Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
20250304_赤煉瓦倉庫_DeepSeek_Deep_Dive
Search
Hiroshi Ouchiyama
March 04, 2025
Technology
330
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
20250304_赤煉瓦倉庫_DeepSeek_Deep_Dive
こちらのイベントで使用した資料
https://redbrick.connpass.com/event/345123/
Hiroshi Ouchiyama
March 04, 2025
Other Decks in Technology
See All in Technology
Claude Mythos、Fable...フロンティアAIの最新動向と企業のセキュリティ対策
flatt_security
0
170
AI エージェント時代のデジタルアイデンティティ
fujie
1
1.2k
なぜ、あなたのエージェントは言うことを聞かないのか
segavvy
1
590
AI Agent を本番環境へ―― Microsoft Foundry × Azure Serverless で作る Enterprise-Ready な基盤
shibayan
PRO
1
900
AIツールを導入しても生産性はあがらない? カオナビが直面した 3つの壁と乗り越え方。/ Overcoming 3 Barriers to AI-Driven Productivity at kaonavi
kaonavi
0
470
AI研修(Day1)【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
2.9k
Power Automateアップデート情報
miyakemito
0
290
WEBフロントエンド研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
810
基調講演:人とAIをつなぐIoTの今と未来 ー 「フィジカル」と「デジタル」が出会うその先へ【SORACOM Discovery 2026】
soracom
PRO
0
360
PLaMo 3.0 Primeの事後学習
pfn
PRO
0
200
AI時代におけるエンジニアの新たな役割──FDEとクオリアの探求/登壇資料(戸井田 裕貴)
hacobu
PRO
0
680
Atlassian Cloudサポート業務でのAIエージェント活用事例
smt7174
0
120
Featured
See All Featured
Building AI with AI
inesmontani
PRO
1
1.1k
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
550
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
650
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4.2k
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
The Curse of the Amulet
leimatthew05
2
13k
Discover your Explorer Soul
emna__ayadi
2
1.2k
Google's AI Overviews - The New Search
badams
0
1.1k
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.8k
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
160
Transcript
©2025 Databricks Inc. — All rights reserved DeepSeek Deep Dive!!!
明日だれかに話したくなる DeepSeek の ”ディープ” なところ 2025年3月4日 赤煉瓦倉庫 第3回
データブリックス・ジャパン株式会社 シニア・スペシャリスト・ソリューション・アーキテクト 大内山 浩(おおうちやま ひろし) ◾職歴 ◾趣味 旅行、音楽、サッカー、Youtube、SUP(を始めたい) 自己紹介 2006~ 2016~ 2019~
2023~
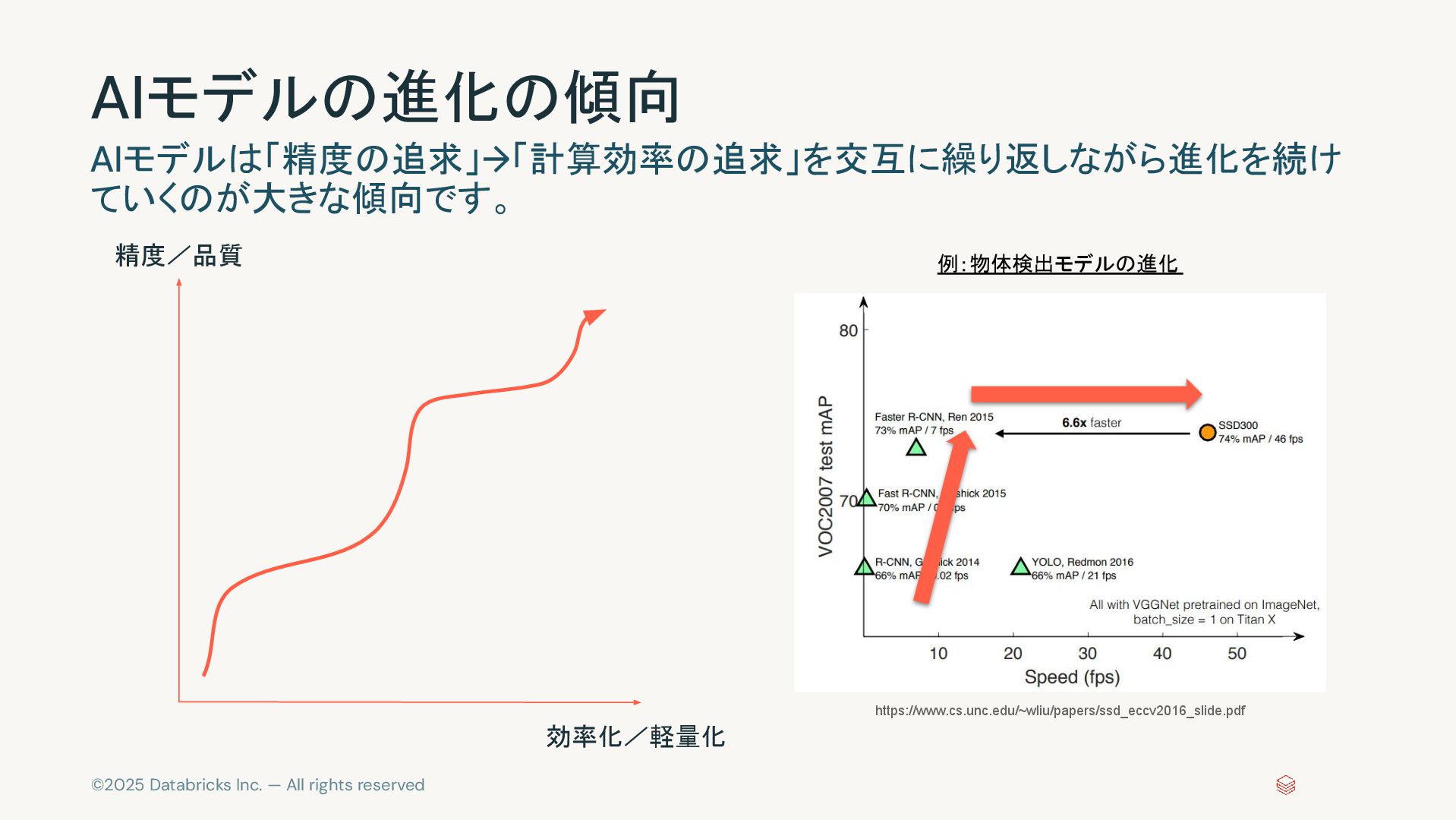
©2025 Databricks Inc. — All rights reserved AIモデルの進化の傾向 AIモデルは「精度の追求」→「計算効率の追求」を交互に繰り返しながら進化を続け ていくのが大きな傾向です。
精度/品質 効率化/軽量化 https://www.cs.unc.edu/~wliu/papers/ssd_eccv2016_slide.pdf 例:物体検出モデルの進化
©2025 Databricks Inc. — All rights reserved 改めてモデルの概要を 眺めてみましょう
©2025 Databricks Inc. — All rights reserved 今回リリースされたDeepSeekのモデル群 • DeepSeek
