Uses Your Data" under "Unpaid Services" and "Paid Services"), when using Grounding with Google Search, Google will store prompts, contextual information that you may provide, and output for thirty (30) days for the purposes of creating Grounded Results and Search Suggestions and the stored information can be used for debugging and testing of systems that support Grounding with Google Search. When using Grounding with Google Search via paid quota of Gemini API, this processing for debugging and testing of systems is in accordance with the Data Processing Addendum for Products Where Google is a Data Processor. Data Collection & How Google Uses Your Data Gemini API
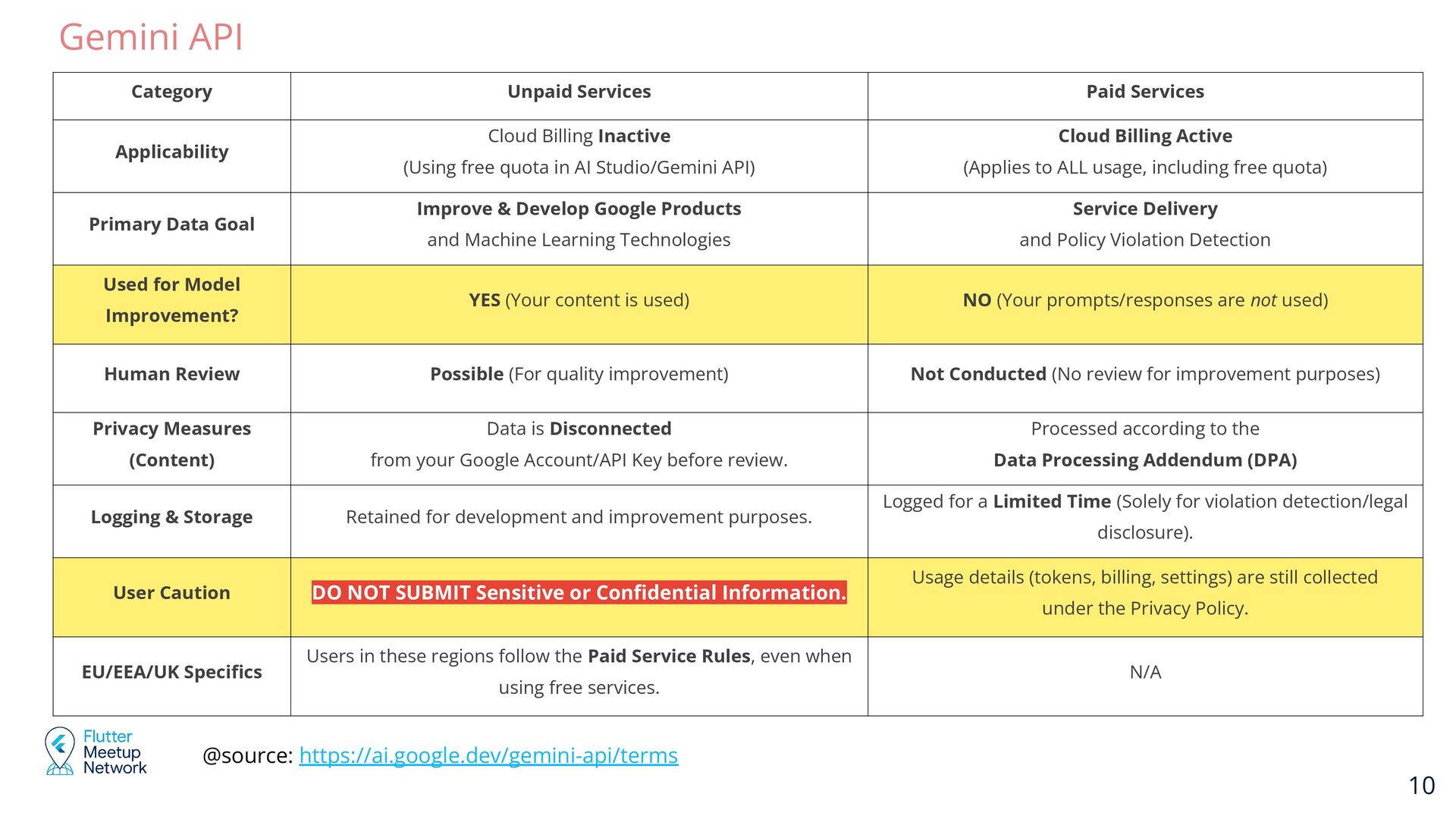
(Using free quota in AI Studio/Gemini API) Cloud Billing Active (Applies to ALL usage, including free quota) Primary Data Goal Improve & Develop Google Products and Machine Learning Technologies Service Delivery and Policy Violation Detection Used for Model Improvement? YES (Your content is used) NO (Your prompts/responses are not used) Human Review Possible (For quality improvement) Not Conducted (No review for improvement purposes) Privacy Measures (Content) Data is Disconnected from your Google Account/API Key before review. Processed according to the Data Processing Addendum (DPA) Logging & Storage Retained for development and improvement purposes. Logged for a Limited Time (Solely for violation detection/legal disclosure). User Caution DO NOT SUBMIT Sensitive