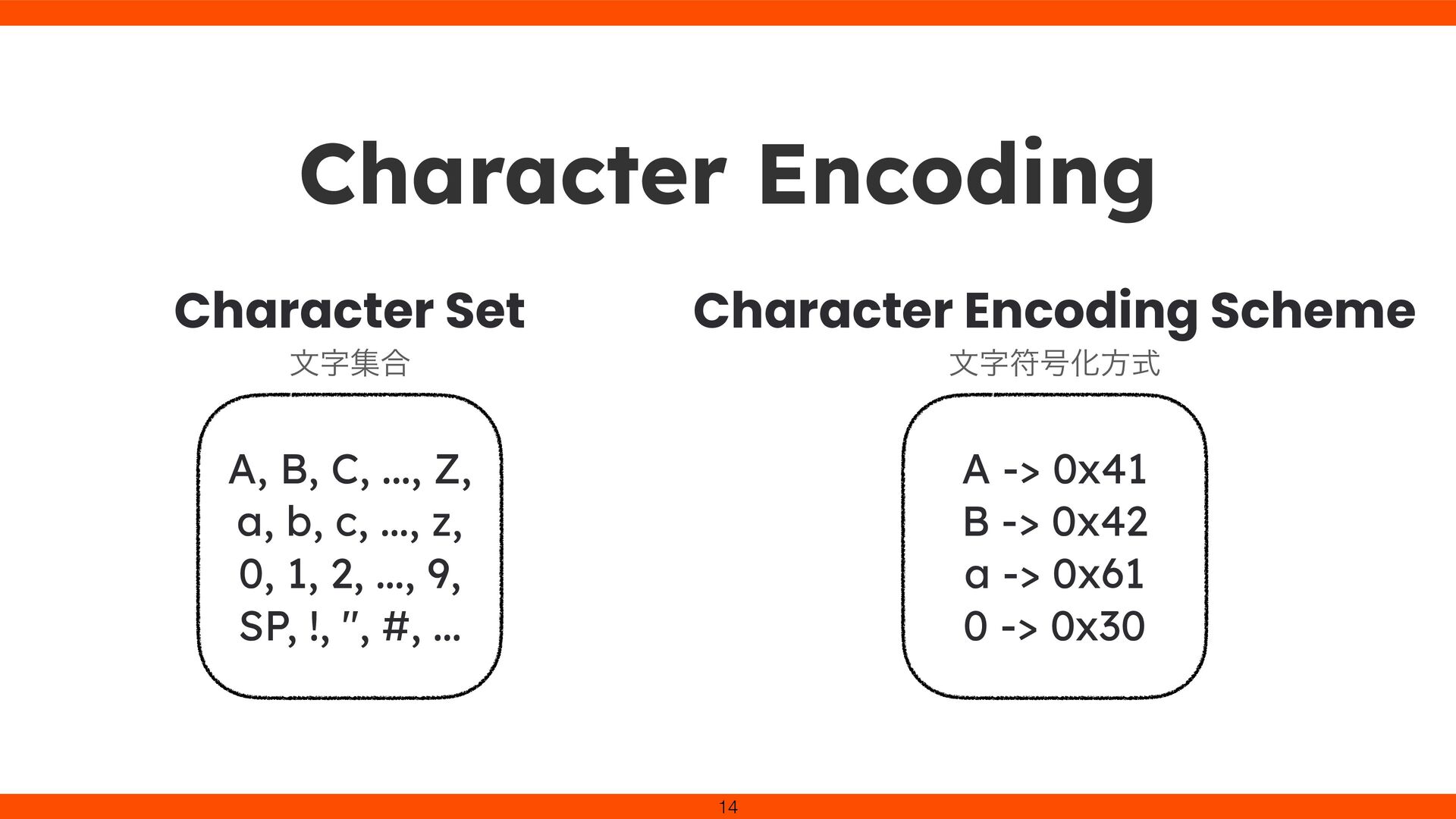
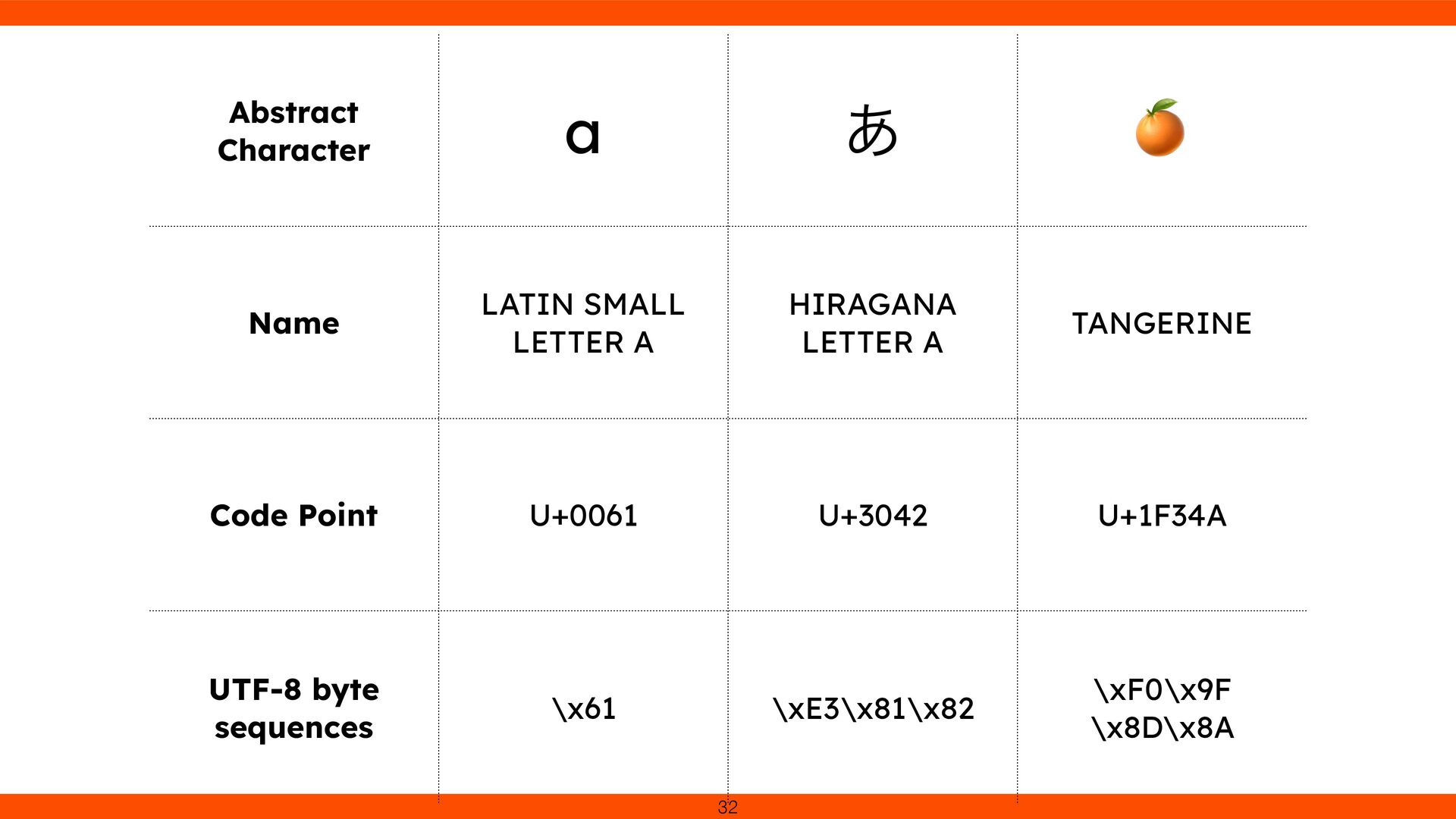
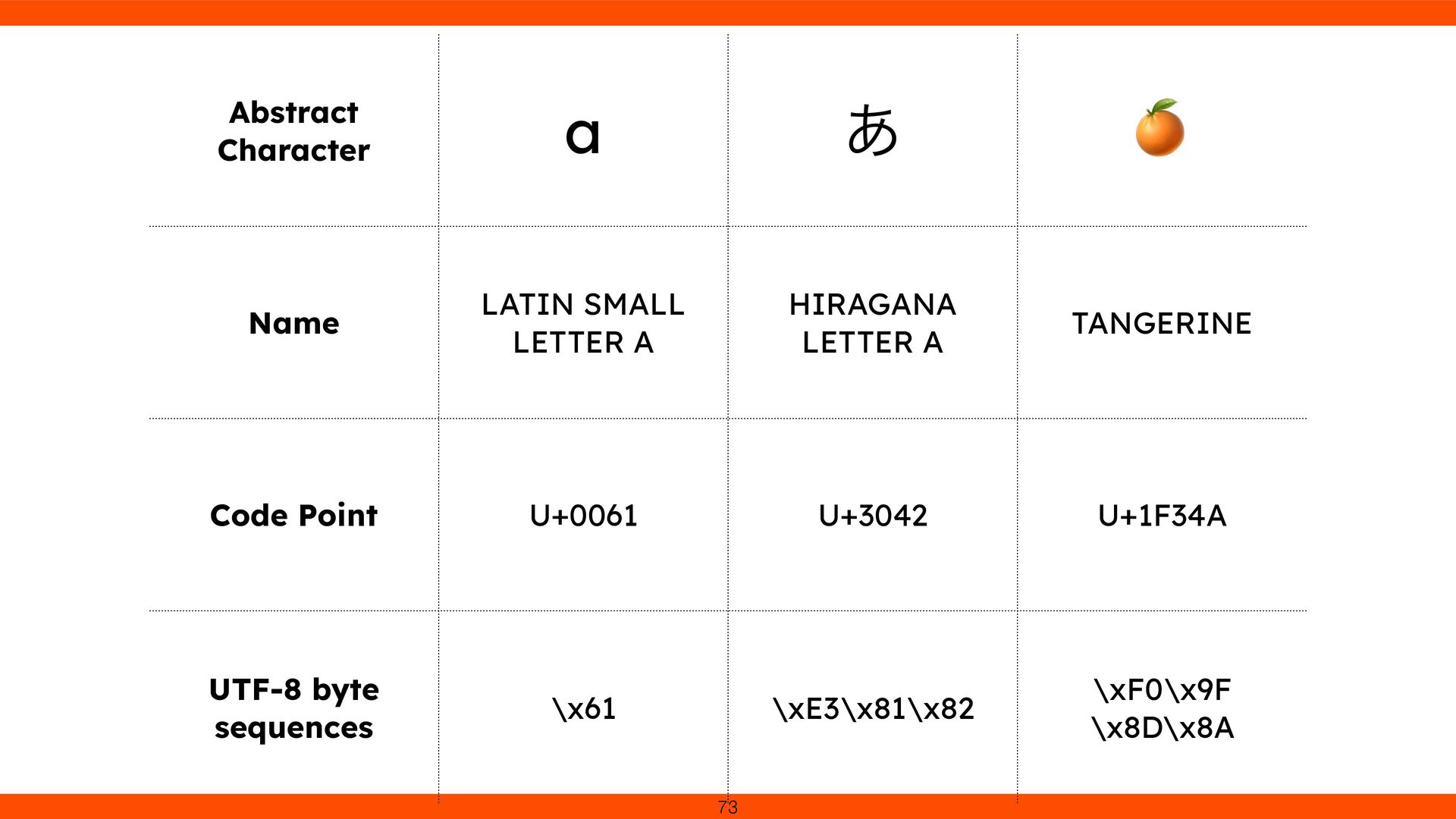
with unique code points. UTF-8 transforms these code points into a variable-length sequence of 1–4 bytes. In short, Unicode is the “what,” and UTF-8 is the “how.” 31
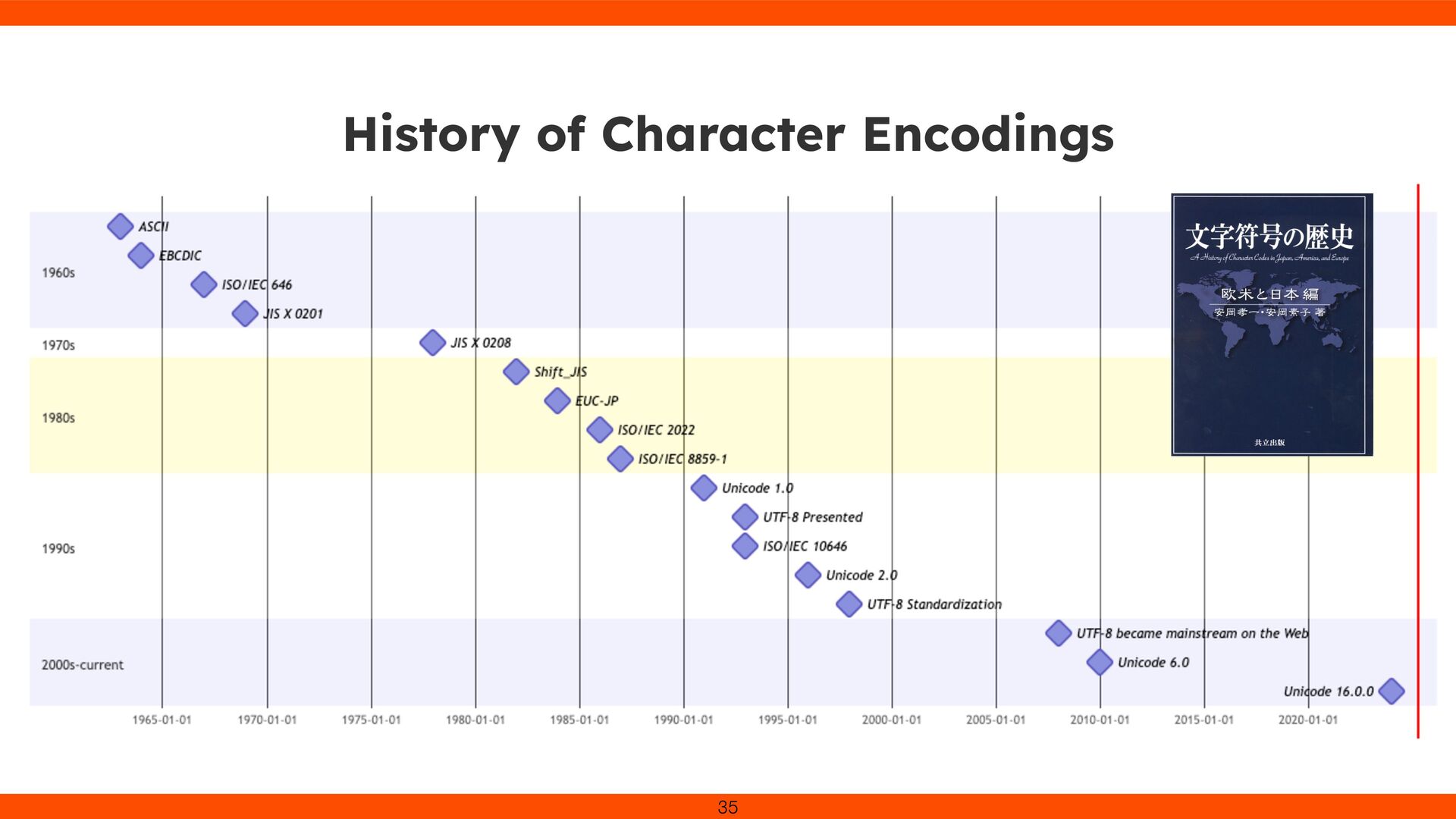
the world was already using Unicode. The major issues with character encoding proliferation and incompatibility primarily surfaced in the 1990s. So why did I become a “character encoding enthusiast” in a Unicode era? 38
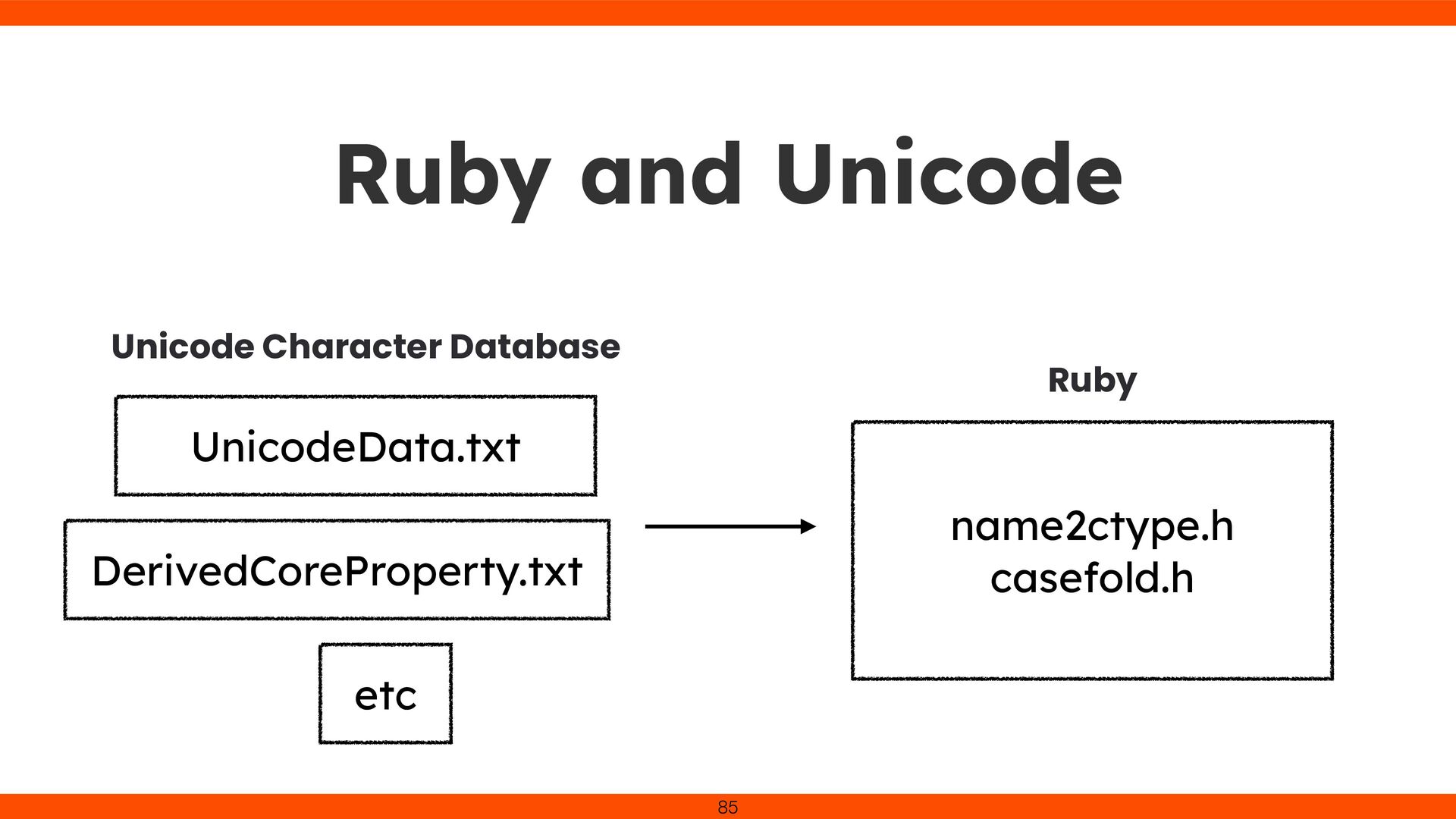
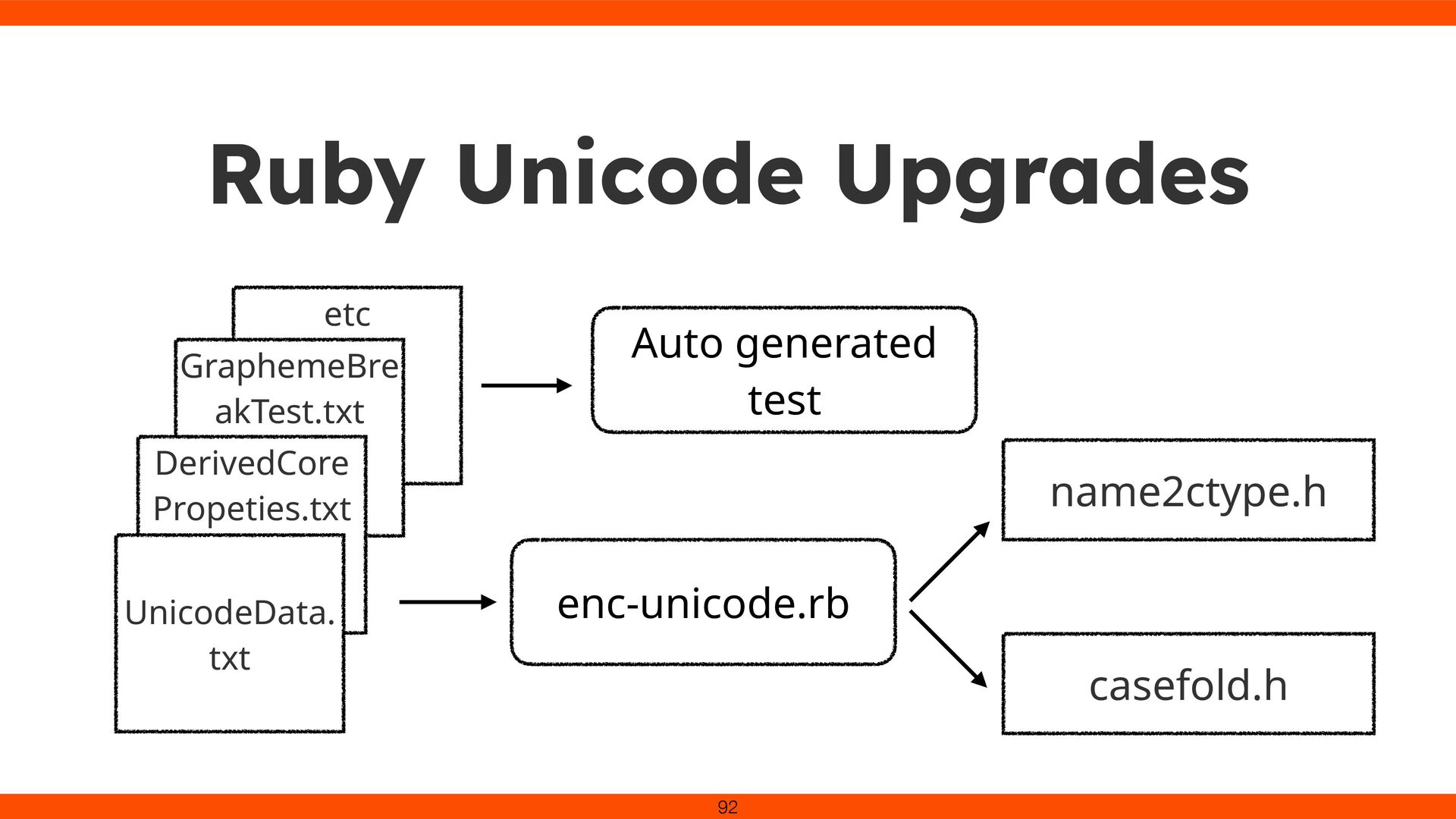
