Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
LLM-as-a-Judgeの具体的な取り組み
Search
AITC - DENTSU SOKEN
January 20, 2026
1.1k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
LLM-as-a-Judgeの具体的な取り組み
AITCコラムに掲載した資料です。
LLM-as-a-Judgeの具体的な取り組みについて、論文調査を行いまとめた概要スライドを掲載しています。
AITC - DENTSU SOKEN
January 20, 2026
More Decks by AITC - DENTSU SOKEN
See All by AITC - DENTSU SOKEN
AIエージェントを現場で実践する際の落とし穴.pdf
isidaitc
1
130
AIエージェントの評価ポイント紹介
isidaitc
0
140
長期・短期メモリを活用したエージェントの個別最適化
isidaitc
0
850
電通総研の生成AI・エージェントの取り組み エンジニアリング業務向けAI活用事例紹介
isidaitc
1
1.8k
IR Reading 2025春 論文紹介「Do Images Clarify? A Study on the Effect of Images on Clarifying Questions in Conversational Search」
isidaitc
0
94
AIアプリケーション開発でAzure AI Searchを使いこなすためには
isidaitc
2
2.2k
IR Reading 2024秋 論文紹介「MeMemo On-device Retrieval Augmentation for Private and Personalized Text Generation」
isidaitc
0
1.7k
電通総研のLLMエージェントの技術開発や製造のAI活用事例紹介
isidaitc
3
5.3k
生成AIエージェントの現状を俯瞰する
isidaitc
0
11k
Featured
See All Featured
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.4k
