Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Learning to Model the World with Language
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
ほき
December 06, 2024
36
0
Share
Learning to Model the World with Language
AcademiX論文読み会#58で発表した資料です
元論文:
https://doi.org/10.48550/arXiv.2308.01399
ほき
December 06, 2024
More Decks by ほき
See All by ほき
Expert-Level Detection of Epilepsy Markers in EEG on Short and Long Timescales
hokkey621
0
32
MMaDA: Multimodal Large Diffusion Language Models
hokkey621
0
30
TAID: Temporally Adaptive Interpolated Distillation for Efficient Knowledge Transfer in Language Models
hokkey621
0
30
脳波を用いた嗜好マッチングシステム
hokkey621
0
510
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
hokkey621
0
97
GeminiとUnityで実現するインタラクティブアート
hokkey621
0
1.7k
LT - Gemma Developer Time
hokkey621
0
25
wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
hokkey621
0
41
イベントを主催してわかった運営のノウハウ
hokkey621
0
84
Featured
See All Featured
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
230
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
200
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
62
54k
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
1.1k
Color Theory Basics | Prateek | Gurzu
gurzu
0
320
GitHub's CSS Performance
jonrohan
1033
470k
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
My Coaching Mixtape
mlcsv
0
140
The Illustrated Children's Guide to Kubernetes
chrisshort
51
52k
For a Future-Friendly Web
brad_frost
183
10k
Abbi's Birthday
coloredviolet
2
7.8k
Transcript
https://www.academix.jp/ AcademiX 論文輪読会 Learning to Model the World with
Language 東京農工大学 Inoue Ibuki 2024/12/06
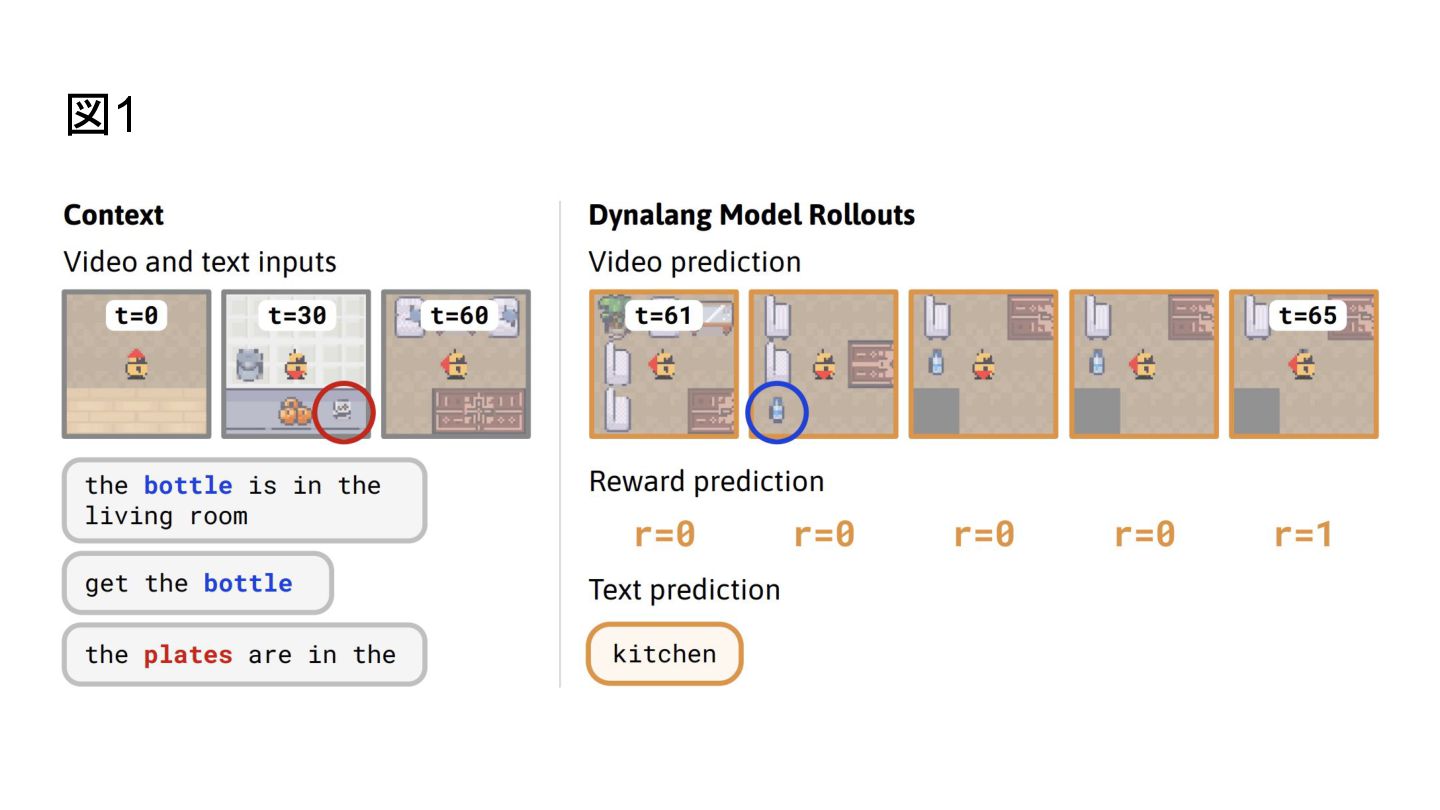
図1
書誌情報 • Learning to Model the World with Language •
Jessy Lin, Yuqing Du, Olivia Watkins, Danijar Hafner, Pieter Abbeel, Dan Klein, Anca Dragan • UC Berkeley • ICML 2024 Accepted • https://doi.org/10.48550/arXiv.2308.01399 ※引用 無い図 こ 論文より引用
世界モデルと • 世界モデル(World model) ◦ 現実世界 物理法則や因果関係,物体間 相互作用など 「世界 仕組み」を表現