V3 • DeepSeek V3-Base • DeepSeek V3 (Chat) • DeepSeek R1 (推論能力に優れたモデル ) • DeepSeek-R1-Zero • DeepSeek-R1 • Qwen-base • DeepSeek-R1-Distill-Qwen-1.5B • DeepSeek-R1-Distill-Qwen-7B • DeepSeek-R1-Distill-Qwen-14B • DeepSeek-R1-Distill-Qwen-32B • Llama-base • DeepSeek-R1-Distill-Llama-8B • DeepSeek-R1-Distill-Llama-70B オリジナルモデル (Original Models) 蒸留モデル (Distill Models) オリジナルモデルに加えて、複数種類の蒸留モデルがリリースされている ※ 蒸留モデルとは、既存の基盤モデル( Llama、Qwenなど)に対して、 DeepSeek-R1の入 出力を学習データとして教師ありファインチューニングを適用したもの https://huggingface.co/deepseek-ai
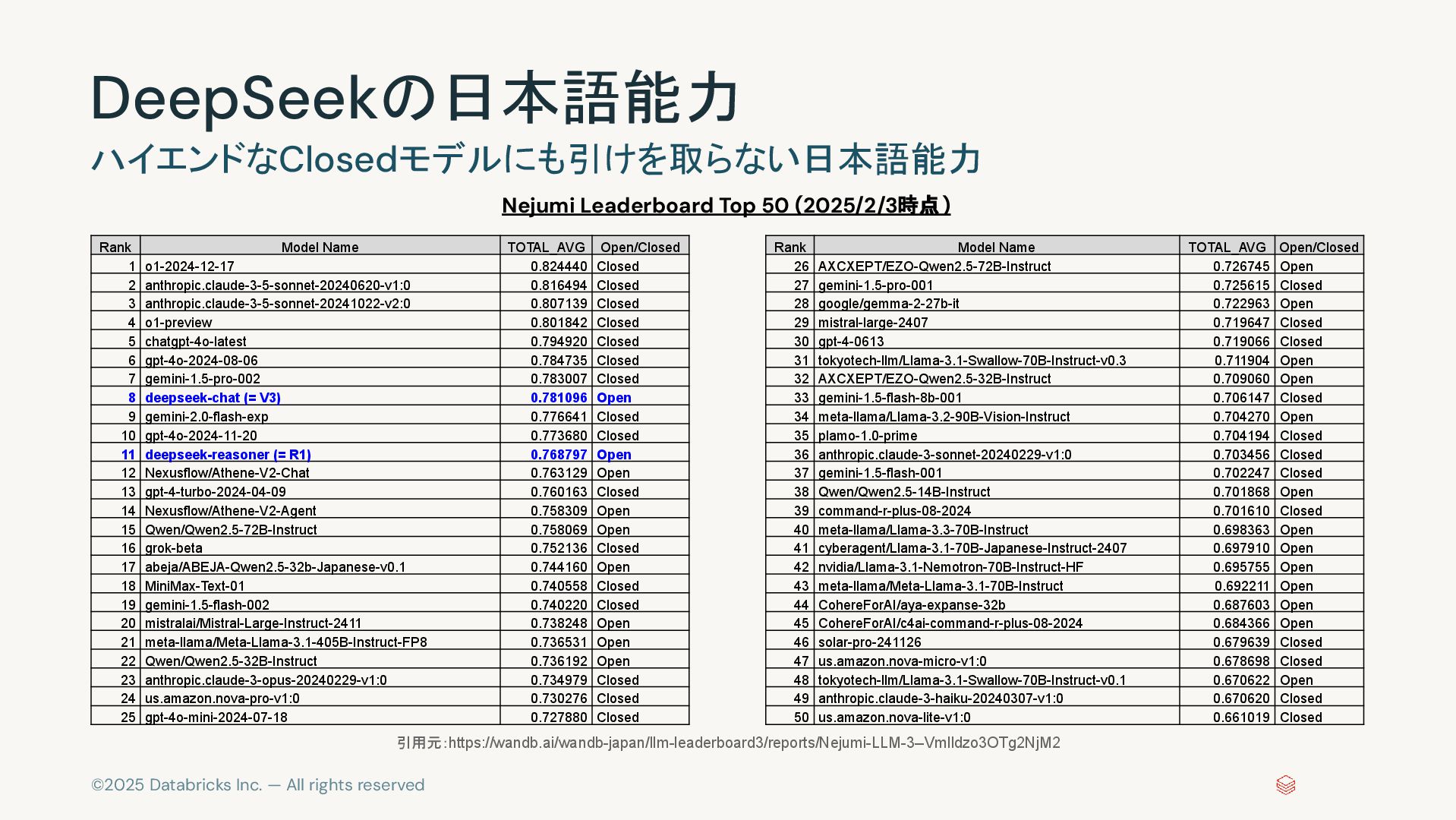
©2025 Databricks Inc. — All rights reserved DeepSeekの日本語能力 ハイエンドなClosedモデルにも引けを取らない日本語能力 Rank
Model Name TOTAL_AVG Open/Closed 1 o1-2024-12-17 0.824440 Closed 2 anthropic.claude-3-5-sonnet-20240620-v1:0 0.816494 Closed 3 anthropic.claude-3-5-sonnet-20241022-v2:0 0.807139 Closed 4 o1-preview 0.801842 Closed 5 chatgpt-4o-latest 0.794920 Closed 6 gpt-4o-2024-08-06 0.784735 Closed 7 gemini-1.5-pro-002 0.783007 Closed 8 deepseek-chat (= V3) 0.781096 Open 9 gemini-2.0-flash-exp 0.776641 Closed 10 gpt-4o-2024-11-20 0.773680 Closed 11 deepseek-reasoner (= R1) 0.768797 Open 12 Nexusflow/Athene-V2-Chat 0.763129 Open 13 gpt-4-turbo-2024-04-09 0.760163 Closed 14 Nexusflow/Athene-V2-Agent 0.758309 Open 15 Qwen/Qwen2.5-72B-Instruct 0.758069 Open 16 grok-beta 0.752136 Closed 17 abeja/ABEJA-Qwen2.5-32b-Japanese-v0.1 0.744160 Open 18 MiniMax-Text-01 0.740558 Closed 19 gemini-1.5-flash-002 0.740220 Closed 20 mistralai/Mistral-Large-Instruct-2411 0.738248 Open 21 meta-llama/Meta-Llama-3.1-405B-Instruct-FP8 0.736531 Open 22 Qwen/Qwen2.5-32B-Instruct 0.736192 Open 23 anthropic.claude-3-opus-20240229-v1:0 0.734979 Closed 24 us.amazon.nova-pro-v1:0 0.730276 Closed 25 gpt-4o-mini-2024-07-18 0.727880 Closed Rank Model Name TOTAL_AVG Open/Closed 26 AXCXEPT/EZO-Qwen2.5-72B-Instruct 0.726745 Open 27 gemini-1.5-pro-001 0.725615 Closed 28 google/gemma-2-27b-it 0.722963 Open 29 mistral-large-2407 0.719647 Closed 30 gpt-4-0613 0.719066 Closed 31 tokyotech-llm/Llama-3.1-Swallow-70B-Instruct-v0.3 0.711904 Open 32 AXCXEPT/EZO-Qwen2.5-32B-Instruct 0.709060 Open 33 gemini-1.5-flash-8b-001 0.706147 Closed 34 meta-llama/Llama-3.2-90B-Vision-Instruct 0.704270 Open 35 plamo-1.0-prime 0.704194 Closed 36 anthropic.claude-3-sonnet-20240229-v1:0 0.703456 Closed 37 gemini-1.5-flash-001 0.702247 Closed 38 Qwen/Qwen2.5-14B-Instruct 0.701868 Open 39 command-r-plus-08-2024 0.701610 Closed 40 meta-llama/Llama-3.3-70B-Instruct 0.698363 Open 41 cyberagent/Llama-3.1-70B-Japanese-Instruct-2407 0.697910 Open 42 nvidia/Llama-3.1-Nemotron-70B-Instruct-HF 