Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
wav2vec 2.0: A Framework for Self-Supervised Le...
Search
ほき
August 10, 2024
41
0
Share
wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
AcademiX論文読み会で発表した資料です
元論文:
https://doi.org/10.48550/arXiv.2006.11477
ほき
August 10, 2024
More Decks by ほき
See All by ほき
Expert-Level Detection of Epilepsy Markers in EEG on Short and Long Timescales
hokkey621
0
32
MMaDA: Multimodal Large Diffusion Language Models
hokkey621
0
30
TAID: Temporally Adaptive Interpolated Distillation for Efficient Knowledge Transfer in Language Models
hokkey621
0
30
脳波を用いた嗜好マッチングシステム
hokkey621
0
510
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
hokkey621
0
97
Learning to Model the World with Language
hokkey621
0
36
GeminiとUnityで実現するインタラクティブアート
hokkey621
0
1.7k
LT - Gemma Developer Time
hokkey621
0
25
イベントを主催してわかった運営のノウハウ
hokkey621
0
84
Featured
See All Featured
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.7k
Documentation Writing (for coders)
carmenintech
77
5.4k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
240
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
330
Designing for humans not robots
tammielis
254
26k
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
200
Speed Design
sergeychernyshev
33
1.8k
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
150
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
5.8k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.2k
Transcript
https://www.academix.jp/ AcademiX 論文輪読会 wav2vec 2.0: A Framework for Self- Supervised
Learning of Speech Representations 東京農工大学 Ibuki Inoue 2024/08/10
書誌情報 • タイトル:wav2vec 2.0: A Framework for Self-Supervised Learning of
Speech Representations • 著者名:Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, Michael Auli • 所属:Facebook AI • 発表学会:NeurIPS 2020 引用が記載されていない図に関してはすべてこの論文より引用
