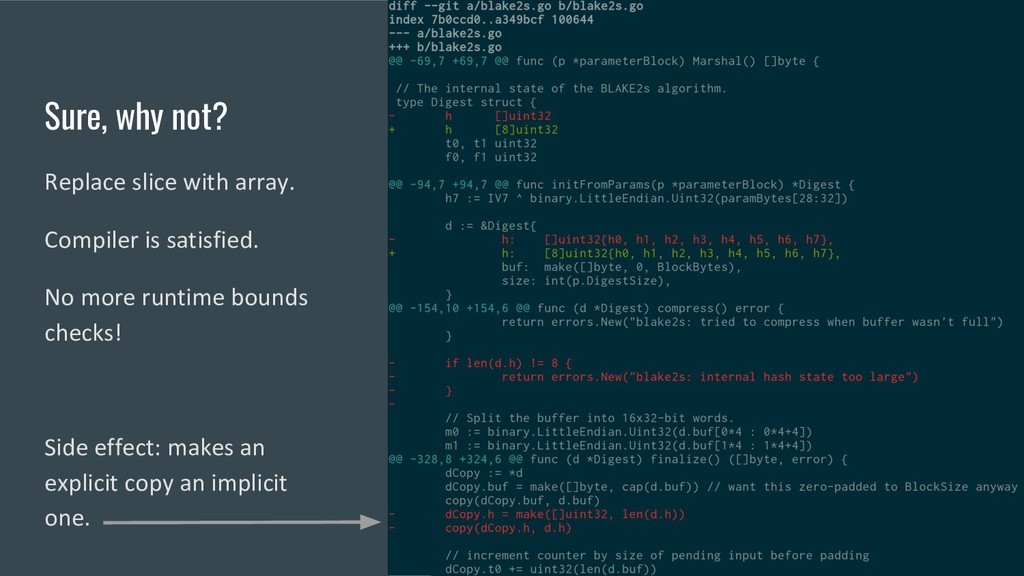
even RFC7693: Note: [The BLAKE2 paper] defines additional variants of BLAKE2 with features such as salting, personalized hashes, and tree hashing. These OPTIONAL features use fields in the parameter block that are not defined in this document.
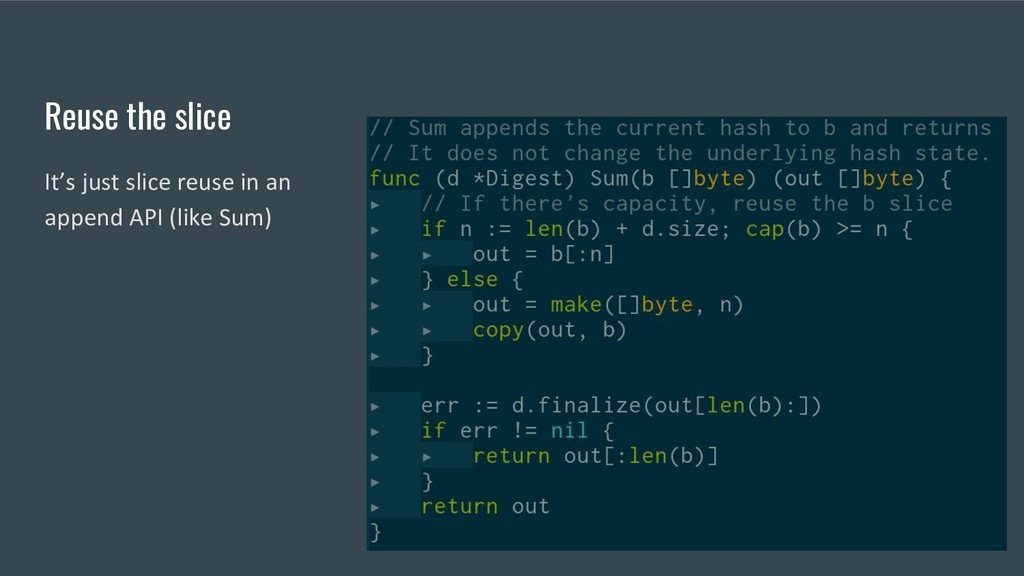
(via the embedded io.Writer) adds more data to the hash. // It never returns an error. io.Writer // Sum appends the current hash to b and returns the resulting slice. // It does not change the underlying hash state. Sum(b []byte) []byte // Reset resets the Hash to its initial state. Reset() // Size returns the number of bytes Sum will return. Size() int // BlockSize returns the hash's underlying block size. // The Write method must be able to accept any amount // of data, but it may operate more efficiently if all writes // are a multiple of the block size. BlockSize() int }