0.695755 Open 43 meta-llama/Meta-Llama-3.1-70B-Instruct 0.692211 Open 44 CohereForAI/aya-expanse-32b 0.687603 Open 45 CohereForAI/c4ai-command-r-plus-08-2024 0.684366 Open 46 solar-pro-241126 0.679639 Closed 47 us.amazon.nova-micro-v1:0 0.678698 Closed 48 tokyotech-llm/Llama-3.1-Swallow-70B-Instruct-v0.1 0.670622 Open 49 anthropic.claude-3-haiku-20240307-v1:0 0.670620 Closed 50 us.amazon.nova-lite-v1:0 0.661019 Closed 引用元:https://wandb.ai/wandb-japan/llm-leaderboard3/reports/Nejumi-LLM-3--Vmlldzo3OTg2NjM2 Nejumi Leaderboard Top 50 (2025/2/3時点)
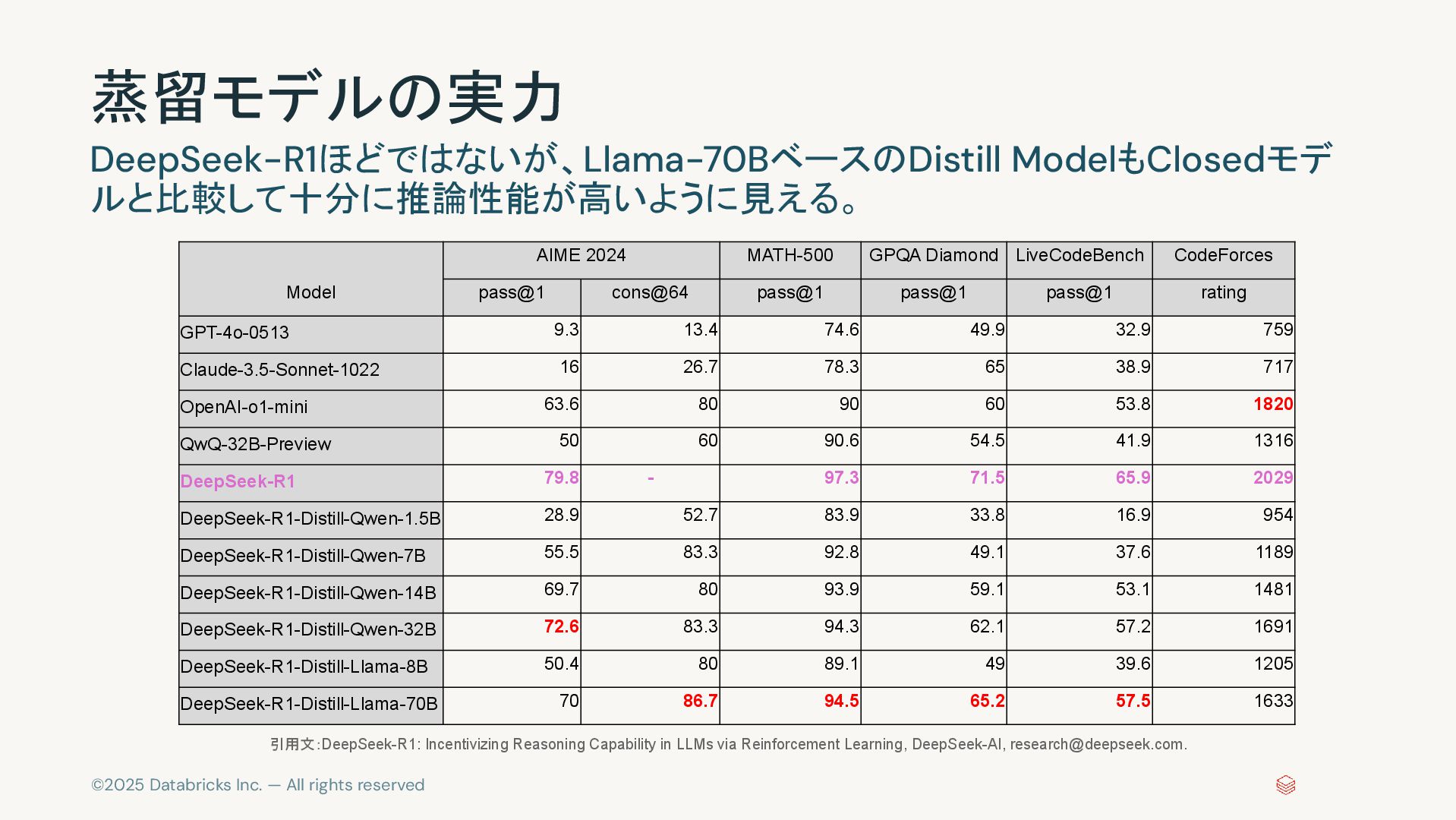
©2025 Databricks Inc. — All rights reserved 蒸留モデルの実力 DeepSeek-R1ほどではないが、Llama-70BベースのDistill ModelもClosedモデ
ルと比較して十分に推論性能が高いように見える。 Model AIME 2024 MATH-500 GPQA Diamond LiveCodeBench CodeForces pass@1 cons@64 pass@1 pass@1 pass@1 rating GPT-4o-0513 9.3 13.4 74.6 49.9 32.9 759 Claude-3.5-Sonnet-1022 16 26.7 78.3 65 38.9 717 OpenAI-o1-mini 63.6 80 90 60 53.8 1820 QwQ-32B-Preview 50 60 90.6 54.5 41.9 1316 DeepSeek-R1 79.8 - 97.3 71.5 65.9 2029 DeepSeek-R1-Distill-Qwen-1.5B 28.9 52.7 83.9 33.8 16.9 954 DeepSeek-R1-Distill-Qwen-7B 55.5 83.3 92.8 49.1 37.6 1189 DeepSeek-R1-Distill-Qwen-14B 69.7 80 93.9 59.1 53.1 1481 DeepSeek-R1-Distill-Qwen-32B 72.6 83.3 94.3 62.1 57.2 1691 DeepSeek-R1-Distill-Llama-8B 50.4 80 89.1 49 39.6 1205 DeepSeek-R1-Distill-Llama-70B 70 86.7 94.5 65.2 57.5 1633 引用文:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, DeepSeek-AI,
[email protected]
.
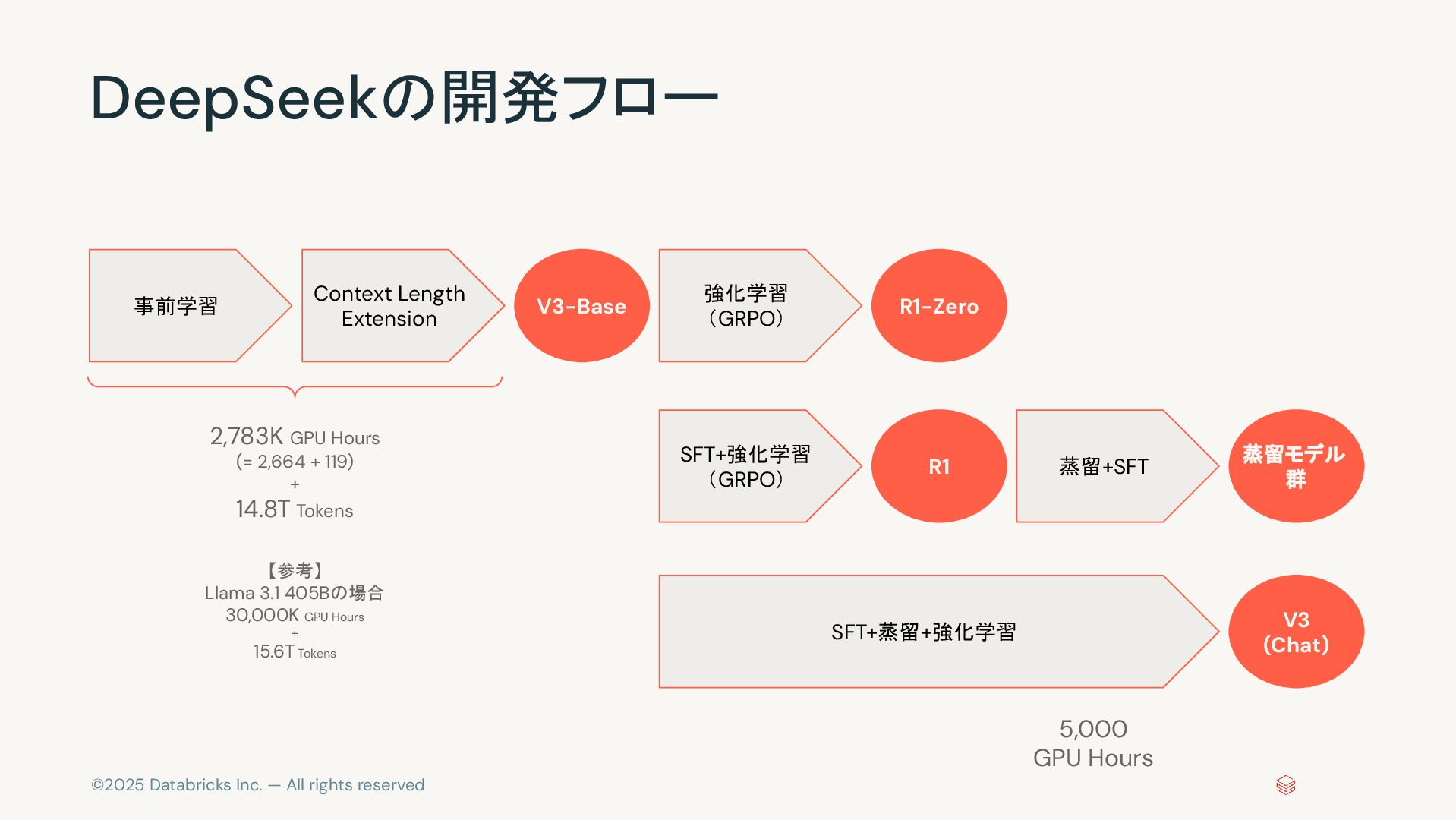
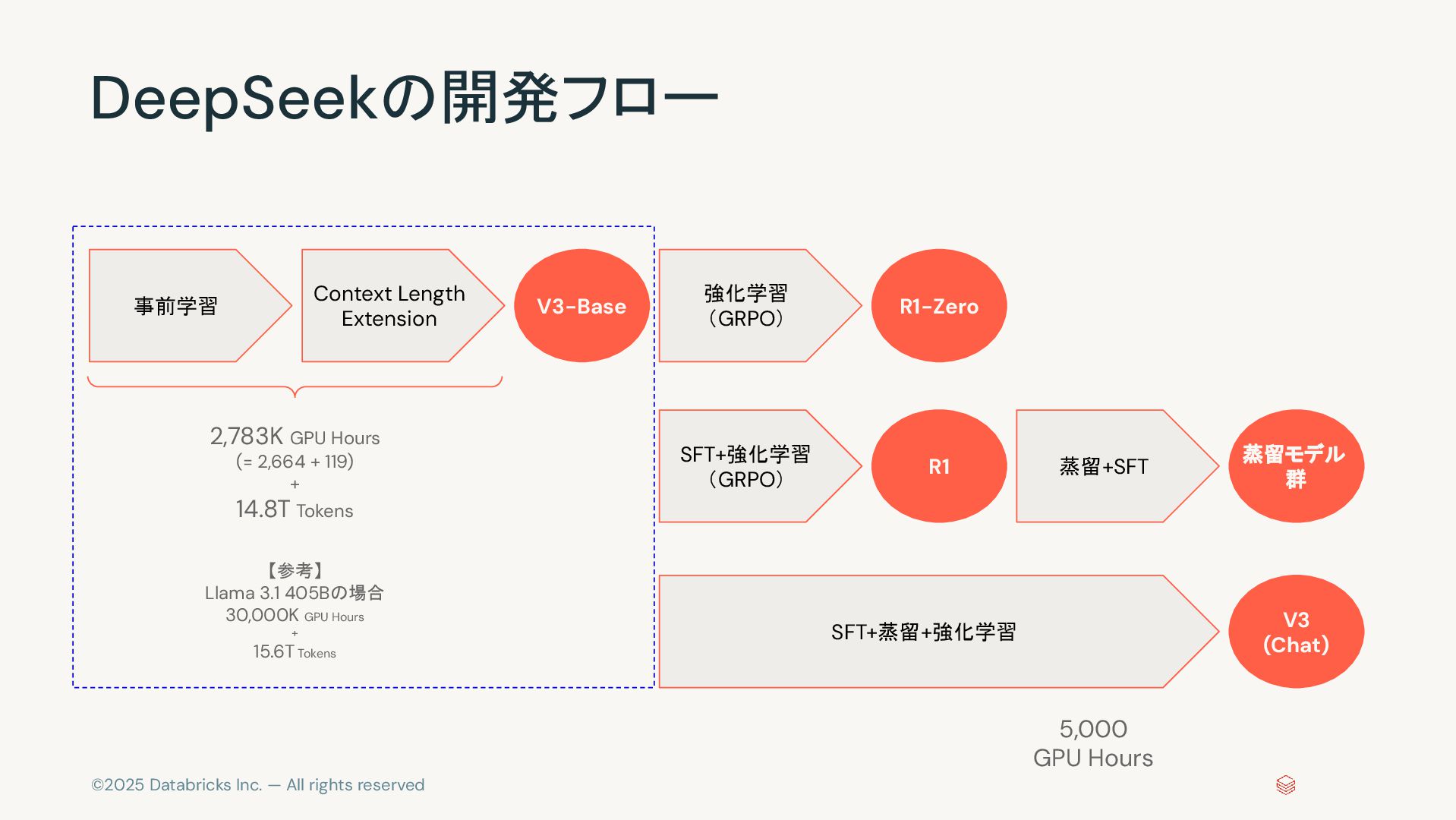
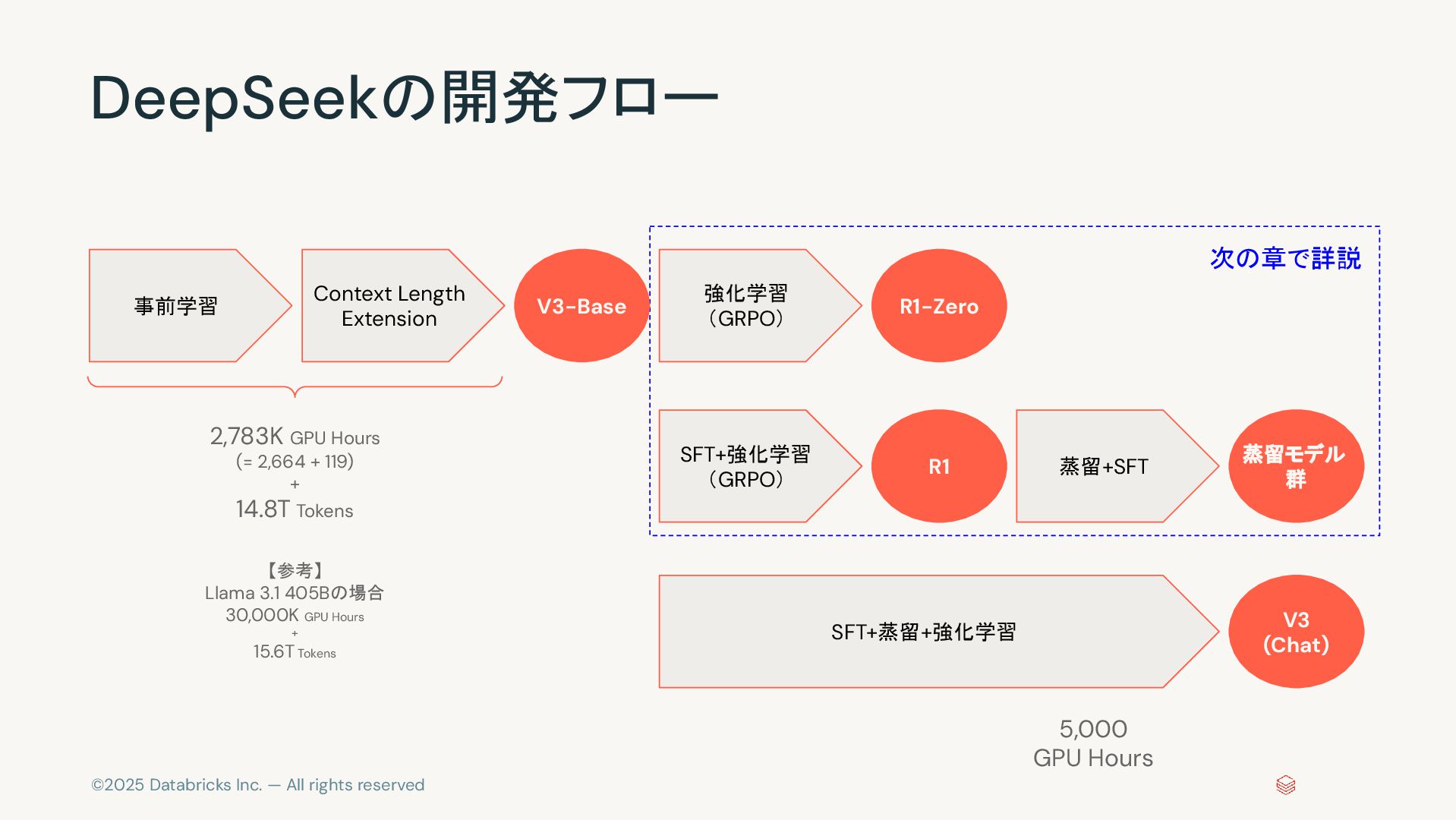
©2025 Databricks Inc. — All rights reserved DeepSeekの開発フロー Context Length
Extension V3-Base 強化学習 (GRPO) SFT+強化学習 (GRPO) R1-Zero R1 蒸留+SFT 蒸留モデル 群 SFT+蒸留+強化学習 V3 (Chat) 事前学習 5,000 GPU Hours 2,783K GPU Hours (= 2,664 + 119) + 14.8T Tokens 【参考】 Llama 3.1 405Bの場合 30,000K GPU Hours + 15.6T Tokens
©2025 Databricks Inc. — All rights reserved で、何がすごいのか?
©2025 Databricks Inc. — All rights reserved OpenAIやGeminiを 超えるモデルを 作るぞ!!
©2025 Databricks Inc. — All rights reserved ただし、 1 /
10のリソース で。。。
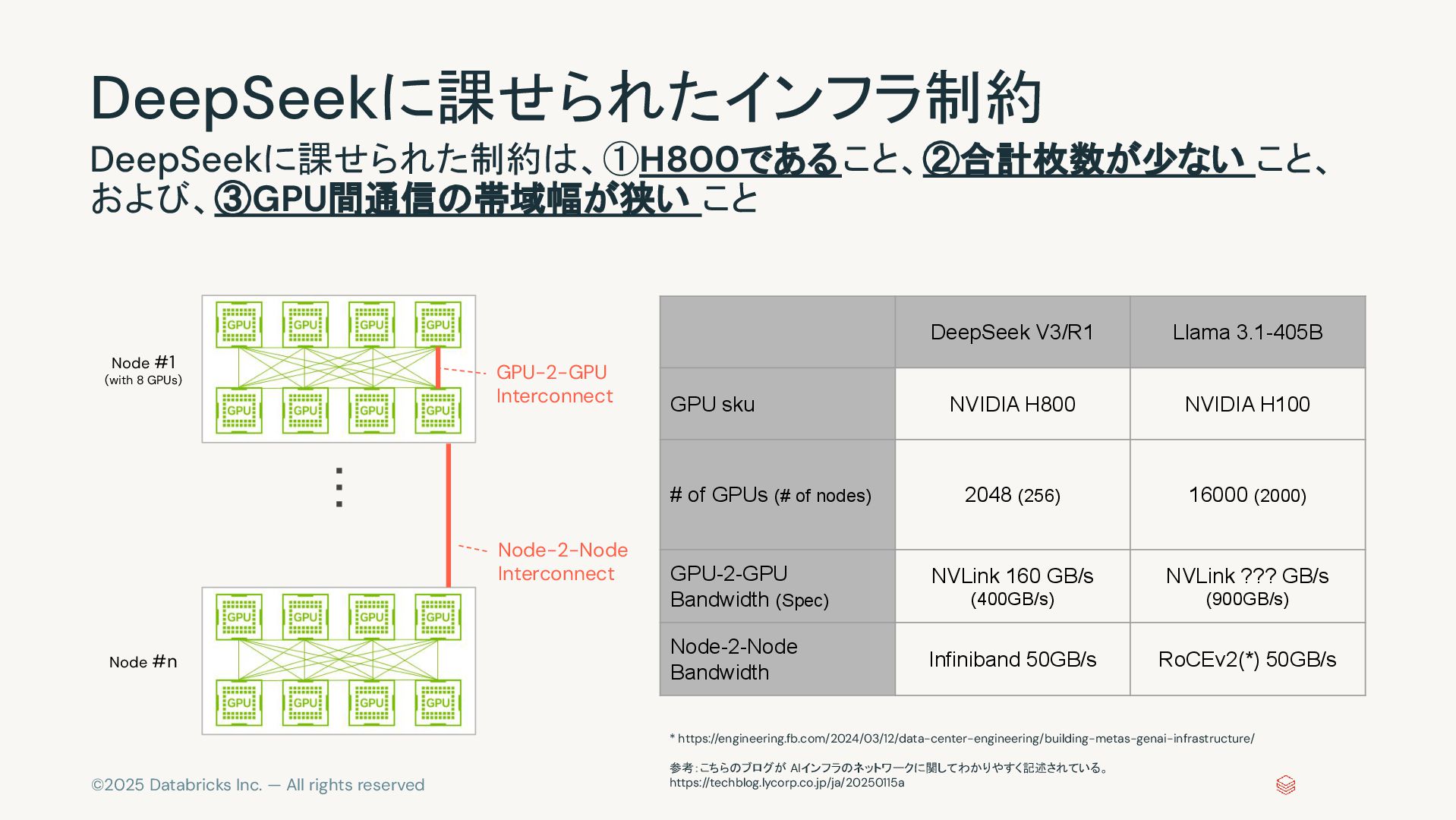
©2025 Databricks Inc. — All rights reserved DeepSeekに課せられたインフラ制約 DeepSeekに課せられた制約は、①H800であること、②合計枚数が少ない こと、
