Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
LLM-Readyなデータ基盤を高速に構築するためのアジャイルデータモデリングの実例
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Kashira
December 10, 2025
Technology
0
400
LLM-Readyなデータ基盤を高速に構築するためのアジャイルデータモデリングの実例
2025-12-10 アジャイルデータモデリング事例共有会の発表資料
イベントページ:
https://connpass.com/event/375524/
Kashira
December 10, 2025
Tweet
Share
More Decks by Kashira
See All by Kashira
【PIXIV DEV MEETUP 2024】AirflowのKubernetes移行 ~ Kubernetesで運用するのは思ったより難しくない ~
kashira
0
1.7k
【PIXIV MEETUP 2023】ピクシブのデータインフラと組織構造
kashira
1
5.7k
Other Decks in Technology
See All in Technology
インシデント対応入門
grimoh
7
5.6k
マイグレーションガイドに書いてないRiverpod 3移行話
taiju59
0
330
AWS CDK の目玉新機能「Mixins」とは / cdk-mixins
gotok365
2
290
社内でAWS BuilderCards体験会を立ち上げ、得られた気づき / 20260225 Masaki Okuda
shift_evolve
PRO
1
150
トラブルの大半は「言ってない」x「言ってない」じゃねーか!!
ichimichi
0
220
【2026年版】生成AIによる情報システムへのインパクト
taka_aki
0
190
Interop Tokyo 2025 ShowNet Team Memberで学んだSRv6を基礎から丁寧に
miyukichi_ospf
0
250
