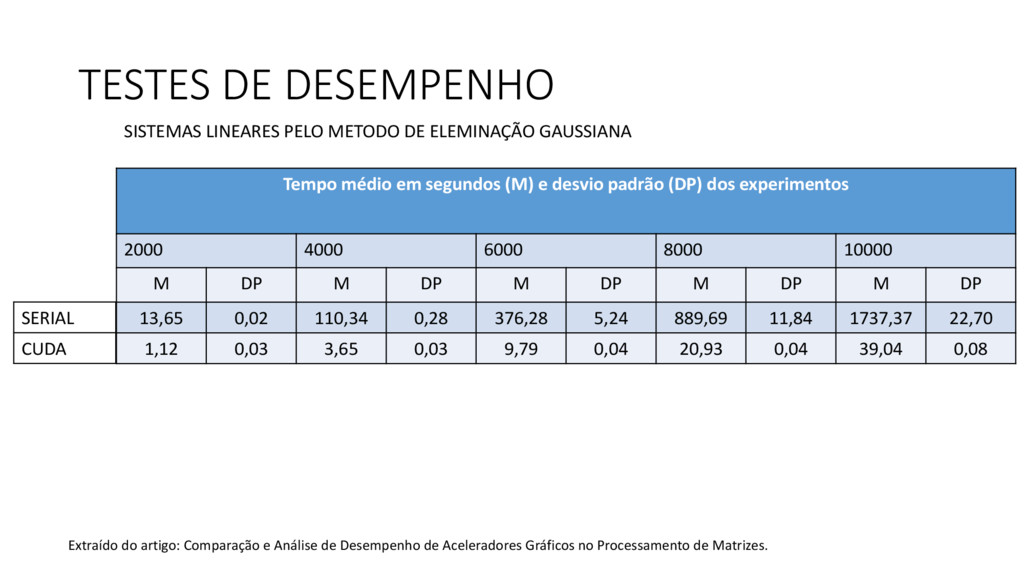
Atualmente através do avanço tecnológico, a indústria de eletrônicos tem disponibilizado uma série de novos dispositivos com características computacionais, como é o caso da GPU. Essa evolução, aliada a novas APIs de programação paralela tem aberto novas alternativas na computação de alto desempenho. Além disso, unir mais de um dispositivo com poder computacional, como por exemplo, CPU e GPU em um ambiente híbrido tende a ter ganhos de desempenho.
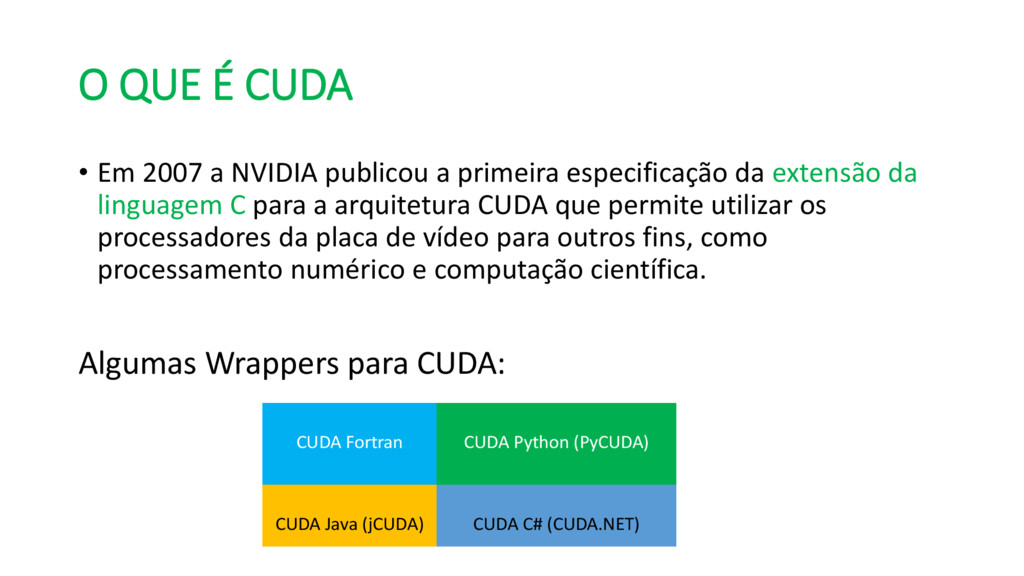
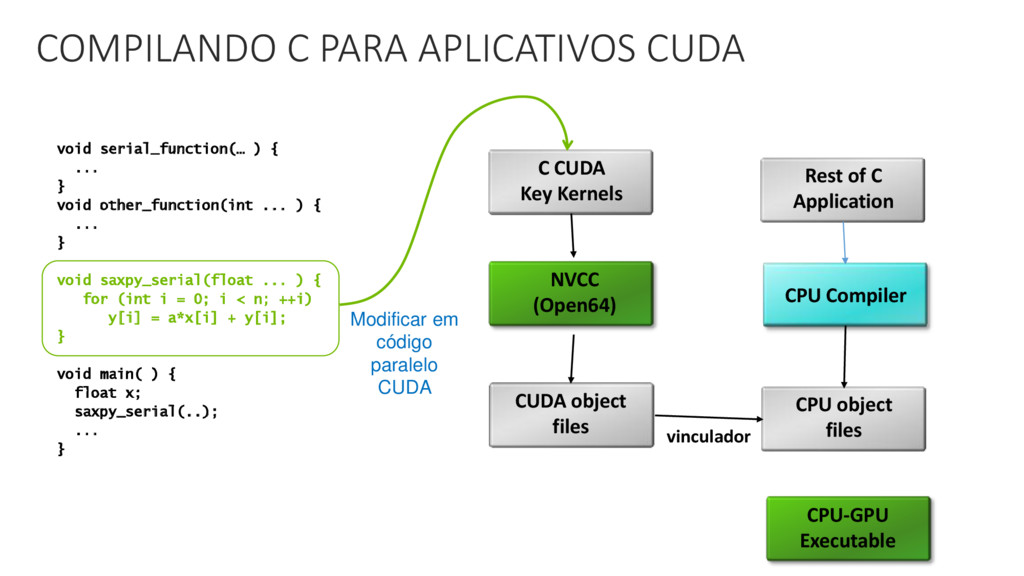
