Linguistics • Classification of Linguistics • Challenges in Linguistics • Information Extraction through Computational Linguistics • Building Blocks for our application • Introduction to spaCy • Early Cancer Detection Model using CL through spaCy
that creates computer systems capable of understanding, analyzing, and extracting meaning from written and spoken language. It is based on traditional Linguistics, Statistics, Computer Science (CS), and Machine Learning (ML). CL, in conjunction with knowledge representation and formal reasoning theories, creates a foundation for Artificial Intelligence (AI). Together We Can Defy Disease Efficient. Effective. Effortless.
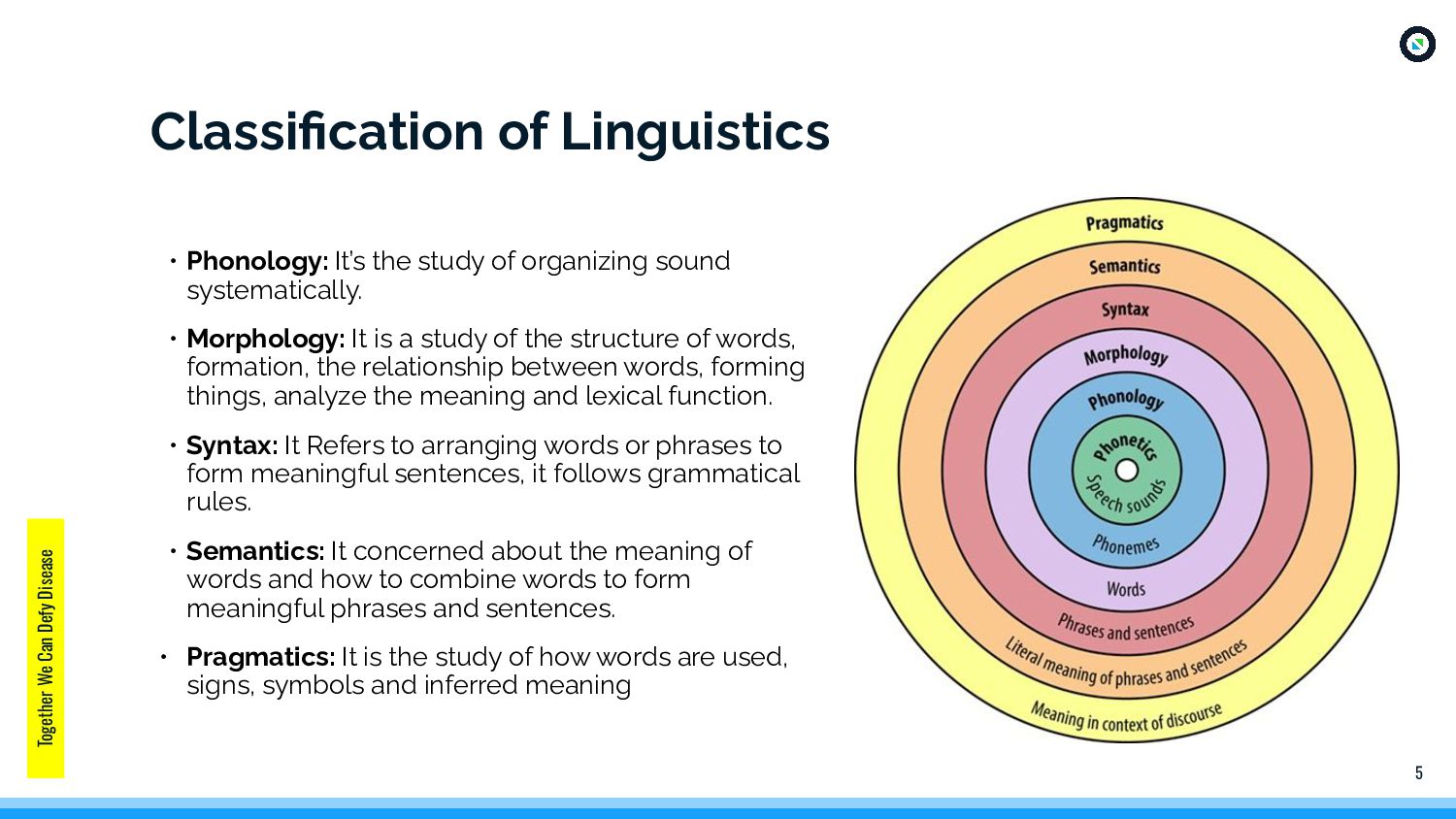
study of organizing sound systematically. • Morphology: It is a study of the structure of words, formation, the relationship between words, forming things, analyze the meaning and lexical function. • Syntax: It Refers to arranging words or phrases to form meaningful