(x0 =250, y0 =320), (x1 =251, y1 =320), . . dog (xmin ,ymin ) = (240, 280), (xmax ,ymax )= (300, 350), object detection image classification dog image captioning A dog running on a grass VQA Q. What is the dog doing? A. running
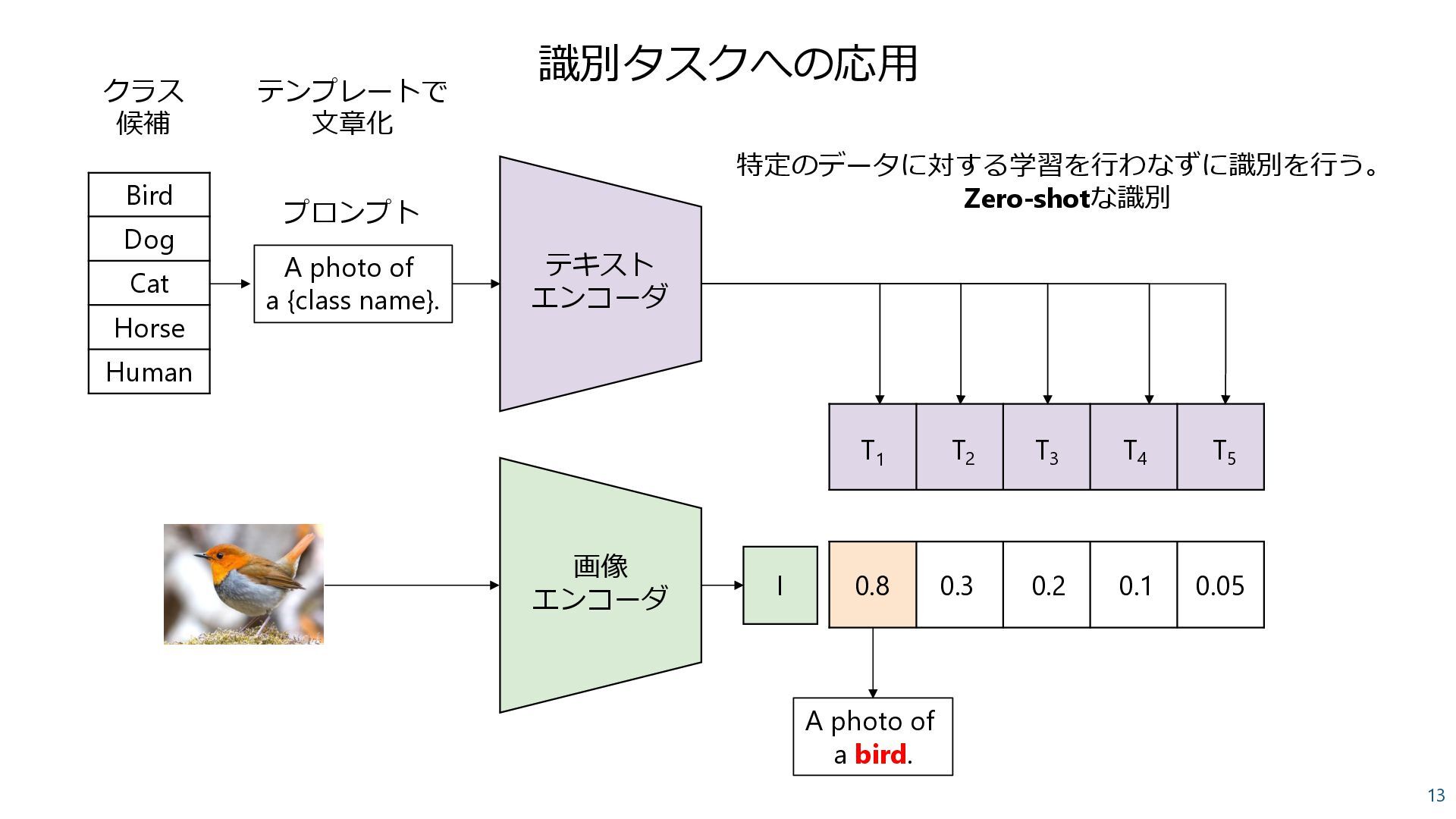
Human A photo of a {class name}. T1 T2 T3 T4 T5 I A photo of a bird. クラス 候補 テンプレートで 文章化 特定のデータに対する学習を行わなずに識別を行う。 Zero-shotな識別 プロンプト 0.8 0.3 0.2 0.1 0.05
2021], BLIP [Li et al., 2022], by Salesforce – CoCa [Yu et al., 2022] by Google 17 https://visualqa.org/ Visual Question Answer (VQA) Image Captioning A man surfing in sunny day