to ASCII and other encodings. Unicode became the universal solution. Even in the Unicode era, deep knowledge of character encodings remains essential. 39
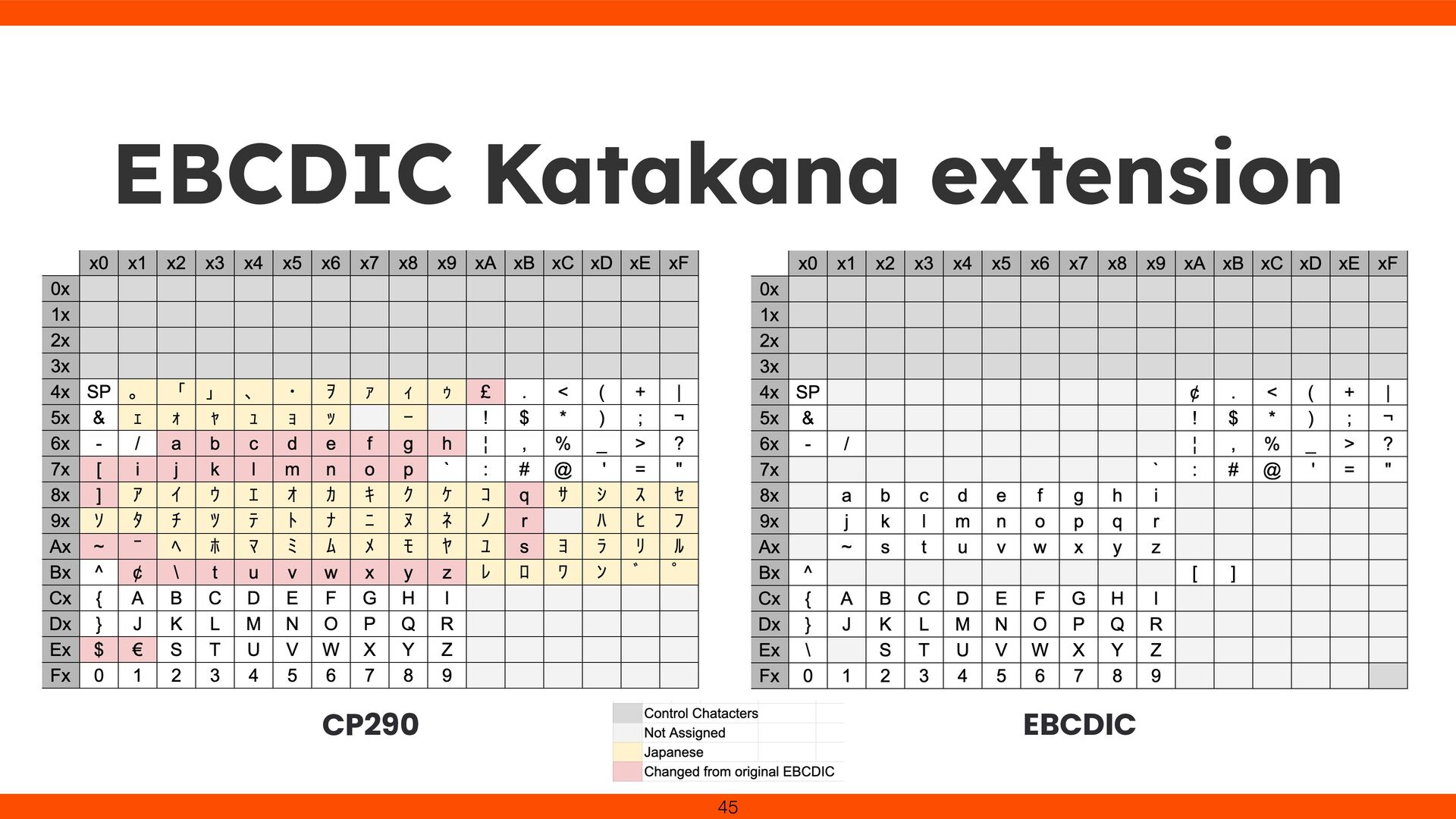
impossible to fully represent Japanese: Hiragana: about 50 characters Katakana: about 50 characters Joyo kanji (commonly used kanji): 2,136 characters 44
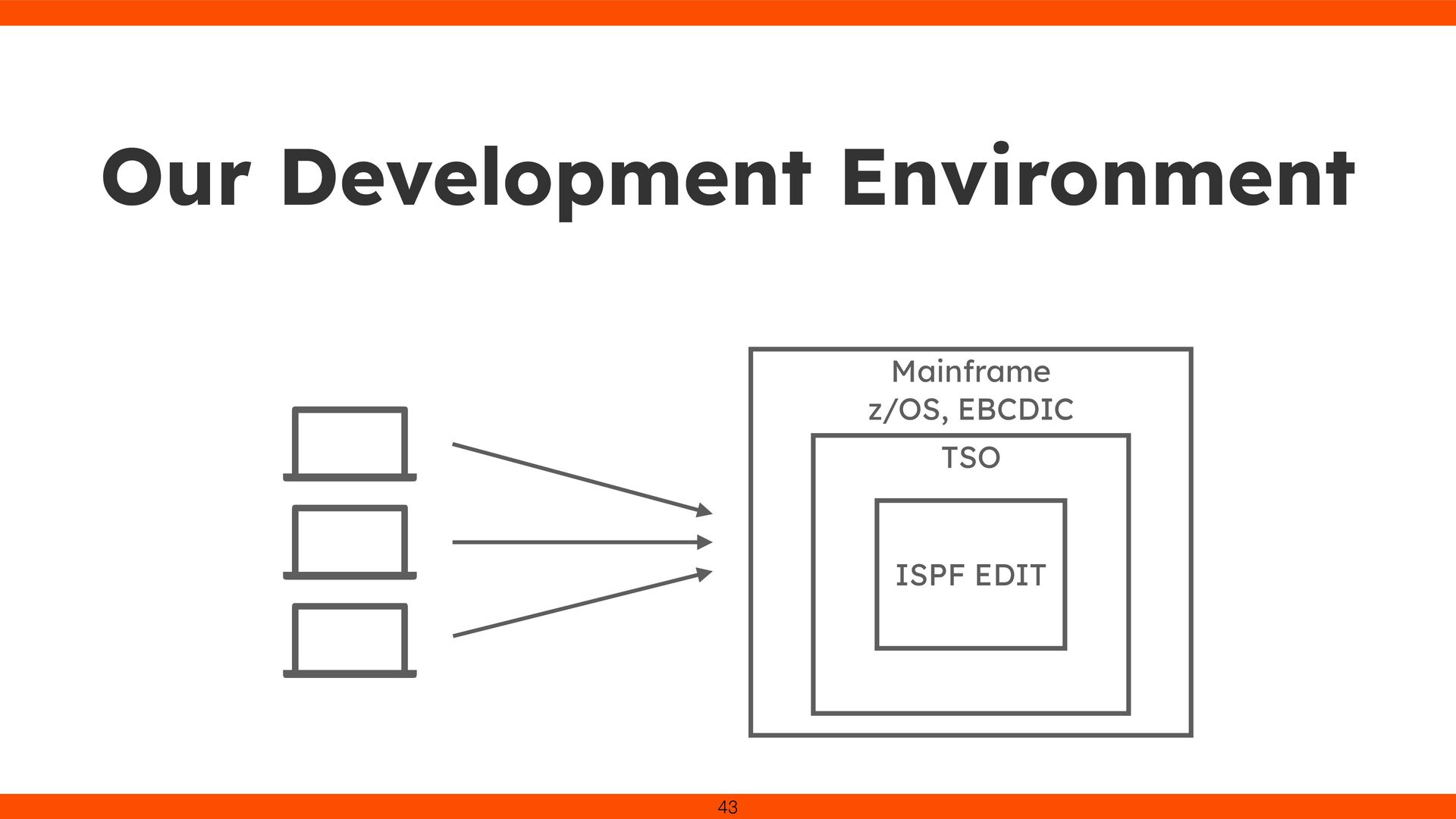
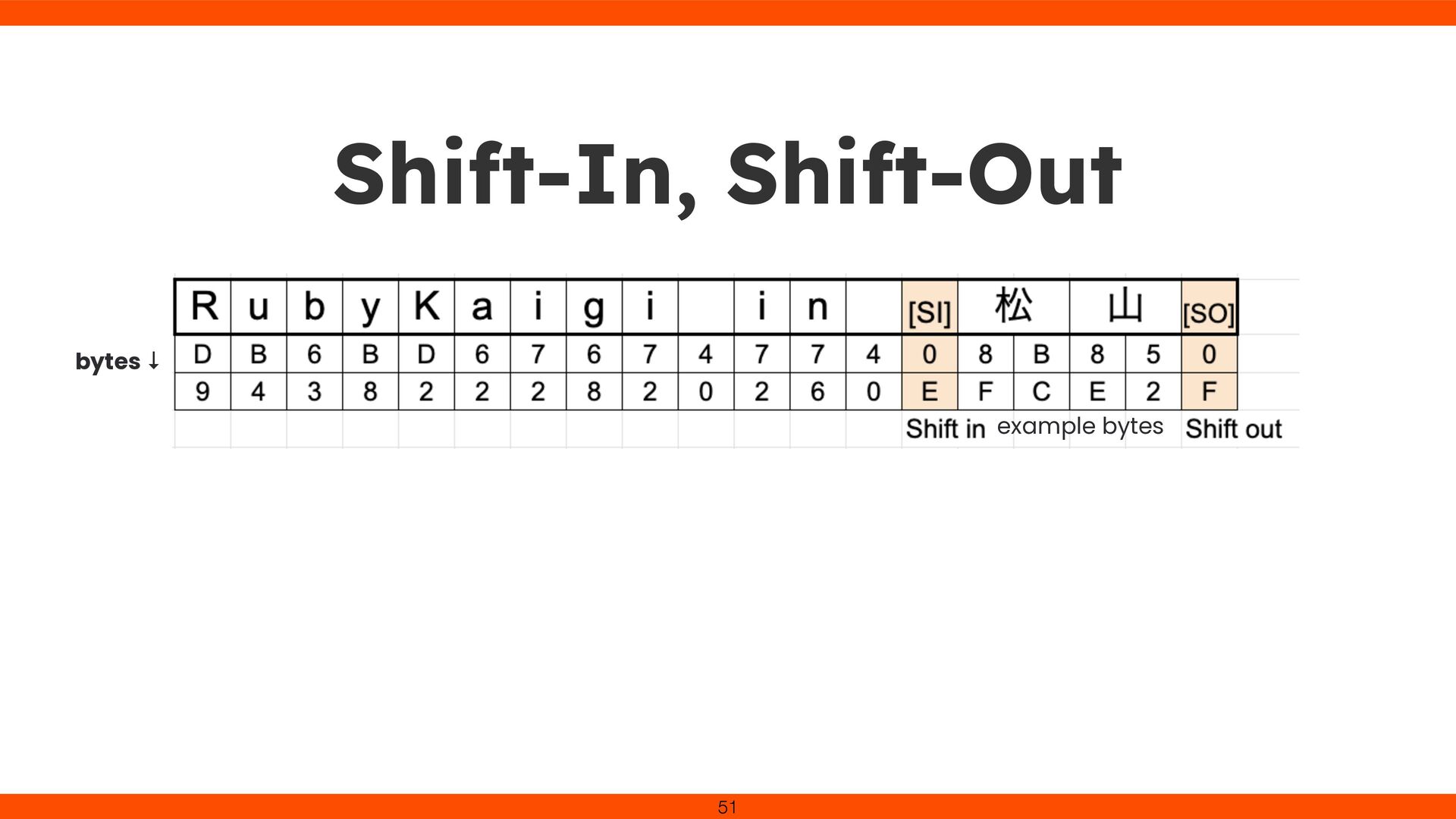
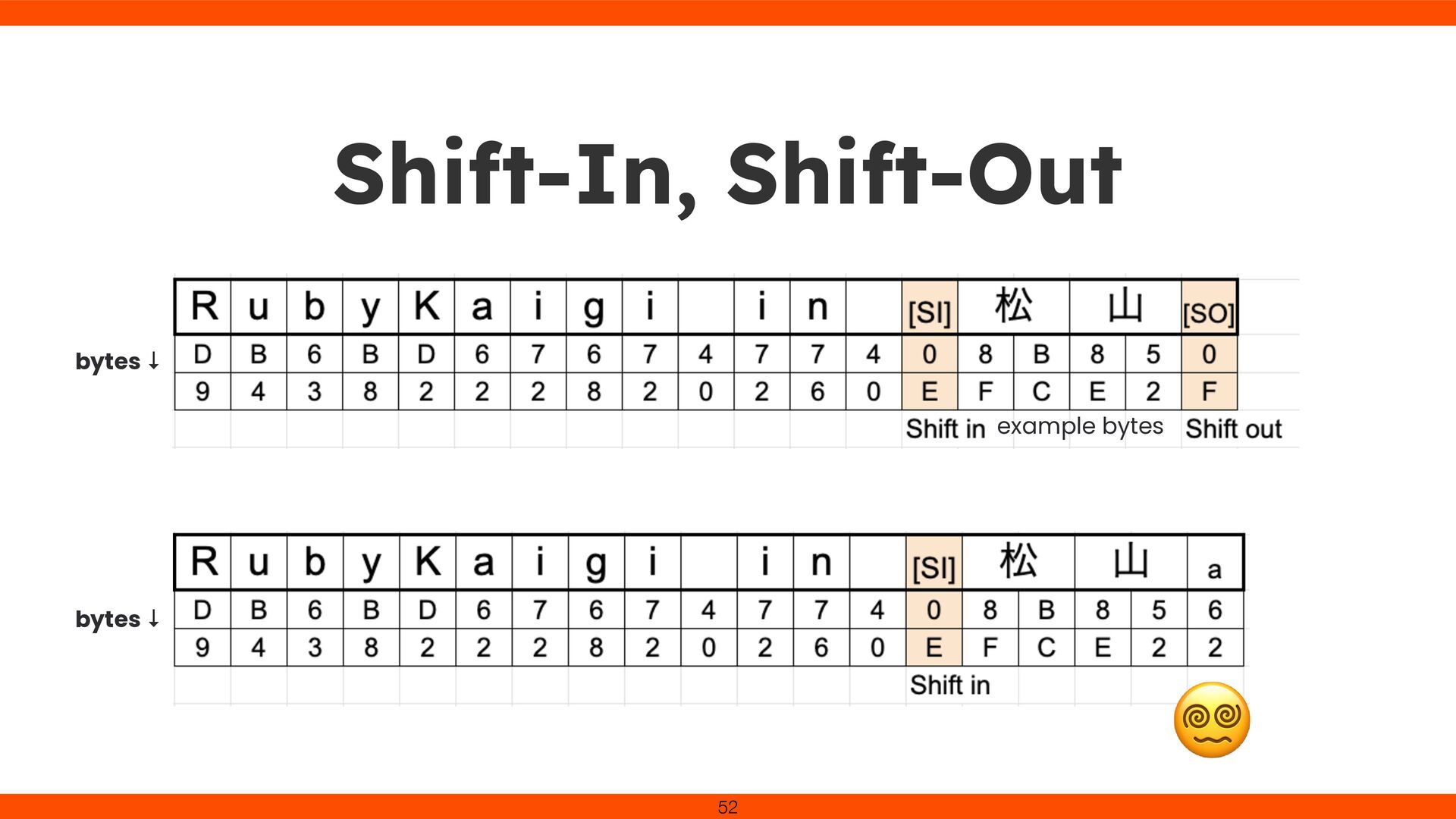
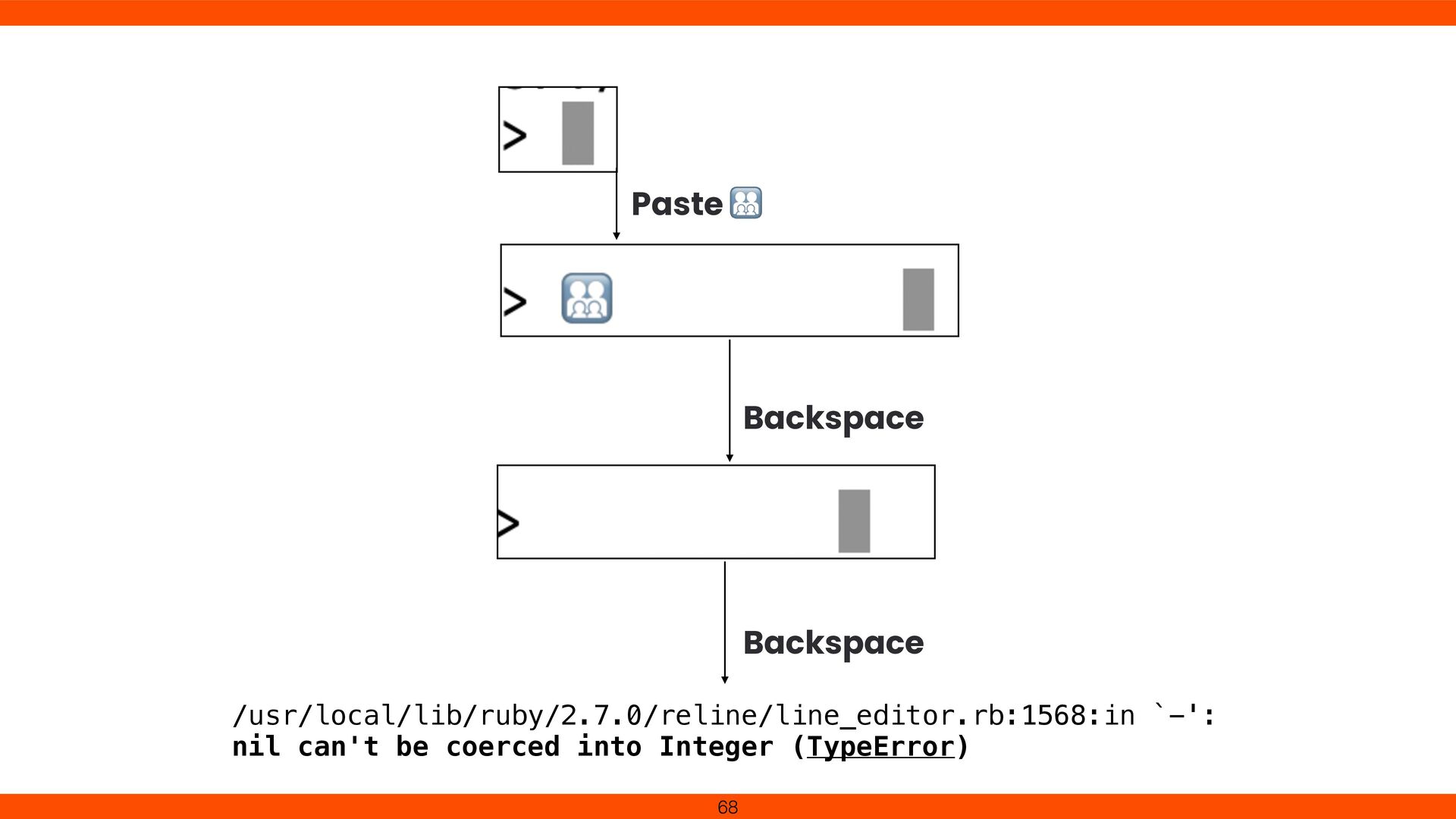
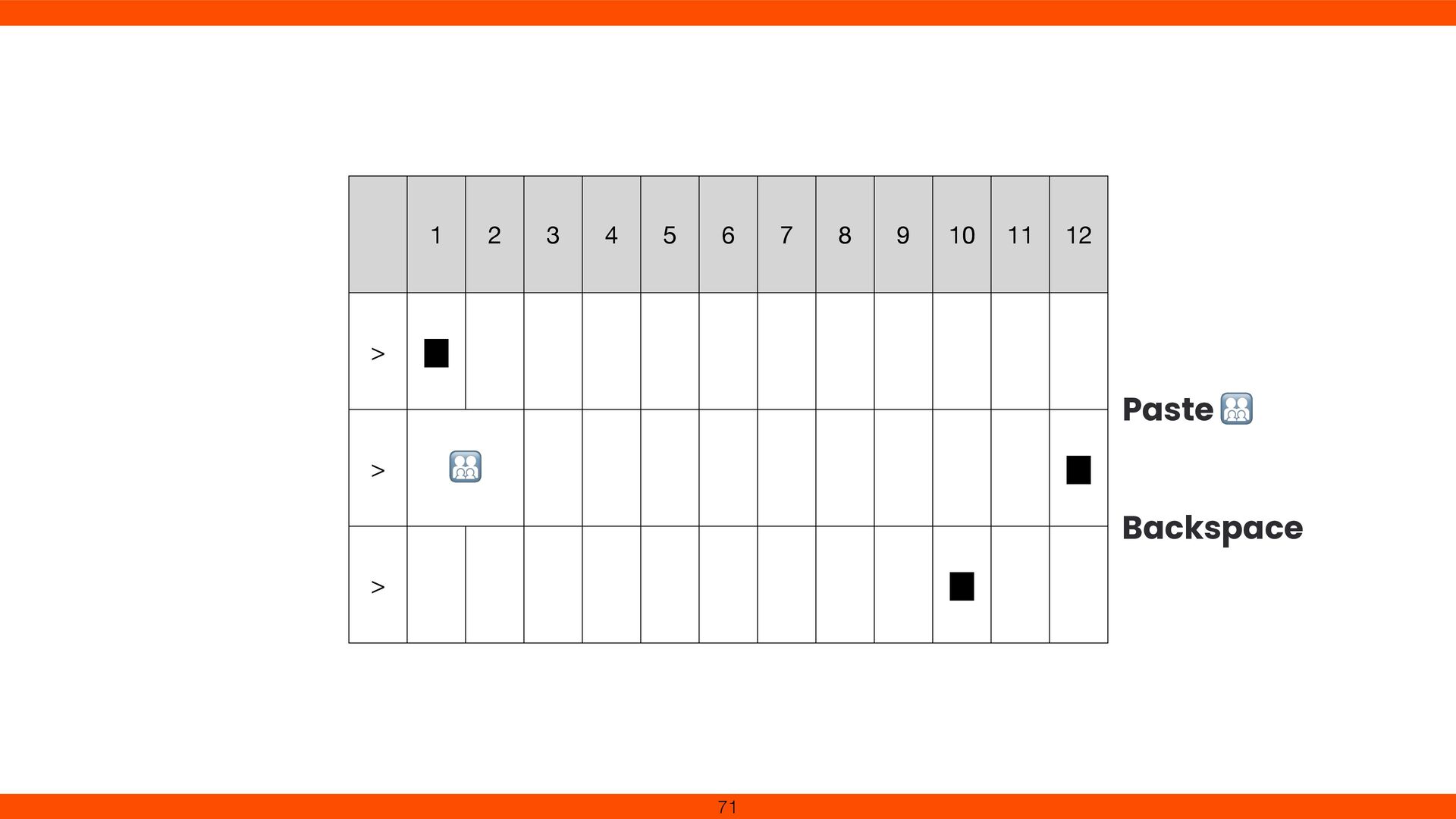
was cumbersome in our environment Constantly checked hex bytes to avoid overwriting SI/SO control chars Realized that correct character input isn’t guaranteed 53
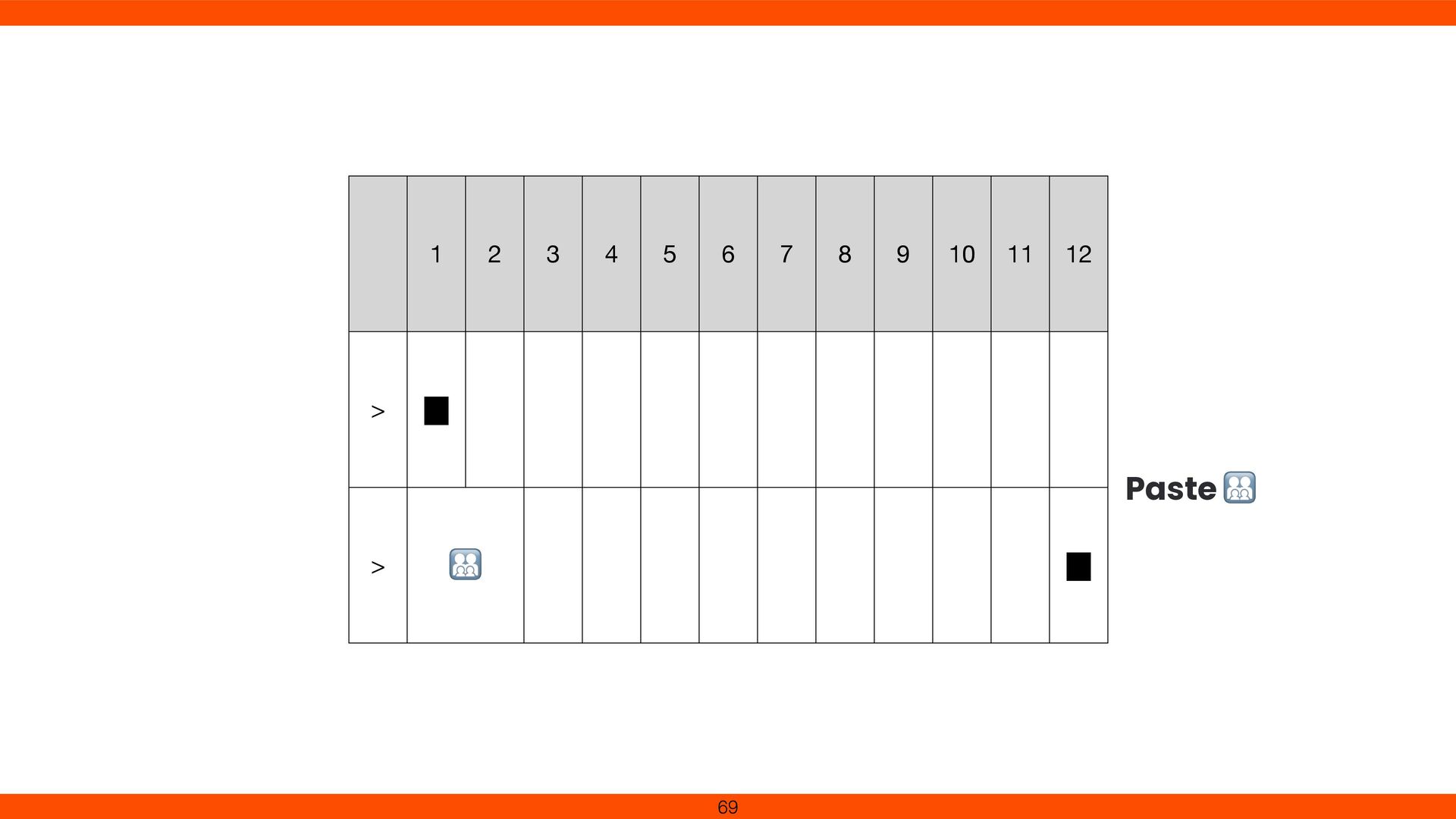
