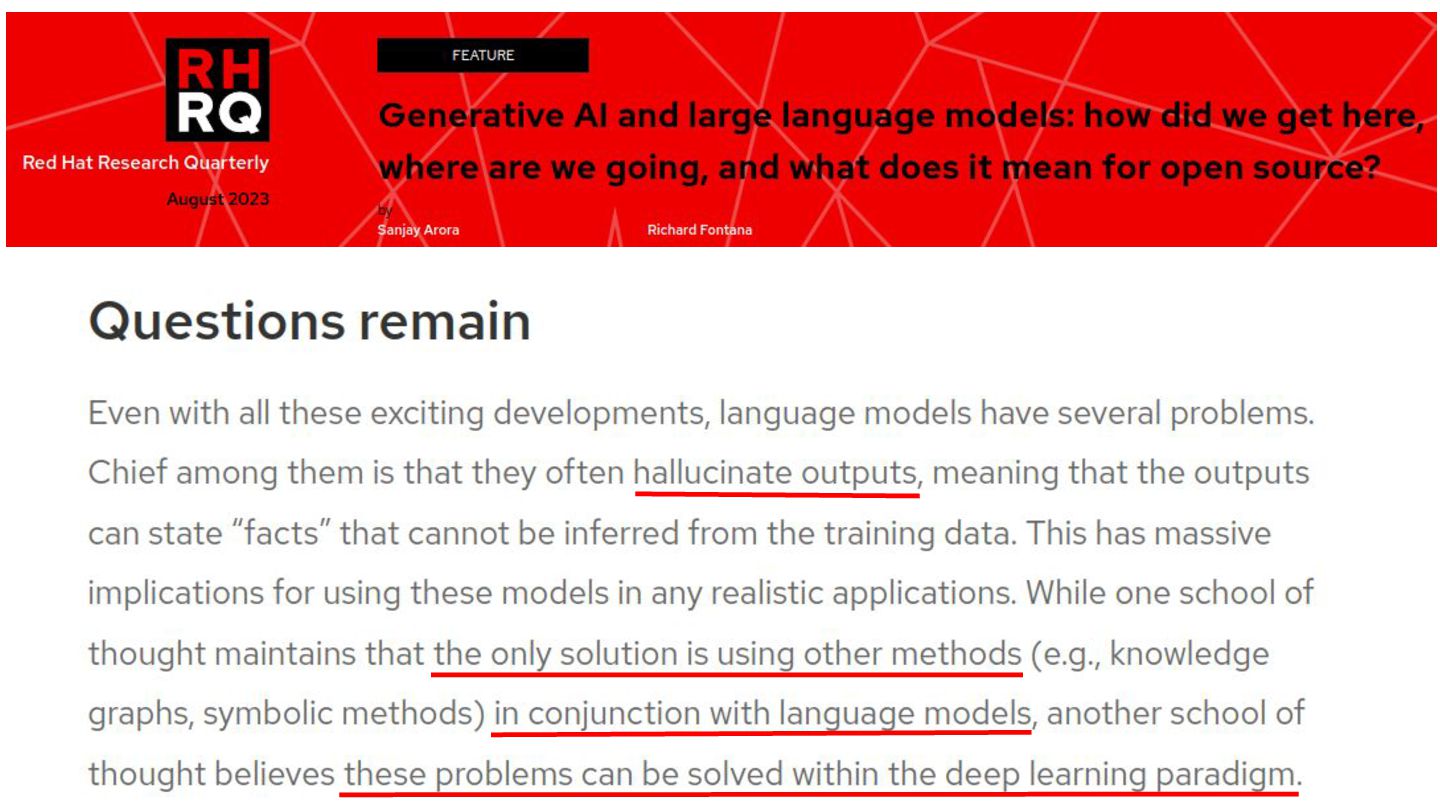
Checking the correctness of an application with an exhaustive suite of unit and integration tests is a natural task for any respectable software developer. Such a test suite also comes with