(via the embedded io.Writer) adds more data to the hash. // It never returns an error. io.Writer // Sum appends the current hash to b and returns the resulting slice. // It does not change the underlying hash state. Sum(b []byte) []byte // Reset resets the Hash to its initial state. Reset() // Size returns the number of bytes Sum will return. Size() int // BlockSize returns the hash's underlying block size. // The Write method must be able to accept any amount // of data, but it may operate more efficiently if all writes // are a multiple of the block size. BlockSize() int } Block padding. Tree modes? Mutating finalize() Needs key Arbitrary parameter but affects hash output Differs by BLAKE2 variant
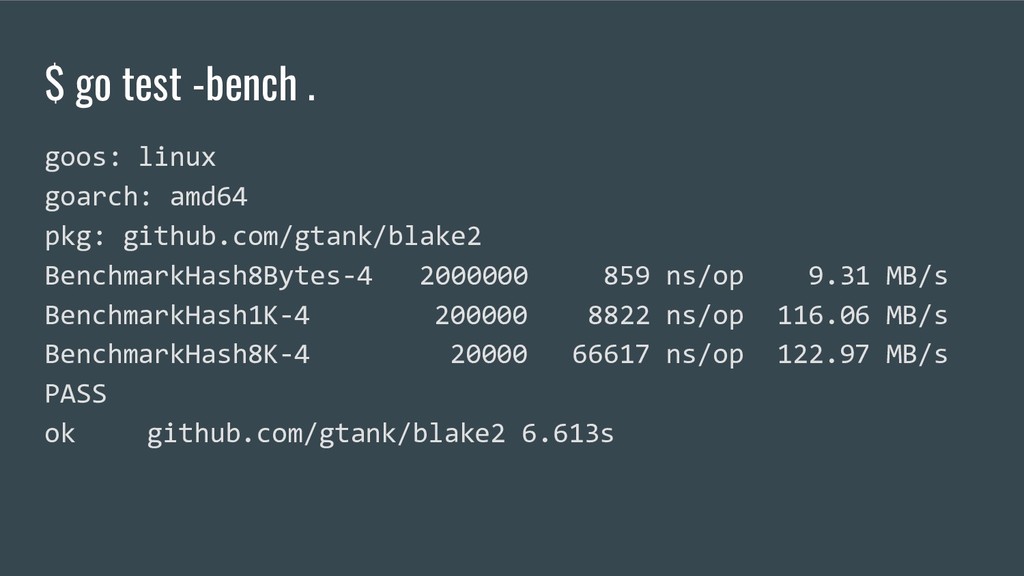
-u +'%s' | tr -d '\n'`; BRANCH=`git rev-parse --abbrev-ref HEAD`; for i in {1..8}; do go test -bench . >> benchmark-$BRANCH-$DATE; done go bench