概要 • 背景 ◦ 大量のラベル付き音声データを収集することは困難 • 目的 ◦ 少ないラベル付きのデータから高精度で文字起こしができるモデルを構築 •
方法 ◦ 大規模ラベル無し音声で表現学習 ◦ テキストの正解有りのデータでファインチューニング • 結果 ◦ 少量のラベル付きデータでファインチューニングすることにより既存モデルと同等の WER を達成
背景 • 音声認識の分野では大量の訓練データが必要 ◦ 世界中で話されている 7000 近くの言語の大部分では不可能 • ラベルづけされたデータを用いた学習は人間の言語取得と相違 ◦
幼児は周囲の大人の話から音声の表現を学習 Lewis+, Ethnologue: Languages of the world, 2016
表現学習 • データの特徴やパターンを自動的に抽出する手法 • 大規模ラベルなしデータを活用 • シンプルなモデルと小規模データから高精度な推定が可能 ◦ 自然言語処理や音声認識において有効 Devlin+,
arXiv, 2018
目的とアプローチ • 目的 ◦ 少量のラベル付き音声を用いて高精度な音声認識システムの構築 • アプローチ ◦ 大規模ラベルなし音声データから音声表現を学習 ◦
小規模のラベルあり音声データで教師あり学習
先行研究 • wav2vec • vq-wav2vec Schneider+, arXiv, 2019 Baevski+, ICLR,
2020
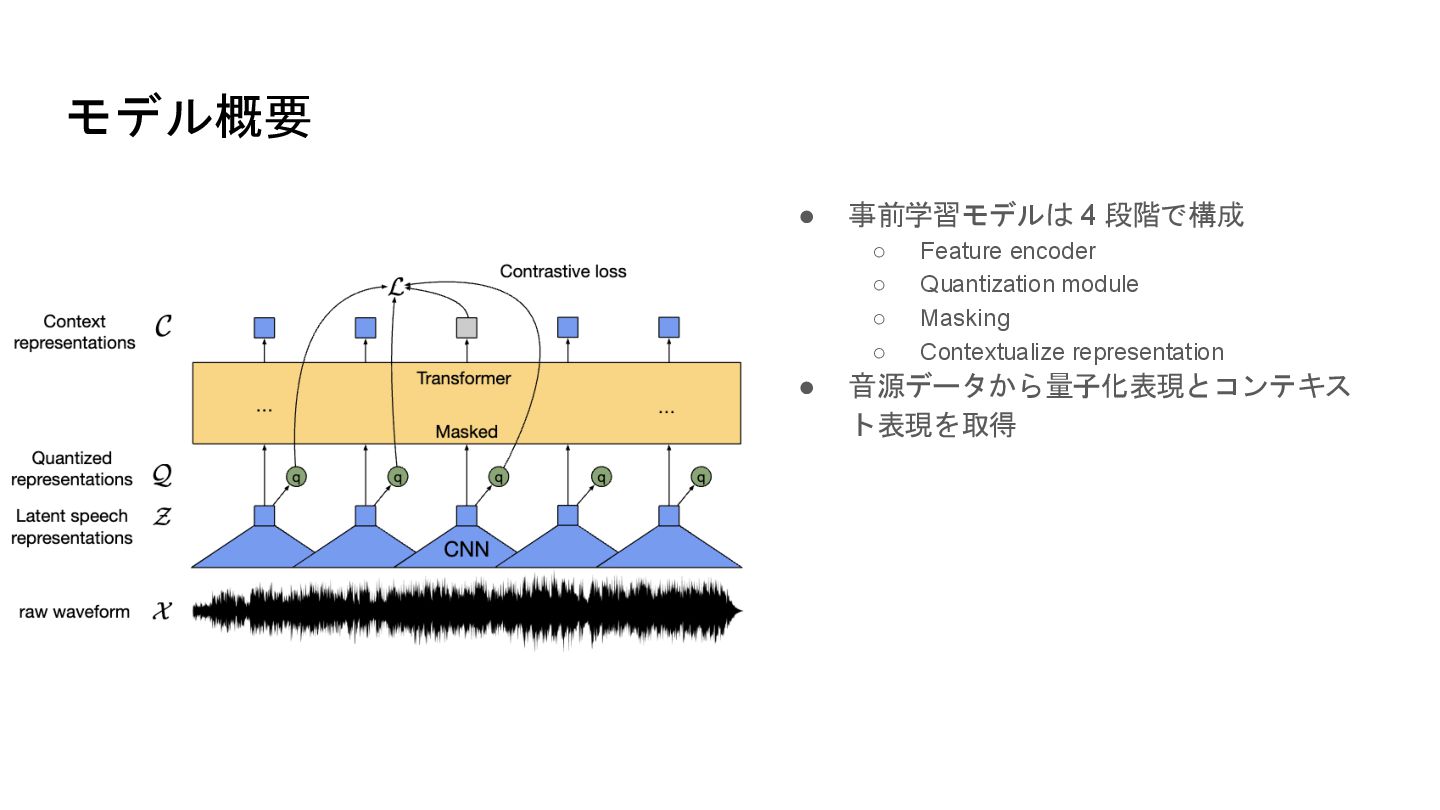
モデル概要 • 事前学習モデルは 4 段階で構成 ◦ Feature encoder ◦ Quantization
module ◦ Masking ◦ Contextualize representation • 音源データから量子化表現とコンテキス ト表現を取得