other advantages like documenting the expected behavior of the application and enabling a fast feedback loop. This is all relatively straightforward when the components of your software are entirely deterministic, but how can you achieve something similar when a key part of it has a probabilistic nature?
This probabilistic nature makes it even more important to observe and collect real user inputs from production to better understand user needs and automate the evaluation of your LLM-infused application.
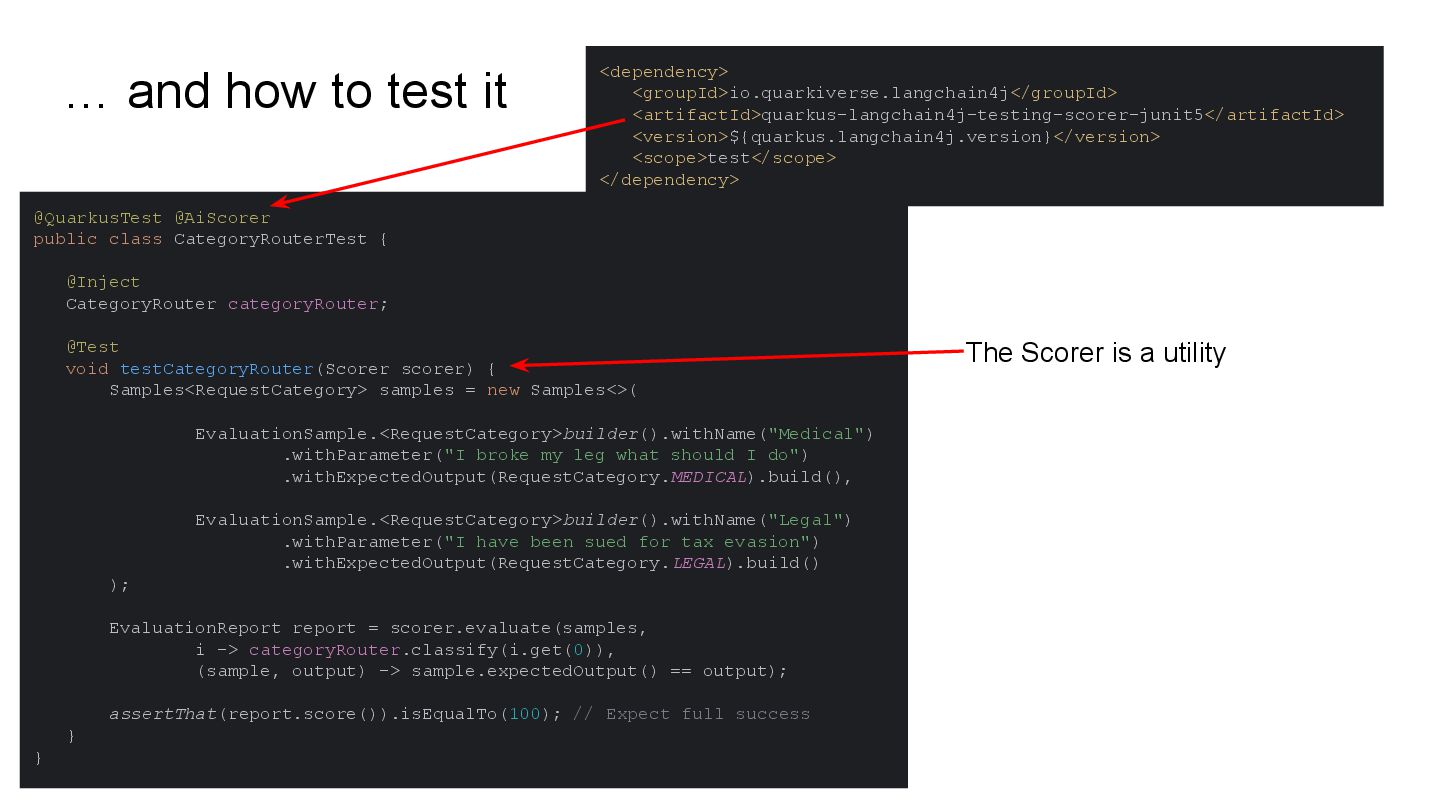
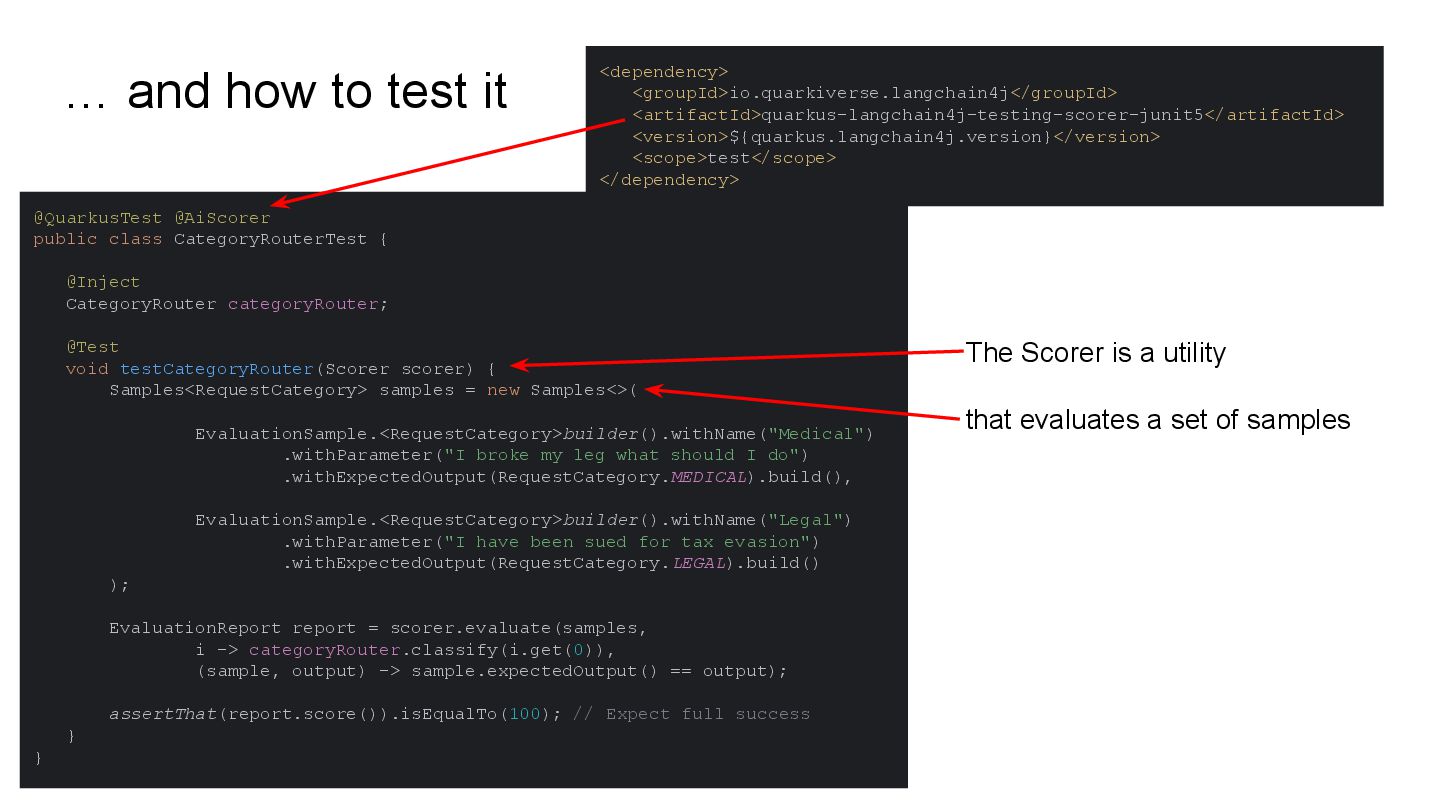
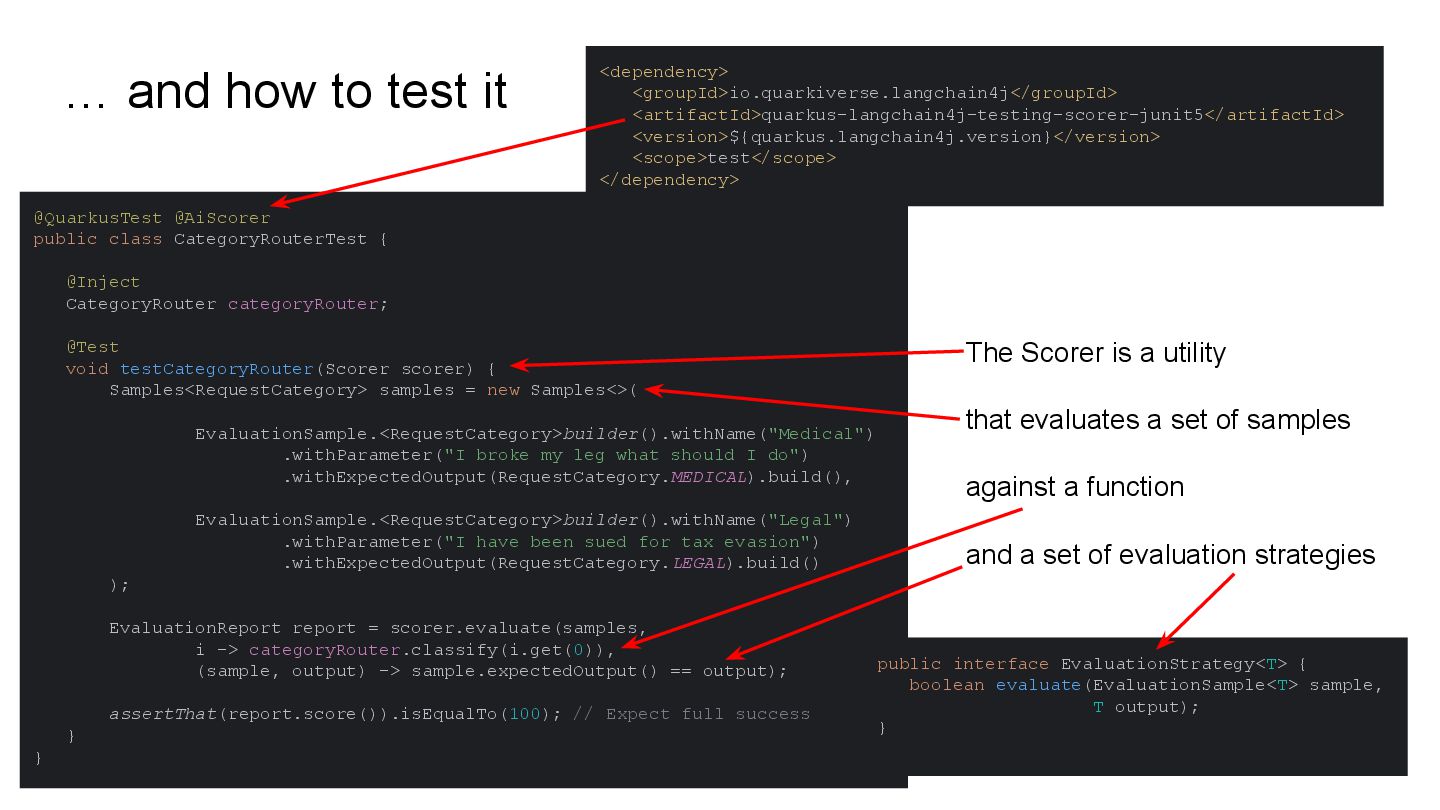
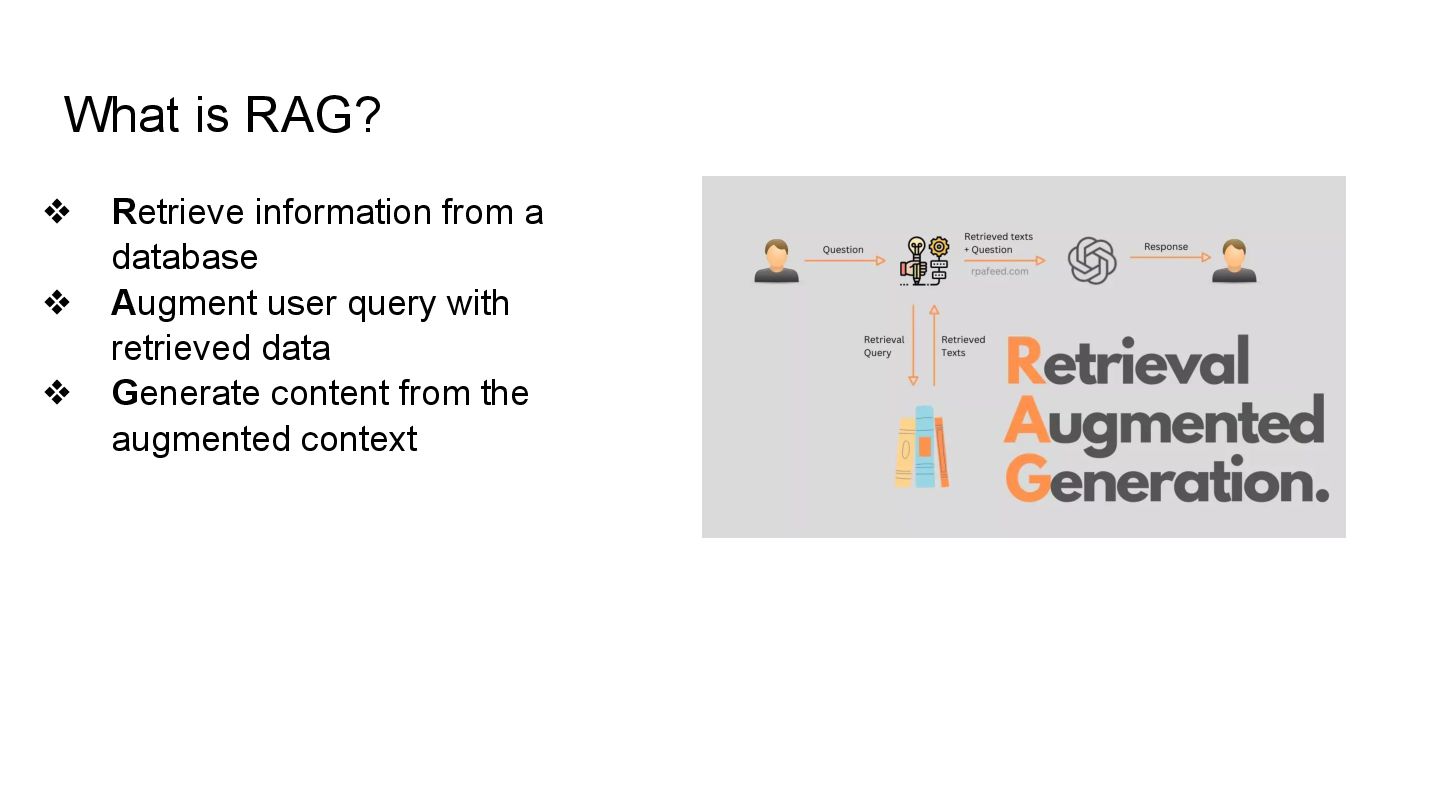