◦ 別名内部モデルや力学モデル • 典型的な深層学習 タスクを事前に与えることが必要 ◦ 入力と出力が与えられた下で,関係性を学習してモデル化 • 世界モデルにより,新たな刺激から 推論が可能 ◦ 外界から 刺激をもとに外界 モデルを学習によって獲得 ◦ 例え 赤ちゃん 環境と相互作用することで, 何をすれ どうなるかを理解 • 例 ◦ Sora ◦ GAIA-1 David Ha, NeurIPS, 2018
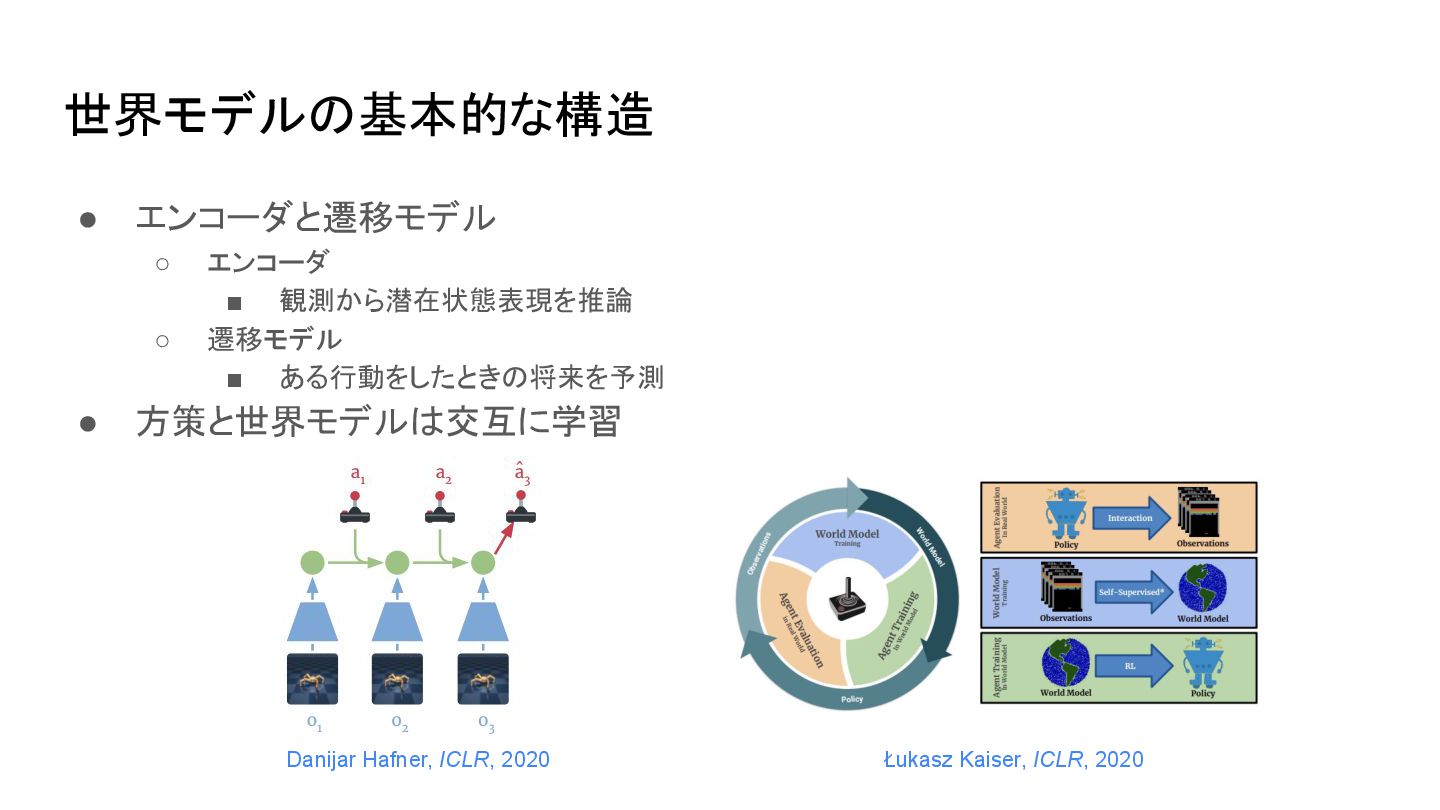
世界モデル 基本的な構造 • エンコーダと遷移モデル ◦ エンコーダ ▪ 観測から潜在状態表現を推論 ◦ 遷移モデル
▪ ある行動をしたとき 将来を予測 • 方策と世界モデル 交互に学習 Danijar Hafner, ICLR, 2020 Łukasz Kaiser, ICLR, 2020
Embodied AI 理想と現実 • 人工知能 長年 目標 ,言語を使って物理世界 人々と自然に対話できるエー ジェント
開発 • 現在 エージェント 基本的な指示に対応可能 ◦ 例 りんごを持ってきて
課題 • 多様な種類 言語を視覚や行動とど ように統合する が最適な か 不明 ◦ エピソード
最初にタスク記述を埋め込み,エージェントが環境内で行動しながら,言語入力を継続 的に統合することが理想的 ◦ 言語による「プロンプト」以外に,行動や映像とともに継続的に言語を入出力する手法へと移行する 必要 • 多様な言語を最適な行動に直接マッピングすること 難しい学習問題 ◦ 言語と最適な行動 ,そ 依存関係が複雑な場合相関が弱い ▪ put the bowls away • 手元 タスクが掃除であれ ,エージェント 次 掃除 ステップへ • 夕食 配膳であれ ,エージェント ボウルを回収