dbt meetup #19 『dbtを『なんとなく動かす』を卒業します』
tiltmax3
0
130
Introduction to Sansan Meishi Maker Development Engineer
sansan33
PRO
0
360
What's new in Go 1.26?
ciarana
2
260
フルカイテン株式会社 エンジニア向け採用資料
fullkaiten
0
10k
opsmethod第1回_アラート調査の自動化にむけて
yamatook
0
330
Featured
See All Featured
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
2.3k
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
1.9k
Mobile First: as difficult as doing things right
swwweet
225
10k
My Coaching Mixtape
mlcsv
0
63
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
26
3.4k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.3k
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
1
140
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.2k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
130
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
340
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
1
140
Balancing Empowerment & Direction
lara
5
920
Transcript
LLM-Readyなデータ基盤を高速に 構築するための アジャイルデータモデリングの実例 2025/12/10 pixiv Inc. 新田大樹(kashira)
2 自己紹介 @kashira Data Engineer X: @kashira202111 最近はSQLMeshで遊んだり、ADKで遊んだりしています。 (みんなもSQLMeshを使ってみて)
会社紹介 3 ドメインの異なる20 のプロダクトを展開
4 ピクシブでは内製LLM Agent(kai)を作成しています。 この発表では、kaiが利用するためのデータ整備でアジャイルデータモデリングをこんな 感じで使ったよという事例について話します。 はじめに
5 kaiはピクシブ内製のLLM Agentです。 • 解 (Solution): 問題解決、答えを見つける • 会 (Encounter):
データと人が出会い、新たな知見に繋がる • 開 (Open): 新たなビジネスの可能性を開拓する といった目的のために作られました。 kaiとは?
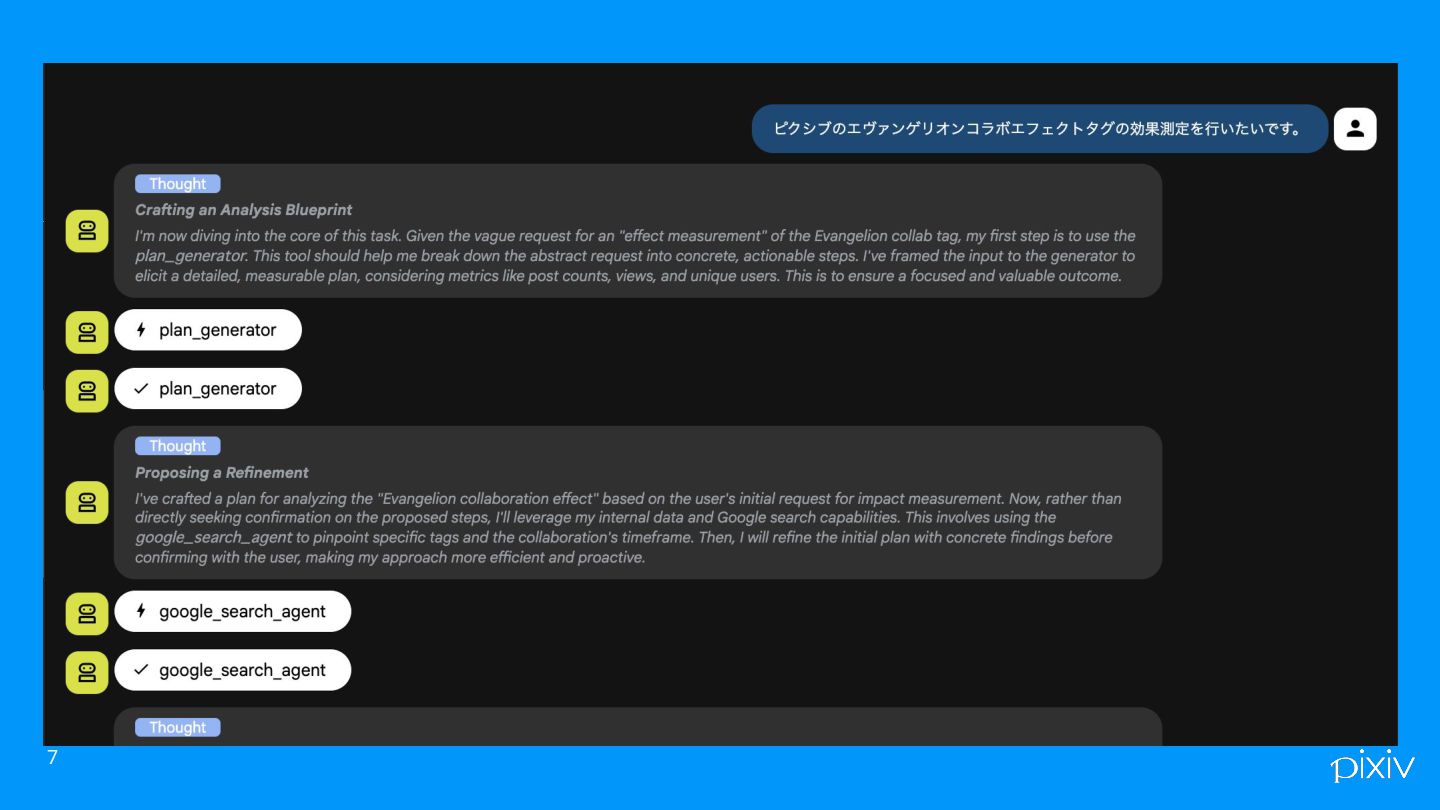
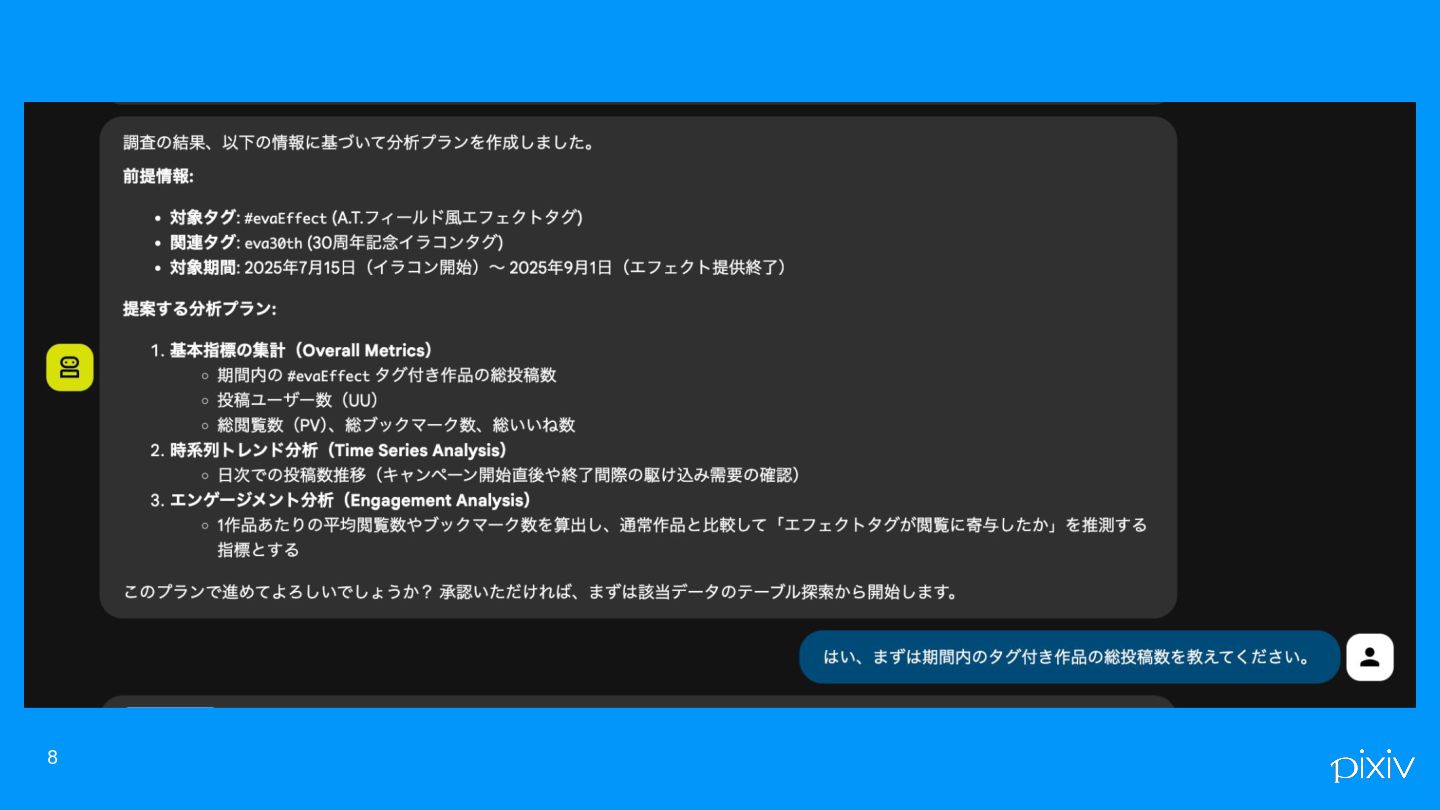
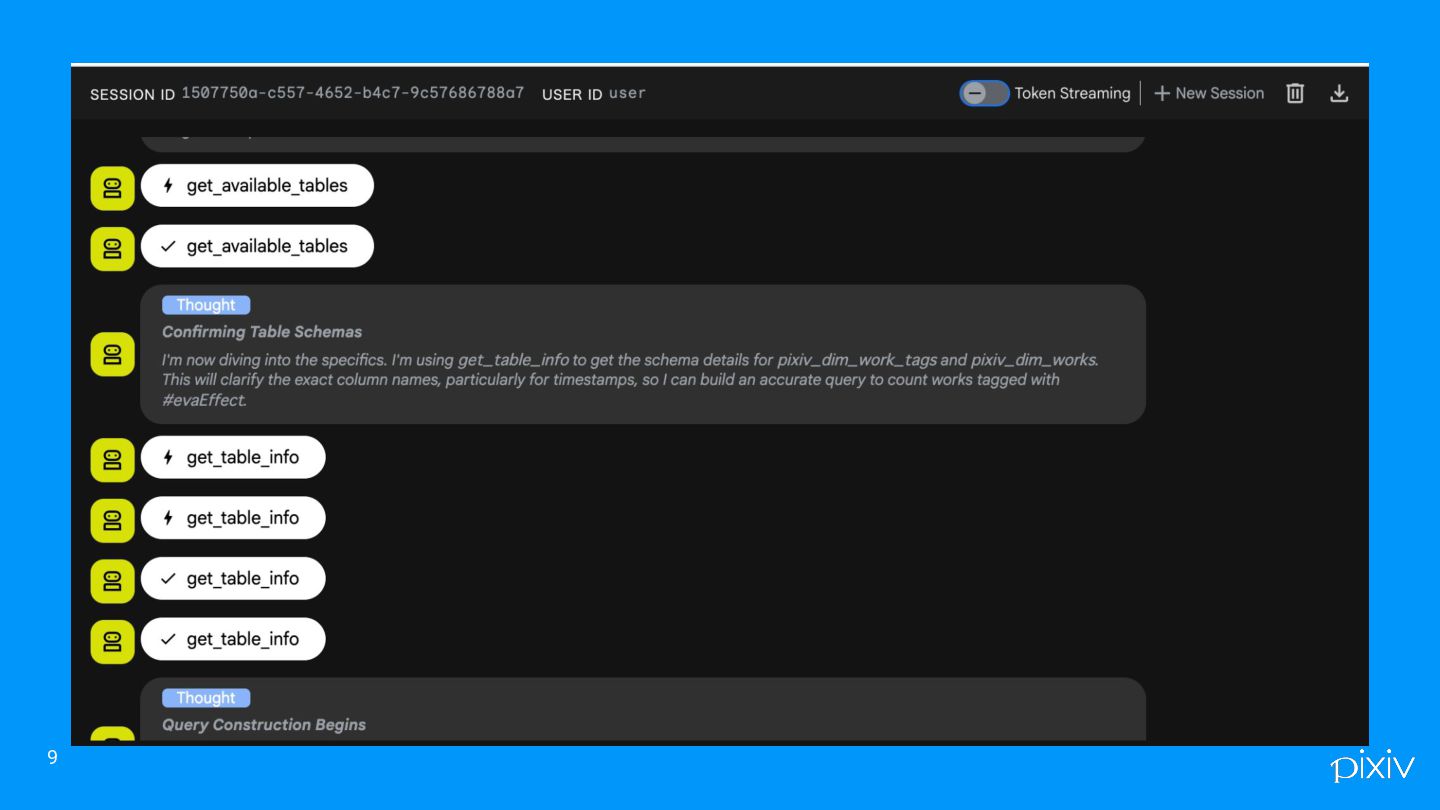
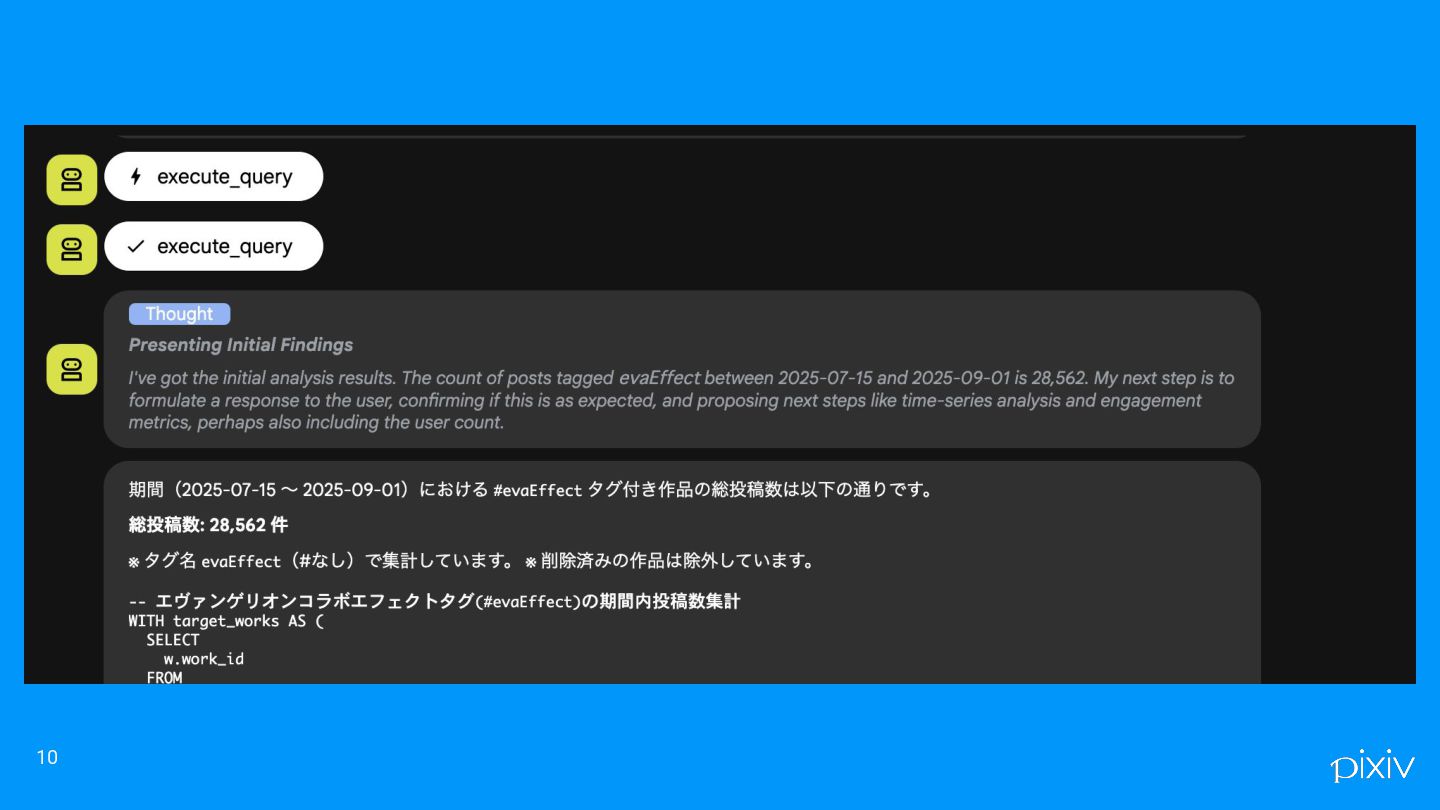
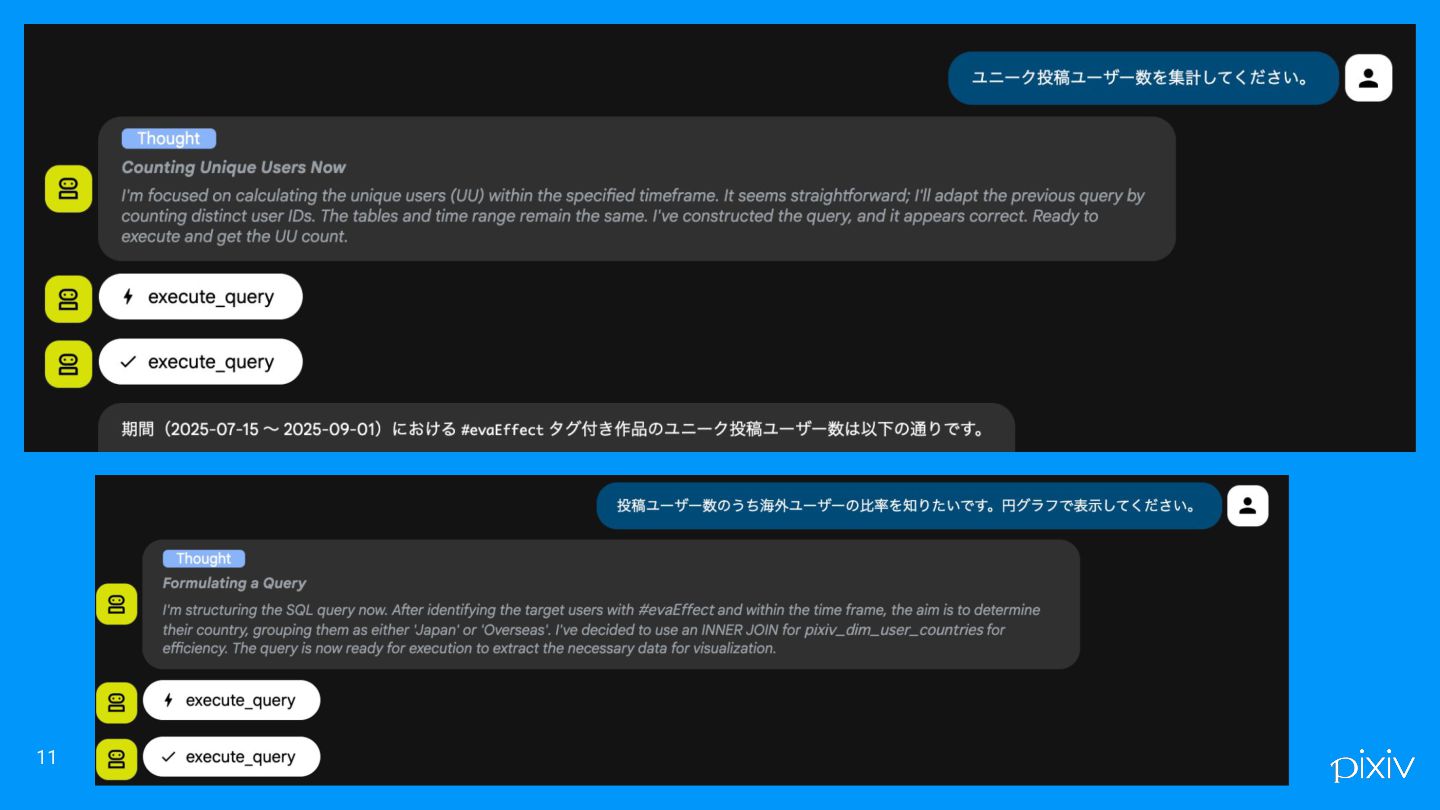
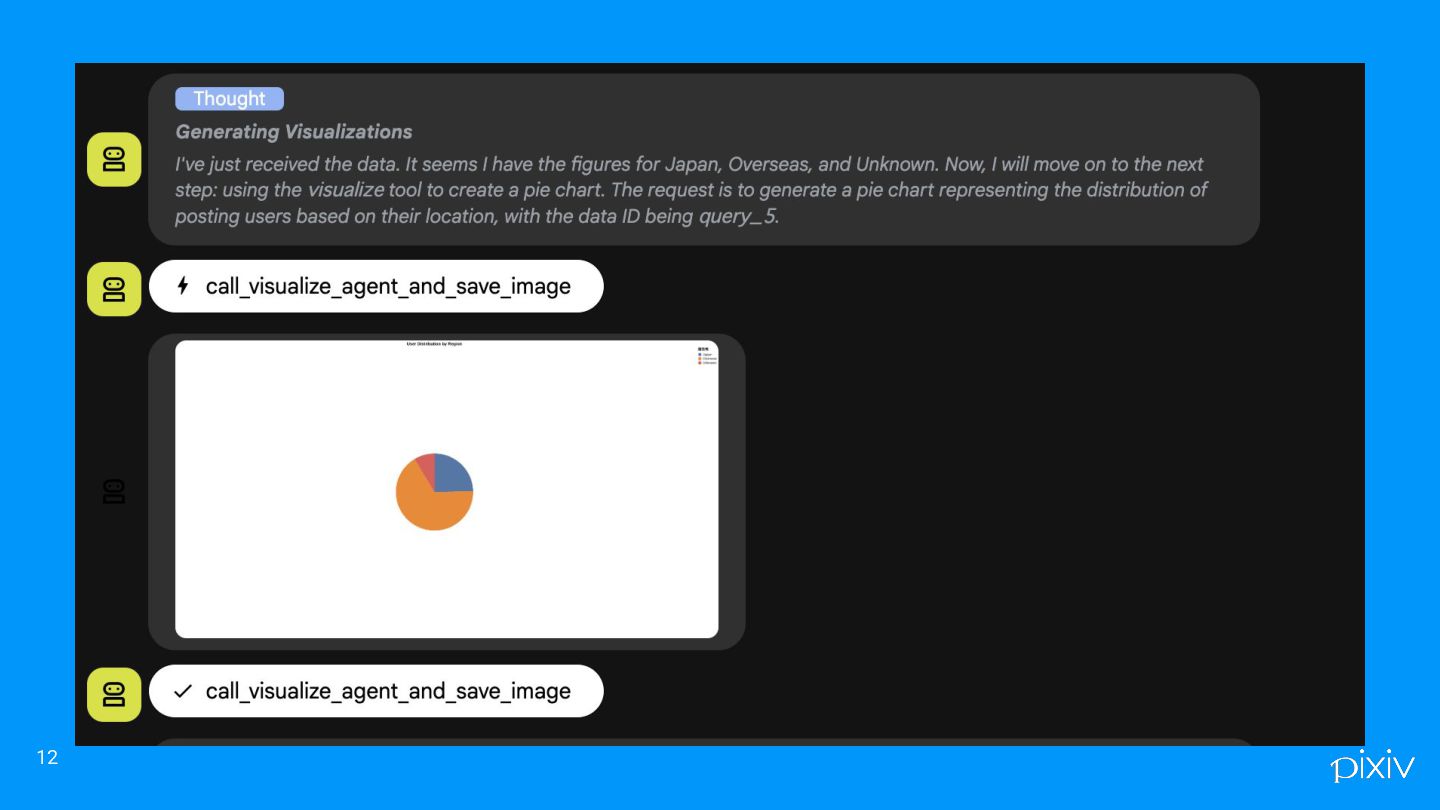
kaiのデモ これくらいなら安定して出せるという例 6
7
8
9
10
11
12
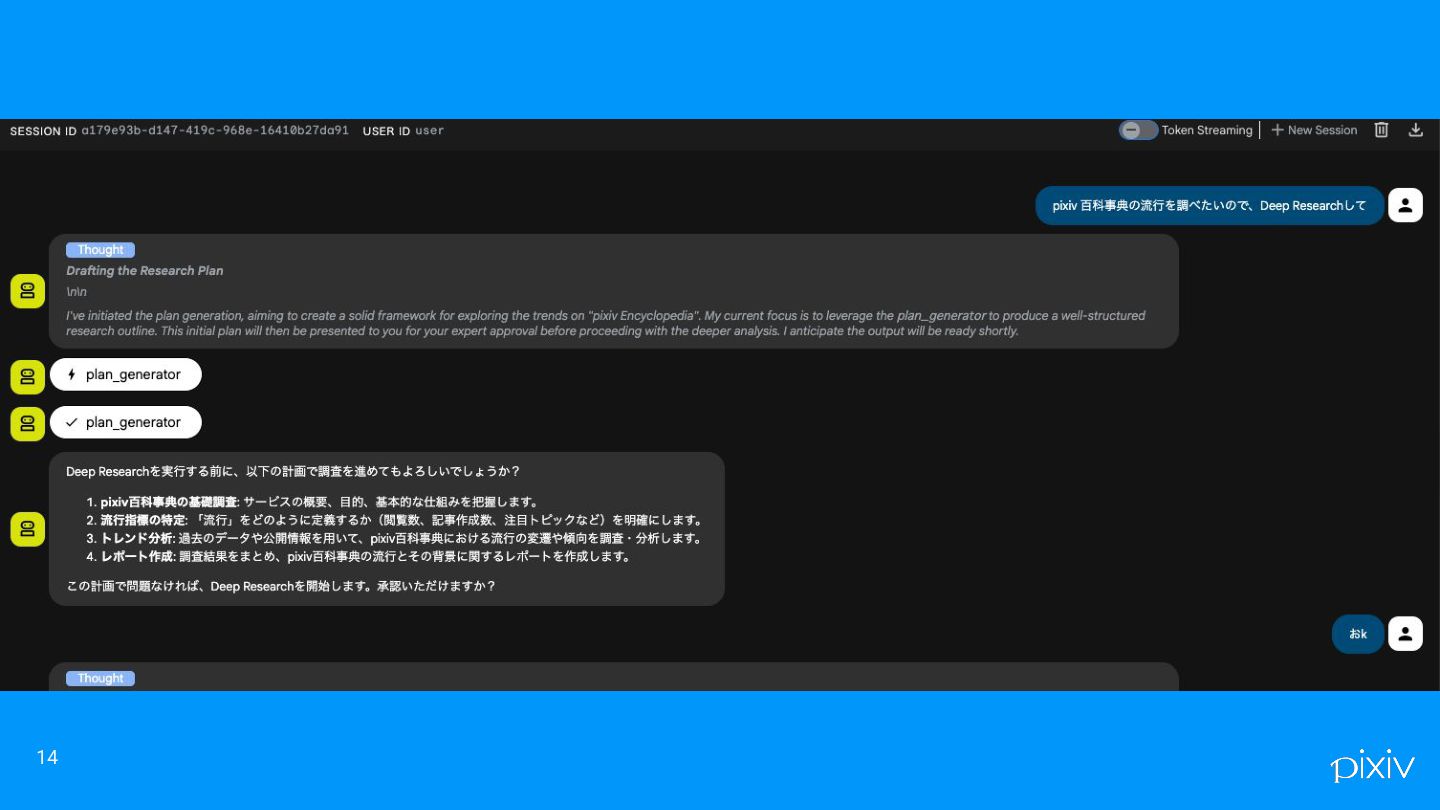
kaiのデモ 安定していないけど、社内版のDeep Researchを使ったパターン. 13
14
15
16
17
kaiが可能にしたビジネス的な成果 これらの分析を非エンジニア・非専門職が行えるように 1. ユーザージャーニーを広く調査する (1日->30分) 2. PdMが自分で数値分析をしてレポートを書く 3. 新しいマーケットの調査 a.
