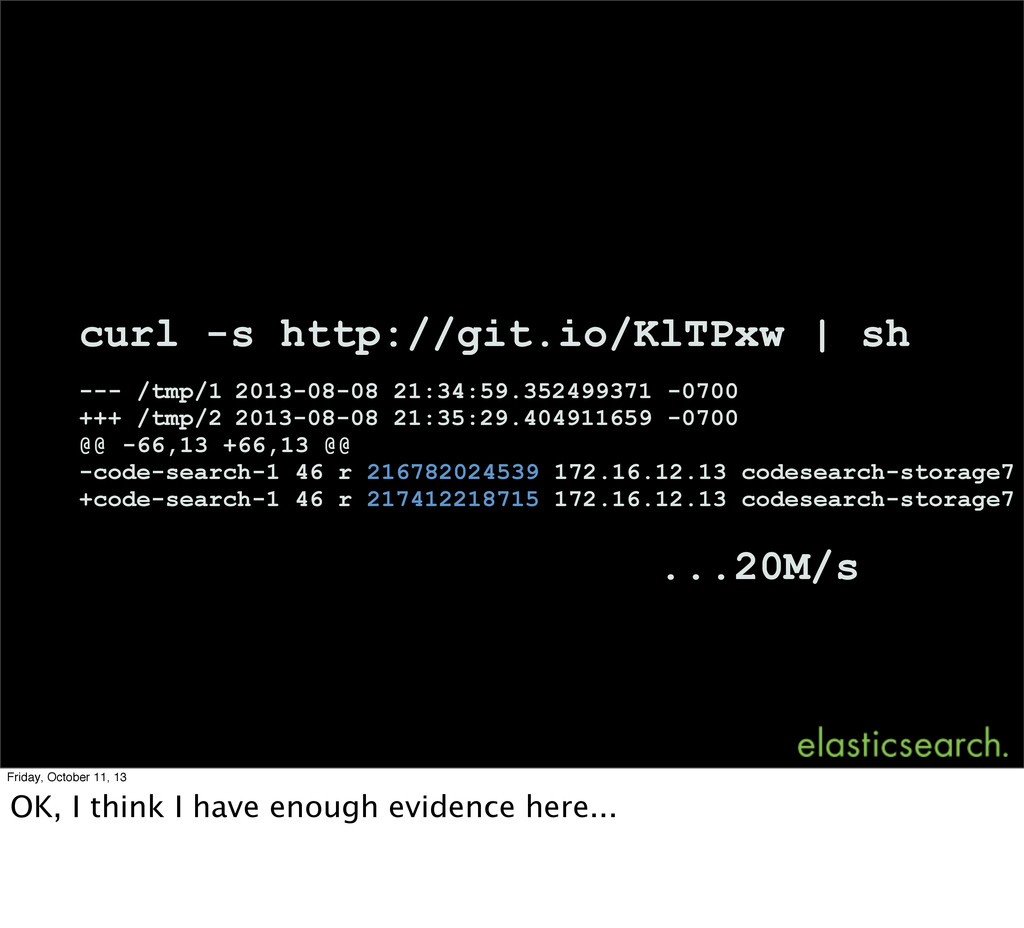
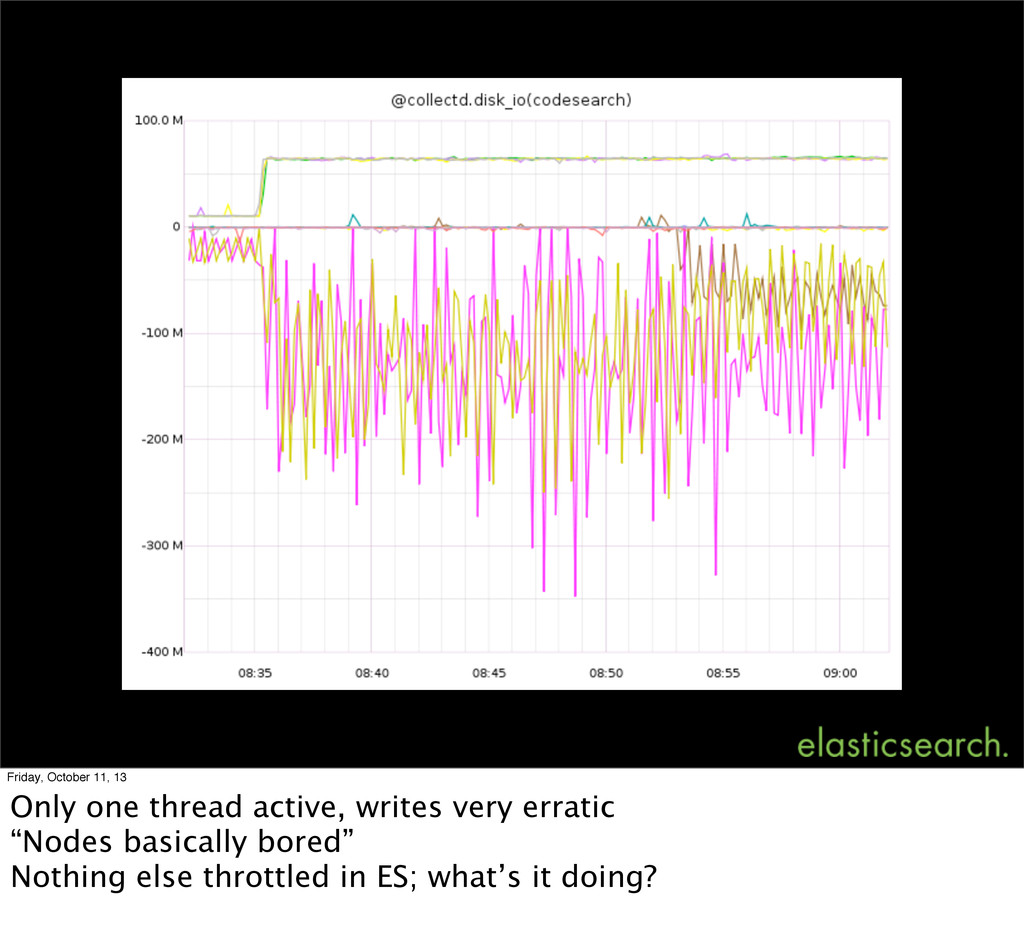
0.90.3 The shard sizes are ~100GB on average, and it is taking an obscenely long time to recover shards on the nodes we have restarted. The restart took place roughly 45 minutes ago, and not a single shard has fully recovered yet. The load on the machines is minimal as is disk IO and network IO. We've bumped the node_concurrent_recoveries to 6. But how long should this take? #1004 Tim Pease, 8 Aug 2013 Friday, October 11, 13
sector ID Designed to most efficiently use rotational media and for multi-user systems, unlike db server * Why is this useless here? (SSD (plus RAID!))
by sector ID Designed to most efficiently use rotational media and for multi-user systems, unlike db server * Why is this useless here? (SSD (plus RAID!))
access by sector ID Designed to most efficiently use rotational media and for multi-user systems, unlike db server * Why is this useless here? (SSD (plus RAID!))
Reorders access by sector ID Designed to most efficiently use rotational media and for multi-user systems, unlike db server * Why is this useless here? (SSD (plus RAID!))
Do it tonight. You cannot make engineering decisions without it. Translates “hrm, this is taking forever” to *action* We’re working on helping you here.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}