Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
LLMでAI-OCR、実際どうなの? / llm_ai_ocr_layerx_bet_ai_d...
Search
sbrf248
July 30, 2025
Technology
10k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
LLMでAI-OCR、実際どうなの? / llm_ai_ocr_layerx_bet_ai_day_lt
sbrf248
July 30, 2025
More Decks by sbrf248
See All by sbrf248
自社開発SaaSバクラクのAI技術とそれに向き合うエンジニアのやりがい / layerx-ai-engineer-dataconference20240601
sbrf248
0
440
バクラクのアノテーション基盤の伸びしろを考えてみた
sbrf248
1
240
Other Decks in Technology
See All in Technology
それでも、技術なブログを書く理由 #kichijojipm / Why I Still Write Tech Blogs Even Now
shinkufencer
0
340
41歳でAWSが好きすぎてITエンジニアになったおっさんの話
yama3133
1
740
仕様駆動開発、導入半年。「本当に速くなってるの?」にデータで答える / AICon2026_hirakawa
rakus_dev
0
320
2026年のソフトウェア開発を考える(2026/07版) / Agentic Software Engineering 2026-07 Findy Edition
twada
PRO
25
10k
アップデートで何が変わった?デモで学んで使いこなすIBM Bob2.0
muehara
0
230
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
Playwright × AI Agent でE2Eテストはどう変わるか AI駆動テストの可能性と実用検証の結果
taiga7543
2
790
JAWS_ICEBERG_BASECAMP
iqbocchi
2
110
ダッシュボード"開発"について 〜使われるダッシュボードのつくりかた〜
kimichan
0
190
AI Native なプロダクト組織の立ち上げ方 : 生産性 100 倍への挑戦
mikesorae
0
1.2k
「顧客の声を聞かなければ何も始まらない」 ── 顧客の声から生まれた『AI返信補助機能』の開発プロセス / AICon2026_shikata_imai
rakus_dev
1
270
キャリアLT会#3
beli68
2
230
Featured
See All Featured
Utilizing Notion as your number one productivity tool
mfonobong
4
450
A designer walks into a library…
pauljervisheath
211
24k
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
310
Joys of Absence: A Defence of Solitary Play
codingconduct
1
420
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2.1k
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
3
360
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
1
410