Dynalang • エージェントが未来を予測するために言語を使用することで,多様な種類 言語を 基礎づけることができることを提案 • 言語と視覚 生成的モデルを利用して計画と行動を実施 ◦ DreamerV3アルゴリズムで将来
テキストと画像 表現を予測 ◦ 強化学習を使って世界モデル 出力から行動を決定
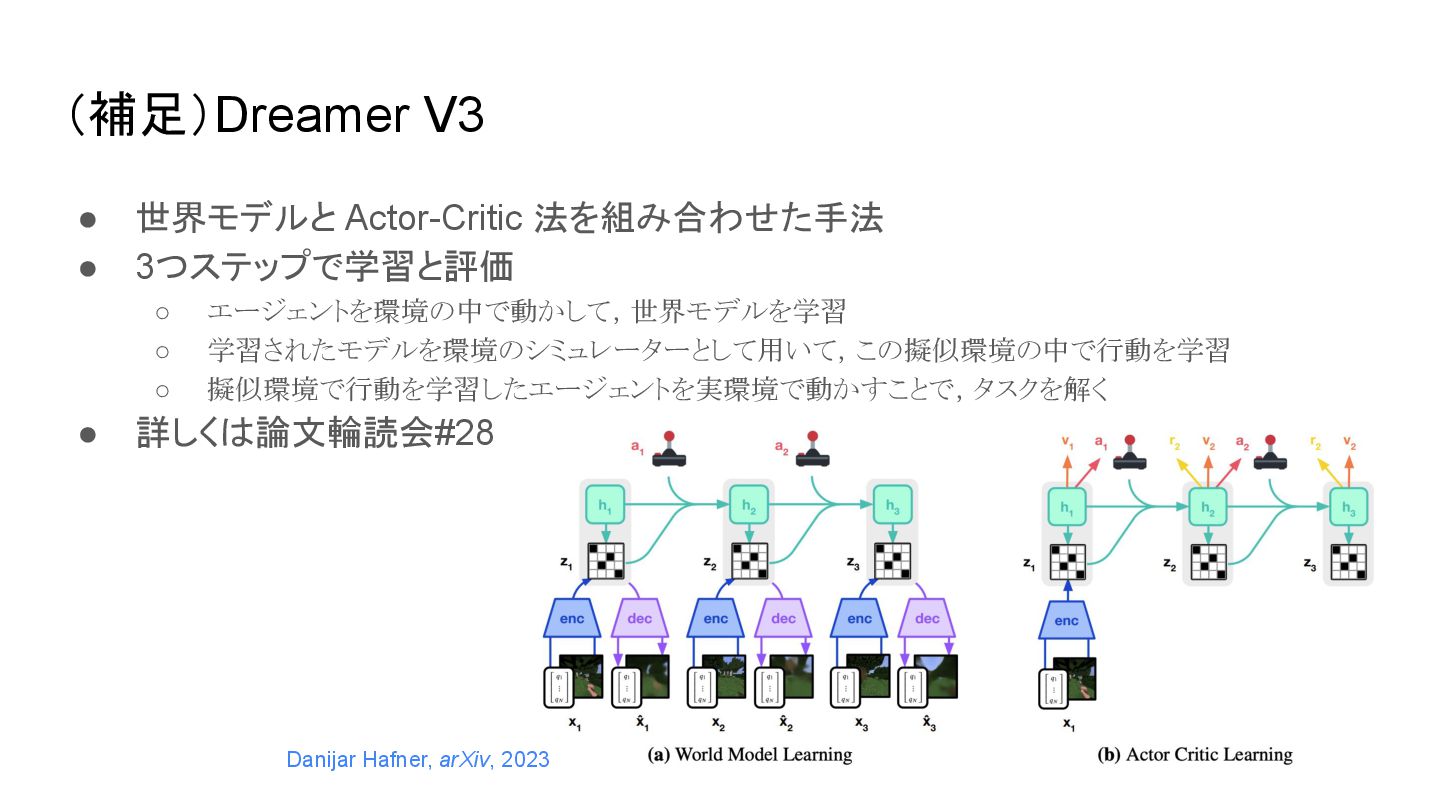
(補足)Dreamer V3 • 世界モデルと Actor-Critic 法を組み合わせた手法 • 3つステップで学習と評価 ◦ エージェントを環境の中で動かして,世界モデルを学習
◦ 学習されたモデルを環境のシミュレーターとして用いて,この擬似環境の中で行動を学習 ◦ 擬似環境で行動を学習したエージェントを実環境で動かすことで,タスクを解く • 詳しく 論文輪読会#28 Danijar Hafner, arXiv, 2023
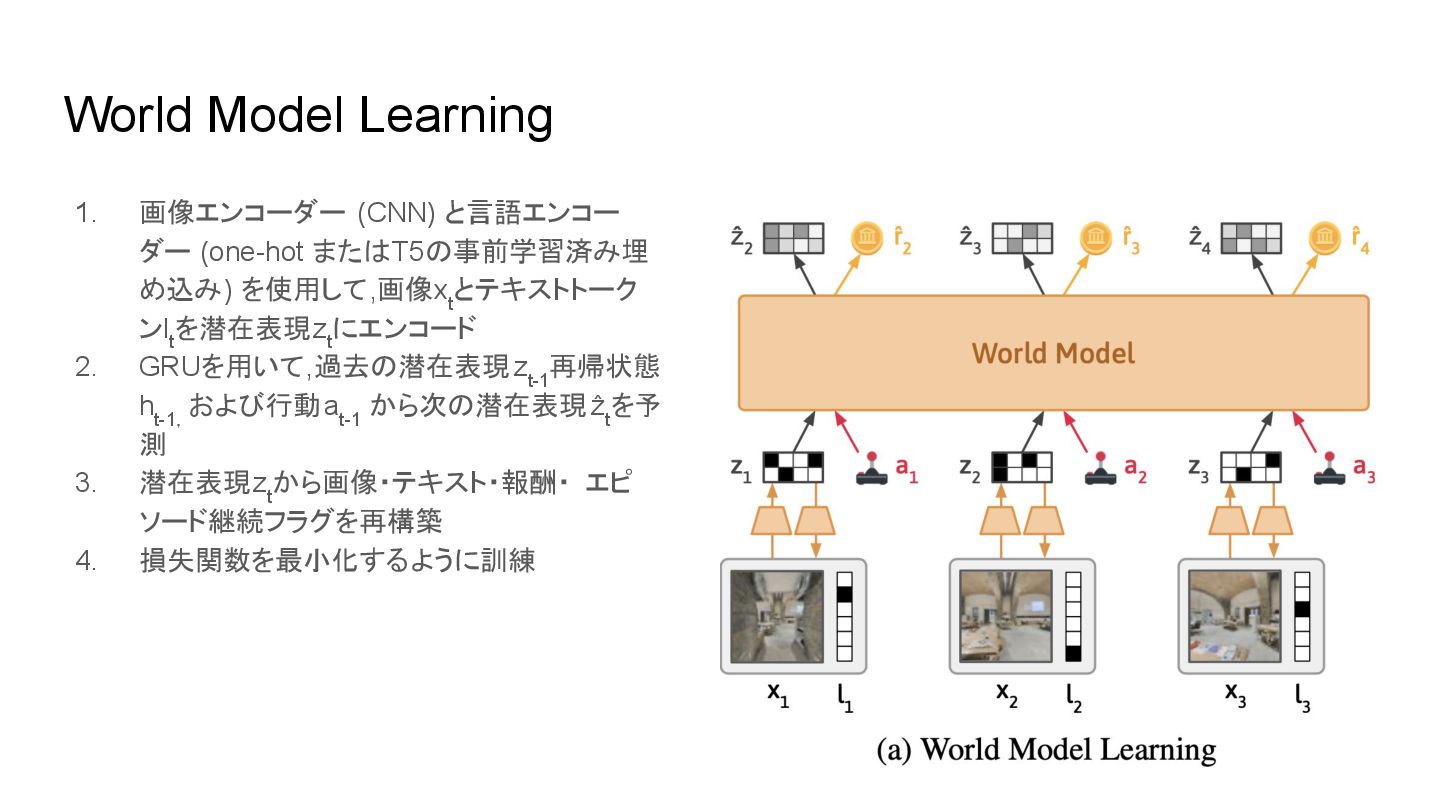
World Model Learning 1. 画像エンコーダー (CNN) と言語エンコー ダー (one-hot また
T5 事前学習済み埋 め込み) を使用して,画像x t とテキストトーク ンl t を潜在表現z t にエンコード 2. GRUを用いて,過去 潜在表現z t-1 再帰状態 h t-1, および行動a t-1 から次 潜在表現ẑ t を予 測 3. 潜在表現z t から画像・テキスト・報酬・ エピ ソード継続フラグを再構築 4. 損失関数を最小化するように訓練