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
550
RailsConf 2023
tenderlove
30
1.5k
The Spectacular Lies of Maps
axbom
PRO
1
850
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
260
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.7k
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
Into the Great Unknown - MozCon
thekraken
41
2.6k
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.8k
Transcript
LLM-as-a-Judgeを活用した具体的な手法
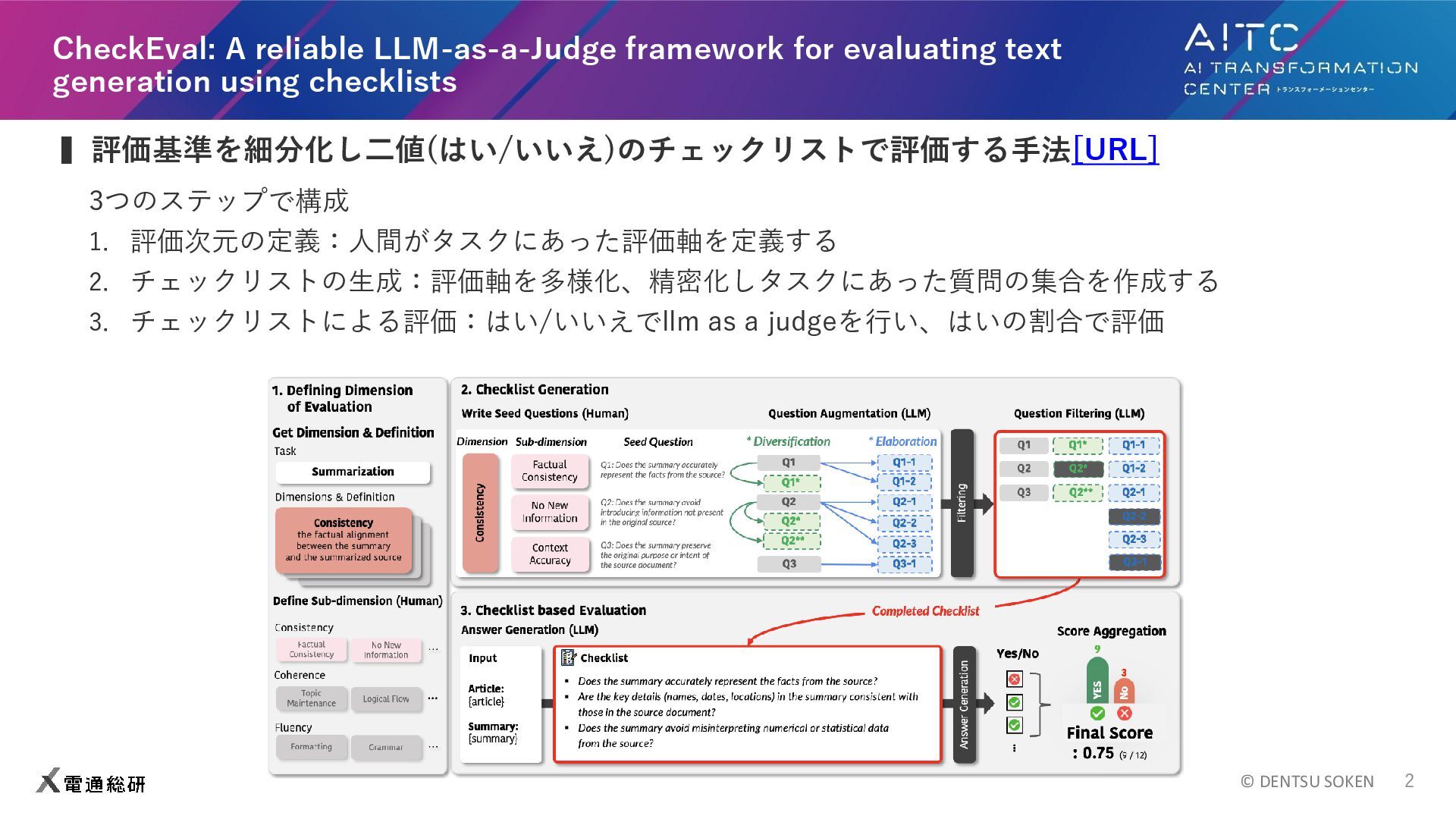
© DENTSU SOKEN 2 CheckEval: A reliable LLM-as-a-Judge framework for
evaluating text generation using checklists ▍評価基準を細分化し二値(はい/いいえ)のチェックリストで評価する手法[URL] 3つのステップで構成 1. 評価次元の定義:人間がタスクにあった評価軸を定義する 2. チェックリストの生成:評価軸を多様化、精密化しタスクにあった質問の集合を作成する 3. チェックリストによる評価:はい/いいえでllm as a judgeを行い、はいの割合で評価
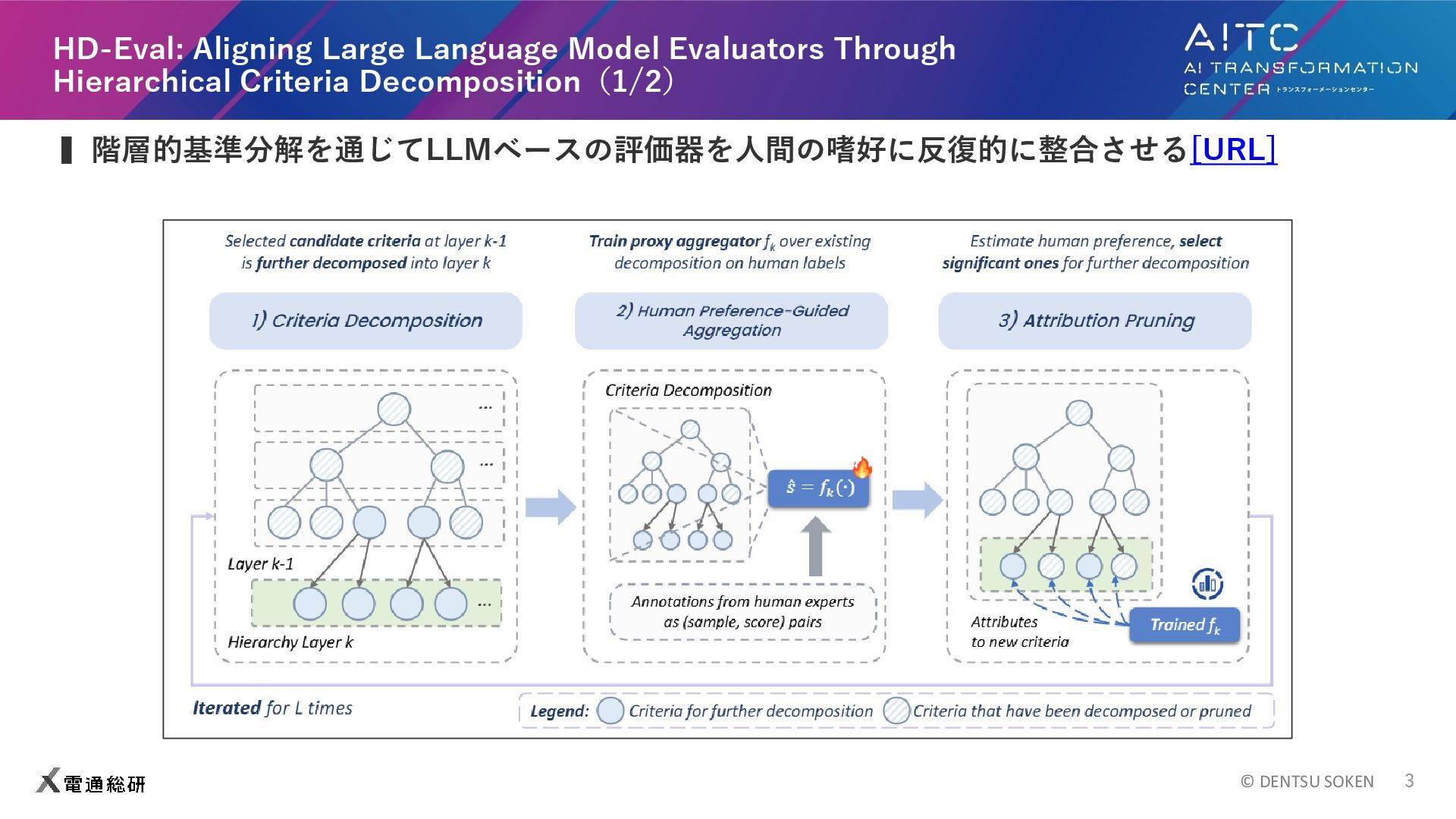
© DENTSU SOKEN 3 HD-Eval: Aligning Large Language Model Evaluators
Through Hierarchical Criteria Decomposition(1/2) ▍階層的基準分解を通じてLLMベースの評価器を人間の嗜好に反復的に整合させる[URL]