Leading Effective Engineering Teams in the AI Era
addyosmani
9
2.2k
Designing Powerful Visuals for Engaging Learning
tmiket
1
460
Between Models and Reality
mayunak
4
380
Transcript
© LayerX Inc. LLMでAI-OCR、実際どうなの? バクラク事業部 AI・機械学習部 AI-OCRグループ 伊藤 駿 ITO,
Shun DAY06 topic Deep into AI Speaker
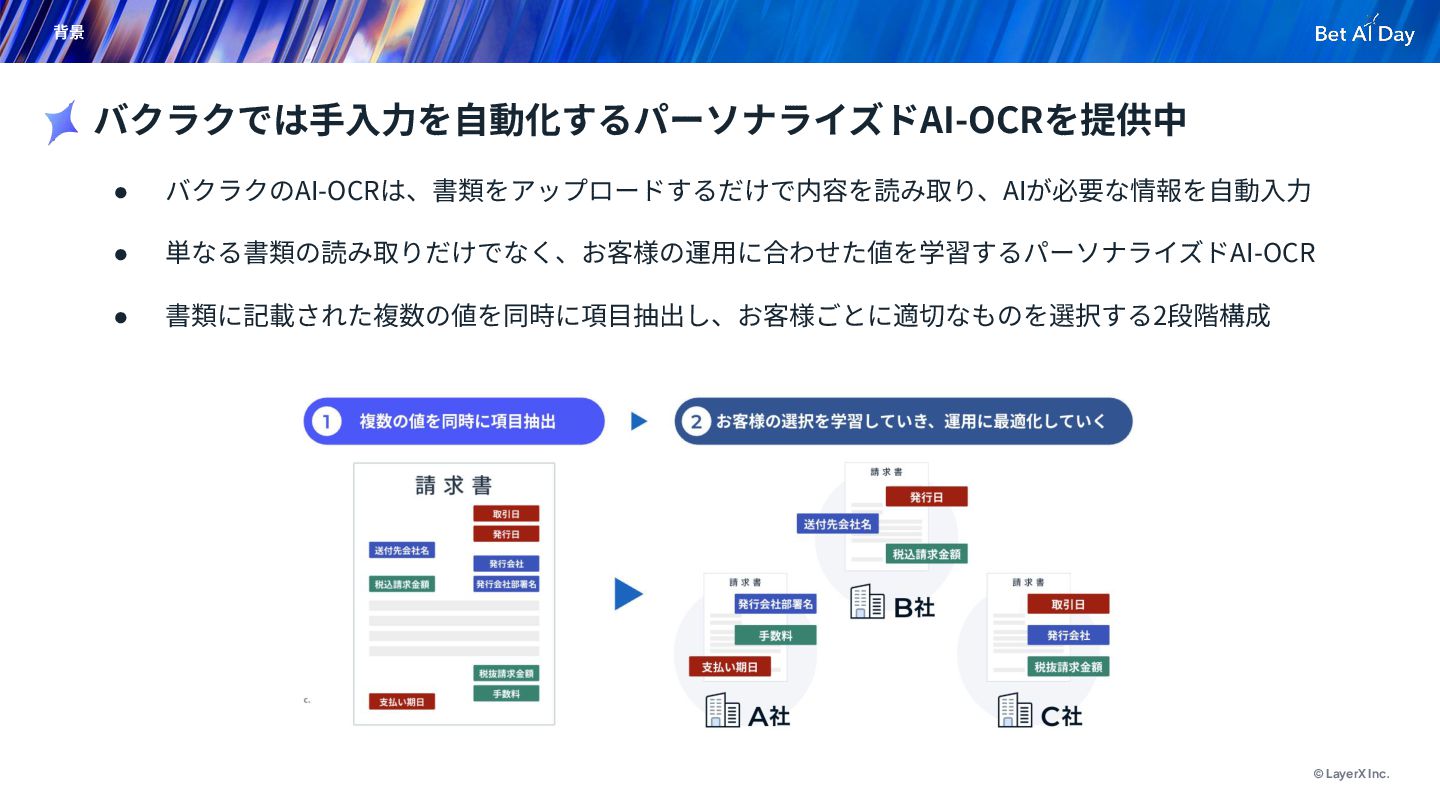
© LayerX Inc. 背景 • バクラクのAI-OCRは、書類をアップロードするだけで内容を読み取り、AIが必要な情報を⾃動⼊⼒ • 単なる書類の読み取りだけでなく、お客様の運⽤に合わせた値を学習するパーソナライズドAI-OCR • 書類に記載された複数の値を同時に項⽬抽出し、お客様ごとに適切なものを選択する2段階構成
バクラクでは⼿⼊⼒を⾃動化するパーソナライズドAI-OCRを提供中
© LayerX Inc. 背景 • パーソナライズドAI-OCRは、LLMではなく⾃社NLPモデル + 推薦モデルで実装 ◦ 問題設定が明確で、⾃社ドメインの⼤量データを使った学習によって
⾼い精度を出せる ◦ In-Context Learningより推薦モデルの⽅がシンプルで解釈しやすい ◦ AI-UX観点での組み込みやすさ、推論速度の速さ • LLMの画像‧⾔語処理能⼒の進歩は著しく、⾼精度なOCRが現実的に ◦ ChatGPTやGeminiなどにレシートを渡すと、⾼精度で内容を 読み取ってくれる Why not LLM? ⼀⽅で、LLMの性能が上がってきているのも事実
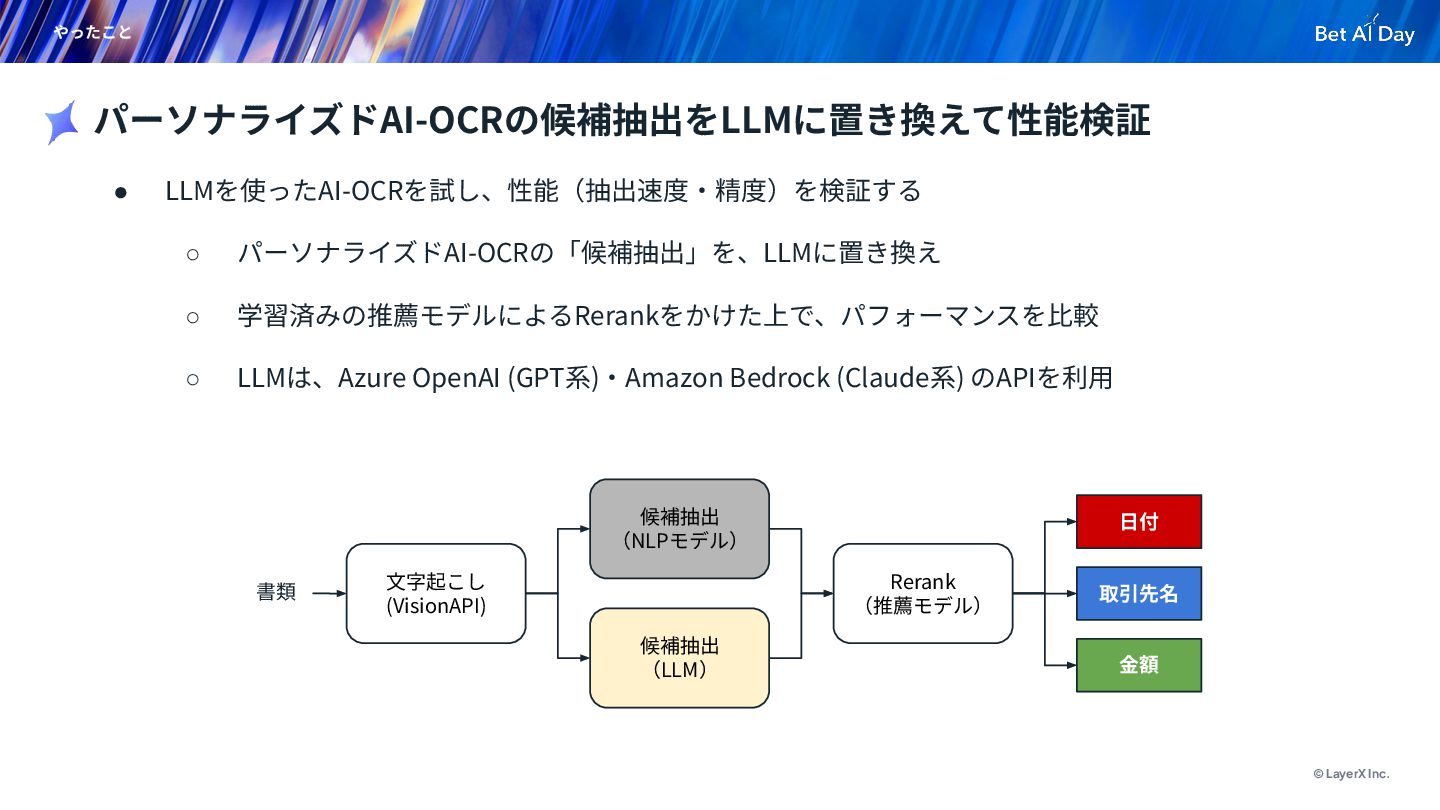