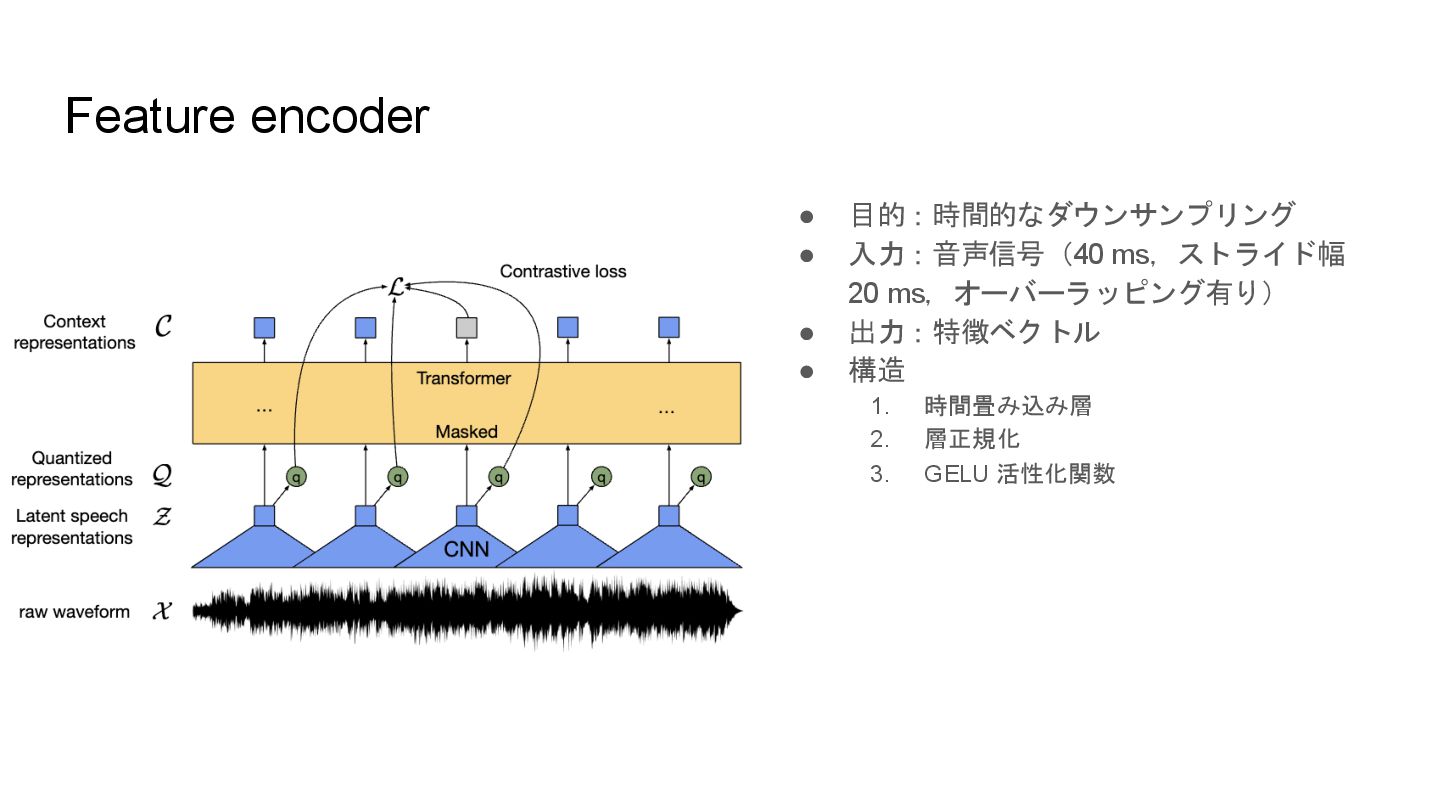
Feature encoder • 目的:時間的なダウンサンプリング • 入力:音声信号(40 ms,ストライド幅 20 ms,オーバーラッピング有り) •
出力:特徴ベクトル • 構造 1. 時間畳み込み層 2. 層正規化 3. GELU 活性化関数
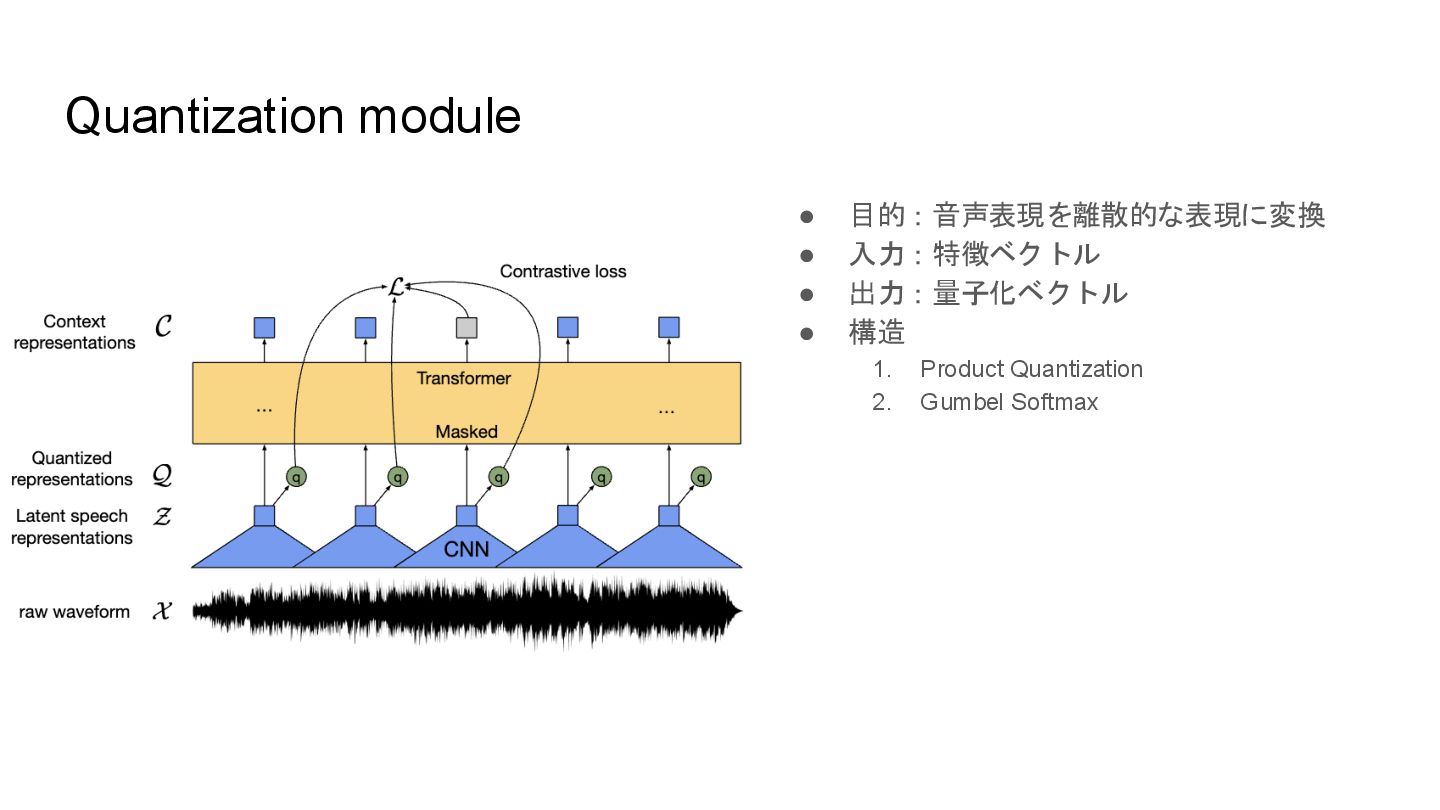
Quantization module • 目的:音声表現を離散的な表現に変換 • 入力:特徴ベクトル • 出力:量子化ベクトル • 構造
1. Product Quantization 2. Gumbel Softmax
Product Quantization 音声データを分割して,それぞれを別々に離散的な値に変換 1. d 次元の元データ z を G 個のグループに分割
𝑧 = [𝑧1, 𝑧2, … , 𝑧𝐺] 2. 各部分 zi をあらかじめ定義された小さなベクトルの集合(コードブック) から最も近いコードワード ei,j に置換 𝑞𝑖 = 𝑒𝑖𝑗, 𝑗 = arg min 𝑗 𝑧𝑖 − 𝑒𝑖𝑗 3. すべてのグループで量子化が終わったら結合 𝑞 = [𝑞1, 𝑞2, … , 𝑞𝐺]
Gumbel Softmax 離散潜在変数に対する微分可能な確率モデリングが可能 1. Gumbel 分布に従う乱数 ni を生成 𝑛𝑖 =
− log − log 𝑈 0,1 2. ある選択肢 i が選ばれる確率 pi を計算して選ぶ選択肢を決定 𝑝𝑖 = exp log 𝜋𝑖 + 𝑛𝑖 𝜏 σ𝑗=1 𝑘 exp log 𝜋𝑗 + 𝑛𝑗 𝜏 πi : 選択肢 i の元の確率 τ: 温度パラメータ
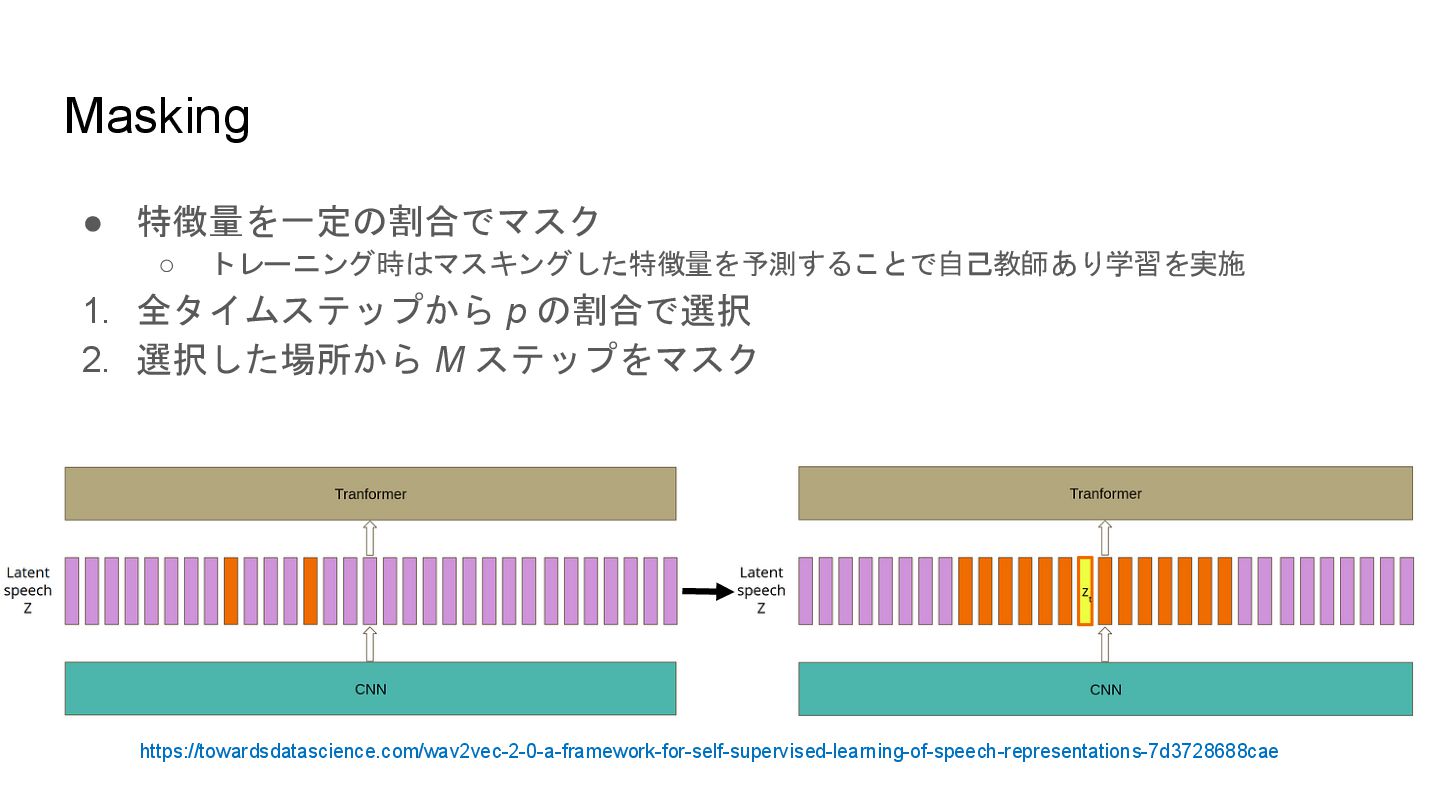
Masking • 特徴量を一定の割合でマスク ◦ トレーニング時はマスキングした特徴量を予測することで自己教師あり学習を実施 1. 全タイムステップから p の割合で選択 2.