sentences, it follows grammatical rules. • Semantics: It concerned about the meaning of words and how to combine words to form meaningful phrases and sentences. • Pragmatics: It is the study of how words are used, signs, symbols and inferred meaning Classification of Linguistics
& Semantics • Think of how a sentence is valid, it based on two things called syntax and semantics • Syntax refers to the grammatical rules, on the other hand, semantics is the meaning of the vocabulary symbols within that structure. Normalization • It involves normalizing text from tags, URLs, text-emojis, special characters e.g. Yahoo!, • Also includes misspellings words, hashtags, new words, and terminologies. • There is no single best way to do normalization. • To do this task we use the Morphology part of Linguistics.
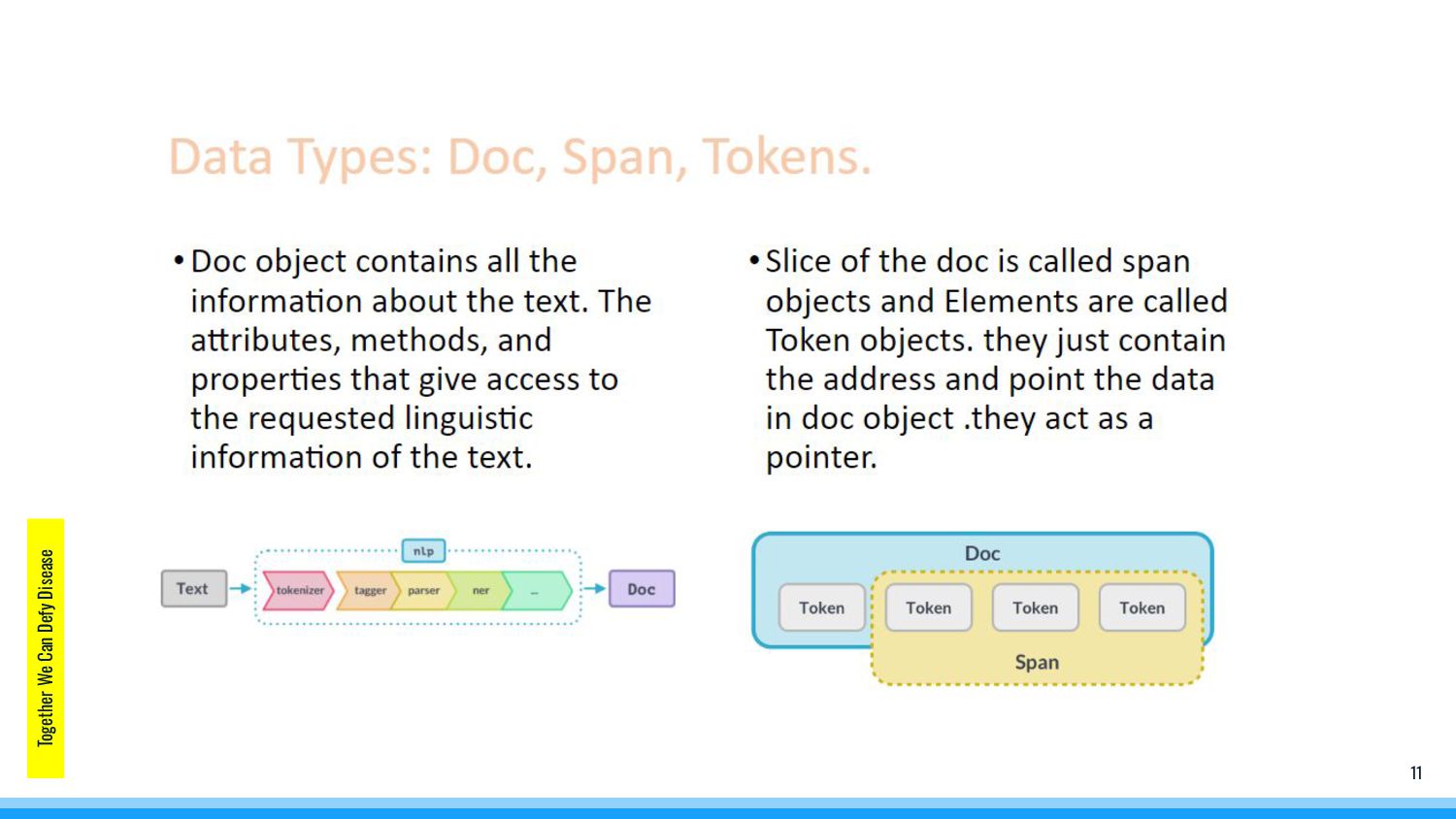