© DENTSU SOKEN 4 HD-Eval: Aligning Large Language Model Evaluators
Through Hierarchical Criteria Decomposition(2/2) ▍階層的基準分解を通じてLLMベースの評価器を人間の嗜好に反復的に整合させる[URL] ⚫ 3つのステップで構成 1. Criteria Decomposition ➢ 評価基準を木構造的に分解 親基準:一貫性 下位基準:分順序、談話構造、話題フォーカス etc ➢ 分解された下位基準はLLMによってスコアリングされる 2. Human Preference-Guided Aggregation ➢ 人間があらかじめ評価したスコアを模倣できるように、統合器(線形回帰・RF・浅いMLPなど)を用意し学習する。 ➢ 統合器は下位基準のLLMによるスコアを入力として、最終的な親基準スコアを計算する ➢ この計算した親基準スコアが人間と近くなるように、投合器を学習する 3. Attribution Pruning ➢ 下位基準から、最終スコアに効いているもののみを選び、重要度の低い基準は打ち切る
© DENTSU SOKEN 5 Limitations of the LLM-as-a-Judge Approach for
Evaluating LLM Outputs in Expert Knowledge Tasks ▍LLM-as-a-Judgeが専門家(Subject Matter Expert)の判断とどの程度一致するかを検証[URL] ⚫ サーベイ論文でもあった一致率について、専門領域ではどうなのかを検証した論文 ⚫ 栄養学とメンタルヘルス領域で、疾病管理や食事管理、心理的支援など専門的な領域を検証 ⚫ 検証の結果、LLM-as-a-JudgeとSMEの評価には乖離があった ⚫ 専門家として振舞うプロンプトに変更しても微妙に改善される程度で大きく乖離は縮まらない ⚫ 結論として、LLMはドメインエキスパートの判断を完全には代替できない ⚫ 論文ではSME-in-the-Loopのような人間も組み込んだ仕組みが重要と言及
© DENTSU SOKEN 6 Prompt Optimization with Human Feedback(POHF) ▍人間のフィードバックによるプロンプト最適化手法[URL]
