Upgrade to PRO for Only $50/Year—Limited-Time Offer! 🔥
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Jigsaw-ACRC-7th-place
Search
ktr
November 26, 2025
1
220
Jigsaw-ACRC-7th-place
ktr
November 26, 2025
Tweet
Share
More Decks by ktr
See All by ktr
atma cup #17 振り返り会
ktrw1011
0
290
Quora With BERT
ktrw1011
0
2k
APTOS_2019_Blindness_Detection_96th_Solution
ktrw1011
0
810
Featured
See All Featured
A better future with KSS
kneath
240
18k
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
Why Our Code Smells
bkeepers
PRO
340
57k
How to Ace a Technical Interview
jacobian
280
24k
Thoughts on Productivity
jonyablonski
73
5k
BBQ
matthewcrist
89
9.9k
Agile that works and the tools we love
rasmusluckow
331
21k
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.5k
Context Engineering - Making Every Token Count
addyosmani
9
450
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
Building a Scalable Design System with Sketch
lauravandoore
463
34k
The Pragmatic Product Professional
lauravandoore
37
7k
Transcript
7th place solution MAP, Jigsaw, Code Golf 振り返り会 by 関東kaggler会
(2025/11/27) Jigsaw - Agile Community Rules Classification
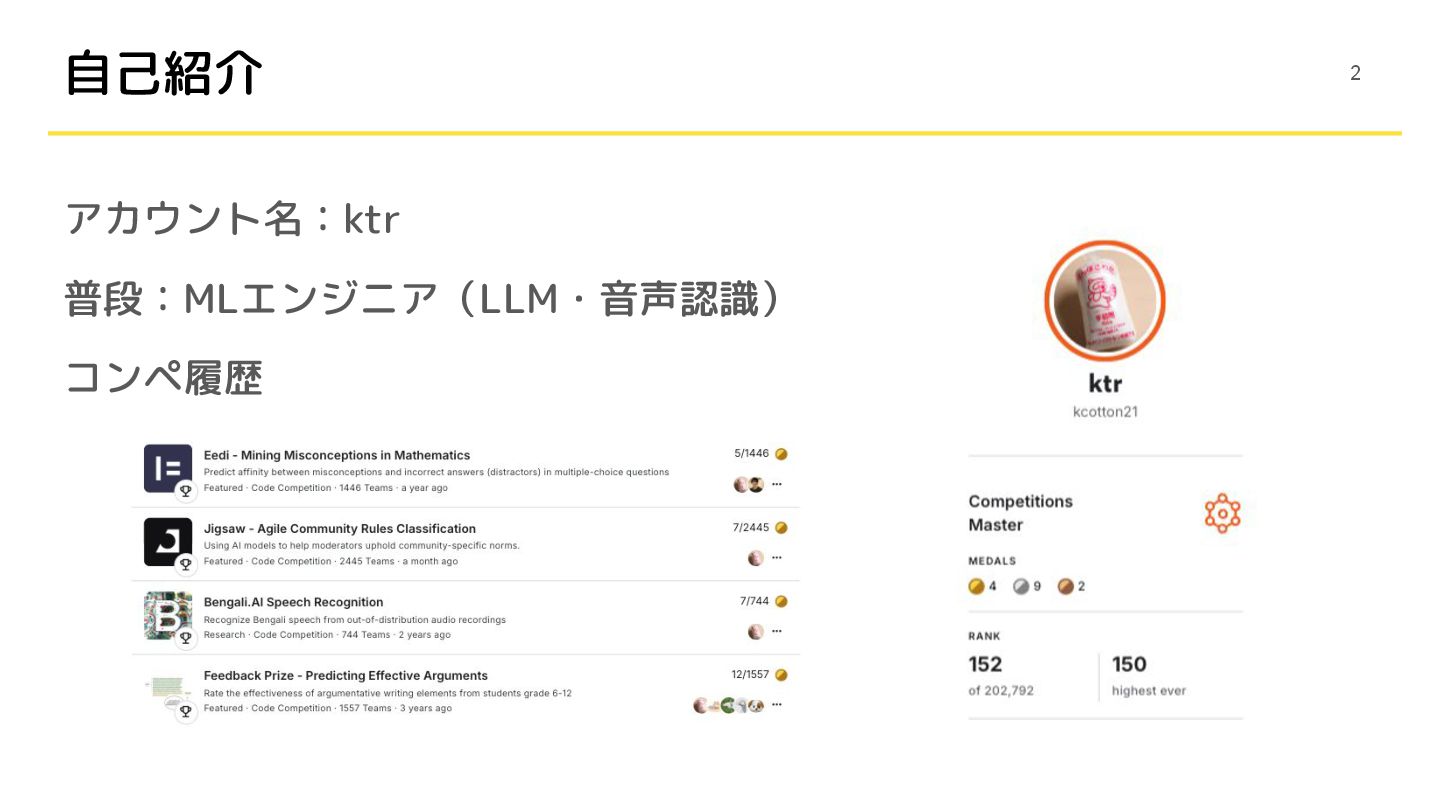
自己紹介 アカウント名:ktr 普段:MLエンジニア(LLM・音声認識) コンペ履歴 2
アジェンダ • ソリューションの紹介 • ソリューションにいたるまで 3