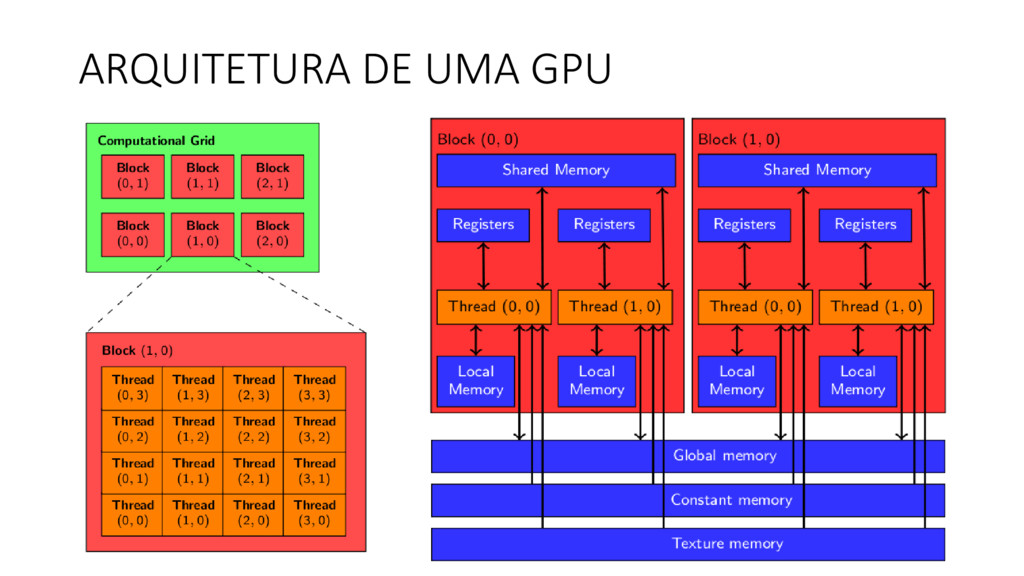
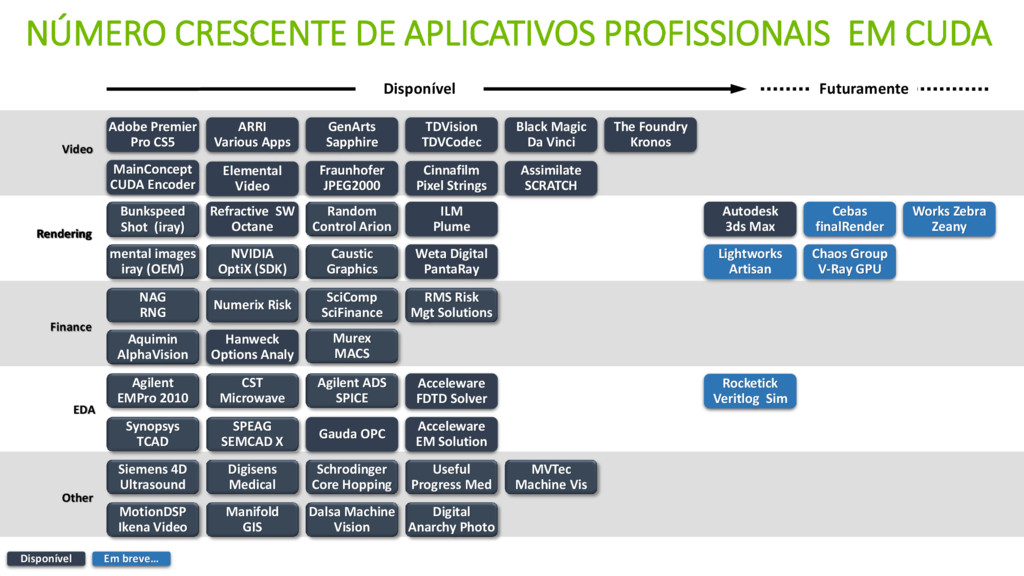
CUDA é uma arquitetura paralela de propósito geral destinada a utilizar o poder computacional de GPUs nVidia.
Extensão da linguagem C, e permite controlar a execução de threads na GPU e gerenciar sua memória.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MUITO OBRIGADO !!! [email protected] (98)9 8160-9856 @herissonchaves www.linkedin.com/in/herisson-chaves](https://files.speakerdeck.com/presentations/d746bc8bc9e549b0b27356b3c0b74e96/slide_36.jpg){kind=link}