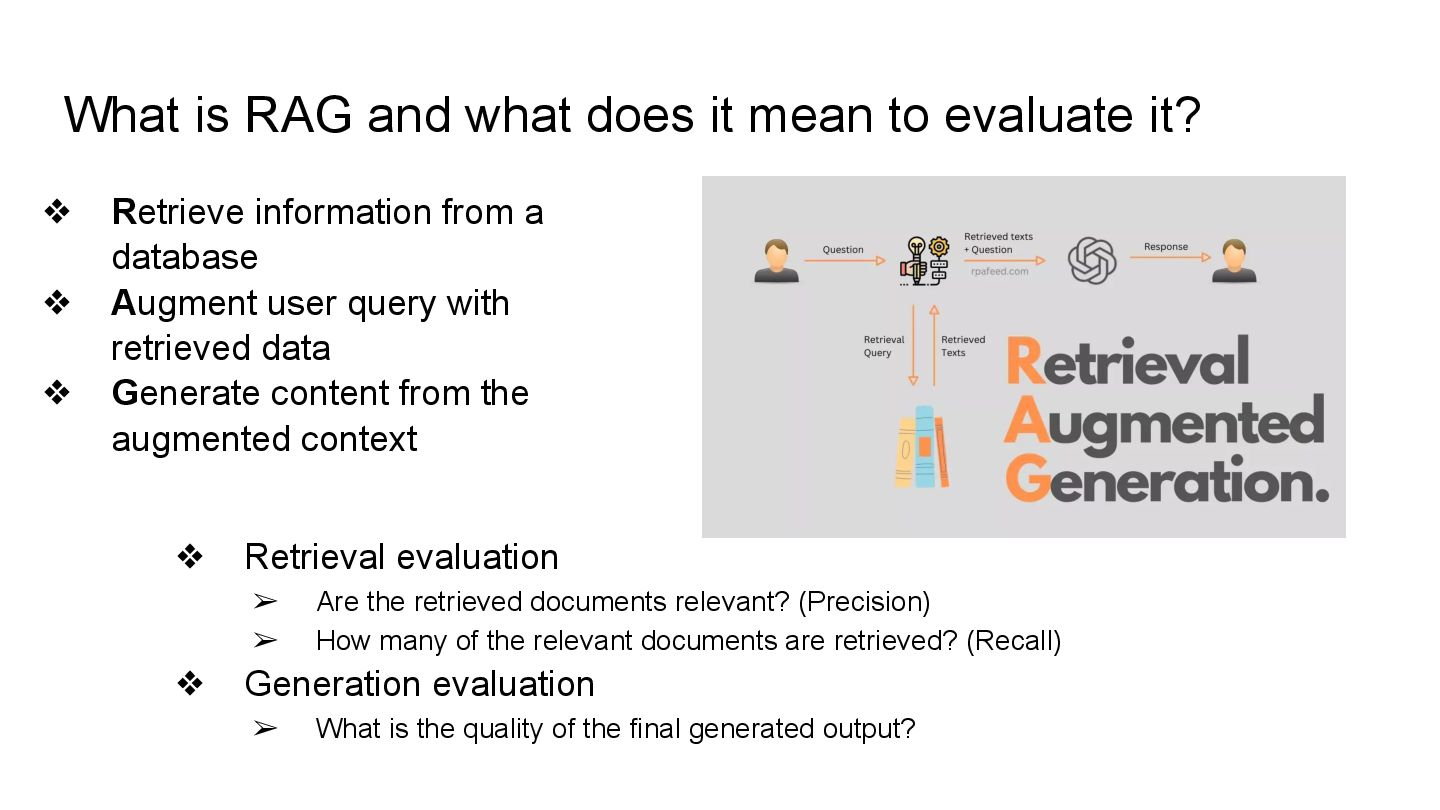
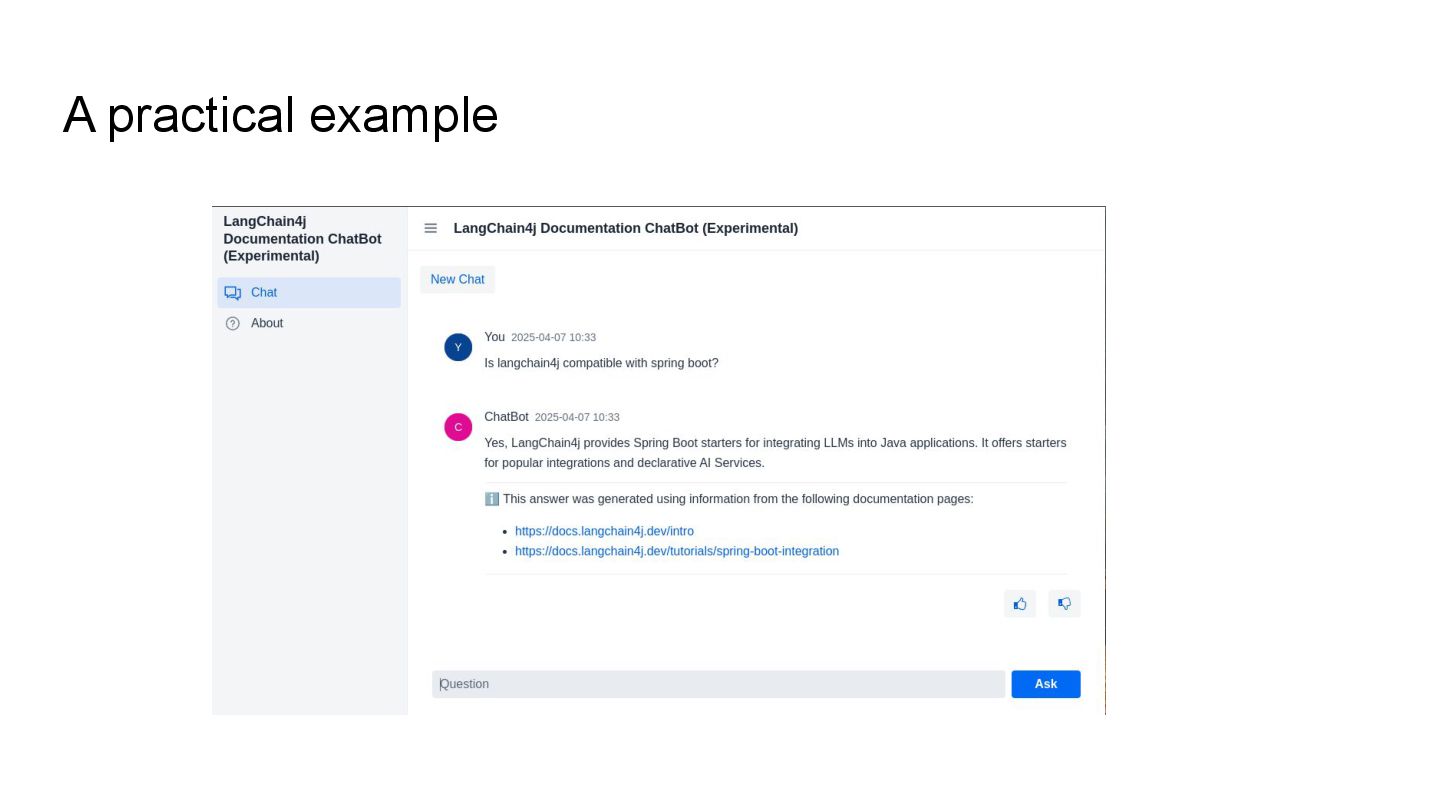
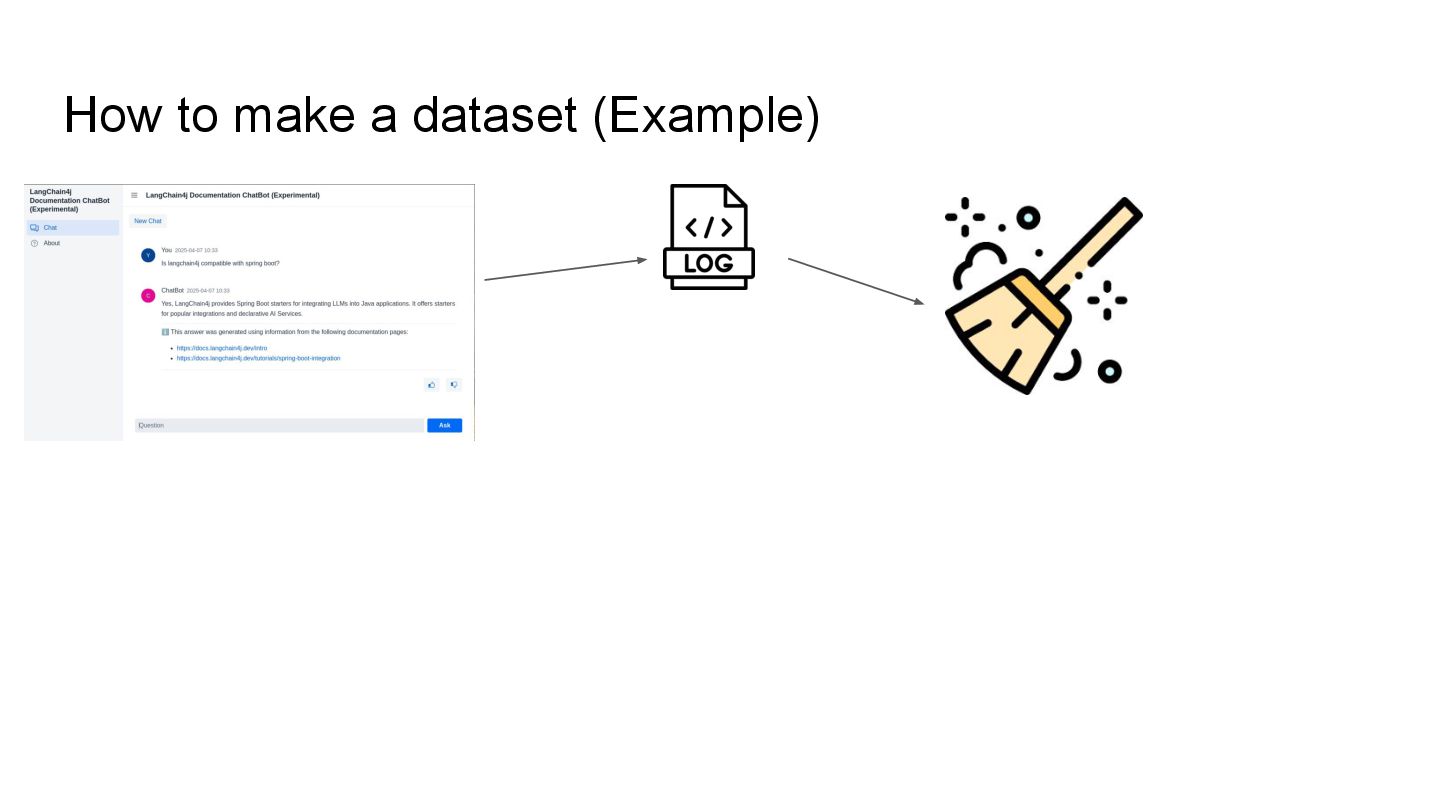
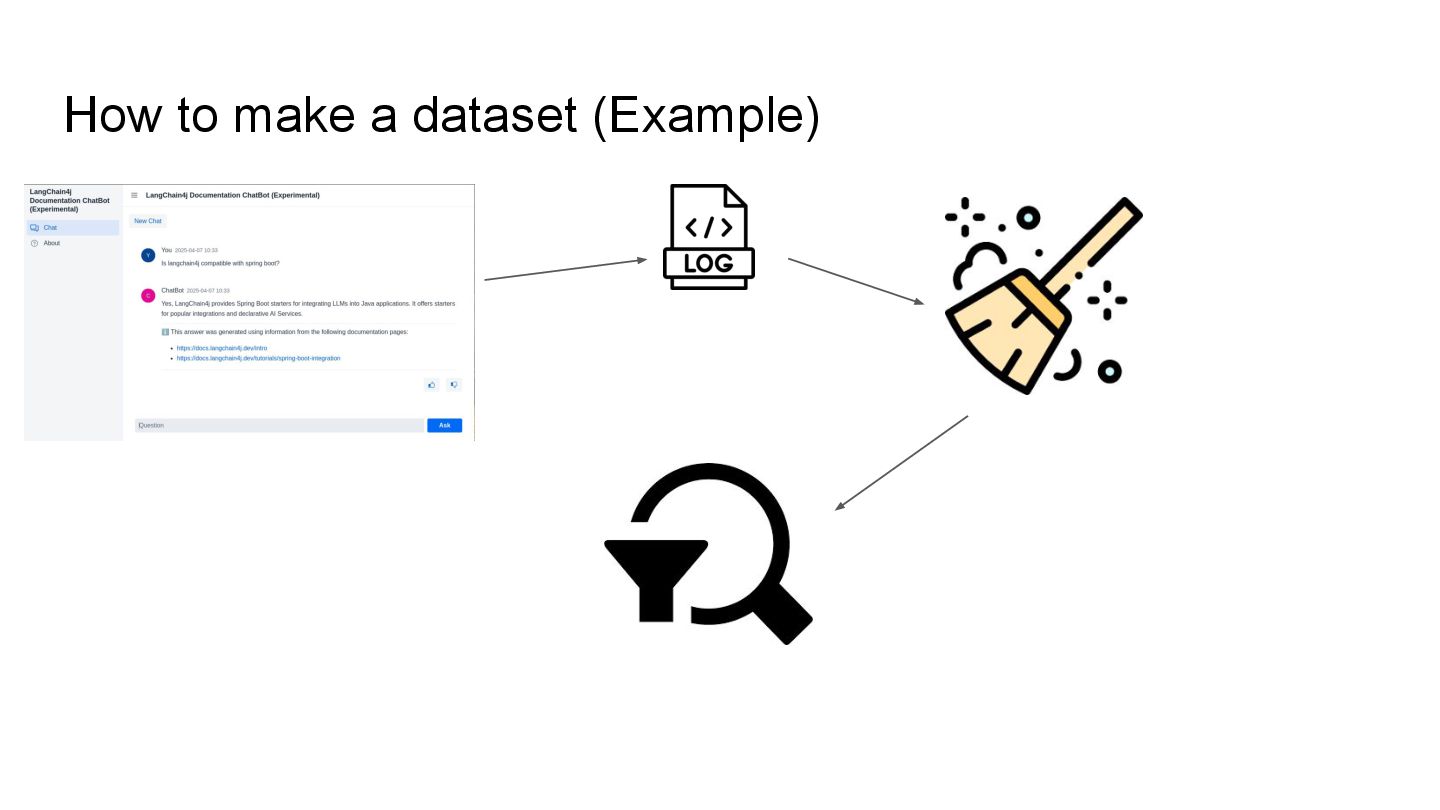
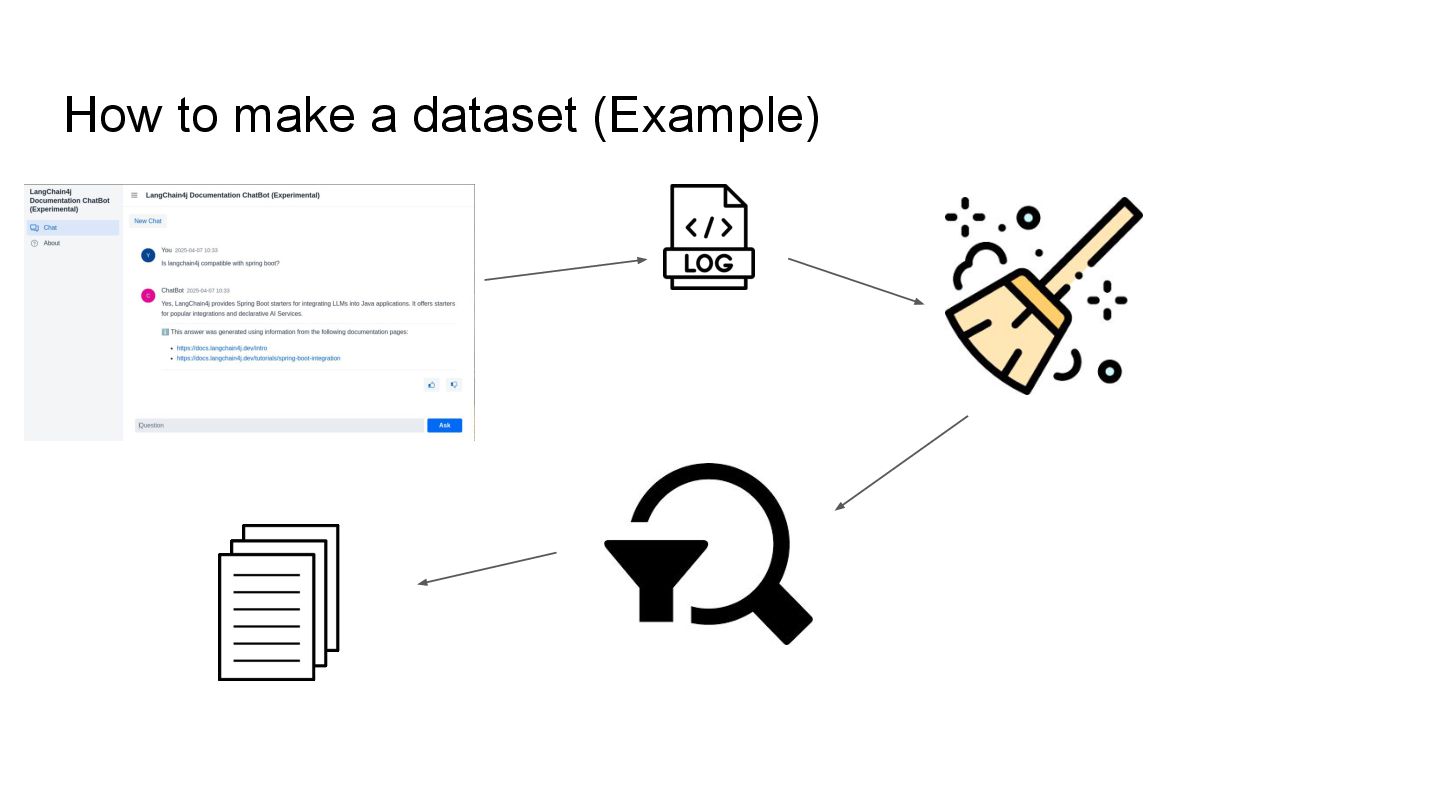
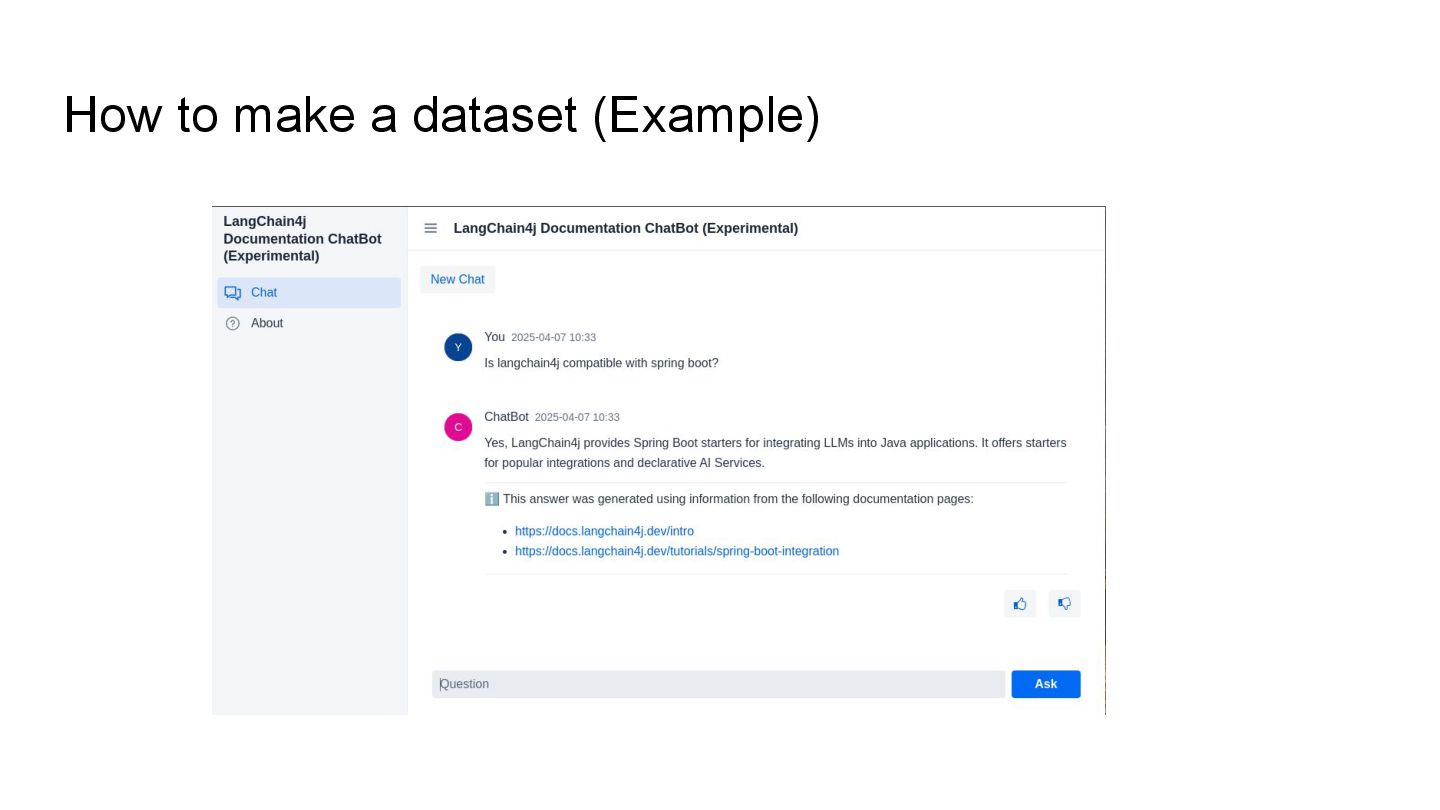