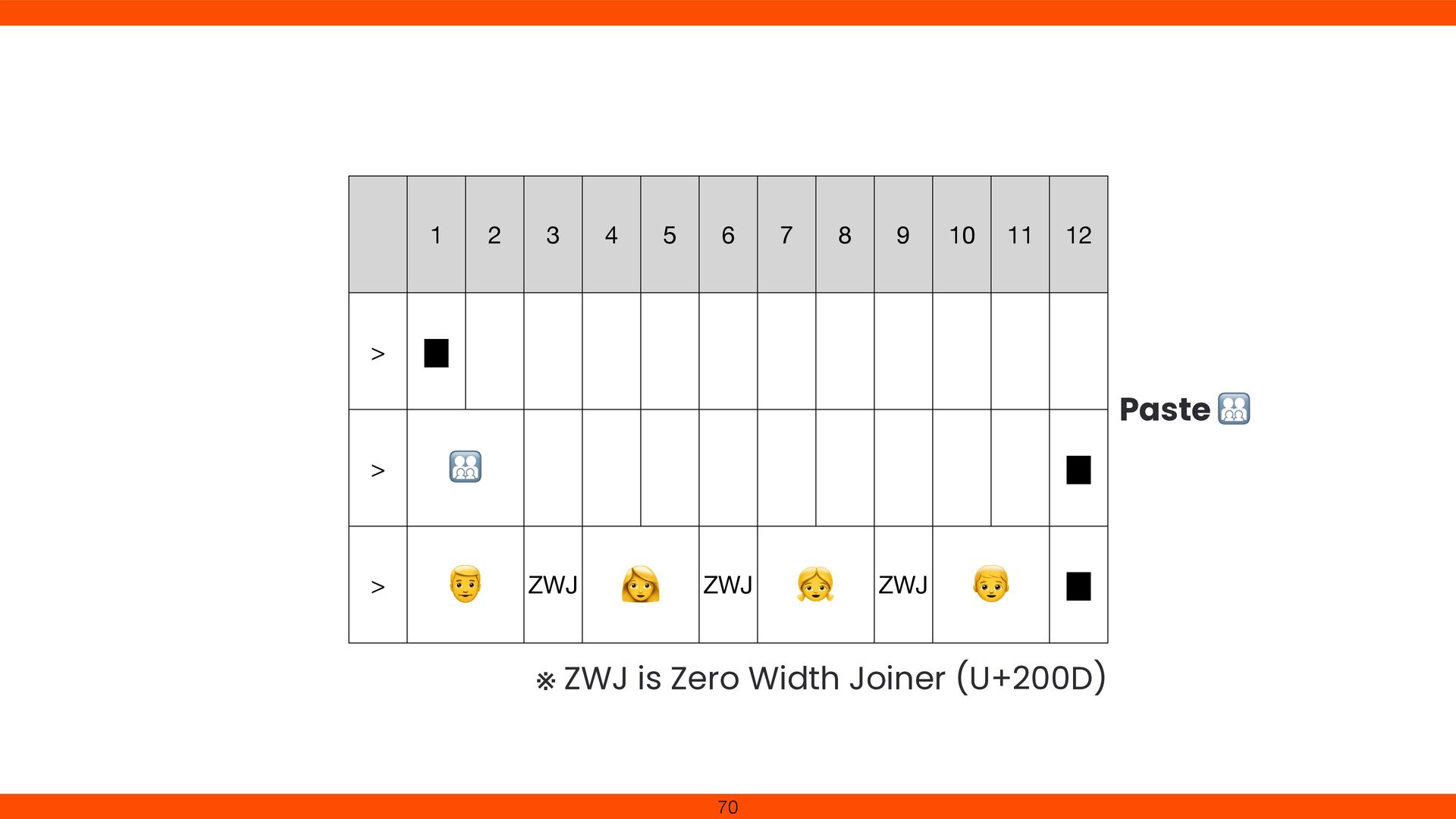
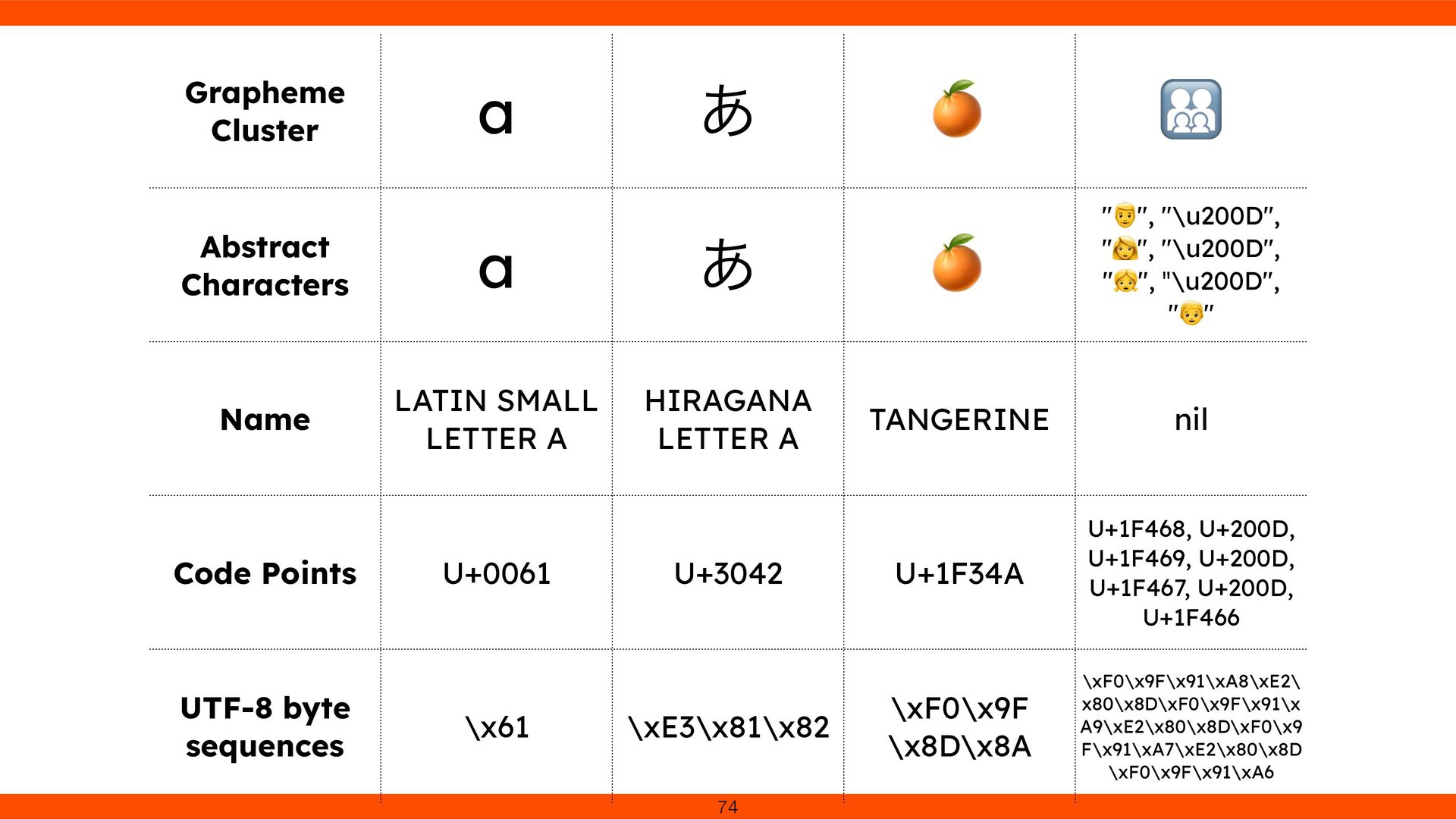
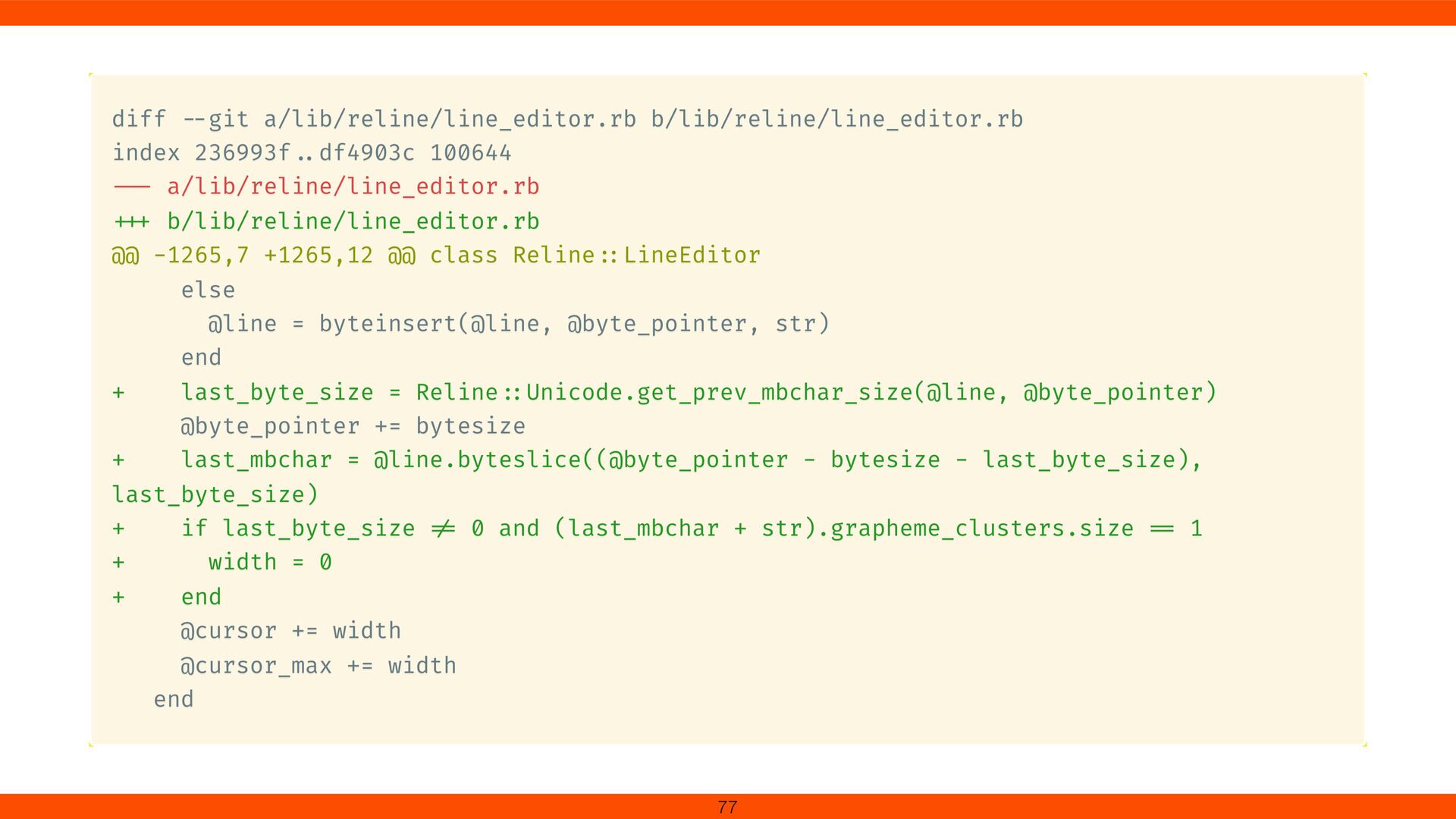
points formed a single visible character. We added Grapheme Cluster handling in Reline to respect Unicode text segmentation. This fi x ensures cursor movement and deletion align with user expectations, revealing the complexity of multi- codepoint characters. 79
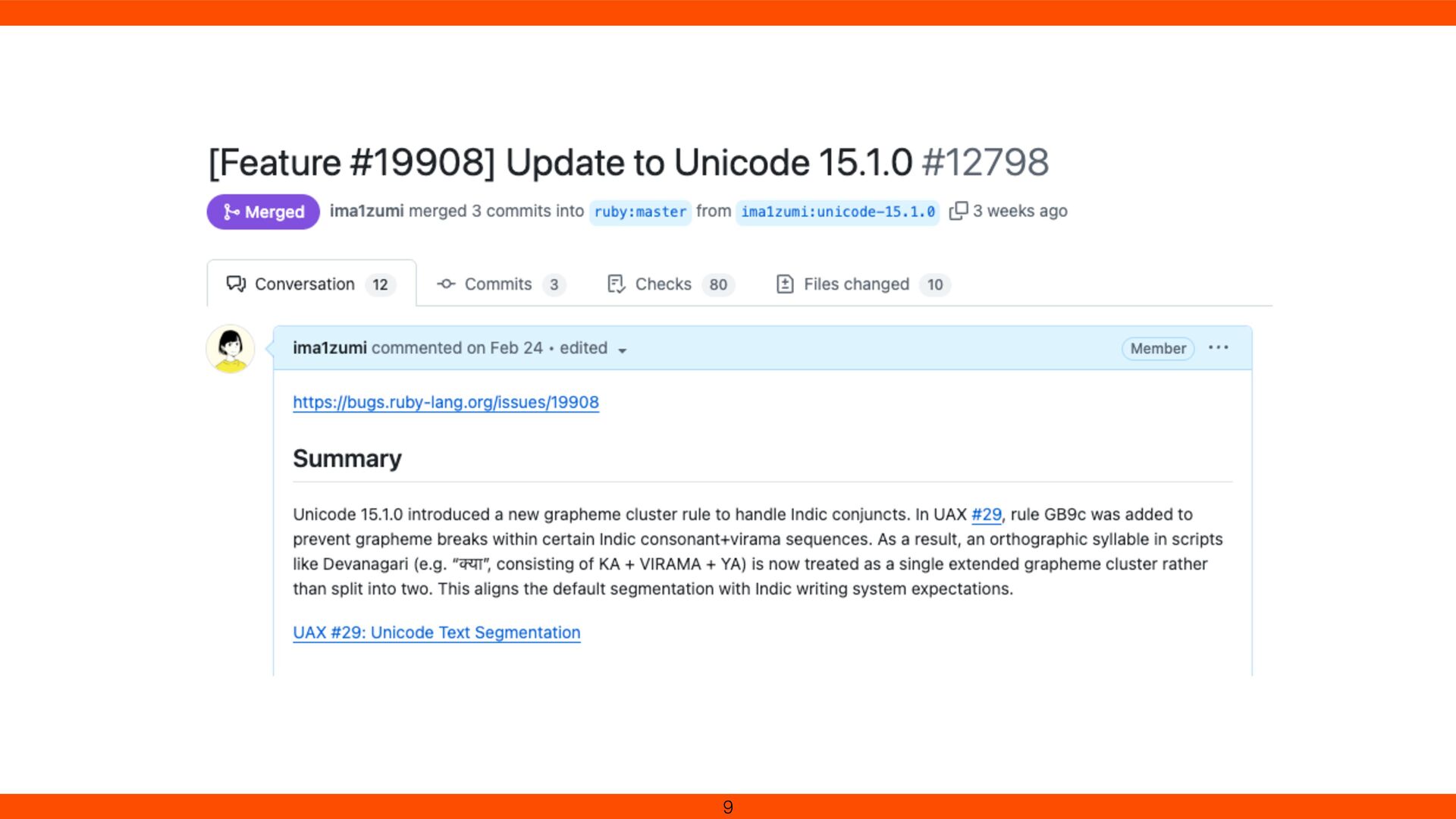
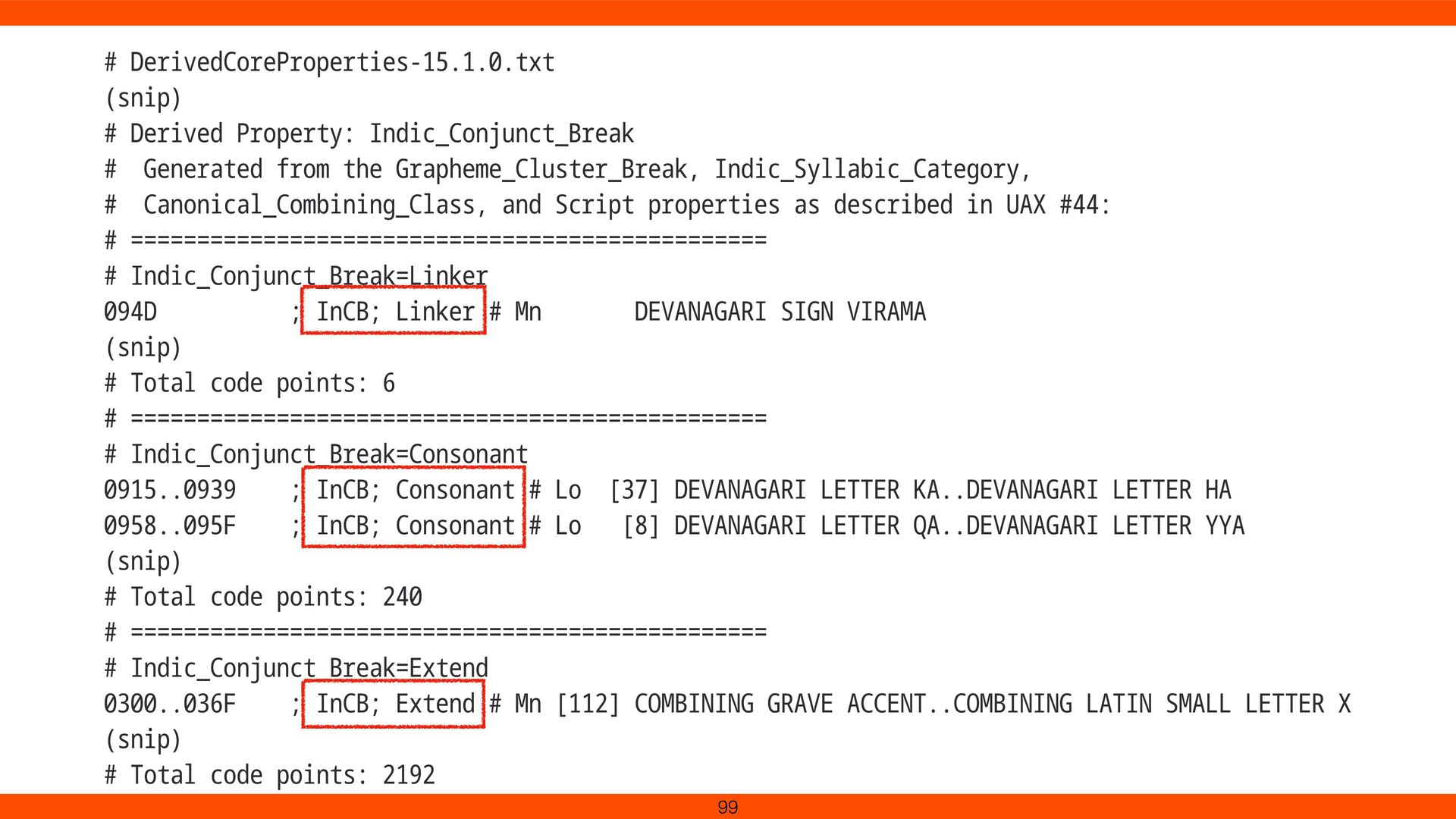
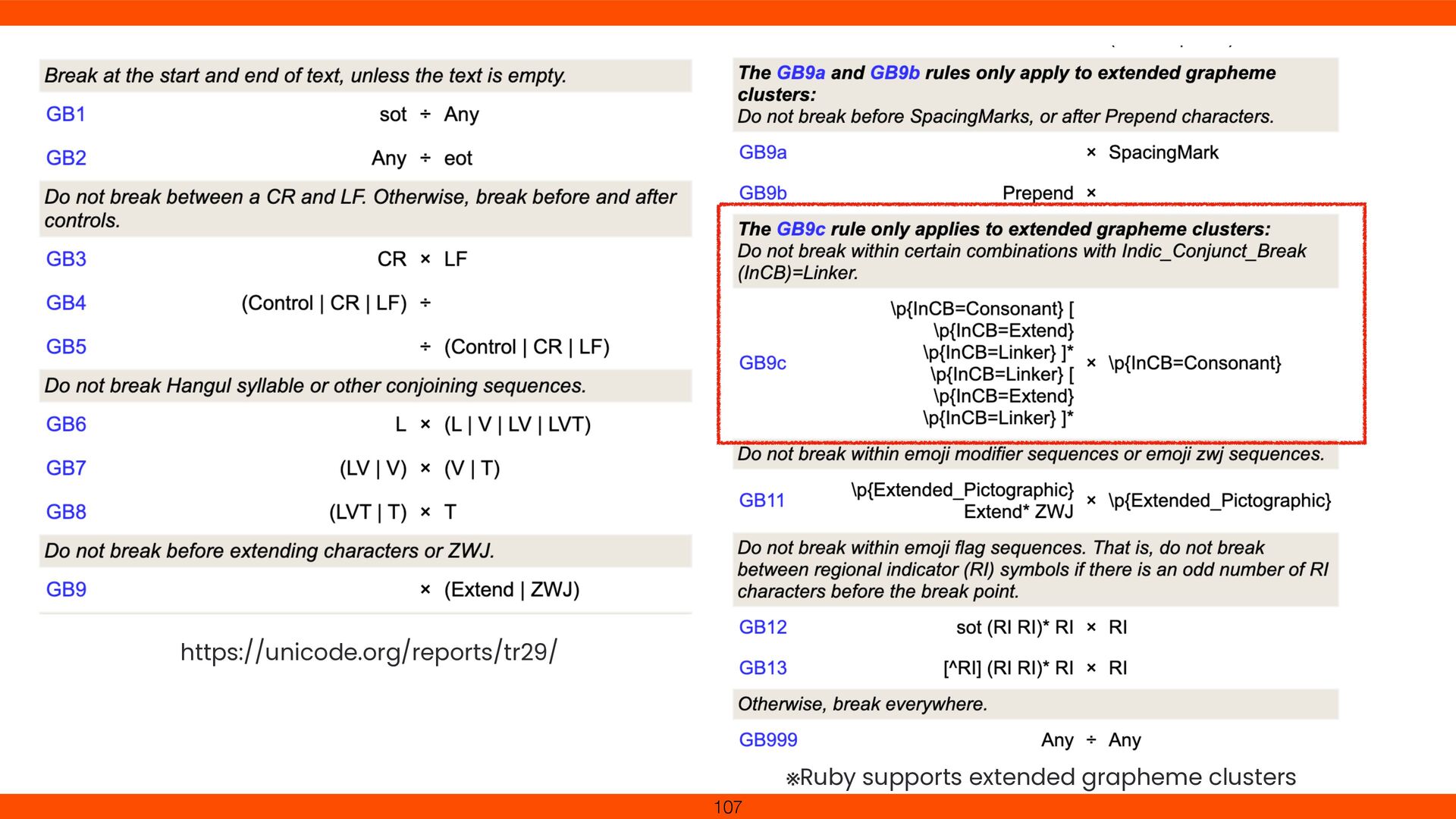
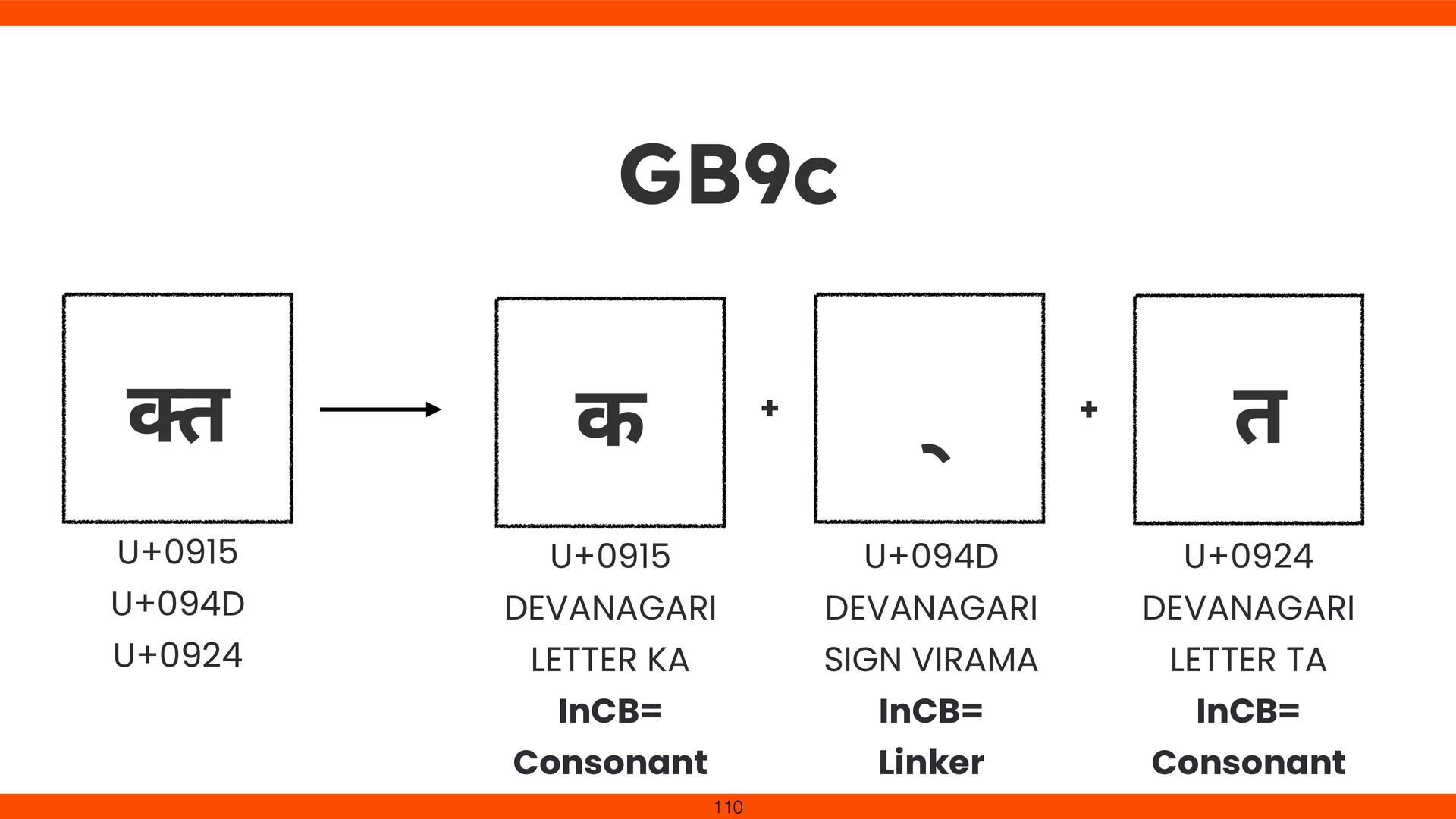
New rule: Indic_Conjunct_Break for Devanagari e.g. श क् ति (śakti) Without update, combined chars aren’t recognized as one Staying current improves international text handling 84