および、③GPU間通信の帯域幅が狭い こと Node #1 (with 8 GPUs) Node #n ・・・ DeepSeek V3/R1 Llama 3.1-405B GPU sku NVIDIA H800 NVIDIA H100 # of GPUs (# of nodes) 2048 (256) 16000 (2000) GPU-2-GPU Bandwidth (Spec) NVLink 160 GB/s (400GB/s) NVLink ??? GB/s (900GB/s) Node-2-Node Bandwidth Infiniband 50GB/s RoCEv2(*) 50GB/s GPU-2-GPU Interconnect Node-2-Node Interconnect * https://engineering.fb.com/2024/03/12/data-center-engineering/building-metas-genai-infrastructure/ 参考:こちらのブログが AIインフラのネットワークに関してわかりやすく記述されている。 https://techblog.lycorp.co.jp/ja/20250115a
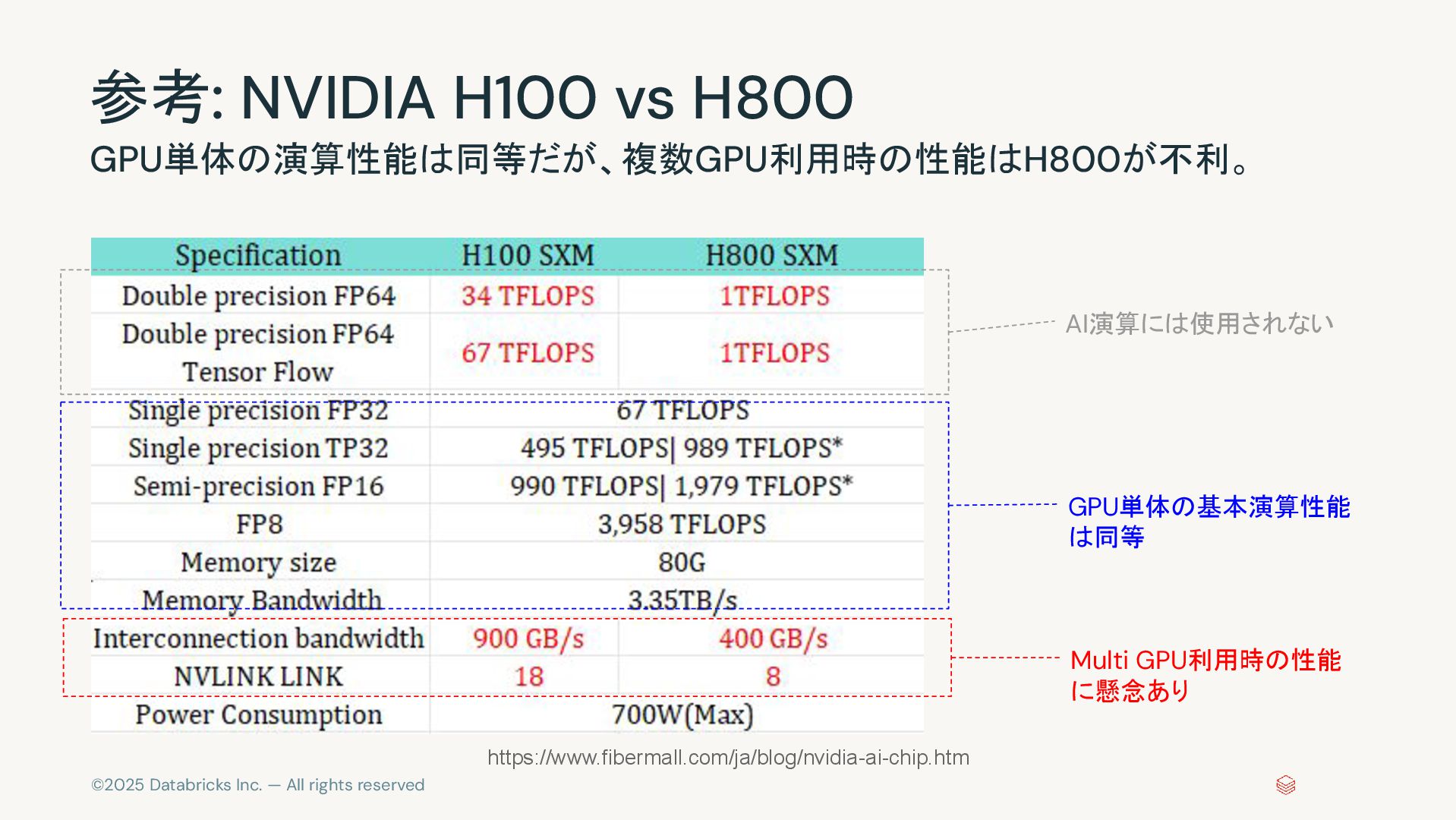
©2025 Databricks Inc. — All rights reserved 参考: NVIDIA H100
vs H800 GPU単体の演算性能は同等だが、複数GPU利用時の性能はH800が不利。 AI演算には使用されない GPU単体の基本演算性能 は同等 Multi GPU利用時の性能 に懸念あり https://www.fibermall.com/ja/blog/nvidia-ai-chip.htm
©2025 Databricks Inc. — All rights reserved 優秀なAI研究者と 最強の最適化職人が 手を組んだ
©2025 Databricks Inc. — All rights reserved DeepSeek V3/R1に導入されている技術 •
Model Architecture • Multi-Head Latent Attention (MLA) 🌙 • DeepSeekMoE ⭐ 🌙 • Auxiliary-Loss-Free Load Balancing 🌙 • Multi-Token Prediction (MTP) ⭐ • Infrastructure • DualPipe Algorithm 🌙 • Efficient Cross-Node All-to-All Communication Kernels 🌙 • Memory Saving Techniques 🌙 • FP8 Mixed Precision Training 🌙 • Low-Precision Storage and Communication 🌙 • Deployment Strategy: Prefilling & Decoding • Pre-Training • Data Construction: Document Packing & Fill-in-Middle (FIM) Strategy • Tokenizer: BPE tokenizer with a 128K token vocabulary • Hyper-Parameters: 61 Transformer layers, 1 shared expert & 256 routed experts, 8 experts activated per token • Long Context Extension: YaRN • Post-Training • Supervised Fine-Tuning (SFT) ⭐ • Reinforcement Learning (RL): Group Relative Policy Optimization (GRPO) ⭐ 🌙 • Knowledge Distillation ⭐ • Self-Rewarding ⭐ モデル精度向上に寄与 🌙 演算の軽量化/効率化に寄与
©2025 Databricks Inc. — All rights reserved 限られたリソースから 生み出された まさに
怪作* モデル * 常識にとらわれない、怪しげで不思議な作品
©2025 Databricks Inc. — All rights reserved もう一つすごいことは “オープン” であること
©2025 Databricks Inc. — All rights reserved DeepSeekは、コンピューティングの歴史から学んだ 3つの重要な教訓を思い出させてくれ ます。
1) コンピューティングは気体の法則に従う。 劇的に安価にすることで、市場が拡大します。 市場は間違った認識を持っているが、これにより AIがより広く普及するようになります。 2) エンジニアリングとは制約を克服することである。 中国のエンジニアは限られたリソー スしか持っていなかったため、創造的なソリューションを見つけなければなりませんでした。 3) オープンが勝利する。 DeepSeekは、基礎的なAIモデルの作業がますます閉鎖的に なっている世界をリセットするのに役立つでしょう。 DeepSeekチームに感謝します。 元インテルCEO パット・ゲルシンガー https://x.com/PGelsinger/status/1883896837427585035
©2025 Databricks Inc. — All rights reserved DeepSeekの開発フロー Context Length
Extension V3-Base 強化学習 (GRPO) SFT+強化学習 (GRPO) R1-Zero R1 蒸留+SFT 蒸留モデル 群 SFT+蒸留+強化学習 V3 (Chat) 事前学習 5,000 GPU Hours 2,783K GPU Hours (= 2,664 + 119) + 14.8T Tokens 【参考】 Llama 3.1 405Bの場合 30,000K GPU Hours + 15.6T Tokens