or Confidential Information. Usage details (tokens, billing, settings) are still collected under the Privacy Policy. EU/EEA/UK Specifics Users in these regions follow the Paid Service Rules, even when using free services. N/A @source: https://ai.google.dev/gemini-api/terms Gemini API
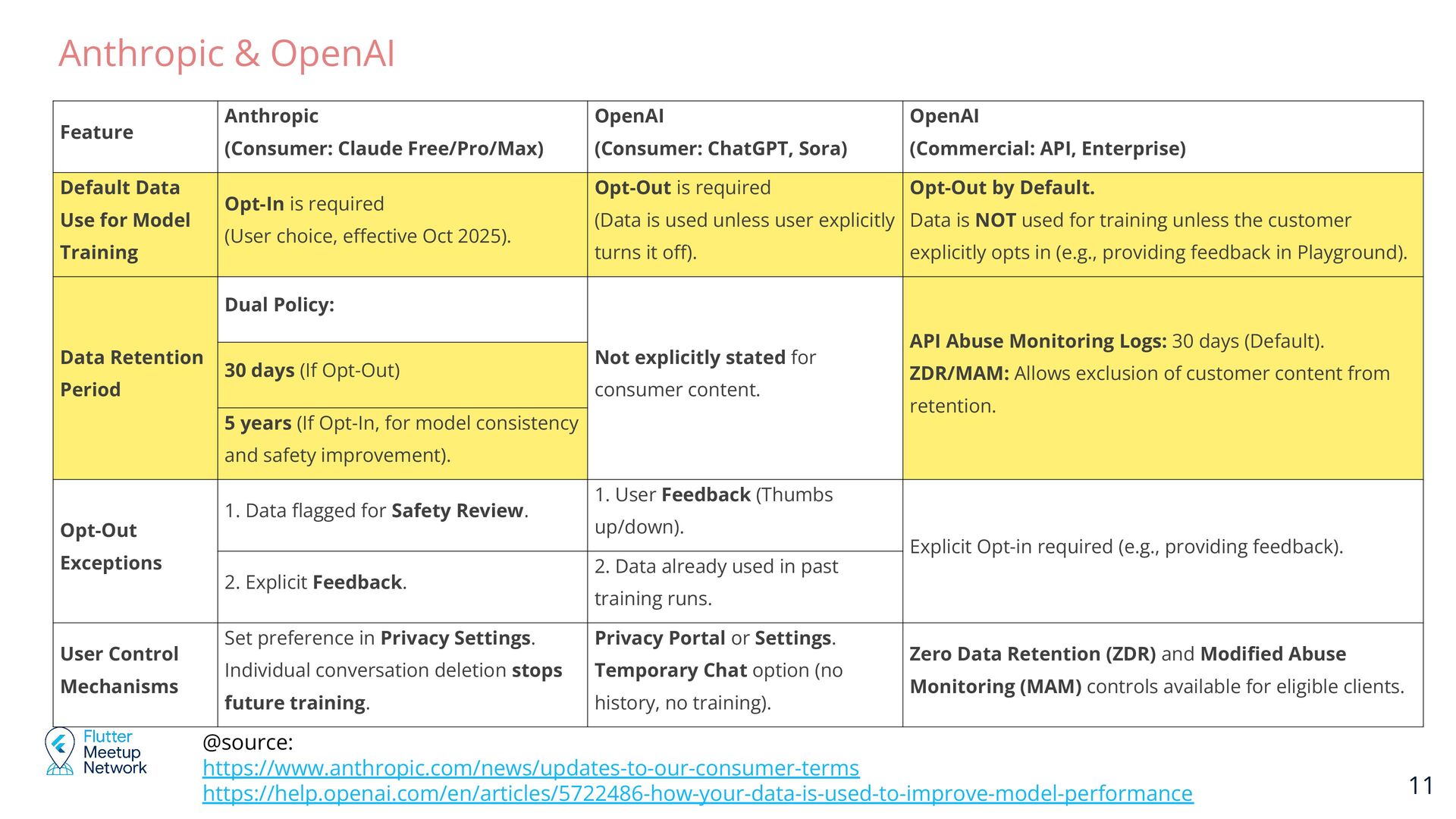
Claude Free/Pro/Max) OpenAI (Consumer: ChatGPT, Sora) OpenAI (Commercial: API, Enterprise) Default Data Use for Model Training Opt-In is required (User choice, effective Oct 2025). Opt-Out is required (Data is used unless user explicitly turns it off). Opt-Out by Default. Data is NOT used for training unless the customer explicitly opts in (e.g., providing feedback in Playground). Data Retention Period Dual Policy: Not explicitly stated for consumer content. API Abuse Monitoring Logs: 30 days (Default). ZDR/MAM: Allows exclusion of customer content from retention. 30 days (If Opt-Out) 5 years (If Opt-In, for model consistency and safety improvement). Opt-Out Exceptions 1. Data flagged for Safety Review. 1. User Feedback (Thumbs up/down). Explicit Opt-in required (e.g., providing feedback). 2. Explicit Feedback. 2. Data already used in past training runs. User Control Mechanisms Set preference in Privacy Settings. Individual conversation deletion stops future training. Privacy Portal or Settings. Temporary Chat option (no history, no training). Zero Data Retention (ZDR) and Modified Abuse Monitoring (MAM) controls available for eligible clients.