https://dave.cheney.net/2013/06/30/how-to-write-benchmarks-in-go benchstat https://godoc.org/golang.org/x/perf/cmd/benchstat pprof https://golang.org/pkg/runtime/pprof/
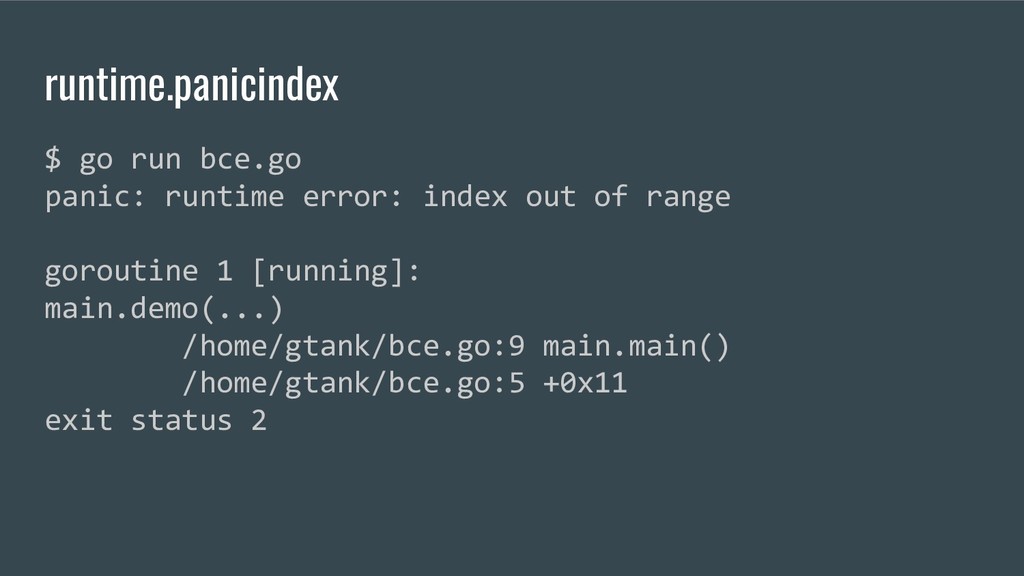
seen testing.T, this is testing.B. • I usually put benchmarks in my test files. The benchmarks I’m using are here: https://github.com/gtank/blake2s/blob/master/blake2s_test.go
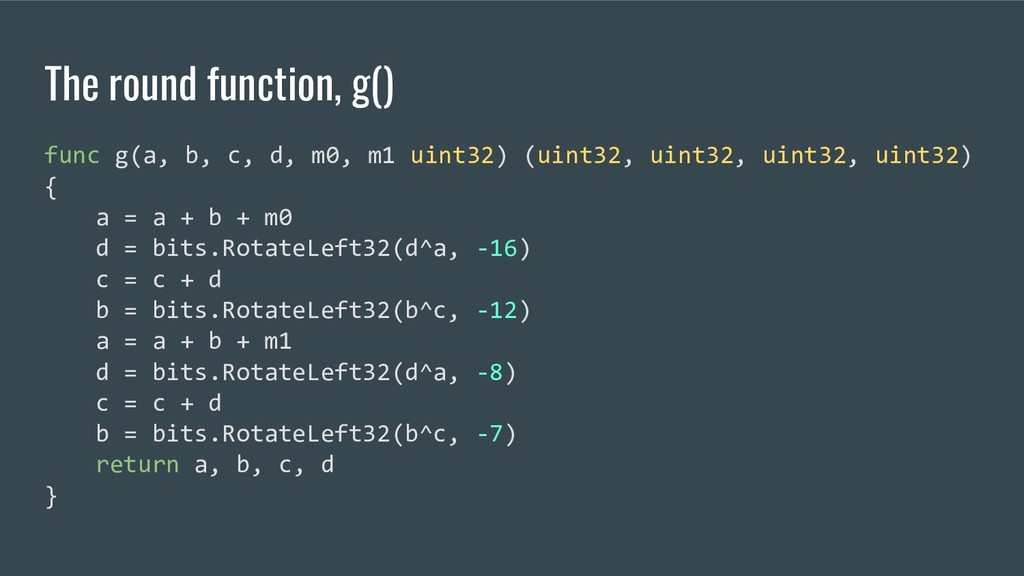
m1 uint32) (uint32, uint32, uint32, uint32) { a = a + b + m0 d = bits.RotateLeft32(d^a, -16) c = c + d b = bits.RotateLeft32(b^c, -12) a = a + b + m1 d = bits.RotateLeft32(d^a, -8) c = c + d b = bits.RotateLeft32(b^c, -7) return a, b, c, d }
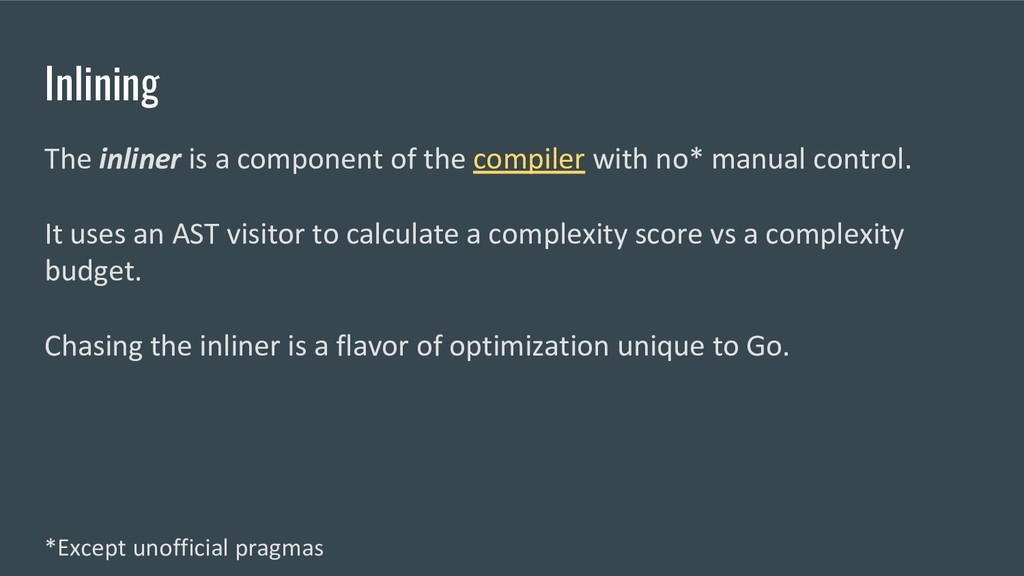
no* manual control. It uses an AST visitor to calculate a complexity score vs a complexity budget. Chasing the inliner is a flavor of optimization unique to Go. *Except unofficial pragmas