©2025 Databricks Inc. — All rights reserved 特徴①:MoE
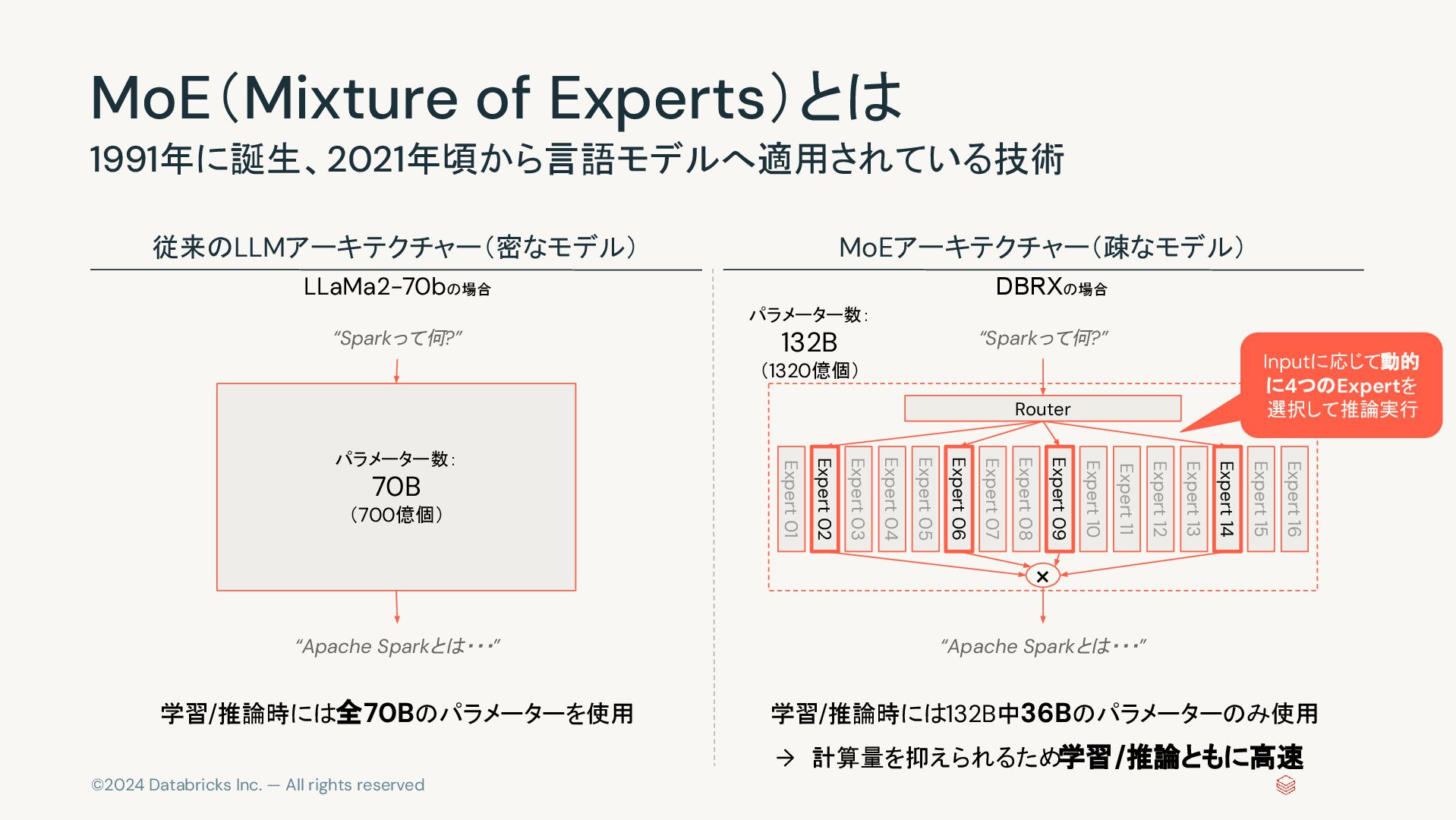
©2024 Databricks Inc. — All rights reserved MoE(Mixture of Experts)とは
1991年に誕生、2021年頃から言語モデルへ適用されている技術 Expert 01 パラメーター数: 70B (700億個) Router “Sparkって何?” “Sparkって何?” “Apache Sparkとは・・・” “Apache Sparkとは・・・” × 従来のLLMアーキテクチャー(密なモデル) MoEアーキテクチャー(疎なモデル) Expert 02 Expert 03 Expert 04 Expert 05 Expert 06 Expert 07 Expert 08 Expert 09 Expert 10 Expert 11 Expert 12 Expert 13 Expert 14 Expert 15 Expert 16 Inputに応じて動的 に4つのExpertを 選択して推論実行 DBRXの場合 パラメーター数: 132B (1320億個) 学習/推論時には全70Bのパラメーターを使用 学習/推論時には132B中36Bのパラメーターのみ使用 → 計算量を抑えられるため学習/推論ともに高速 LLaMa2-70bの場合
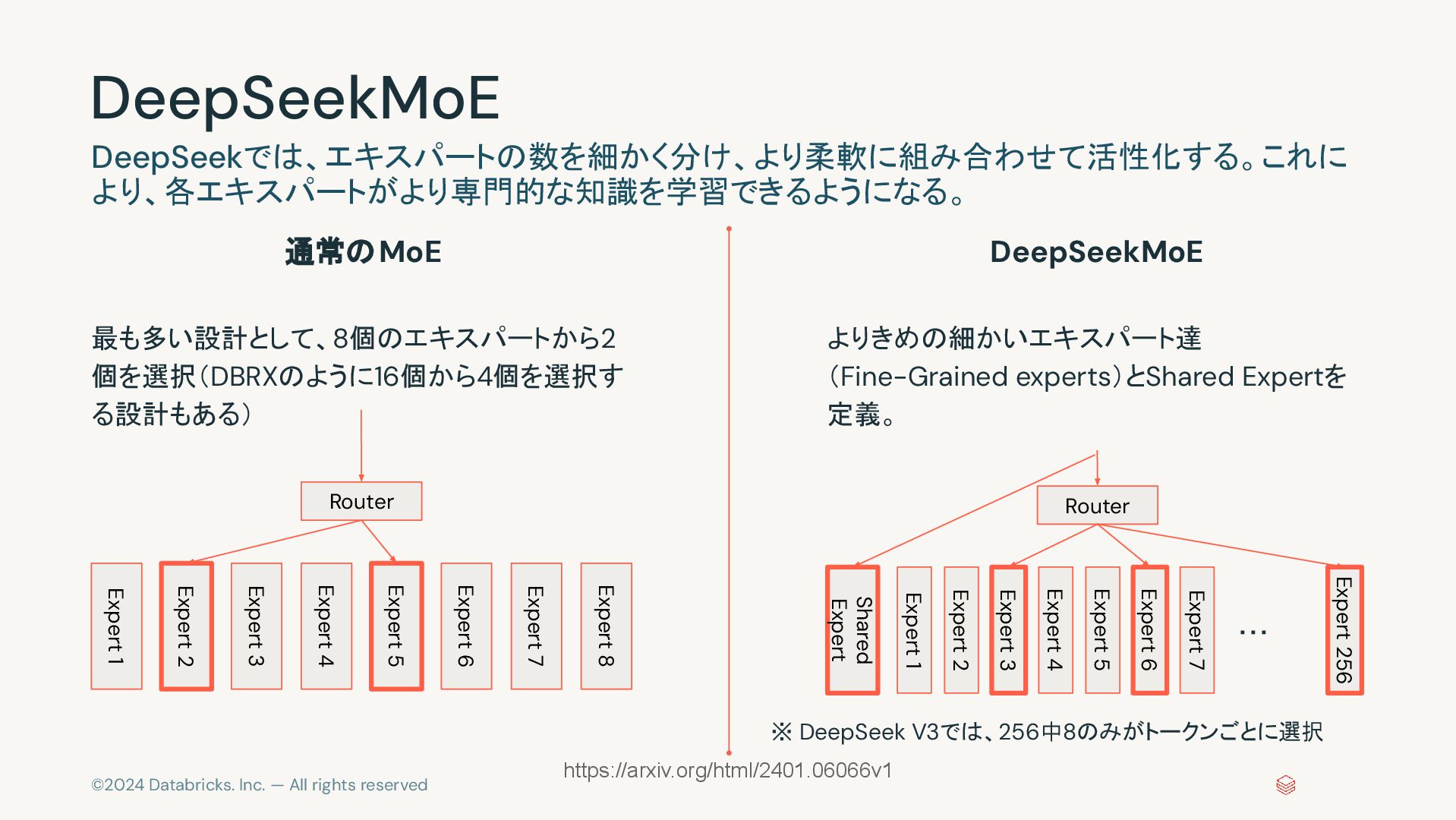
©2024 Databricks. Inc. — All rights reserved DeepSeekMoE 最も多い設計として、8個のエキスパートから2 個を選択(DBRXのように16個から4個を選択す
る設計もある) よりきめの細かいエキスパート達 (Fine-Grained experts)とShared Expertを 定義。 DeepSeekでは、エキスパートの数を細かく分け、より柔軟に組み合わせて活性化する。これに より、各エキスパートがより専門的な知識を学習できるようになる。 通常のMoE DeepSeekMoE Expert 1 Expert 2 Expert 3 Expert 4 Expert 5 Expert 6 Expert 7 Expert 8 Router https://arxiv.org/html/2401.06066v1 Shared Expert Expert 1 Expert 2 Expert 3 Expert 4 Expert 5 Expert 6 Expert 7 Router Expert 256 ・・・ ※ DeepSeek V3では、256中8のみがトークンごとに選択
©2024 Databricks. Inc. — All rights reserved DeepSeekMoE 2024年1月に発表 https://arxiv.org/abs/2401.06066v1
©2025 Databricks Inc. — All rights reserved 特徴②:インフラレベルの最適化 超弩級な
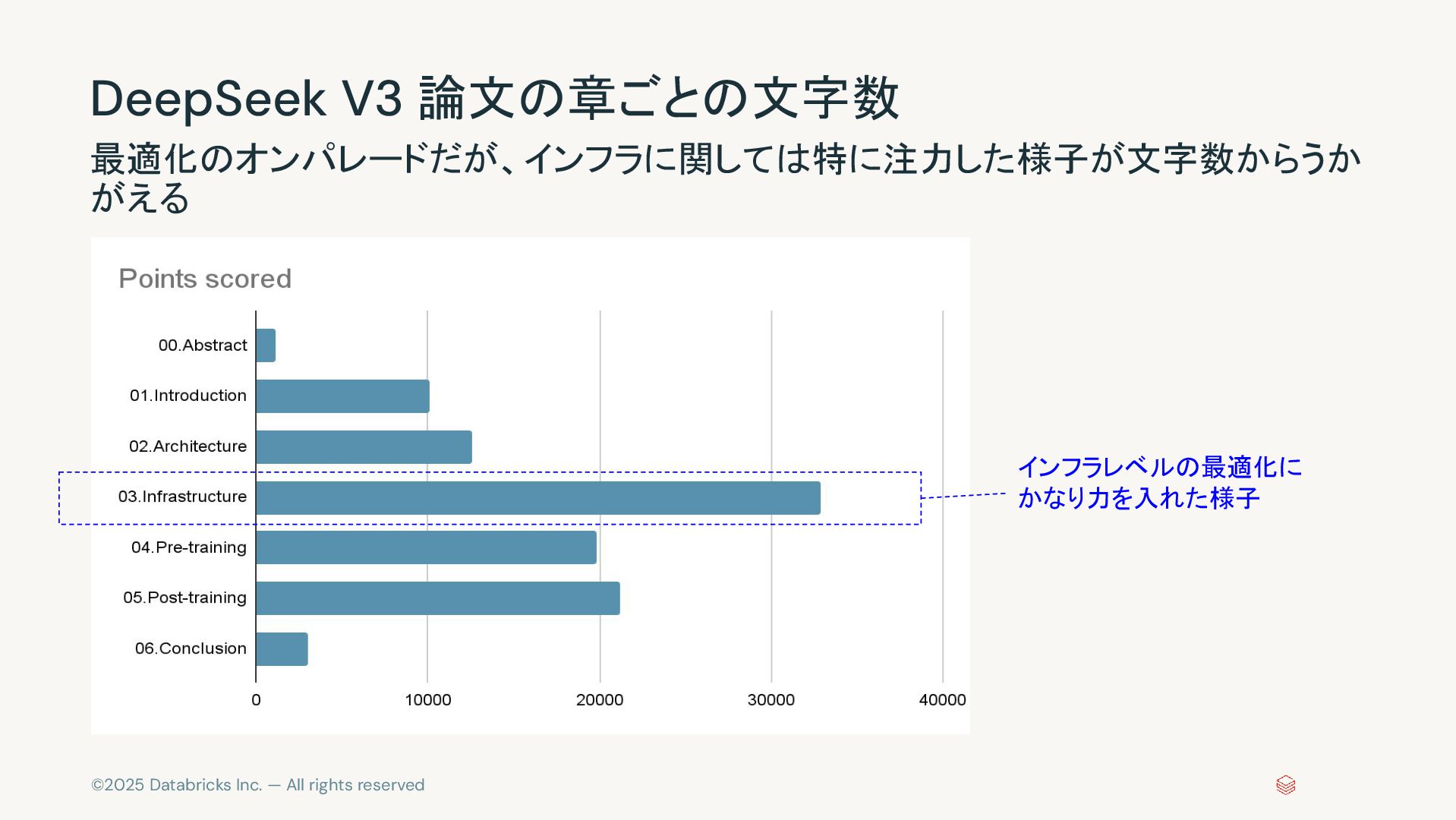
©2025 Databricks Inc. — All rights reserved DeepSeek V3 論文の章ごとの文字数
最適化のオンパレードだが、インフラに関しては特に注力した様子が文字数からうか がえる インフラレベルの最適化に かなり力を入れた様子
©2025 Databricks Inc. — All rights reserved CUDAではなくPTXを使用して開発
©2024 Databricks Inc. — All rights reserved NVIDIA CUDAとは PyTorch
/ TensorFlowで当然のようにGPUが使えるのはCUDAのおかげ GPU OS / Driver CUDA PyTorch / TensorFlow AI モデル • NVIDIAにより2006年から開発されているGPUを汎用的に使用するため の開発用ソフトウェア ◦ Proprietary software (つまりOSSではないが無償で利用可能) ◦ C言語、C++、Fortranなどで実装可能 • “cuDNN”など深層学習特化のCUDAライブラリもあり、GPU版PyTorch / TensorFlowの下でも動いている • 他にも”cuML”、“cuDF”、“cuGraph”などデータサイエンス向けライブラリ も充実。NVIDIA RAPIDS(NVIDIA版scikit-learnみたいなもの)の下で動 いている • NVIDIA GPU上でしか動かない。
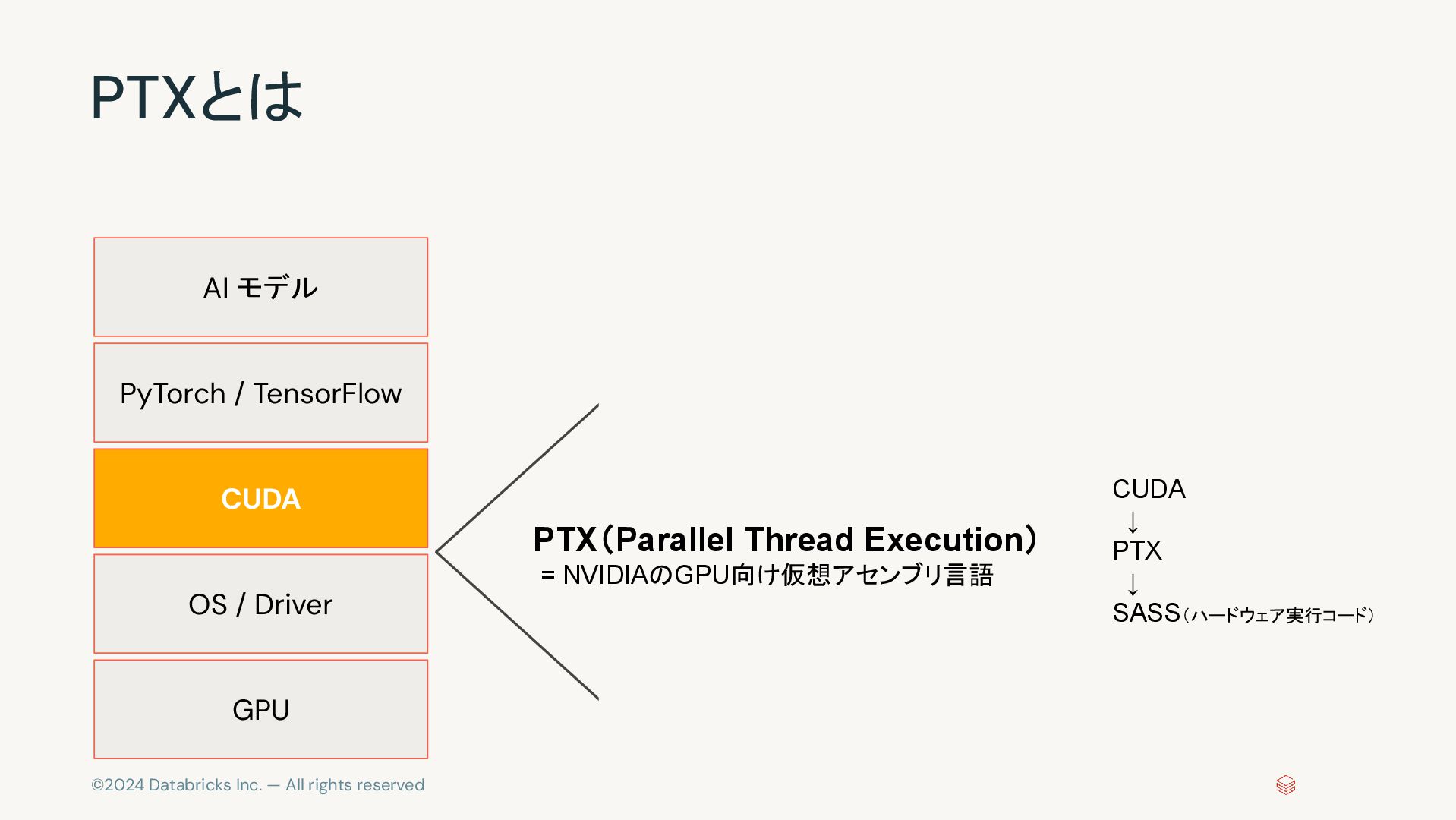
©2024 Databricks Inc. — All rights reserved PTXとは GPU OS
/ Driver CUDA PyTorch / TensorFlow AI モデル PTX(Parallel Thread Execution) = NVIDIAのGPU向け仮想アセンブリ言語 CUDA ↓ PTX ↓ SASS(ハードウェア実行コード)
©2024 Databricks Inc. — All rights reserved PTXとは • PTX(Parallel
