Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
MMaDA: Multimodal Large Diffusion Language Models
Search
ほき
June 21, 2025
30
0
Share
MMaDA: Multimodal Large Diffusion Language Models
ほき
June 21, 2025
More Decks by ほき
See All by ほき
Expert-Level Detection of Epilepsy Markers in EEG on Short and Long Timescales
hokkey621
0
32
TAID: Temporally Adaptive Interpolated Distillation for Efficient Knowledge Transfer in Language Models
hokkey621
0
30
脳波を用いた嗜好マッチングシステム
hokkey621
0
510
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
hokkey621
0
97
Learning to Model the World with Language
hokkey621
0
36
GeminiとUnityで実現するインタラクティブアート
hokkey621
0
1.7k
LT - Gemma Developer Time
hokkey621
0
25
wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
hokkey621
0
41
イベントを主催してわかった運営のノウハウ
hokkey621
0
84
Featured
See All Featured
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Designing for Performance
lara
611
70k
Crafting Experiences
bethany
1
160
30 Presentation Tips
portentint
PRO
1
310
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
Building AI with AI
inesmontani
PRO
1
1k
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2k
4 Signs Your Business is Dying
shpigford
187
22k
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
260
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
190
YesSQL, Process and Tooling at Scale
rocio
174
15k
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.3k
Transcript
https://www.academix.jp/ AcademiX 論文輪読会 MMaDA: Multimodal Large Diffusion Language Models ほき
