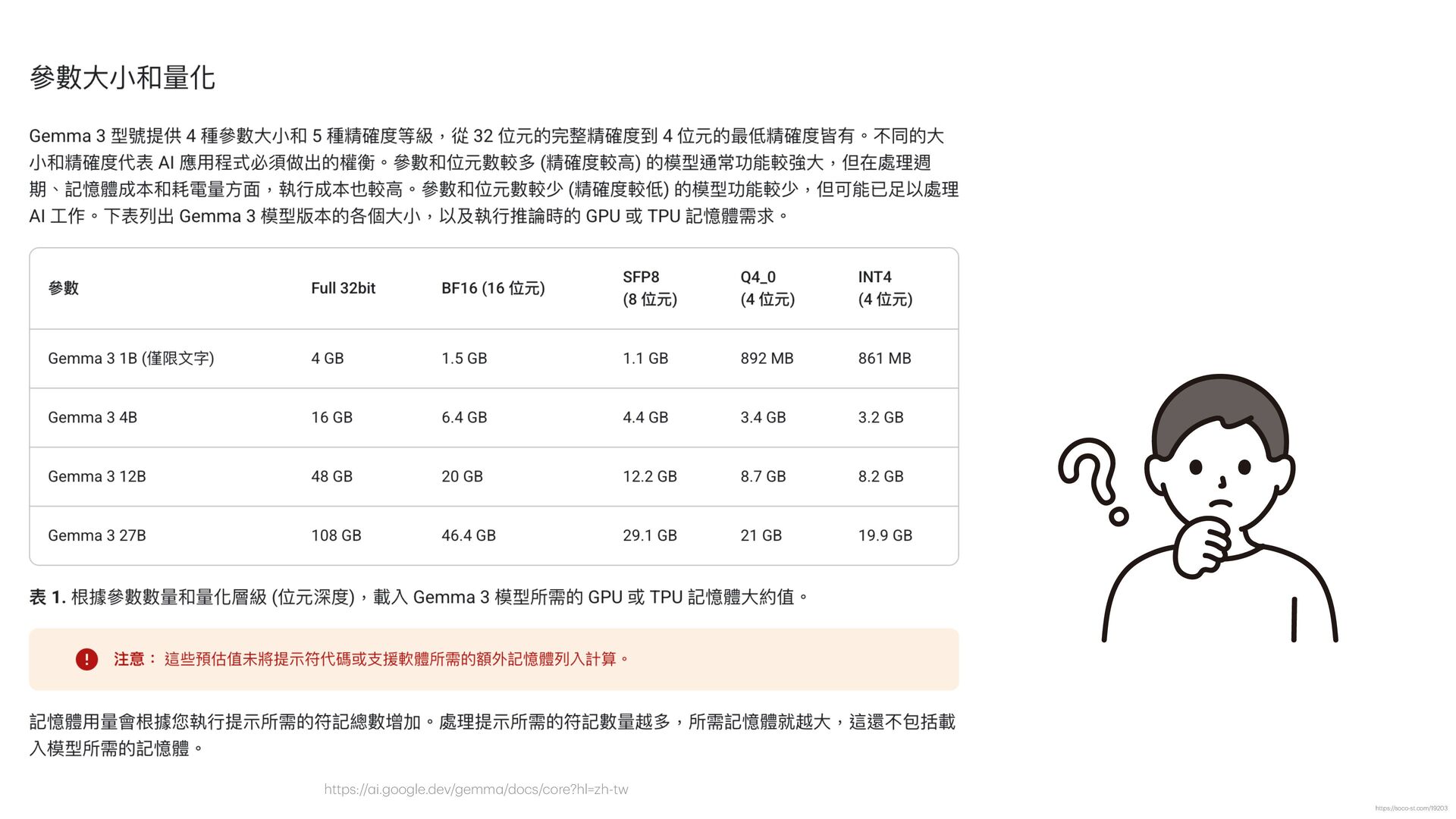
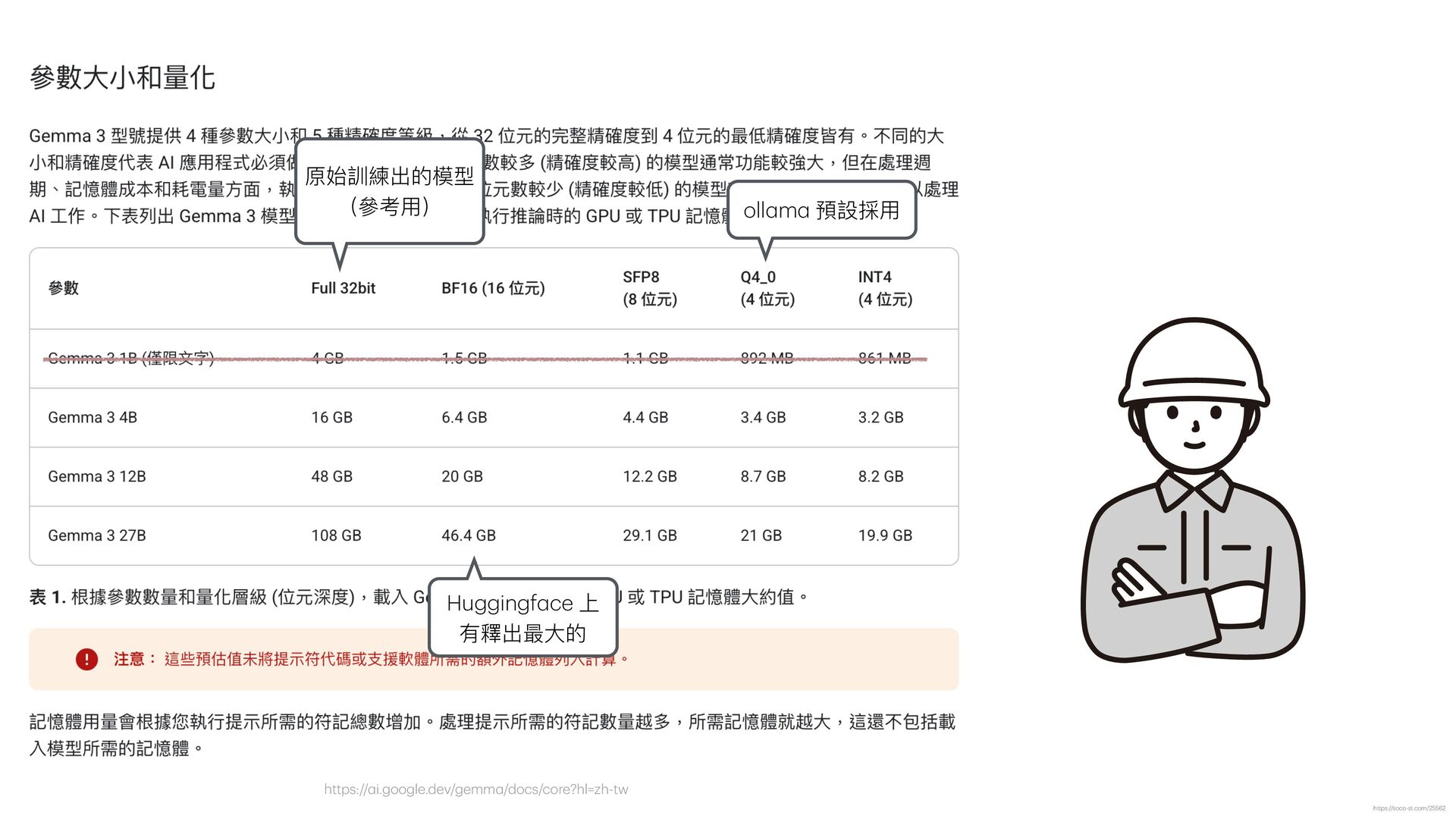
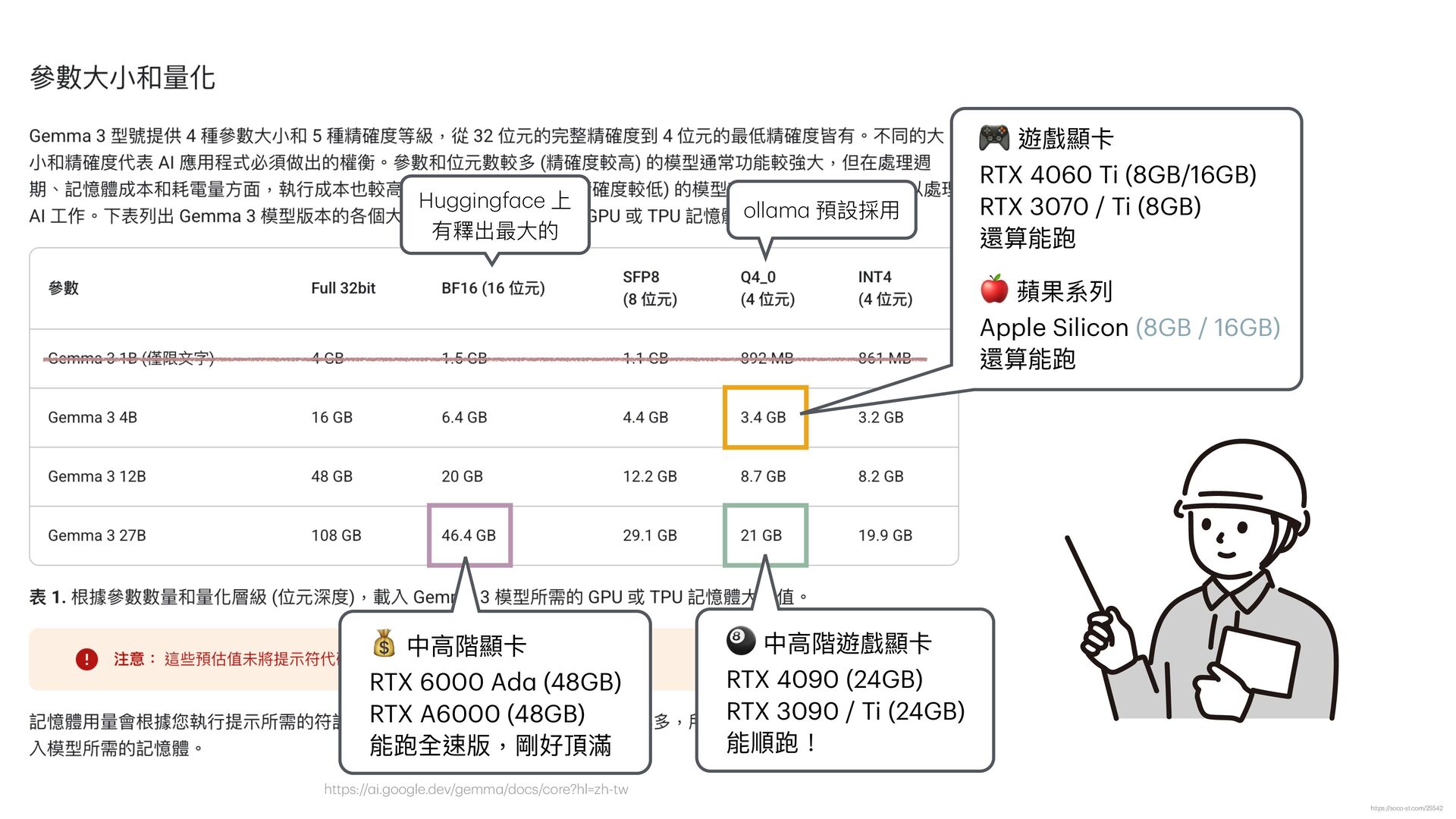
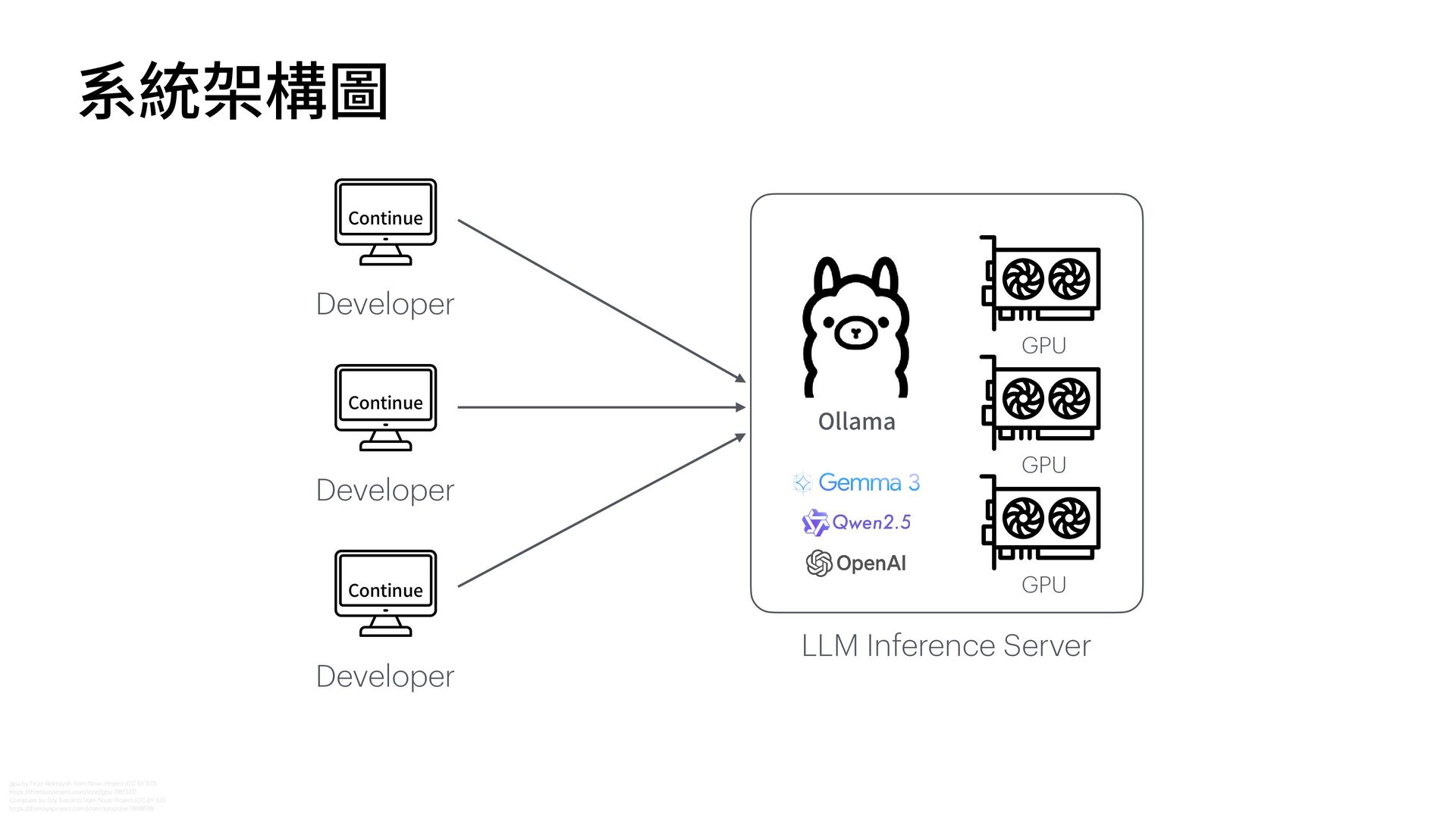
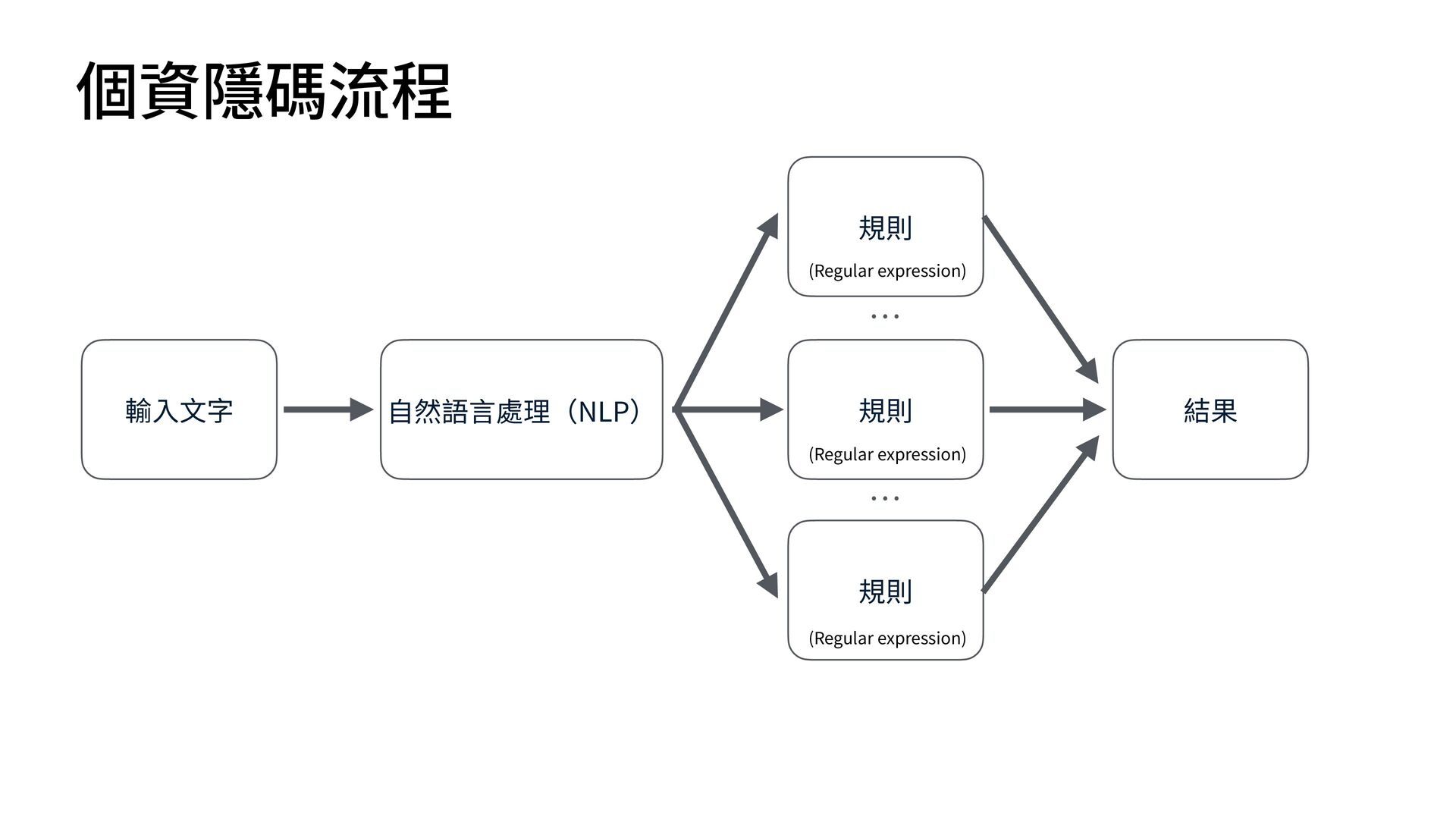