NLTK library from Stanford university is used by people for decades. It was built by researchers and scholars to serve as a tool for the NLP/CL system. NLTK was initially created to support education and help students to explore ideas. Although, it works great for NLP systems, it is a string processing library it returns string as a result. spaCy is built for “Industrial strength NLP/CL in Python” developed by Matt Honnibal at Explosion AI. It is mainly used for the production environment and its extreme user-friendliness. It is an object-based approach it returns objects instead of strings and arrays.
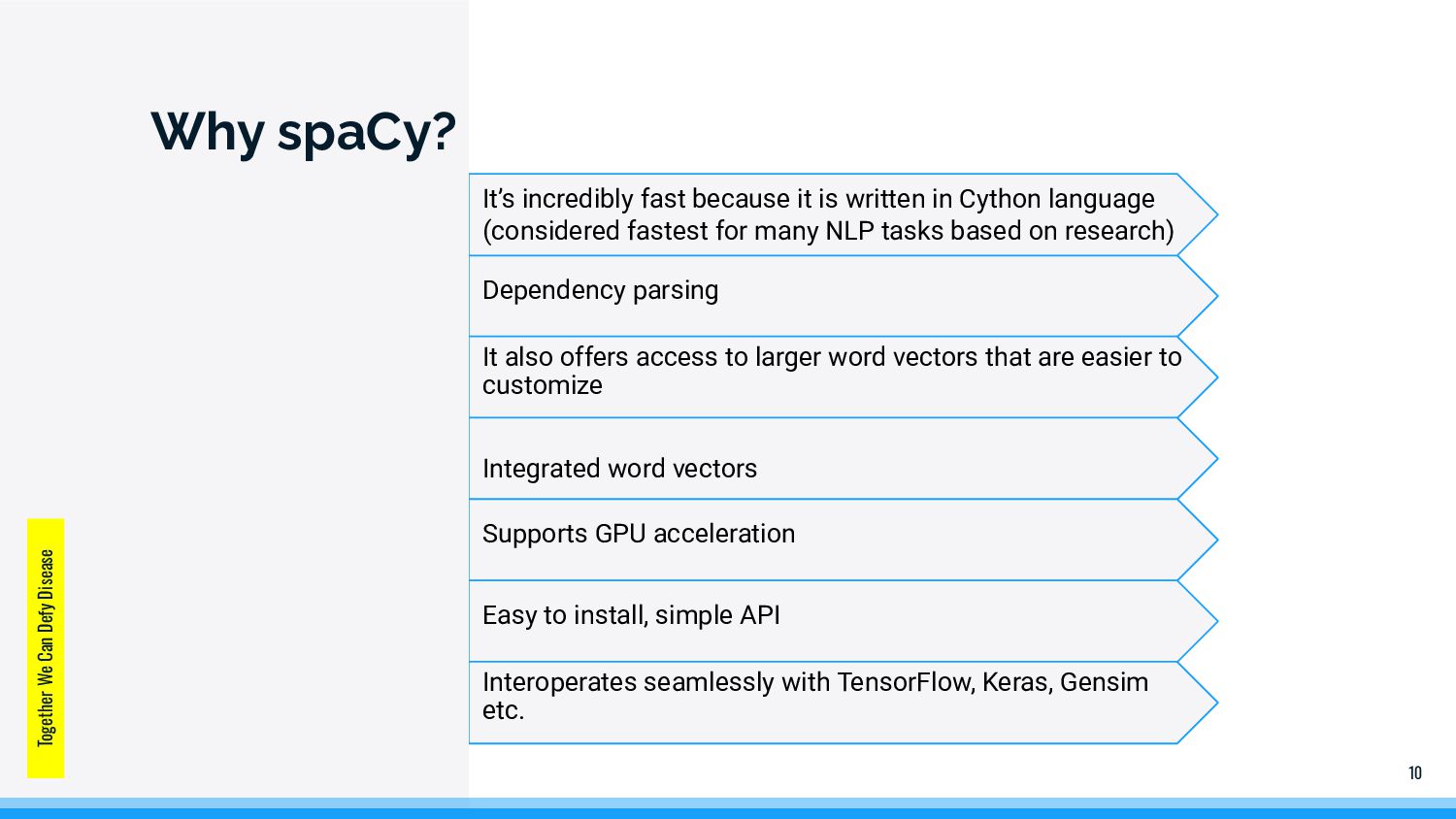
that are easier to customize Integrated word vectors Supports GPU acceleration Easy to install, simple API Interoperates seamlessly with TensorFlow, Keras, Gensim etc. It’s incredibly fast because it is written in Cython language (considered fastest for many NLP tasks based on research) 10 Together We Can Defy Disease Why spaCy?
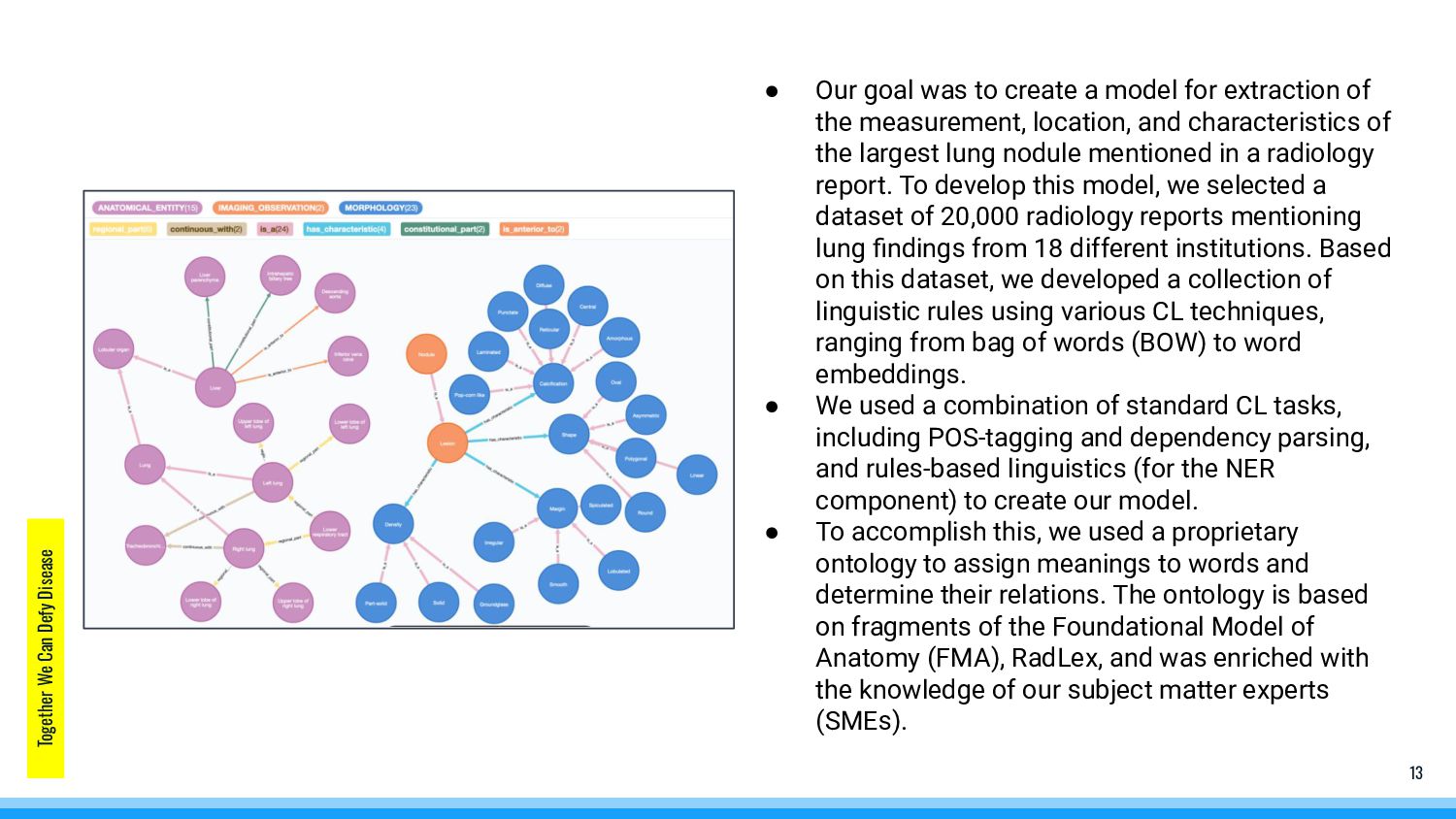
