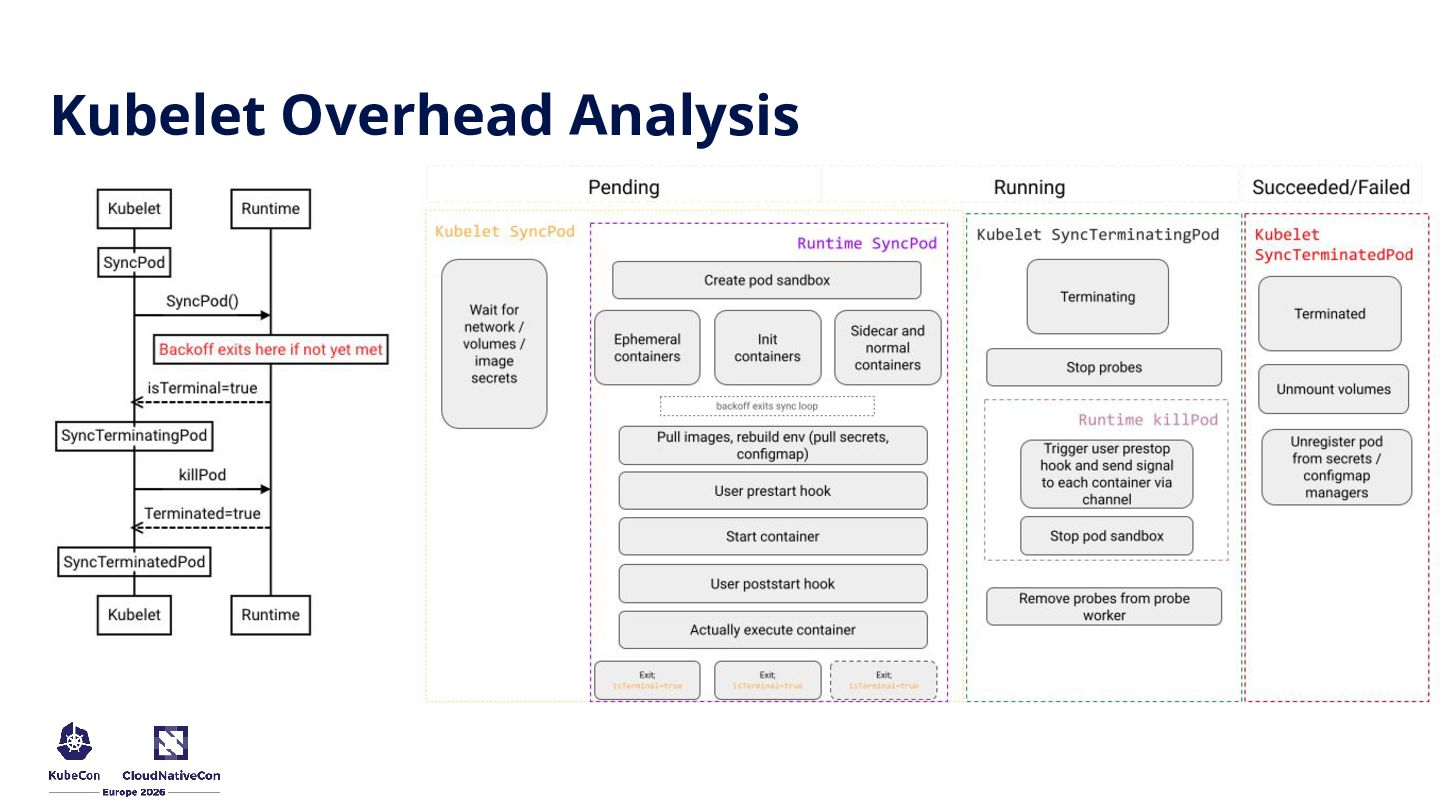
without Pod rescheduling overhead. • Fast Restart on Failure: Transient, recoverable errors causing massive cascade delays in AI/ML. • Critical Sidecars: Infra kills (e.g., OOMKilled proxies) isolating perfectly healthy main apps.