2025/06/21
概要 • 背景 ◦ 既存の統合型マルチモーダル基盤モデル は モデル構造と事前学習 に焦点が偏在 ◦ 非
AR 系モデルのポストトレーニング を 深く掘り下げた研究はほとんどない • 目的 ◦ 統合型マルチモーダル・拡散基盤モデル の設計空間 を体系的に再検討しアーキテ クチャと学習パラダイムの両面で前進 • 方法 ◦ 確率的定式化とモダリティ非依存設計を採用し た統一された拡散アーキテクチャを採用 ◦ モダリティ全体で統一されたCoT形式をキュレ ート ◦ 統一ポリシー勾配ベースRLアルゴリズムを活用 • 結果 ◦ テキスト推論:LLaMA-3-7BやQwen2-7Bを凌駕 ◦ マルチモーダル理解:Show-oやSEED-Xを上回 る ◦ 画像生成:SDXLやJanusを凌駕 3
書誌情報 • MMaDA: Multimodal Large Diffusion Language Models • Ling
Yang, Ye Tian, Bowen Li, Xinchen Zhang, Ke Shen, Yunhai Tong, Mengdi Wang • 2025/05/21公開 • https://doi.org/10.48550/arXiv.2505.15809 ※引用のない図表は本論文より引用 4
MLMMの変遷 • 大規模言語モデル(LargeLanguageModel; LLM)は自然言語処理において 様々なタスクで最先端の性能を達成 • 研究コミュニティはLLMを マルチモーダルドメインに拡張 ◦ GPT-4