a <mask> sleeping in bed dog Masked Language Modeling (MLM) ⚫ ランダムにトークンを<mask>トークンに置き換える ⚫ 置き換えた場所のトークンを正しく予測 Transformer [s] Causal Language Modeling (CLM) (推論時) ⚫ ある時点までのトークンは与えられる ⚫ 次のトークンを予測する ⚫ 推論は1トークンずつ ⚫ Decoderとも呼ぶ a [s] a dog sleeping in bed
a <mask> sleeping in bed dog Masked Language Modeling (MLM) ⚫ ランダムにトークンを<mask>トークンに置き換える ⚫ 置き換えた場所のトークンを正しく予測 Transformer [s] a a dog ⚫ ある時点までのトークンは与えられる ⚫ 次のトークンを予測する ⚫ 推論は1トークンずつ ⚫ Decoderとも呼ぶ Causal Language Modeling (CLM) (推論時) [s] a dog sleeping in bed
a <mask> sleeping in bed dog Masked Language Modeling (MLM) ⚫ ランダムにトークンを<mask>トークンに置き換える ⚫ 置き換えた場所のトークンを正しく予測 Transformer [s] a dog a dog sleeping ⚫ ある時点までのトークンは与えられる ⚫ 次のトークンを予測する ⚫ 推論は1トークンずつ ⚫ Decoderとも呼ぶ Causal Language Modeling (CLM) (推論時) [s] a dog sleeping in bed
