PySpark (the component of Spark that allows users to write their code in Python) has grabbed the attention of Python programmers who analyze and process data for a living. The appeal is obvious: you don't need to learn a new language, and you still have access to modules (pandas, nltk, statsmodels, etc.) that you are familiar with, but you are able to run complex computations quickly and at scale using the power of Spark.
In this talk, we will examine a real PySpark job that runs a statistical analysis of time series data to motivate the issues described above and provides a concrete example of best practices for real world PySpark applications. We will cover:
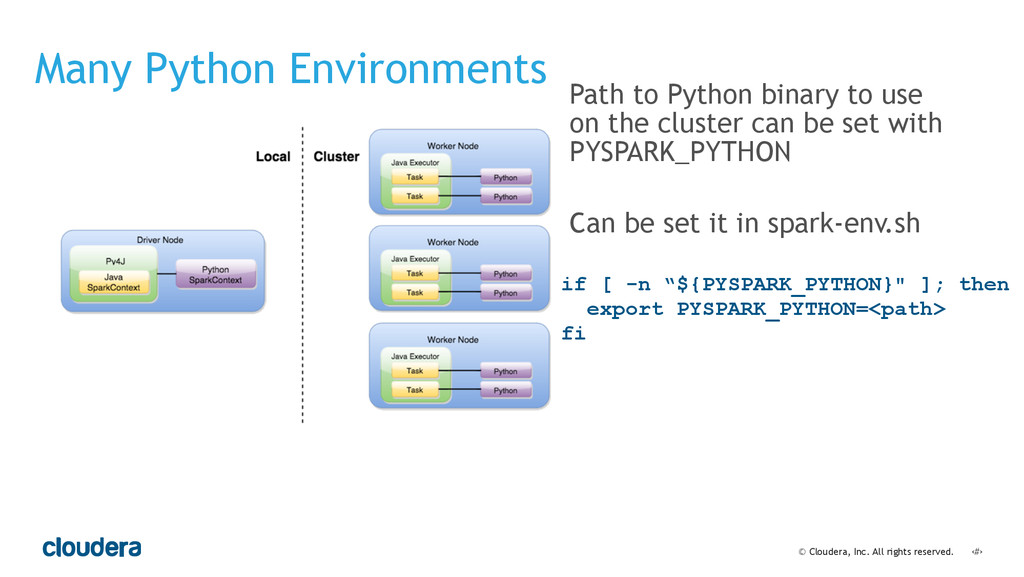
• Python package management on a cluster using Anaconda or virtualenv.
• Testing PySpark applications.
