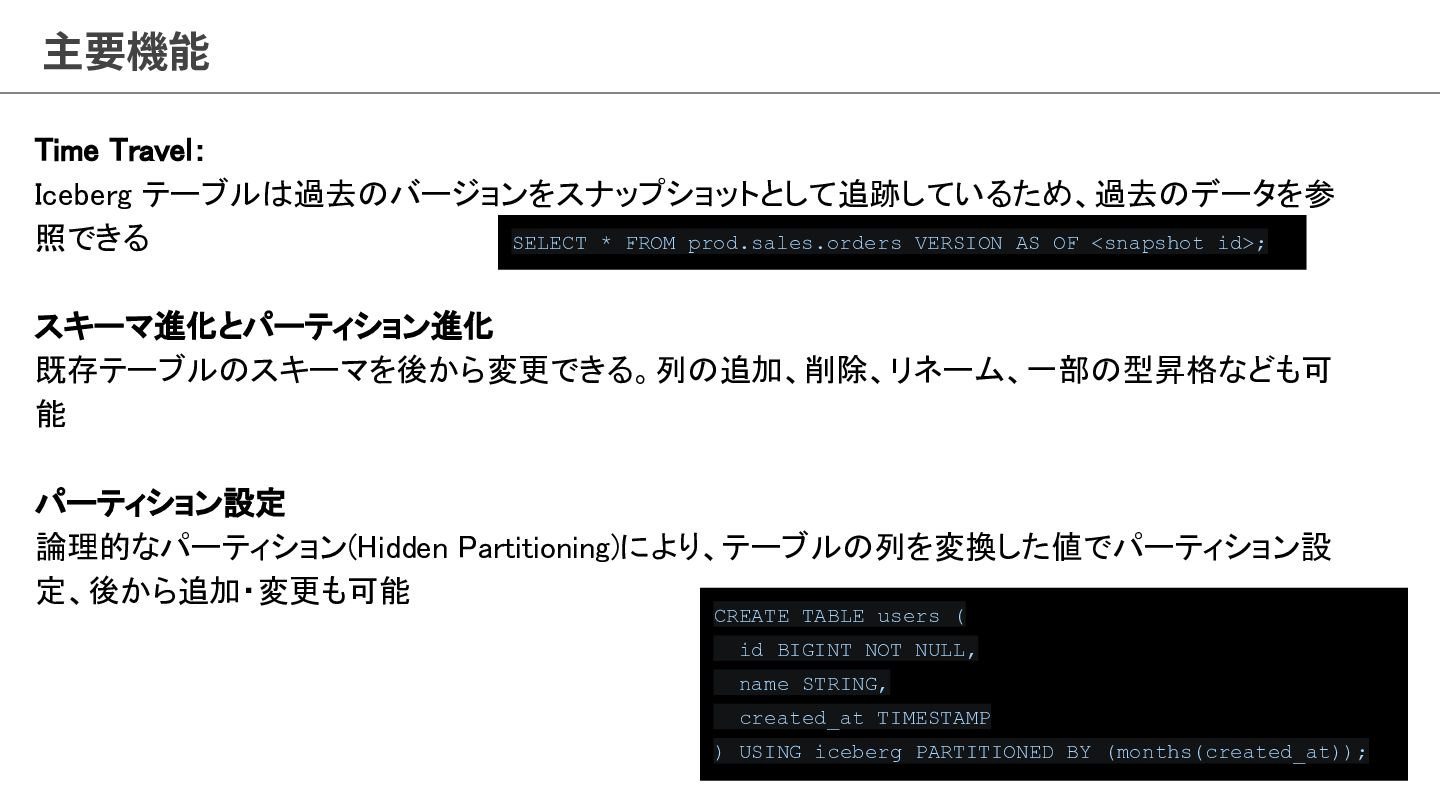
論理的なパーティション(Hidden Partitioning)により、テーブルの列を変換した値でパーティション設 