Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
LightGBMを理解しようとするLT
Search
daidesukedonanika
June 15, 2019
Technology
1.5k
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
LightGBMを理解しようとするLT
daidesukedonanika
June 15, 2019
More Decks by daidesukedonanika
See All by daidesukedonanika
モダンデータアーキテクチャ~ウィッシュじゃないよデータメッシュ~
daidesukedonanika
0
2.4k
XGBoostを数式で理解しようとするLT
daidesukedonanika
1
2.1k
Other Decks in Technology
See All in Technology
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
2
400
AI時代の開発生産性は、個人技からチーム設計へ
moongift
PRO
4
2.4k
2年前に削除したPHPクラスが、 ある日突然決済をエラーにした
ykagano
1
300
「AIに依存している」と 「AIを使いこなしている」の違い
k8yasuma
0
120
そのドキュメント、自動化しませんか?
yuksew
1
300
ファミコンでPHPを動かす / PHP on the Famicom
tomzoh
2
430
AIレビューはどこまで任せられるのか?自動化と人が背負うレビューの境界
sansantech
PRO
3
1.1k
End-to-Endで考える信頼性 — LINEアプリにおける クライアント開発×SRE連携の実践
maruloop
4
4.6k
Network Firewallやっていき!
news_it_enj
0
170
CIで使うClaude
iwatatomoya
0
290
誤解だらけの開発生産性 / Myths and Misconceptions about Developer Productivity
i35_267
2
810
しくみを学んで使いこなそう GitHub Copilot app
torumakabe
2
290
Featured