損失関数 •
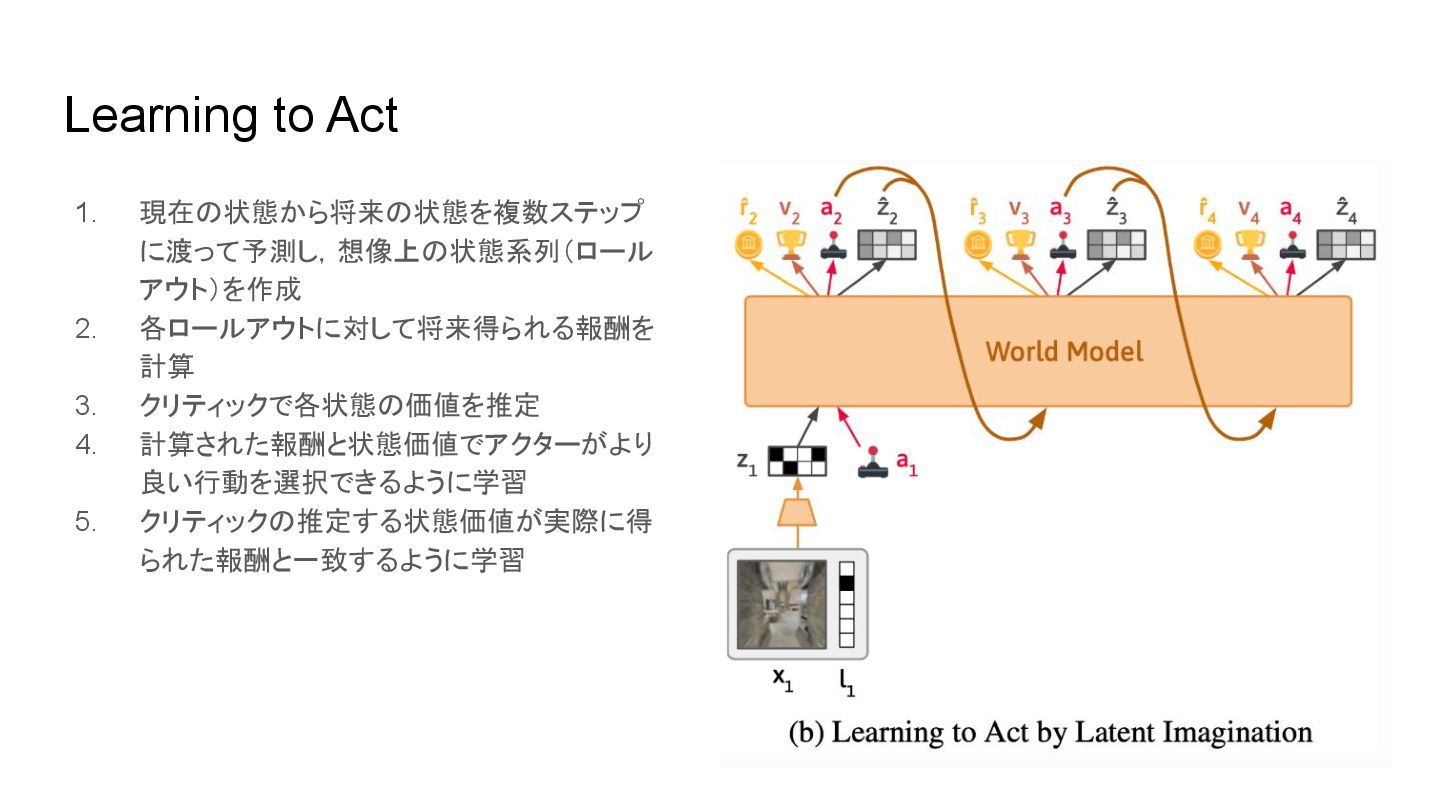
Learning to Act 1. 現在 状態から将来 状態を複数ステップ に渡って予測し,想像上 状態系列(ロール アウト)を作成
2. 各ロールアウトに対して将来得られる報酬を 計算 3. クリティックで各状態 価値を推定 4. 計算された報酬と状態価値でアクターがより 良い行動を選択できるように学習 5. クリティック 推定する状態価値が実際に得 られた報酬と一致するように学習
仮説 A) 画像と言語をタイムステップごとに単一 (画像とトークン )ペアとして揃えること ,DreamerV3に言語を組み込むため 他 方法よりも良い B) 言語条件付きポリシーよりも,タスク
パフォーマンスを向上させるために多様 なタイプ 言語をより良く利用可能 C) 世界モデルに命令を組み込むほうが言語条件付きポリシーを直接学習するより 良い D) 基底言語生成とオフライン テキスト み データで事前学習を必要とするタス クを扱える
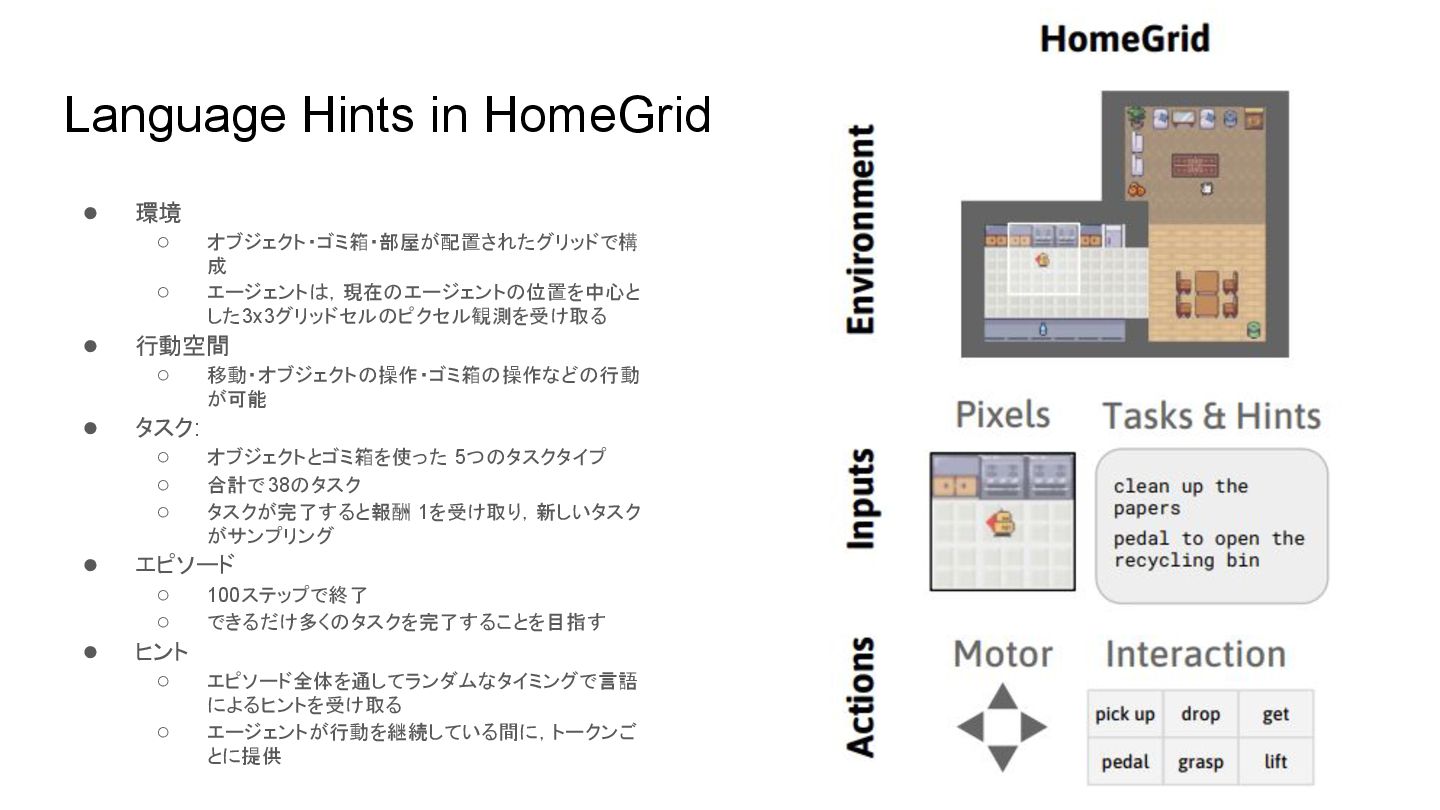
Language Hints in HomeGrid • 環境 ◦ オブジェクト・ゴミ箱・部屋が配置されたグリッドで構 成 ◦