選択した場所から M ステップをマスク https://towardsdatascience.com/wav2vec-2-0-a-framework-for-self-supervised-learning-of-speech-representations-7d3728688cae
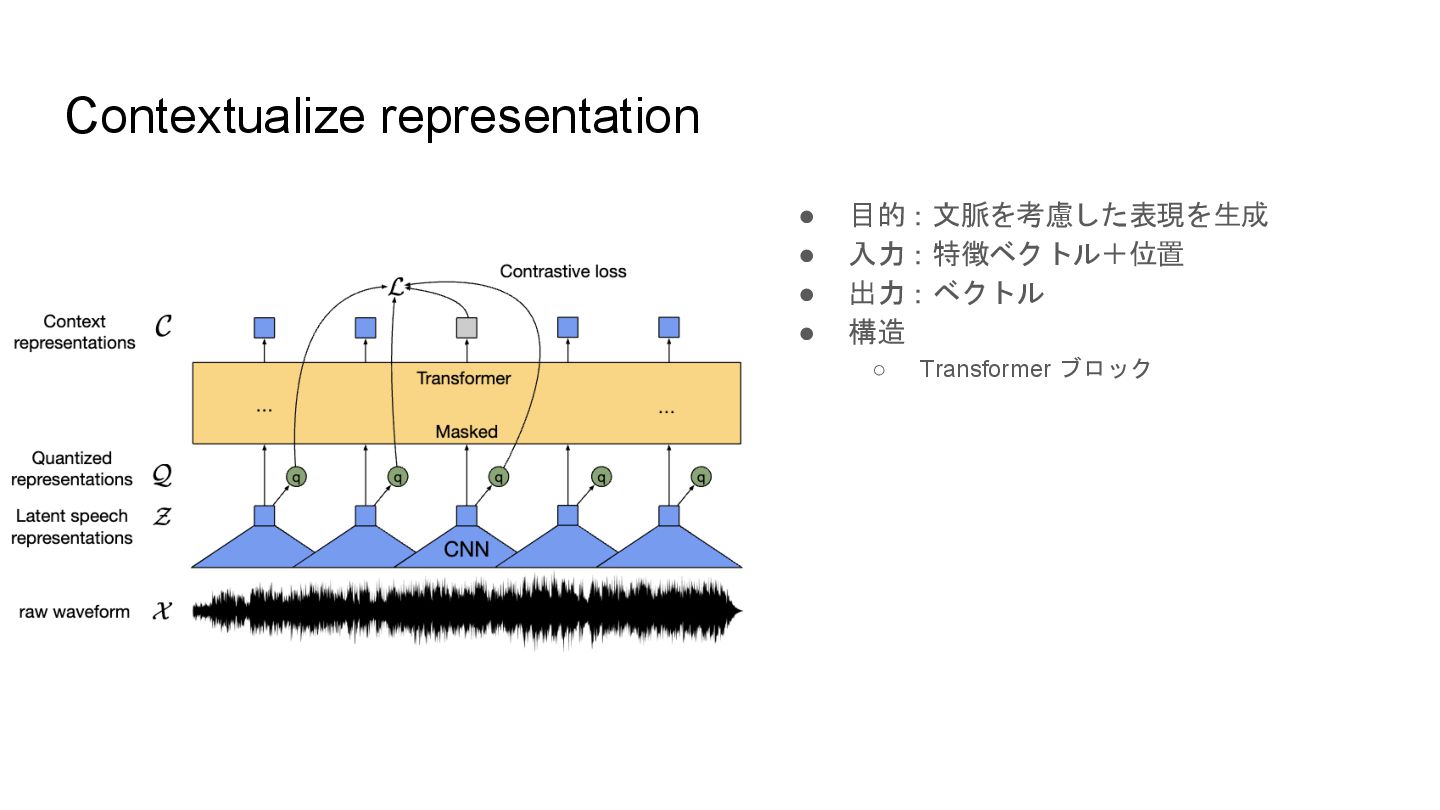
Contextualize representation • 目的:文脈を考慮した表現を生成 • 入力:特徴ベクトル+位置 • 出力:ベクトル • 構造
◦ Transformer ブロック
事前学習 • 損失関数 𝐿 = 𝐿𝑚 + 𝛼 ∗ 𝐿𝑑
𝐿𝑚 = − log 𝑒𝑥𝑝 𝑠𝑖𝑚 𝑐𝑡, 𝑞𝑡 𝜅 𝛴 𝑞∈ 𝑄𝑡 ex𝑝 𝑠𝑖𝑚 𝑐𝑡, 𝑞𝑘 𝜅 𝐿𝑑 = 1 (𝐺 ∗ 𝑉) ∗ 𝛴𝑔=1 𝐺 𝛴𝑣=1 𝑉 𝑝𝑔,𝑣 ∗ log(𝑝𝑔,𝑣) • データセット ◦ ラベルなし音声(後述)