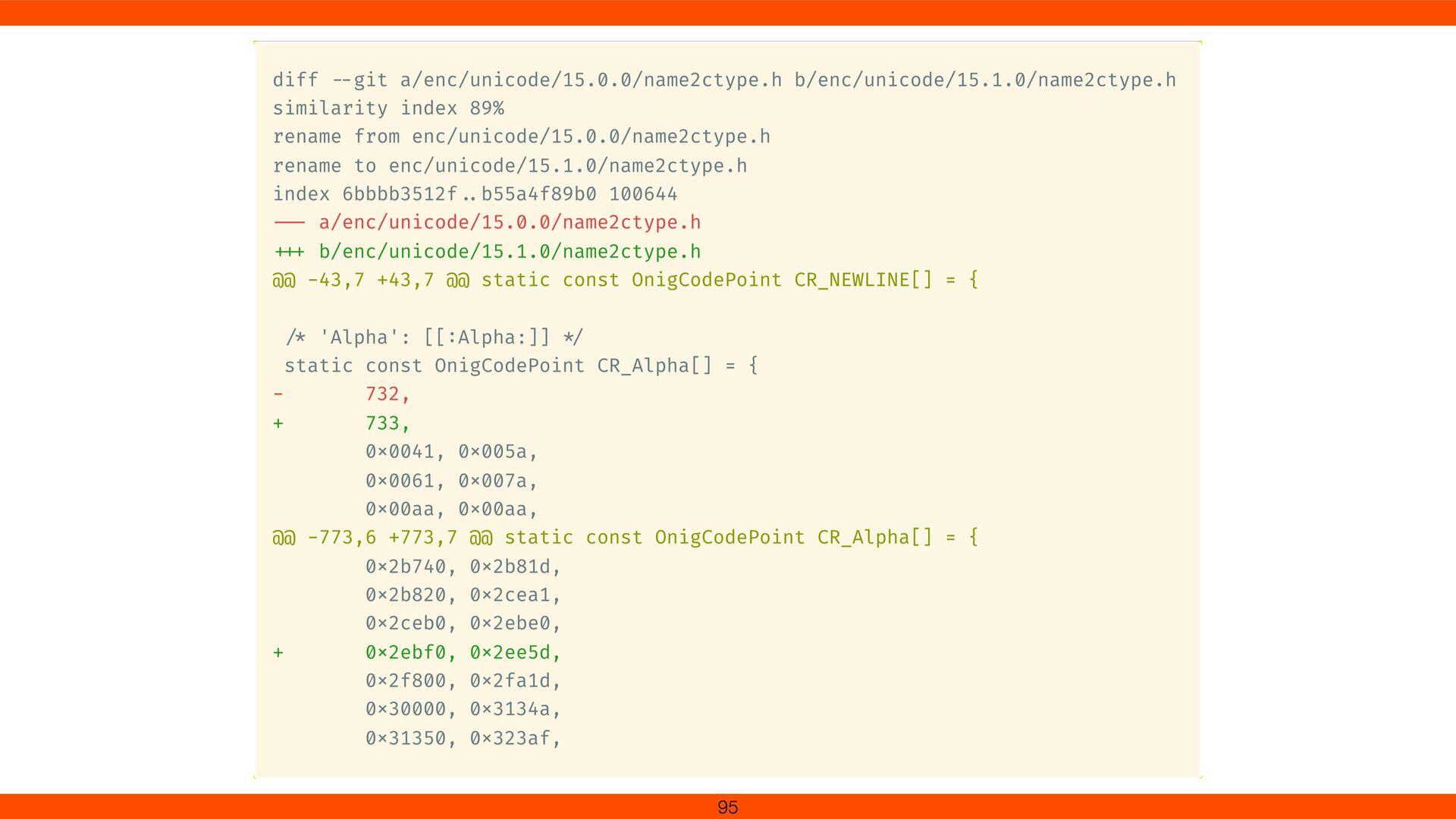
B;Lu;0;L;;;;;N;;;;0062; 0043;LATIN CAPITAL LETTER C;Lu;0;L;;;;;N;;;;0063; 0044;LATIN CAPITAL LETTER D;Lu;0;L;;;;;N;;;;0064; 0045;LATIN CAPITAL LETTER E;Lu;0;L;;;;;N;;;;0065; 0046;LATIN CAPITAL LETTER F;Lu;0;L;;;;;N;;;;0066; ... 304C;HIRAGANA LETTER GA;Lo;0;L;304B 3099;;;;N;;;;; ... 094D;DEVANAGARI SIGN VIRAMA;Mn;9;NSM;;;;;N;;;;; ... 10FFFD;<Plane 16 Private Use, Last>;Co;0;L;;;;;N;;;;; 88
2024 Unicode®, Inc. # ================================================ # Derived Property: Math # Generated from: Sm + Other_Math 002B ; Math # Sm PLUS SIGN 003C..003E ; Math # Sm [3] LESS-THAN