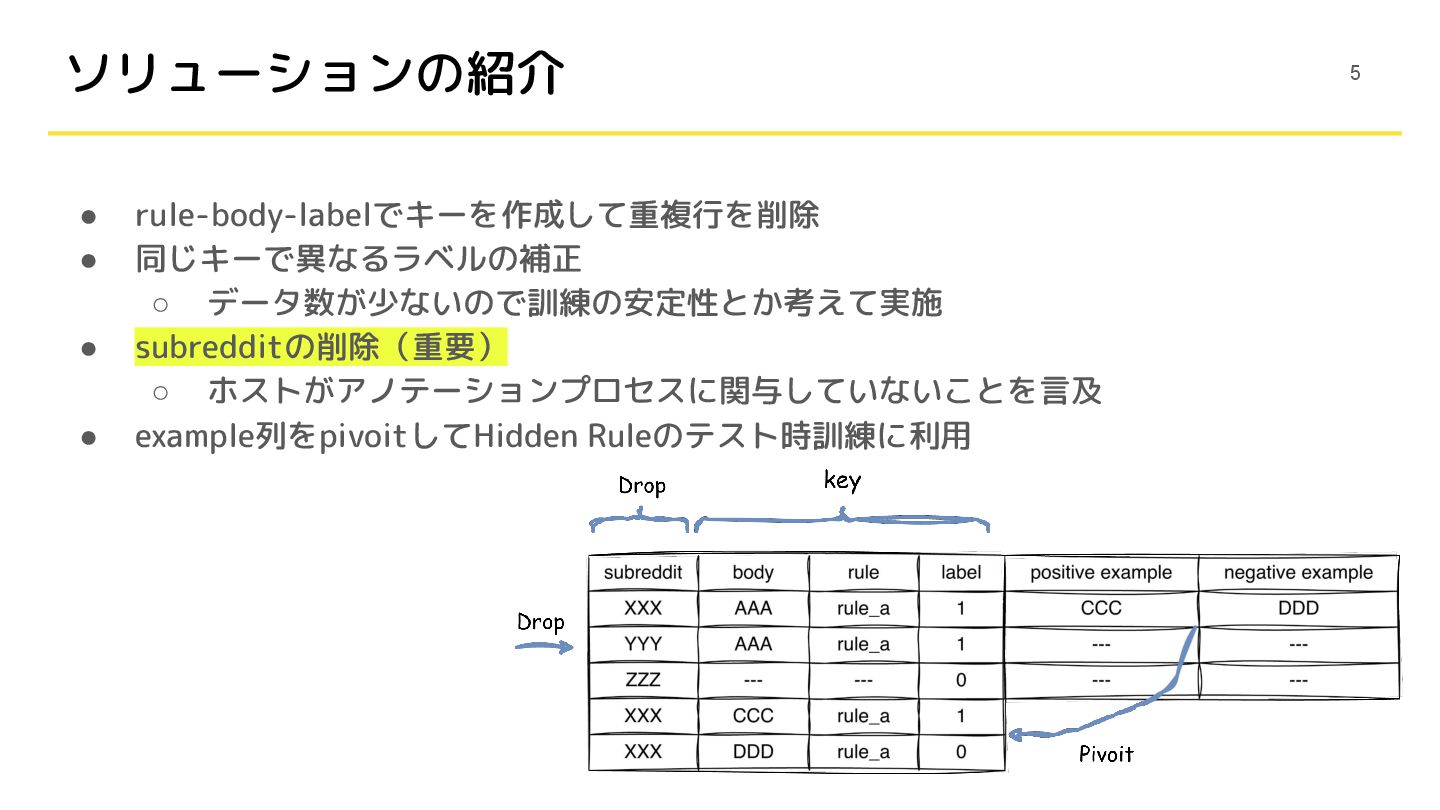
ソリューションの紹介 4
• rule-body-labelでキーを作成して重複行を削除 • 同じキーで異なるラベルの補正 ◦ データ数が少ないので訓練の安定性とか考えて実施 • subredditの削除(重要) ◦ ホストがアノテーションプロセスに関与していないことを言及
• example列をpivoitしてHidden Ruleのテスト時訓練に利用 ソリューションの紹介 5
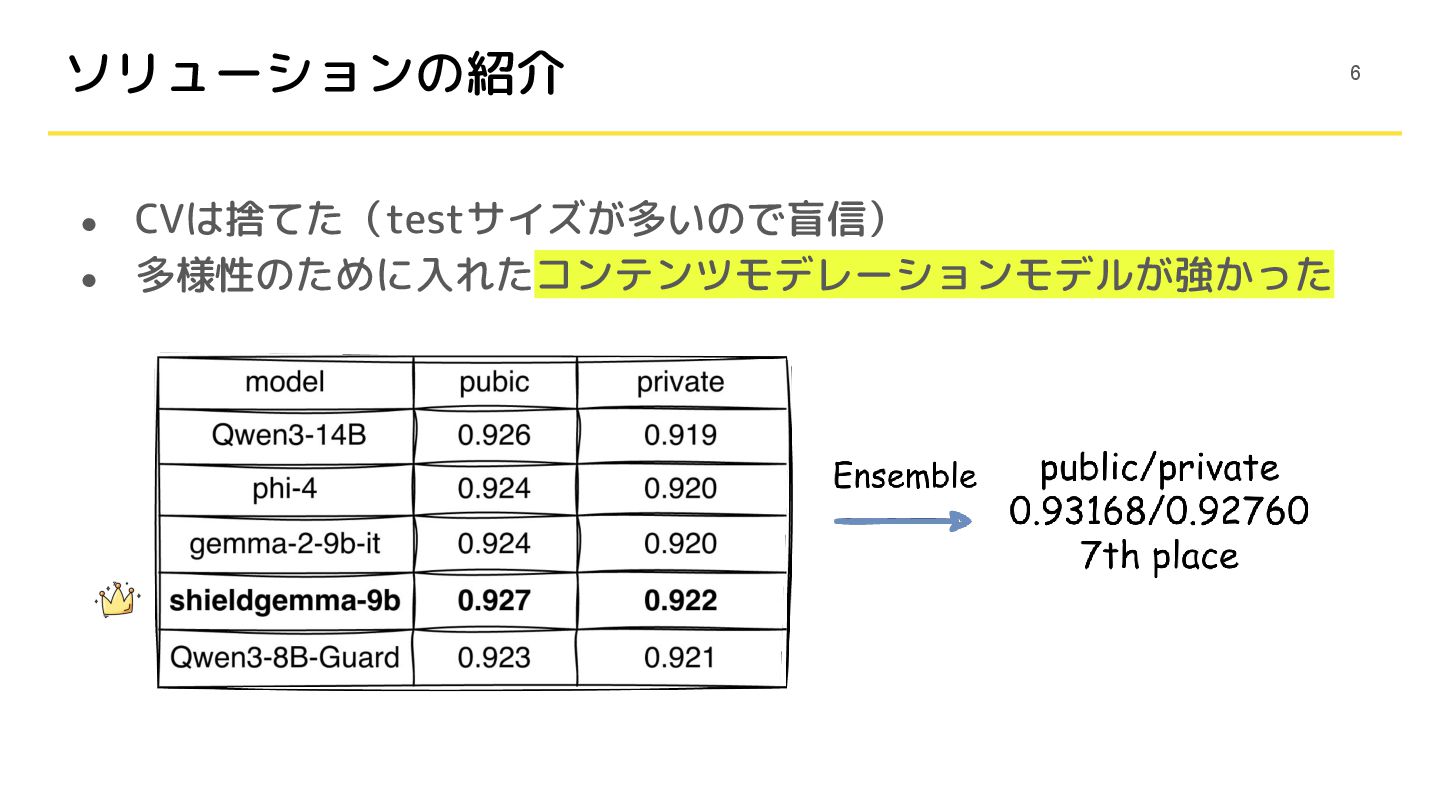
• CVは捨てた(testサイズが多いので盲信) • 多様性のために入れたコンテンツモデレーションモデルが強かった ソリューションの紹介 6
ソリューションにいたるまで 7
ソリューションにいたるまで 1. デカいモデルは絶対につよいはず 2. 合成・外部データをうまく扱った人が勝つ 3. とにかくモデルを積む(アンサンブル) 8
1. デカいモデルは絶対につよいはず 過去コンペ • LMSYS、WSDM ◦ 70Bから14Bへの蒸留 • Eedi 1st、2nd
◦ 70Bの直接利用 30Bクラスは視野。場合によっては70Bクラスまで使う 9
1. デカいモデルは絶対につよいはず 今回のタスクではNotebook(T4x2)で訓練+推論まで行う必要がある • 訓練:14BくらいまでシングルGPUで可能 ◦ QLoRA+unslothを利用してT4x2で並列実行 • 推論:vllm T4x2で14Bを量子化なしで実行