⚫ LLMの振る舞いを決めるプロンプトの評価を数値スコアで行う場合、スコアリング自体が難しいことや スコア自体の妥当性を評価することが出来ないという課題がある ⚫ 本研究ではAutomation-POHFを提案し、人間にどちらの出力が好ましいかを提示、獲得する ⚫ 手法は人間が選択した好みの情報(バイナリ)とプロンプト情報からNNを学習し、各プロンプトをスコアリングす ることが可能 ⚫ Automation-POHFではLLMがプロンプトをパターン生成し、NNを通じて最も高い効用のあるプロンプトを決定
© DENTSU SOKEN 7 AutoLibra: AI Agent Metric Induction from
Open-Ended Human Feedback ▍人間からのフィードバックを解釈可能な指標に変換し、エージェントの行動を最適化[URL] ⚫ 既存のAIエージェントの評価はタスクの成功率など荒い指標かつ、評価の構築自体にドメインエキスパートの労力が 必要な課題がある ⚫ AutoLibraでは人間からのフィードバックを指標として分解を行い、エージェントの良かった行動と悪かった行動を 分類 ・エージェントの行動に対して人間がフィードバック ・人間のフィードバックをLLMによって分析し、 どのエージェントの行動が良い/悪い行動か、指標を構築 ・エージェントは新しいタスクを実行した際に構築した指標で行動を評価される ・人間はスコアを基に行動を修正するようなプロンプトの改修を行う
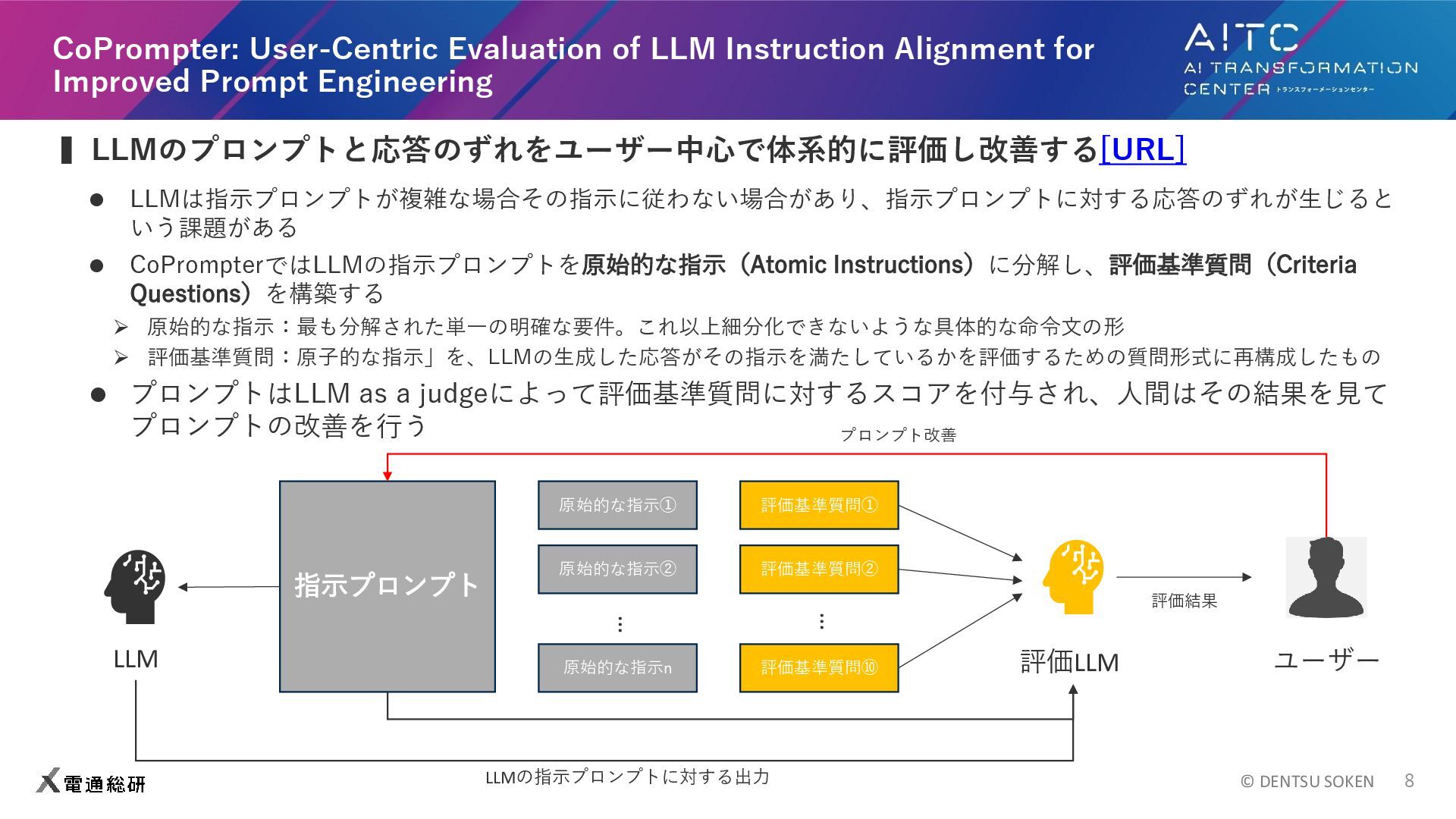
© DENTSU SOKEN 8 CoPrompter: User-Centric Evaluation of LLM Instruction
Alignment for Improved Prompt Engineering ▍LLMのプロンプトと応答のずれをユーザー中心で体系的に評価し改善する[URL] ⚫ LLMは指示プロンプトが複雑な場合その指示に従わない場合があり、指示プロンプトに対する応答のずれが生じると いう課題がある ⚫ CoPrompterではLLMの指示プロンプトを原始的な指示(Atomic Instructions)に分解し、評価基準質問(Criteria Questions)を構築する ➢ 原始的な指示:最も分解された単一の明確な要件。