定、後から追加・変更も可能 SELECT * FROM prod.sales.orders VERSION AS OF <snapshot id>; CREATE TABLE users ( id BIGINT NOT NULL, name STRING, created_at TIMESTAMP ) USING iceberg PARTITIONED BY (months(created_at));
{kind=link}
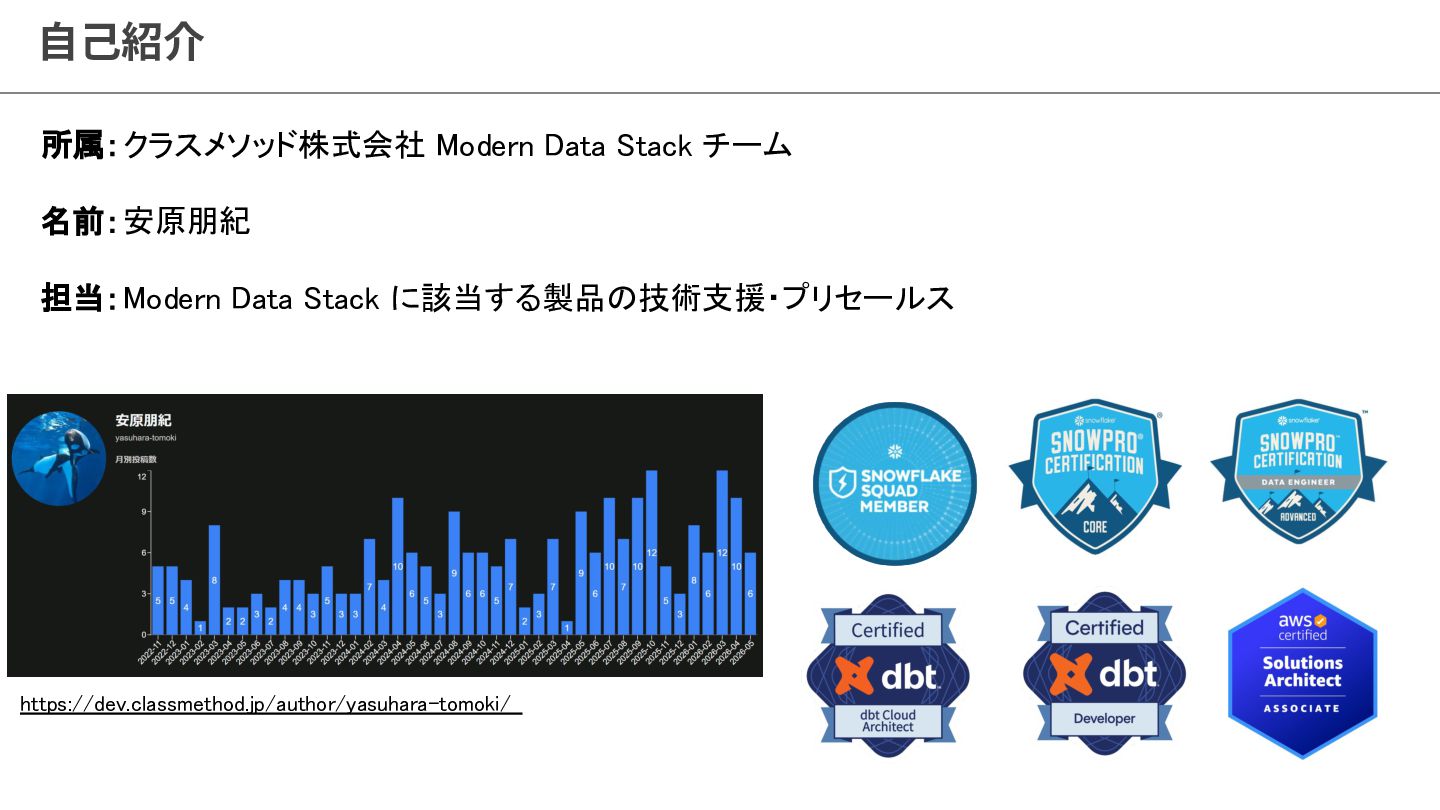{kind=link}
{kind=link}
{kind=link}
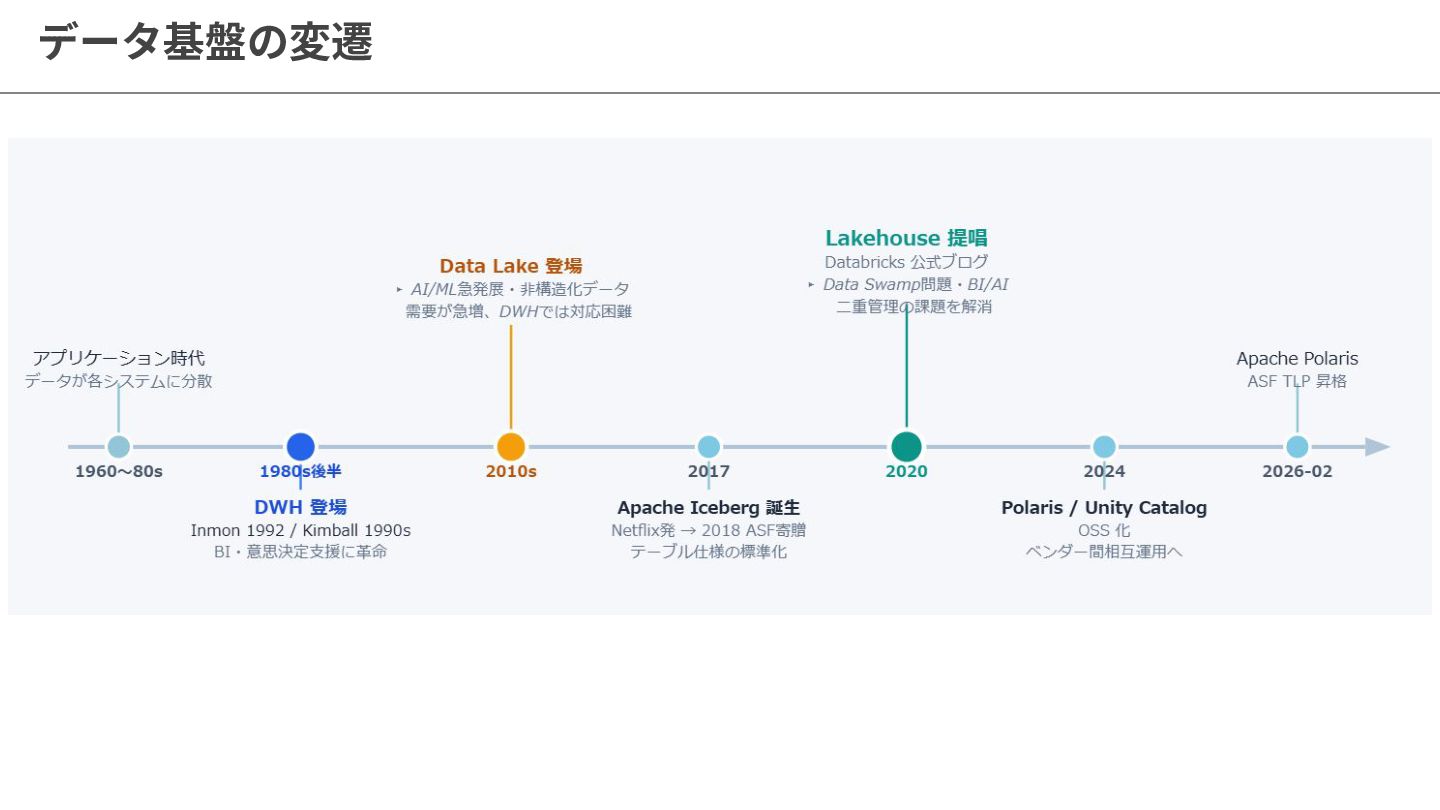