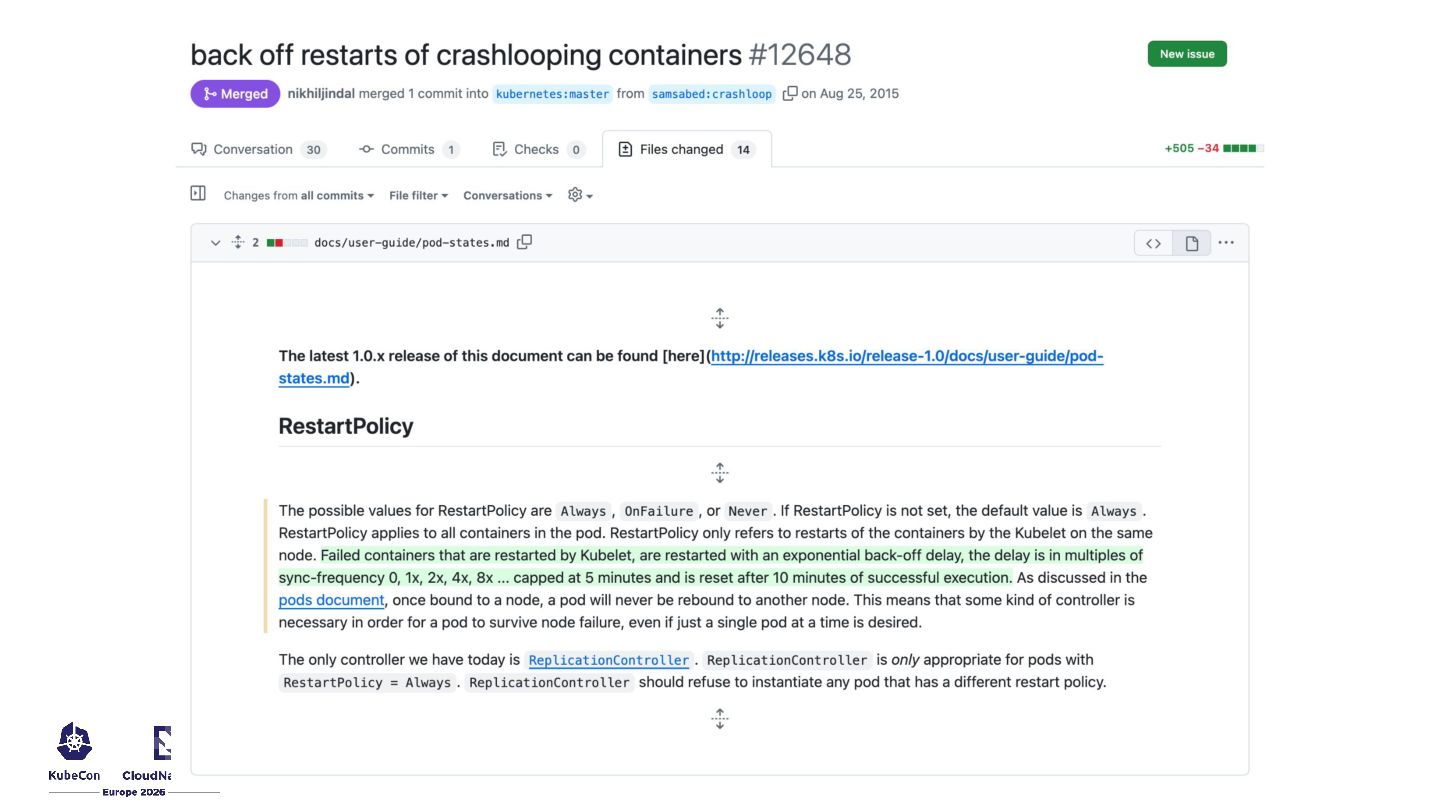
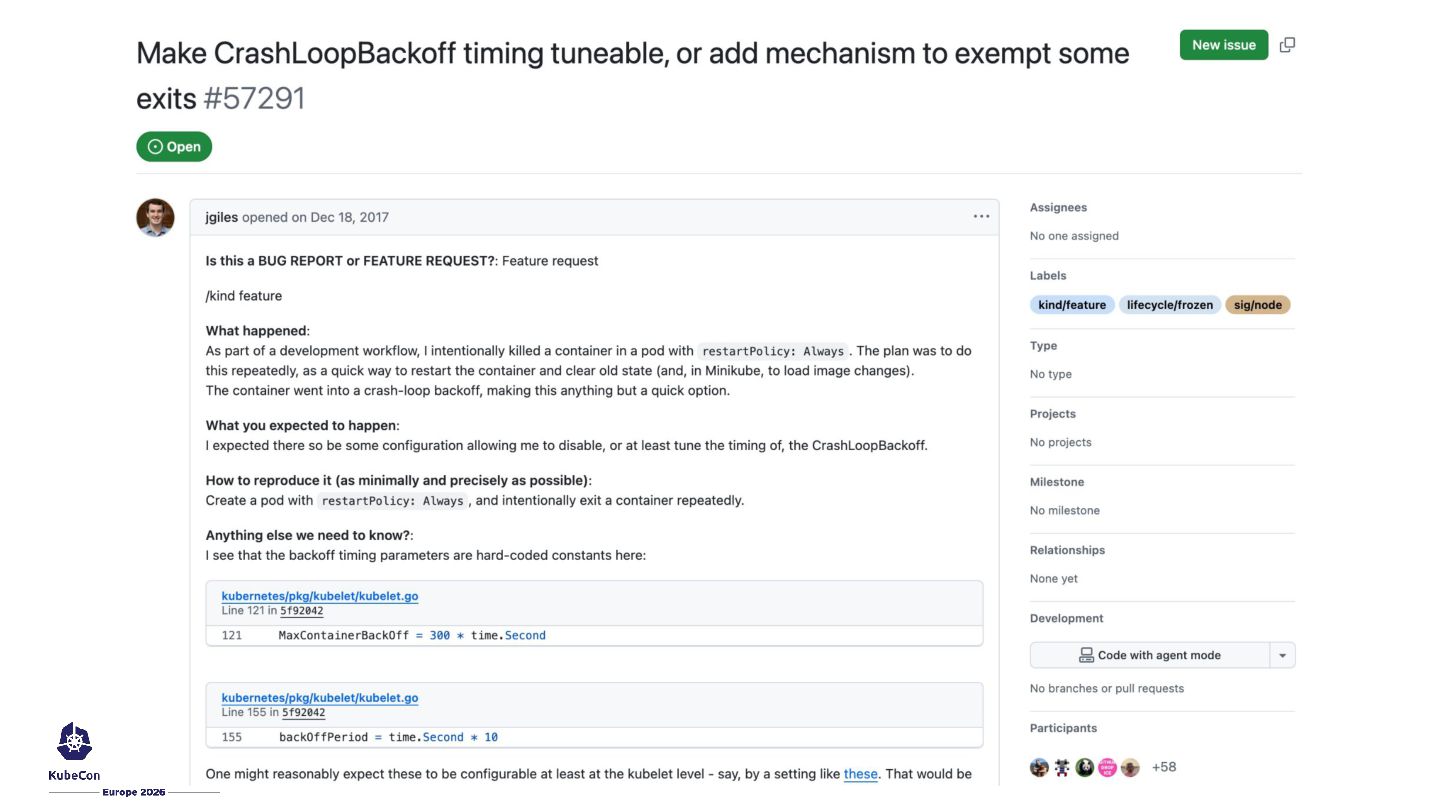
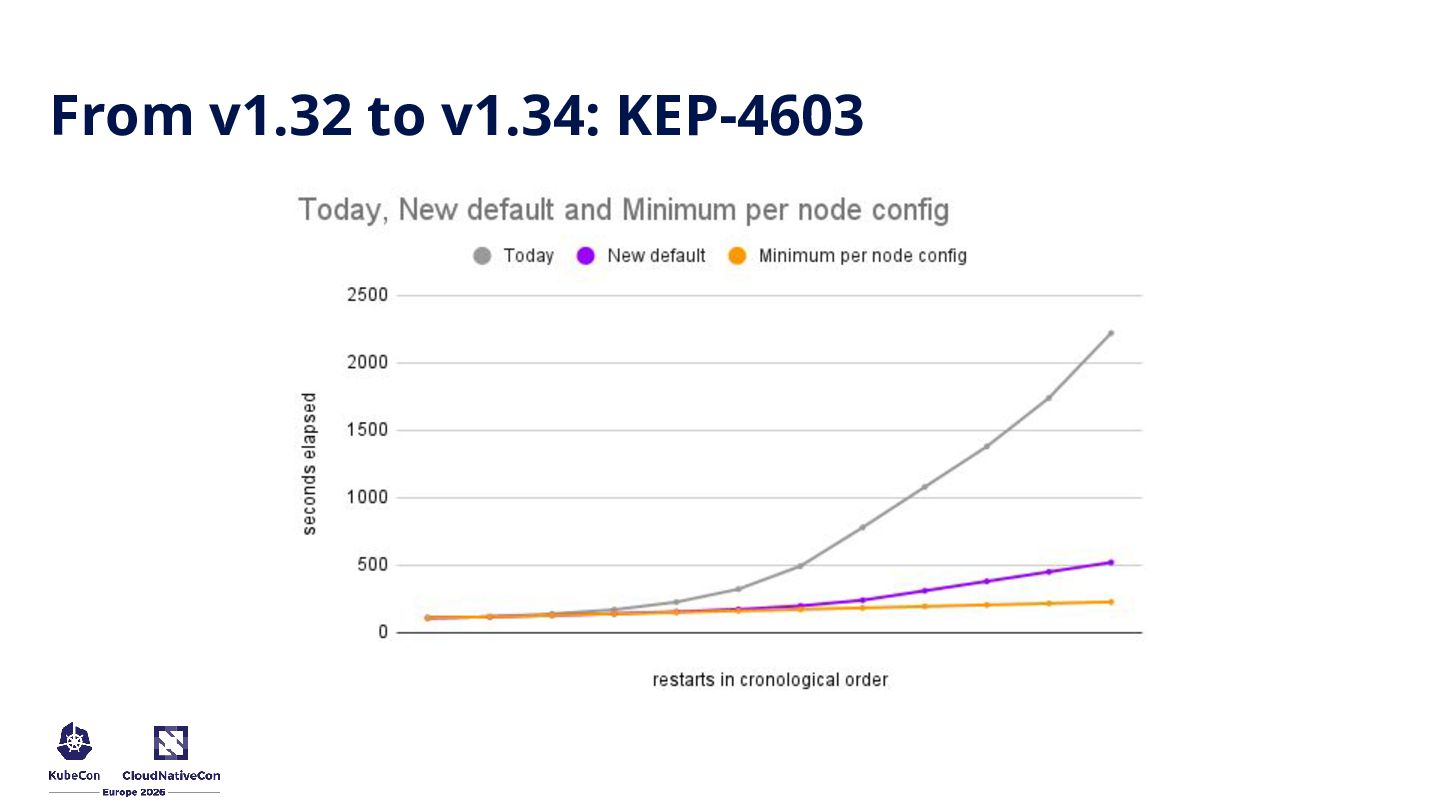