◦ Gemini • 初期のマルチモーダル研究は言語モデル+ディフュージョンモデルの組み合 わせ • その後自己回帰(Autoregressive; AR)型 が登場 • テキストは AR画像はディフュージョンで処理するハイブリッド方式も提案 5
ARモデルの課題 • 高い計算コスト:ARモデルはトークンを順次生成するため、計算コストが高 い • 反転推論タスクの限界:反転の呪い(reversal curse)と呼ばれる性能低下が 見られる • スケーラビリティの課題:連続的な拡散モデルをテキストデータに直接適用
する単純なアプローチでは同等の性能を達成するために多くの計算が必要 ※ここらへんは先週の発表を参照してください 6
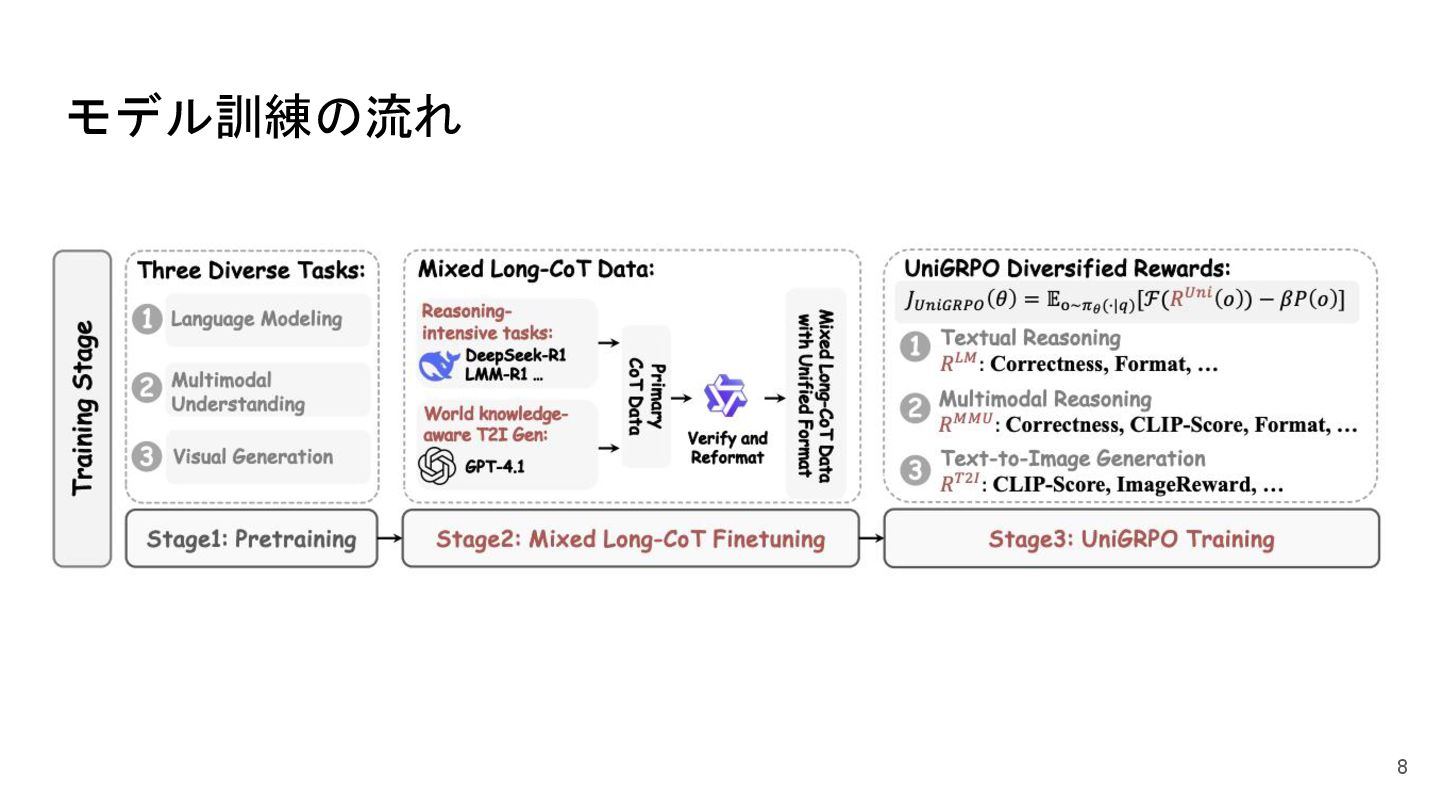
MMaDAの貢献 • 統一ディフュージョン基盤アーキテクチャ 離散・連続データをまたぐ単一の確率モデルとモダリティ非依存構造により モダリティ固有の部品を排除しつつ高性能を実現 • Mixed Long-CoT ポストトレーニング モダリティ横断で統一フォーマットの
“長尺 Chain-of-Thought” データを整備 し推論過程を揃えてクロスモーダルな相乗効果を引き出す • 統一型強化学習(UniGRPO) ディフュージョンモデルに特化した政策勾配型 RL を導入し多様な報酬設計 で推論・生成タスクを一括ポストトレーニング 7
モデル訓練の流れ 8
統一拡散アーキテクチャと目的関数を用いた事前学習 • LLaDAと同じ(省略) 9 Nie (2025)