{kind=link}
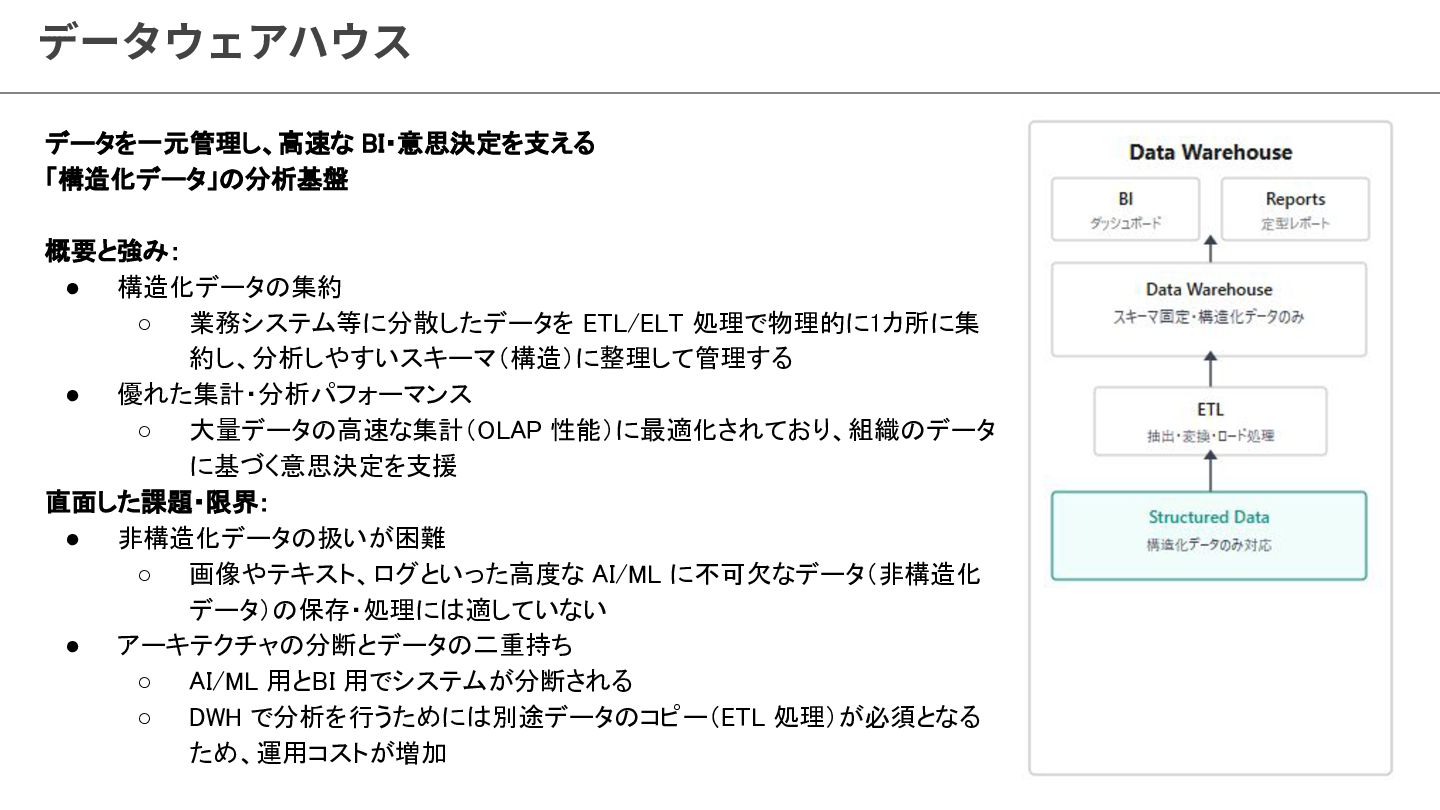{kind=link}
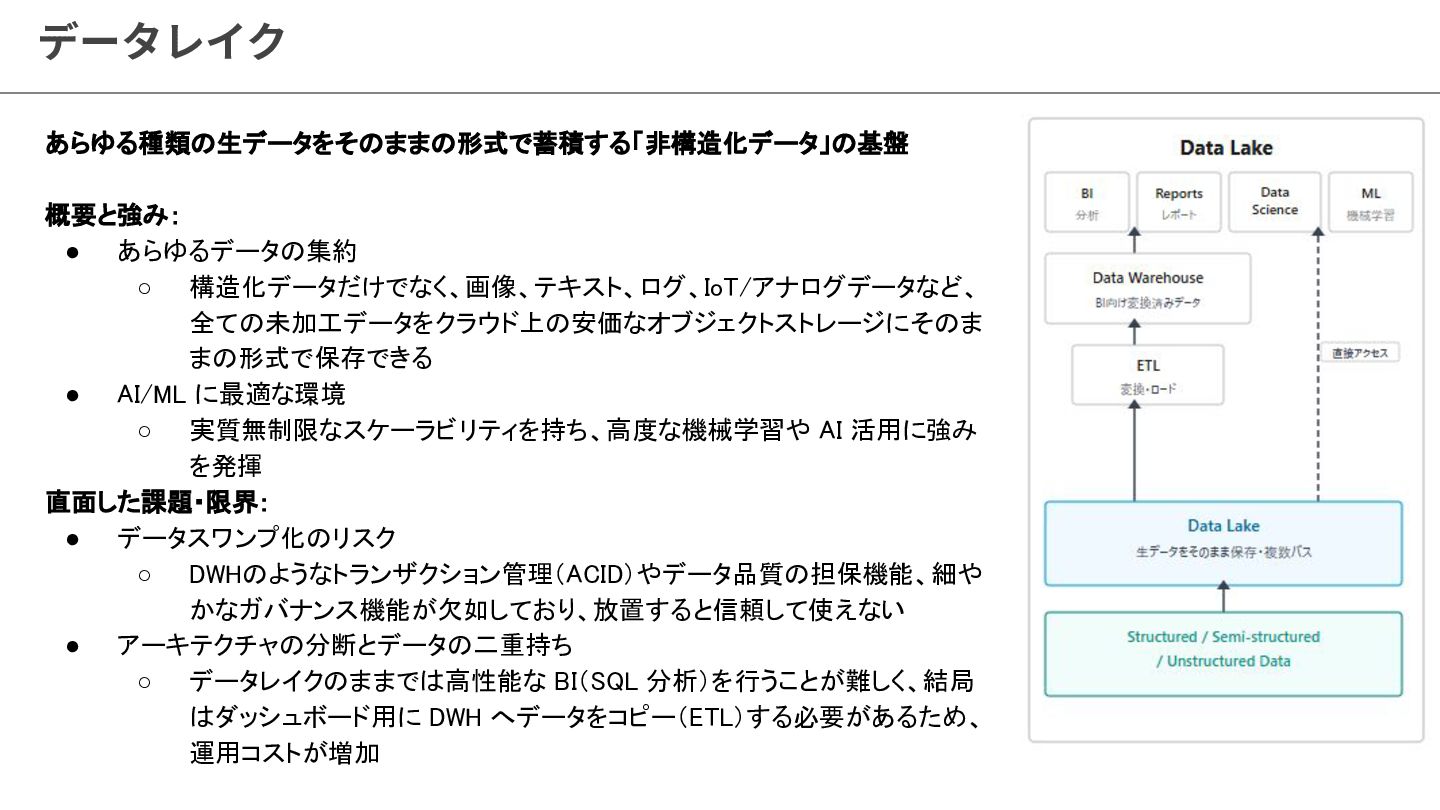