Возможно, вы не знаете, но прямо сейчас происходит революция, и, похоже, гегемону придется поделиться своей властью. Можете ли вы предположить, что лучший CPU для вашего серверного приложения уже не x86?
«Это вообще законно? И при чём тут Java?» — спросите вы.
Процессоры ARM традиционно использовались для встроенных систем. А теперь сразу несколько производителей CPU бросают вызов Intel в сегменте железа для облаков и HPC. И на их ARM-тачках работает Java, a также всё, что есть в экосистеме. Серверные процессоры с архитектурой ARM64 — это горы быстрой памяти, десятки быстрых ядер, сотни нитей и здоровенные кластеры. Закономерно встаёт ряд вопросов:
- а действительно ли оно работает, и почему так быстро?
- когда же это работает действительно хорошо, и что можно оптимизировать для более эффективного использования ARM-серверов?
Из этого доклада вы узнаете о том, как эволюционировала экосистема Java на ARM, а также о фичах ARM-порта OpenJDK и о производительности некоторых рабочих нагрузок. Мы расскажем, как из порта AARCH64 за два года стала вырисовываться конфетка. А на подходе уже новое железо и Java 12.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![34 WWW.BELL-SW.COM StringCoding.hasNegatives() @HotSpotIntrinsicCandidate public static boolean hasNegatives(byte[] ba, int](https://files.speakerdeck.com/presentations/edeef64a72b4437e94db6251eadc6c45/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
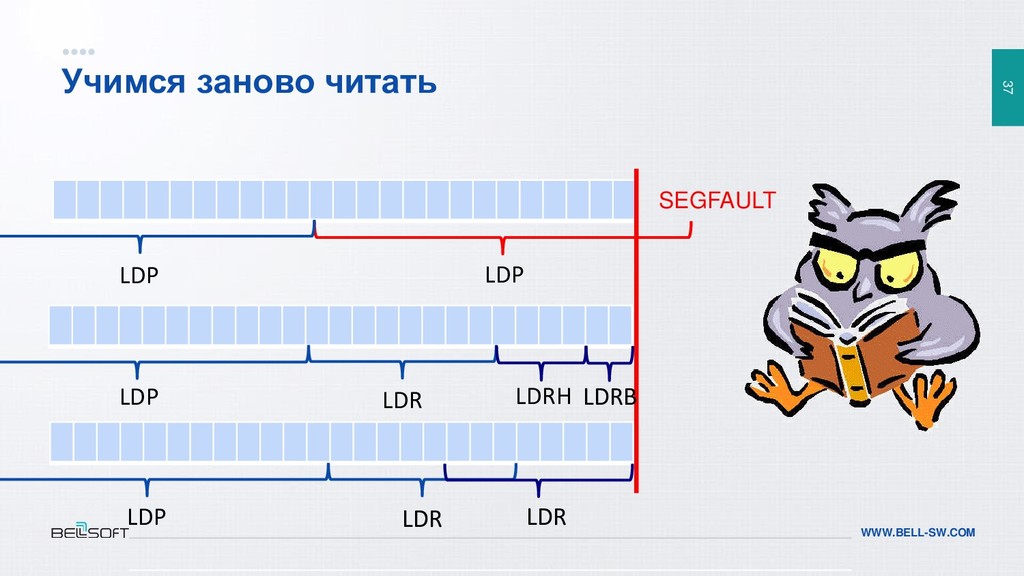{kind=link}