<mask> sleeping in bed dog Masked Language Modeling (MLM) ⚫ ランダムにトークンを<mask>トークンに置き換える ⚫ 置き換えた場所のトークンを正しく予測 [s] a dog sleeping in bed Causal Language Modeling (CLM) (学習時) sleeping bed ⚫ 1個1個生成されるのを待つと遅い ⚫ 学習時には、GTのトークン列で一気に学習 ⚫ Attentionでどのトークンが見えるか管理 Transformer a dog sleeping in bed [e] Transformer Teacher Forcing Ground-truthの トークン列を使う [s] a dog sleeping in bed
<mask> sleeping in bed dog Masked Language Modeling (MLM) ⚫ ランダムにトークンを<mask>トークンに置き換える ⚫ 置き換えた場所のトークンを正しく予測 [s] a dog sleeping in bed sleeping bed Attention Maskを 操作することで、 どのトークンを見るか 制御している Causal Language Modeling (CLM) (学習時) ⚫ 1個1個生成されるのを待つと遅い ⚫ 学習時には、GTのトークン列で一気に学習 ⚫ Attentionでどのトークンが見えるか管理
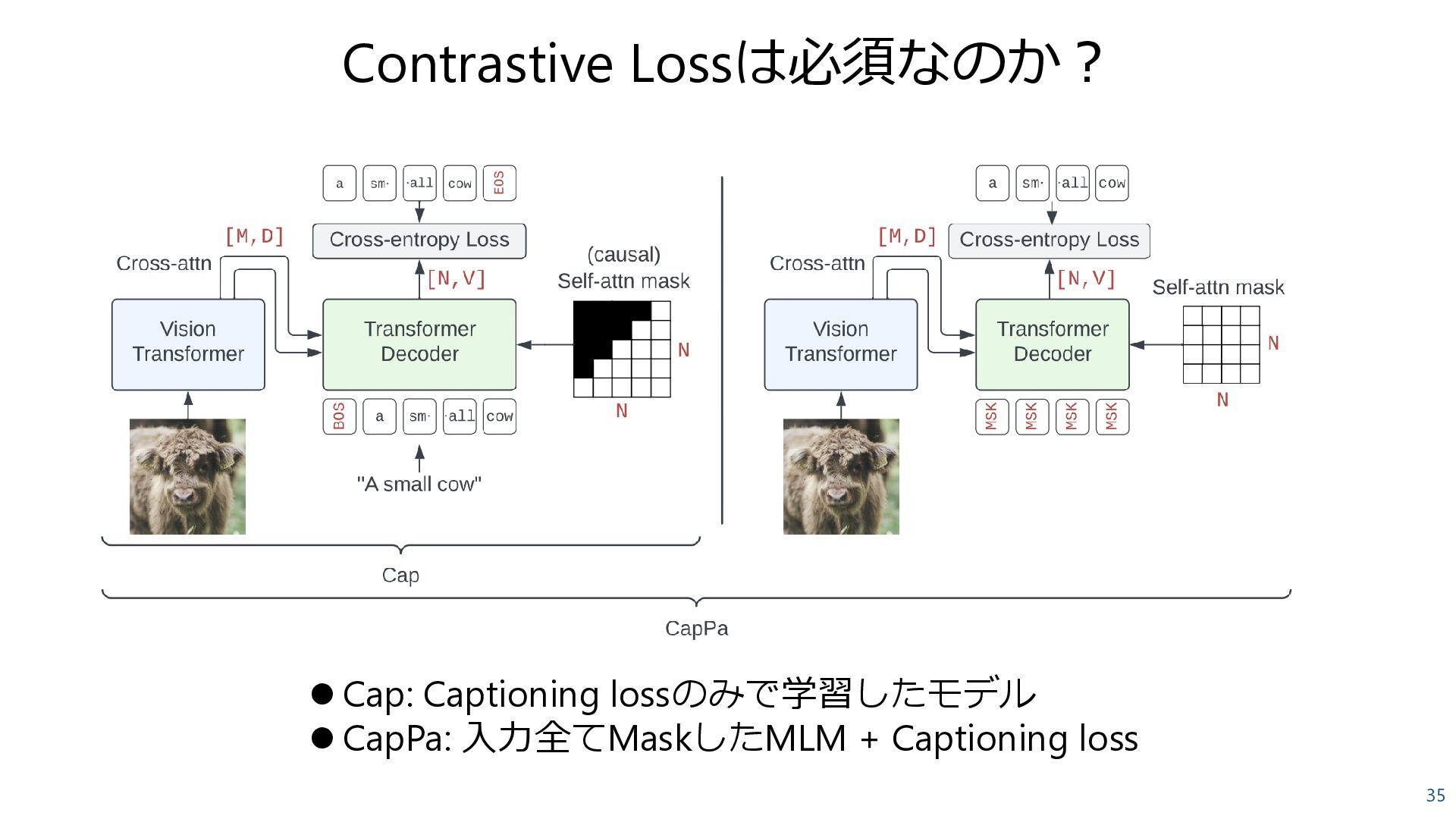