See All Featured
Faster Mobile Websites
deanohume
310
32k
Producing Creativity
orderedlist
PRO
348
40k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
1
390
Building AI with AI
inesmontani
PRO
1
1.1k
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
280
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
220
Documentation Writing (for coders)
carmenintech
77
5.4k
Accessibility Awareness
sabderemane
1
160
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
390
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
320
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
Transcript
© 2019 Chura DATA inc. PROPRIETARY & CONFIDENTIAL. LightGBMを数式で理解しよう とするLT
発表者 兼城大(見習いデータサイエンティスト)
早速ですが質問です (1)XGBoostまたはLightGBMを使ったことある人 (2)XGBoostまたはLightGBMのアルゴリズムを説明できる人 (3)XGBoostからLightGBMのアルゴリズムを説明できる人 (繋がりが見えてくると理解が深まる) © 2019 Chura DATA inc.
PROPRIETARY & CONFIDENTIAL.
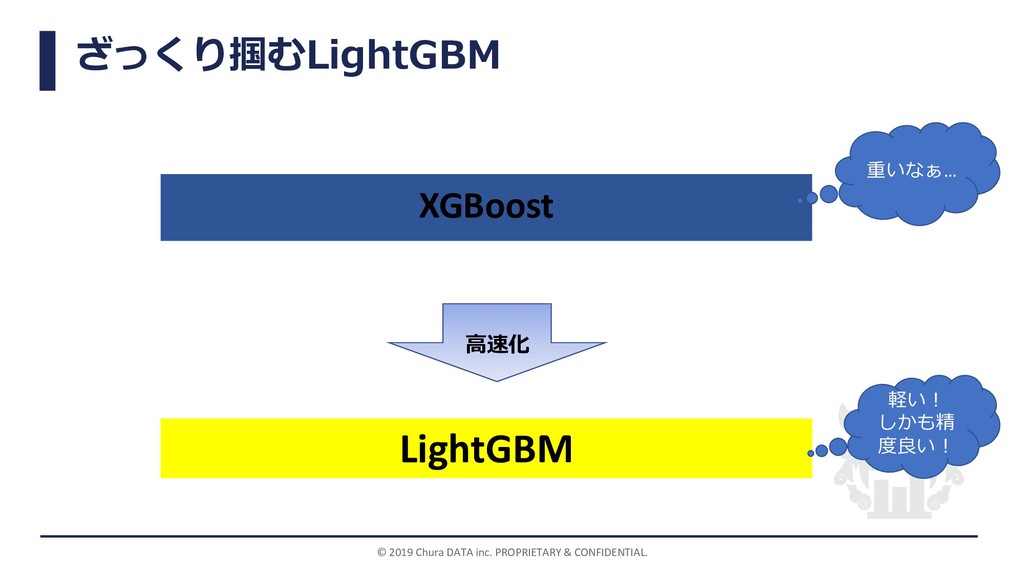
ざっくり掴むLightGBM © 2019 Chura DATA inc. PROPRIETARY & CONFIDENTIAL. XGBoost
LightGBM 重いなぁ… 軽い! しかも精 度良い! 高速化
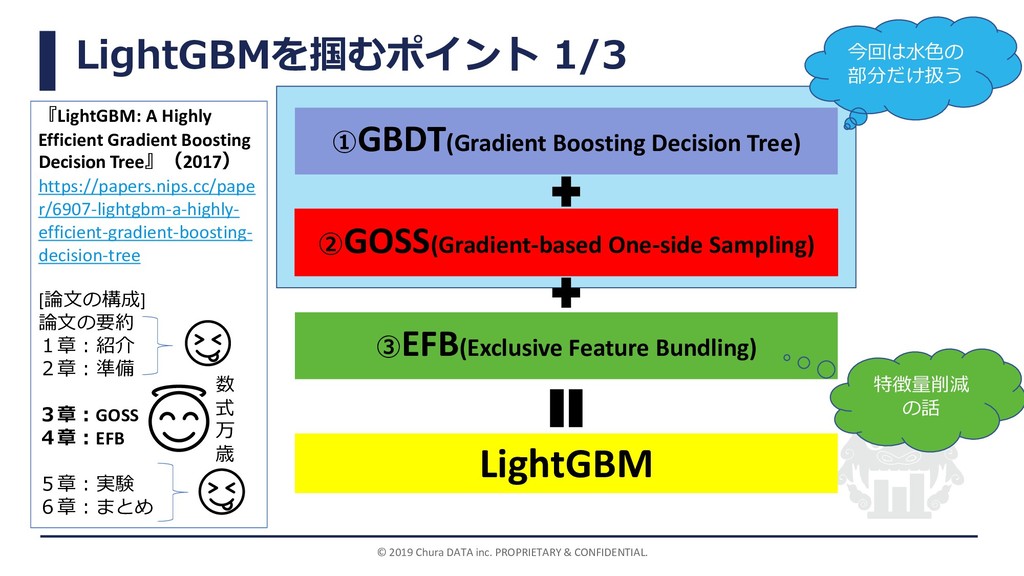