今までマーケターが1人で出来なかった分析が可能に 4. クエリの制作時間の作成 a. 複雑なクエリを書くのが面倒なので、それのdraftを作ってもらう b. Draftに30分かかるようなクエリもすぐに出力される 18 現在はDAUが10人程度の活発度です(限定公開中だが)
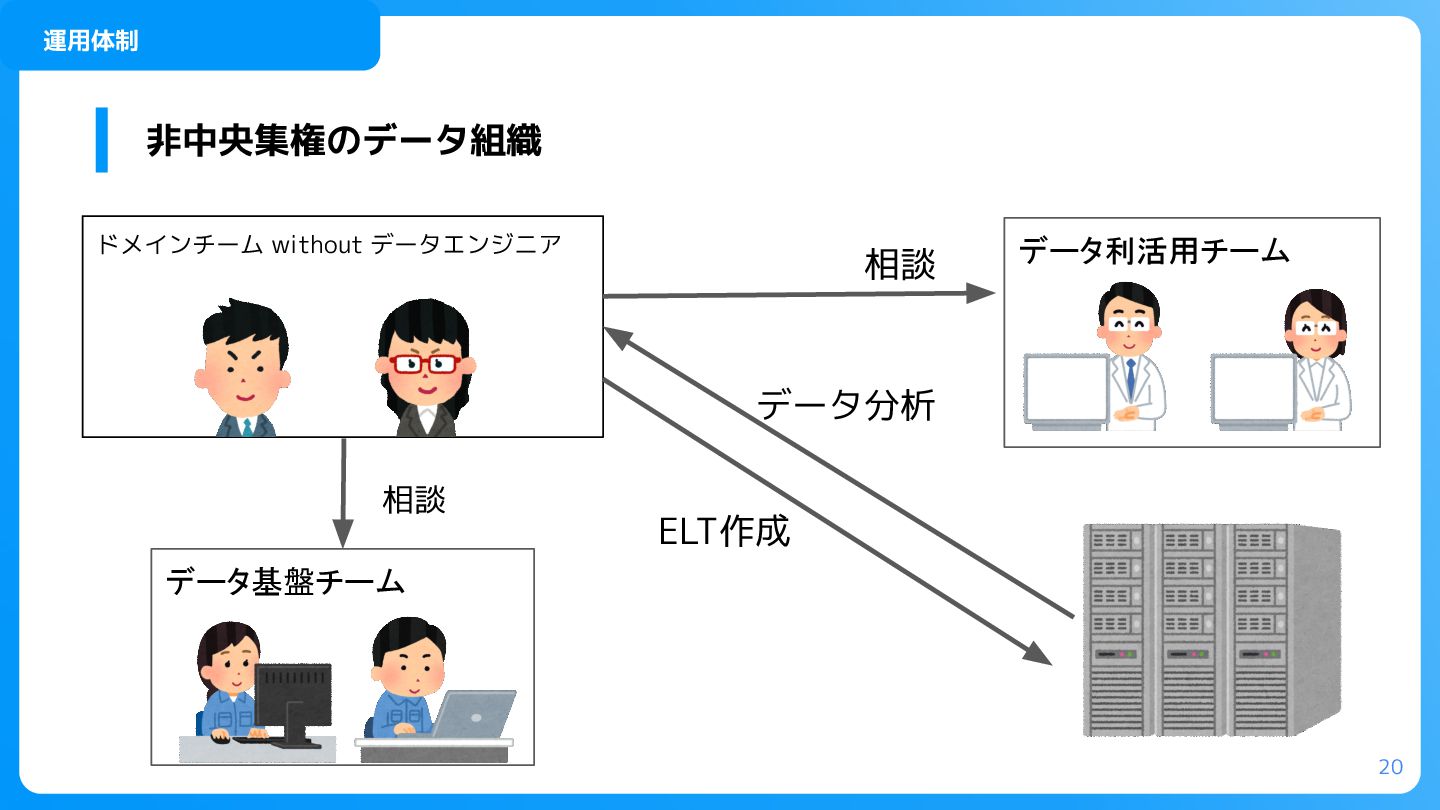
kaiが生まれた背景 弊社では立ち上げ時から、非中央集権のデータ整備で運用していました。 これはデータ基盤の立ち上げ当初から、プロダクト数が多く、中央のデータ組織で全 ての分析要件を満たすのは難しいという判断です。 19 なんちゃってData Mesh (プロダクトとしてのデータ品質の保証はされていない)
20 非中央集権のデータ組織 ドメインチーム without データエンジニア データ基盤チーム データ利活用チーム ELT作成 データ分析 相談
相談 運用体制
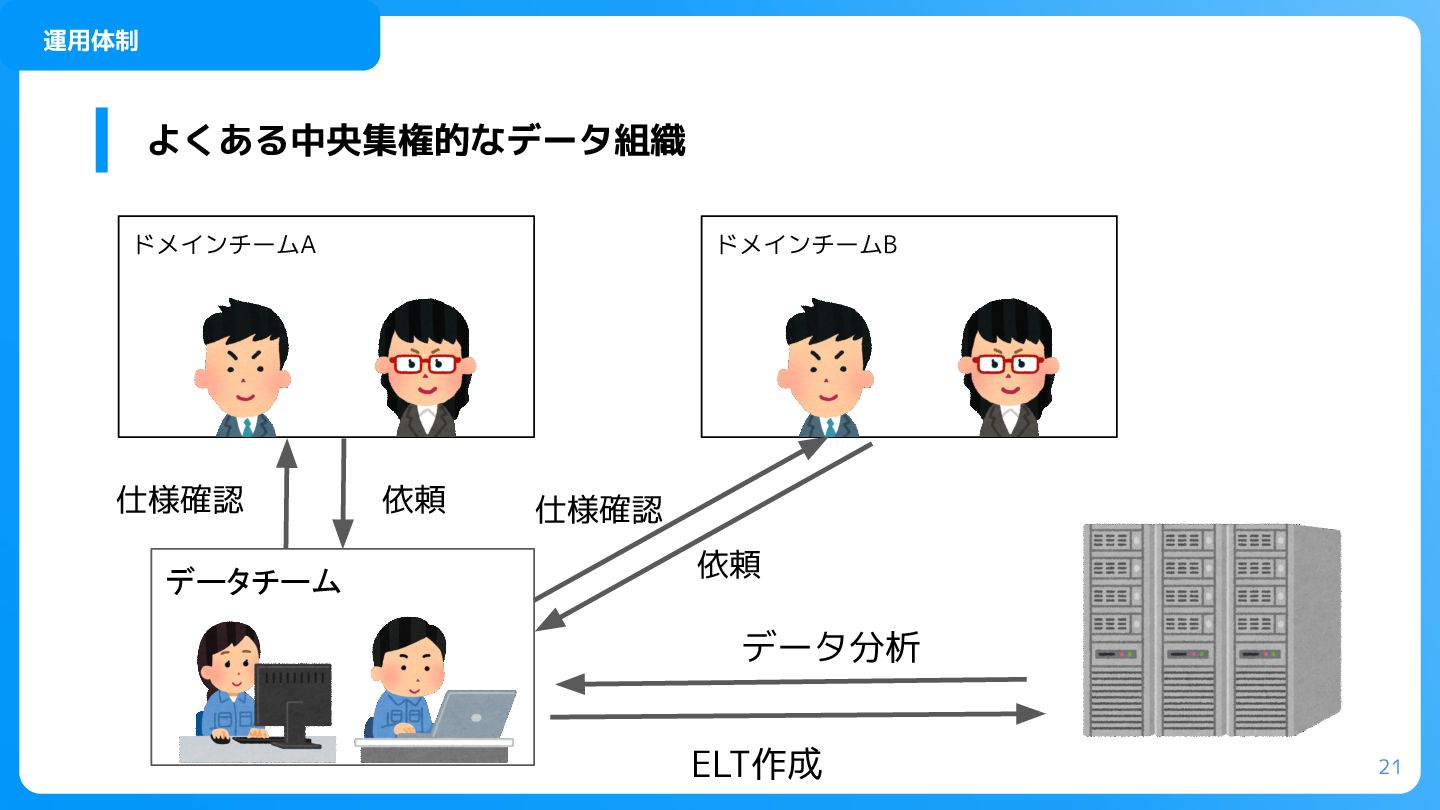
21 よくある中央集権的なデータ組織 ドメインチームA データチーム ELT作成 データ分析 仕様確認 依頼 運用体制 ドメインチームB
仕様確認 依頼
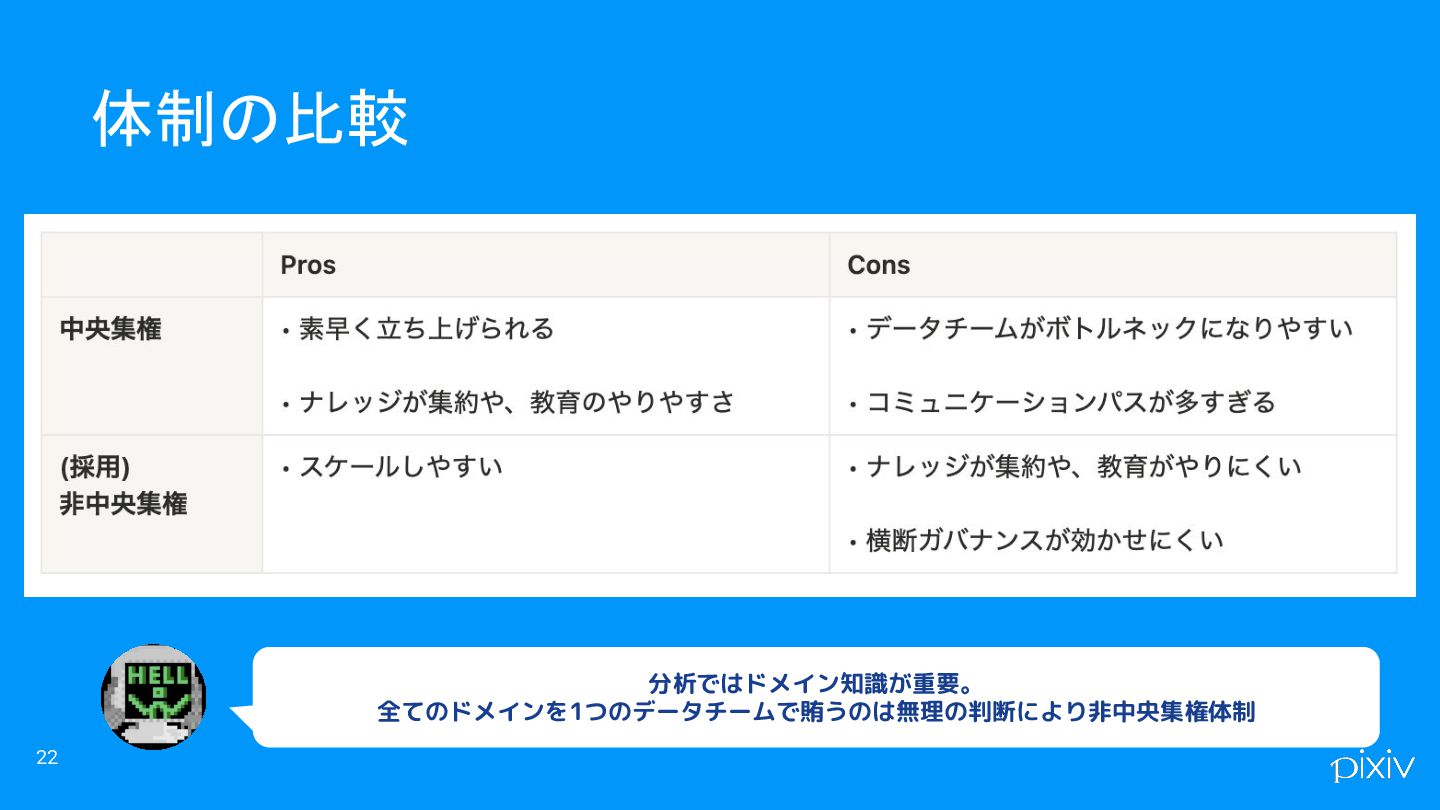
22 体制の比較 分析ではドメイン知識が重要。 全てのドメインを1つのデータチームで賄うのは無理の判断により非中央集権体制
23 • 非エンジニアのメンバーが分析をするハードルが高い ◦ エンジニアが多い会社で、PdMもエンジニア上がりの人も多い ◦ データが分かりやすい状態で整備されていない • マルチプロダクトを横断して分析するハードルが高い ◦
横断でデータを整備する動きがあまり発生していない ◦ それぞれが局所最適かつ、ディメンショナルモデリングも分からない状態で データ整備がされる ◦ MartとSourceはあるけどDWHは無いになりがち • プロダクトによって利活用の差が大きい 現行の体制での課題
LLM Agentってやつで解決出来ないか? (part1) 24 とりあえずAgentを試してみる Looker Conversational Analytics
LLM Agentってやつで解決出来ないか? (part1) 25 結果: ダメでした
LookerはURLでディメンションや フィルタ、可視化の状態を指定できる
LookerのConversational Analytics • 悪くはないけど、LookMLも汚い状態でどれが正しいのか?LLMは判別 できない ◦ マルチプロダクト故に、同じような定義がそこらじゅうにある • セマンティックレイヤでの制約は柔軟性が低い ◦
全てのカラムが繋ぎ込まれていないと動かない ◦ 例えば、 ▪ pixiv閲覧Exploreでは、user_idをキーに閲覧が分析できる ▪ BOOTH注文 Exploreでは、user_idをキーに注文を分析できる ▪ これを合わせた分析が不可能(SQLならjoinするだけ) • Looker特有のコンテキストを覚えさせるのが大変 ◦ fieldsでカラムを指定してとか、visには何があってみたいな 27