© LayerX Inc. やったこと • LLMを使ったAI-OCRを試し、性能(抽出速度‧精度)を検証する ◦ パーソナライズドAI-OCRの「候補抽出」を、LLMに置き換え ◦ 学習済みの推薦モデルによるRerankをかけた上で、パフォーマンスを⽐較
◦ LLMは、Azure OpenAI (GPT系)‧Amazon Bedrock (Claude系) のAPIを利⽤ パーソナライズドAI-OCRの候補抽出をLLMに置き換えて性能検証 候補抽出 (NLPモデル) 候補抽出 (LLM) Rerank (推薦モデル) ⽇付 取引先名 ⾦額 ⽂字起こし (VisionAPI) 書類
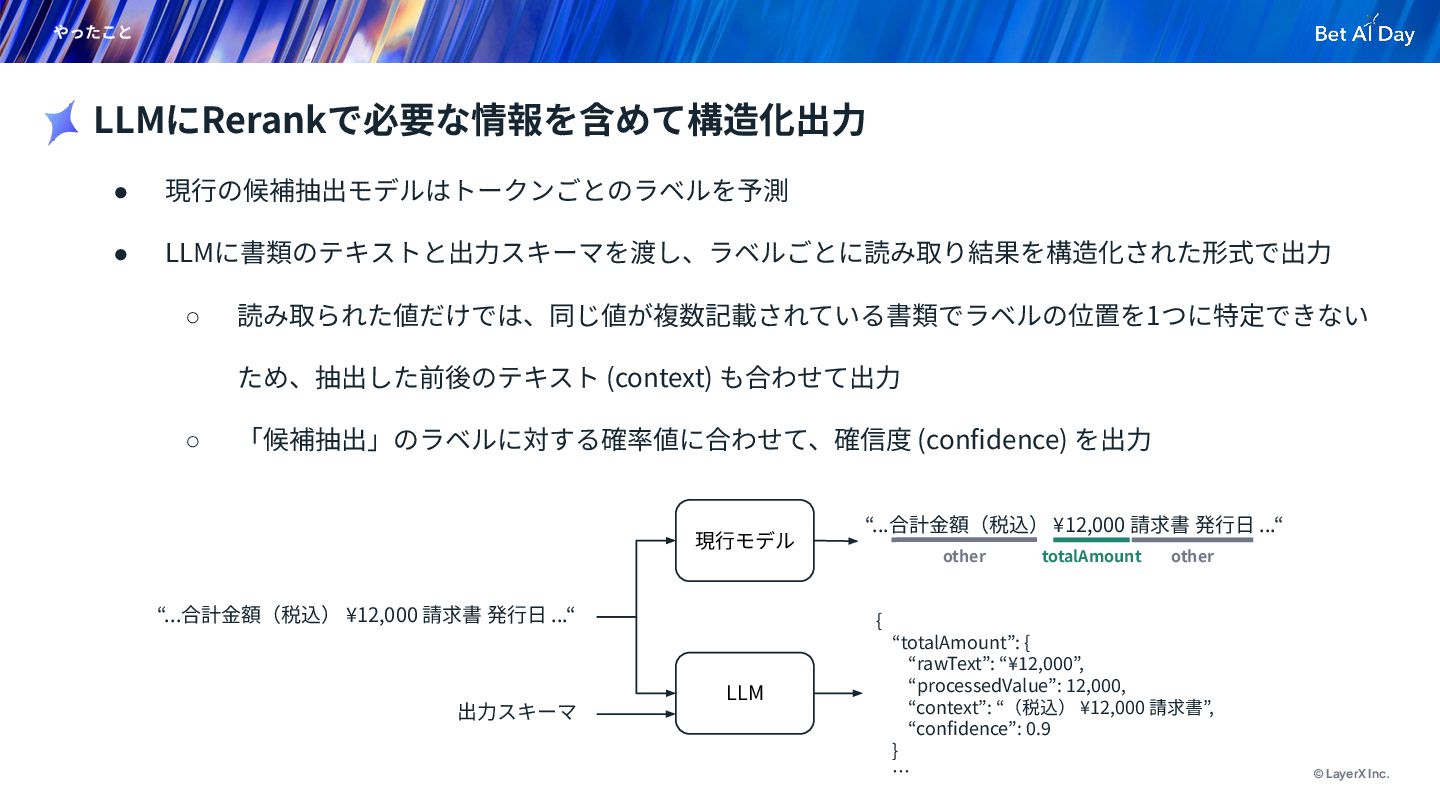
© LayerX Inc. やったこと • 現⾏の候補抽出モデルはトークンごとのラベルを予測 • LLMに書類のテキストと出⼒スキーマを渡し、ラベルごとに読み取り結果を構造化された形式で出⼒ ◦ 読み取られた値だけでは、同じ値が複数記載されている書類でラベルの位置を1つに特定できない
ため、抽出した前後のテキスト (context) も合わせて出⼒ ◦ 「候補抽出」のラベルに対する確率値に合わせて、確信度 (confidence) を出⼒ LLMにRerankで必要な情報を含めて構造化出⼒ “...合計⾦額(税込) ¥12,000 請求書 発⾏⽇ ...“ 現⾏モデル LLM 出⼒スキーマ { “totalAmount”: { “rawText”: “¥12,000”, “processedValue”: 12,000, “context”: “(税込) ¥12,000 請求書”, “confidence”: 0.9 } … totalAmount “...合計⾦額(税込) ¥12,000 請求書 発⾏⽇ ...“ other other
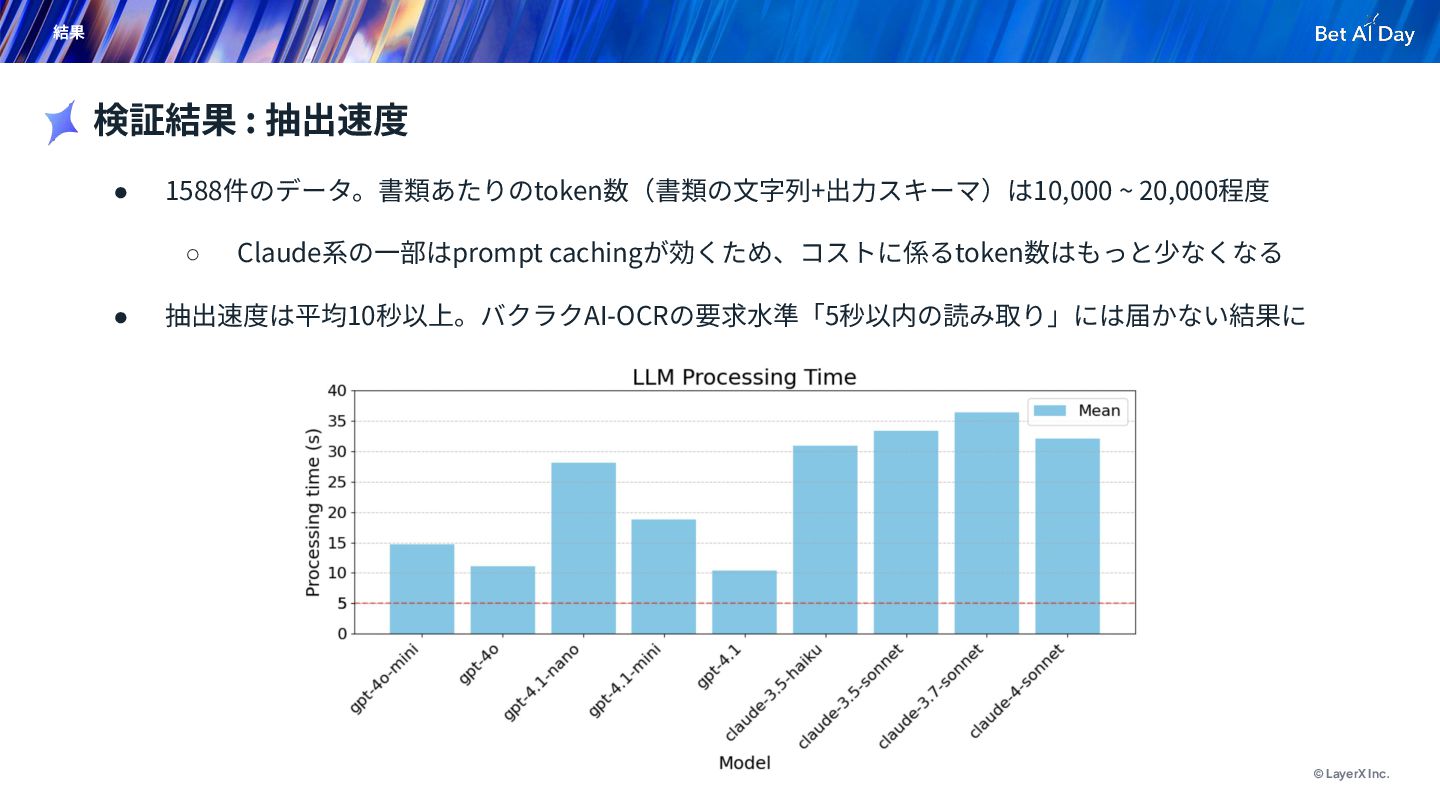