LightGBMを掴むポイント 1/3 © 2019 Chura DATA inc. PROPRIETARY & CONFIDENTIAL.
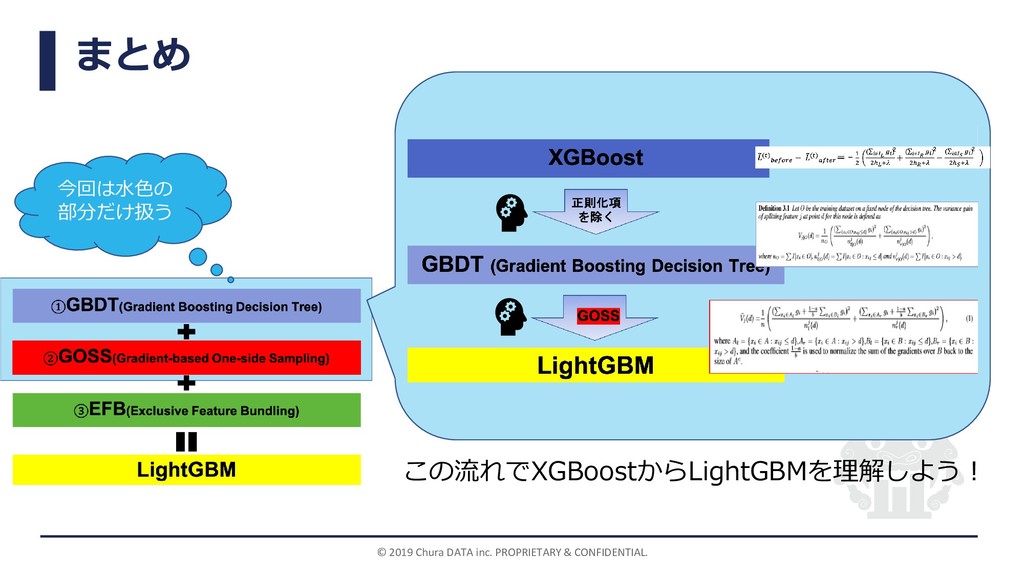
①GBDT(Gradient Boosting Decision Tree) LightGBM ②GOSS(Gradient-based One-side Sampling) ③EFB(Exclusive Feature Bundling) 今回は水色の 部分だけ扱う 『LightGBM: A Highly Efficient Gradient Boosting Decision Tree』(2017) https://papers.nips.cc/pape r/6907-lightgbm-a-highly- efficient-gradient-boosting- decision-tree [論文の構成] 論文の要約 1章:紹介 2章:準備 3章:GOSS 4章:EFB 5章:実験 6章:まとめ 数 式 万 歳 特徴量削減 の話
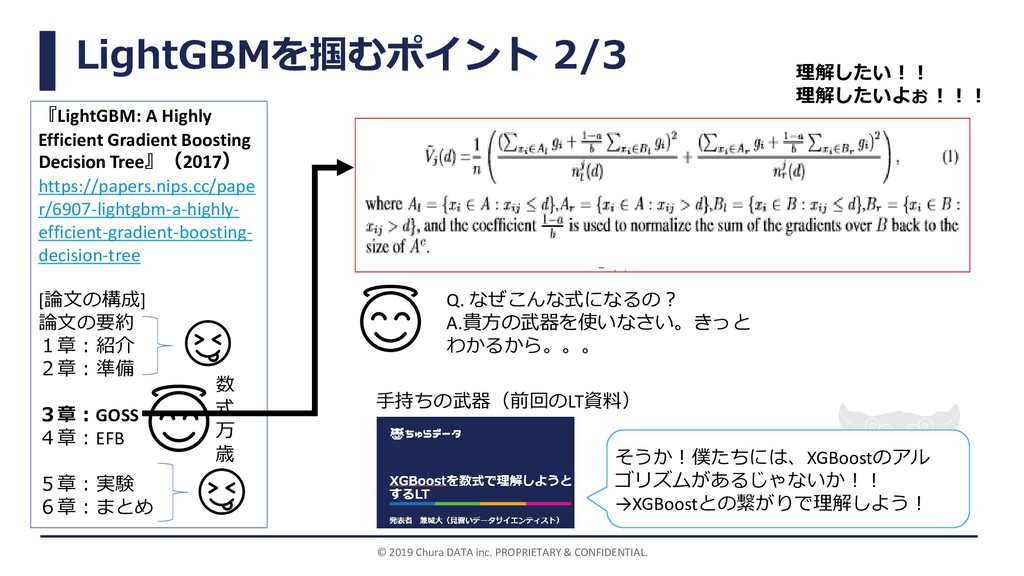
LightGBMを掴むポイント 2/3 © 2019 Chura DATA inc. PROPRIETARY & CONFIDENTIAL.
『LightGBM: A Highly Efficient Gradient Boosting Decision Tree』(2017) https://papers.nips.cc/pape r/6907-lightgbm-a-highly- efficient-gradient-boosting- decision-tree [論文の構成] 論文の要約 1章:紹介 2章:準備 3章:GOSS 4章:EFB 5章:実験 6章:まとめ 数 式 万 歳 Q. なぜこんな式になるの? A.貴方の武器を使いなさい。きっと わかるから。。。 手持ちの武器(前回のLT資料) そうか!僕たちには、XGBoostのアル ゴリズムがあるじゃないか!! →XGBoostとの繋がりで理解しよう! 理解したい!! 理解したいよぉ!!!
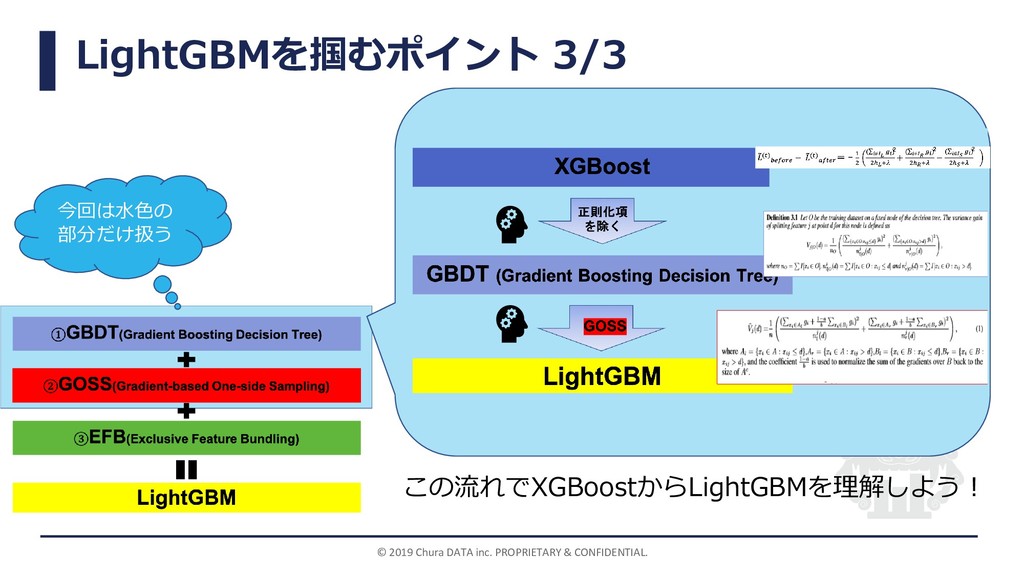
LightGBMを掴むポイント 3/3 © 2019 Chura DATA inc. PROPRIETARY & CONFIDENTIAL.