Masked Language Modeling (MLM) Transformer [s] a dog sleeping in bed Causal Language Modeling (CLM) ⚫ 文を画像から生成できる? ⚫ ある時点までのトークン+ 画像特徴を見る。 ⚫ 生成タスクに使われる ⚫ Captioning loss a dog sleeping in bed [e] ⚫ 画像から情報を補完できる? [s] a dog sleeping in bed
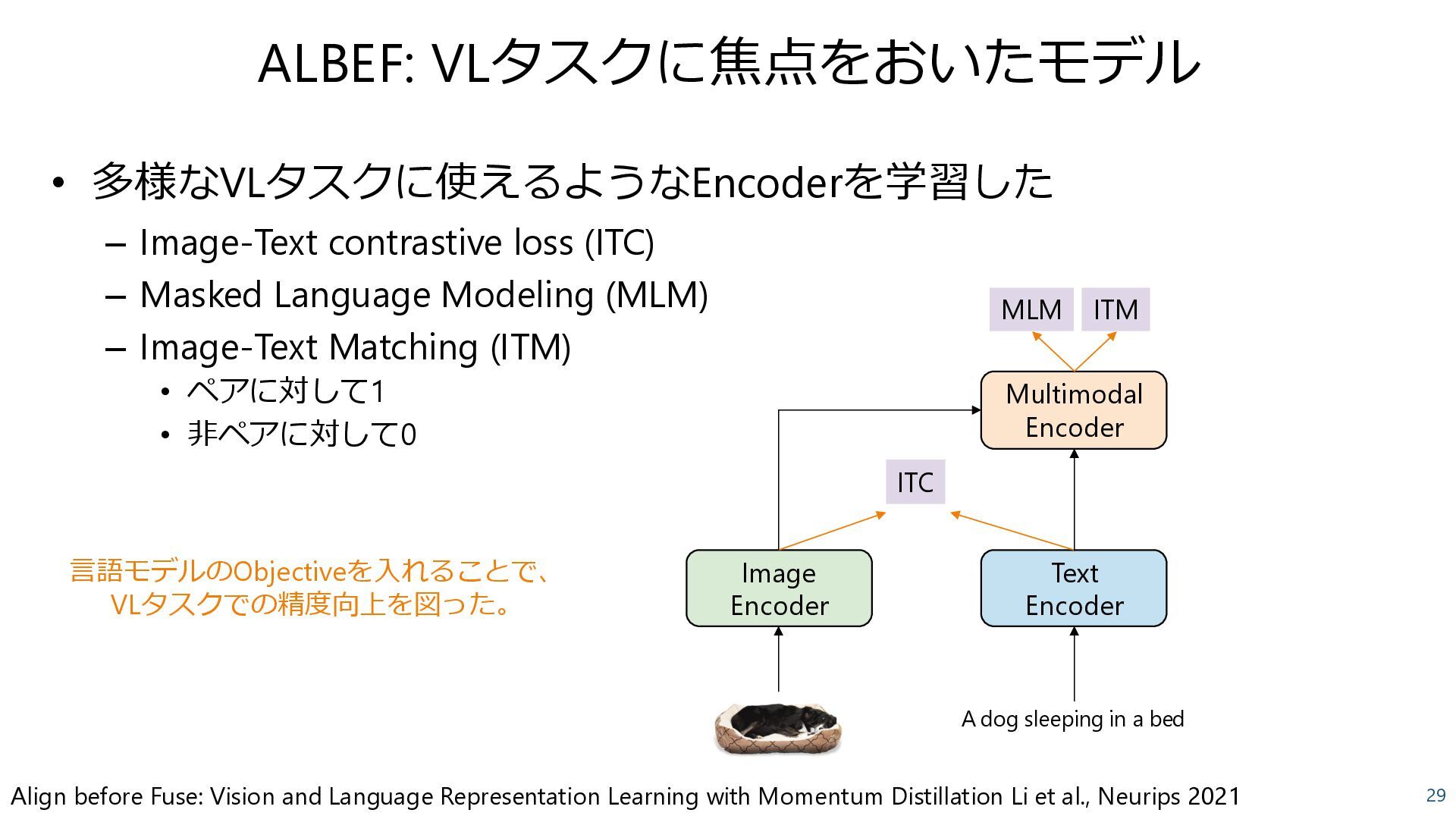
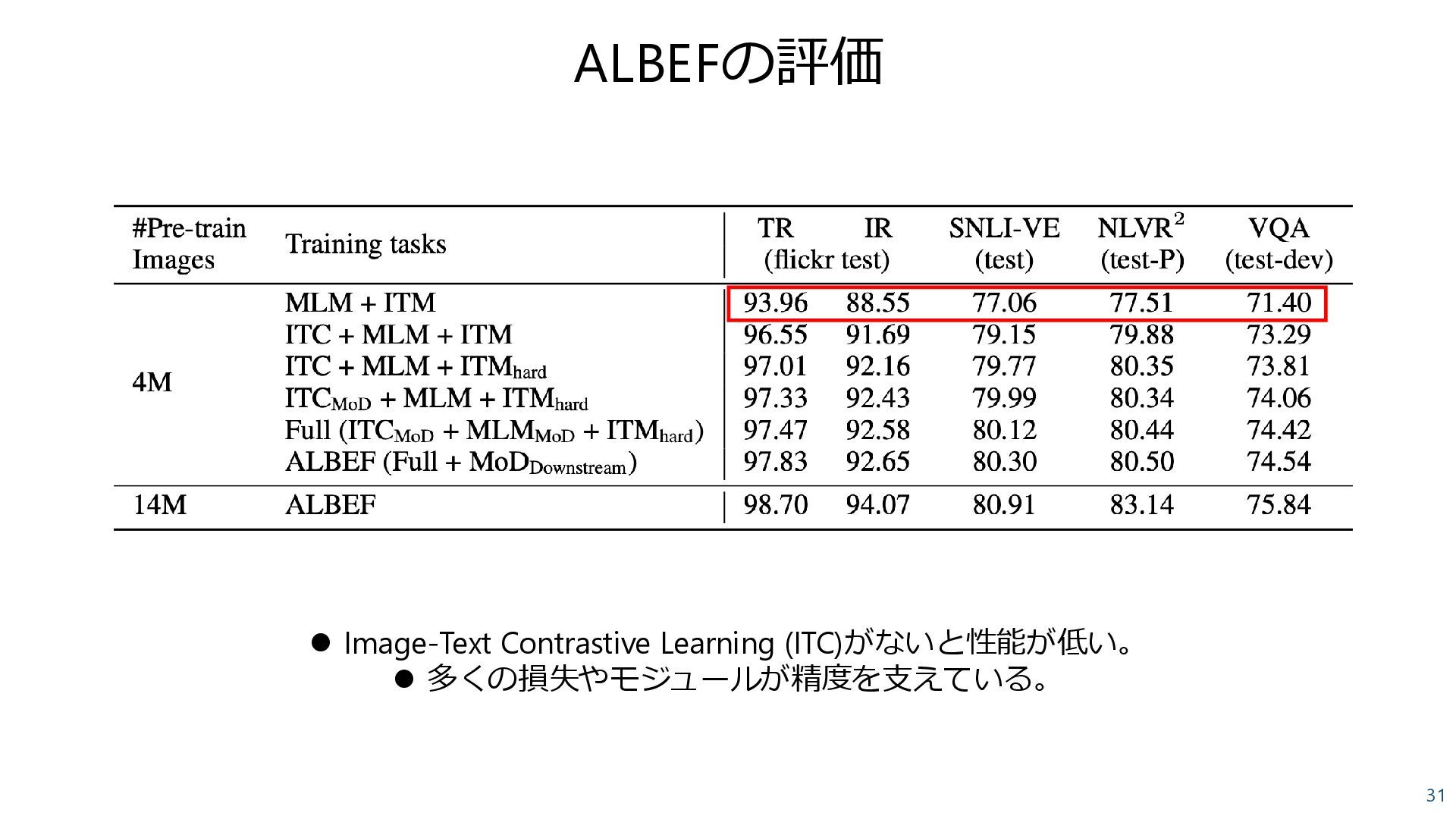
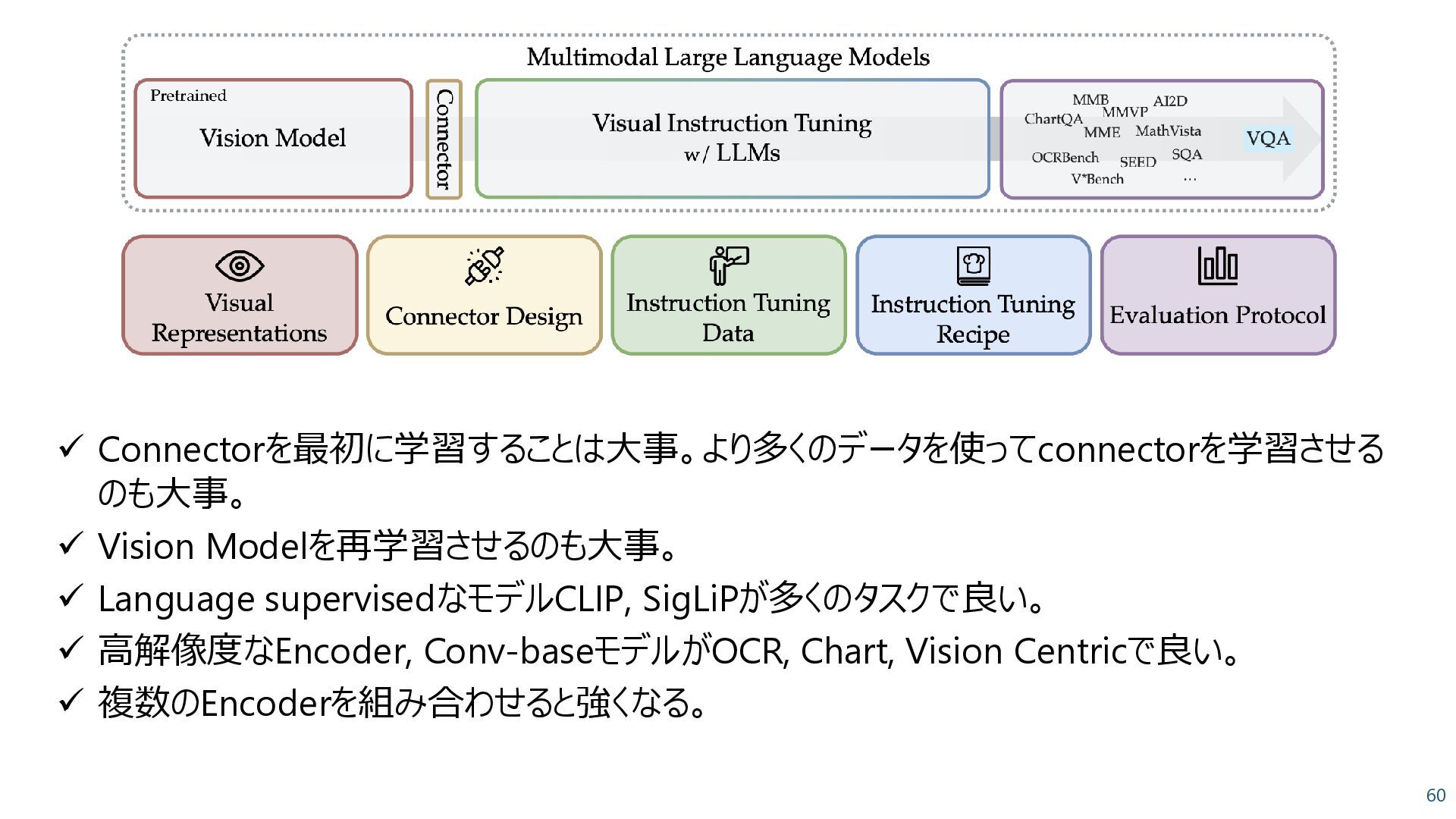
Learning with Momentum Distillation Li et al., Neurips 2021 • 多様なVLタスクに使えるようなEncoderを学習した – Image-Text contrastive loss (ITC) – Masked Language Modeling (MLM) – Image-Text Matching (ITM) • ペアに対して1 • 非ペアに対して0 Image Encoder Text Encoder Multimodal Encoder A dog sleeping in a bed ITC MLM ITM 言語モデルのObjectiveを入れることで、 VLタスクでの精度向上を図った。