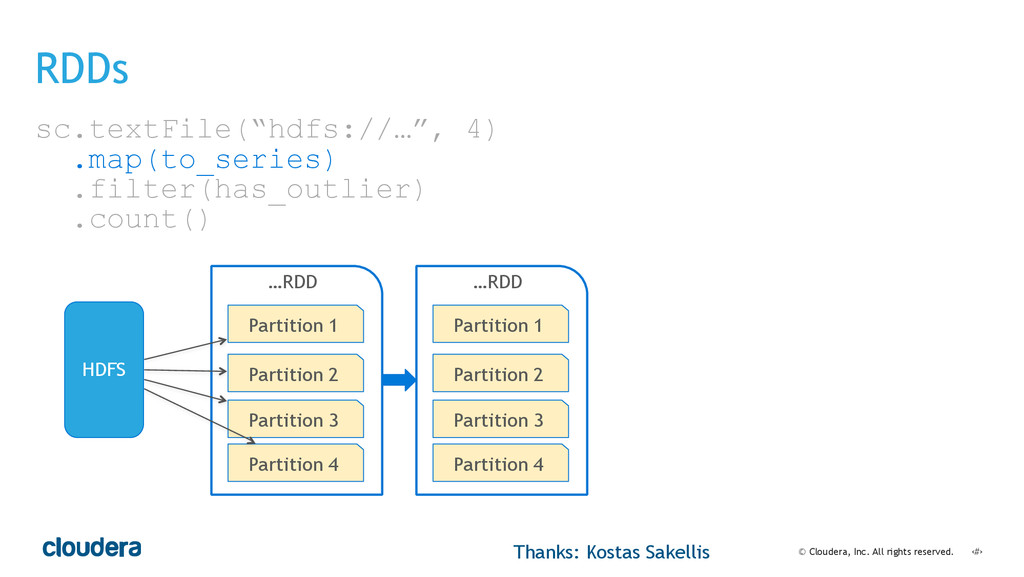
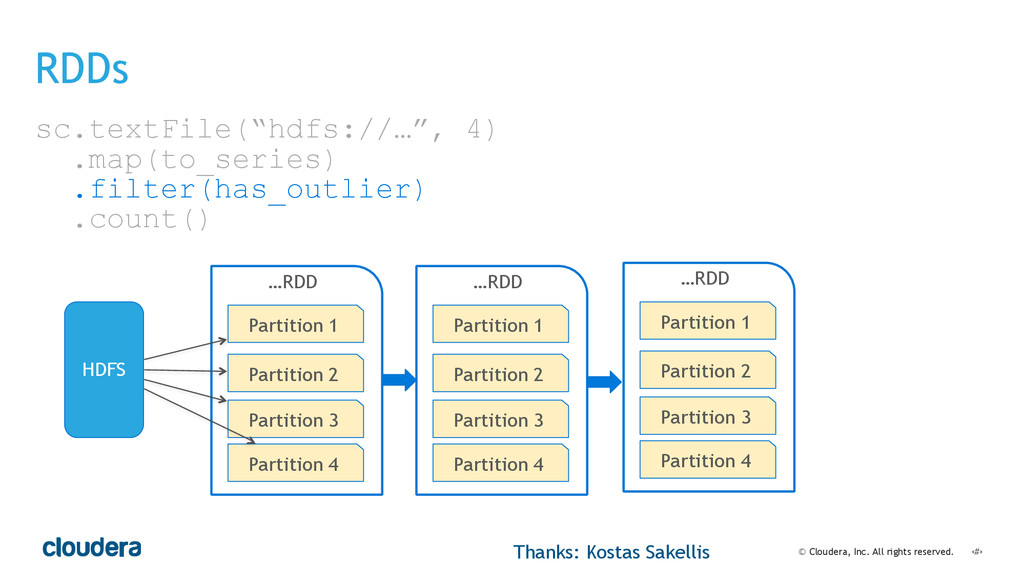
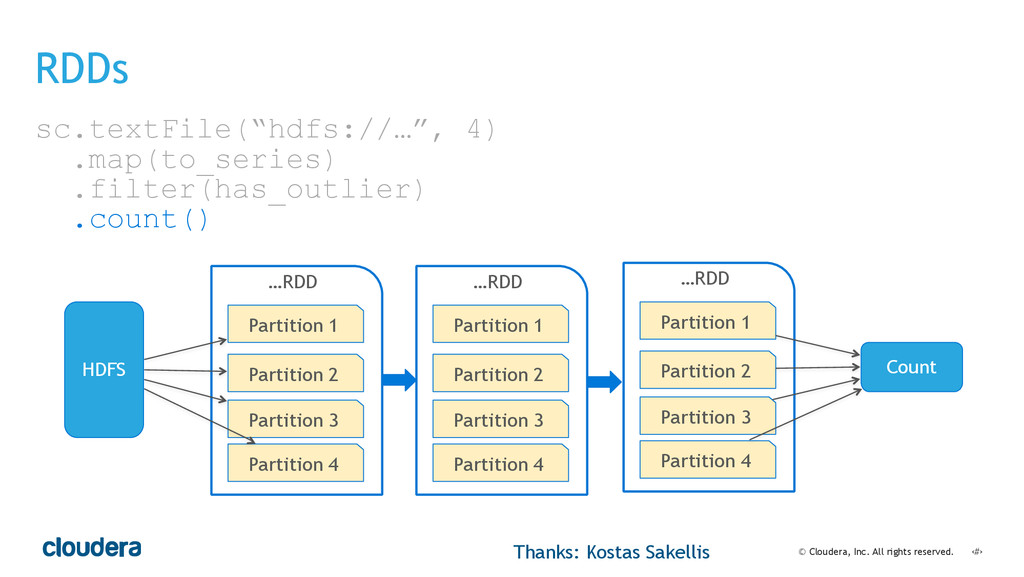
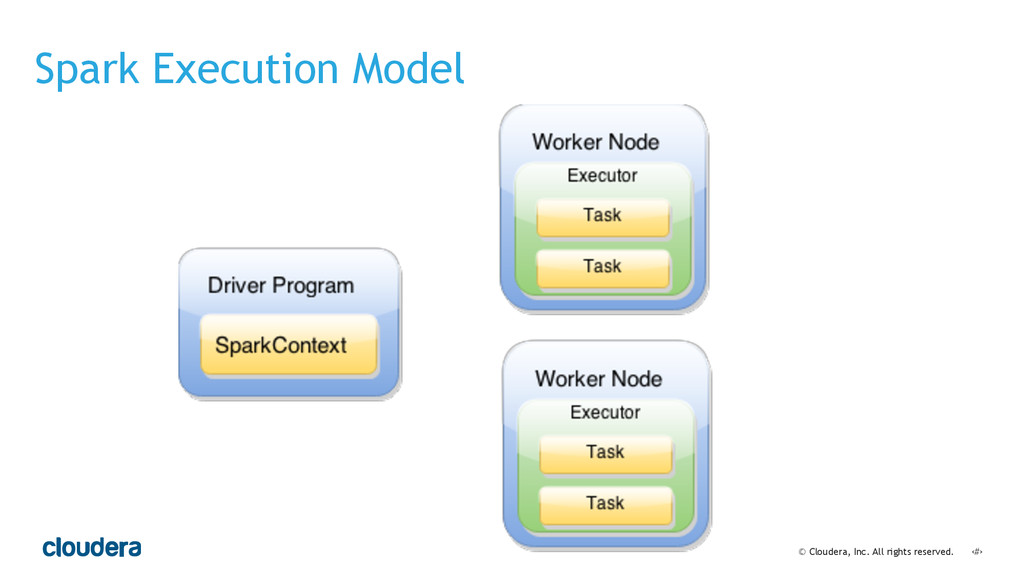
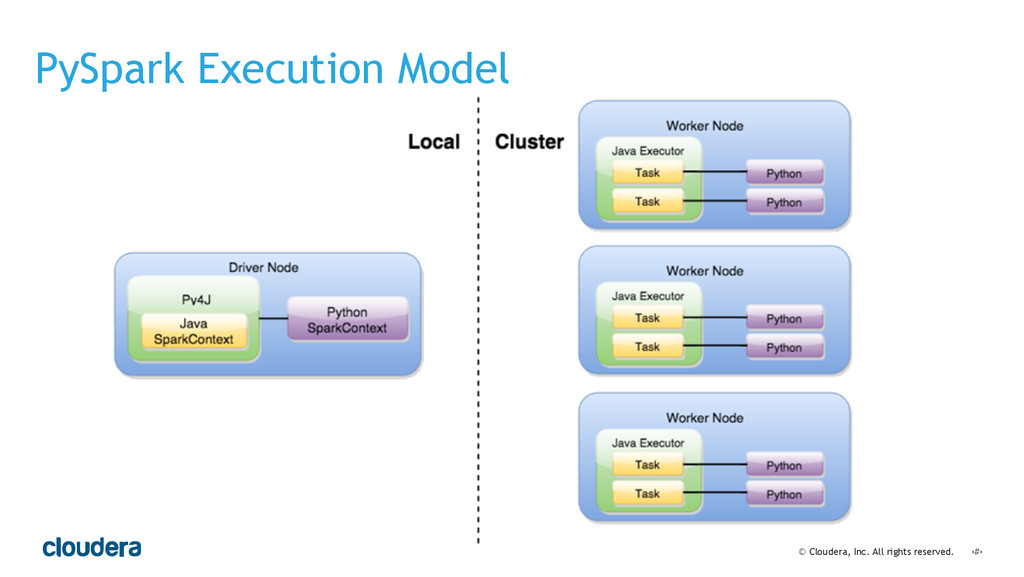
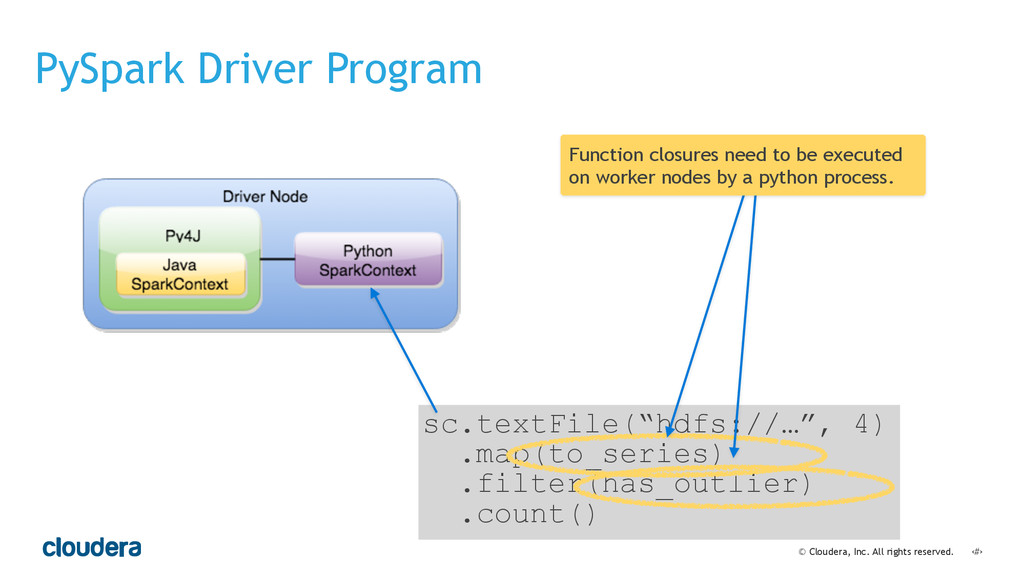
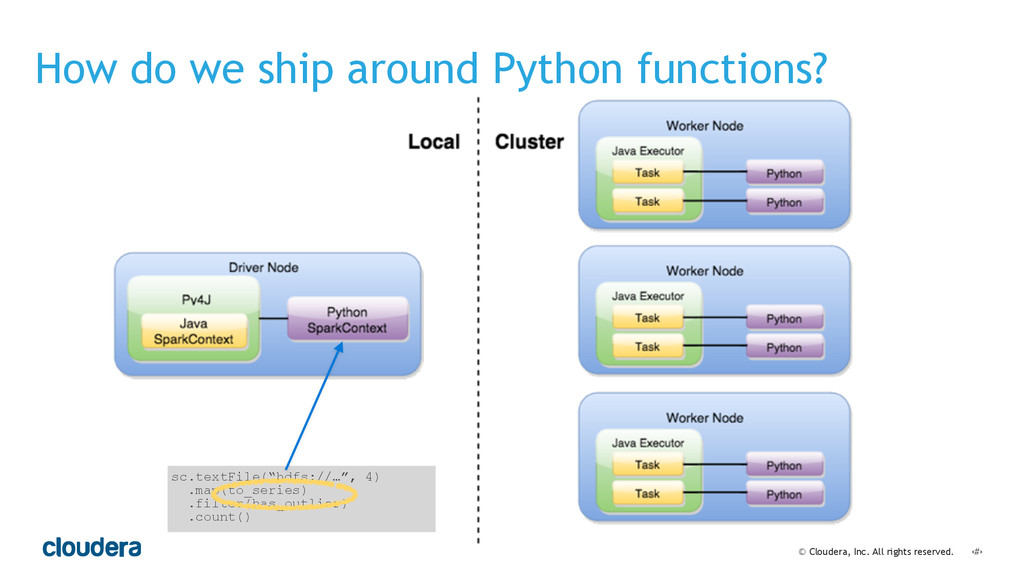