この流れでXGBoostからLightGBMを理解しよう! 今回は水色の 部分だけ扱う
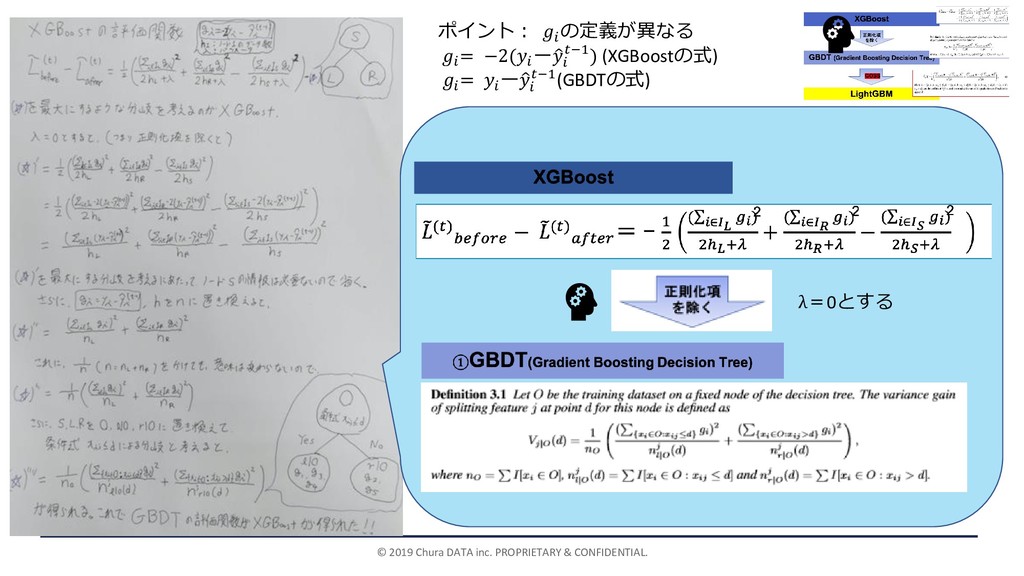
© 2019 Chura DATA inc. PROPRIETARY & CONFIDENTIAL. λ=0とする ポイント:
の定義が異なる = −2( ーො −1) (XGBoostの式) = ーො −1(GBDTの式)
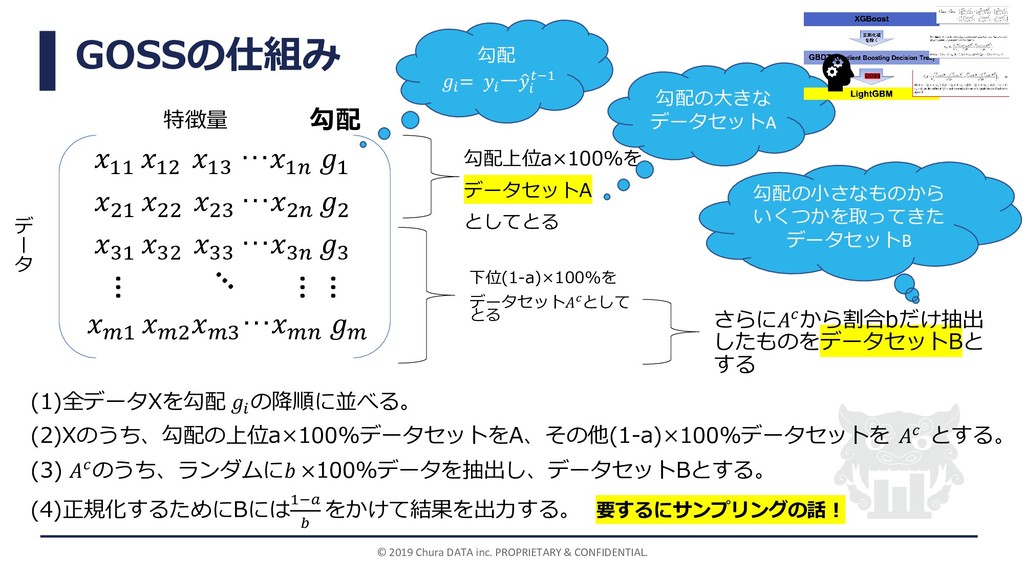
GOSSの仕組み 11 12 13 …1 1 21 22 23 …2
2 31 32 33 …3 3 © 2019 Chura DATA inc. PROPRIETARY & CONFIDENTIAL. … 1 2 3 … … … (1)全データXを勾配 の降順に並べる。 (2)Xのうち、勾配の上位a×100%データセットをA、その他(1-a)×100%データセットを とする。 (3) のうち、ランダムに ×100%データを抽出し、データセットBとする。 (4)正規化するためにBには1− をかけて結果を出力する。 勾配上位a×100%を データセットA としてとる 下位(1-a)×100%を データセットとして とる 勾配 特徴量 デ ー タ さらにから割合bだけ抽出 したものをデータセットBと する 勾配の大きな データセットA 勾配の小さなものから いくつかを取ってきた データセットB 勾配 = ーො −1 要するにサンプリングの話!