구성 요소 Model 모델 The Brain 학습된 지식 A trained file with pattern recognition capabilities, optimized for mobile devices. 훈련 과정을 거쳐 패턴 인식 능력을 갖춘 파일. 반드시 모바일 환경에 맞게 경량화되어야 합니다. Hardware 하드웨어 The Body 실행 환경 Hardware that executes the model, determining speed and efficiency. 모델이 실제 계산을 수행하는 물리적 장치. 속도와 효율성을 결정합니다. Inference Engine / Runtime 추론 엔진/런타임 The Translator 번역 및 실행기 Software layer that converts the model into hardware-executable instructions and runs inference. 모델 파일(1)을 가져와 하드웨어(2)가 이해할 수 있는 명령어로 변환하고 추론을 실행하는 소프트웨어 레이어. 17
17 (Pro) Apple iPhone 17(Standard) Expected Release Q1 2025 October 2025 September 2025 Processor Qualcomm Snapdragon 8 Google Tensor G5 Apple A19 Pro Apple A19 RAM 12GB - 16GB 12GB 12GB 8GB HARDWARE On-Device AI
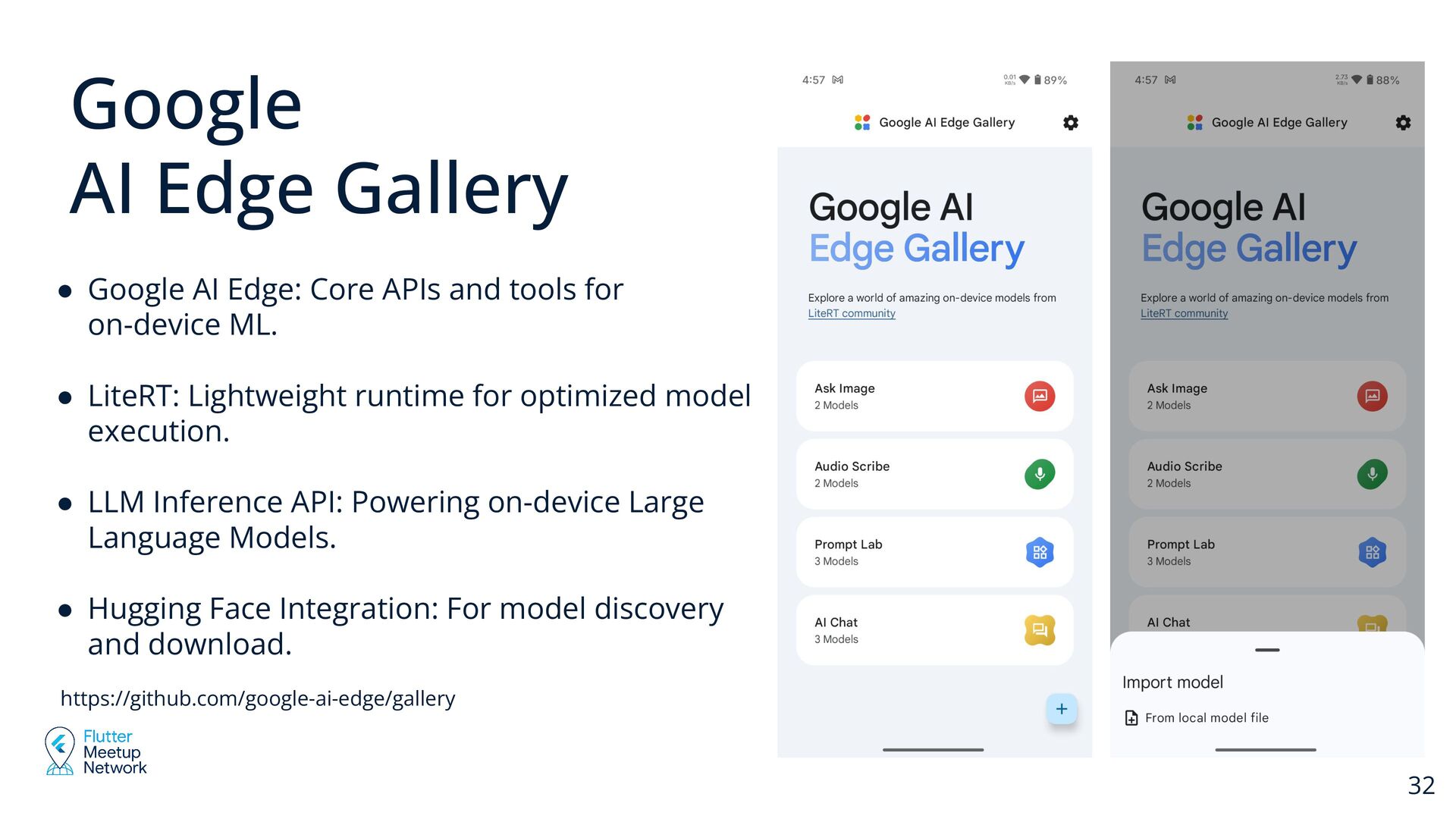
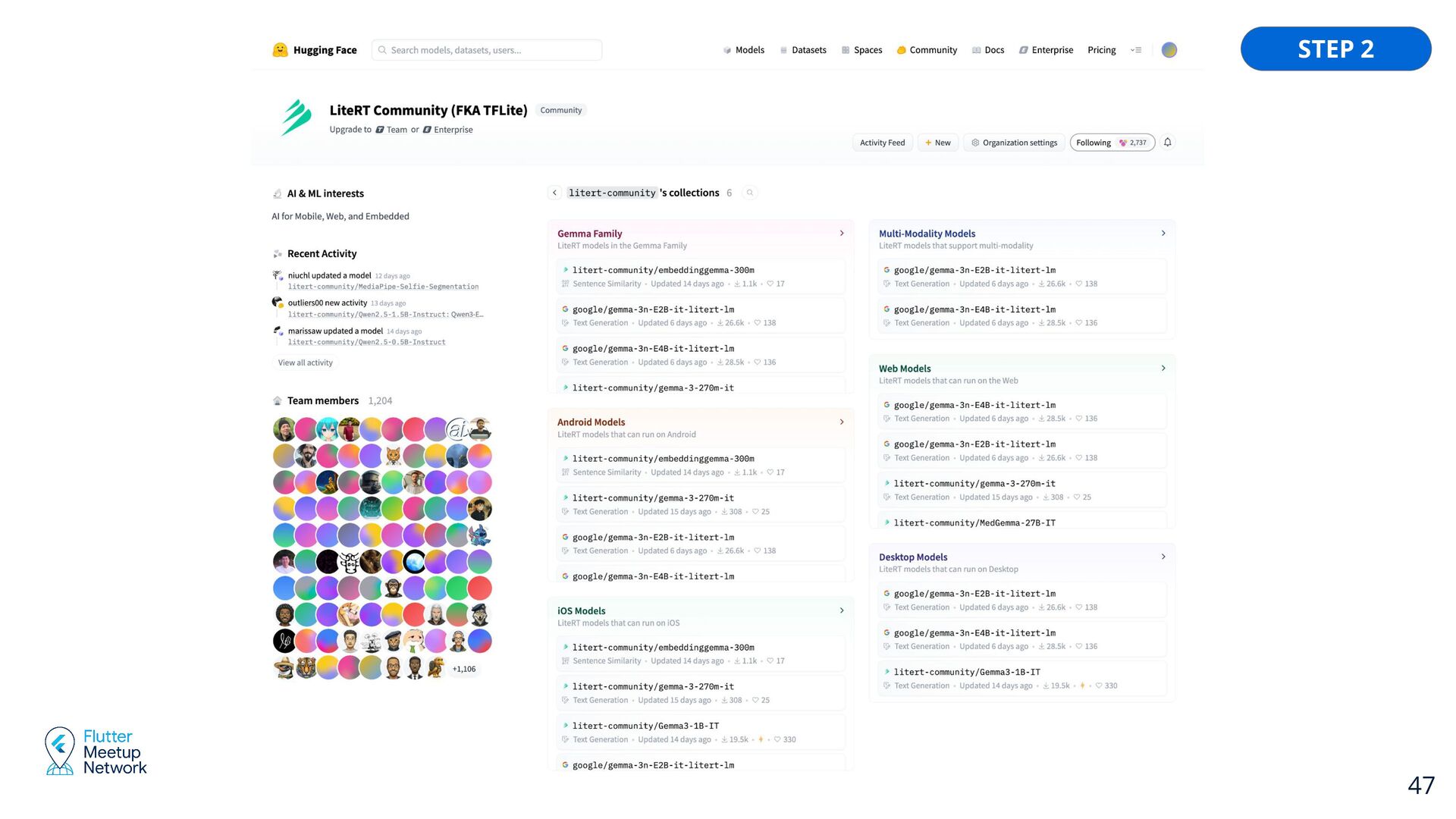
ML. • LiteRT: Lightweight runtime for optimized model execution. • LLM Inference API: Powering on-device Large Language Models. • Hugging