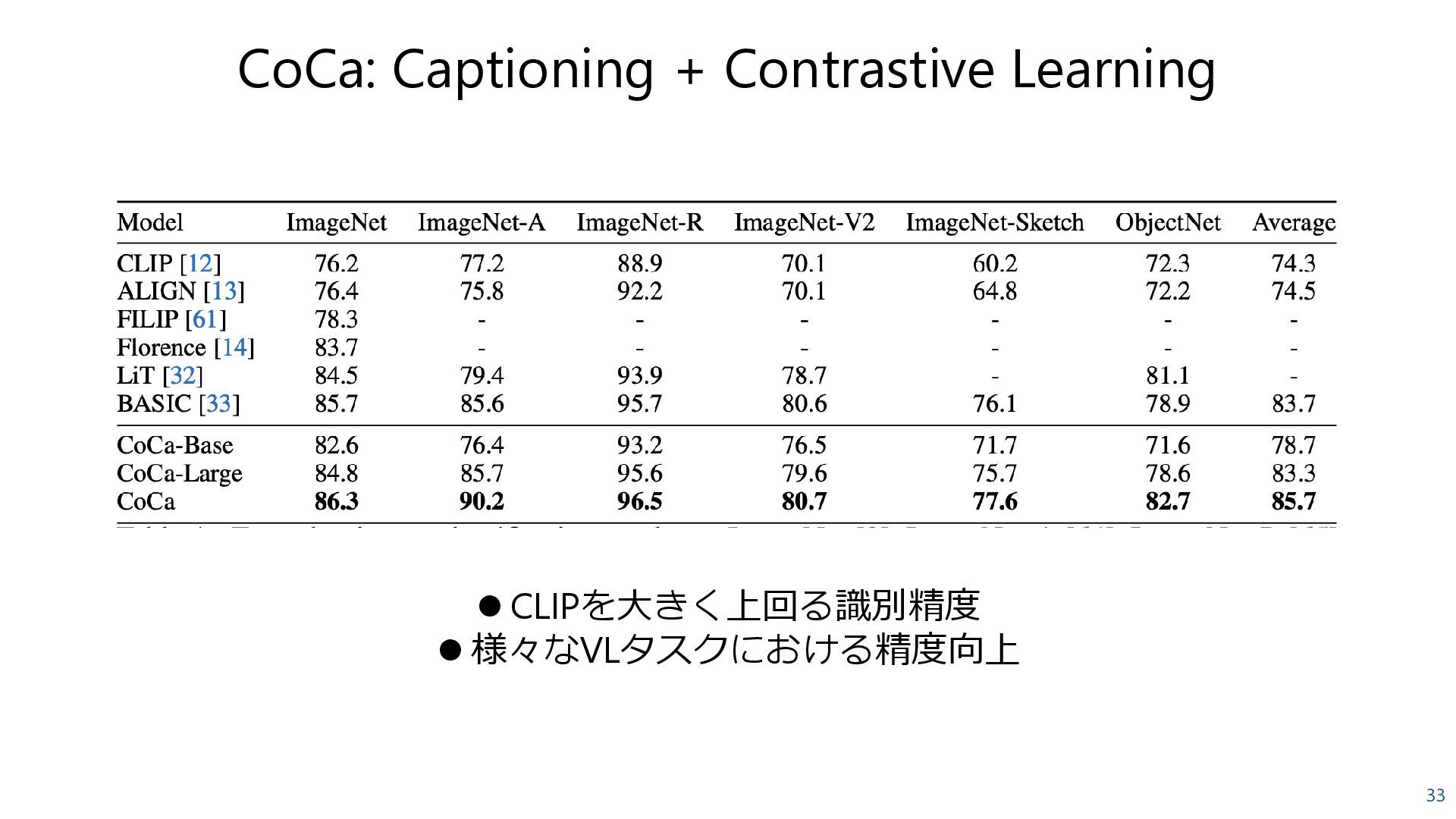
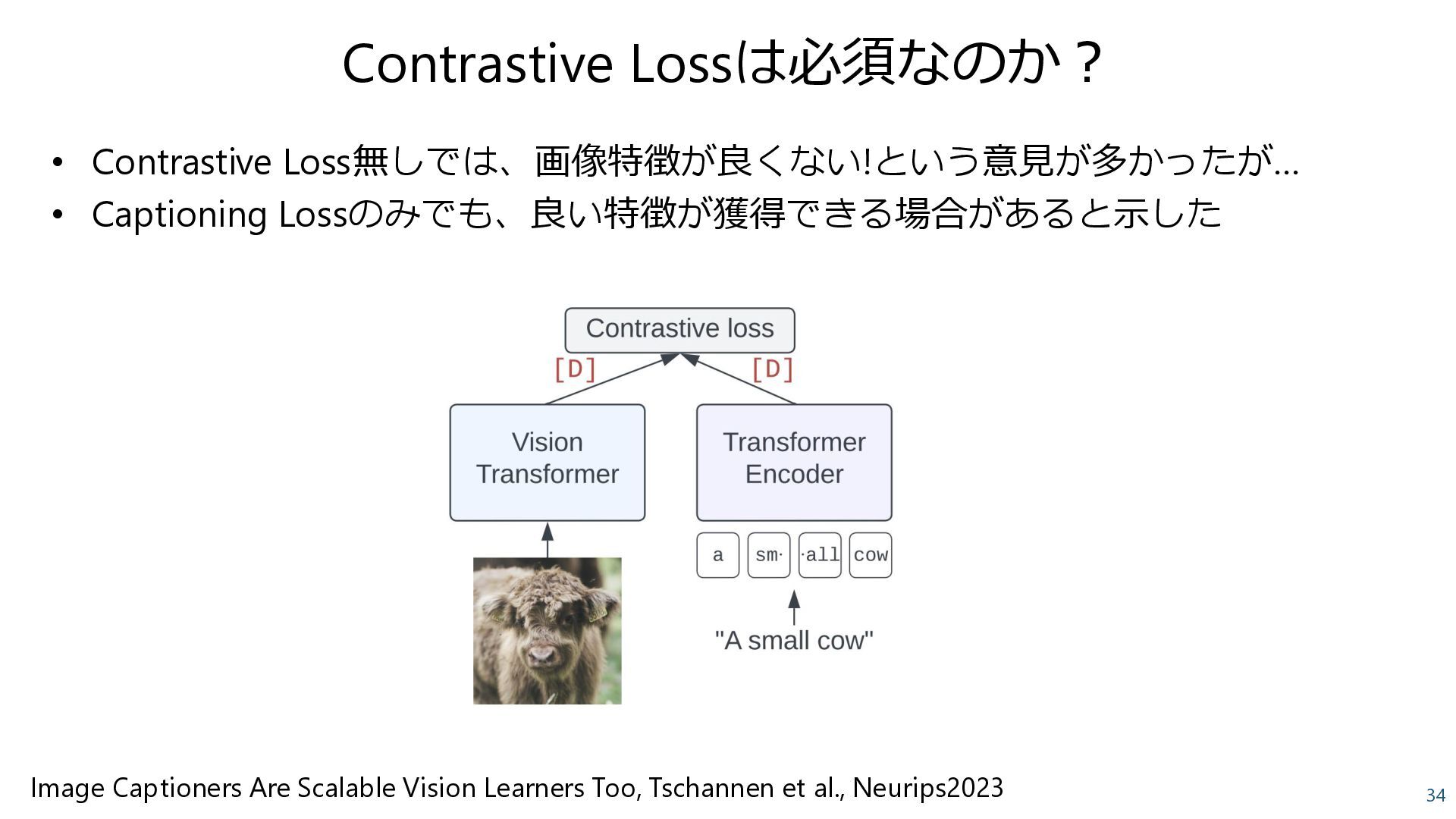
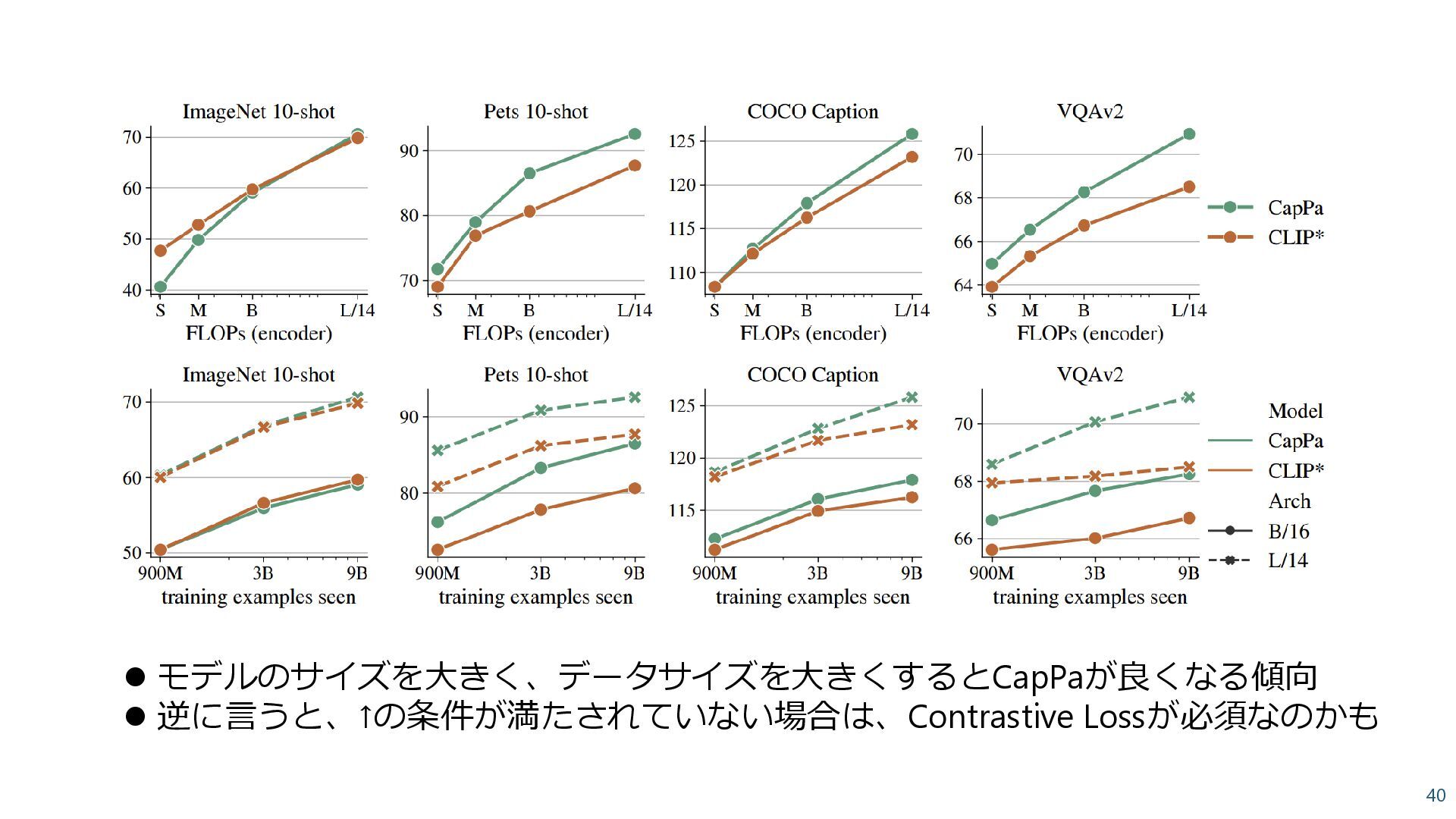
Pair + JFT-3B classification ⚫ Contrastive loss + Captioning loss CoCa: Contrastive Captioners are Image-Text Foundation Models, Yu et al., 2022 +9.8 Caption lossでVQAが大きく向上
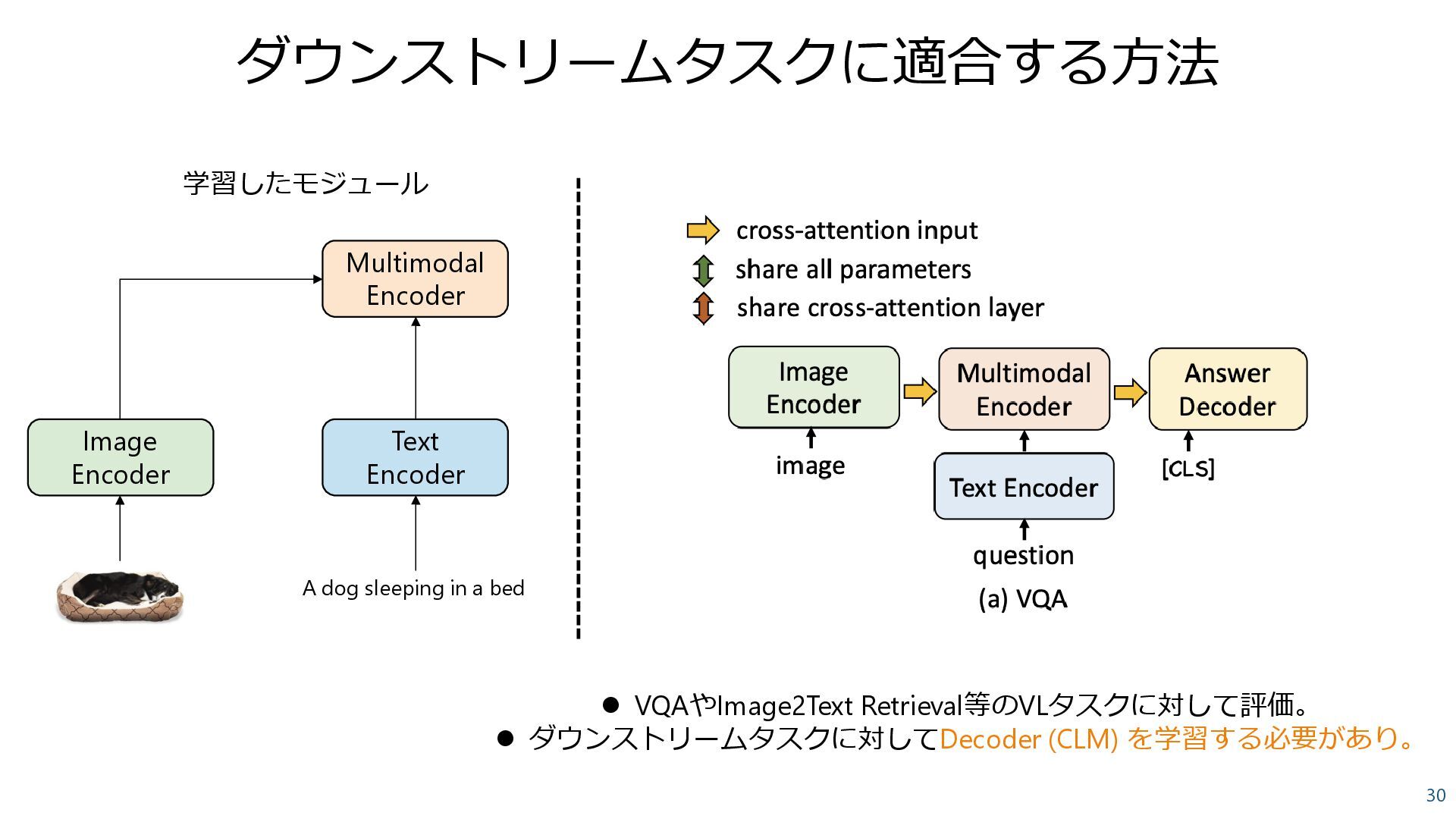
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models, Li et al., 2023 ✓ Connector: 画像を説明できるようなトークンを得る ✓ Two stage学習: Connectorの学習 -> 全体(or一部)のチューニングが一般的
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Masked Language Modeling と Causal Language Modeling 20 Transformer [s]](https://files.speakerdeck.com/presentations/17c3783d671c478396c64a8ae1d0b214/slide_19.jpg){kind=link}