(Optional) Conversational Analytics での取り組みはここから見てください. https://cloudonair.withgoogle.com/events/gemini-at-work-data-24-jp 28
LLM Agentってやつで解決出来ないか? (part2) 29 既存の製品でダメなら、 LLM Agentを内製しよう!!
LLM Agentってやつで解決出来ないか? (part2) 30 データ整備がちゃんとされていないのに、まともに動くはずがない 結果: ダメでした
初期のLLM Agent BigQueryにある全てテーブルからクエリを生成させようとした。 出てきた課題 • テーブルの選択が間違っている(テーブル名は適当です) ◦ pixiv.user, pixiv.user_with_deleted, hub.user
◦ どれを使えば良いのか分からないから、無難にpixiv.userを使う • Sample値が分からないのでfilterが上手くいかない ◦ work_typeのdescが、work_type: 作品タイプ だけ ◦ 中身が分からないから、work_type = ‘イラスト’など適当にフィルタする • Joinのキーがおかしい ◦ Uniqueが分からないので、ファンアウト引き起こしやすい ◦ 全然違うカラムで結合しようとする 31
当初のLLMの出力: user_idごとにイラスト・漫画の合計作品数を教えて 32 LLMの出力結果 期待している回答
LLM Agentってやつで解決出来ないか? (part3) 33 アプローチを変えて、 整備済みのデータからのみ クエリを生成させよう
LLM Agentってやつで解決出来ないか? (part3) 34 結局はデータ整備 結果: 上手くいった!!🎉
成功したLLM Agent 上手くいった点 • テーブルの選択は大体成功する • クエリもまあまあ成功する ◦ どれだけテーブルからコンテキストが得られるか次第で大きく変わるけど 出てきた課題
• LLMが使えるレベルのテーブルが圧倒的に足りない ◦ 既存で整備されているテーブルでも、Descriptionやサンプル値の不足、テーブル利用 時の注意点が分からないなどLLM-Readyではない 35
LLM Agent構築のまとめ 36 限定的なテーブルに絞るアプローチを採用することで、実運用に耐えられるように
本題: アジャイルデータモデリングの実例 37
データ整備を0から始めなければ • 非専門家のデータ整備では、LLMが使えるレベルのデータにならない • 中央集権的にデータの専門家がデータ整備をする必要性が出てきた ◦ プロダクト固有のデータはプロダクトが管理 ◦ Tierが高い、経営的な関心が高く、他部署でも頻繁に見たいプロセスはデータ基盤チームで 汎用的に整備