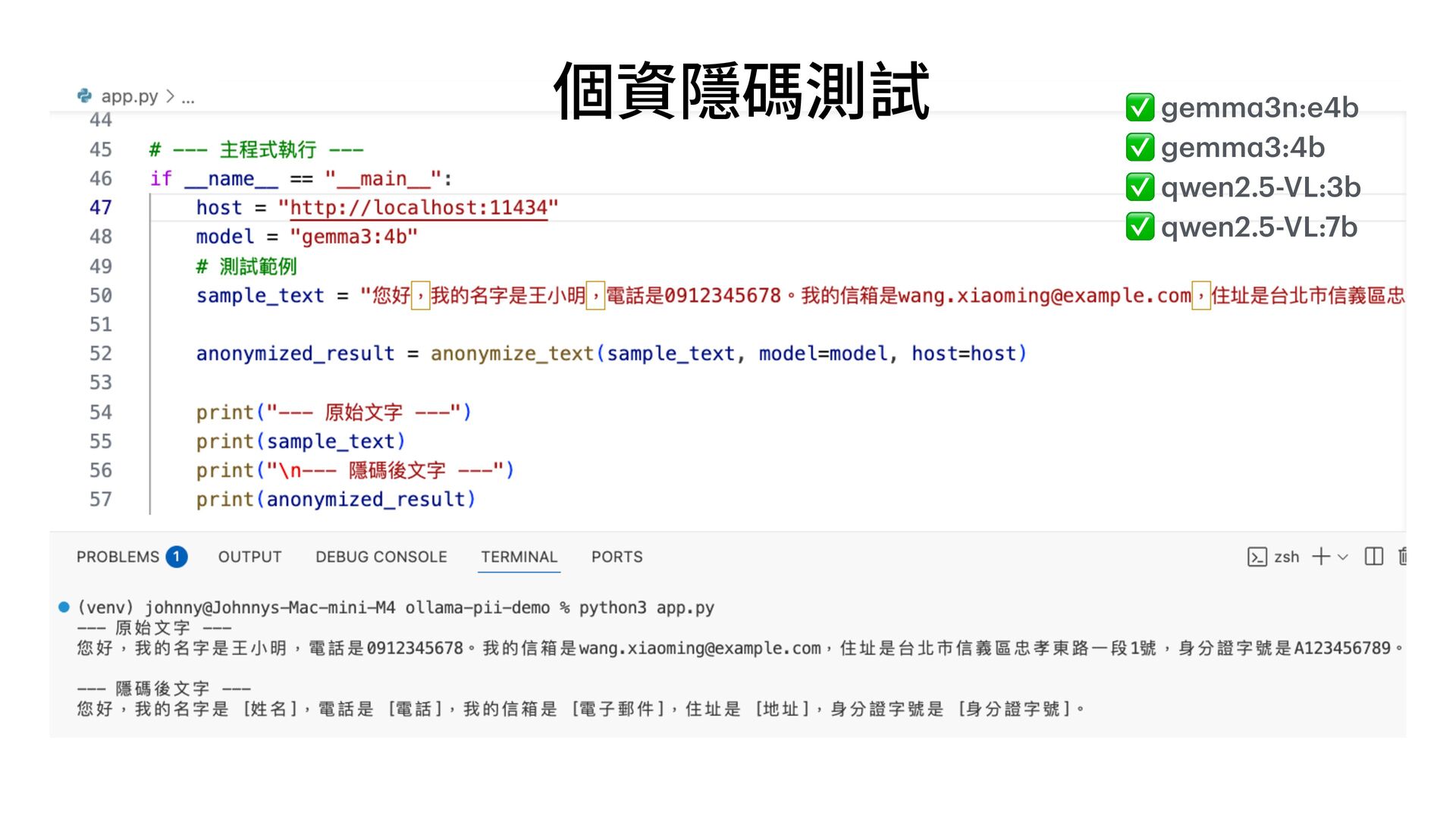
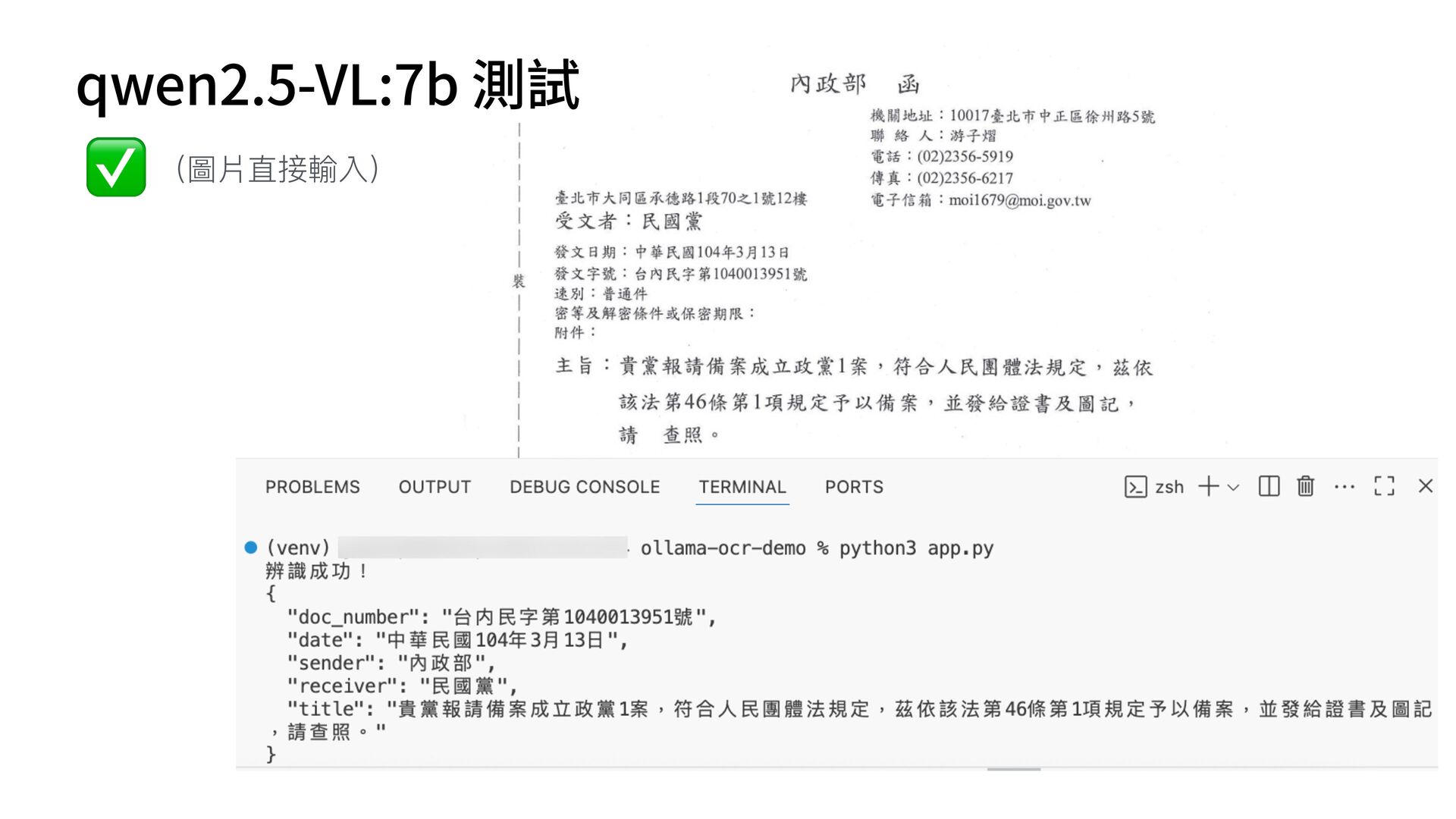
函", "receiver": "各縣市政府", "title": "關於檢討修正『漁業資源永續利 用 相關法規』實施情形及配套措施 一 案" } { "doc_number": "N/A", "date": "11/22", "sender": "外交部 