Share
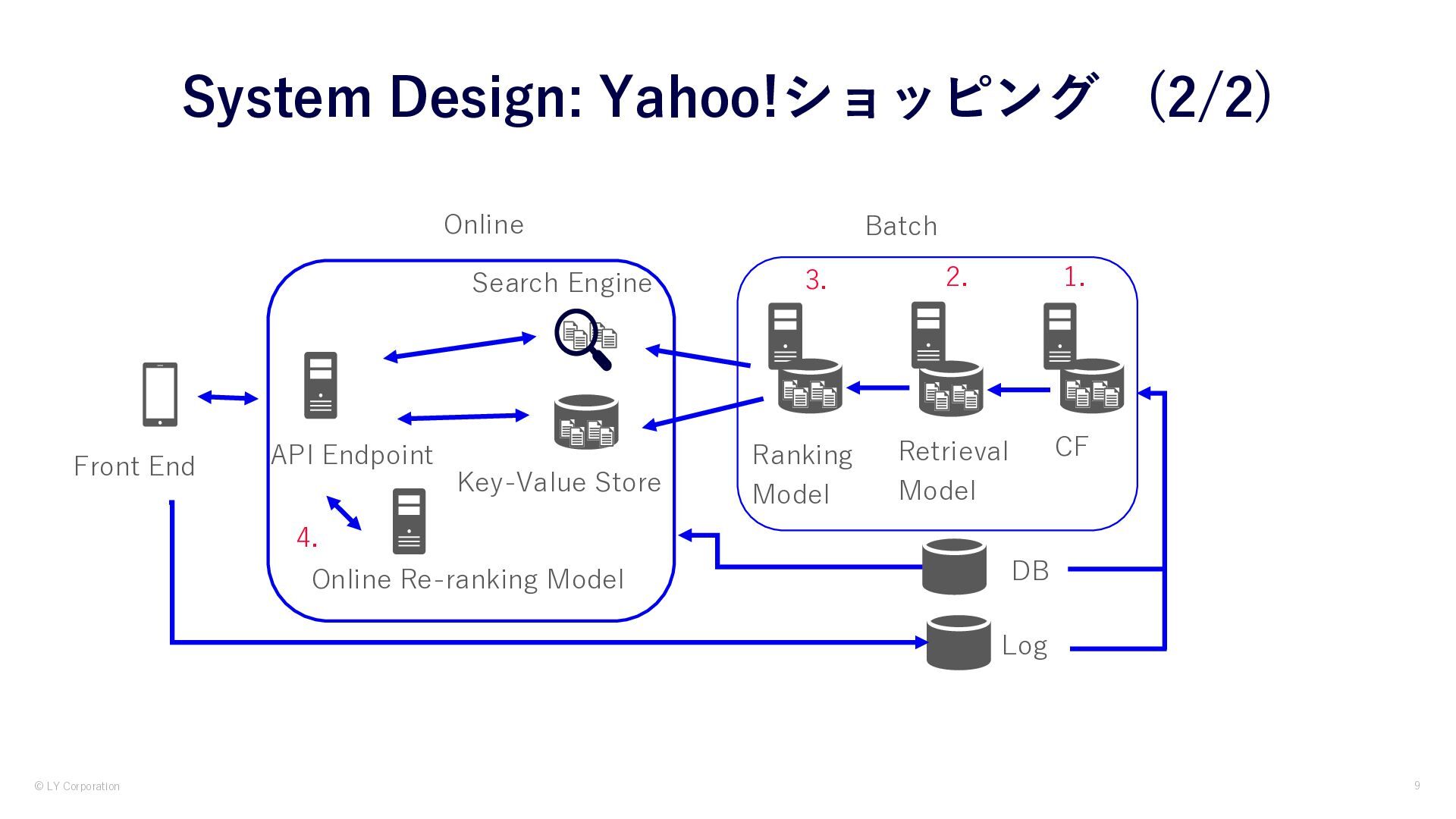
LINEヤフーでは、様々なサービスの基盤に機械学習(ML)技術が使用され ています。サービスの一つであるYahoo!ショッピングでは、数多くの商 品を扱うレコメンデーション・システム向けに、大規模なデータ処理と MLモデルの学習と推論を日々行っています。本発表では大規模なレコメ ンデーション・システムならではの構成と、使用しているML技術の概要 について解説します。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}