これ以上細分化できないような具体的な命令文の形 ➢ 評価基準質問:原子的な指示」を、LLMの生成した応答がその指示を満たしているかを評価するための質問形式に再構成したもの ⚫ プロンプトはLLM as a judgeによって評価基準質問に対するスコアを付与され、人間はその結果を見て プロンプトの改善を行う 指示プロンプト 原始的な指示① 原始的な指示② 原始的な指示n … 評価基準質問① 評価基準質問② 評価基準質問⑩ … 評価LLM LLM LLMの指示プロンプトに対する出力 評価結果 ユーザー プロンプト改善
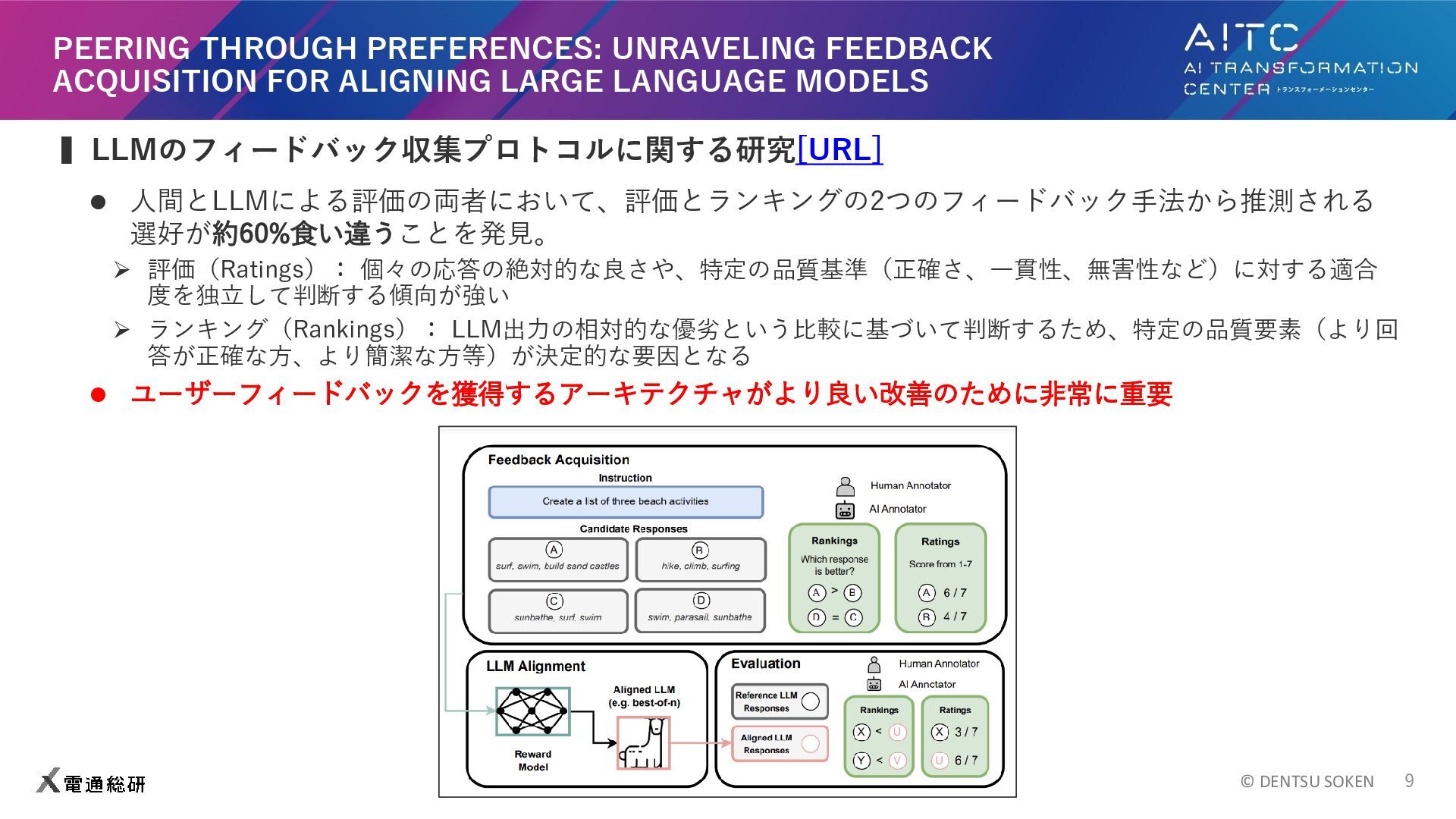
© DENTSU SOKEN 9 PEERING THROUGH PREFERENCES: UNRAVELING FEEDBACK ACQUISITION
FOR ALIGNING LARGE LANGUAGE MODELS ▍LLMのフィードバック収集プロトコルに関する研究[URL] ⚫ 人間とLLMによる評価の両者において、評価とランキングの2つのフィードバック手法から推測される 選好が約60%食い違うことを発見。 ➢ 評価(Ratings): 個々の応答の絶対的な良さや、特定の品質基準(正確さ、一貫性、無害性など)に対する適合 度を独立して判断する傾向が強い ➢ ランキング(Rankings): LLM出力の相対的な優劣という比較に基づいて判断するため、特定の品質要素(より回 答が正確な方、より簡潔な方等)が決定的な要因となる ⚫ ユーザーフィードバックを獲得するアーキテクチャがより良い改善のために非常に重要
© DENTSU SOKEN 10 LLMRefine: Pinpointing and Refining Large Language
Models via Fine- Grained Actionable Feedback ▍LLMが生成した出力テキストの品質を向上させ るための推論時最適化手法の提案[URL] ⚫ これまでのLLMへのフィードバックは、どこにど のような問題があったか が具体的に示されてお らず改善に繋げられないという課題があった ⚫ 提案手法ではError Pinpoint Modelを構築し、 エラーの場所、種類、そして深刻度を細かく特定 することが可能(LLMをデータセットでfine- tuning) ⚫ FBを受け取ったLLMは再度回答を生成。