混合ロングCoTとは • 使用データセット ◦ テキスト数学・論理推論データセット(ReasonFlux・LIMO・s1k・OpenThoughts・ AceMath-Instructなど) ◦ マルチモーダル推論データセット( LMM-R1モデルがGeoQAおよびCLEVRで生成した応 答)
• 統一CoT形式 ◦ タスクに依存しないCoT形式 |<special_token>| <reasoning_process> |<special_token>| <result> を提案 ▪ <reasoning_process>は、最終出力に先行するステップバイステップの推論軌跡をエン コード ▪ モダリティ固有の出力を橋渡ししタスク間の知識転送を促進 10
混合ロングCoTのファインチューニング方法 • プロンプトの保持とトークンマスク: 元のプロンプトを保持し結果内のトー クンを独立してマスク(マスクされたトークンはrt) • 入力と損失の共同計算: 結合された入力[p0, rt]を事前訓練されたマスク予測器 で損失計算
11
UniGRPOで解決したい課題 • 局所マスキング依存性 トークンレベルの対数尤度は,拡散プロセス中にマスクされた領域内でのみ 有効 • マスク比率の感度 ポリシー分布を近似するためには,応答セグメントに対して均一なマスク比 率をサンプリングする必要 •
非オートリグレッシブなシーケンスレベルの尤度 拡散モデルではオートリグレッシブな連鎖律が存在しないためシーケンスレ ベルの対数尤度をトークンレベルの確率から直接累積不可 12
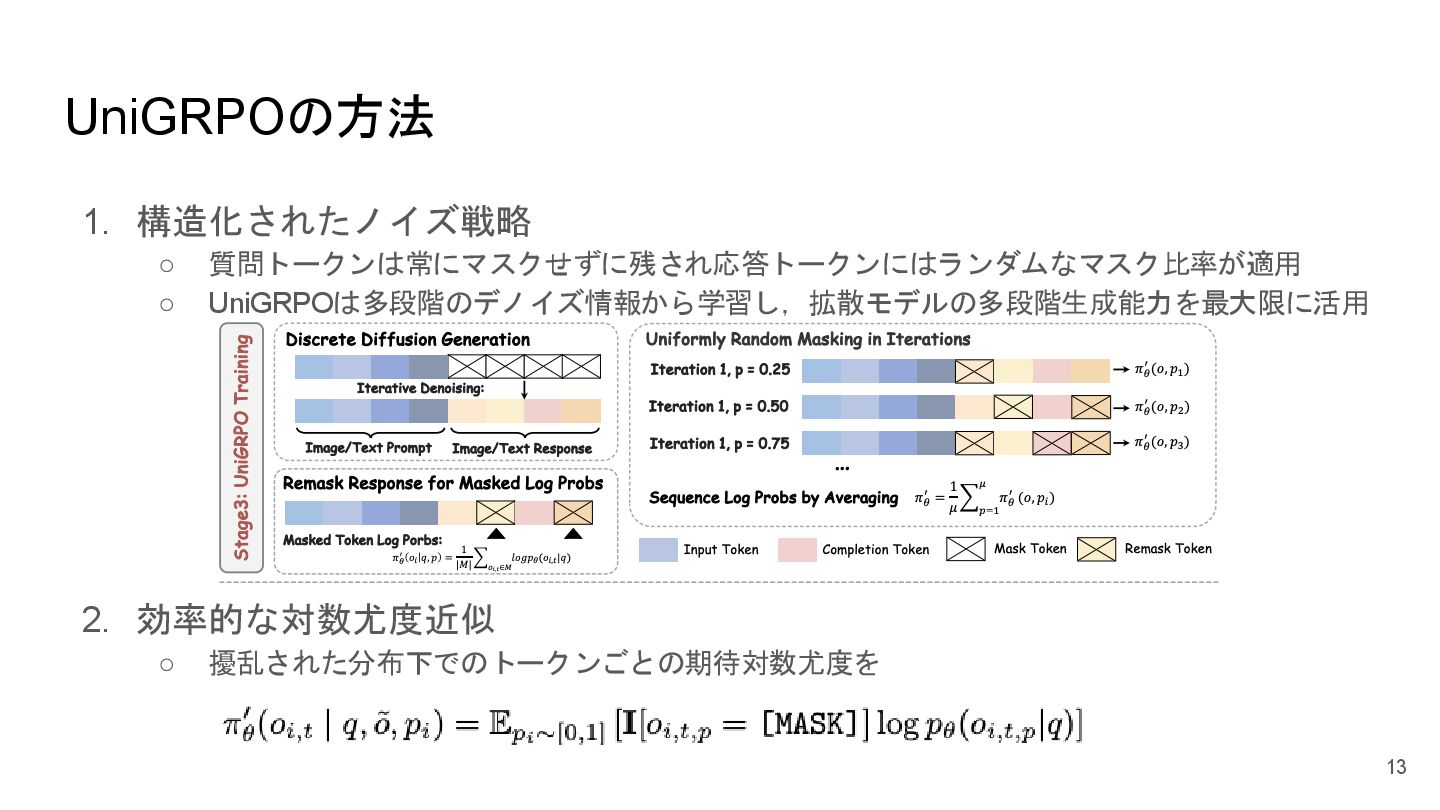
UniGRPOの方法 1. 構造化されたノイズ戦略 ◦ 質問トークンは常にマスクせずに残され応答トークンにはランダムなマスク比率が適用 ◦ UniGRPOは多段階のデノイズ情報から学習し,拡散モデルの多段階生成能力を最大限に活用 2. 効率的な対数尤度近似 ◦