Face Integration: For model discovery and download. https://github.com/google-ai-edge/gallery Google AI Edge Gallery 32
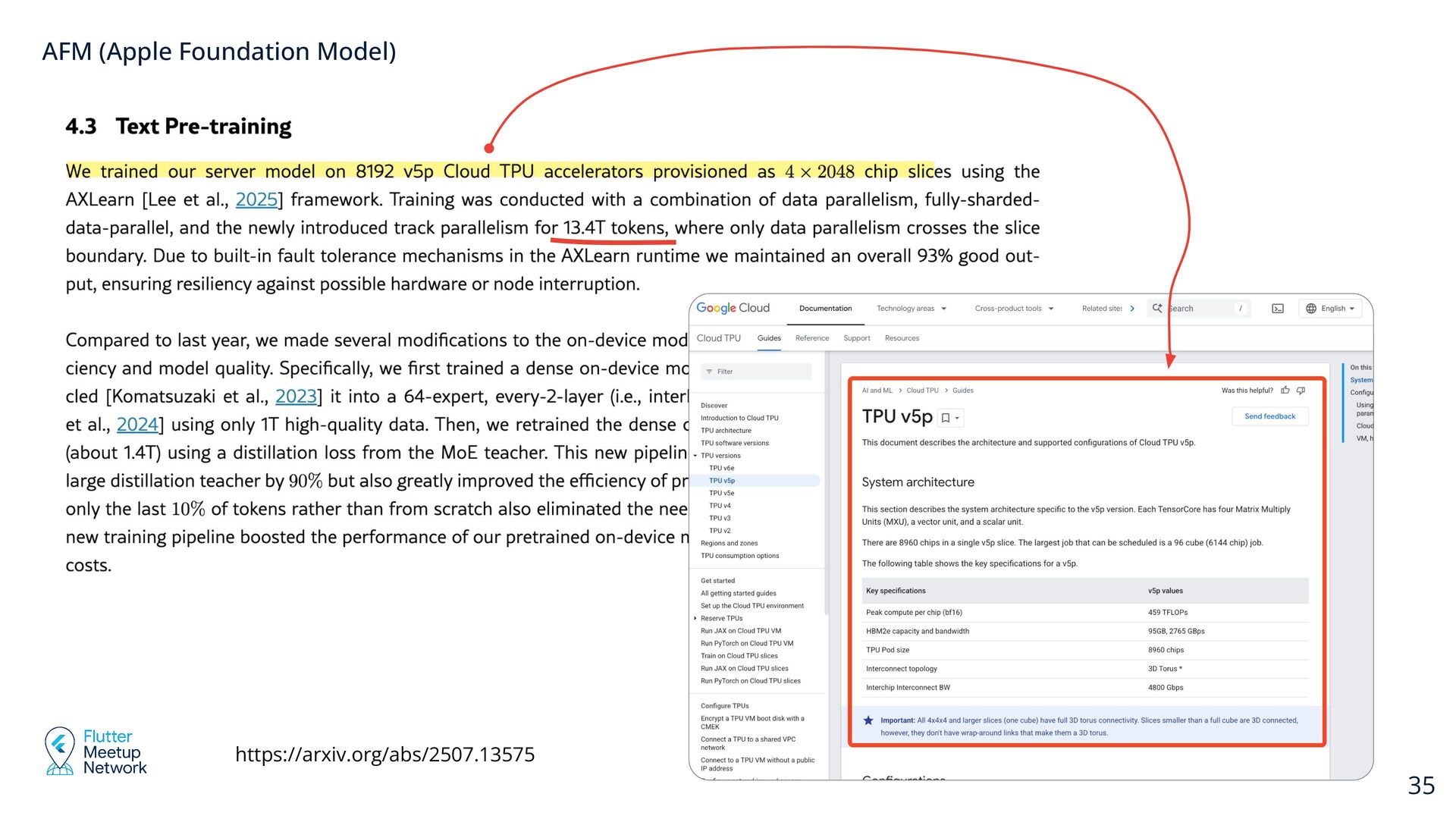
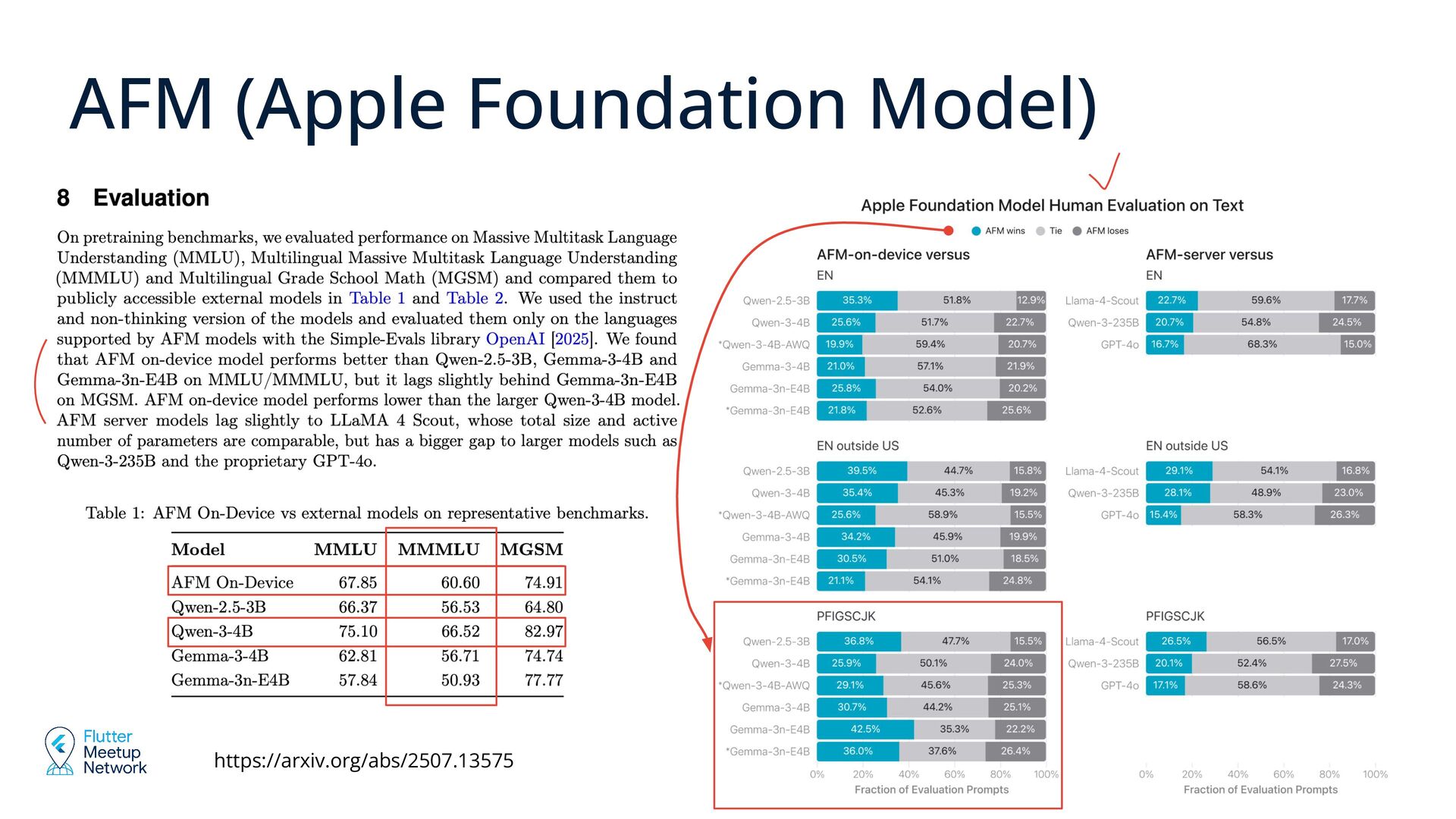
innovations such as KV-cache sharing and 2-bit quantization-aware training; The context window size: the system model