Thread Execution)は、NVIDIAのGPU 向け仮想アセンブリ言語 • CUDAコードは最終的にPTXにコ ンパイルされ、その後、GPUアー キテクチャに最適化されたバイナ リコード(SASS: Streaming Assembler)に変換される • CUDA → PTX → SASS(ハードウェ ア実行コード) • PTXはGPUのバイトコードのような役 割を果たす 1. CUDAのオーバーヘッドを回避 a. CUDAのランタイムAPIのオーバー ヘッドを回避し、低レベルの最適化 を直接行うためにPTXを記述 2. GPUアーキテクチャに最適化 a. PTXを直接記述すると、特定のGPU アーキテクチャ向けにCUDA以上の 最適化が可能 3. CUDAのバージョン依存を回避 a. PTXを直接書くことでCUDAのAPI変 更に影響されずにGPUプログラムを 動かすことが可能 1. 開発が難しい a. PTXはCUDAよりも低レベルで、アセ ンブリ言語に近いため、開発やデ バッグが困難です。 2. GPUアーキテクチャ依存 a. PTXは仮想アセンブリ言語ですが、 最適化には特定のGPU世代 (sm_75 など)を考慮する必要があ ります。 3. メンテナンスコストが高い a. CUDAのAPIは抽象化が進んでいる ため、CUDAコードの方が保守性が 高いです。 PTX概要 メリット デメリット https://acoustype.com/?p=2434 https://note.com/akikito/n/n6cf81b33663d https://www.panewslab.com/jp/articledetails/g6p9f7qa59nq.html
©2024 Databricks Inc. — All rights reserved PTXのプログラミング例 C言語やC++の拡張ライブラリとして提供されている extern
"C" void convolutionRowCPU(float *h_Dst, float *h_Src, float *h_Kernel, int imageW, int imageH, int kernelR) { for (int y = 0; y < imageH; y++) for (int x = 0; x < imageW; x++) { float sum = 0; for (int k = -kernelR; k <= kernelR; k++) { int d = x + k; if (d >= 0 && d < imageW) sum += h_Src[y * imageW + d] * h_Kernel[kernelR - k]; } h_Dst[y * imageW + x] = sum; } } PTXプログラムはCUDAよりも低レベルなコードになる CUDA PTX .version 6.5 .target sm_75 .address_size 64 .entry my_kernel (.param .u64 data) { .reg .b32 r1, r2; ld.param.u64 r1, [data]; add.u32 r2, r1, 10; st.global.u32 [r1], r2; } https://acoustype.com/?p=2434
©2025 Databricks Inc. — All rights reserved 画期的な計算効率の向上手法 「DualPipe」
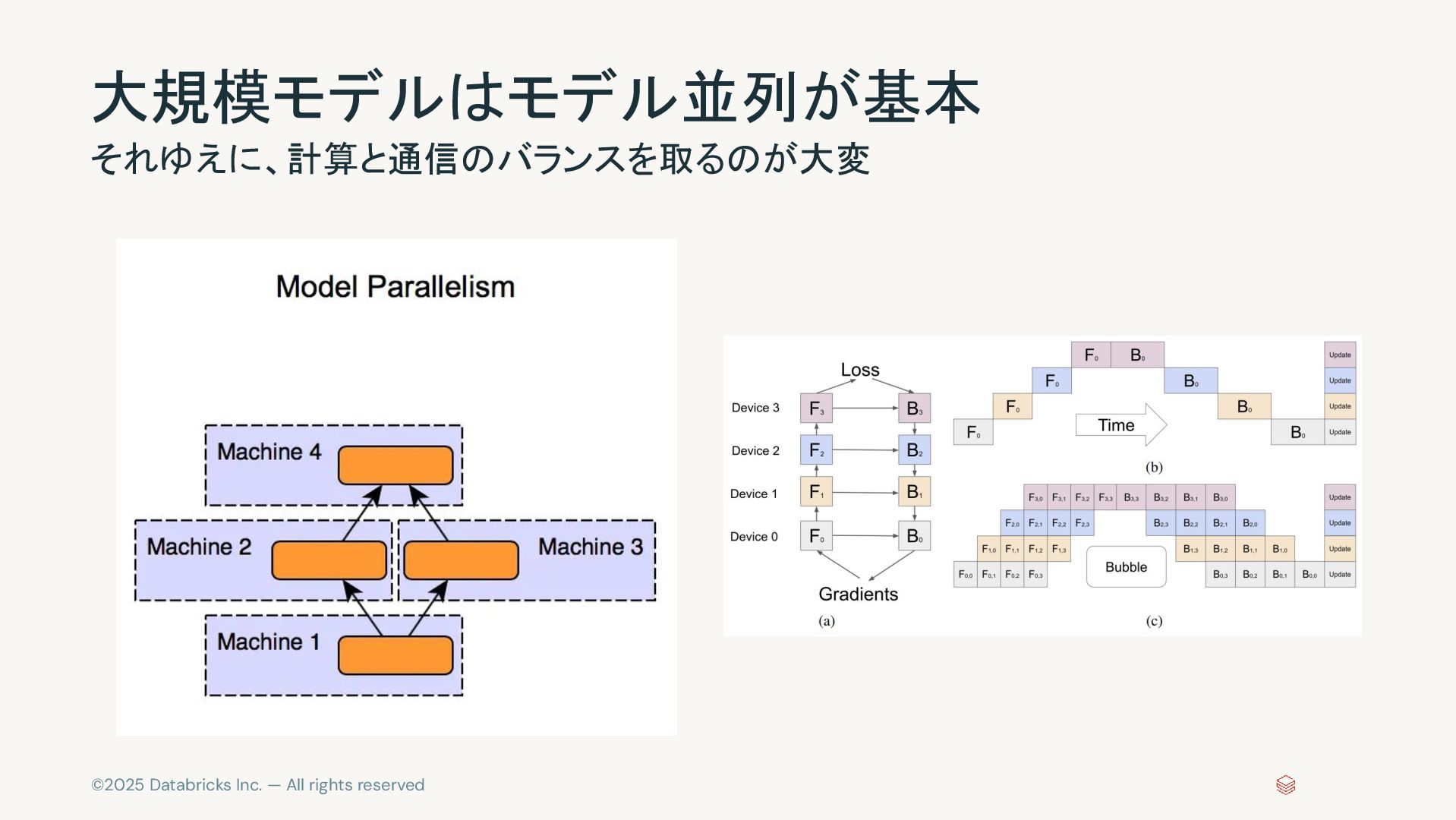
©2025 Databricks Inc. — All rights reserved 大規模モデルはモデル並列が基本 それゆえに、計算と通信のバランスを取るのが大変
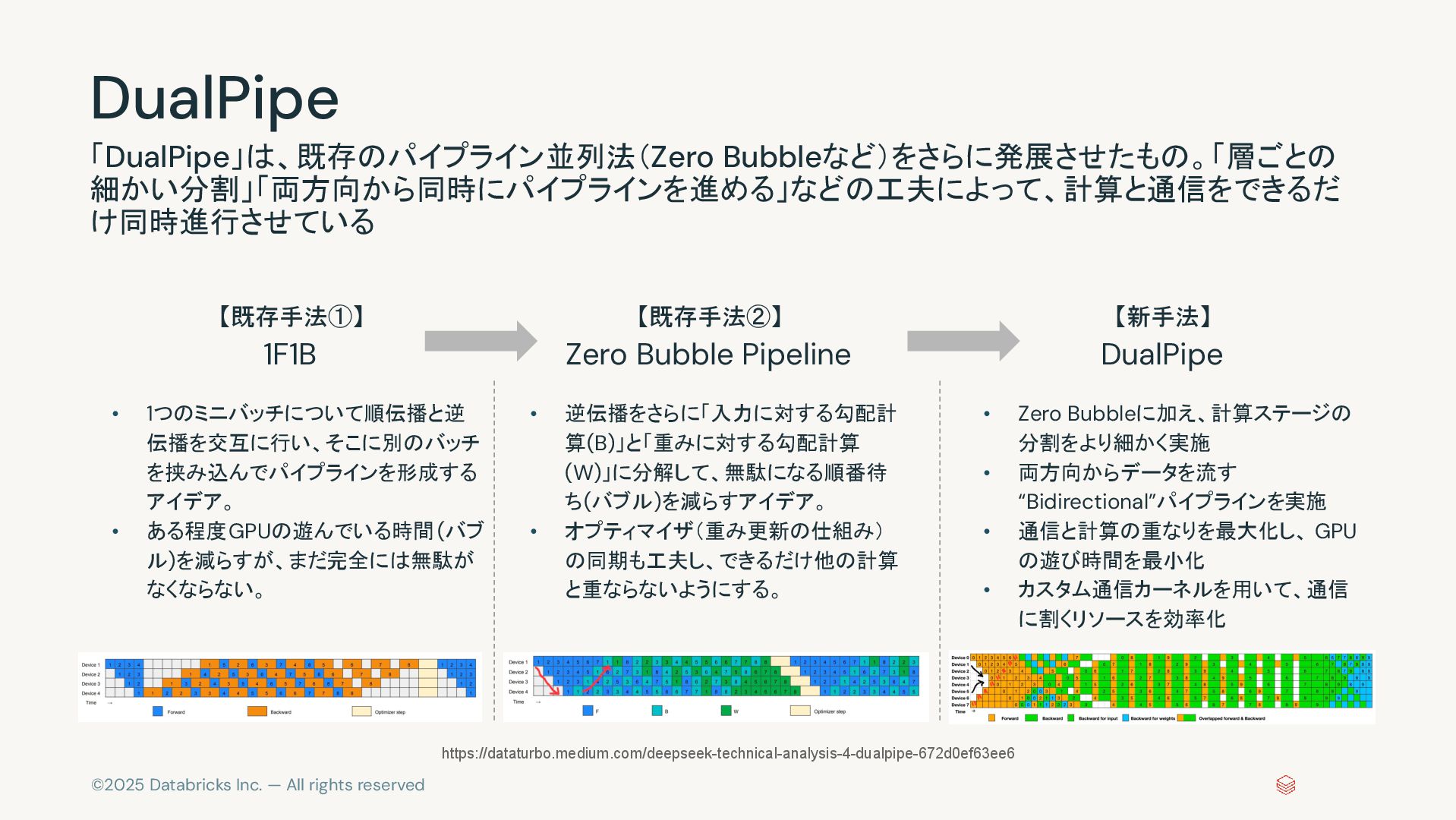
©2025 Databricks Inc. — All rights reserved DualPipe 【既存手法①】 1F1B
「DualPipe」は、既存のパイプライン並列法(Zero Bubbleなど)をさらに発展させたもの。「層ごとの 細かい分割」「両方向から同時にパイプラインを進める」などの工夫によって、計算と通信をできるだ け同時進行させている https://dataturbo.medium.com/deepseek-technical-analysis-4-dualpipe-672d0ef63ee6 【既存手法②】 Zero Bubble Pipeline 【新手法】 DualPipe • 1つのミニバッチについて順伝播と逆 伝播を交互に行い、そこに別のバッチ を挟み込んでパイプラインを形成する アイデア。 • ある程度GPUの遊んでいる時間(バブ ル)を減らすが、まだ完全には無駄が なくならない。 • 逆伝播をさらに「入力に対する勾配計 算(B)」と「重みに対する勾配計算 (W)」に分解して、無駄になる順番待 ち(バブル)を減らすアイデア。 • オプティマイザ(重み更新の仕組み) の同期も工夫し、できるだけ他の計算 と重ならないようにする。 • Zero Bubbleに加え、計算ステージの 分割をより細かく実施 • 両方向からデータを流す “Bidirectional”パイプラインを実施 • 通信と計算の重なりを最大化し、 GPU の遊び時間を最小化 • カスタム通信カーネルを用いて、通信 に割くリソースを効率化
©2025 Databricks Inc. — All rights reserved DeepSeekチームからチップメーカーへの提言 • 通信ハードウェアの最適化