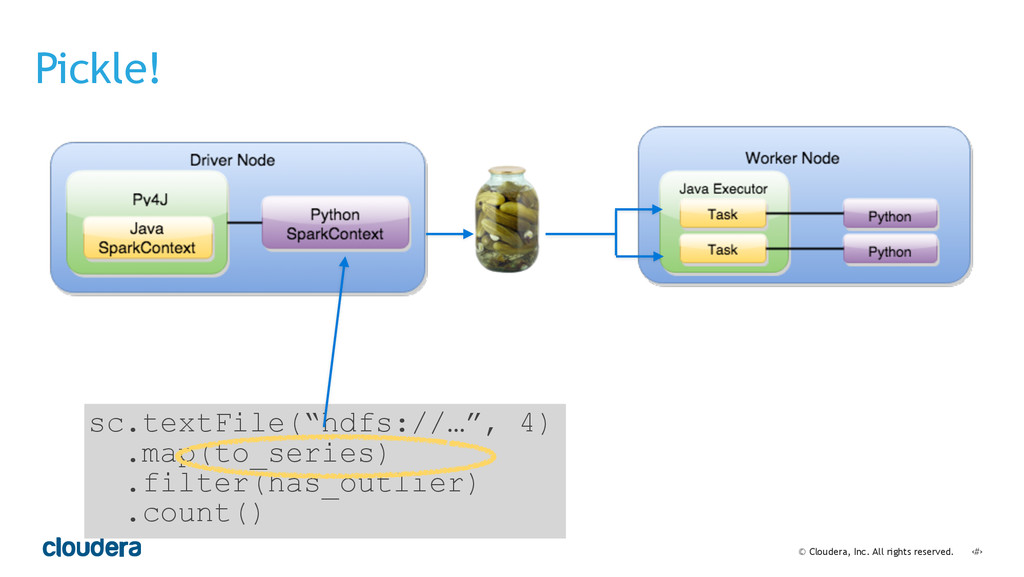
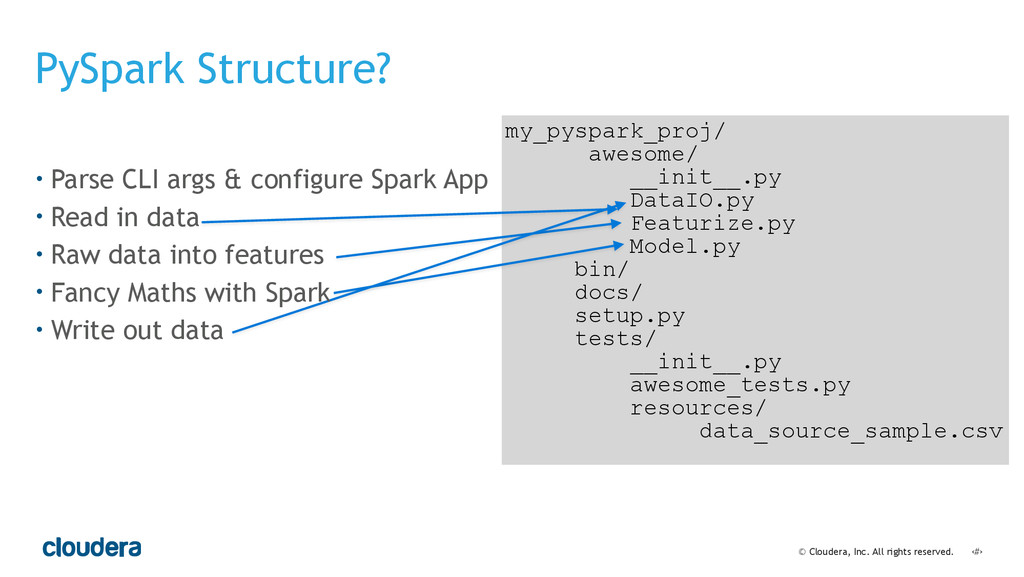
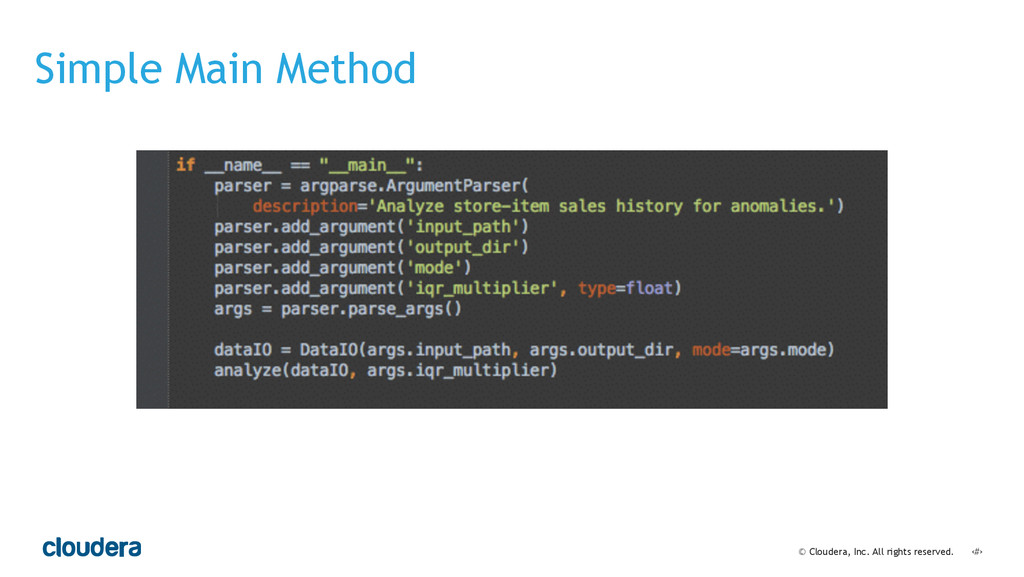
• Spark's computational model and its relationship to how you structure your code.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}