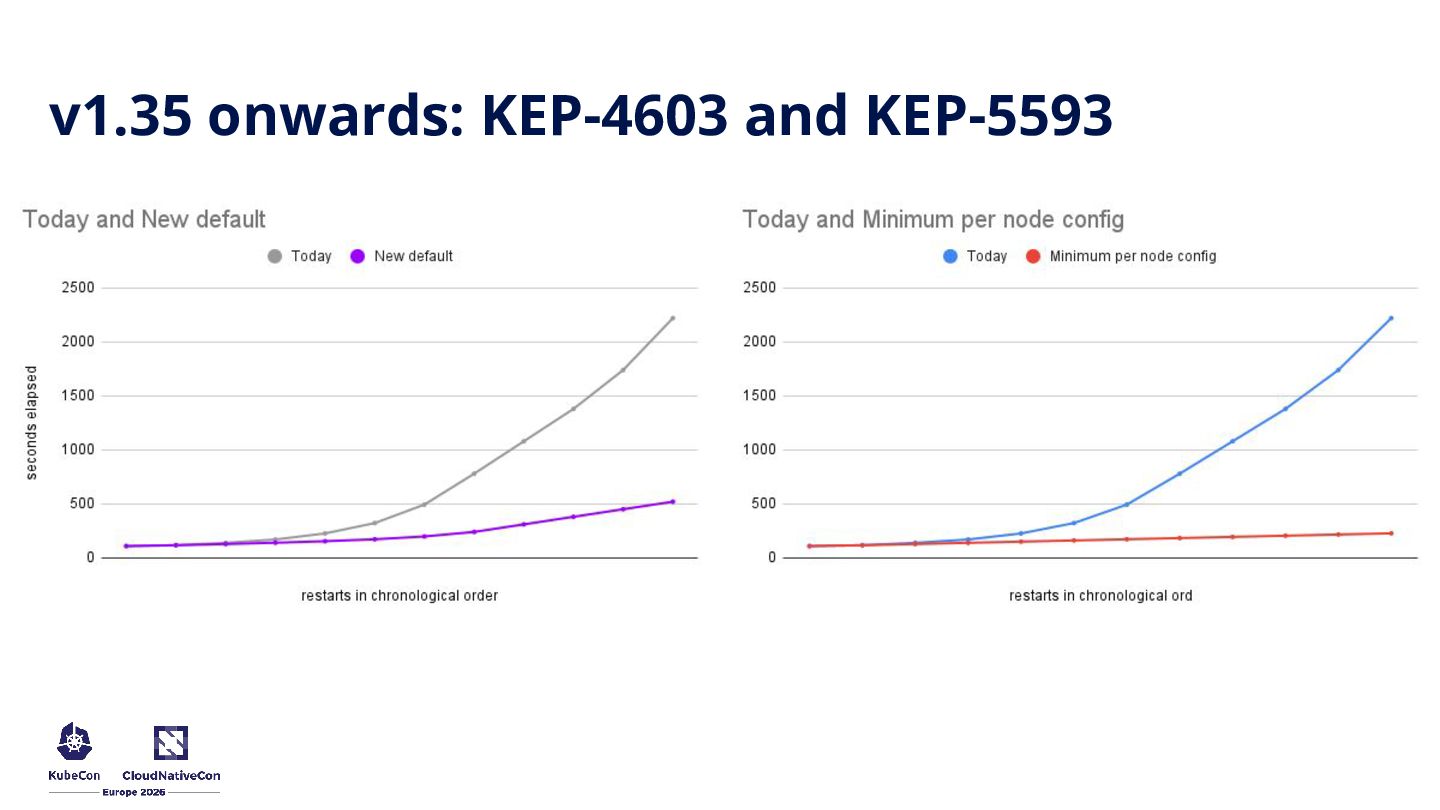
start at 10s, increasing # 2x each time they are restarted, to a maximum of 100s crashLoopBackOff: maxContainerRestartPeriod: "100s" apiVersion: kubelet.config.k8s.io/v1beta1 kind: KubeletConfiguration # delays between container restarts will always be 2s crashLoopBackOff: maxContainerRestartPeriod: "2s"
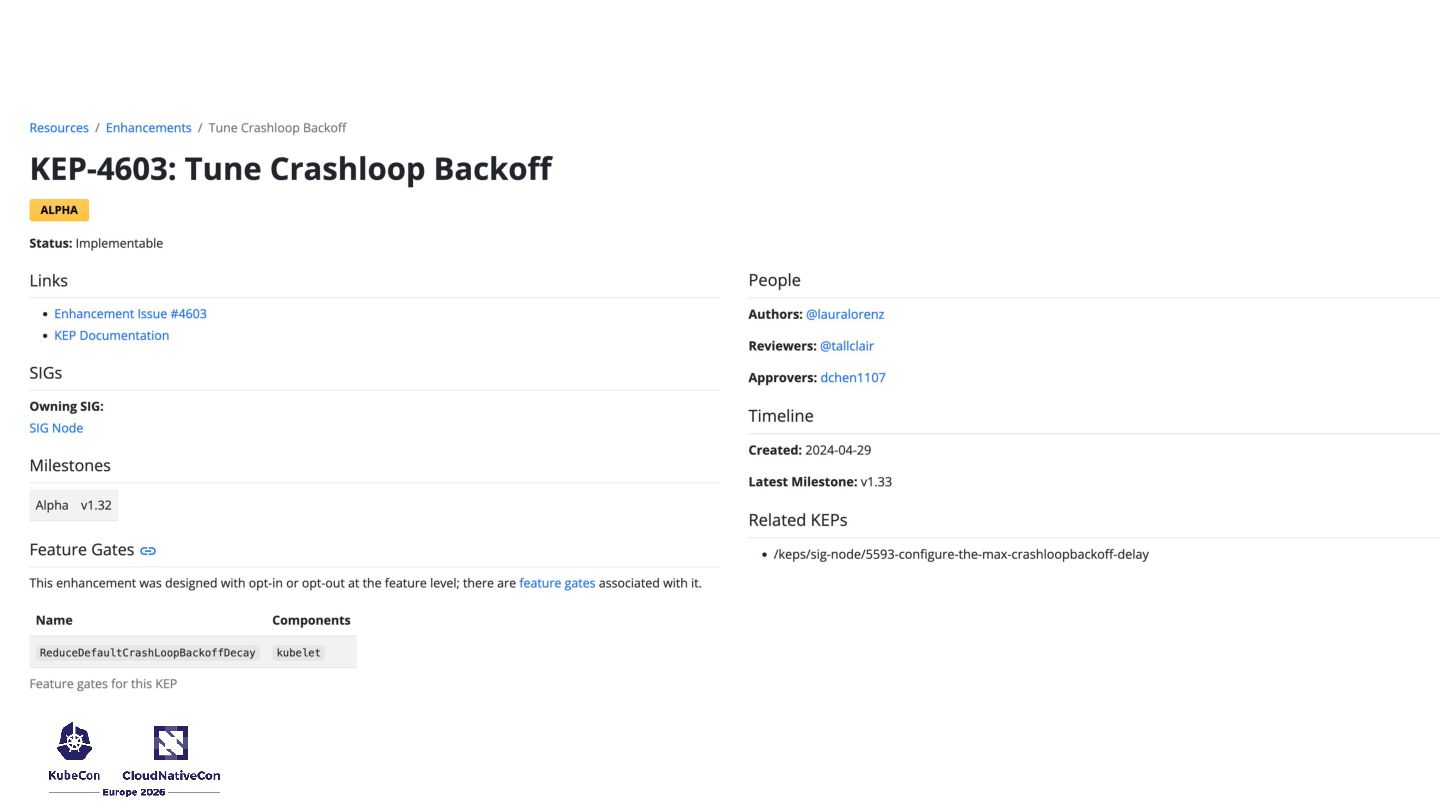