{kind=link}
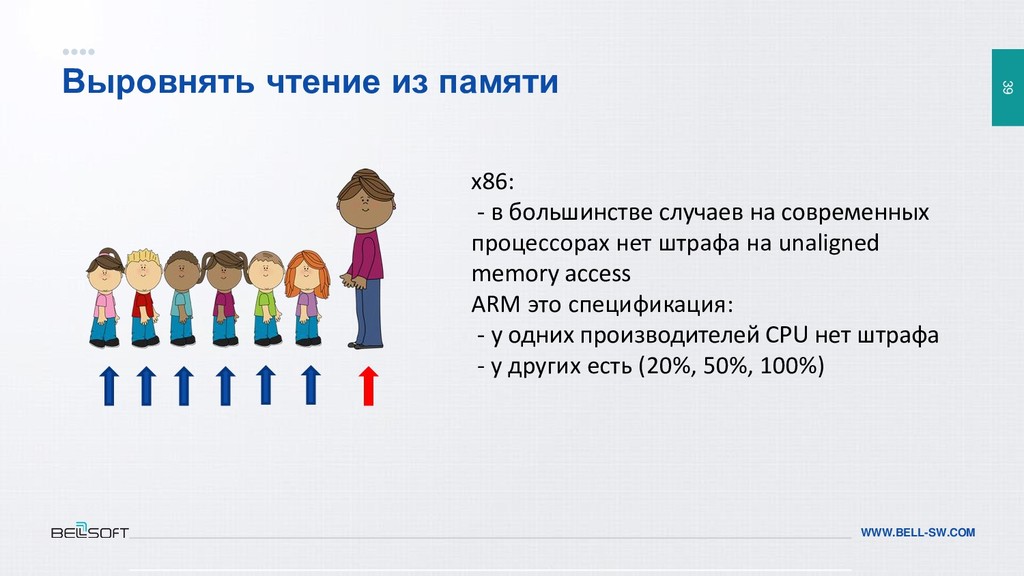{kind=link}
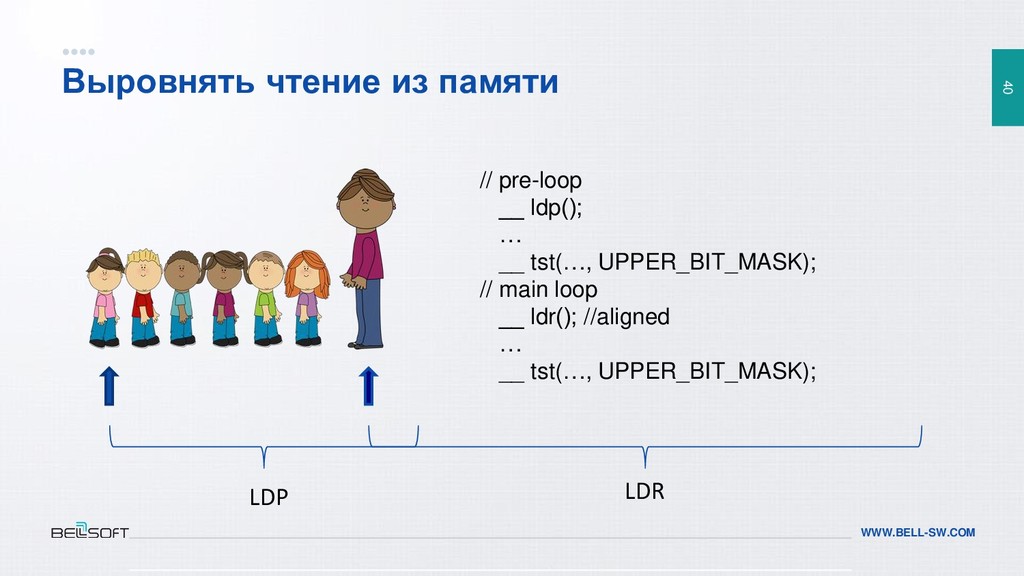{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
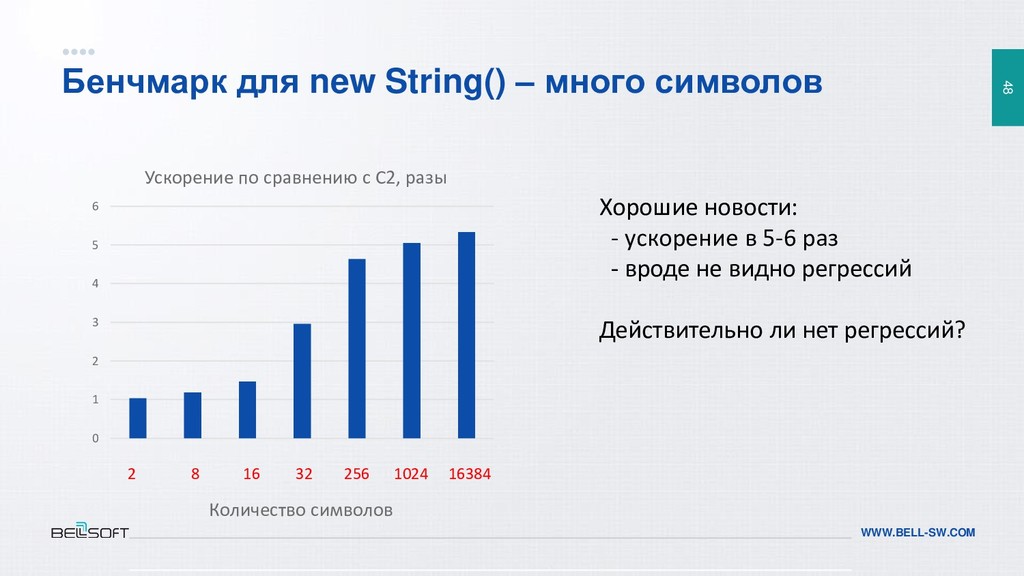{kind=link}
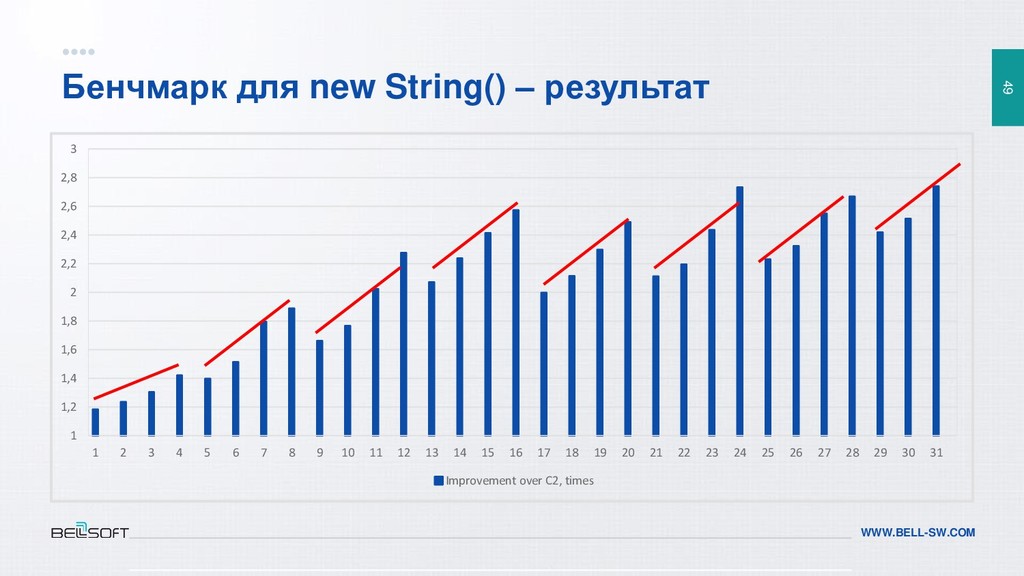{kind=link}
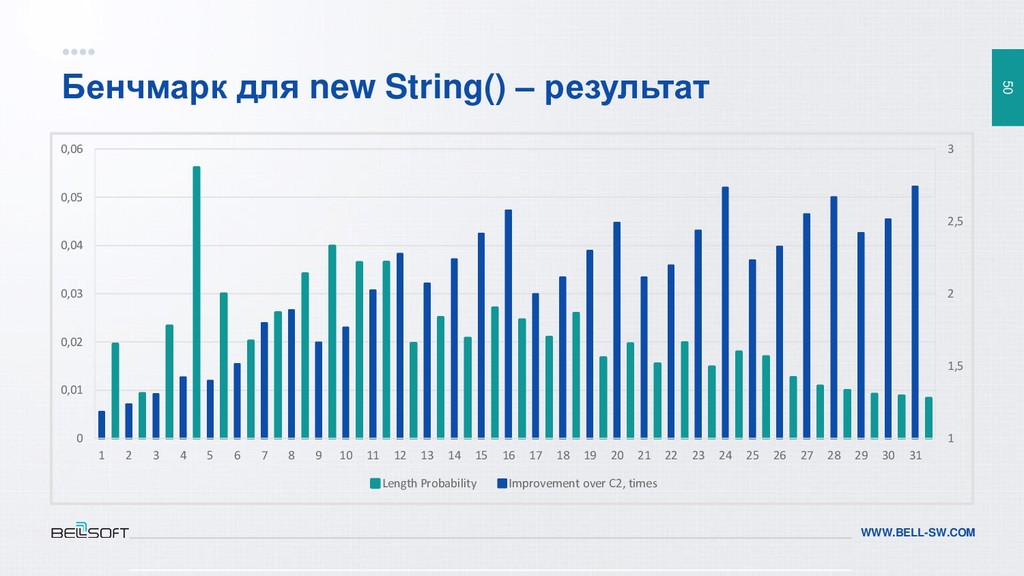{kind=link}
{kind=link}
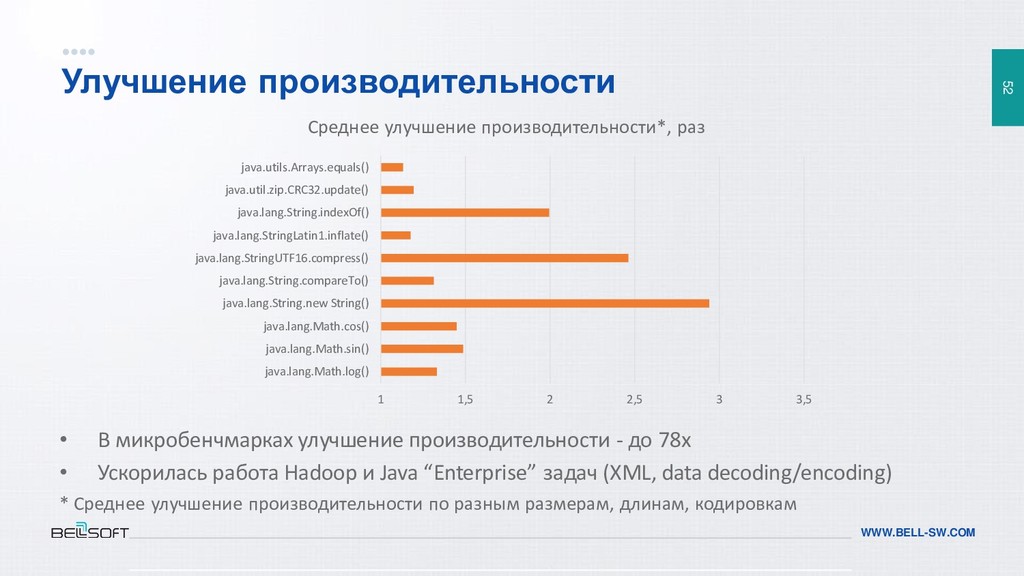{kind=link}
{kind=link}
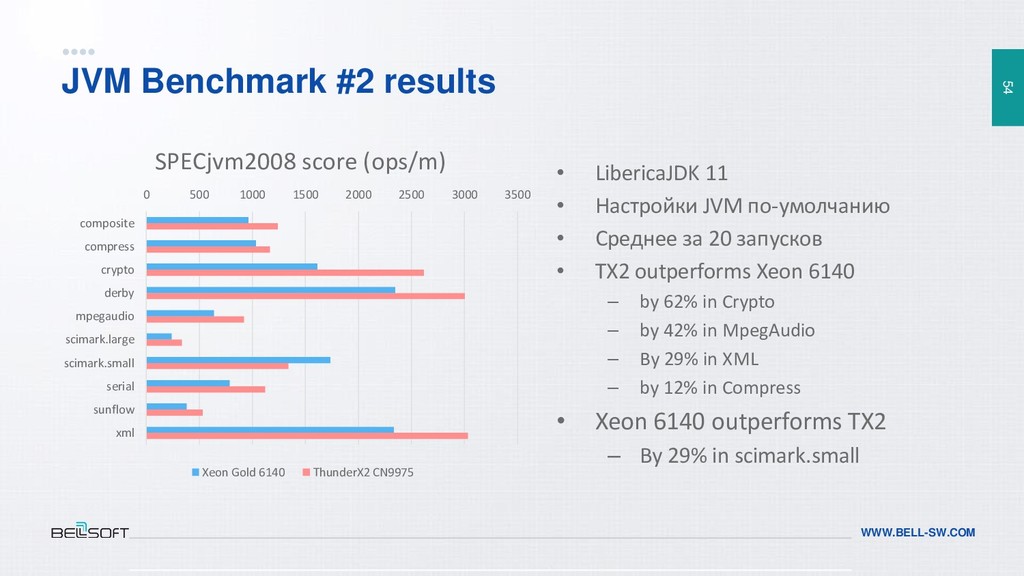{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}