問題設定 • タスク ◦ オーディオブックの音声文字起こし • データセット ◦ LV-60k ▪
6 万時間のオーディオブック音声 ▪ ラベルなし ◦ LS-960 ▪ 1000 時間に対してテキストと音声のアライメントを取得 ▪ clean(ノイズなし)・other(ノイズ有り) • 評価指標 ◦ WER(Word Error Rate)
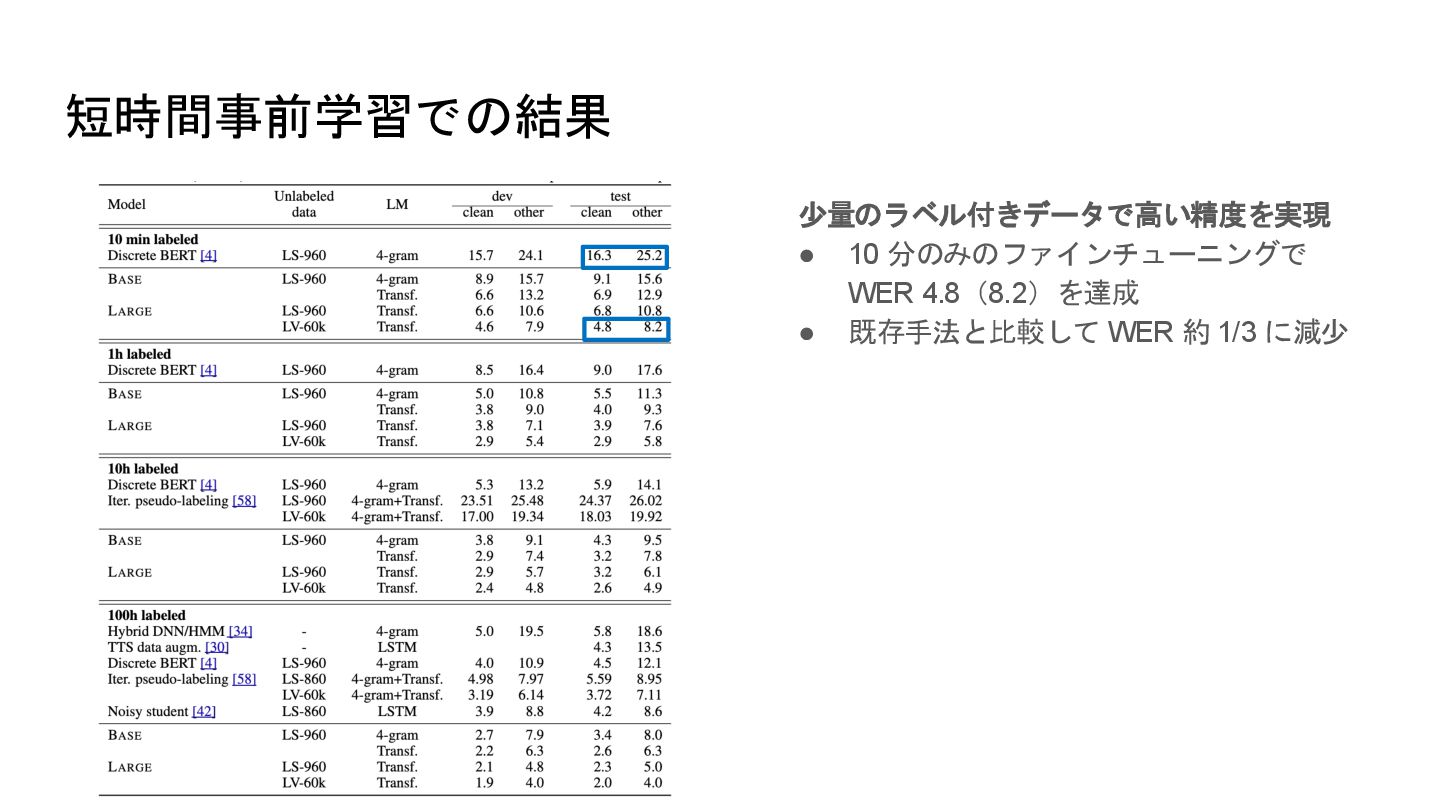
短時間事前学習での結果 少量のラベル付きデータで高い精度を実現 • 10 分のみのファインチューニングで WER 4.8(8.2)を達成 • 既存手法と比較して WER
約 1/3 に減少
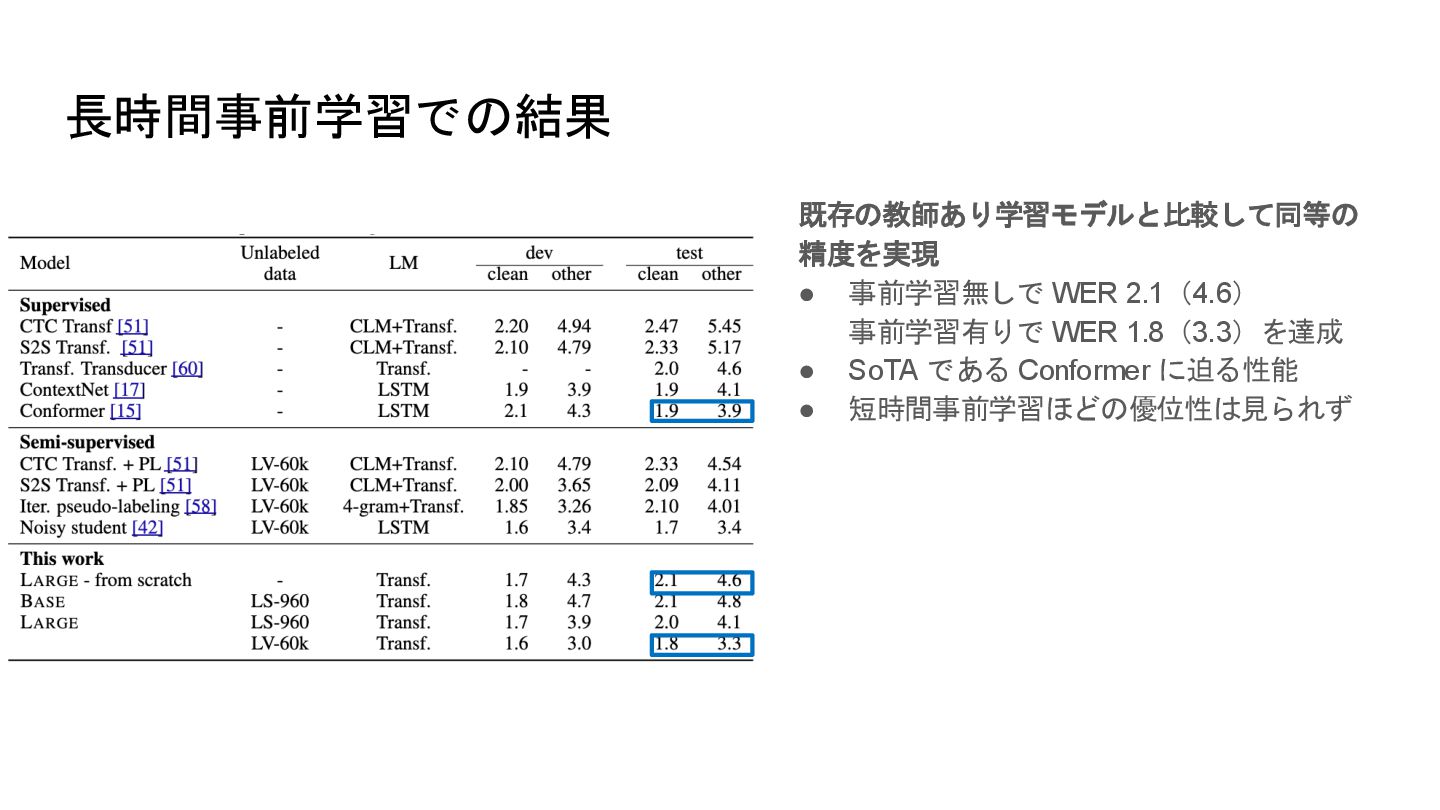
