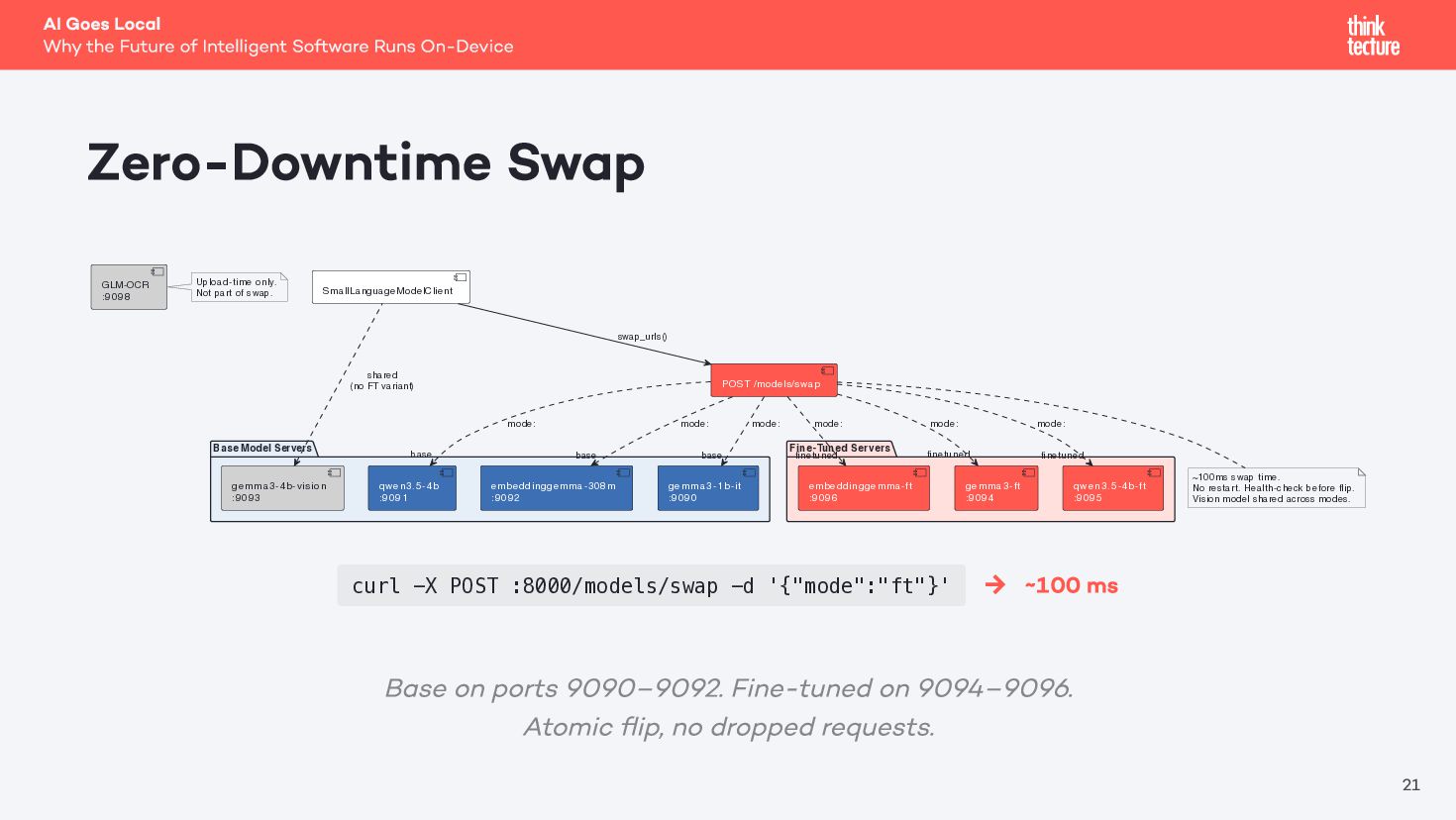{kind=link}
{kind=link}
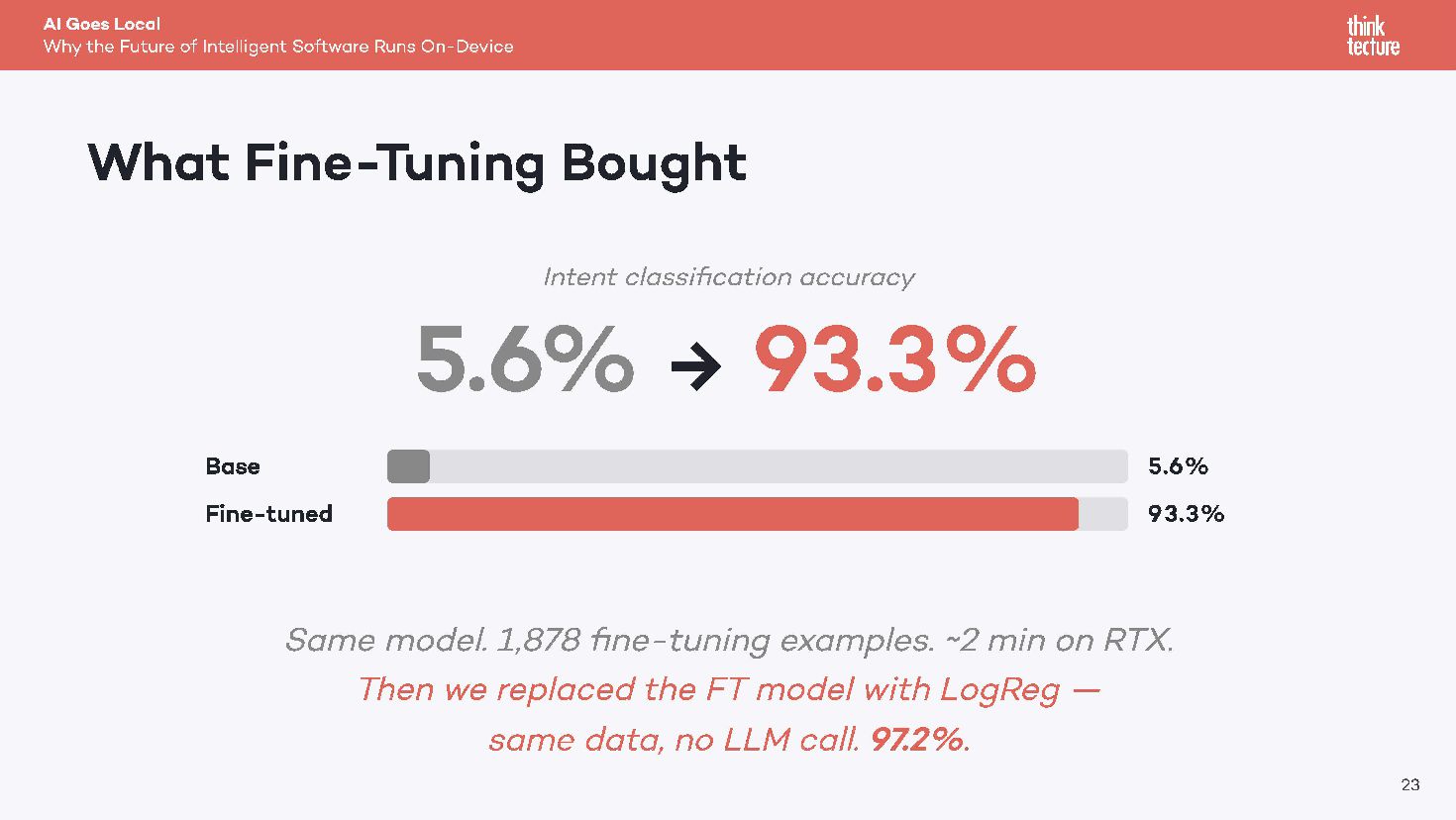