擾乱された分布下でのトークンごとの期待対数尤度を 13
UniGRPOの方法 3. ポリシー勾配目的関数 ◦ 明示的な値関数のモデリングを排除しグループ相対的な方法でアドバンテージを計算 ◦ 最終的なUniGRPOの目的関数は、クリップされた代理報酬とKL正則化を統合した形式で定義 4. 多様な報酬モデリング ◦
テキスト推論報酬 正しい回答には2.0の正確性報酬,定義されたフォーマットに準拠した応答には0.5のフォーマット報酬を適 用 ◦ マルチモーダル推論報酬 ▪ 数学タスクにはテキスト推論と同じ正確性報酬とフォーマット報酬を適用 ▪ キャプションベースのタスクでは、さらにテキストと画像の整合性を測るCLIP報酬(0.1 * CLIPスコ ア)を導入し,その影響のバランスを取る ◦ テキストから画像への生成報酬: テキストと画像の意味的な整合性を評価するためにCLIP報酬を組み込み,さらに人間の好みを反映する ImageRewardも利用 14
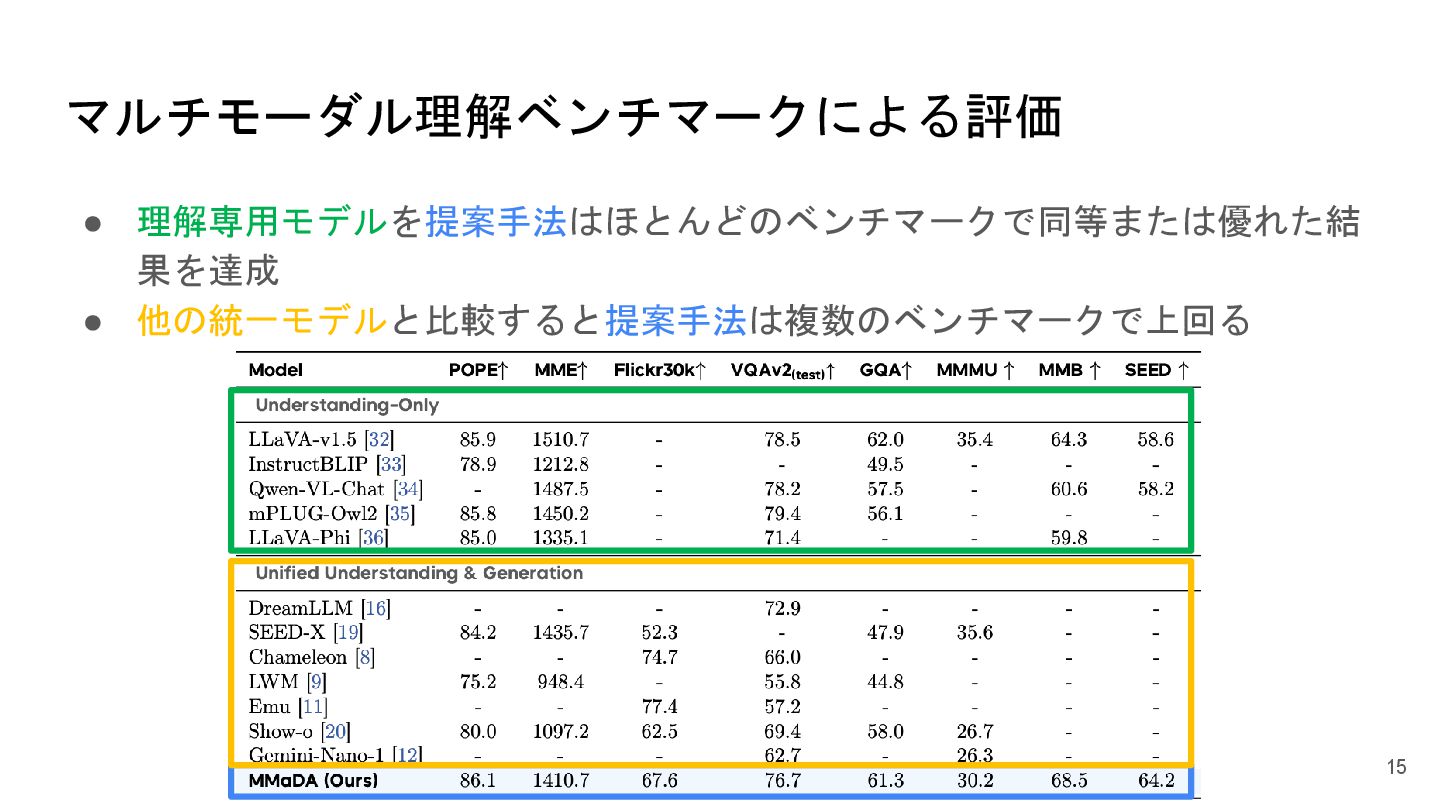
マルチモーダル理解ベンチマークによる評価 • 理解専用モデルを提案手法はほとんどのベンチマークで同等または優れた結 果を達成 • 他の統一モデルと比較すると提案手法は複数のベンチマークで上回る 15
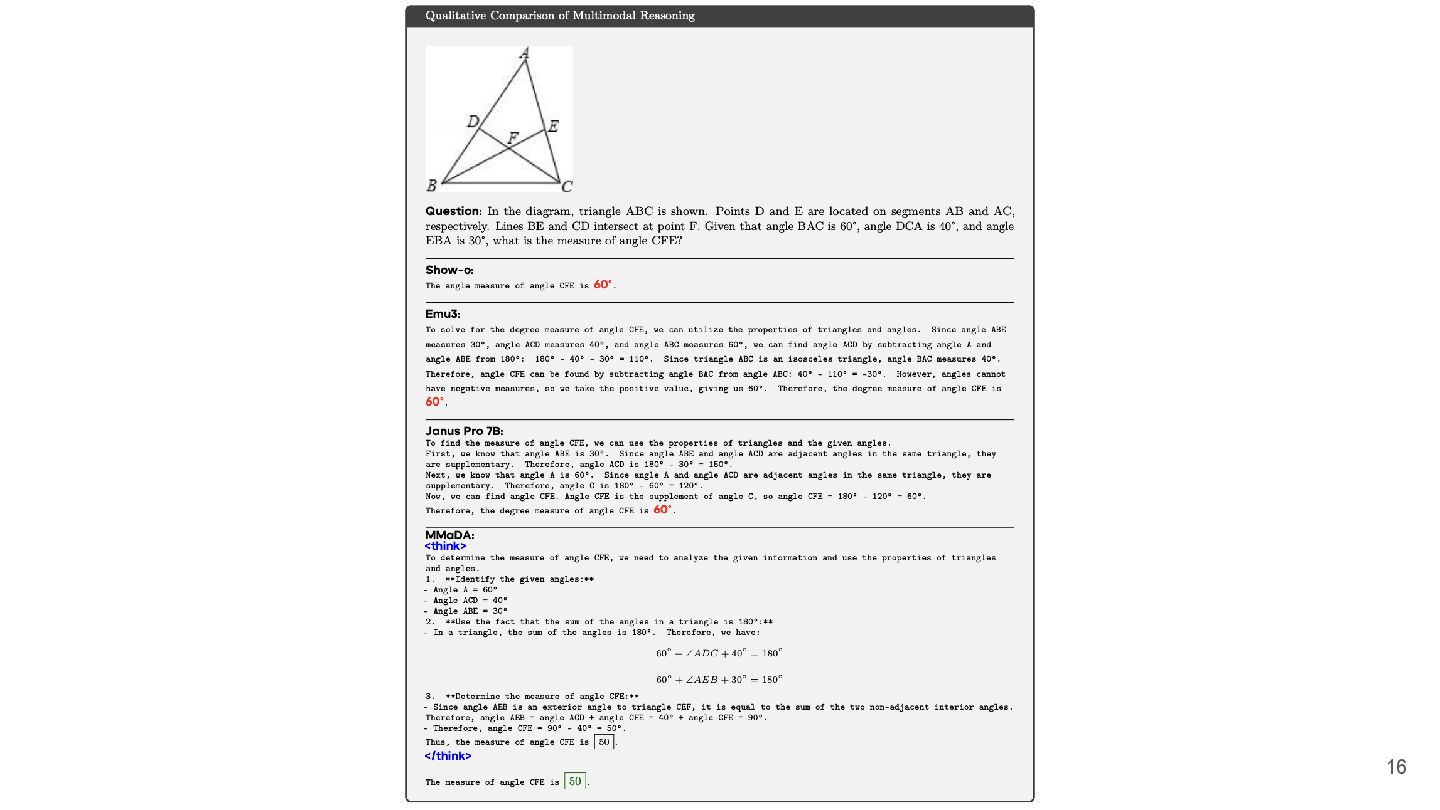
16
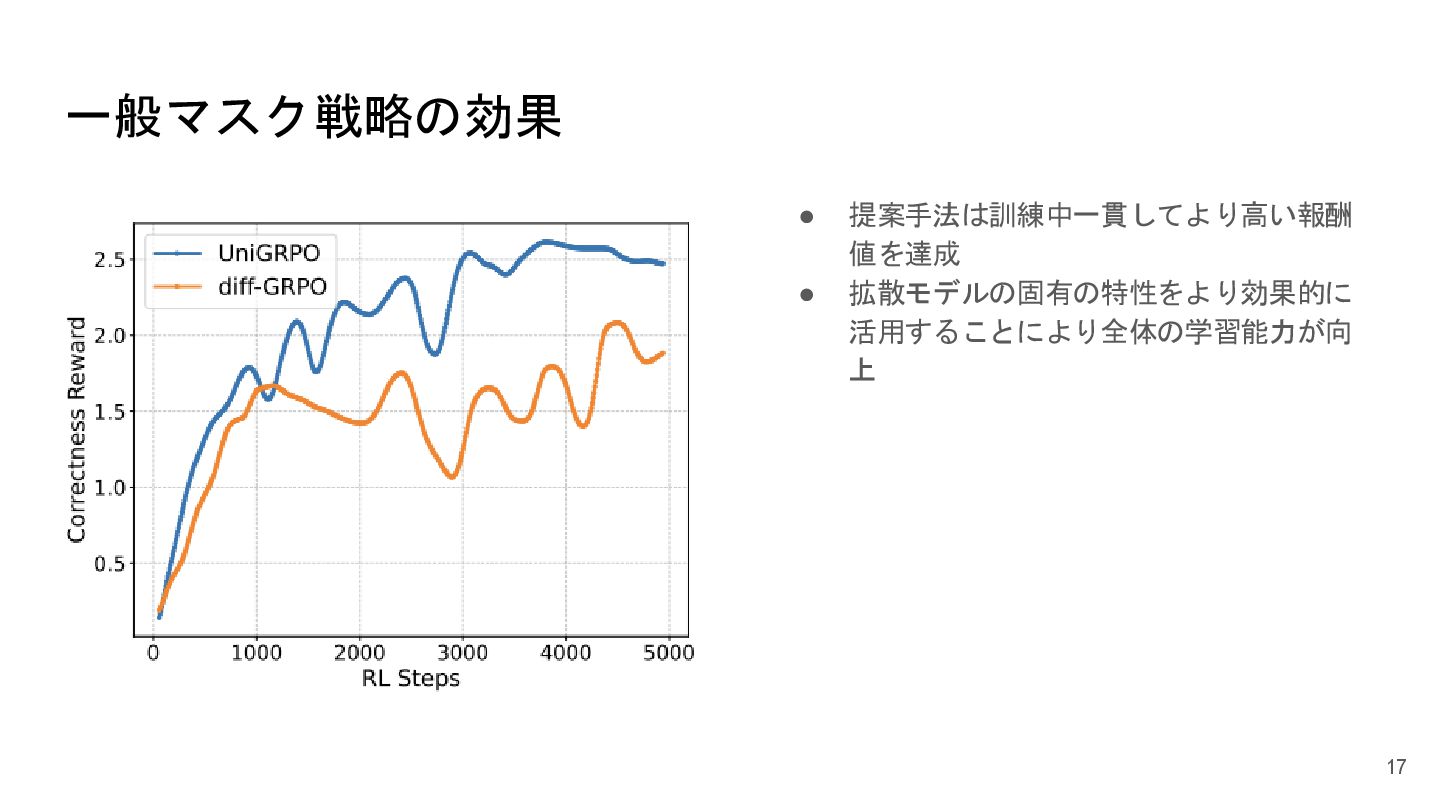
一般マスク戦略の効果 • 提案手法は訓練中一貫してより高い報酬 値を達成 • 拡散モデルの固有の特性をより効果的に 活用することにより全体の学習能力が向 上 17
