nonexistence of certain statistical procedures in nonparametric problems, Ann. Math. Stat. 27 (1956), 1115–1122. [Gil15] M. B. Giles, Multilevel Monte Carlo methods, Acta Numer. 24 (2015), 259–328. [H00] F. J. Hickernell, What a ff ects the accuracy of quasi-Monte Carlo quadrature?, Monte Carlo and Quasi-Monte Carlo Methods 1998 (H. Niederreiter and J. Spanier, eds.), Springer-Verlag, Berlin, 2000, pp. 16–55. [HJLO13] F. J. Hickernell, L. Jiang, Y. Liu, and A. B. Owen, Guaranteed conservative fi xed width con fi dence intervals via Monte Carlo sampling, Monte Carlo and Quasi-{M}onte {C}arlo Methods 2012 (J. Dick, F. Y. Kuo, G. W. Peters, and I. H. Sloan, eds.), Springer Proceedings in Mathematics and Statistics, vol. 65, Springer-Verlag, Berlin, 2013, pp. 105–128. [HJ16] F. J. Hickernell and Ll. A. Jiménez Rugama, Reliable adaptive cubature using digital sequences, Monte Carlo and Quasi-Monte Carlo Methods: MCQMC, Leuven, Belgium, April 2014 (R. Cools and D. Nuyens, eds.), Springer Proceedings in Mathematics and Statistics, vol. 163, Springer-Verlag, Berlin, 2016, pp. 367–383.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Discrepancy measures the quality of [H00] x0 , x1 ,](https://files.speakerdeck.com/presentations/3907cd88f279486ab3f9d0e30c293d67/slide_26.jpg){kind=link}
![Discrepancy measures the quality of [H00] x0 , x1 ,](https://files.speakerdeck.com/presentations/3907cd88f279486ab3f9d0e30c293d67/slide_27.jpg){kind=link}