• データ整備は中核の業務領域、Agentの作成は一般的な業務領域(ドメイン駆動設計) 38 中央集権と非中央集権のハイブリッドなデータ整備体制
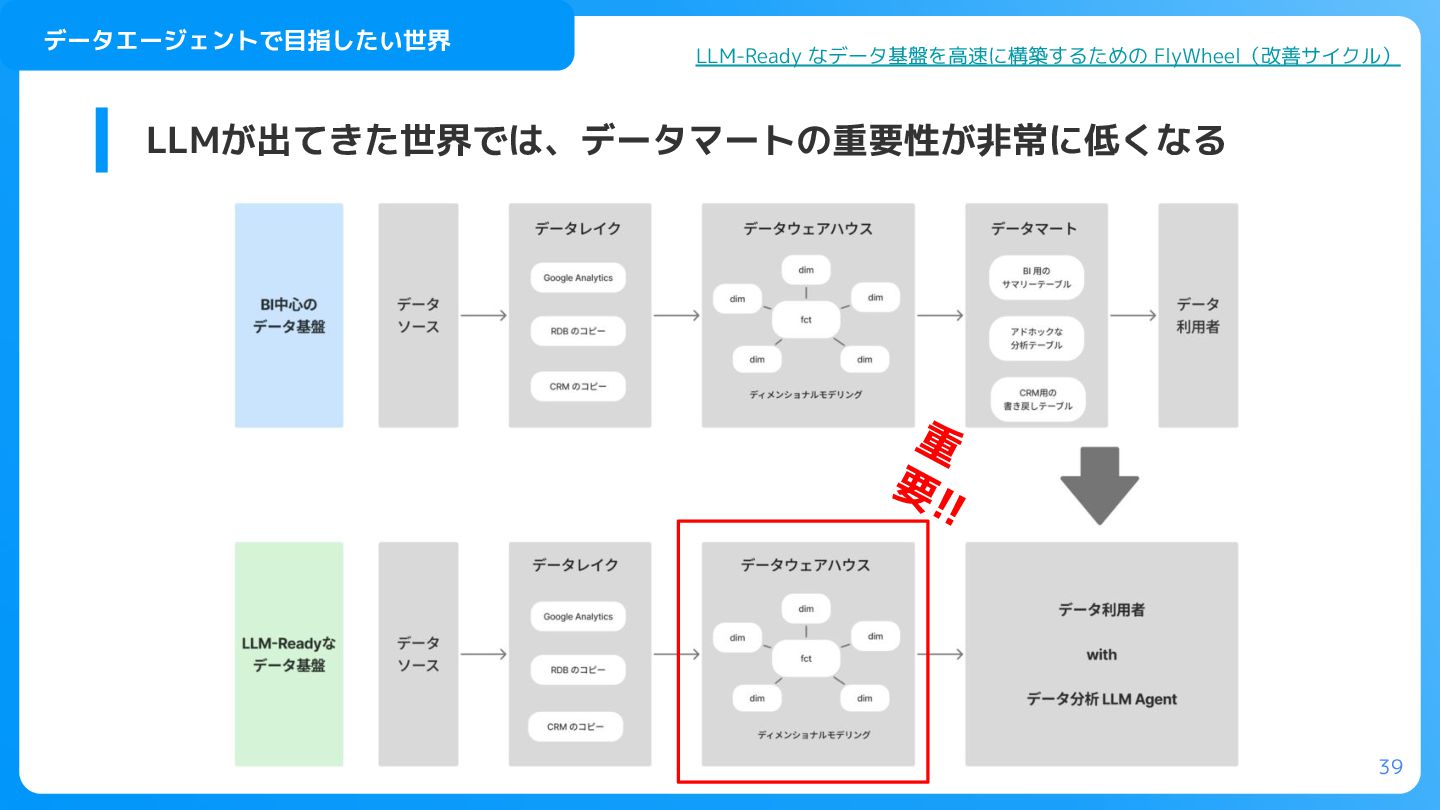
39 LLMが出てきた世界では、データマートの重要性が非常に低くなる データエージェントで目指したい世界 LLM-Ready なデータ基盤を高速に構築するための FlyWheel(改善サイクル) 重 要!!
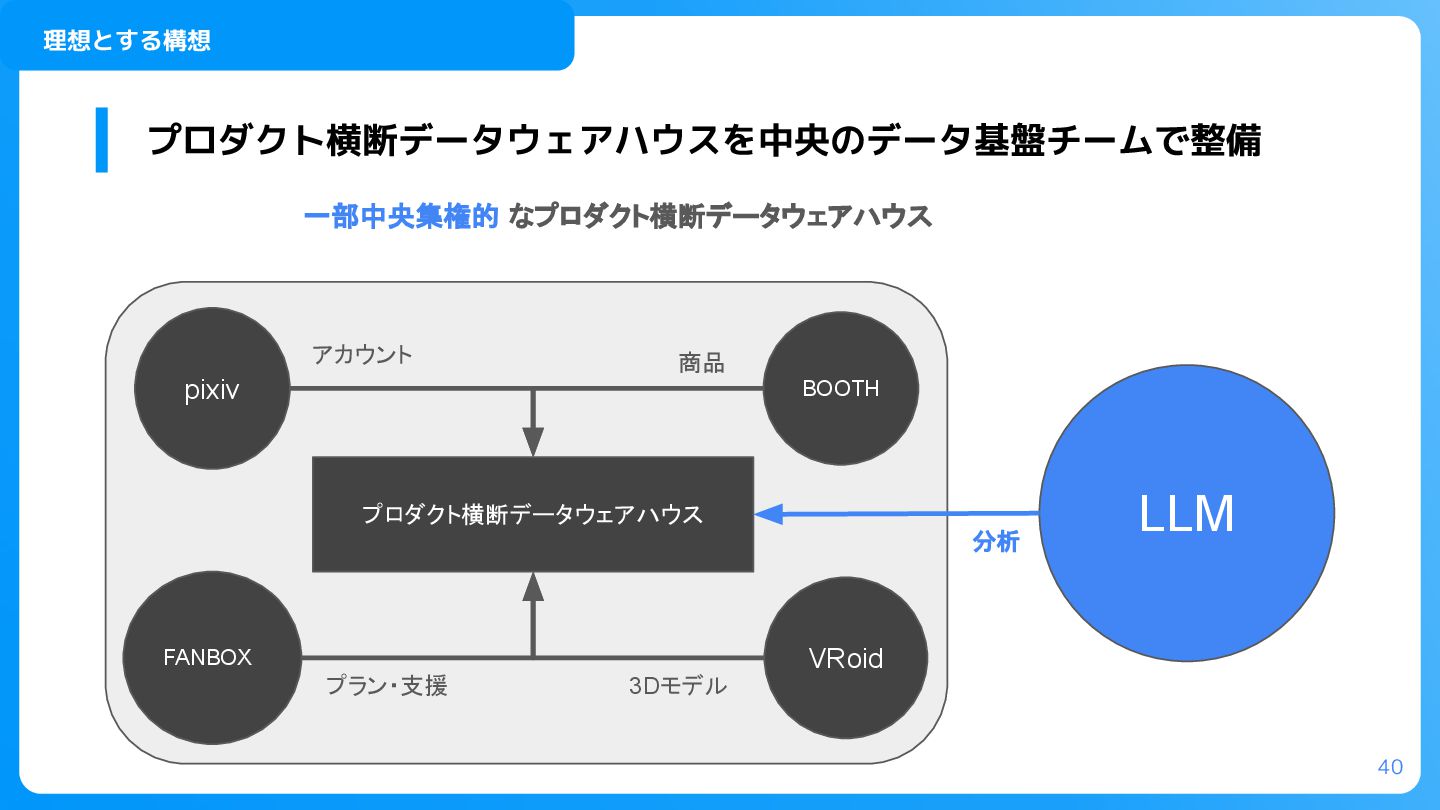
40 プロダクト横断データウェアハウスを中央のデータ基盤チームで整備 戦略③次世代を見据えた新たな価値提供 理想とする構想 一部中央集権的 なプロダクト横断データウェアハウス プロダクト横断データウェアハウス pixiv FANBOX BOOTH
VRoid 3Dモデル アカウント プラン・支援 商品 LLM 分析
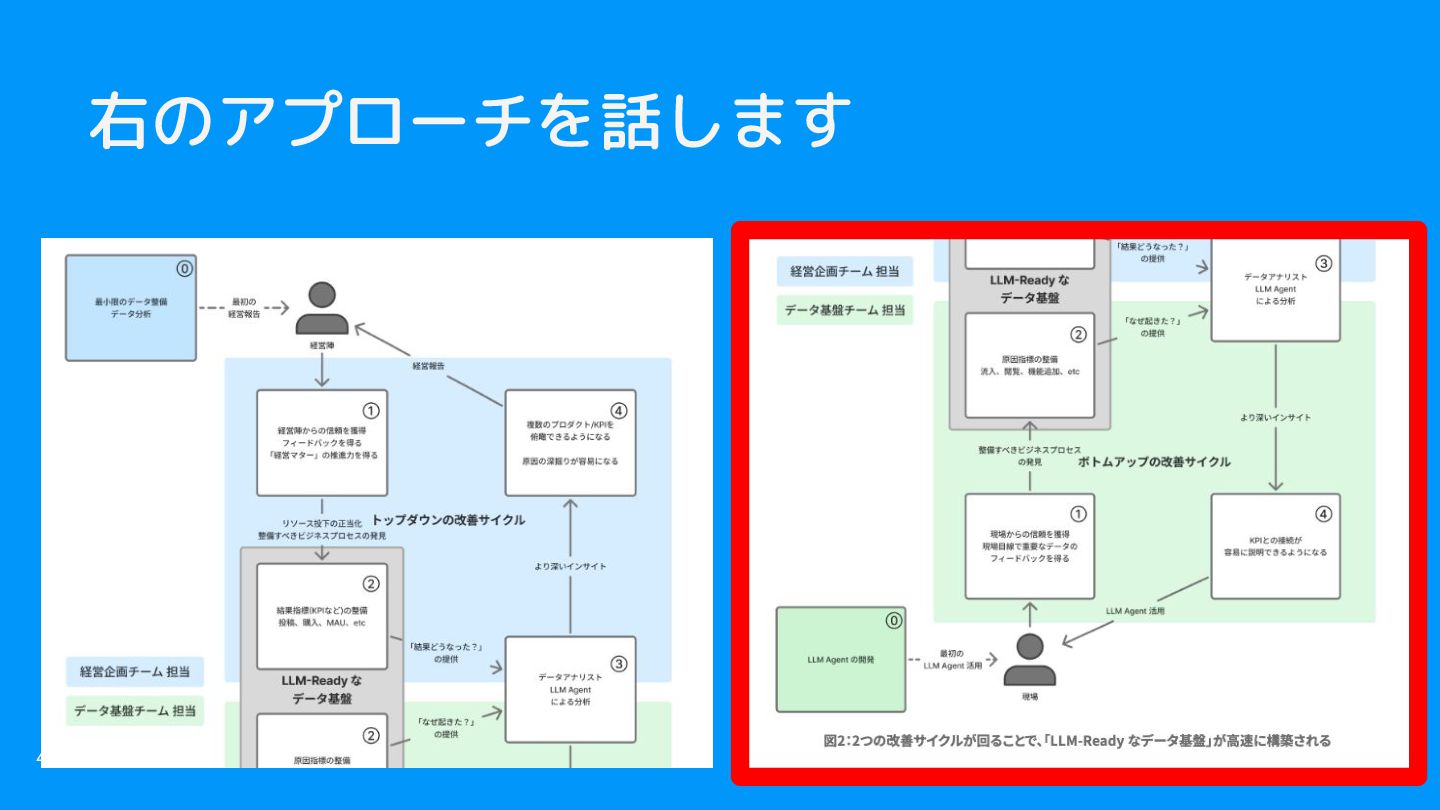
どこから手をつければ良い? • どのビジネスプロセスから手をつければ良いのか分からない • 「トップダウン(経営報告)」と「ボトムアップ(現場活用)」の2側面があり そう • まずは独断と偏見でデータ分析に困ってそうな2部署にヒアリングを開始 41
右のアプローチを話します 42
ヒアリングの仕方も分からないなぁ 43 アジャイルデータモデリングで分かるよ
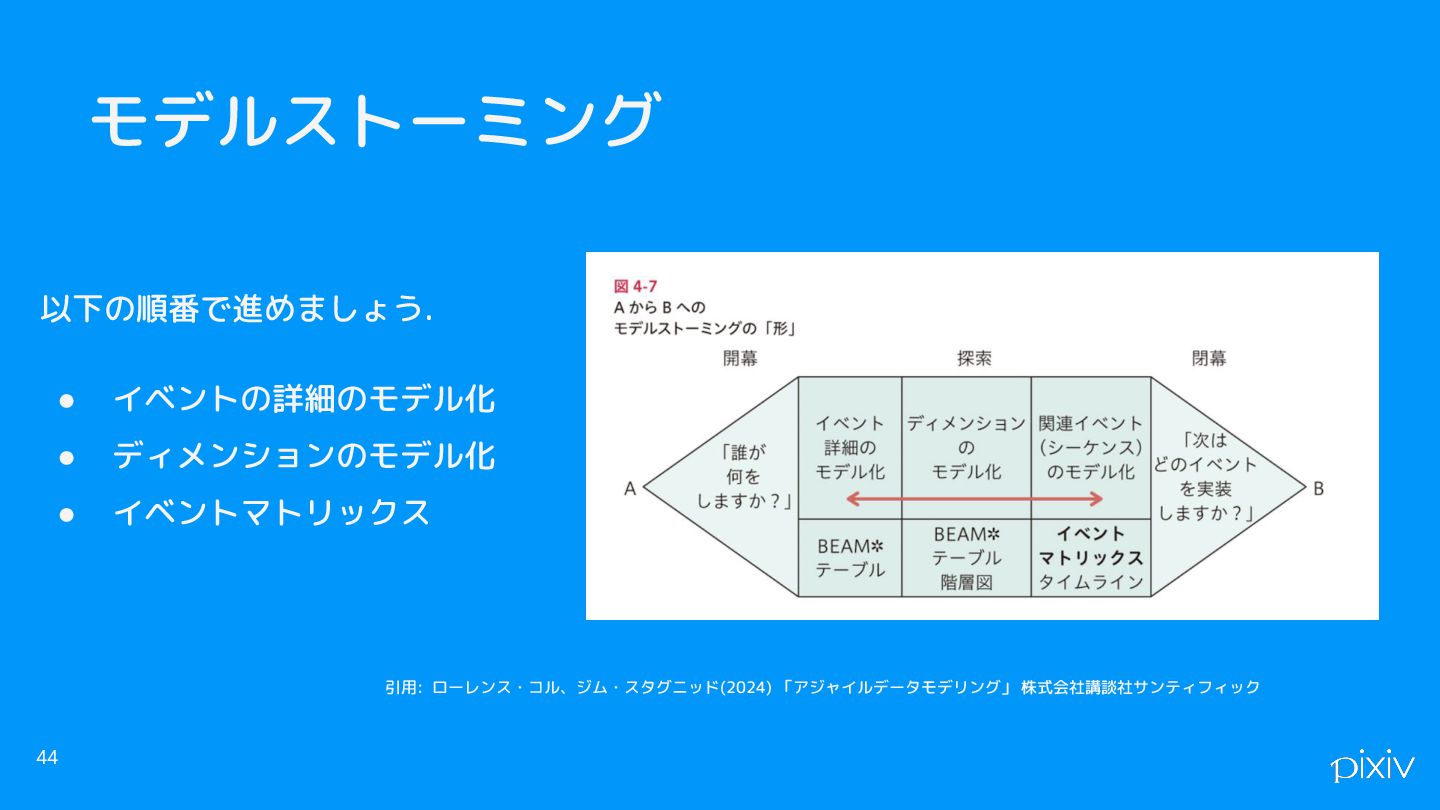
モデルストーミング 以下の順番で進めましょう. • イベントの詳細のモデル化 • ディメンションのモデル化 • イベントマトリックス 44 引用:
ローレンス・コル、ジム・スタグニッド(2024) 「アジャイルデータモデリング」 株式会社講談社サンティフィック
イベント詳細のモデル化 週1で30分かつ、4部署合同なため、かなり簡略化しました。 • 3Wがメイン (Where, Who, What) ◦ 弊社はプロダクトごとに見ることが多いので、Whereで絞ってあげてWho, Whatの方
が答えやすい。今回は特にプロダクト横断の部署とのやり取りだったので。 ◦ ここで得られた回答から、残りの要素で気になることがあれば質問する • BEAMテーブルは使っていない ◦ これは力量不足 ◦ Sample値を書き出す時間がなかなか取れない ◦ 今思うと、LLMで生成すればもう少し良い感じかも 45 力不足な所もあると思うが、今回のケースは3Wあればデータ整備の優先度付けには十分だった。 モデルの一貫性や完全性が担保されていないが、すでに存在しているものがベースに作業。
