Talk presented at Velocity San Jose 2017 (see https://conferences.oreilly.com/velocity/vl-ca/public/schedule/detail/58799).
"Despite the continuing high industrial demand for building new distributed systems, there are few institutionalized, commonly applicable techniques and design approaches like those found in other engineering disciplines. Practitioners are left to learn the same lessons over and over again, either through hard-won experience or by stumbling across a relevant paragraph in an academic paper.
Henry Robinson shares practical lessons learned from more than eight years spent building distributed systems using the Hadoop ecosystem (including Apache Zookeeper, Apache Flume, Apache Impala, and more), focusing on the thorny question of how to scale a distributed system. Henry outlines a framework for thinking about the problems of scale (in many dimensions) and effectively navigating the phase transitions between 10-, 100-, and 1,000-node deployments."
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[spoiler: everyone argues about CAP, forever]](https://files.speakerdeck.com/presentations/f502176edfdc44749f2775753026e1ff/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
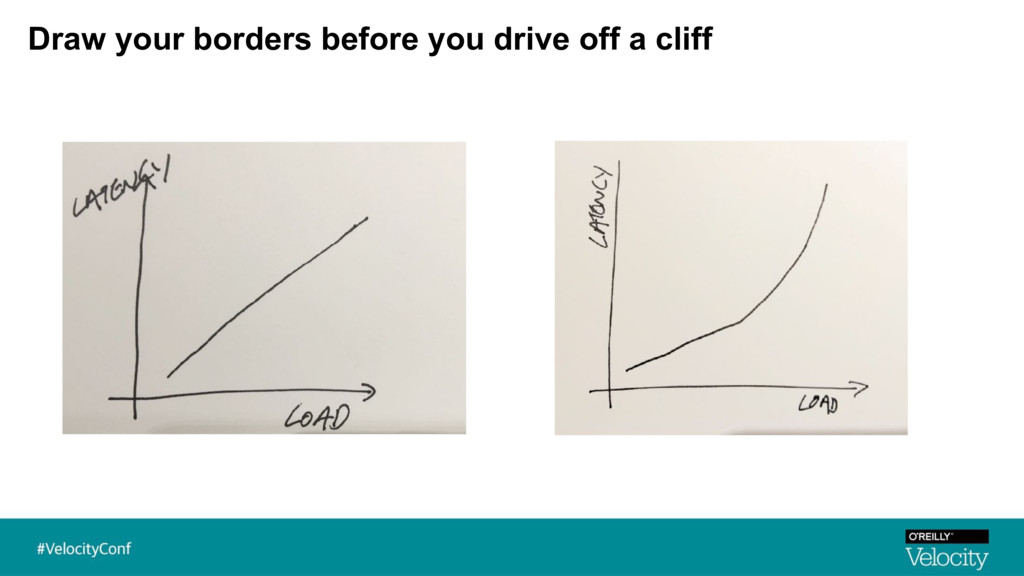{kind=link}
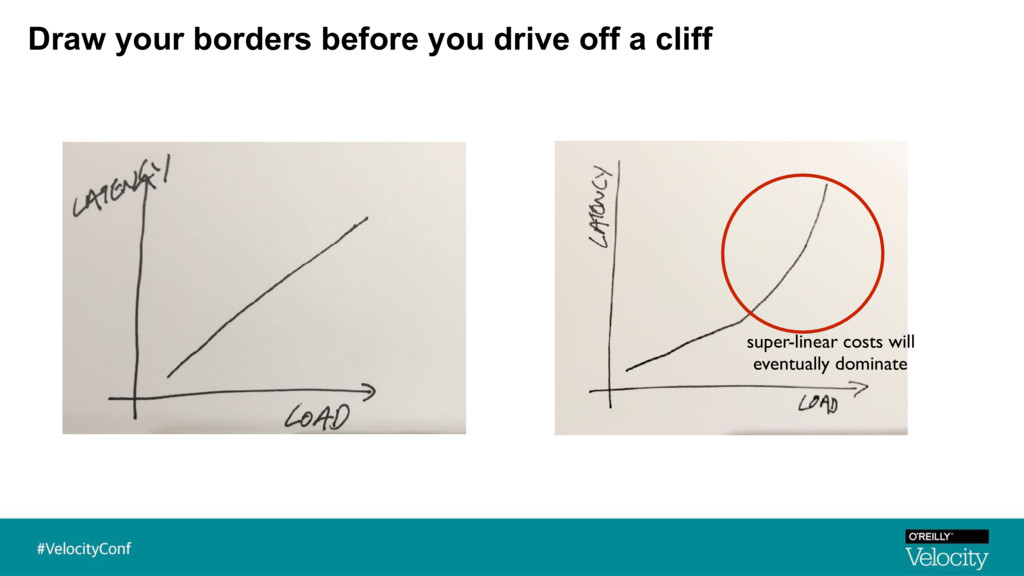{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}