回答は 提案手法の焼きなまし法によってReject/Accept を決定する ※焼きなまし法:金属の焼きなまし過程にヒントを得た手法で、局 所解に陥るリスクを軽減しながら大域的最適解を探索できる 提案手法のFB 提案手法によって、LLM の再出力結果を Accept/Rejectするか決定 既存のFB 具体的なエラーの箇所と理 由がないため改善できない
© DENTSU SOKEN 11 その他 ▍Building an Effective LLM Judge:
Tips and Pitfalls ⚫ https://www.bunnyshell.com/blog/when-ai-becomes-the-judge-understanding-llm-as-a-j/ ⚫ この記事で効果的なJudgeモデルの構築について書かれているが非常に良い ① プロンプトは明瞭かつシンプルに ② 複雑な基準を分解する:評価に複数の側面がある場合はサブジャッジに分解など、シンプルに ③ 例を慎重に使う:良い例と悪い例を提示する ④ CoTとtemperature:評価のランダム性を低減するために使用 ⑤ 検証と反復:ゴールドスタンダードの例を少数用意する ⑥ 複数の評価:高い確信度の評価を獲得するために、評価を複数回試行、多数決などを使用する ⑦ 監視:LLM評価は完全に正しくない。評価のずれに気づいたら、人間が介入し改善せよ ⑧ 専門家を巻き込む:LLM評価を使用したいドメイン領域でなにが正しいのかをしっかりと定義づける
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![© DENTSU SOKEN 6 Prompt Optimization with Human Feedback(POHF) ▍人間のフィードバックによるプロンプト最適化手法[URL]](https://files.speakerdeck.com/presentations/cb9dda5b7fff428b89a6fb2c9229e989/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}