to create a model for extraction of the measurement, location, and characteristics of the largest lung nodule mentioned in a radiology report. To develop this model, we selected a dataset of 20,000 radiology reports mentioning lung findings from 18 different institutions. Based on this dataset, we developed a collection of linguistic rules using various CL techniques, ranging from bag of words (BOW) to word embeddings. • We used a combination of standard CL tasks, including POS-tagging and dependency parsing, and rules-based linguistics (for the NER component) to create our model. • To accomplish this, we used a proprietary ontology to assign meanings to words and determine their relations. The ontology is based on fragments of the Foundational Model of Anatomy (FMA), RadLex, and was enriched with the knowledge of our subject matter experts (SMEs).
step of the model was defining the relationships between entities. After all previous steps are completed, and the model knows what the tagged entities (measures, organs, locations) are referring to, as well as knows the syntactic dependencies between them, the model uses a set of rules and heuristics to determine semantic relations between entities. • Once the relations extraction is completed, the model has all the required information to extract data of interest, in this case, a set of measured lung nodules. It excludes measurements from reference citations (such as the Fleischner Society guidelines for incidentally detected lung nodule follow-up). Finally, the model selects the largest nodule and outputs its size, location, and characteristics. • We found the accuracy agreement between the model and the annotated gold standard records for the presence of a lung nodule was 98.95%, with 98.99% precision and 99.66% recall. • The model is a brain of our healthcare product that is currently being used in hundreds of hospitals in US, impacting thousands of patients every year and saving crucial lives.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}