![Masked Language Modeling と Causal Language Modeling 21 Transformer [s]](https://files.speakerdeck.com/presentations/17c3783d671c478396c64a8ae1d0b214/slide_20.jpg){kind=link}
![Masked Language Modeling と Causal Language Modeling 22 Transformer [s]](https://files.speakerdeck.com/presentations/17c3783d671c478396c64a8ae1d0b214/slide_21.jpg){kind=link}
![Masked Language Modeling と Causal Language Modeling 23 Transformer [s]](https://files.speakerdeck.com/presentations/17c3783d671c478396c64a8ae1d0b214/slide_22.jpg){kind=link}
![Masked Language Modeling と Causal Language Modeling 24 [s] a](https://files.speakerdeck.com/presentations/17c3783d671c478396c64a8ae1d0b214/slide_23.jpg){kind=link}
![Masked Language Modeling と Causal Language Modeling 25 [s] a](https://files.speakerdeck.com/presentations/17c3783d671c478396c64a8ae1d0b214/slide_24.jpg){kind=link}
![画像を言語モデルに理解させるには? 26 Transformer [s] a <mask> sleeping in bed dog](https://files.speakerdeck.com/presentations/17c3783d671c478396c64a8ae1d0b214/slide_25.jpg){kind=link}
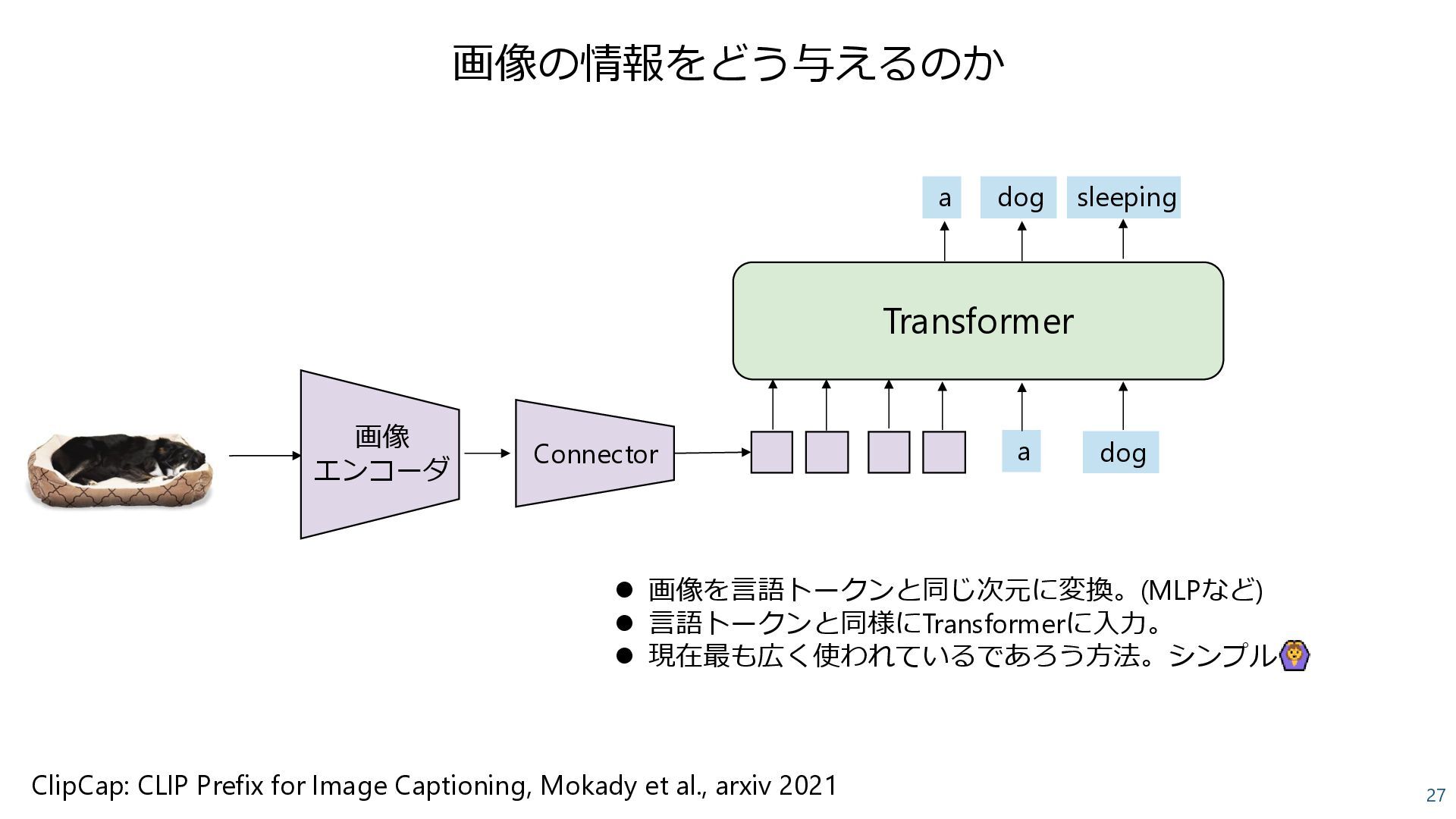{kind=link}
![画像の情報をどう与えるのか 28 画像 エンコーダ [s] a dog K V Q](https://files.speakerdeck.com/presentations/17c3783d671c478396c64a8ae1d0b214/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
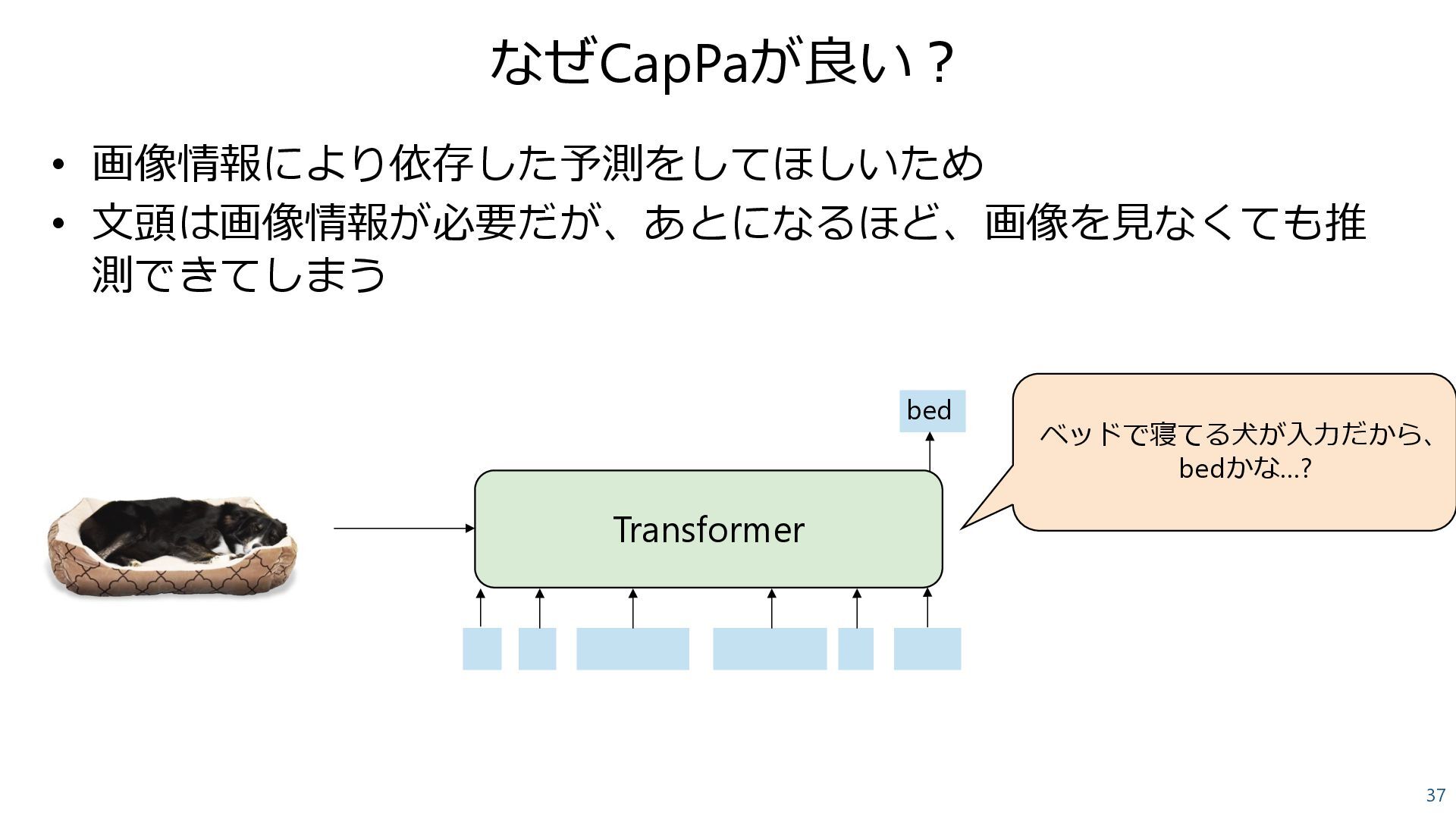