◦ LoRAアダプターのマージなしでOK 10
2. 合成・外部データをうまく扱った人が勝つ 過去コンペ • LMSYS、WSDM ◦ 外部データで事前学習 => コンペデータで学習 •
Eedi ◦ Claude (1st)、Qwen2.5 72B (4th)を使って合成データ作成 11
2. 合成・外部データをうまく扱った人が勝つ • ProbingでRuleは判明したので、labelを指定してBodyさえ合成すれ ば良い状況 • 実験してみても改善しない+スコアの大きな変動がほとんどなかった アイディアを捨てた • コンテキストがなさすぎる?有用なモデルは大抵セーフガードが入って
いてToxicなデータを生成しづらい? 12
3. とにかくモデルを積む(アンサンブル) 過去コンペ • CommonLit Readability Prize 2nd(19モデル) • Jigsaw
Rate Severity of Toxic Comments 1th (15モデル) ◦ 壮大なソリューションのモデル欄 合成がうまくいかないのでこちらを重点的にやることに 13
3. とにかくモデルを積む(アンサンブル) • 8 -14Bモデルまでをsweepして実験 • 30モデルくらいためした • unslothの動作+チャットテンプレート+vllmのモデル対応とか地味 な動作検証がコンペ時間の大半だった
14
3. とにかくモデルを積む(アンサンブル) • ベースライン:llama3.1 8b(public:0.920) • これより後にリリースされた同程度サイズのモデルで、このスコアを 超えるモデルはほとんど存在しなかった ◦ GLM-4-9B:0.919、Falcon-3-10b-it:0.914
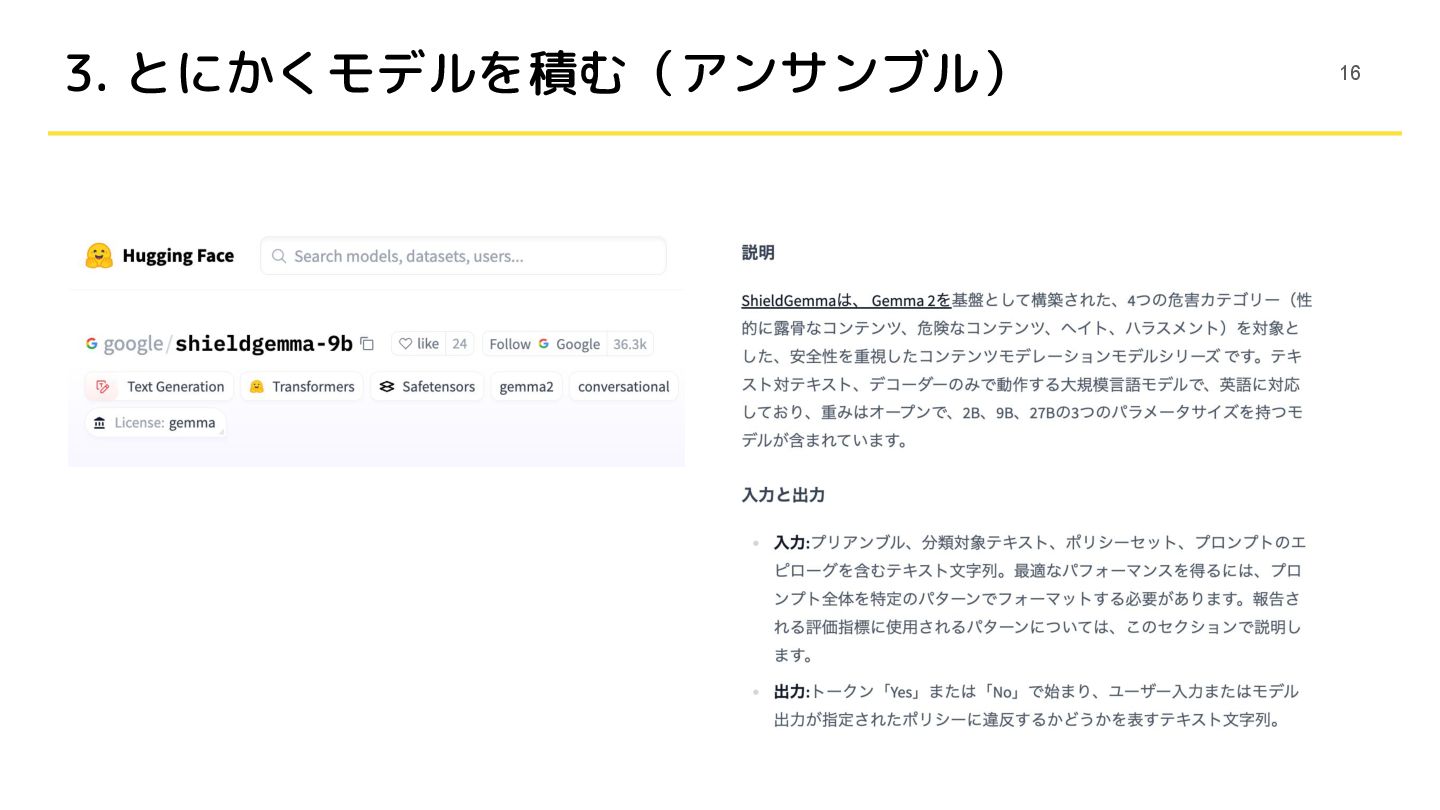
• gemma-2-9b-itがモデルサイズに対して強い(0.924) • shieldgemma-9bが最もパフォーマンスがよかった(0.927) ◦ コンテンツモデレーションタスクで学習した派生モデル ◦ Qwen(Guard)でも同様の傾向だった 15
3. とにかくモデルを積む(アンサンブル) 16
まとめ • 過去の動向とかを考えてやることを3つに絞ってやってた ◦ タスクの本質的(OODへの対応)的な部分にリーチした感覚はない ◦ 他チーム:Triplet Lossで多様性だすとかの独創的なアプローチ • 金圏ボーダーのスコア差は0.00082。振り返るとアンサンブルのゴ
リ押し+CVの盲信で運の要素も大きかった印象 17
ありがとうございました🤗 18
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}