ディメンションのモデル化 • 今回はスキップ • すでにモデル化されたものを利用した ◦ 履歴に関しては、ほぼscd type1で進めている(たまにscd type2) ◦
階層に関しても複雑な階層を扱うケースはそこまで多く無かった ▪ BOOTHのカテゴリくらい ▪ ucchi-先生がやってくれた 46
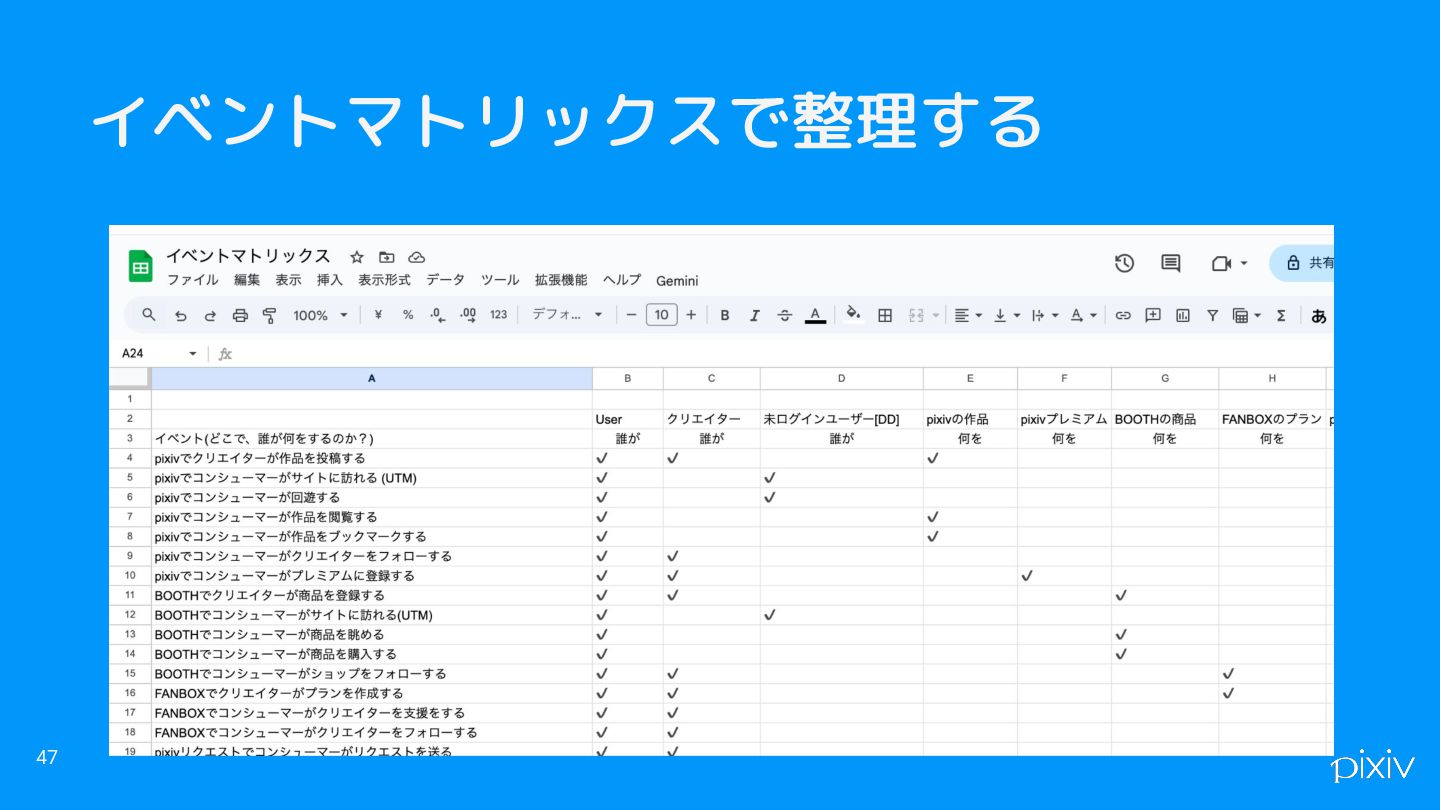
イベントマトリックスで整理する 47
優先度を決める • 現場が欲しいデータの優先度 ◦ 書籍で紹介されているように、dimはプロセスより高得点になる • 実装の難易度・提供の速度 ◦ 早く価値を出すほど、相手からのフィードバックも多い ◦
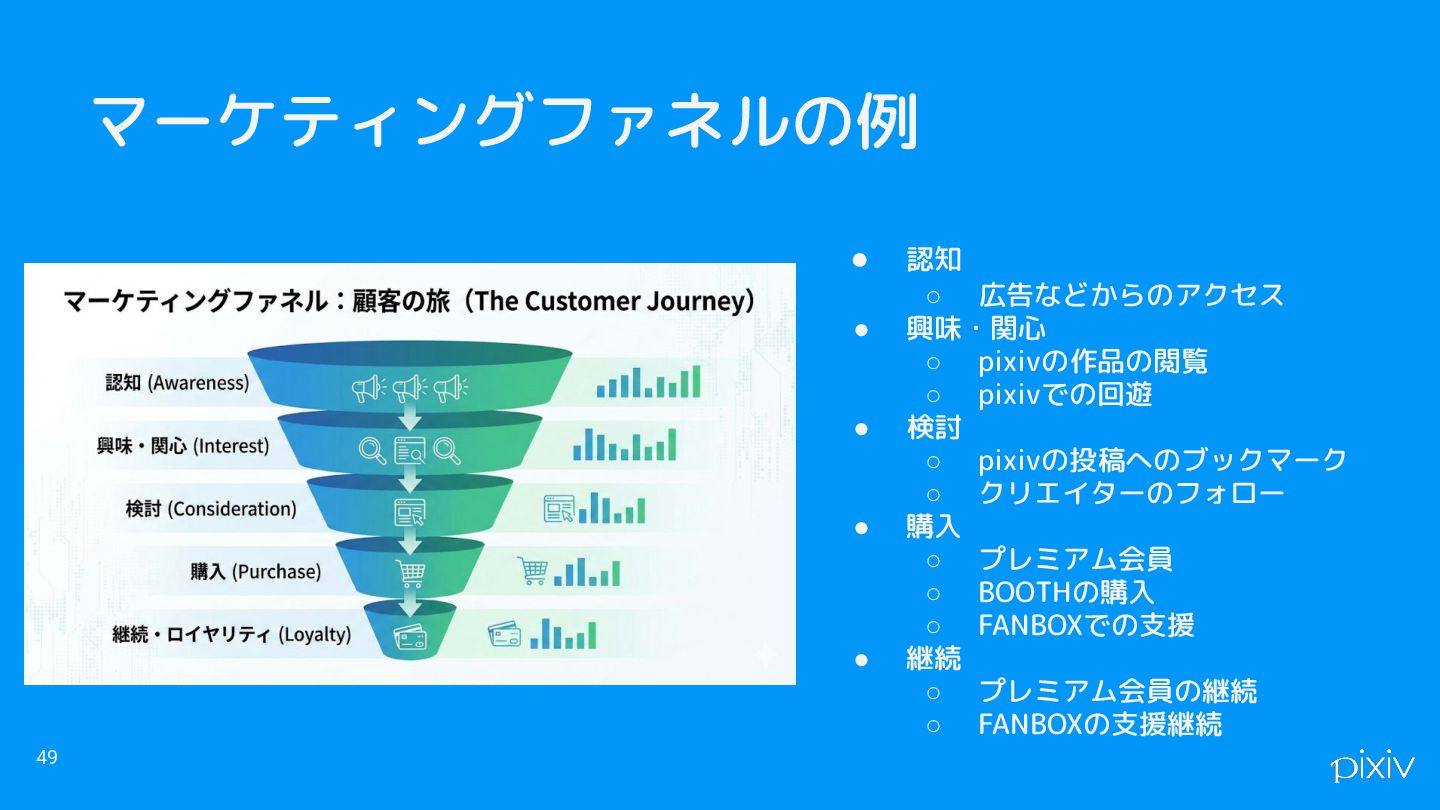
信頼してもらうために、実装が簡単なプロセスを実装するのも大事 • 入り口・出口までを意識する ◦ マーケティングファネルが参考になった 48 正解はないので、チームの事情に合わせてバランスよく取り組むと良い. 私の場合は、実装が簡単なタスクを1つ、実装が難しいが現場が欲しいデータ関連を1つ 並行して進めることが多かった
マーケティングファネルの例 • 認知 ◦ 広告などからのアクセス • 興味・関心 ◦ pixivの作品の閲覧 ◦
pixivでの回遊 • 検討 ◦ pixivの投稿へのブックマーク ◦ クリエイターのフォロー • 購入 ◦ プレミアム会員 ◦ BOOTHの購入 ◦ FANBOXでの支援 • 継続 ◦ プレミアム会員の継続 ◦ FANBOXの支援継続 49
実装時の工夫(part1) • dbtのdata testの充実 ◦ Unique, Not Null, Accepted Value,
Relationshipは可能な限り設定 • BigQueryのDescriptionにメタデータを寄せる ◦ データカタログ製品にメタデータを登録すると呼び出しツールが増えるので、精度が 悪くなる(トークン量も増える) ◦ schemaを見せるだけでクエリがかける状態に持っていく ◦ カラムのType(FK、PK), Sample Value(特にSTRING)など 50