SIGN..GREATER-THAN SIGN # ================================================ # Derived Property: Lowercase # Generated from: Ll + Other_Lowercase 0061..007A ; Lowercase # L& [26] LATIN SMALL LETTER A..LATIN SMALL LETTER Z # ================================================ # Derived Property: Uppercase # Generated from: Lu + Other_Uppercase 0041..005A ; Uppercase # L& [26] LATIN CAPITAL LETTER A..LATIN CAPITAL LETTER Z 89
from the Grapheme_Cluster_Break, Indic_Syllabic_Category, # Canonical_Combining_Class, and Script properties as described in UAX #44: # ================================================ # Indic_Conjunct_Break=Linker 094D ; InCB; Linker # Mn DEVANAGARI SIGN VIRAMA (snip) # Total code points: 6 # ================================================ # Indic_Conjunct_Break=Consonant 0915..0939 ; InCB; Consonant # Lo [37] DEVANAGARI LETTER KA..DEVANAGARI LETTER HA 0958..095F ; InCB; Consonant # Lo [8] DEVANAGARI LETTER QA..DEVANAGARI LETTER YYA (snip) # Total code points: 240 # ================================================ # Indic_Conjunct_Break=Extend 0300..036F ; InCB; Extend # Mn [112] COMBINING GRAVE ACCENT..COMBINING LATIN SMALL LETTER X (snip) # Total code points: 2192
; Math # Sm PLUS SIGN # ================================================ # Indic_Conjunct_Break=Linker 094D ; InCB; Linker # Mn DEVANAGARI SIGN VIRAMA # ================================================ # Indic_Conjunct_Break=Consonant 0915..0939 ; InCB; Consonant # Lo [37] DEVANAGARI LETTER KA..DEVANAGARI LETTER HA # ================================================ # Indic_Conjunct_Break=Extend 0300..036F ; InCB; Extend # Mn [112] COMBINING GRAVE ACCENT..COMBINING LATIN SMALL LETTER X 101
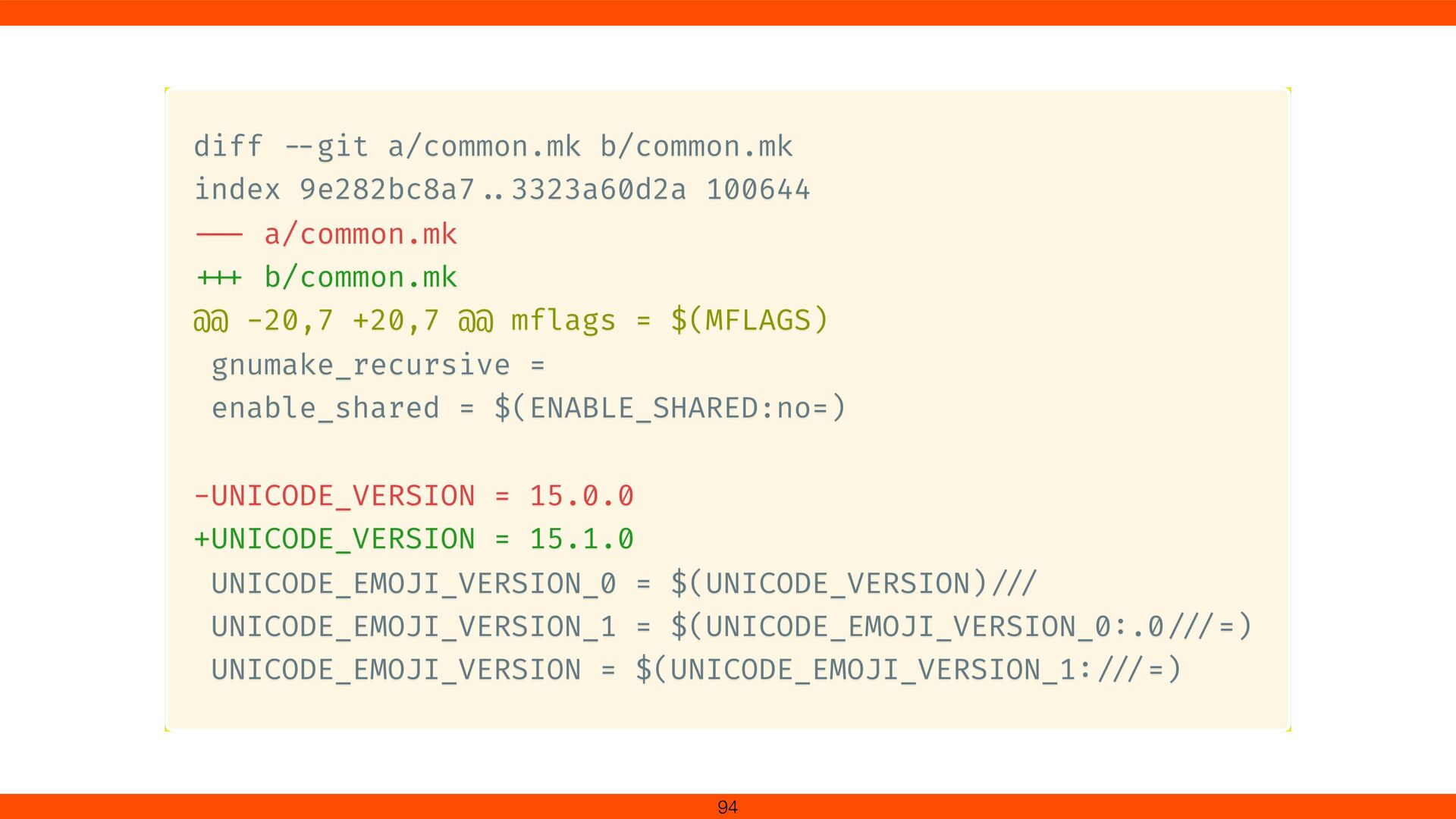
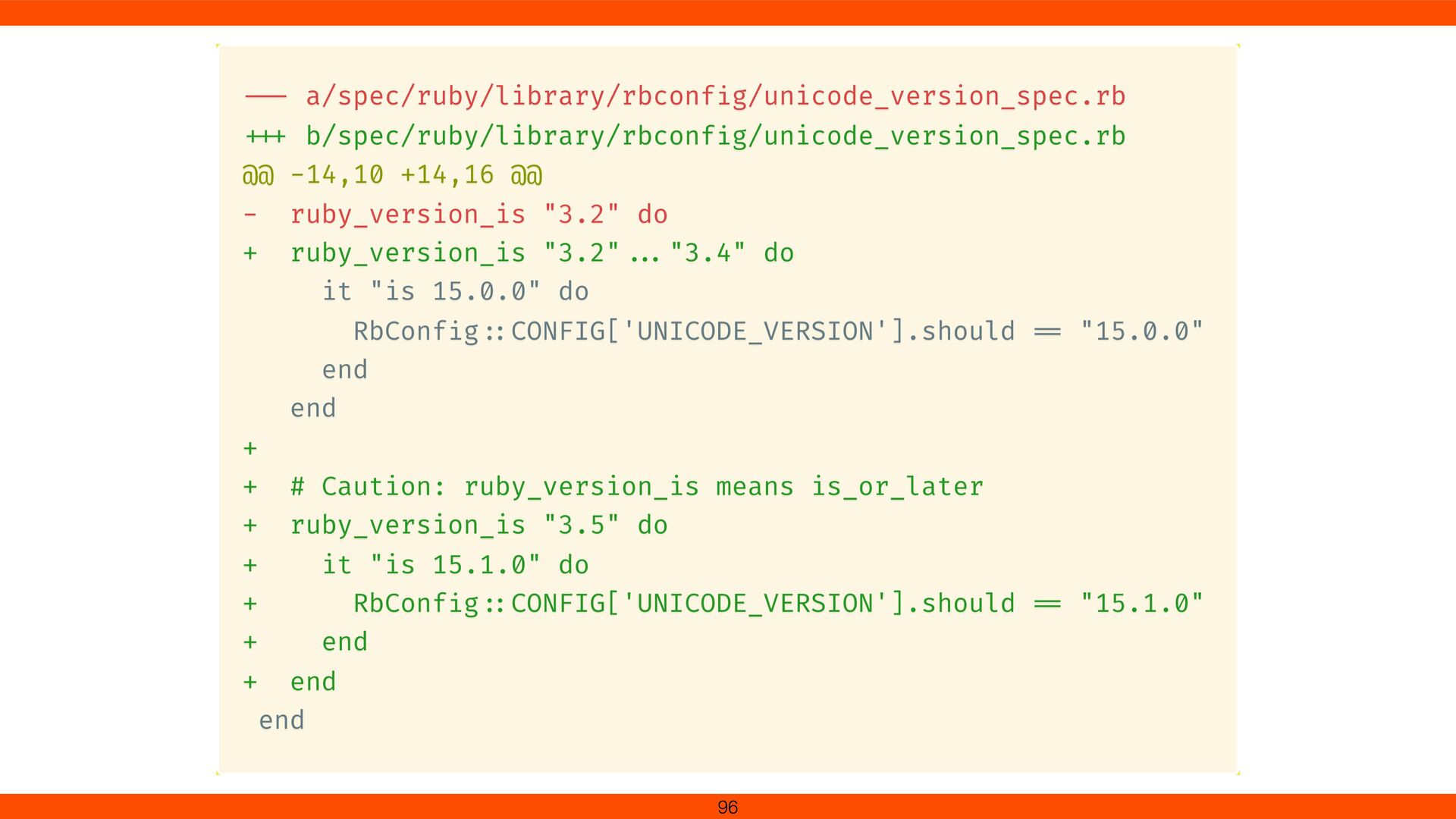
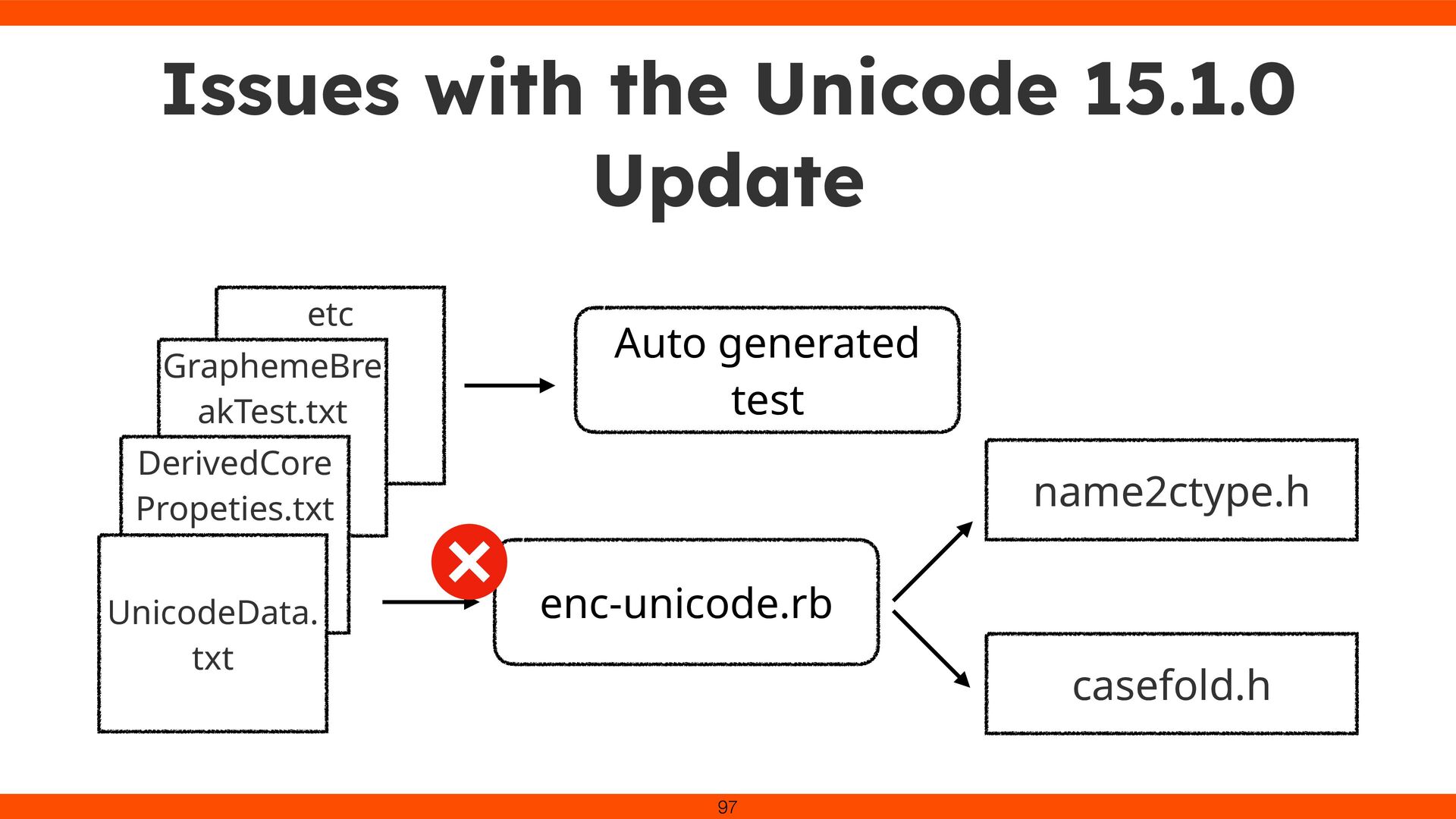
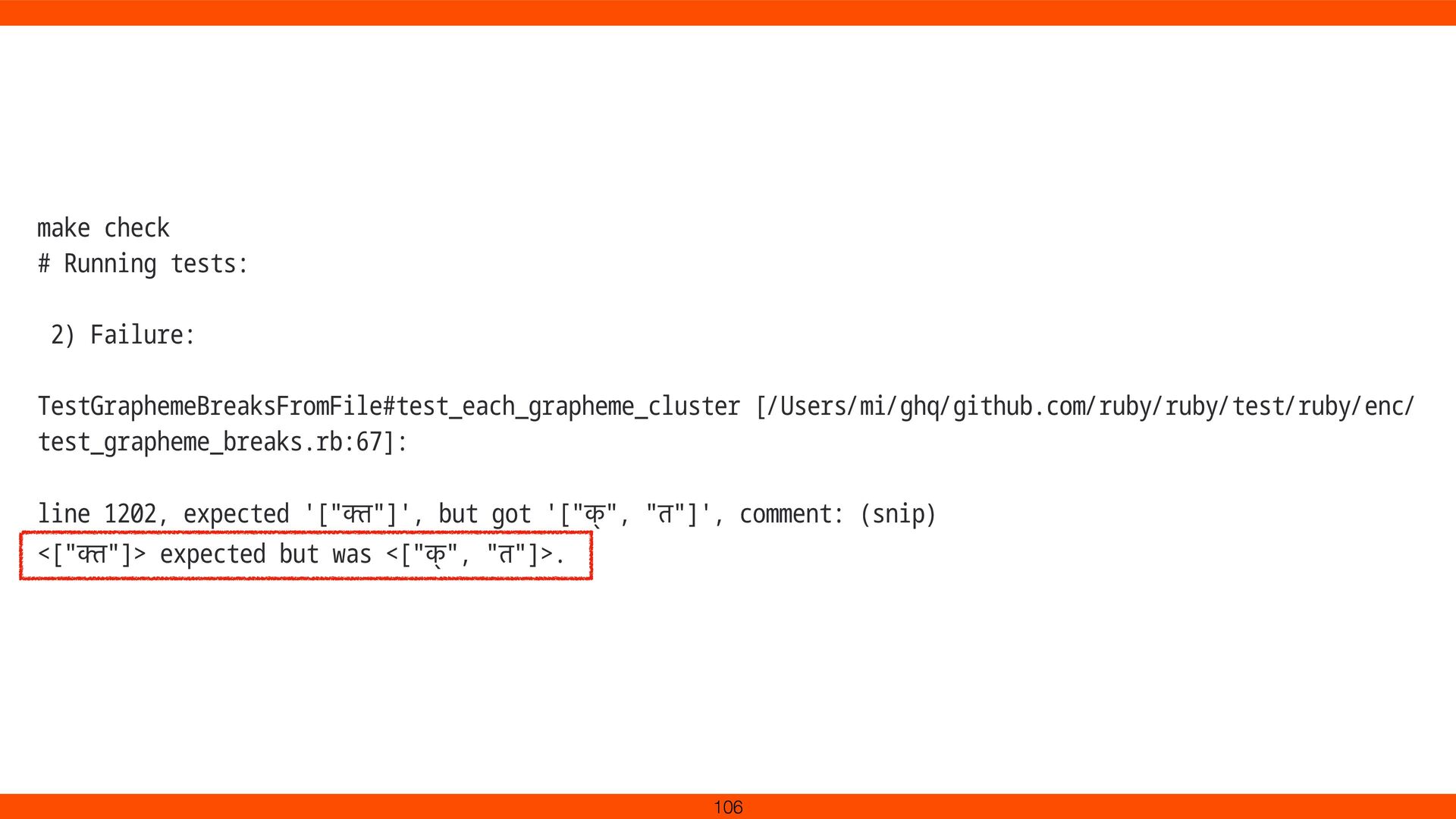
for Devanagari ligatures. Onigmo’s grapheme cluster logic (\X) was updated with new break rules (GB9c). Devanagari consonant clusters (e.g., क्त ) no longer split In Ruby 3.5, Unicode 15.1.0 is available.