• 高帯域幅を持つインターコネクト( InfiniBandやNVLink)を最大限活用する設計。 • モデルのスケールアップに合わせて、計算と通信の比率を最適化するアーキテクチャの設計。 • 計算ハードウェアの改善 • より効率的なパイプライン並列処理のための専用ハードウェアの設計。 • FP8などの低精度トレーニング向けに最適化された演算ユニットの導入。 • 低精度演算の活用 • 高精度な積算を維持しつつ、低精度( FP8)での演算を可能にするGPUアーキテクチャの強化。 • FP8対応の新しい演算方法(例えば、細粒度の量子化)をサポートするハードウェアの提供。 • 動的な負荷分散とエキスパート管理 • エキスパート並列処理の効率を向上させるため、動的に負荷分散を調整できるハードウェアの設計。 • モデルの実行中に最適なエクスパートルーティングを実現するためのハードウェアサポート。
©2025 Databricks Inc. — All rights reserved DeepSeekの開発フロー Context Length
Extension V3-Base 強化学習 (GRPO) SFT+強化学習 (GRPO) R1-Zero R1 蒸留+SFT 蒸留モデル 群 SFT+蒸留+強化学習 V3 (Chat) 事前学習 5,000 GPU Hours 次の章で詳説 2,783K GPU Hours (= 2,664 + 119) + 14.8T Tokens 【参考】 Llama 3.1 405Bの場合 30,000K GPU Hours + 15.6T Tokens
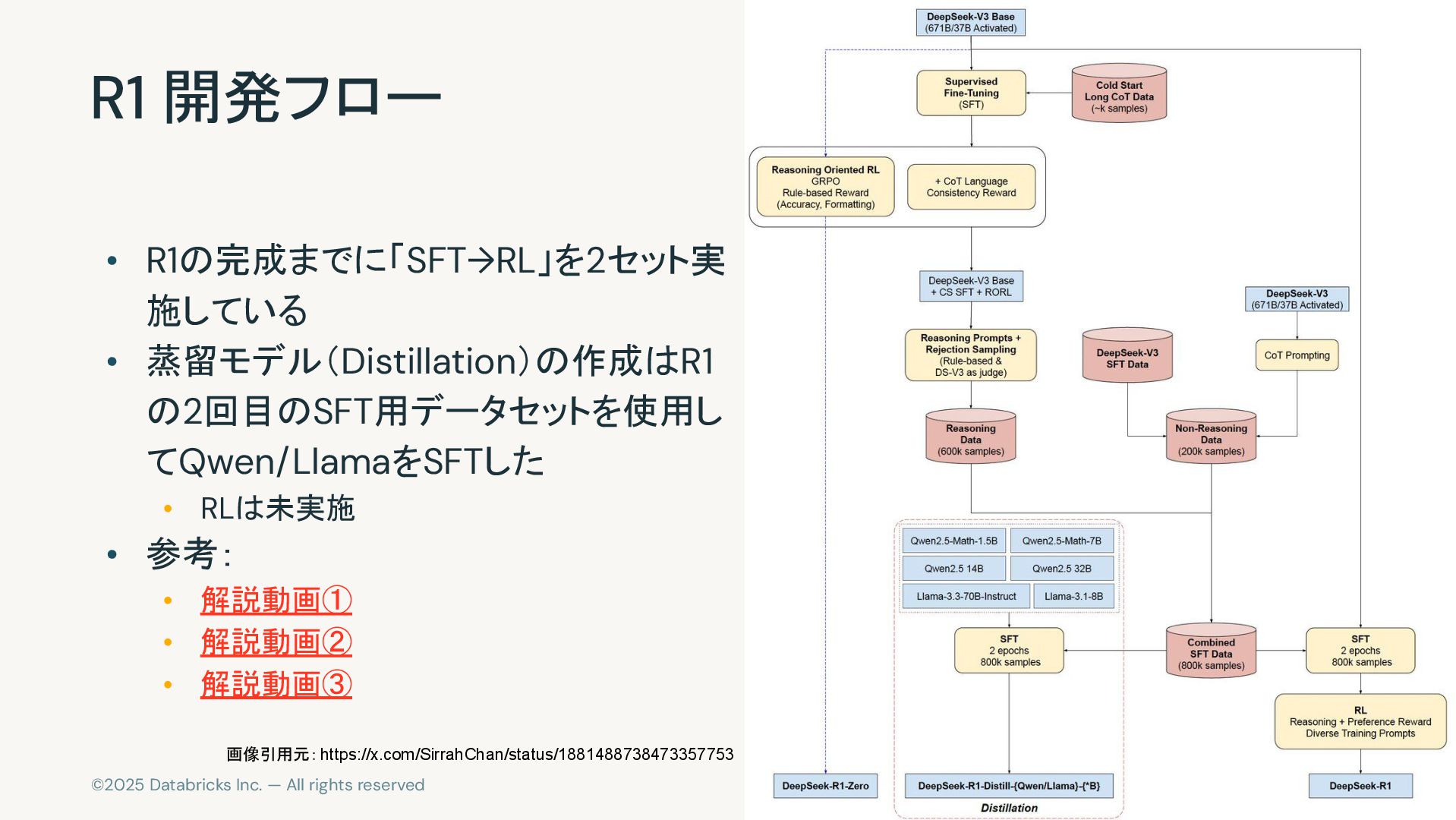
©2025 Databricks Inc. — All rights reserved R1 開発フロー •
R1の完成までに「SFT→RL」を2セット実 施している • 蒸留モデル(Distillation)の作成はR1 の2回目のSFT用データセットを使用し てQwen/LlamaをSFTした • RLは未実施 • 参考: • 解説動画① • 解説動画② • 解説動画③ 画像引用元:https://x.com/SirrahChan/status/1881488738473357753
©2025 Databricks Inc. — All rights reserved 特徴③:強化学習 - GRPO
©2024 Databricks. Inc. — All rights reserved DeepSeekの特徴③:強化学習 - GRPO
GRPO(Group Relative Policy Optimization) • Human Feedbackにより教師データを作成し、それを使用し てReward Modelを構築 • その後、Reward ModelによりLLMの出力を評価し、評価値 が最大なるようにLLMを強化学習 一般的な手法: PPO https://www.brainpad.co.jp/doors/contents/01_tech_2023-05-31-160719/ LLM Reward Model Prompt Answer Reward Loss Answer Label Train Train Human Feedback
©2024 Databricks. Inc. — All rights reserved DeepSeekの特徴③:強化学習 - GRPO
GRPO(Group Relative Policy Optimization) • Human Feedbackにより教師データを作成し、それを使用し てReward Modelを構築 • その後、Reward ModelによりLLMの出力を評価し、評価値 が最大なるようにLLMを強化学習 • 複数のモデル応答をグループ内で比較し、優れた応答を選 択することで、より効率的に学習する手法 • MLベースの報酬モデルではなく、ルールベースの報酬を使 用し演算コストを削減 一般的な手法: PPO DeepSeekの場合:GRPO https://www.brainpad.co.jp/doors/contents/01_tech_2023-05-31-160719/ LLM Reward Model Prompt Answer Reward Loss Answer Label Train Train Human Feedback LLM Prompt Answer 1 Answer 2 Answer 3 ・ ・ Answer N Reward 1 Reward 2 Reward 3 ・ ・ Reward N Loss Train Reward Rule https://arxiv.org/pdf/2402.03300
©2024 Databricks. Inc. — All rights reserved GRPO 2024年4月に発表 https://arxiv.org/abs/2402.03300
©2025 Databricks Inc. — All rights reserved 特徴④:蒸留
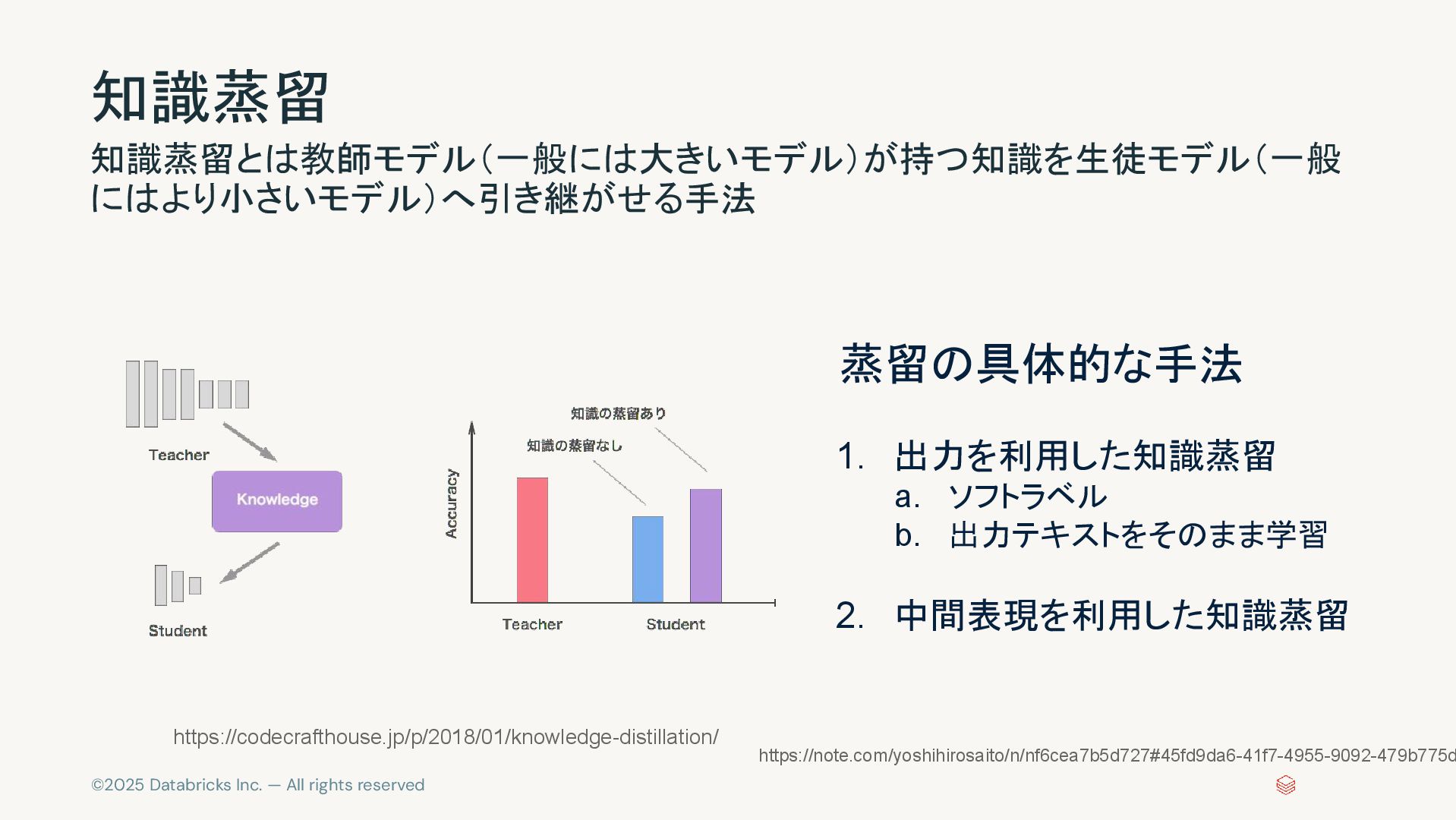
©2025 Databricks Inc. — All rights reserved 知識蒸留 知識蒸留とは教師モデル(一般には大きいモデル)が持つ知識を生徒モデル(一般 にはより小さいモデル)へ引き継がせる手法
https://codecrafthouse.jp/p/2018/01/knowledge-distillation/ 蒸留の具体的な手法 1. 出力を利用した知識蒸留 a. ソフトラベル b. 出力テキストをそのまま学習 2. 中間表現を利用した知識蒸留 https://note.com/yoshihirosaito/n/nf6cea7b5d727#45fd9da6-41f7-4955-9092-479b775d
©2025 Databricks Inc. — All rights reserved 以上です!