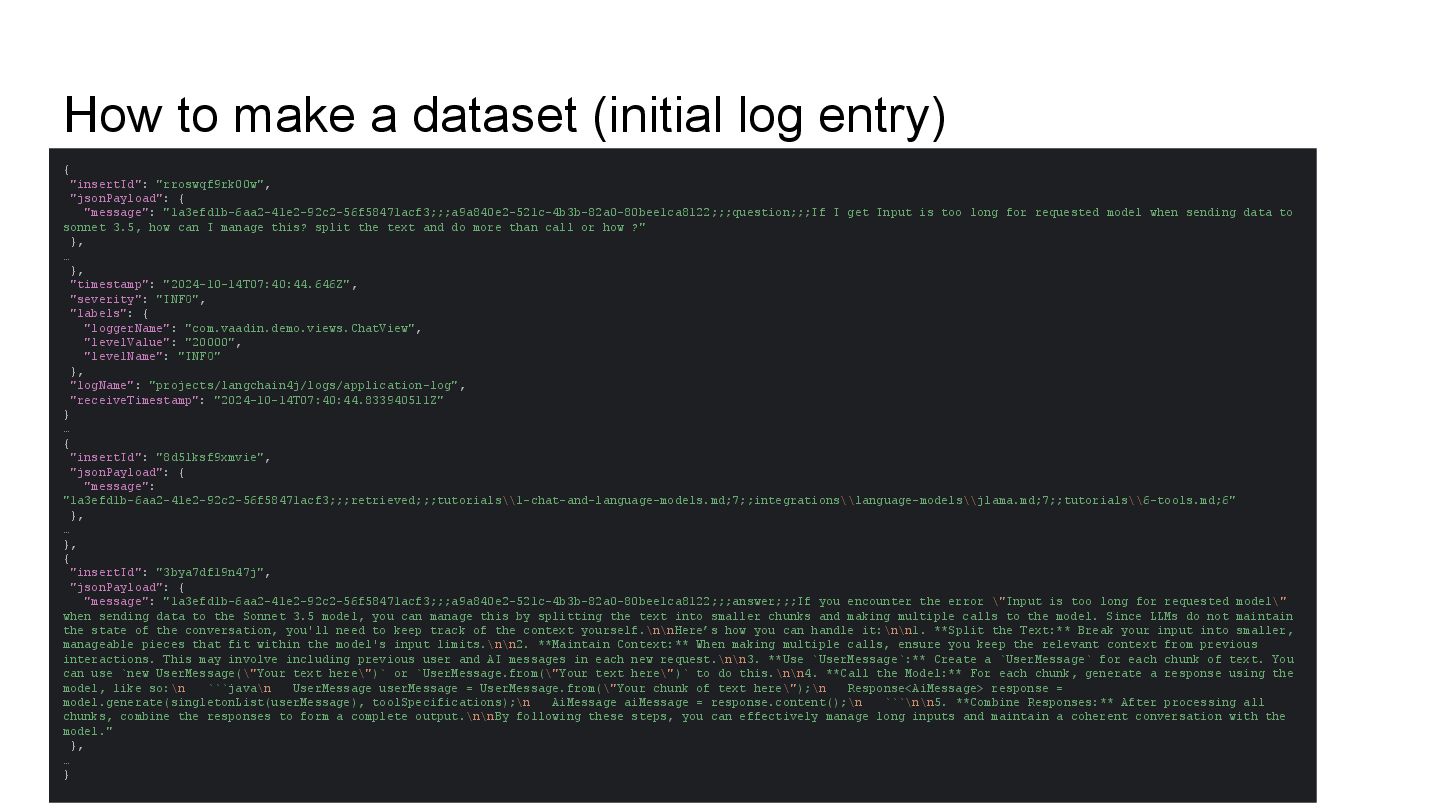
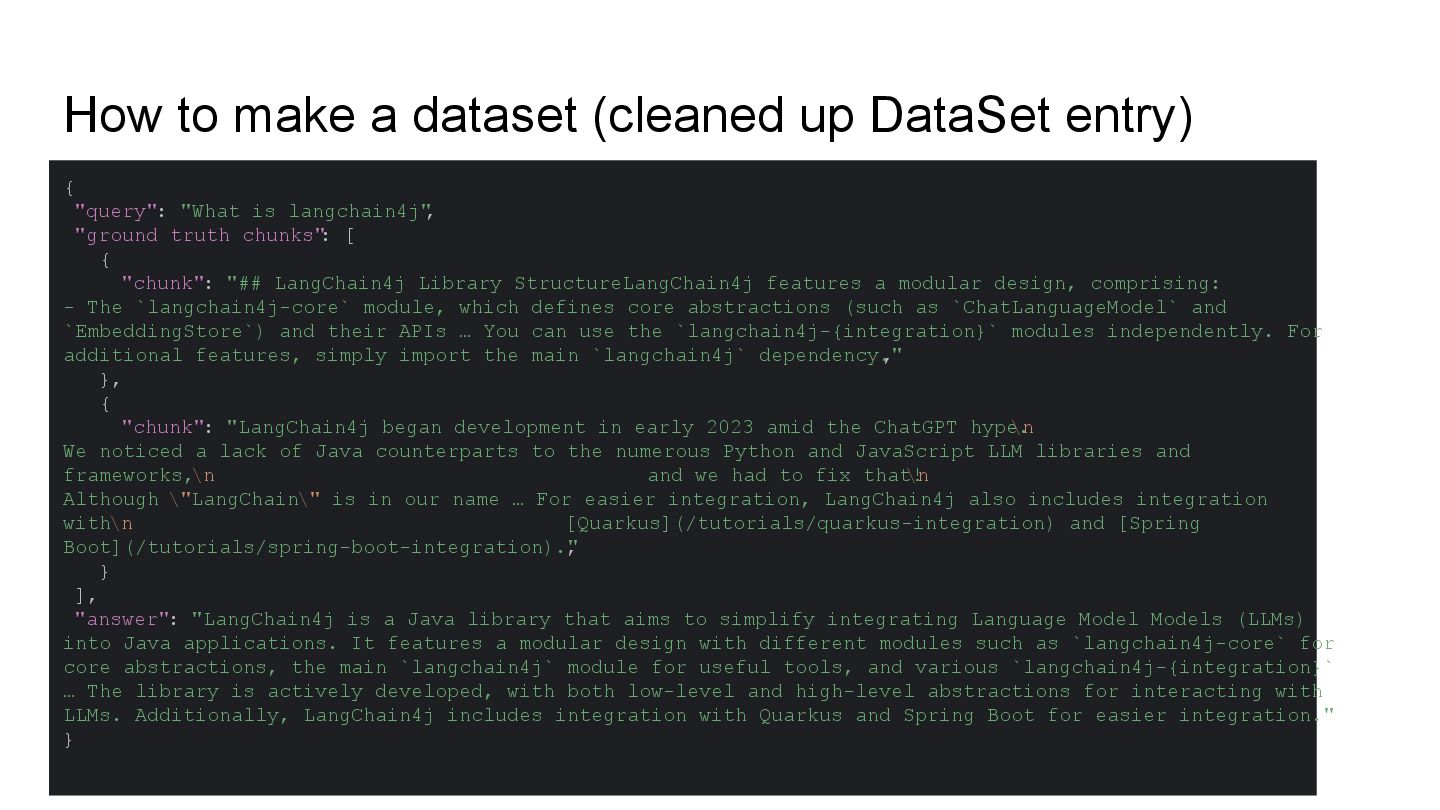
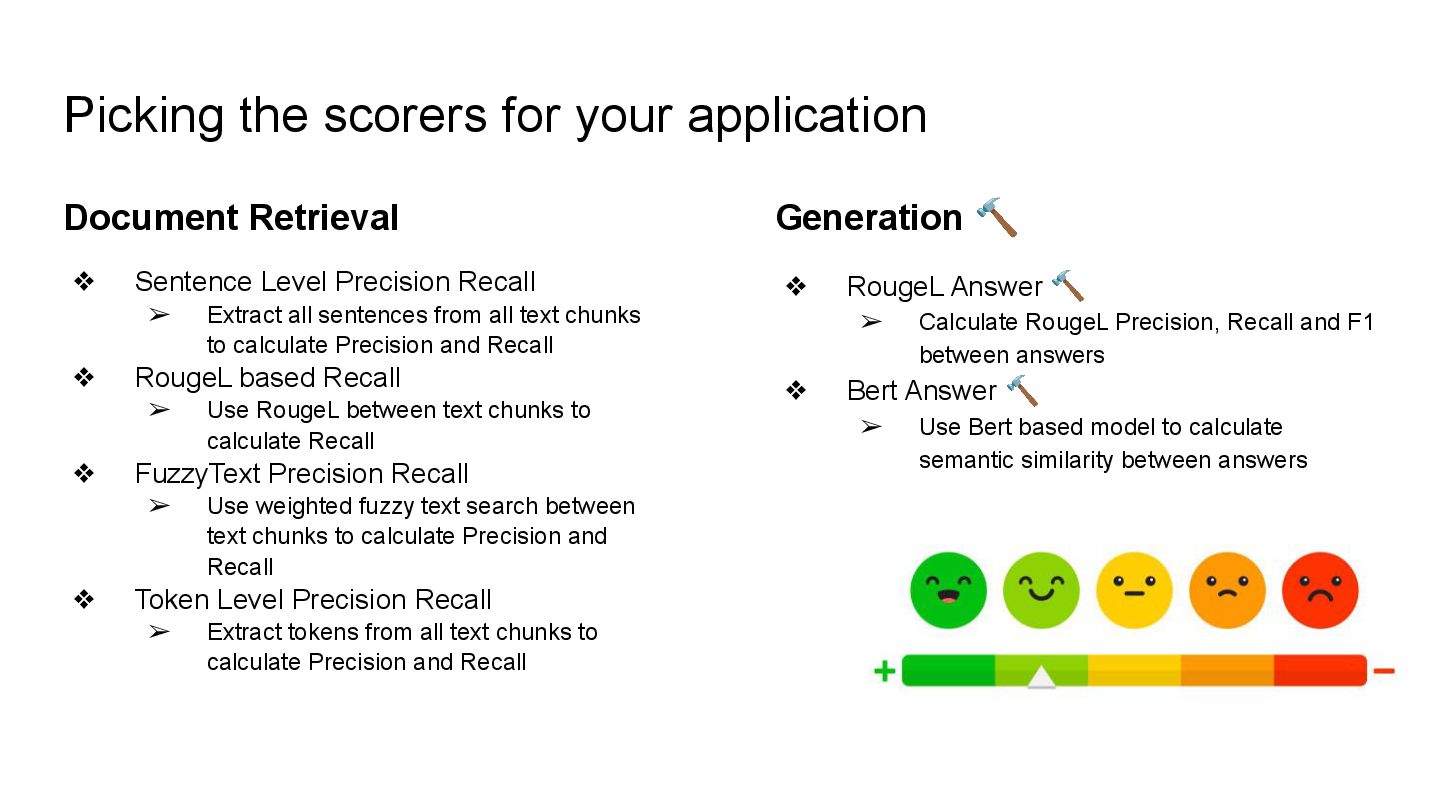
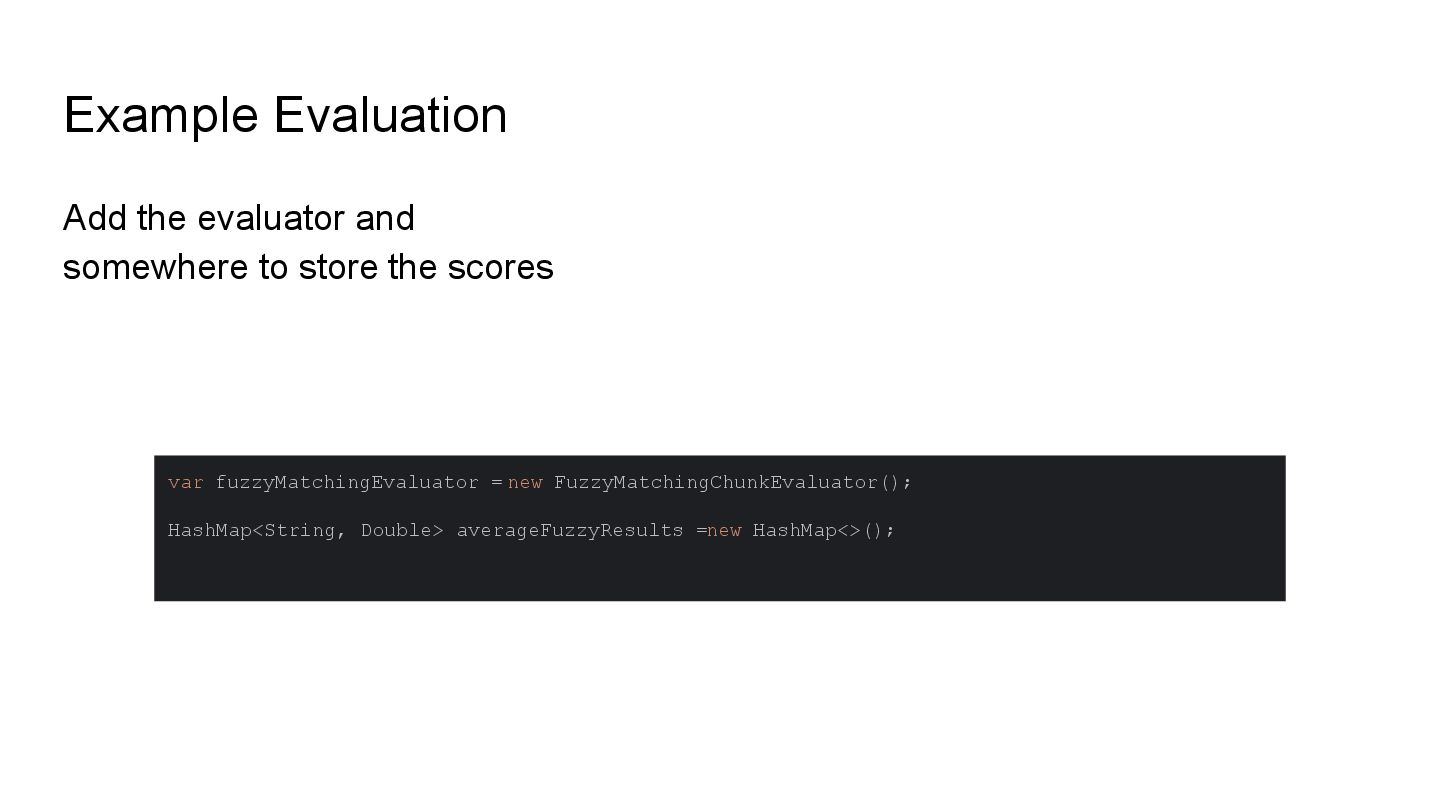
This talk will show in practice how to test a LLM-infused application with a mix of deterministic assertions and an LLM-as-a-judge approach. It will also demonstrate how LangChain4j 1.0 allows us to extensively observe the behavior of this application, and create a dataset out of the collected traces. Finally this dataset will be used in an evaluation framework through which assessing the performance of our RAG assisted LLM chatbot on both its retrieval and generation stages.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}