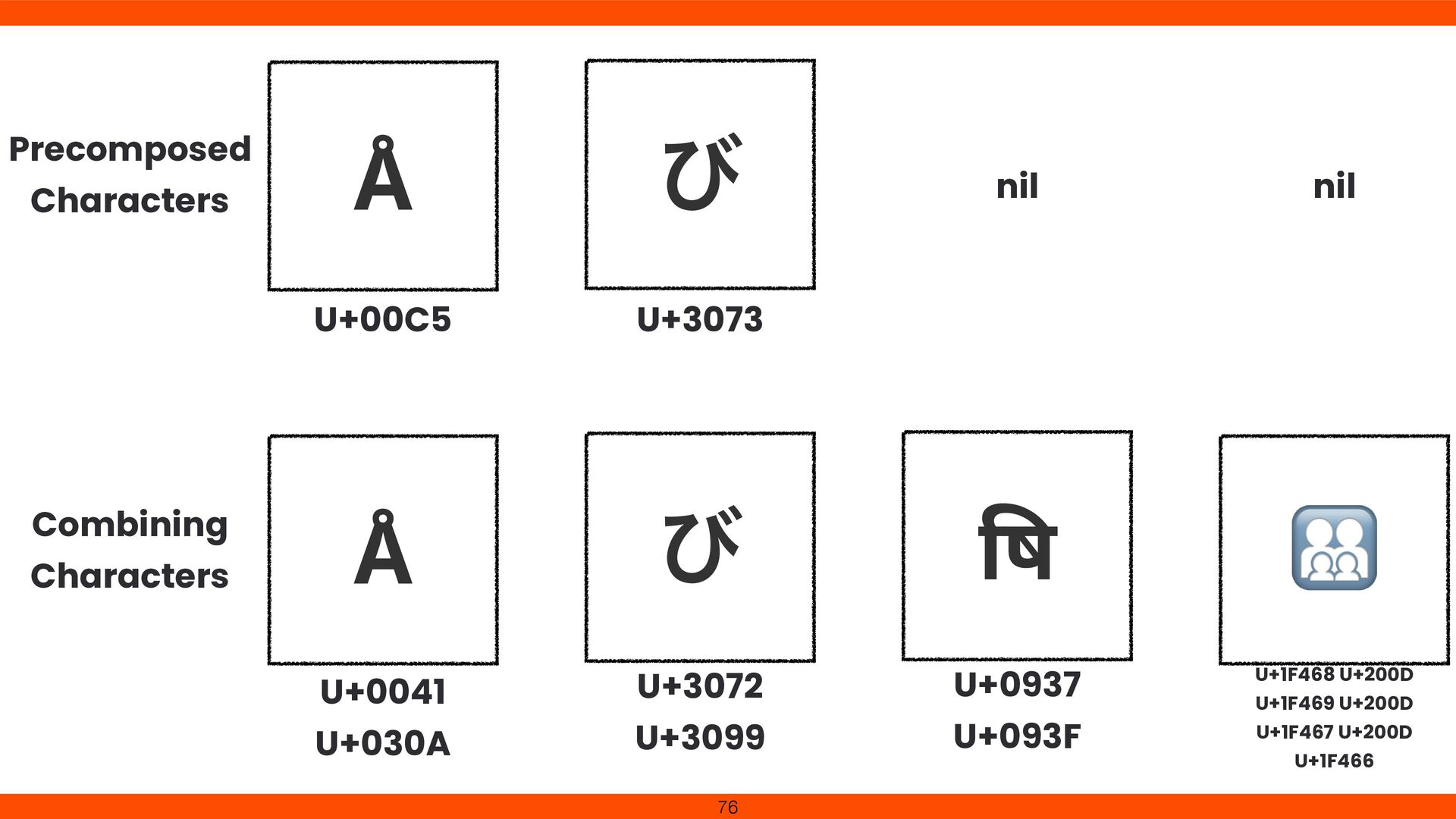
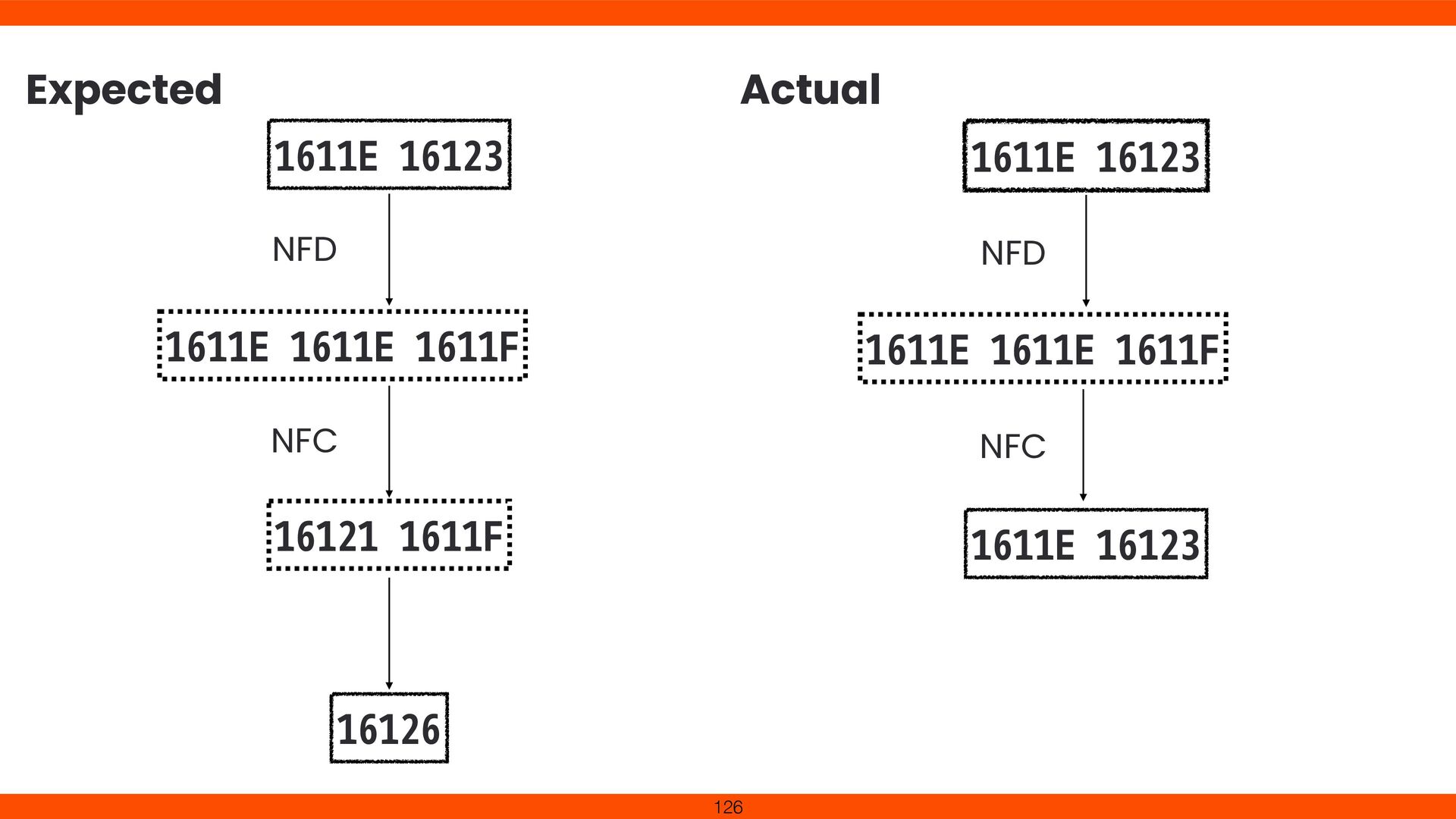
identical but di ff er internally. NFD/NFC use canonical equivalence (e.g., e + ⤆ 㲗 é). NFKD/NFKC use compatibility equivalence (e.g., ᶃ → 1). Normalization reduces search mismatches and security risks. Prevents garbled text across OS/ fi le systems and boosts data compatibility. 125
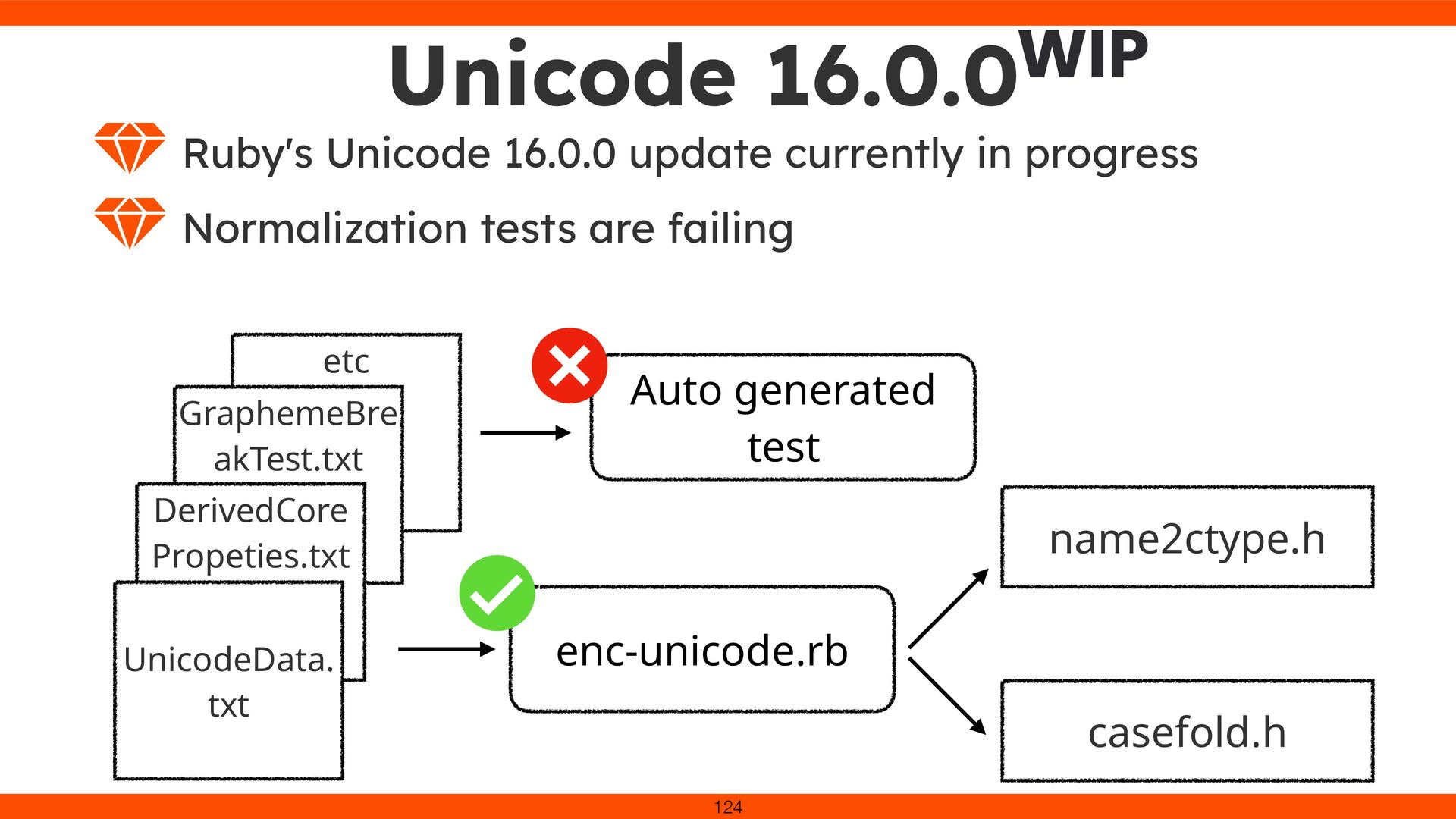
I removed optimizations temporarily. Plan to maintain performance while upgrading to Unicode 16.0.0. Considering “Quick Check” for faster validation. 128
scheduling support. Special thanks to fujimura-san, @ko1, and @mame for repeatedly reviewing my work. My husband Takuya’s support made this presentation possible. I’m also grateful to everyone who reviewed my PRs and provided valuable advice. 130
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![109 GB9c \p{InCB=Consonant} [ \p{InCB=Extend} \p{InCB=Linker} ]* \p{InCB=Linker} [ \p{InCB=Extend}](https://files.speakerdeck.com/presentations/0a7e33e668e7481ab760985a6b03de0e/slide_108.jpg){kind=link}
{kind=link}
![111 क्त \p{InCB=Consonant} [ \p{InCB=Extend} \p{InCB=Linker} ]* \p{InCB=Linker} [ \p{InCB=Extend}](https://files.speakerdeck.com/presentations/0a7e33e668e7481ab760985a6b03de0e/slide_110.jpg){kind=link}
![112 क्त \p{InCB=Consonant} [ \p{InCB=Extend} \p{InCB=Linker} ]* \p{InCB=Linker} [ \p{InCB=Extend}](https://files.speakerdeck.com/presentations/0a7e33e668e7481ab760985a6b03de0e/slide_111.jpg){kind=link}
![113 क्त \p{InCB=Consonant} [ \p{InCB=Extend} \p{InCB=Linker} ]* \p{InCB=Linker} [ \p{InCB=Extend}](https://files.speakerdeck.com/presentations/0a7e33e668e7481ab760985a6b03de0e/slide_112.jpg){kind=link}
![114 क्त \p{InCB=Consonant} [ \p{InCB=Extend} \p{InCB=Linker} ]* \p{InCB=Linker} [ \p{InCB=Extend}](https://files.speakerdeck.com/presentations/0a7e33e668e7481ab760985a6b03de0e/slide_113.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
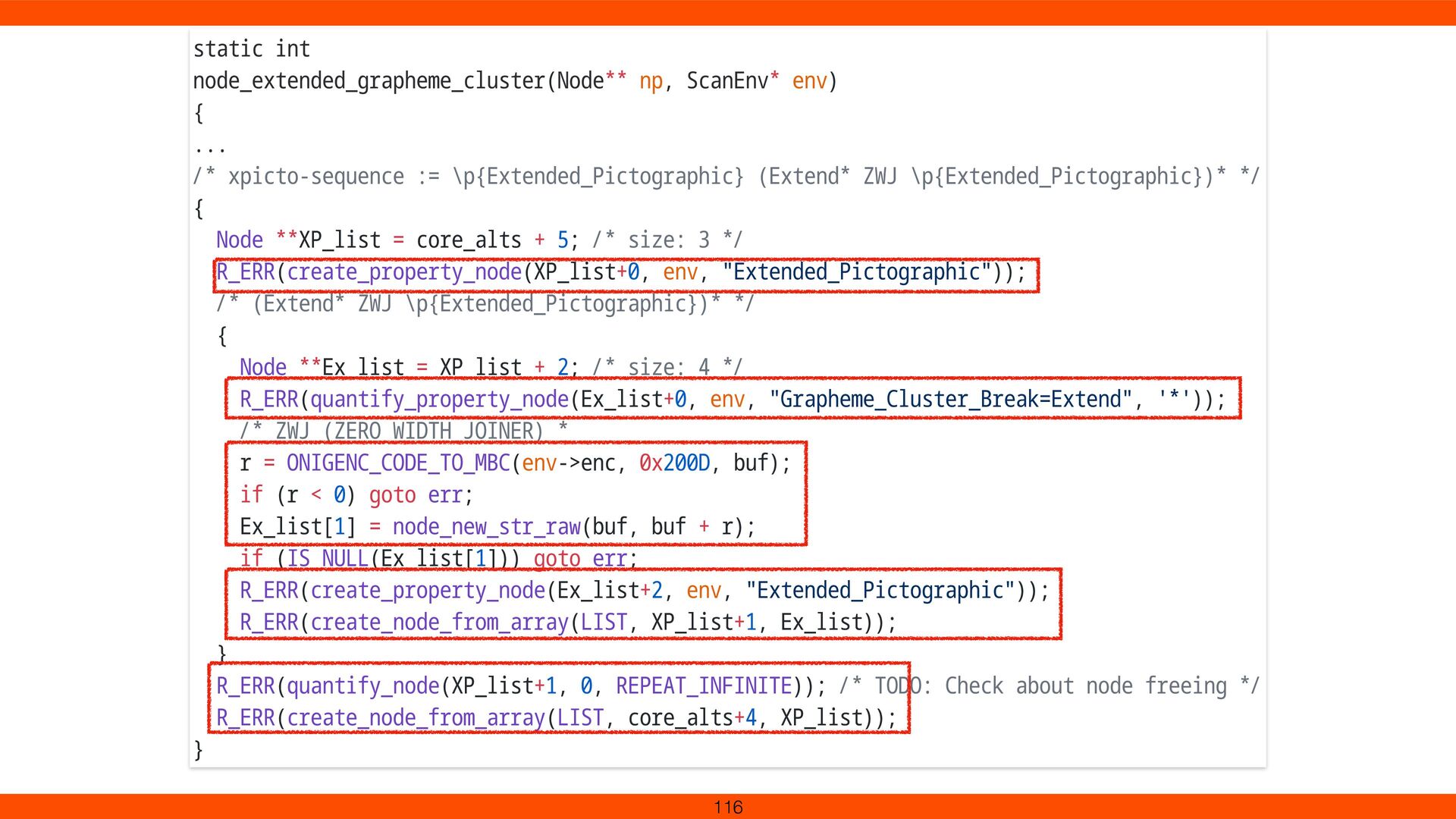
![Grapheme Clusters Implementation Create Nodes for \p{InCB=Consonant} [\p{InCB=Extend} \p{InCB=Linker}]* \p{InCB=Linker}](https://files.speakerdeck.com/presentations/0a7e33e668e7481ab760985a6b03de0e/slide_117.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}