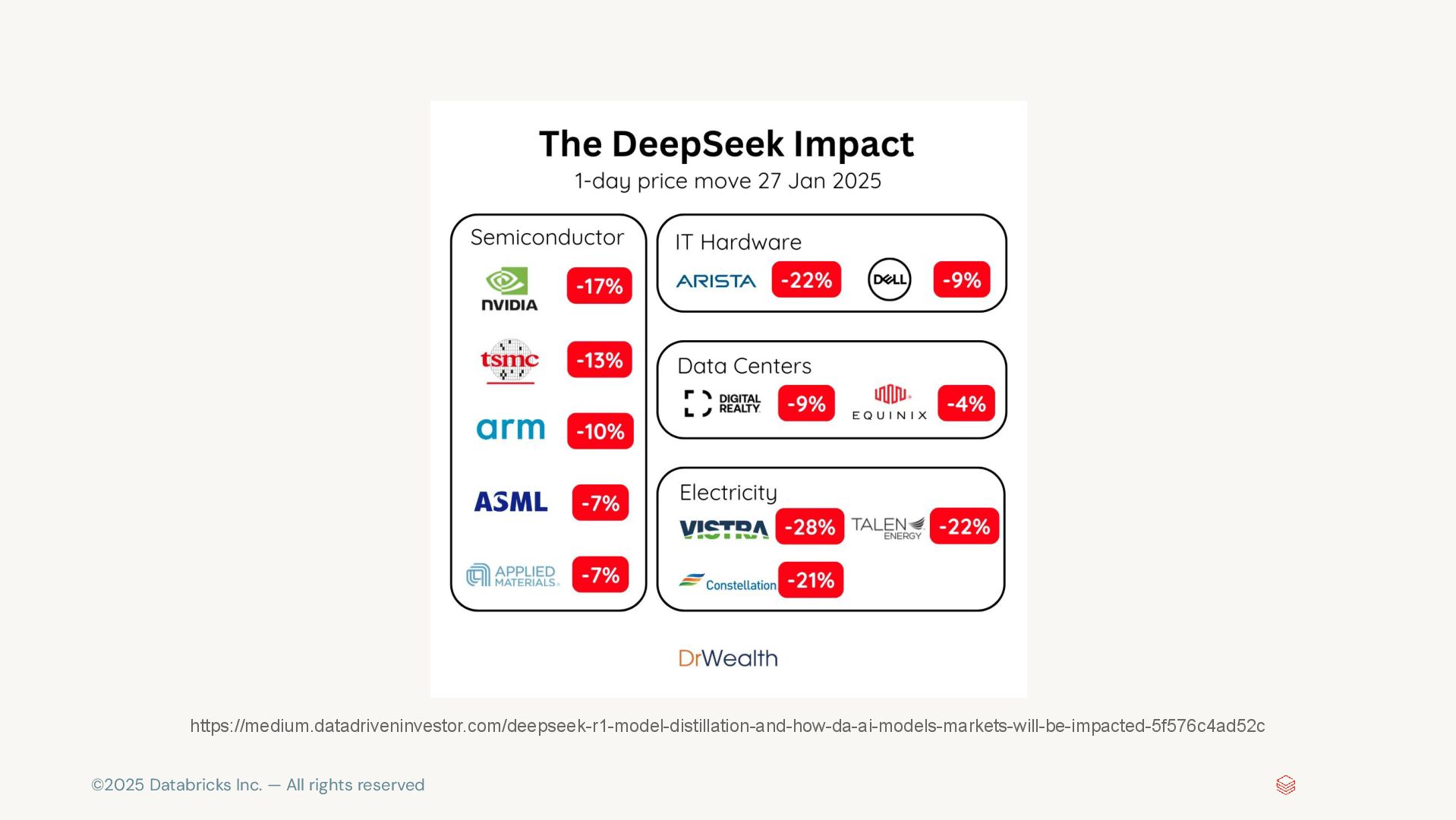
©2025 Databricks Inc. — All rights reserved マーケットへの影響
©2025 Databricks Inc. — All rights reserved https://medium.datadriveninvestor.com/deepseek-r1-model-distillation-and-how-da-ai-models-markets-will-be-impacted-5f576c4ad52c
©2025 Databricks Inc. — All rights reserved 各社の動き • Microsoft
• Azure AI FoundryでDeepSeek R1を提供開始 (ref) • Perplexity • R1ベースの検索エンジン提供開始 (ref) • Groq • DeepSeek R1を提供開始 (ref) • CyberAgent • DeepSeek R1の蒸留モデル (Qwen) をローカライズ (ref) • Alibaba • Qwen2.5-MaxでDeepSeek V3を超えたと主張 (ref) • Meta • DeepSeekの登場により、OSS LLMが私たちが集中的に取り組むべき正しいことだという確信を強めた (ref)
©2025 Databricks Inc. — All rights reserved 今後の展開? • 世界中で再現性の確認が始動
• 論文で公開した内容で、本当に DS V3/R1相当が作れるか各研究機関で確認開始 • DeepSeekのトレーニング用コードとデータセットは非公開 • HuggingFace:Open-R1 • UC BerkleyがDeepSeek R1の再現性をすでに確認 • 大規模GPUクラスター不要? • もし、再現性が確認でき、かつ、 HAI-LLMのようなフレームワークが公開されれば、少なくとも現在の Transformer ベースのLLMのトレーニングにはこれまでのような大規模 GPUは必要なくなるかも • ただし、推論用途では、まだまだ GPU必要かも。特にエージェントは一回の実行で他段階の推論を実行するため。 • マルチモーダルモデルも同様の路線に? • DeepSeekはマルチモーダルモデル「Janus-Pro」も公開
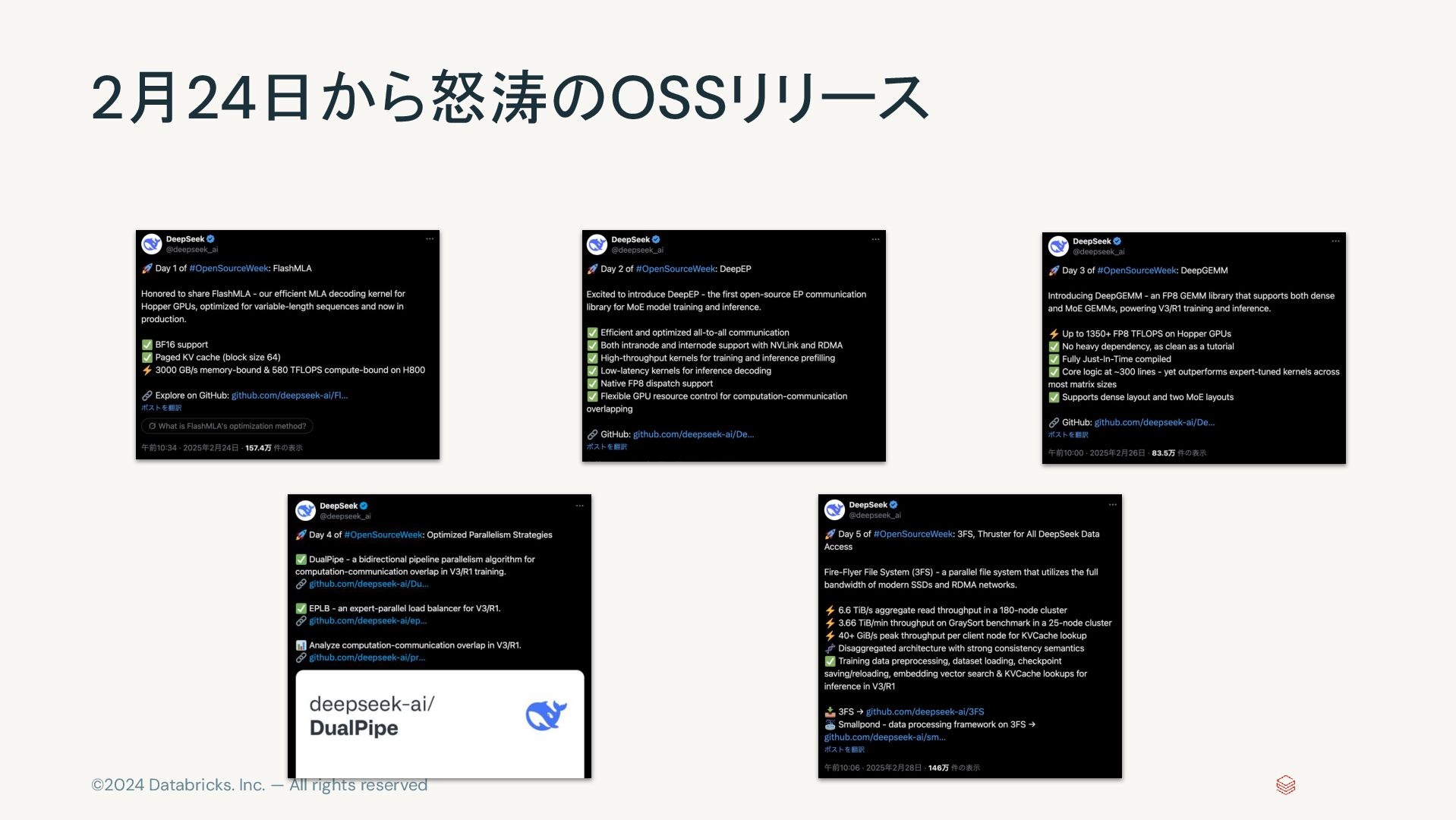
©2024 Databricks. Inc. — All rights reserved 2月24日から怒涛のOSSリリース
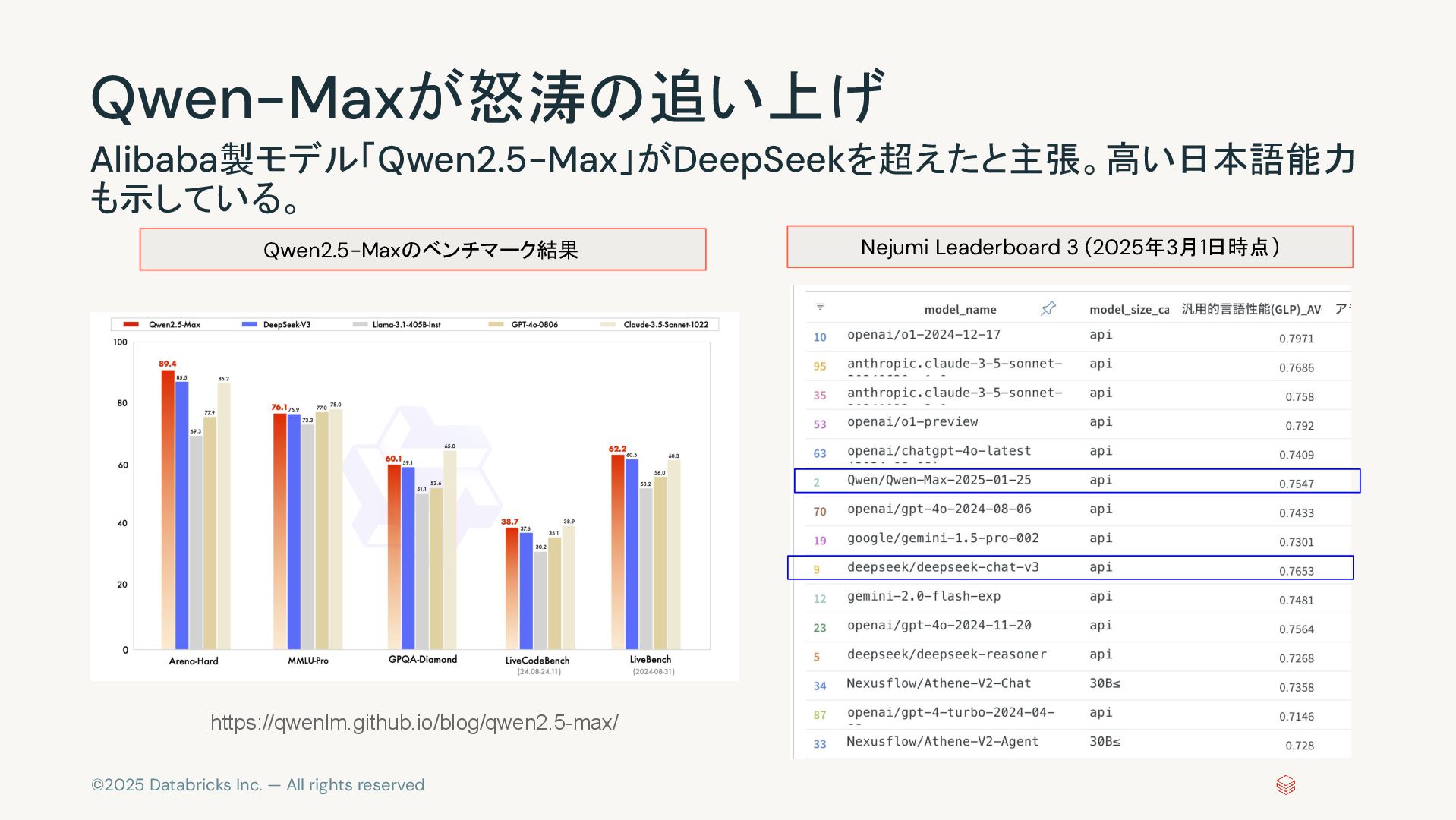
©2025 Databricks Inc. — All rights reserved Qwen-Maxが怒涛の追い上げ Alibaba製モデル「Qwen2.5-Max」がDeepSeekを超えたと主張。高い日本語能力 も示している。
Nejumi Leaderboard 3 (2025年3月1日時点) Qwen2.5-Maxのベンチマーク結果 https://qwenlm.github.io/blog/qwen2.5-max/
©2025 Databricks Inc. — All rights reserved
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}