instruction tree Slices are expensive! A slice node is +2 or +3 depending. Function calls OK in most cases if we have budget for it. But a call is +2 regardless.
- for, range, select, break, defer, type switch • Recover (but not panic) • Certain runtime funcs and all non-intrinsic assembly [#17373] Full details (as of go1.11) in inl.go
m1 uint32) (uint32, uint32, uint32, uint32) { a = a + b + m0 d = bits.RotateLeft32(d^a, -16) c = c + d b = bits.RotateLeft32(b^c, -12) a = a + b + m1 d = bits.RotateLeft32(d^a, -8) c = c + d b = bits.RotateLeft32(b^c, -7) return a, b, c, d }
m1 uint32) (uint32, uint32, uint32, uint32) { a = a + b + m0 d = ((d ^ a) >> 16) | ((d ^ a) << (32 - 16)) c = c + d b = ((b ^ c) >> 12) | ((b ^ c) << (32 - 12)) a = a + b + m1 d = ((d ^ a) >> 8) | ((d ^ a) << (32 - 8)) c = c + d b = ((b ^ c) >> 7) | ((b ^ c) << (32 - 7)) return a, b, c, d }
m1 uint32) (uint32, uint32, uint32, uint32) { a = a + b + m0 d = ((d ^ a) >> 16) | ((d ^ a) << (32 - 16)) c = c + d b = ((b ^ c) >> 12) | ((b ^ c) << (32 - 12)) a = a + b + m1 d = ((d ^ a) >> 8) | ((d ^ a) << (32 - 8)) c = c + d b = ((b ^ c) >> 7) | ((b ^ c) << (32 - 7)) return a, b, c, d }
(uint32, uint32, uint32, uint32) { // a = a + b + m0 d = ((d ^ a) >> 16) | ((d ^ a) << (32 - 16)) c = c + d b = ((b ^ c) >> 12) | ((b ^ c) << (32 - 12)) a = a + b + m1 d = ((d ^ a) >> 8) | ((d ^ a) << (32 - 8)) c = c + d b = ((b ^ c) >> 7) | ((b ^ c) << (32 - 7)) return a, b, c, d }
(uint32, uint32, uint32, uint32) { // a = a + b + m0 d = ((d ^ a) >> 16) | ((d ^ a) << (32 - 16)) c = c + d b = ((b ^ c) >> 12) | ((b ^ c) << (32 - 12)) a = a + b + m1 d = ((d ^ a) >> 8) | ((d ^ a) << (32 - 8)) c = c + d b = ((b ^ c) >> 7) | ((b ^ c) << (32 - 7)) return a, b, c, d }
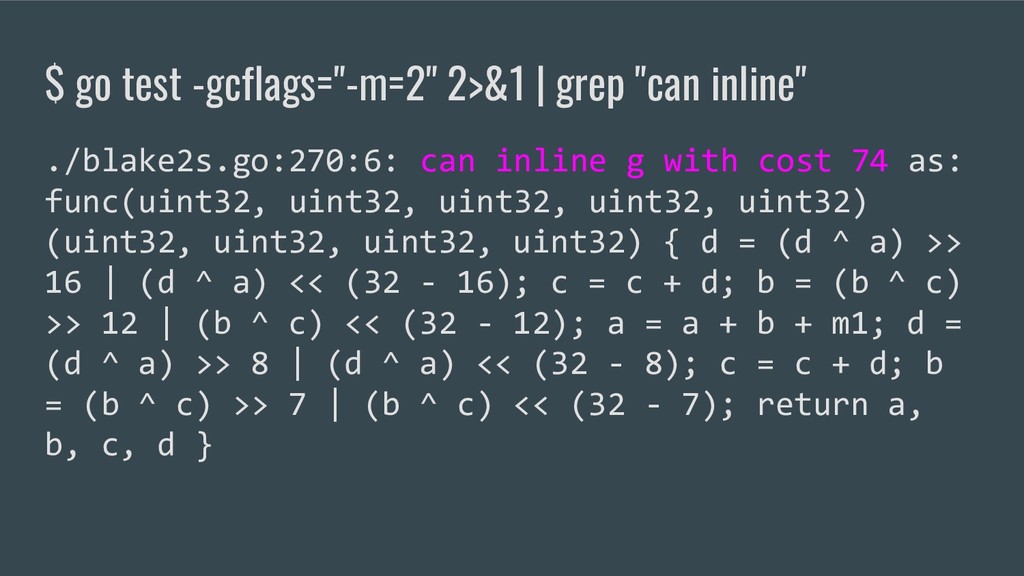