エージェント ,現在 エージェント 位置を中心と した3x3グリッドセル ピクセル観測を受け取る • 行動空間 ◦ 移動・オブジェクト 操作・ゴミ箱 操作など 行動 が可能 • タスク: ◦ オブジェクトとゴミ箱を使った 5つ タスクタイプ ◦ 合計で38 タスク ◦ タスクが完了すると報酬 1を受け取り,新しいタスク がサンプリング • エピソード ◦ 100ステップで終了 ◦ できるだけ多く タスクを完了することを目指す • ヒント ◦ エピソード全体を通してランダムなタイミングで言語 によるヒントを受け取る ◦ エージェントが行動を継続している間に,トークンご とに提供
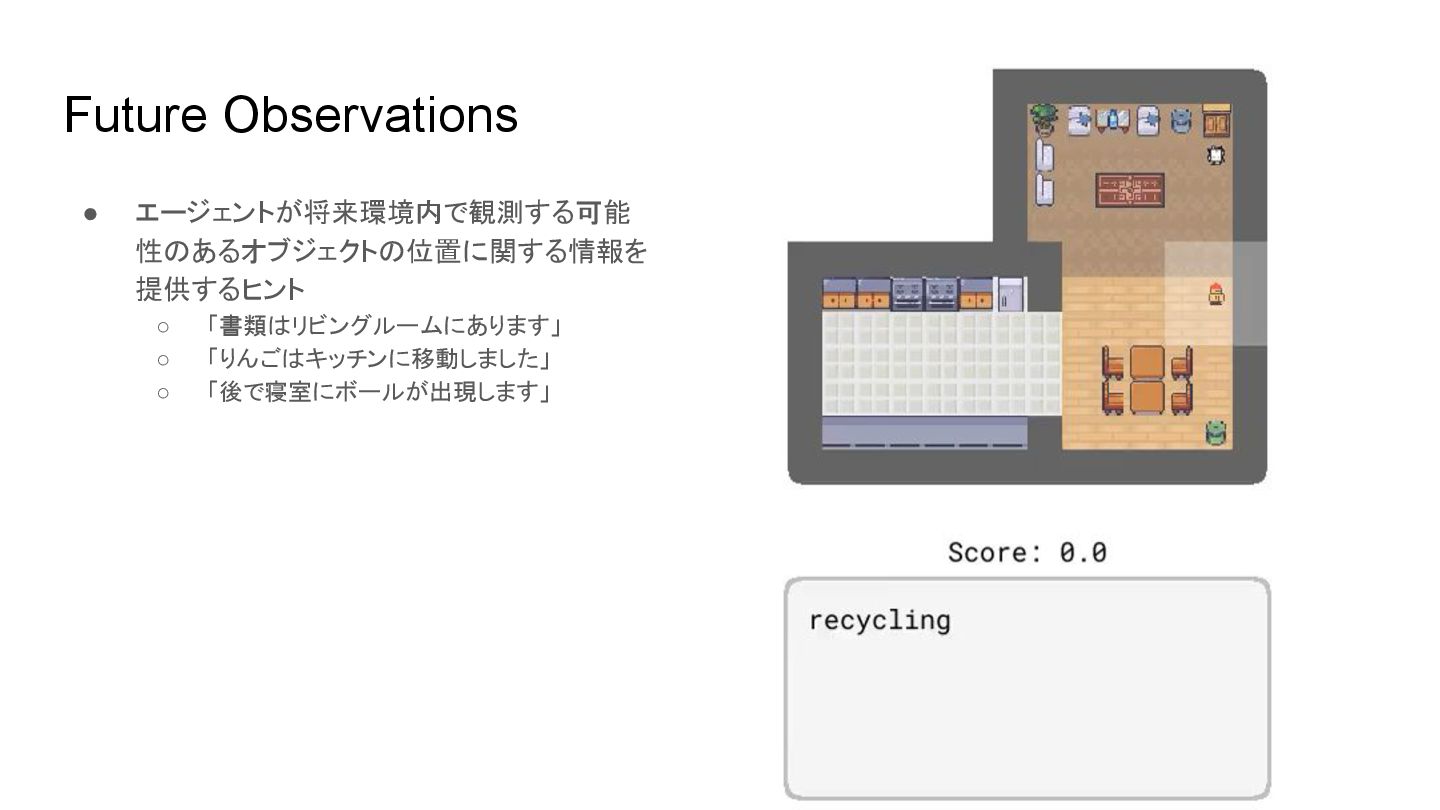
Future Observations • エージェントが将来環境内で観測する可能 性 あるオブジェクト 位置に関する情報を 提供するヒント ◦ 「書類
リビングルームにあります」 ◦ 「りんご キッチンに移動しました」 ◦ 「後で寝室にボールが出現します」
Corrections • エージェントが現在 タスク目標に対して非 効率的な行動を取っているときに,軌道修正 を促すヒント ◦ 「いいえ、向きを変えてください」
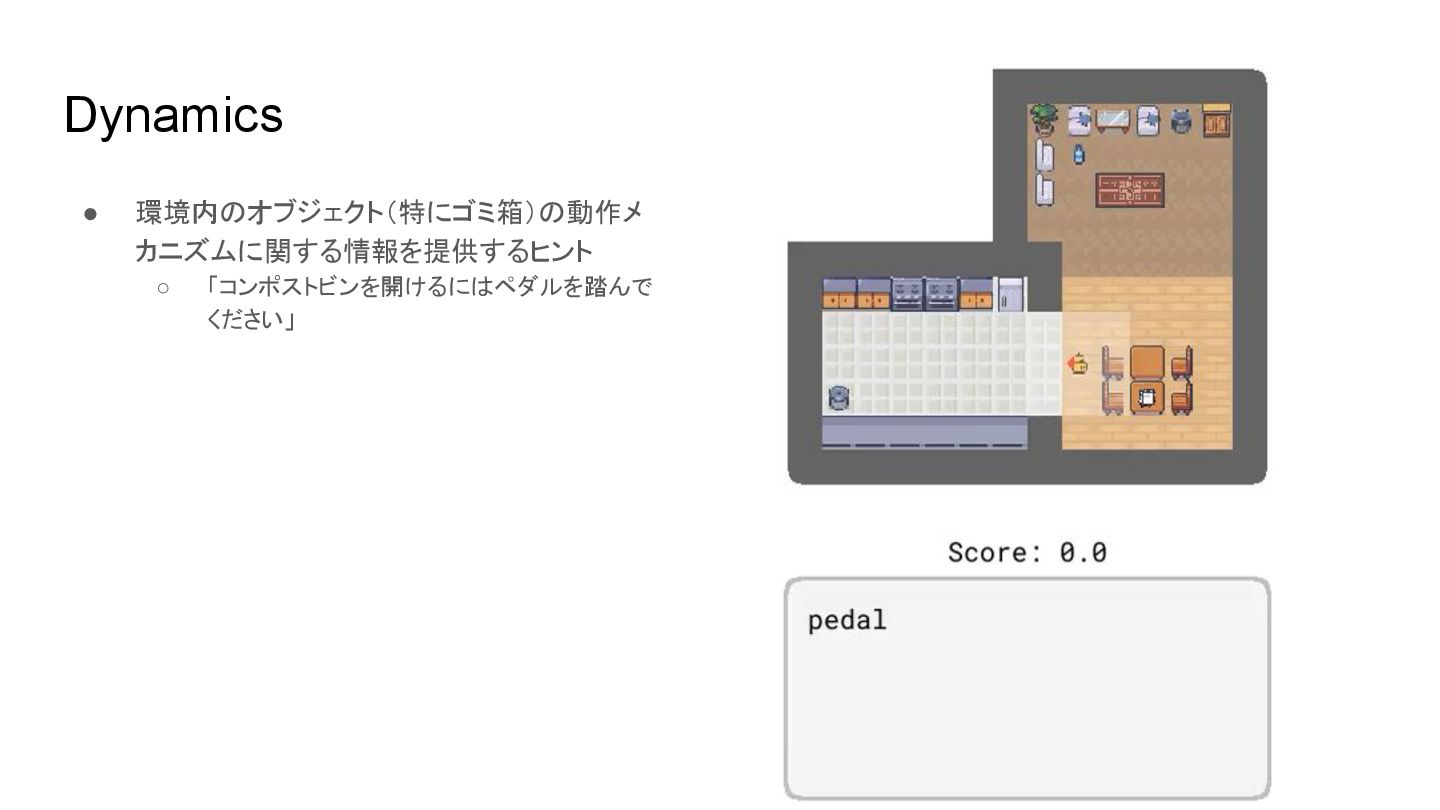
Dynamics • 環境内 オブジェクト(特にゴミ箱) 動作メ カニズムに関する情報を提供するヒント ◦ 「コンポストビンを開けるに ペダルを踏んで ください」
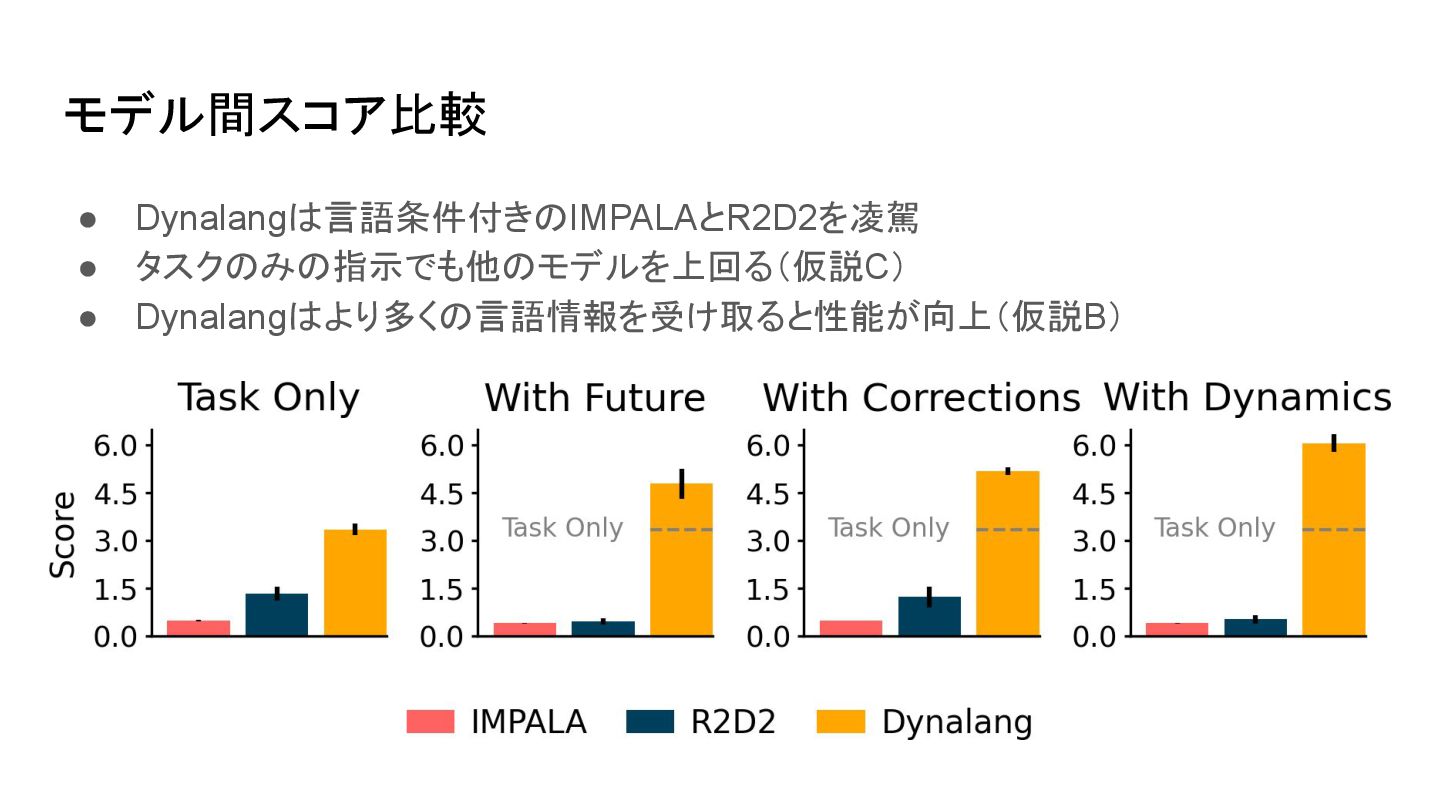