![Deterministic stopping rules for QMC [HJ16, JH16, SJ24] μ :=](https://files.speakerdeck.com/presentations/3907cd88f279486ab3f9d0e30c293d67/slide_28.jpg){kind=link}
![Deterministic stopping rules for QMC [HJ16, JH16, SJ24] μ :=](https://files.speakerdeck.com/presentations/3907cd88f279486ab3f9d0e30c293d67/slide_29.jpg){kind=link}
![Bayesian stopping rules for QMC [JH19, JH22] μ := expectation](https://files.speakerdeck.com/presentations/3907cd88f279486ab3f9d0e30c293d67/slide_30.jpg){kind=link}
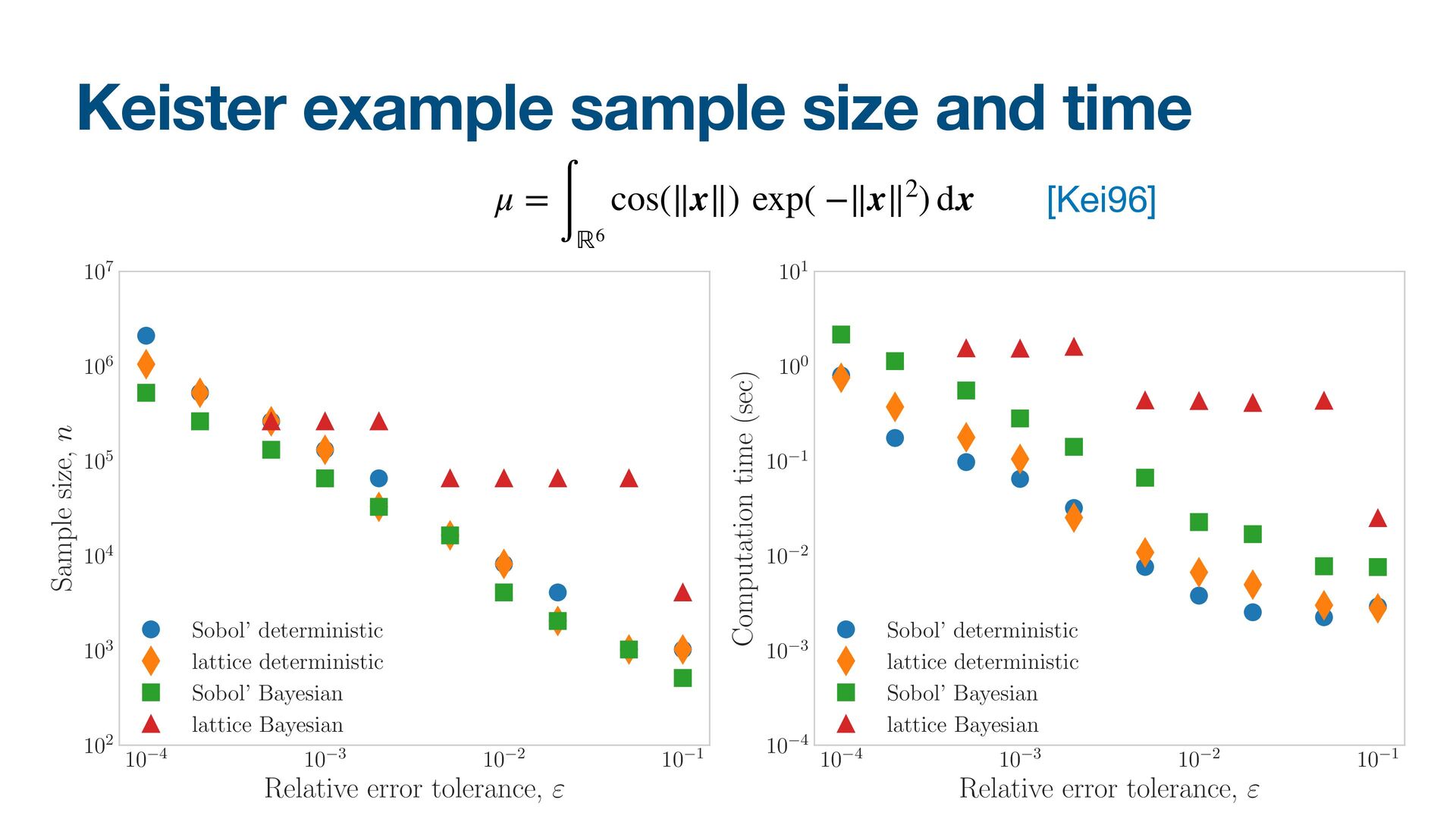{kind=link}
{kind=link}
{kind=link}
![References [BS56] R. R. Bahadur and L. J. Savage, The](https://files.speakerdeck.com/presentations/3907cd88f279486ab3f9d0e30c293d67/slide_34.jpg){kind=link}
![References [HKS25] F. J. Hickernell, N. Kirk, and A. G.](https://files.speakerdeck.com/presentations/3907cd88f279486ab3f9d0e30c293d67/slide_35.jpg){kind=link}
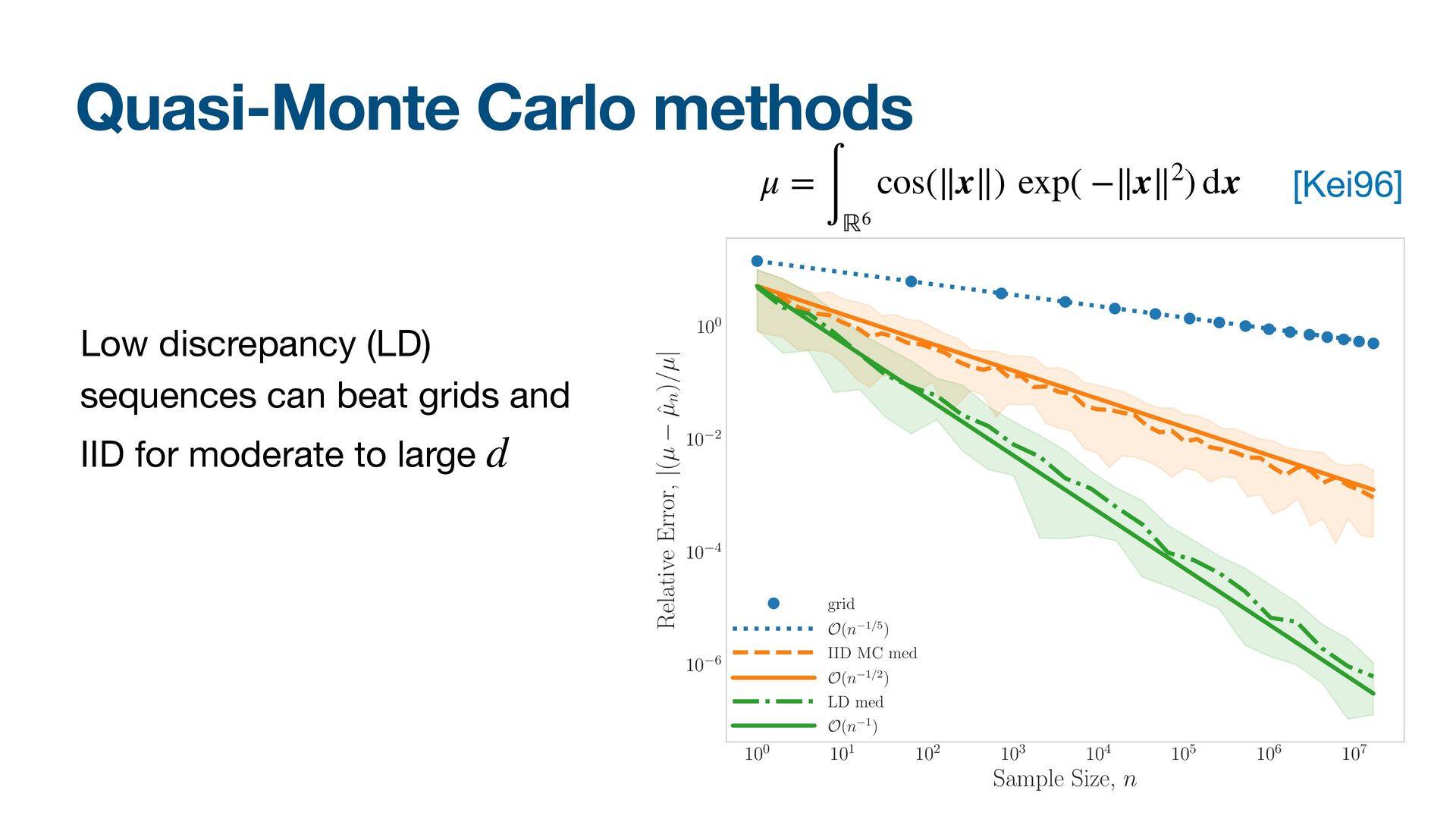
![References [Kei96] B. D. Keister, Multidimensional quadrature algorithms, Computers in](https://files.speakerdeck.com/presentations/3907cd88f279486ab3f9d0e30c293d67/slide_36.jpg){kind=link}
![Multilevel methods reduce computational cost [Gil15] μ := expectation 𝔼](https://files.speakerdeck.com/presentations/3907cd88f279486ab3f9d0e30c293d67/slide_37.jpg){kind=link}