51 dbt configのサンプル
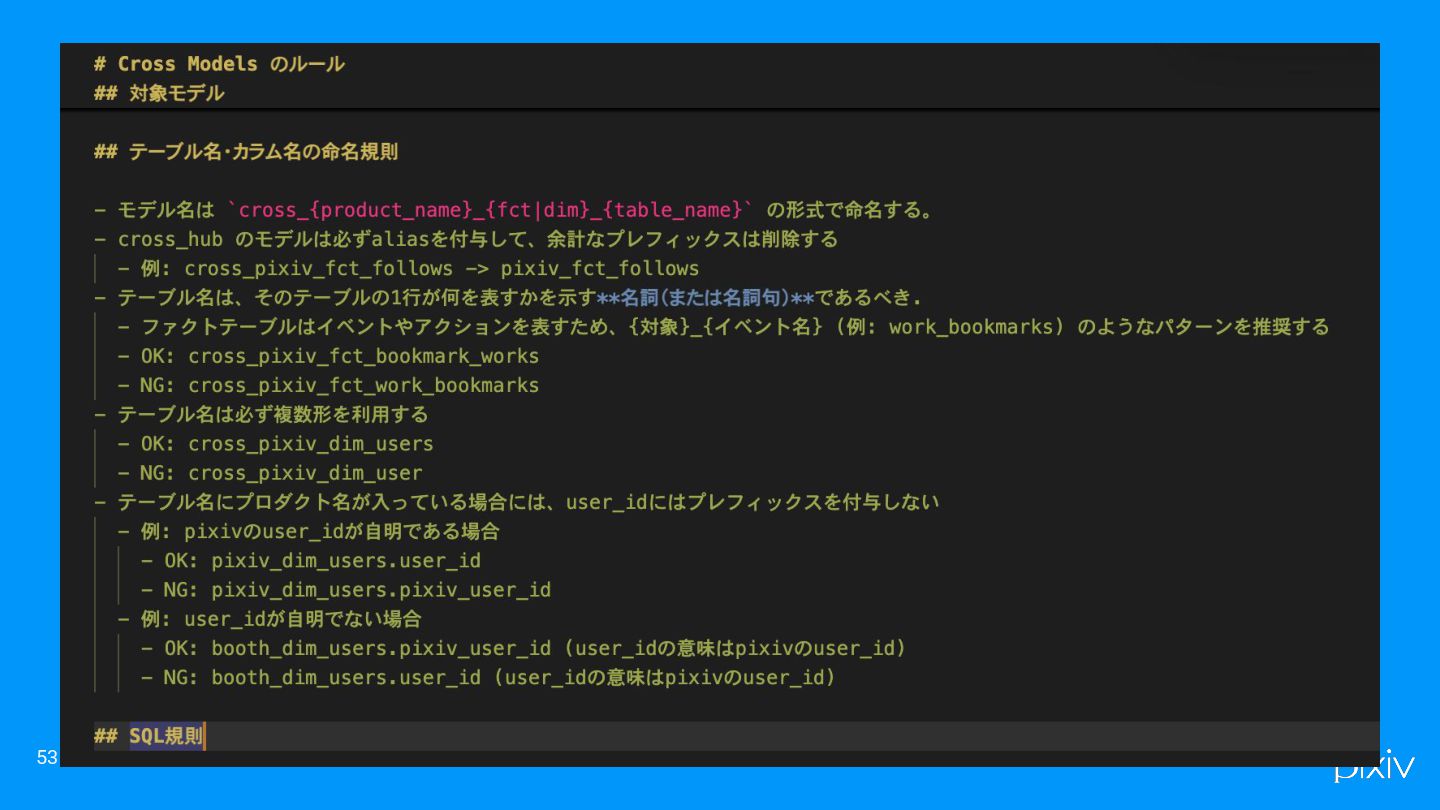
実装時の工夫(part2) • マルチプロダクトのテーブル・カラムの命名規則を決める ◦ user_idと指すものは、どのプロダクトのuser_id? • レビュー・開発の効率化 ◦ 命名規則や、メタデータで生成する型をgitのdocに保存して、LLMに助けて貰う ▪
テーブル名・カラム名 ▪ SQLの変換の規則 ▪ testの規則 ▪ など 52
53
改善後のLLMの出力: user_idごとにイラスト・漫画の合計作品数を教えて 54 期待している回答 LLMの出力結果 整備済みのデータであれば基礎的なクエリは、ほぼ完璧に出せる
結果: 改善後の出力の話 • ⭕ ビジネスプロセスのカバレッジが大幅に上がった • ⭕ 社内でもkaiのLLM Agentはすごいと声をいただけた ◦
経営層からもデータ整備の重要性を認識して貰えている • ❌ ドメイン特化で使うには課題があり ◦ 例えば、BOOTHチームのみが知りたいデータは出せない(整備が追いつかない) ▪ ショップの振り込み履歴の有無 ▪ ショップのニュースの受け取り設定 • ❌ 非構造なデータ周りが非常に弱い ◦ 社内の分析の知見や、ビジネスモデルの繋がりなどをAgentが認識できていない • ❌ 想定よりクエリレビューの依頼が来ないので不安 ◦ 社内向けには、本調査の前段階で使うこと想定していると伝えている 55
将来の構想 • LLM-Readyなデータ整備をスケールさせる • LLMそのものの使いこなし力を上げる ◦ 思ったより、使いこなせていない人が多いので、基礎力向上も必要 • 過去の分析結果などの非構造化データの取り扱い 56
まだ答えを見つけれていないので、懇親会で話せると嬉しいです!
最後: まとめ • LLM Readyな世界ではDWH層のモデリングの重要度が上がっている • DWH層のモデリングはアジャイルデータモデリングを参考に実装すると筋が良い ◦ 今回は話さなかったけど、デザインパターンも豊富 •
どこに何のデータを、どのように保持するか?もデータモデリング一環で考える 重要性が高まっている ◦ 精度はコンテキストに左右される 57
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}