© LayerX Inc. 結果 • 1588件のデータ。書類あたりのtoken数(書類の⽂字列+出⼒スキーマ)は10,000 ~ 20,000程度 ◦ Claude系の⼀部はprompt
cachingが効くため、コストに係るtoken数はもっと少なくなる • 抽出速度は平均10秒以上。バクラクAI-OCRの要求⽔準「5秒以内の読み取り」には届かない結果に 検証結果 : 抽出速度
© LayerX Inc. 結果 • パーソナライズドAI-OCRを1.0としてLLMの項⽬ごとにRerankした後の精度(Top1 Accuracy)を⽐較 ◦ ⾦額(PaymentAmount)‧取引先名(ClientName)‧⽇付(DocumentDate)について評価 •
GPT系のモデルよりも、Claude系のモデルが全体的にやや⾼精度 • いずれのモデル‧項⽬についても 1.0 を下回り、⾼いものは 0.9 前後の精度に ◦ 軽量なモデルほど、取引先名となる名前の⼀部しか取れていないような間違いが⽬⽴つ 検証結果 : 項⽬別の読み取り精度
© LayerX Inc. 結論 • 今回は、パーソナライズドAI-OCRの「候補抽出」をそのままLLMに置き換えるだけの性能は確認できず ◦ パーソナライズドAI-OCRを基準に0.9程度の精度はでているものの、より⾼める⼯夫が必要 ◦ 抽出速度は特にボトルネックになりそう
• とはいえ、LLMによるAI-OCRはまだまだ別の可能性が考えられる ◦ コンテキストに過去の⼊⼒履歴に関する情報を加え、LLMでRerankも含めたE2Eの推論 ◦ 主要項⽬(⾦額‧取引先名‧⽇付)以外の読み取り項⽬への拡張 • 既存の機械学習技術だけに囚われず、状況に応じて適切な技術を使い分け、お客様の様々な 課題を解決していきます! まとめ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}