函", "receiver": "N/A", "title": "關於「台灣參與國際組織」相關事宜之說明" } { "doc_number": "N/A", "date": "11/29", "sender": " 行 政院農委會 農業技術司 函", "receiver": " 行 政院農業委員會", "title": "關於農藥使 用 管理辦法調整 一 案之說明" } { "doc_number": "N/A", "date": "中華 民 國104年3 月 13 日 ", "sender": "臺北市政府", "receiver": "N/A", "title": "有關強化停 車 場 自 動引導系統功能及改善提升規劃作業" } { "doc_number": "46", "date": "104年2 月 17 日 ", "sender": " 行 政院", "receiver": "N/A", "title": "就電 辦理 行 政院 獎勵品發放事宜" } { "doc_number": "46", "date": "2017年2 月 17 日 ", "sender": " 行 政院", "receiver": "各 戶 籍", "title": "關於 行 政院備案訊息的規定" } { "doc_number": "104年3 月 13 日 ", "sender": " 行 政院", "receiver": "N/A", "date": "2015/03/13", "title": "修正 行 政院訓 示 警 號" } https://soco-st.com/25578 你是 一 位專業的台灣政府公 文 辨識助 手 。 請辨識這張圖 片 中的 文 字,並嚴格按照以下要求,抽取 出指定的四個欄位資訊,並以 一 個 JSON 物件格式回傳。 1. 發 文 字號 (JSON key: "doc_number") 2. 發 文日 期 (JSON key: "date") 3. 發 文 機關 在標題 XXX 函 (JSON key: "sender") 4. 受 文 者 (JSON key: "receiver") 5. 主旨 (JSON key: "title") 如果某個欄位在圖 片 中找不到,請將其值設為 "N/A"。 你的回覆**只能**包含 一 個沒有任何額外說明的 JSON 物 件。 Gemma 3 測試 Prompt (圖片直接輸入) ❌ ❌ ❌ ❌ ❌ ❌ ❌
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}