can inline g with cost 74 as: func(uint32, uint32, uint32, uint32, uint32) (uint32, uint32, uint32, uint32) { d = (d ^ a) >> 16 | (d ^ a) << (32 - 16); c = c + d; b = (b ^ c) >> 12 | (b ^ c) << (32 - 12); a = a + b + m1; d = (d ^ a) >> 8 | (d ^ a) << (32 - 8); c = c + d; b = (b ^ c) >> 7 | (b ^ c) << (32 - 7); return a, b, c, d }
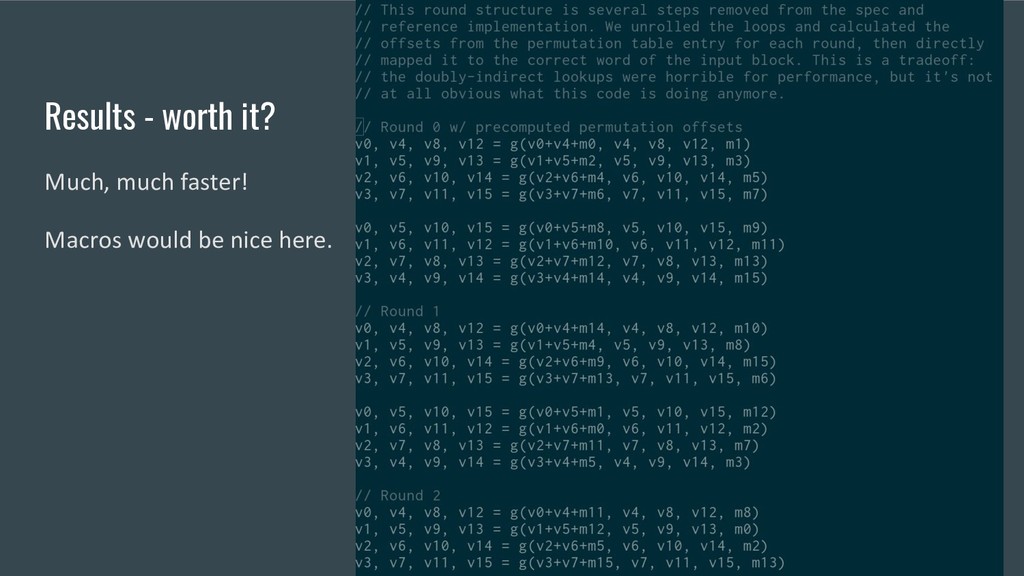
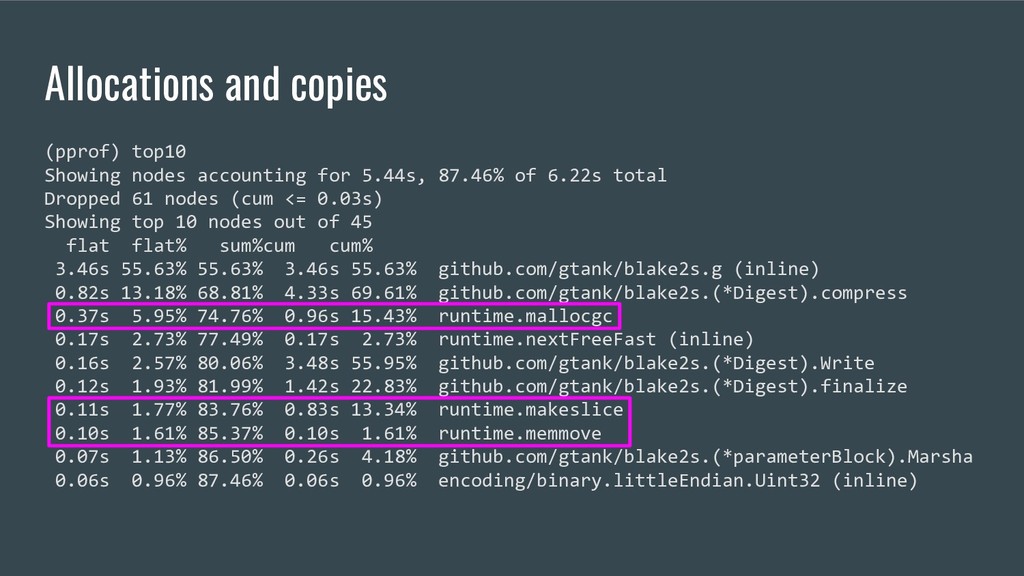
• Propagate constants • Unroll loops • Reuse previously-allocated local variables In pursuit of a specific thing: • Bounds-Check Elimination (further reading)
slice, but it’s always of fixed size. Can we eliminate these? Well, not as we expect. SSA bounds check output Corresponding to these lines in compress():
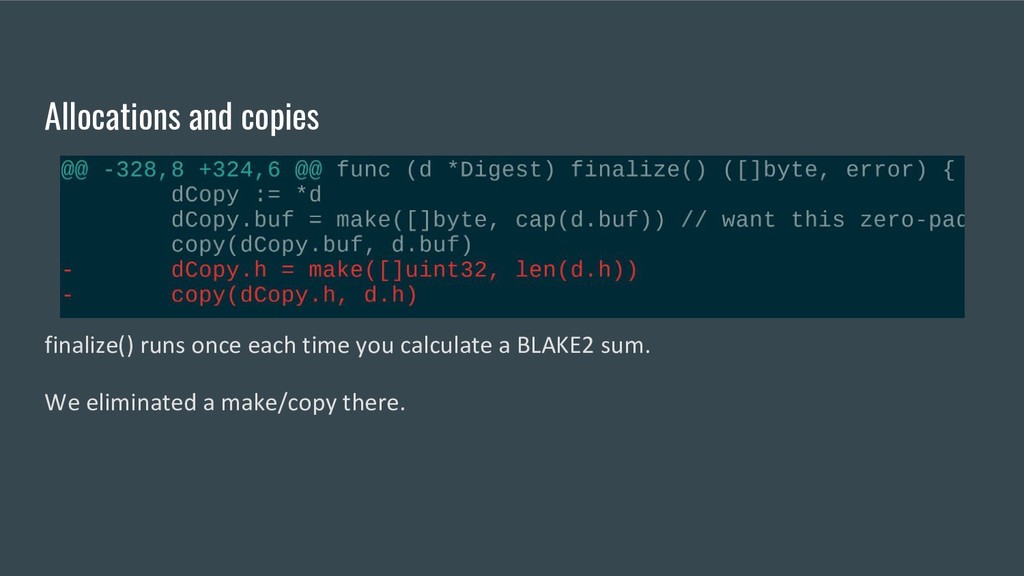
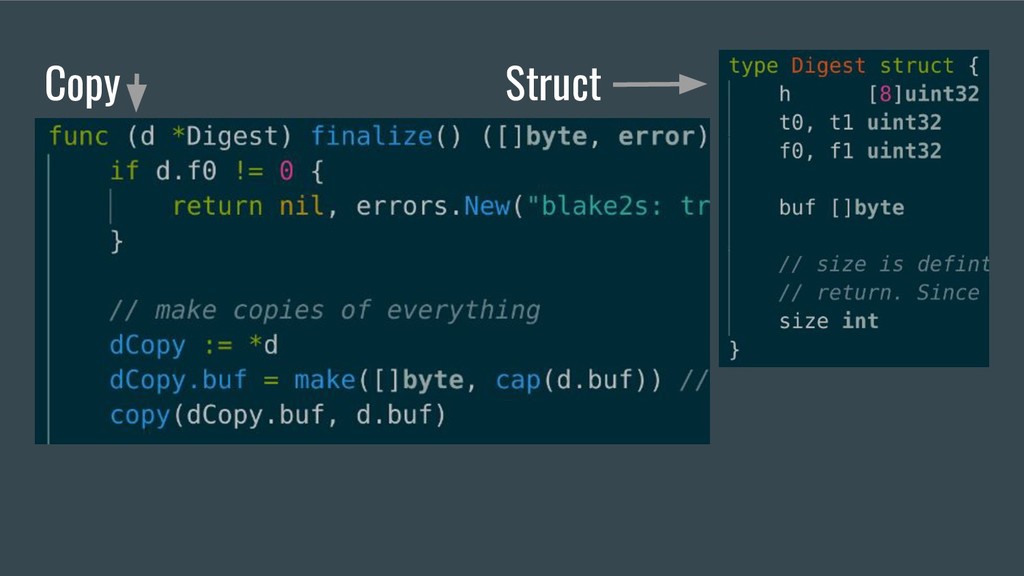
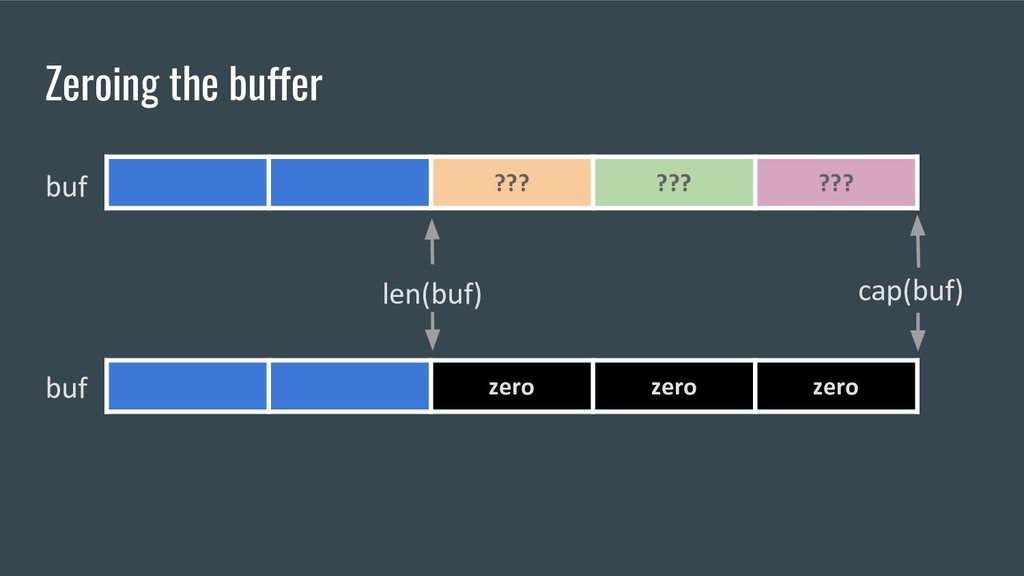
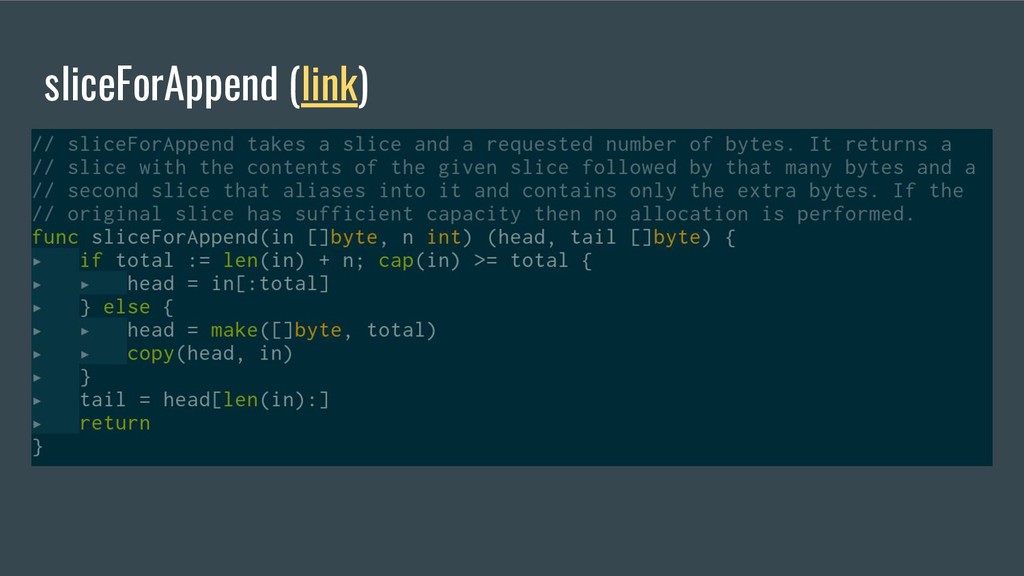