{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
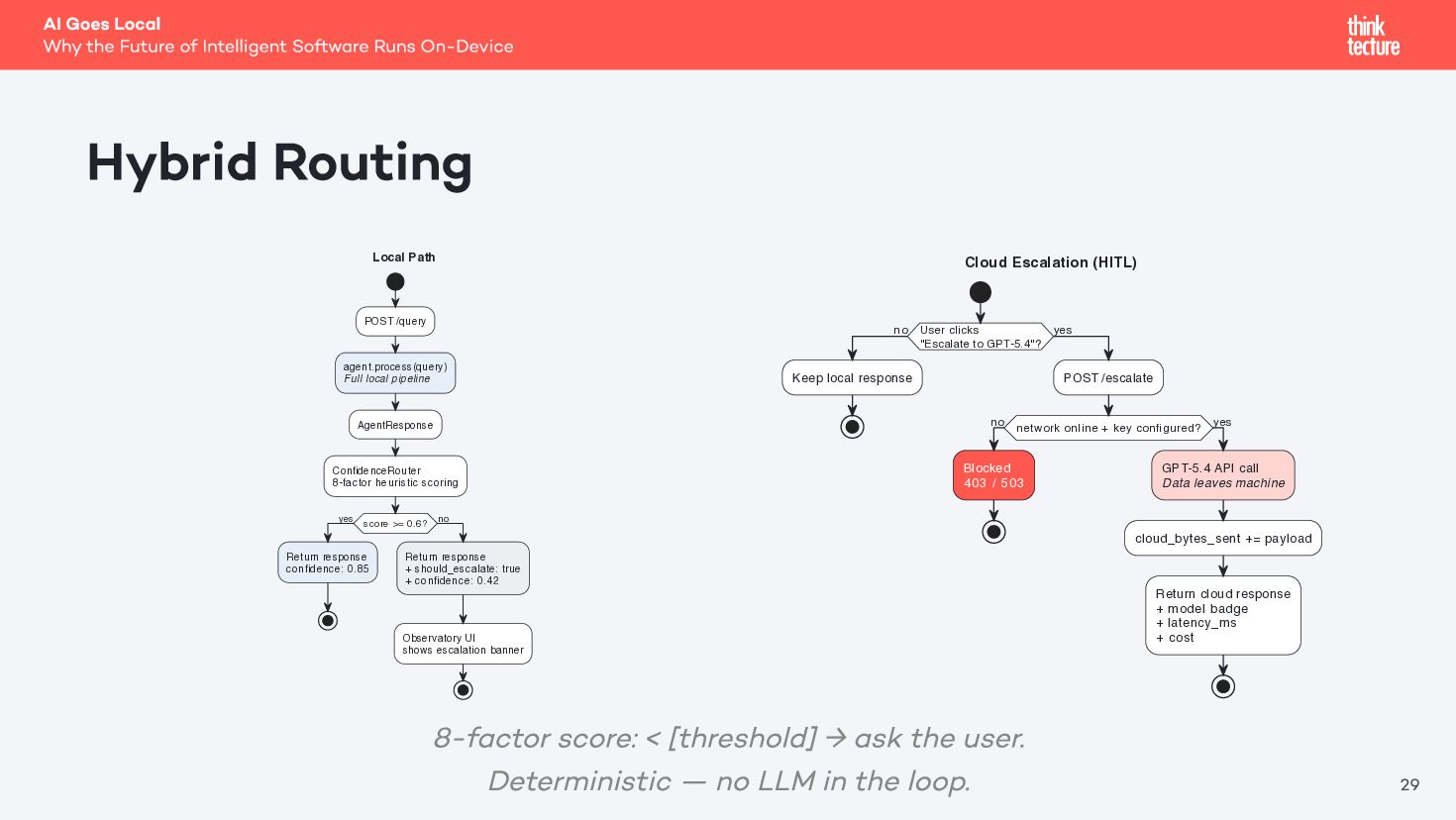{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}