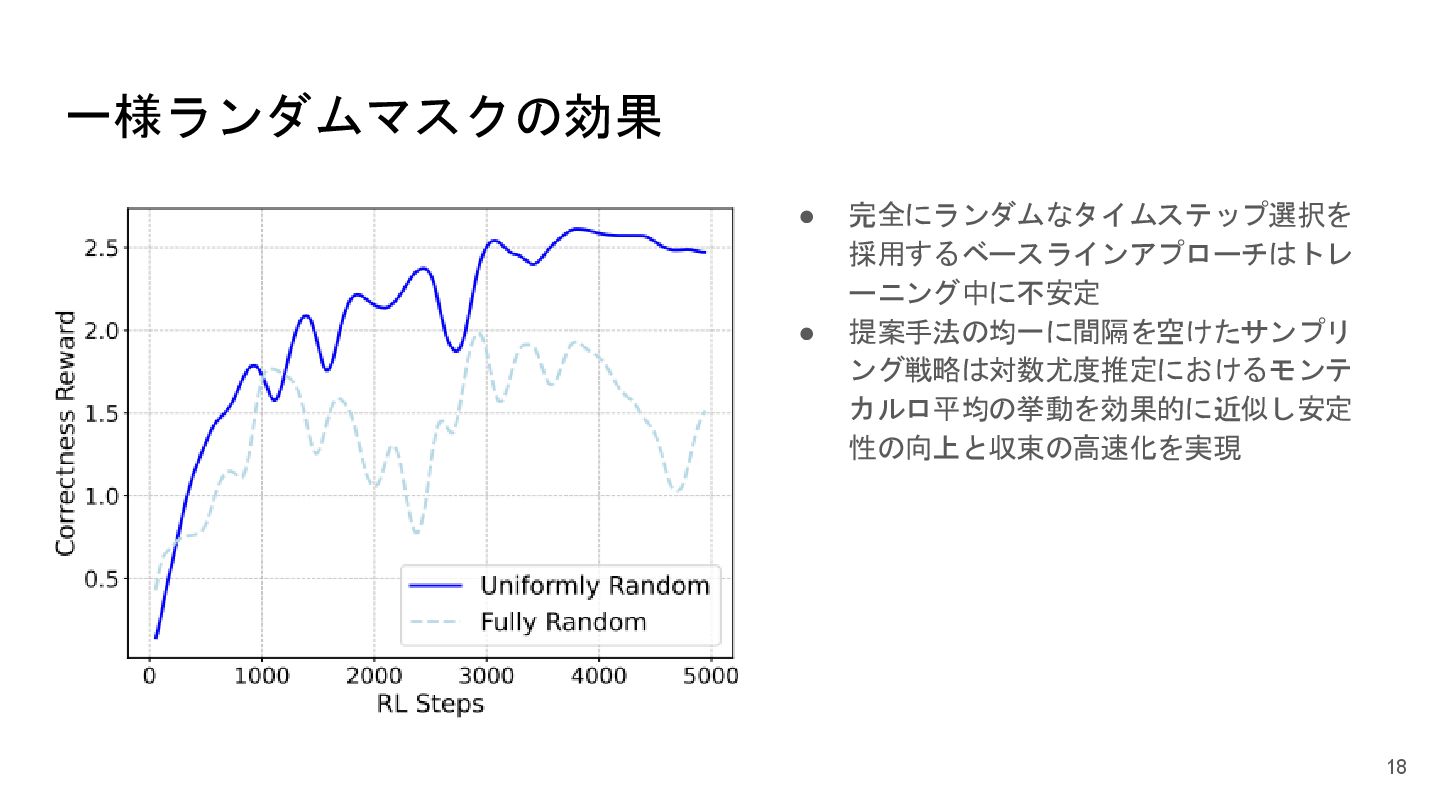
一様ランダムマスクの効果 • 完全にランダムなタイムステップ選択を 採用するベースラインアプローチはトレ ーニング中に不安定 • 提案手法の均一に間隔を空けたサンプリ ング戦略は対数尤度推定におけるモンテ カルロ平均の挙動を効果的に近似し安定 性の向上と収束の高速化を実現
18
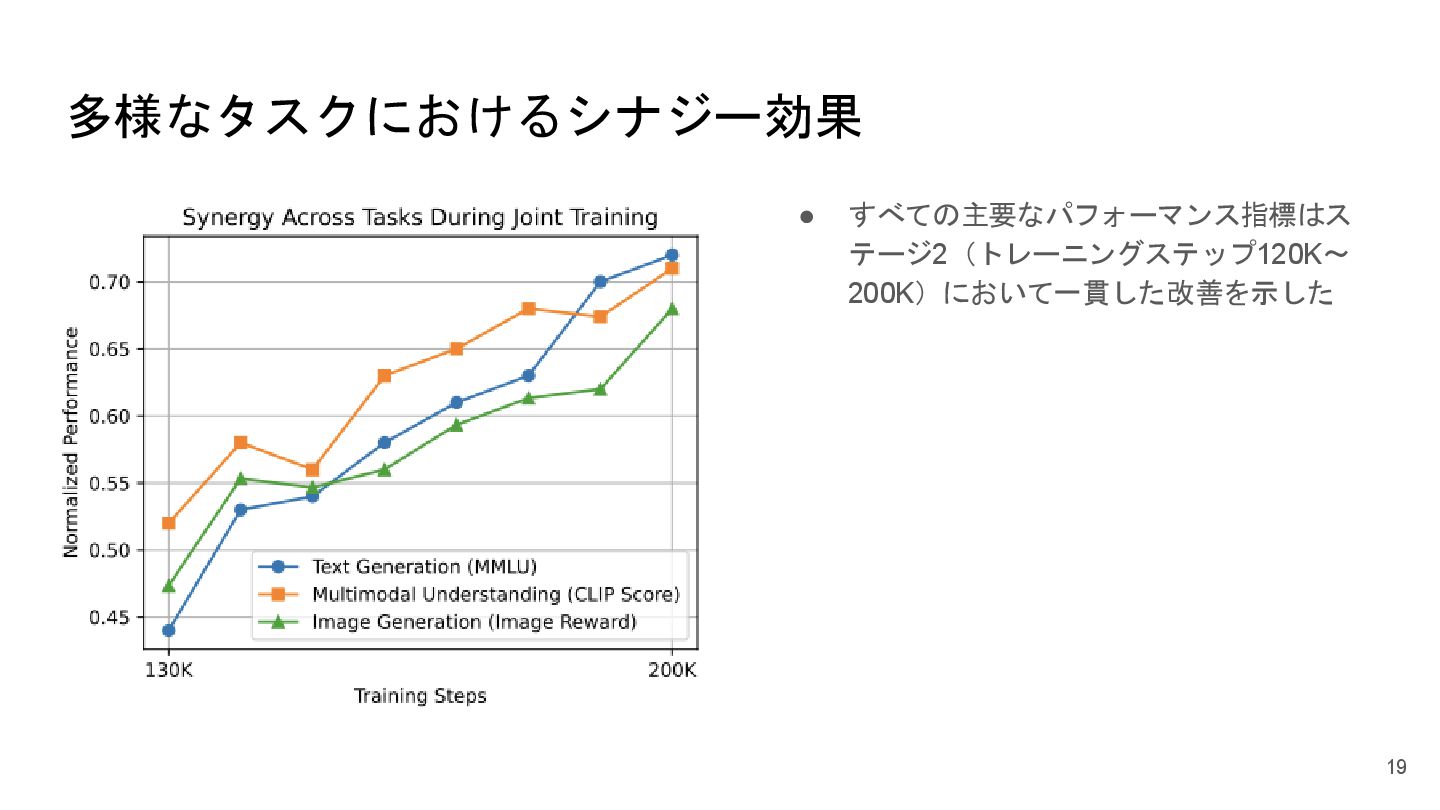
多様なタスクにおけるシナジー効果 • すべての主要なパフォーマンス指標はス テージ2(トレーニングステップ120K~ 200K)において一貫した改善を示した 19
多様なタスクにおけるシナジー効果 • モデルの応答複雑で一貫性のあるものに変化 ◦ テキスト出力はより情報豊富で論理的に構造化されたものとなり,ビジュアル理解はより正 確で現実的な説明を生成 • 同じプロンプトに対して生成される画像は,より正確で詳細になりクロスモ ーダルな一致性と構成性が向上 20
サンプリング効率 • 画像生成 ◦ 15ステップや50ステップといった少ないステップ数でも高い性能を維持 • テキストやマルチモーダルタスク ◦ フルステップの4分の1や半分で一貫性のある出力を得る •
拡散ベースの言語モデルの効率性の可能性を強調し,サンプリング技術や高 次ソルバーの今後の進歩がその速度と品質をさらに向上させる可能性を示唆 21
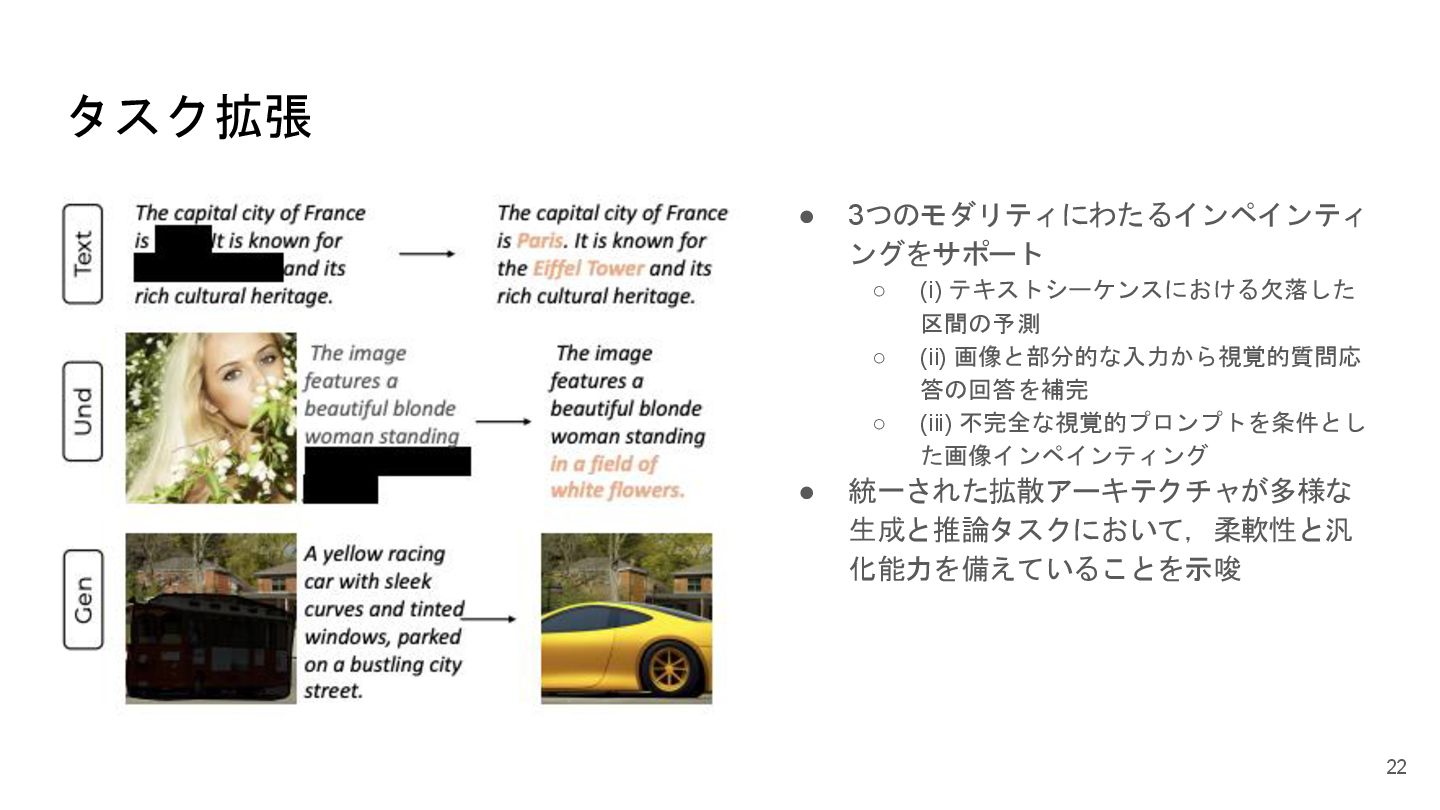