supports up to 4,096 tokens https://arxiv.org/abs/2507.13575 AFM (Apple Foundation Model)
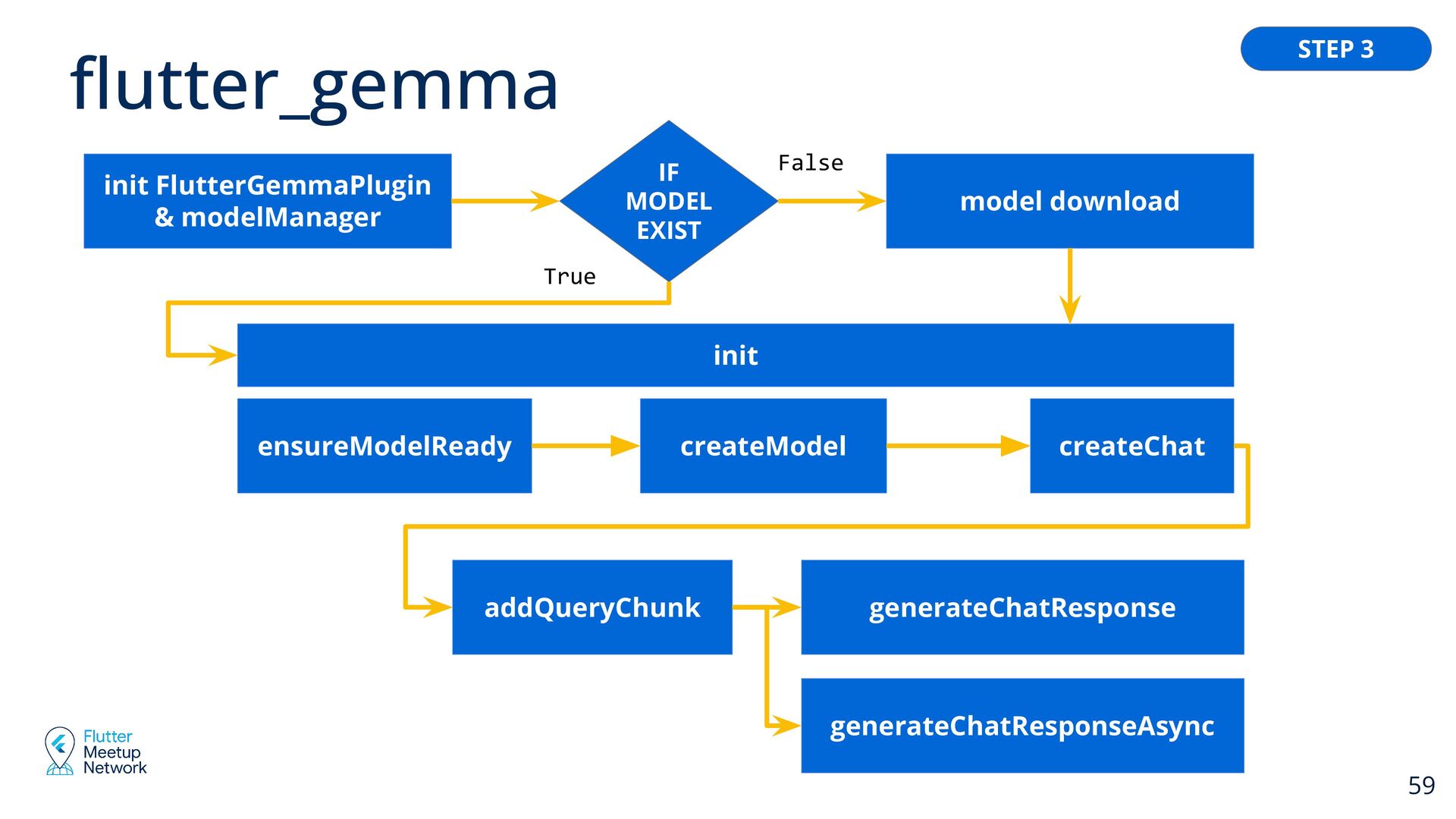
플러터 패키지 탐색하기 또는 직접 개발하기 Build the UI 화면 개발하기 Download the model (locally or from cloud storage) 모델 다운로드 받기 (로컬 또는 클라우드 스토리지) Add inference functionality 추론 기능 넣기 Review the results 결과 검토하기 + + + Steps + + 39