{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
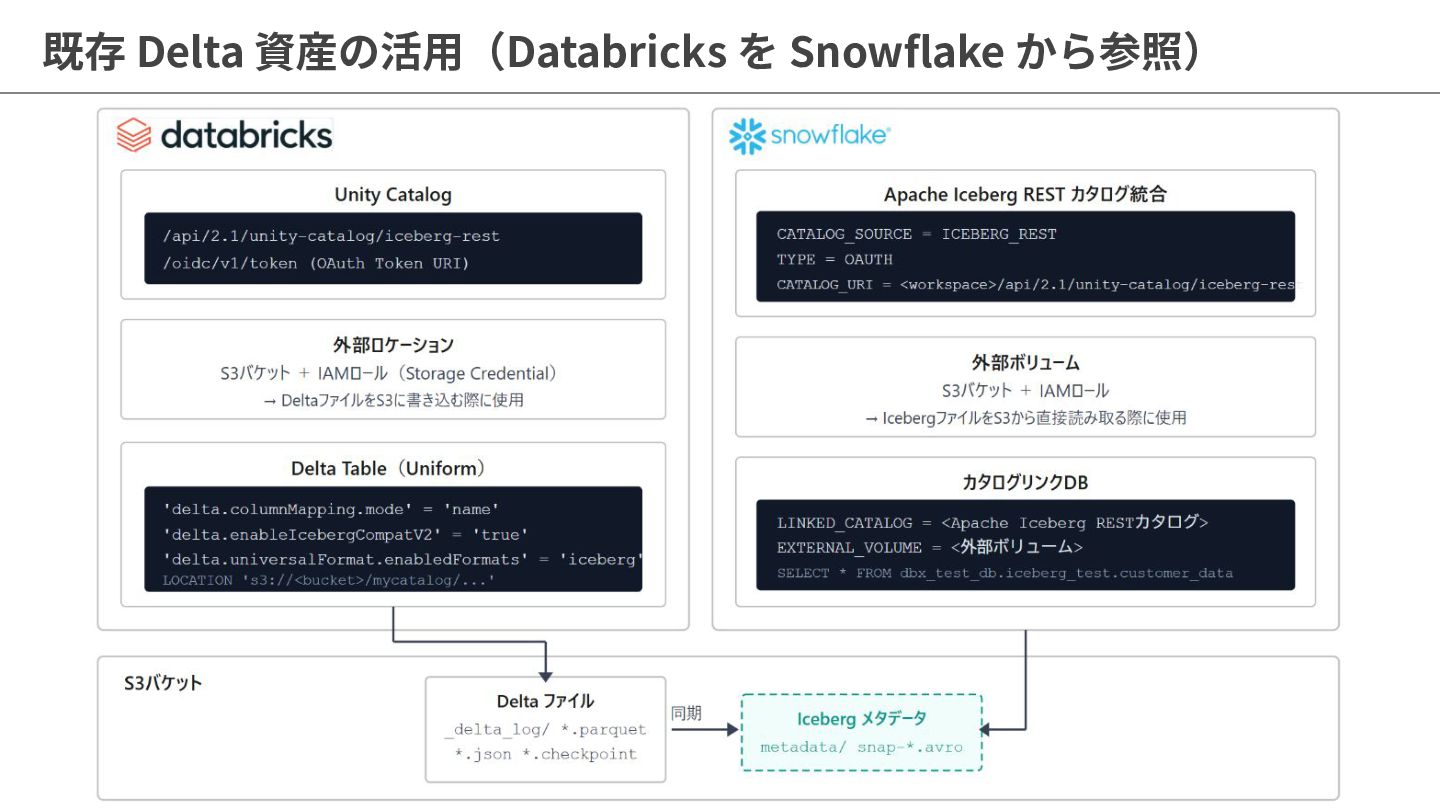