© 2019 Chura DATA inc. PROPRIETARY & CONFIDENTIAL. 勾配の小さいデータ セットは少なくサン
プリングする ポイント: 出力に対する係数 Aはそのまま、Bには1− をかける
まとめ © 2019 Chura DATA inc. PROPRIETARY & CONFIDENTIAL. この流れでXGBoostからLightGBMを理解しよう!
今回は水色の 部分だけ扱う
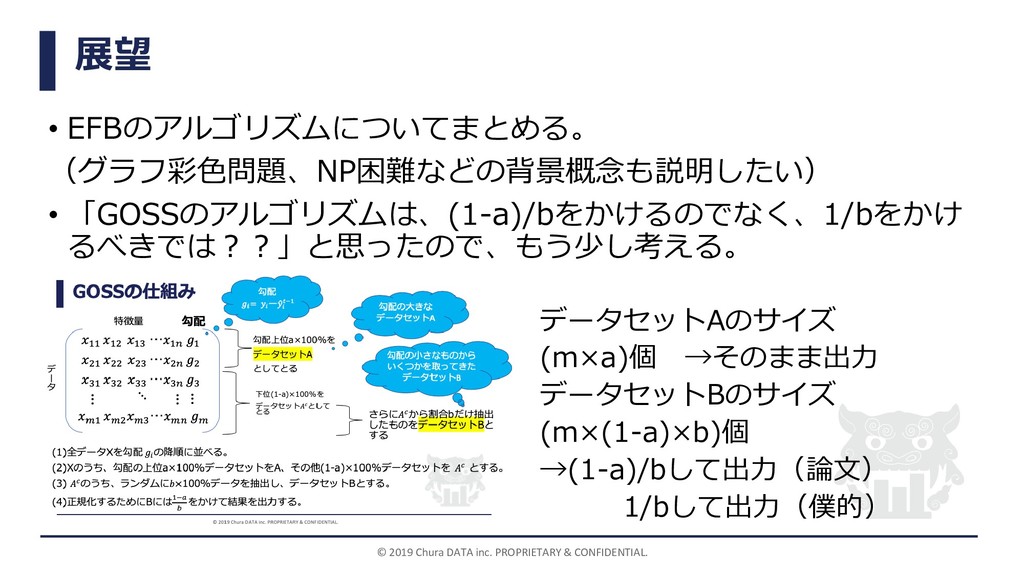
展望 • EFBのアルゴリズムについてまとめる。 (グラフ彩色問題、NP困難などの背景概念も説明したい) • 「GOSSのアルゴリズムは、(1-a)/bをかけるのでなく、1/bをかけ るべきでは??」と思ったので、もう少し考える。 © 2019 Chura
DATA inc. PROPRIETARY & CONFIDENTIAL. データセットAのサイズ (m×a)個 →そのまま出力 データセットBのサイズ (m×(1-a)×b)個 →(1-a)/bして出力(論文) 1/bして出力(僕的)
主な参考・引用文献 『LightGBM:A Highly Efficient Gradient Boosting Decision Tree』 Year :2017
Authors:Guolin Ke, Qi Meng , Thomas Finley , Taifeng Wang, Wei Chen, Weidong Ma , Qiwei Ye , Tie-Yan Liu https://papers.nips.cc/paper/6907-lightgbm-a-highly-efficient- gradient-boosting-decision-tree © 2019 Chura DATA inc. PROPRIETARY & CONFIDENTIAL.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}