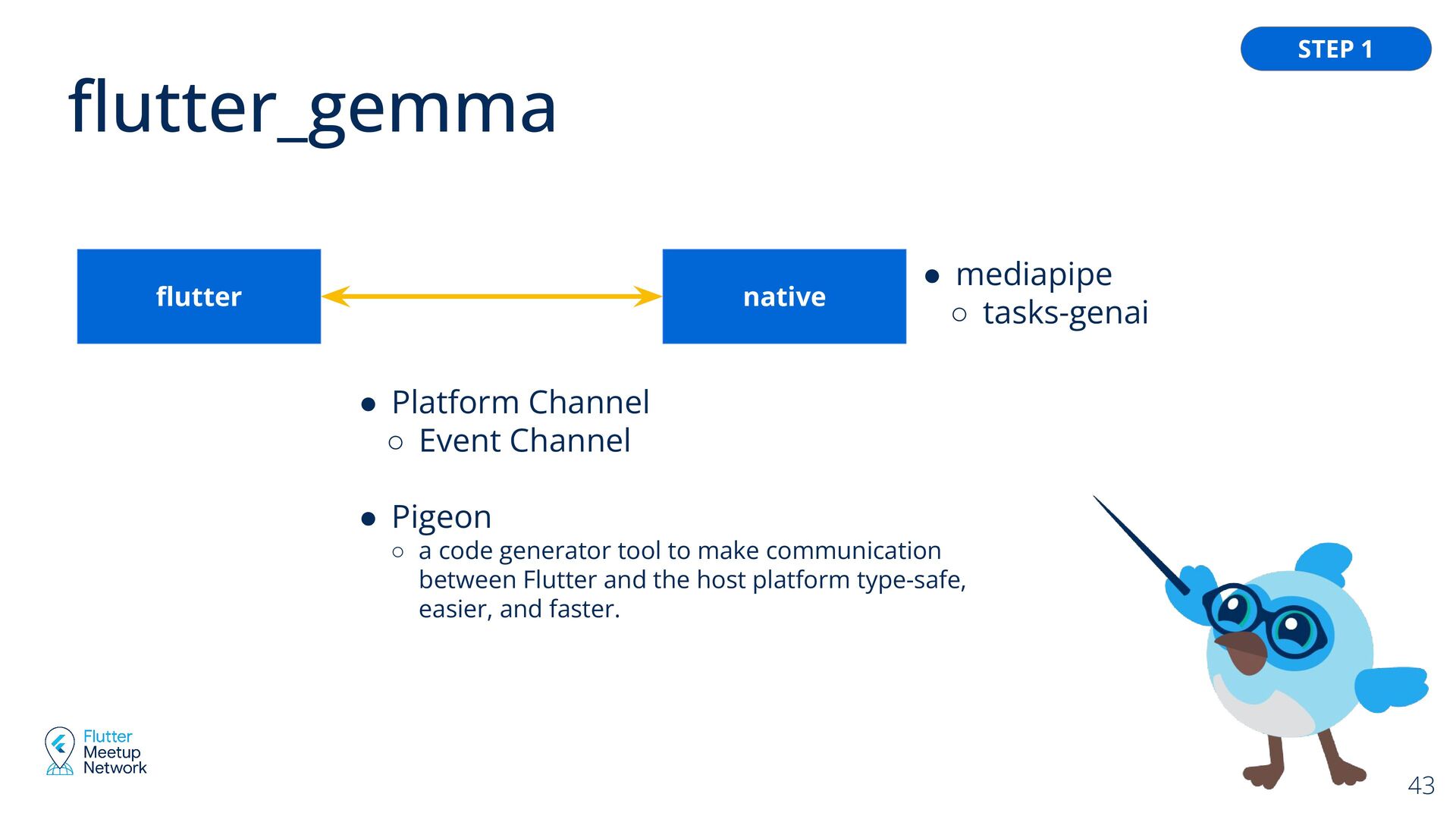
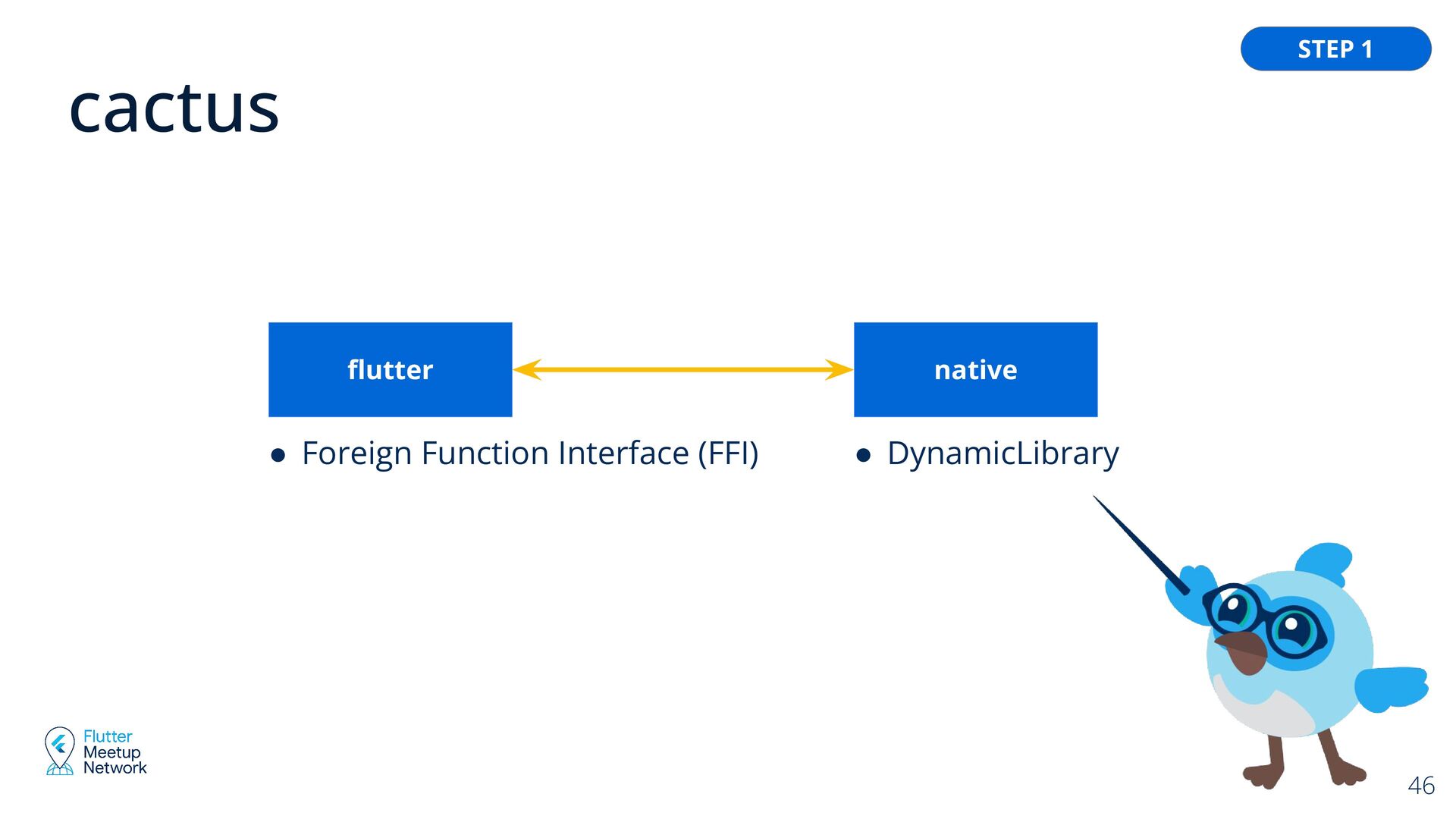
Event Channel • Pigeon ◦ a code generator tool to make communication between Flutter and the host platform type-safe, easier, and faster. • mediapipe ◦ tasks-genai
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}