{kind=link}
{kind=link}
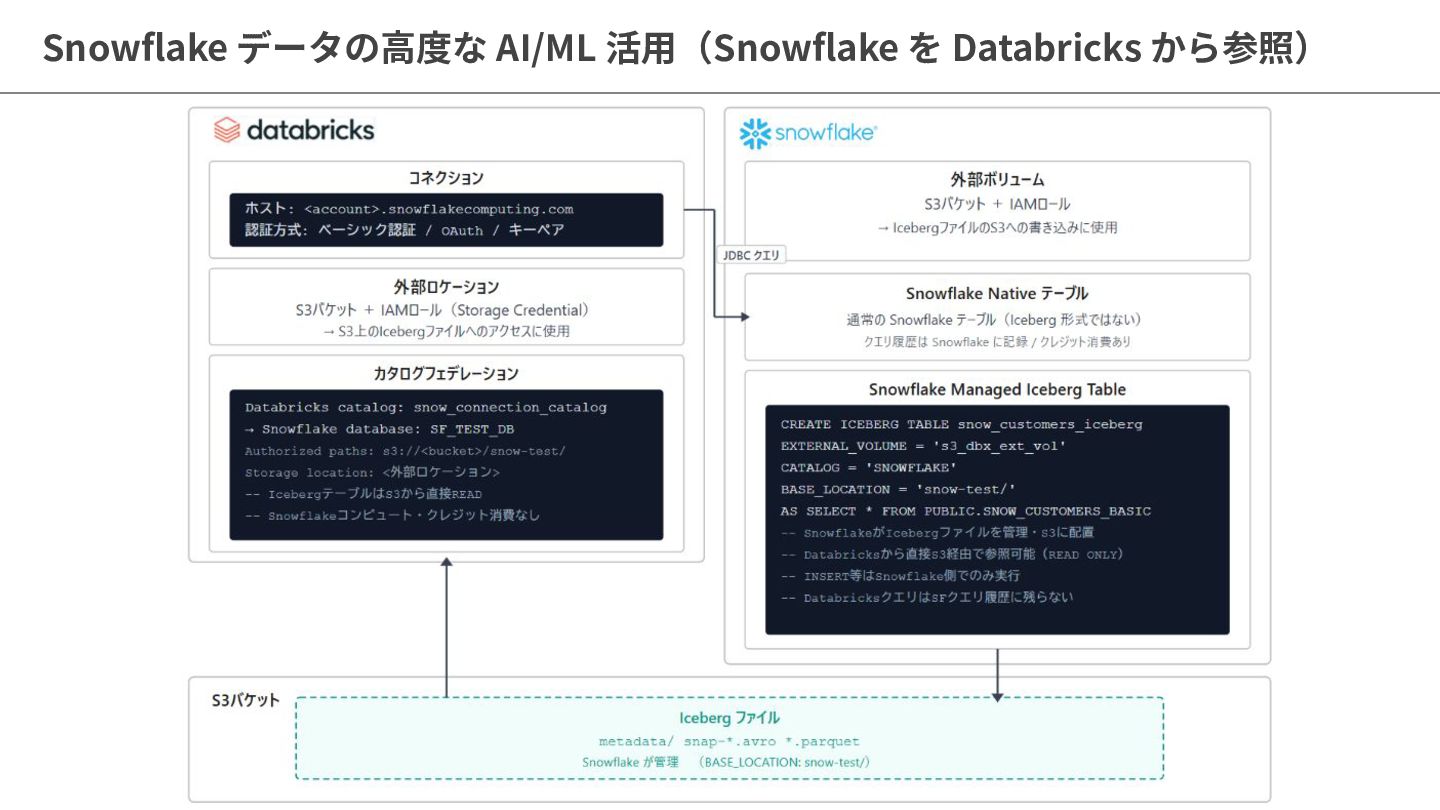{kind=link}
{kind=link}
{kind=link}