タスク拡張 • 3つのモダリティにわたるインペインティ ングをサポート ◦ (i) テキストシーケンスにおける欠落した 区間の予測 ◦ (ii)
画像と部分的な入力から視覚的質問応 答の回答を補完 ◦ (iii) 不完全な視覚的プロンプトを条件とし た画像インペインティング • 統一された拡散アーキテクチャが多様な 生成と推論タスクにおいて,柔軟性と汎 化能力を備えていることを示唆 22
まとめ • テキスト推論,マルチモーダル理解,生成を単一の確率的枠組み内に統合し た統一的な拡散型基盤モデルであるMMaDAを提案 • 多様なビジョン・言語タスクにおける広範な実験結果から,MMaDAは専門 モデルと同等またはそれ以上の性能を示し • MMaDAは現在のモデルサイズ(8Bパラメーター)に起因する制限を有して おり,より高い性能を実現するため,より大規模なモデルサイズを採用予定
23
おまけ • https://huggingface.co/spaces/Gen-Verse/MMaDA 24
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![混合ロングCoTのファインチューニング方法 • プロンプトの保持とトークンマスク: 元のプロンプトを保持し結果内のトー クンを独立してマスク(マスクされたトークンはrt) • 入力と損失の共同計算: 結合された入力[p0, rt]を事前訓練されたマスク予測器 で損失計算](https://files.speakerdeck.com/presentations/afe387a568794decb04ad35ef8c0c0d3/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}