You’re not alone when it comes to certain challenges with your Elasticsearch deployment. Come learn about solutions to some of the most common issues our users face from a few of our support engineers. You’ll be sure to leave with learnings you can apply to our own clusters when you get home!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
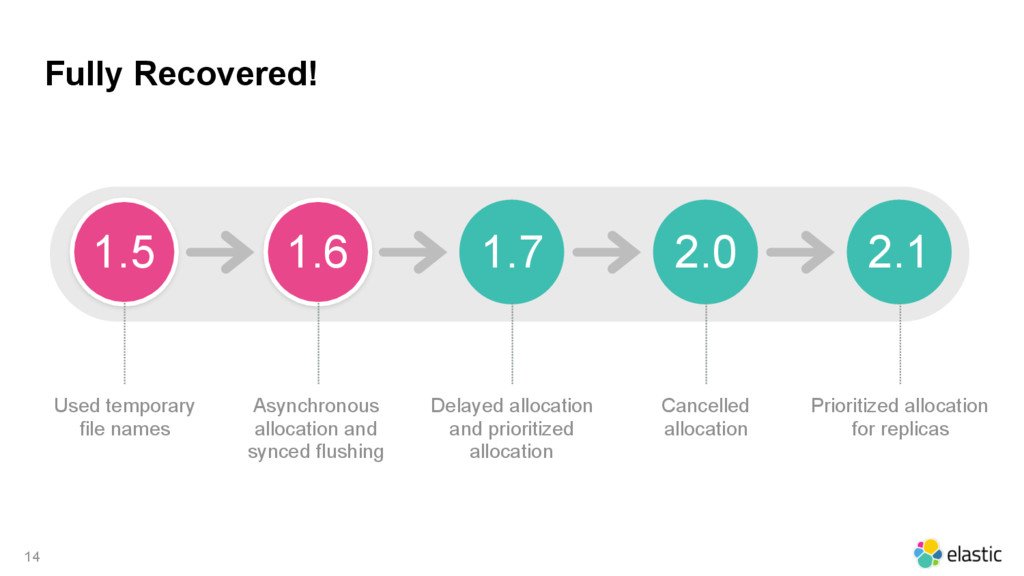{kind=link}
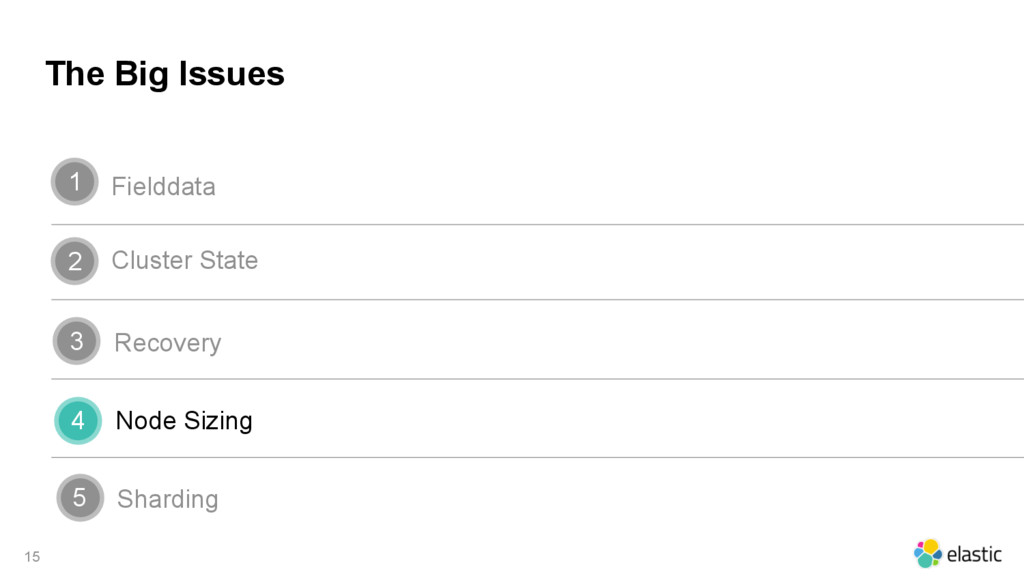{kind=link}
{kind=link}
{kind=link}
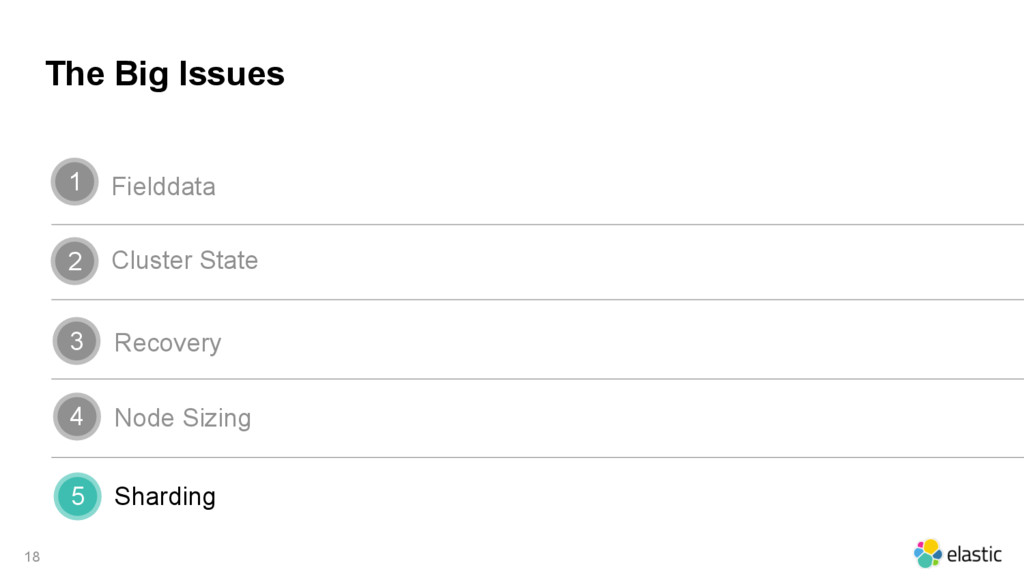{kind=link}
{kind=link}
{kind=link}
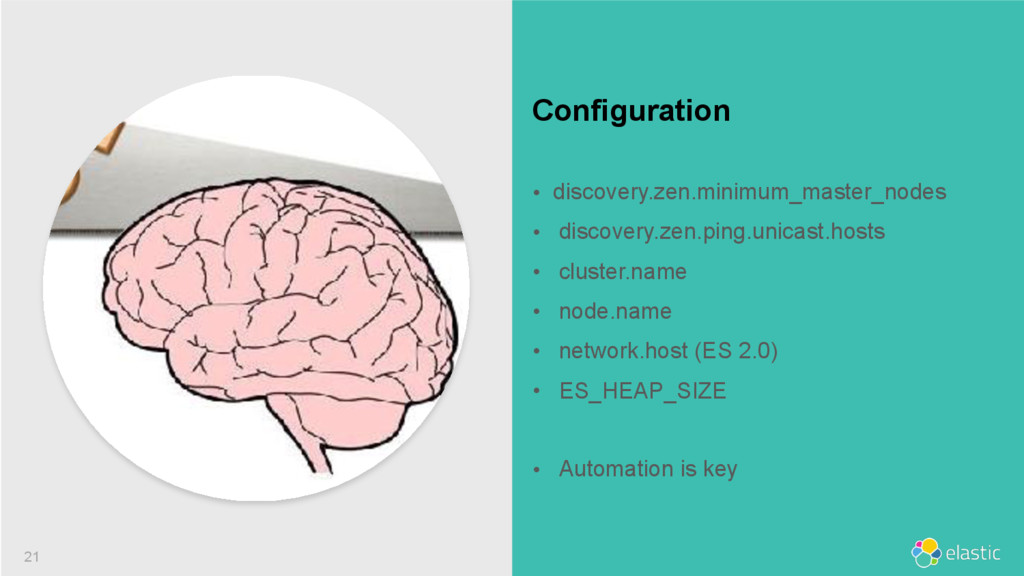{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}