![なぜCapPaが良い? 36 • 画像情報により依存した予測をしてほしいため • 文頭は画像情報が必要だが、あとになるほど、画像を見なくても推 測できてしまう Transformer [s] a](https://files.speakerdeck.com/presentations/17c3783d671c478396c64a8ae1d0b214/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
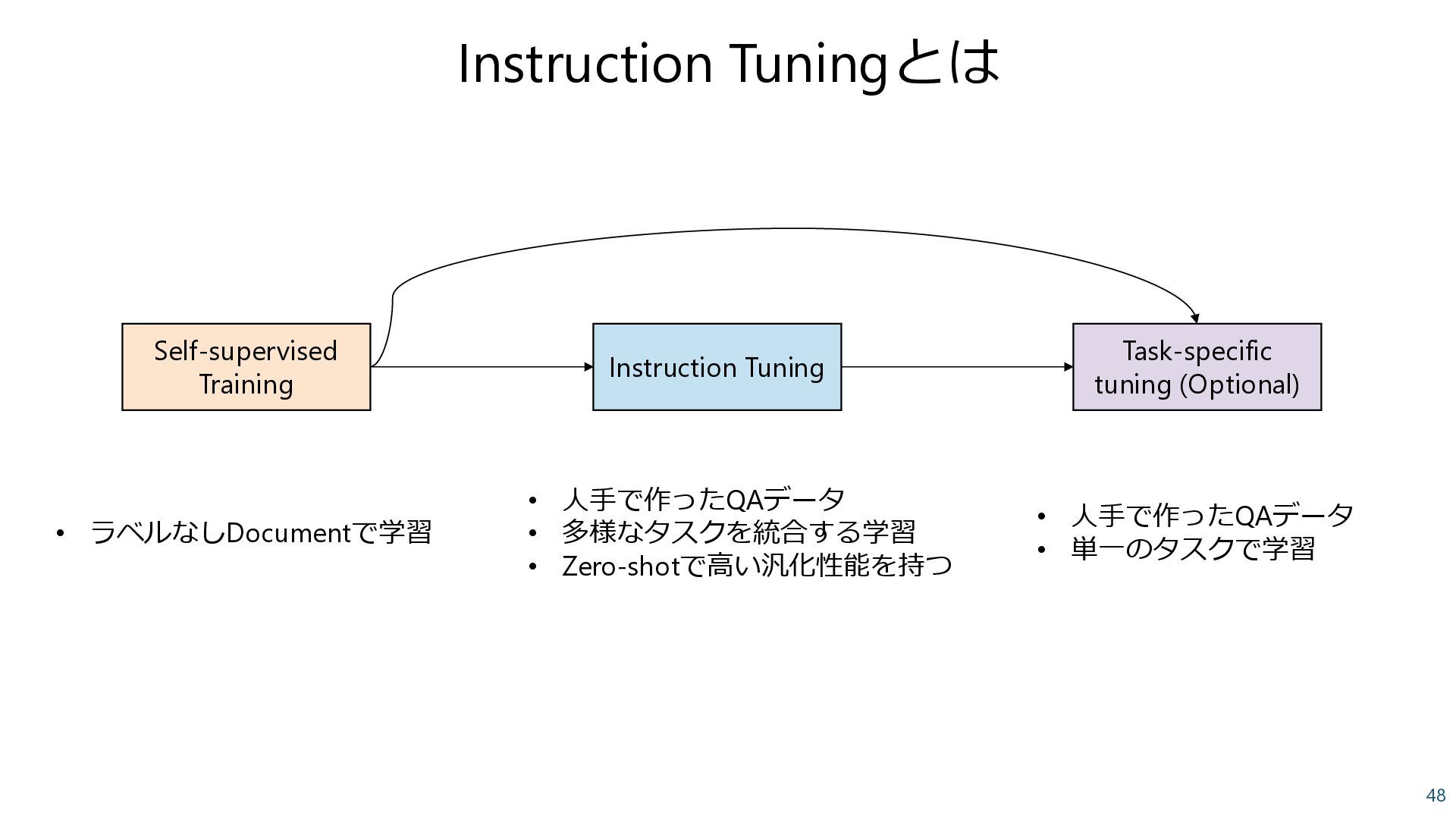{kind=link}
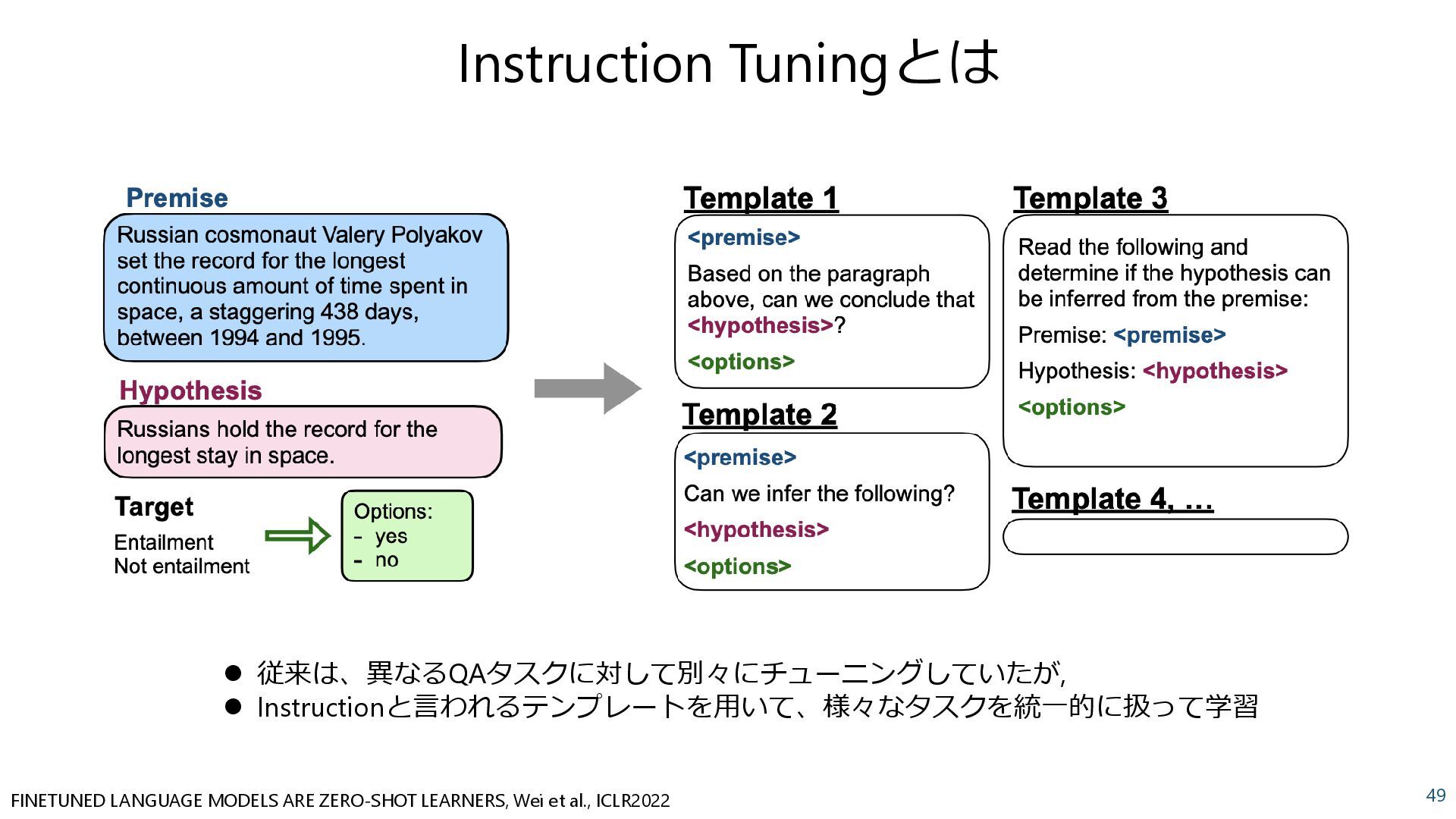{kind=link}
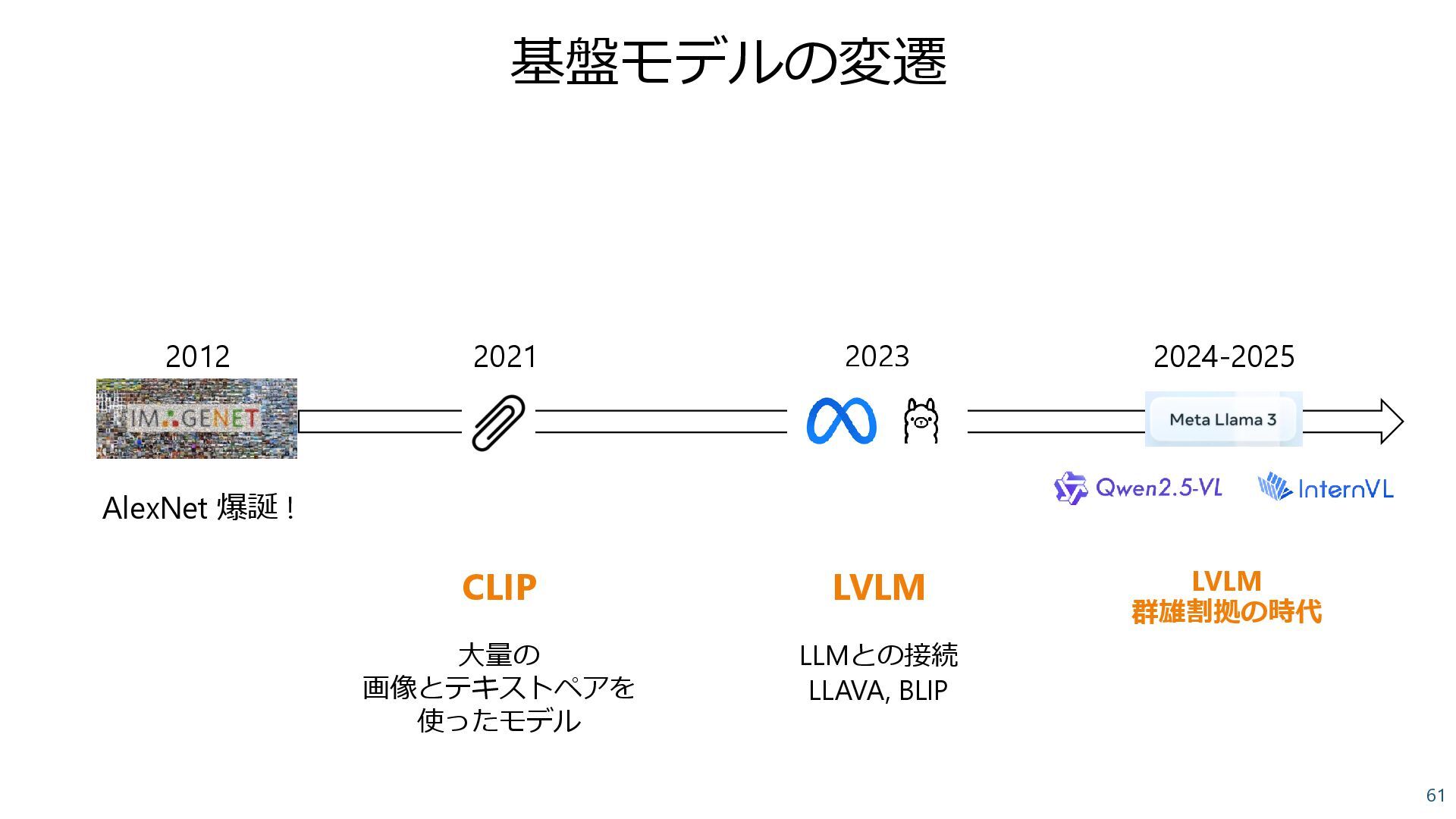
![LVLM時代に突入 50 BLIP-2 [Li et.al., 2023] • LLMと接続する手法が提案される (BLIP-2, LLaVA)](https://files.speakerdeck.com/presentations/17c3783d671c478396c64a8ae1d0b214/slide_49.jpg){kind=link}
{kind=link}
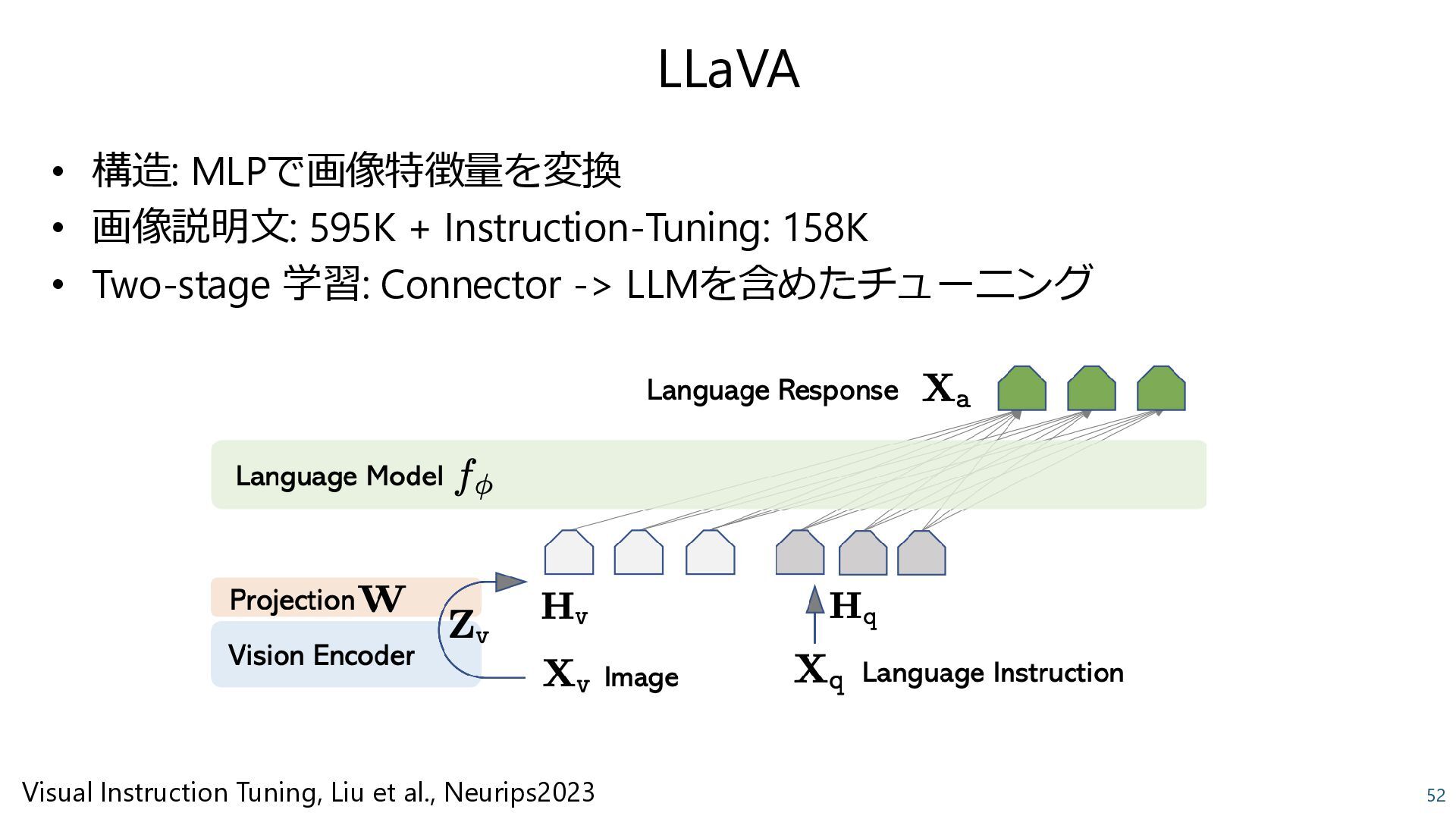{kind=link}
{kind=link}
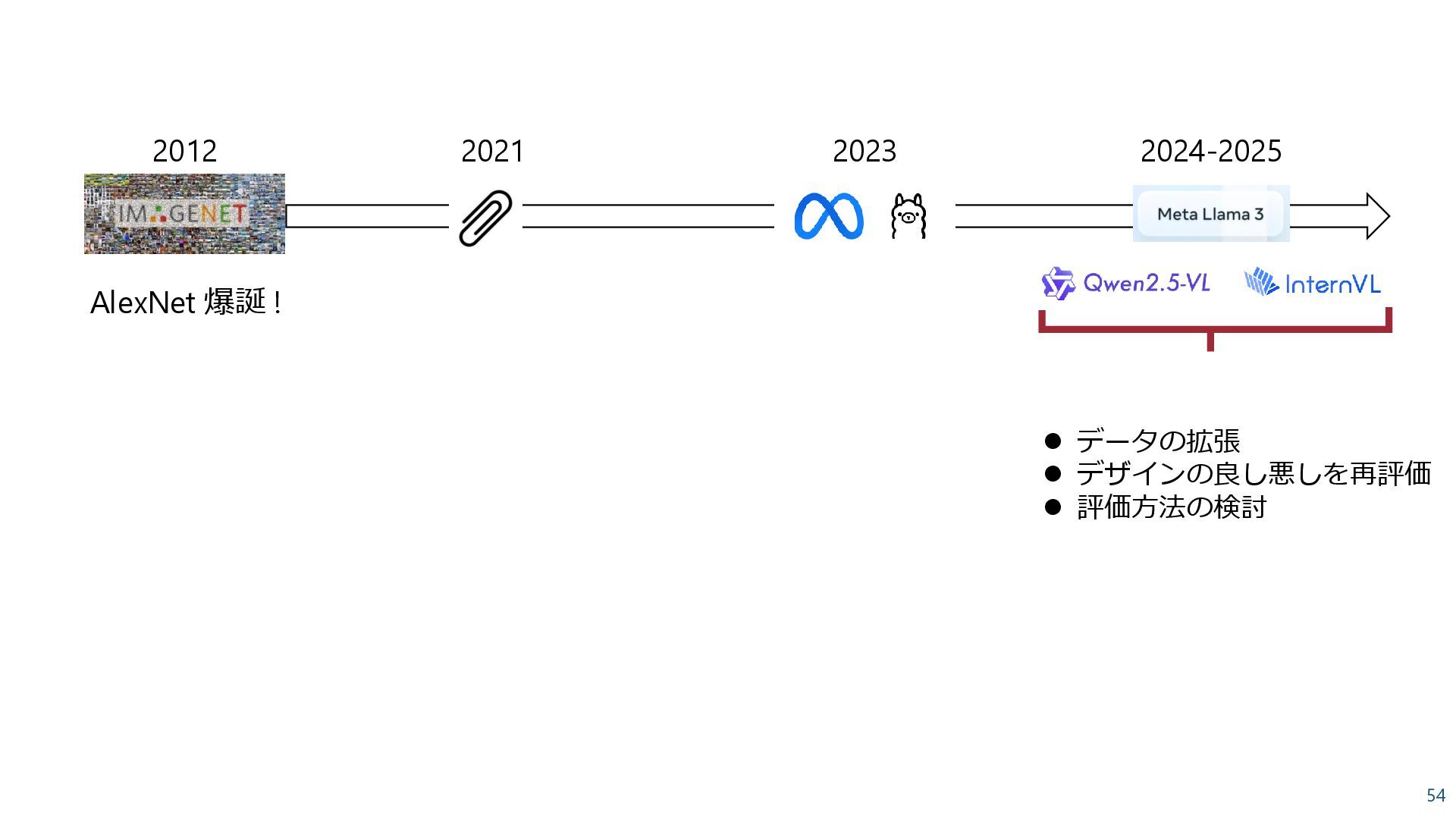{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}