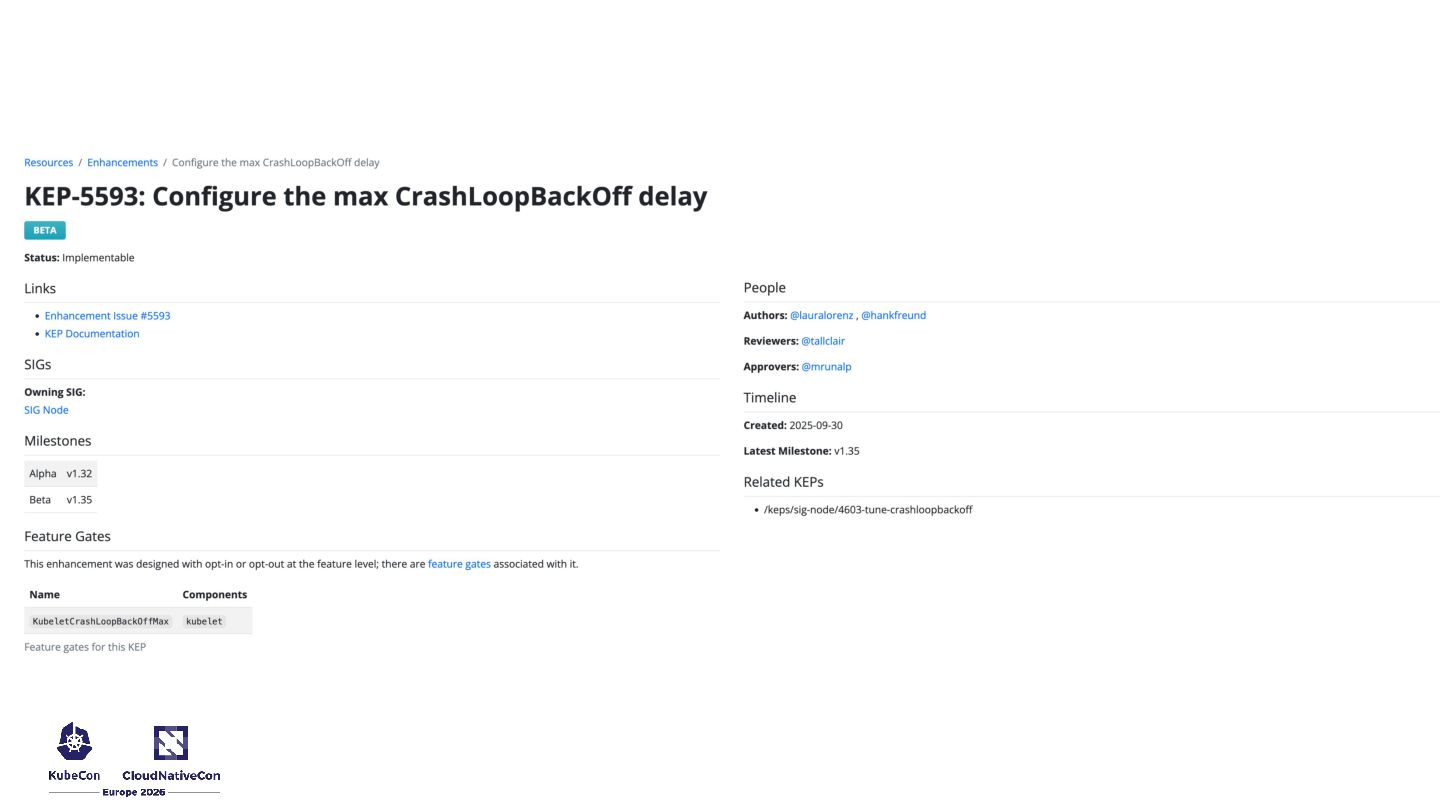
physical limits • KEP-4603 and KEP-5593 gives cluster operators granular, safe control over recovery times • Open source is a marathon, pragmatic splits unblock years of frustration
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}