buffer. This triggers a specific optimization for memset, see https://codereview.appspot.com/137880043 padBuf := d.buf[len(d.buf):cap(d.buf)] for i := range padBuf { padBuf[i] = 0 } dCopy.buf = d.buf[0:cap(d.buf)]
intermediate variables • Unroll remaining fixed loops • Copy small functions into this package to allow inlining them • Hunt down the less significant bounds checks
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Benchmarks var emptyBuf = make([]byte, 8192) func benchmarkHashSize(b *testing.B, size](https://files.speakerdeck.com/presentations/1cfc27e0eaf6473fbfd9de1badbb496c/slide_13.jpg){kind=link}
![Benchmarks var emptyBuf = make([]byte, 8192) func benchmarkHashSize(b *testing.B, size](https://files.speakerdeck.com/presentations/1cfc27e0eaf6473fbfd9de1badbb496c/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![$ go test -gcflags="-m=2" 2>&1 | grep "too complex" [...]](https://files.speakerdeck.com/presentations/1cfc27e0eaf6473fbfd9de1badbb496c/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
![$ go test -gcflags="-m=2" 2>&1 | grep "too complex" [...]](https://files.speakerdeck.com/presentations/1cfc27e0eaf6473fbfd9de1badbb496c/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Another view: $ go test -gcflags="-d=ssa/check_bce/debug=1" [...] ./blake2s.go:199:11: Found IsInBounds](https://files.speakerdeck.com/presentations/1cfc27e0eaf6473fbfd9de1badbb496c/slide_41.jpg){kind=link}
![Bounds check elimination, normally func (bigEndian) PutUint32(b []byte, v uint32)](https://files.speakerdeck.com/presentations/1cfc27e0eaf6473fbfd9de1badbb496c/slide_42.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Benchmark var emptyBuf = make([]byte, 8192) func benchmarkHashSize(b *testing.B, size](https://files.speakerdeck.com/presentations/1cfc27e0eaf6473fbfd9de1badbb496c/slide_50.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}