長時間事前学習での結果 既存の教師あり学習モデルと比較して同等の 精度を実現 • 事前学習無しで WER 2.1(4.6) 事前学習有りで WER 1.8(3.3)を達成
• SoTA である Conformer に迫る性能 • 短時間事前学習ほどの優位性は見られず
アブレーション 入力が Continuous feature,出力が Quantized feature の組み合わせが最も性能が良い
まとめ • ラベル無し音声を活用した表現学習モデルを提案 ◦ 音源から特徴ベクトルを作成 ◦ 潜在表現から量子化表現を作成 ◦ 特徴ベクトルと量子化表現を対照学習 •
短時間のファインチューニングで高い精度を実現
コメント • シンプルな構造で理解しやすかった • ファインチューニングが 10 分のデータで十分なことに驚いた • 他の信号処理の表現学習にも活用できそうだと感じた
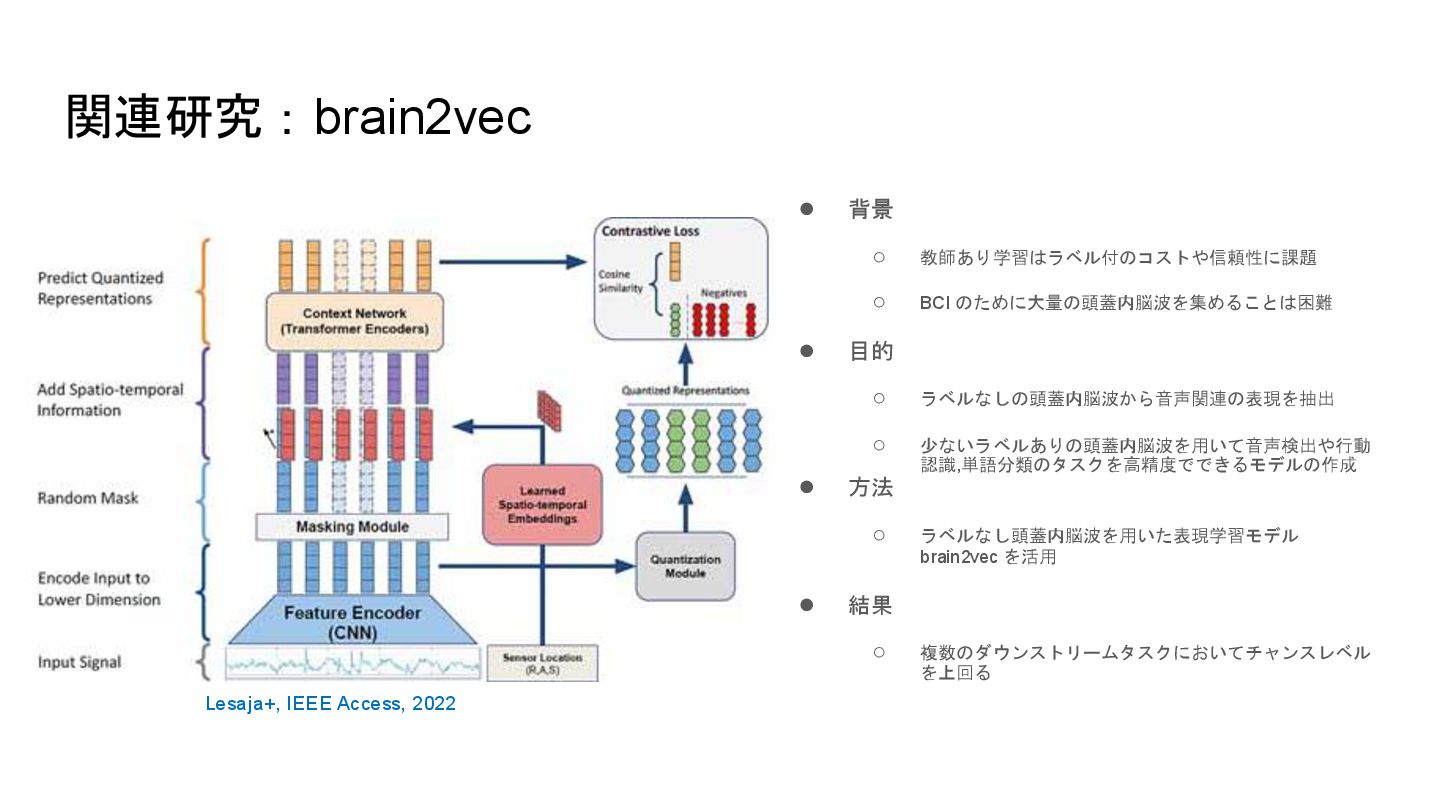
関連研究:brain2vec • 背景 ◦ 教師あり学習はラベル付のコストや信頼性に課題 ◦ BCI のために大量の頭蓋内脳波を集めることは困難 • 目的
◦ ラベルなしの頭蓋内脳波から音声関連の表現を抽出 ◦ 少ないラベルありの頭蓋内脳波を用いて音声検出や行動 認識,単語分類のタスクを高精度でできるモデルの作成 • 方法 ◦ ラベルなし頭蓋内脳波を用いた表現学習モデル brain2vec を活用 • 結果 ◦ 複数のダウンストリームタスクにおいてチャンスレベル を上回る Lesaja+, IEEE Access, 2022
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}