モデル間スコア比較 • Dynalang 言語条件付き IMPALAとR2D2を凌駕 • タスク み 指示でも他 モデルを上回る(仮説C)
• Dynalang より多く 言語情報を受け取ると性能が向上(仮説B)
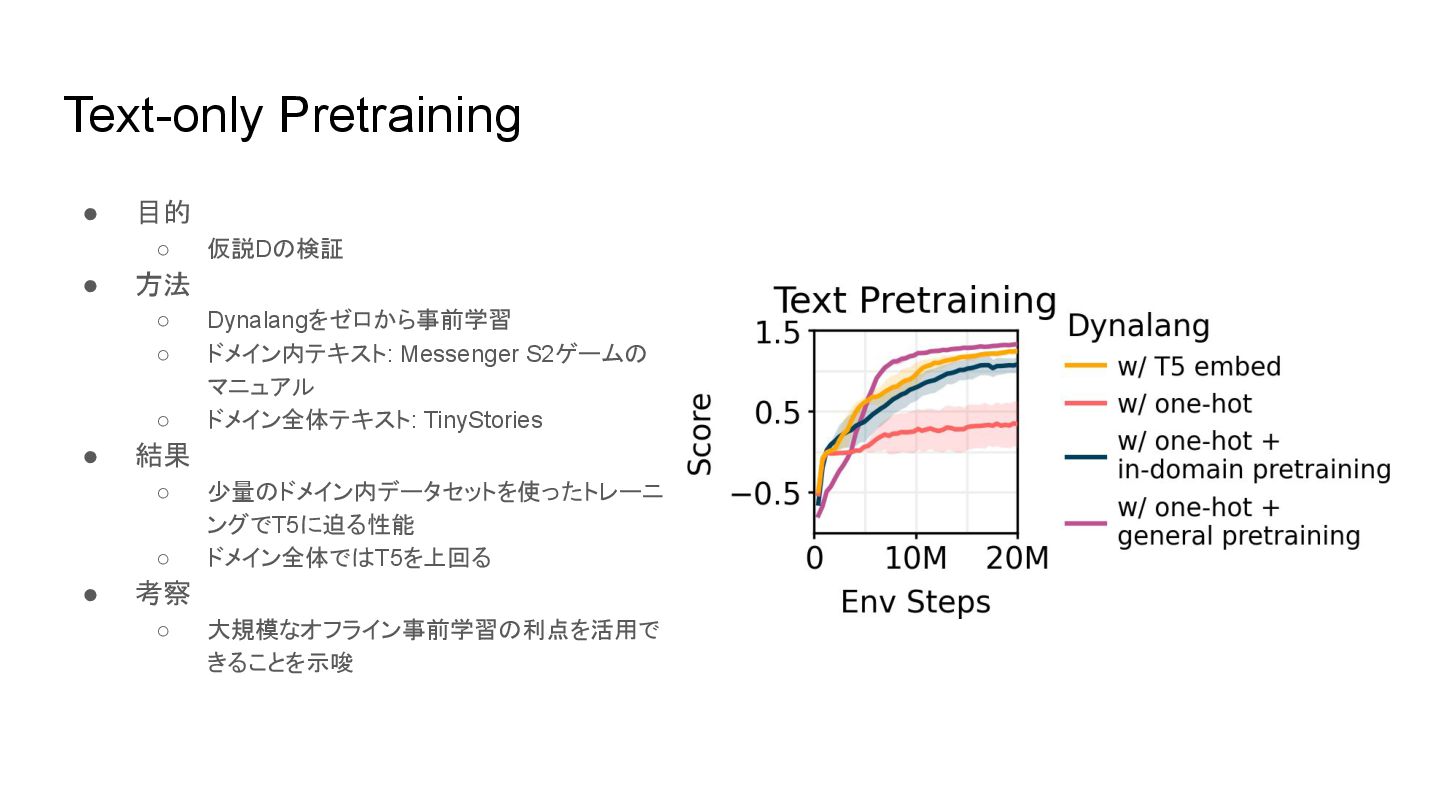
Text-only Pretraining • 目的 ◦ 仮説D 検証 • 方法 ◦
Dynalangをゼロから事前学習 ◦ ドメイン内テキスト: Messenger S2ゲーム マニュアル ◦ ドメイン全体テキスト: TinyStories • 結果 ◦ 少量 ドメイン内データセットを使ったトレーニ ングでT5に迫る性能 ◦ ドメイン全体で T5を上回る • 考察 ◦ 大規模なオフライン事前学習 利点を活用で きることを示唆
まとめ • 世界モデルと言語 接地を表現したモデルDynalangを提案 • DreamerV3に言語埋め込みを追加 • 既存モデルを上回るタスク成功率 • 言語条件付きタスクポリシー
有効性を示唆 • 所感 ◦ DreamerV3に言語埋め込みを加えるだけ シンプルな仕組みに好感が持てる ◦ ベンチマークが単純な で複雑なタスク とき 結果がほしい ◦ 入力をLLMやVLM 出力にするとどうなる か気になる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
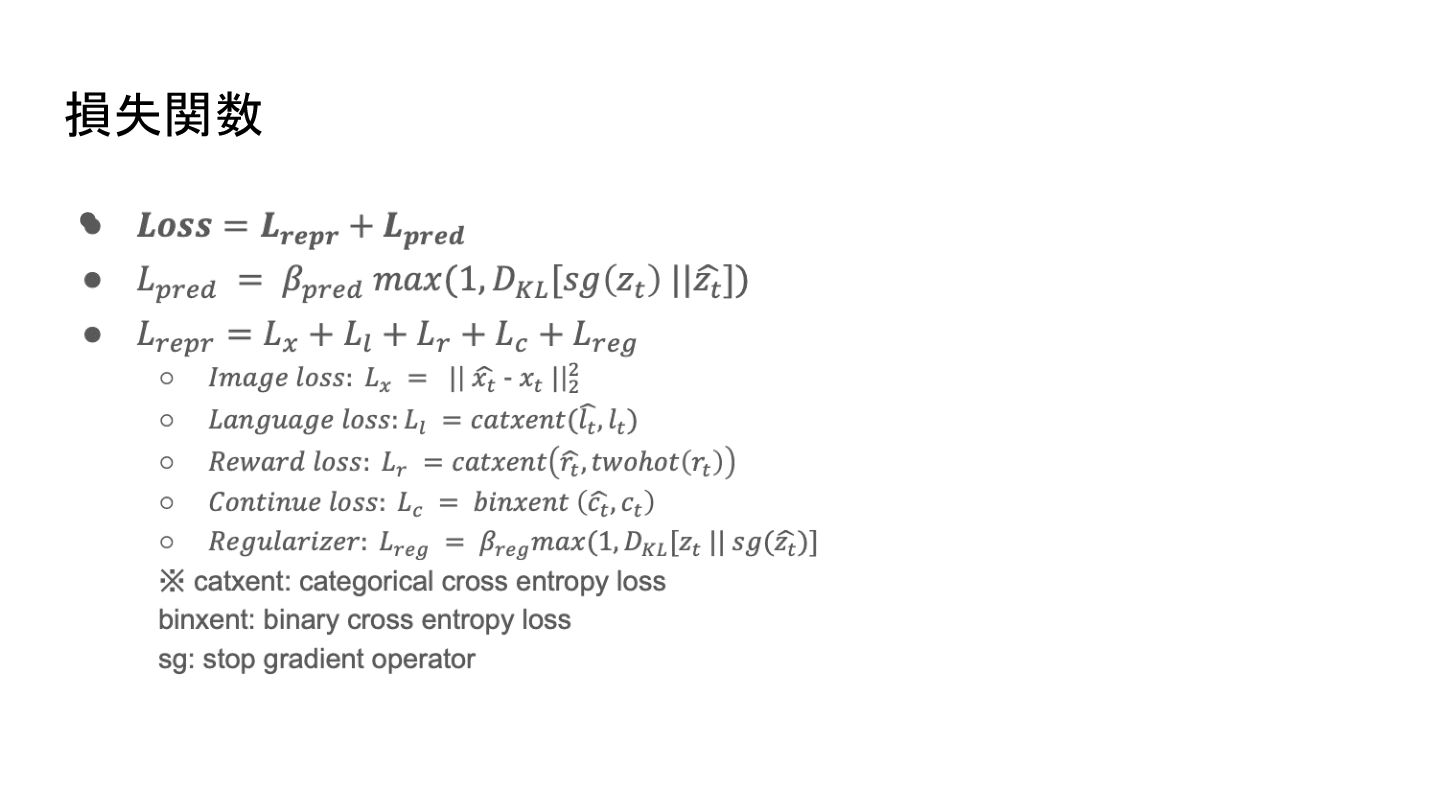{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}