{kind=link}
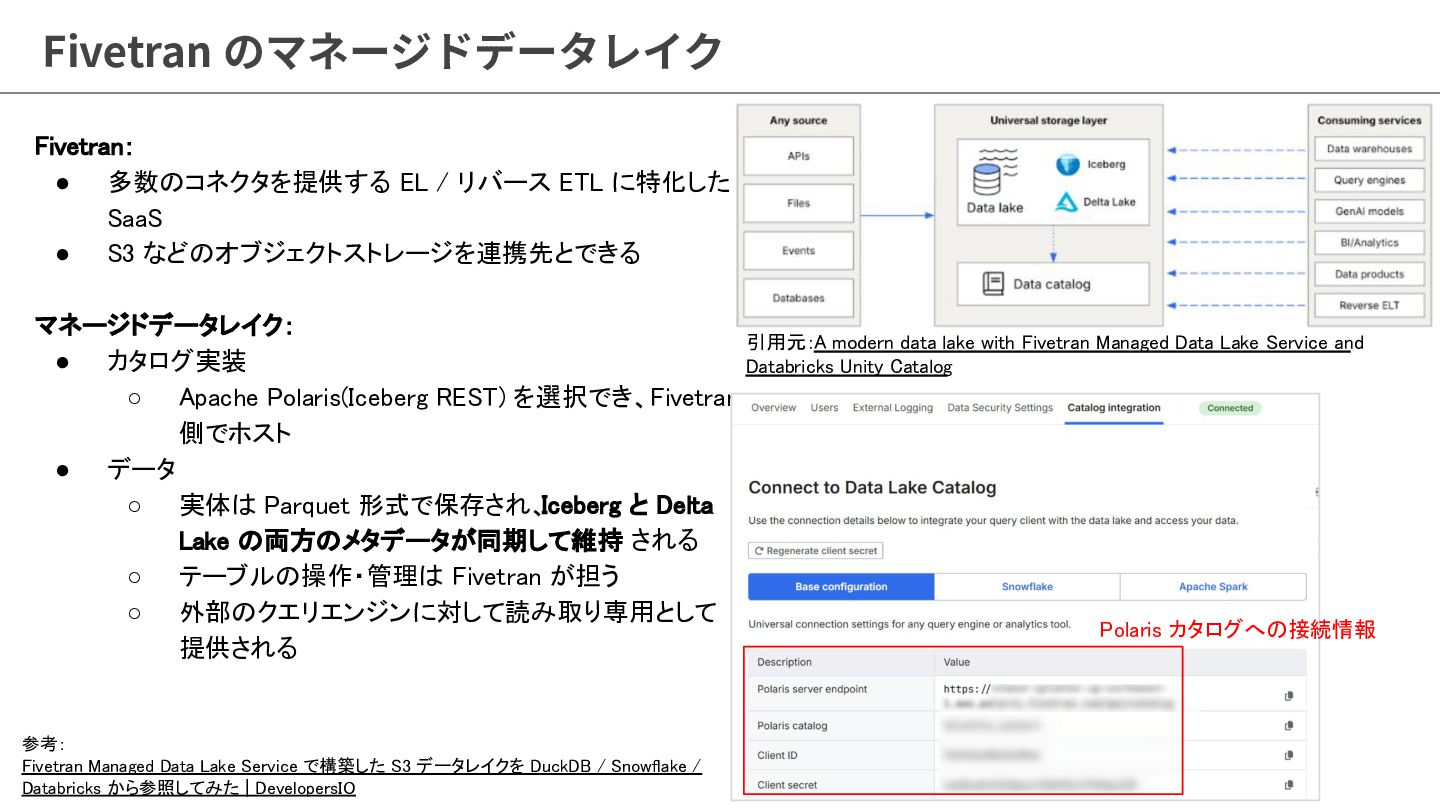{kind=link}
{kind=link}
{kind=link}
{kind=link}