プロンプトエンジニアリング⼊⾨を以下の資料をもとに講義で解説しました。
⼤規模⾔語モデル(LLM)の可能性を最⼤限に引き出す技術
Prompt Engineering (2025)
Lee Boonstra (Google)
https://www.kaggle.com/whitepaper-prompt-engineering
ビデオはこちら:https://youtu.be/hXlDlVPKjLE
#エージェント #AI #生成AI #プロンプトエンジニアリング
@サプライ・チェイン最適化チャンネル(MIKIO KUBO)
https://www.moai-lab.jp/
https://youtube.com/@kubomikio
https://x.com/MickeyKubo
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![フューショットプロンプトの構造 基本的な形: [タスクの説明 (任意)] 例1: 入力: [入力テキスト1] 出力: [期待される出力1] 例2:](https://files.speakerdeck.com/presentations/c12b72acfd894ed888b4ebd589b71020/slide_17.jpg){kind=link}
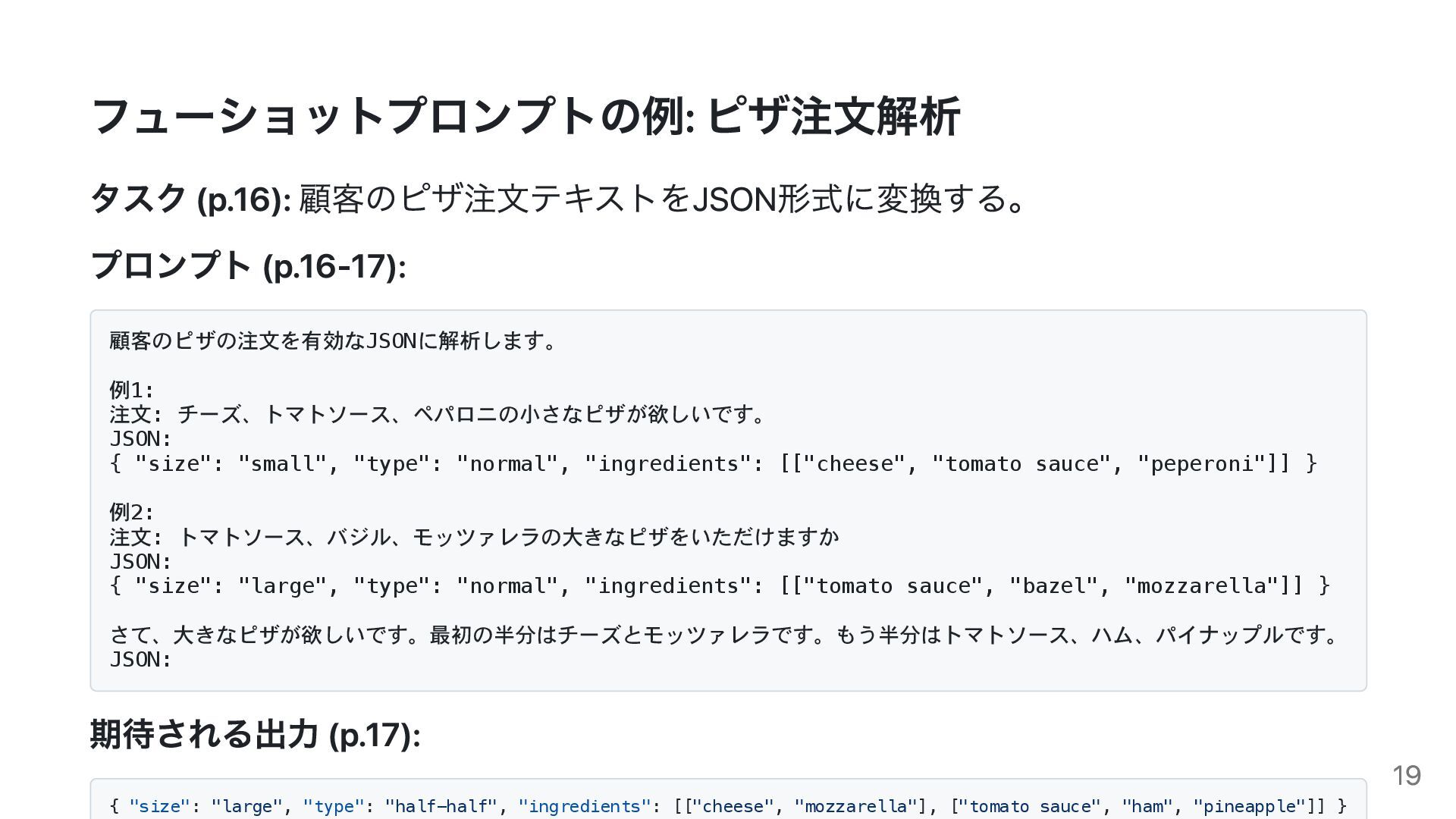{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![セルフコンシステンシーの例: メール分類 タスク (p.32): ウェブサイトのバグを(やや皮肉っぽく)報告するメールを「重要」か 「重要でない」かに分類する。 プロンプト (CoT形式) (p.33): [メール本文]](https://files.speakerdeck.com/presentations/c12b72acfd894ed888b4ebd589b71020/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
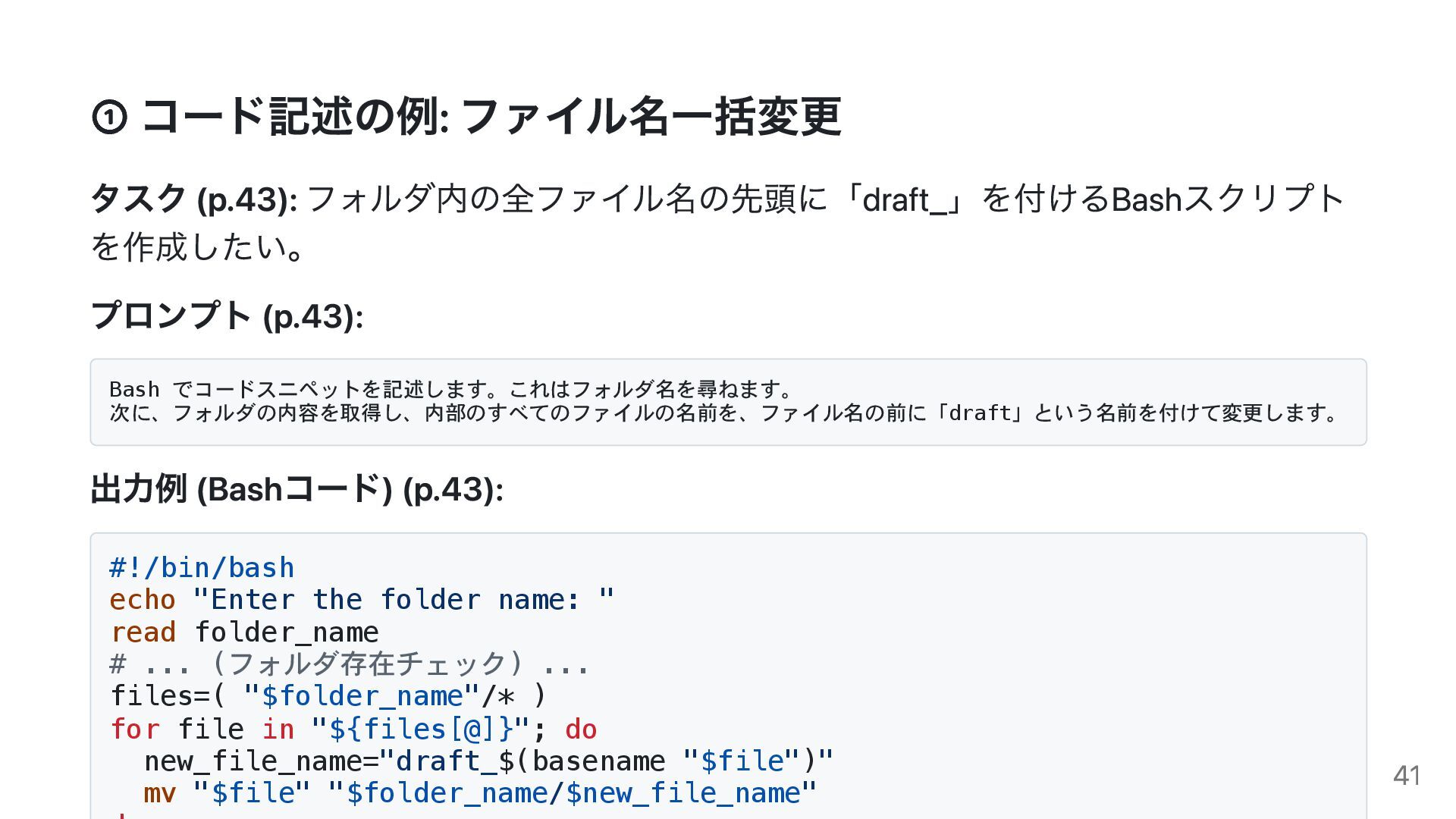{kind=link}
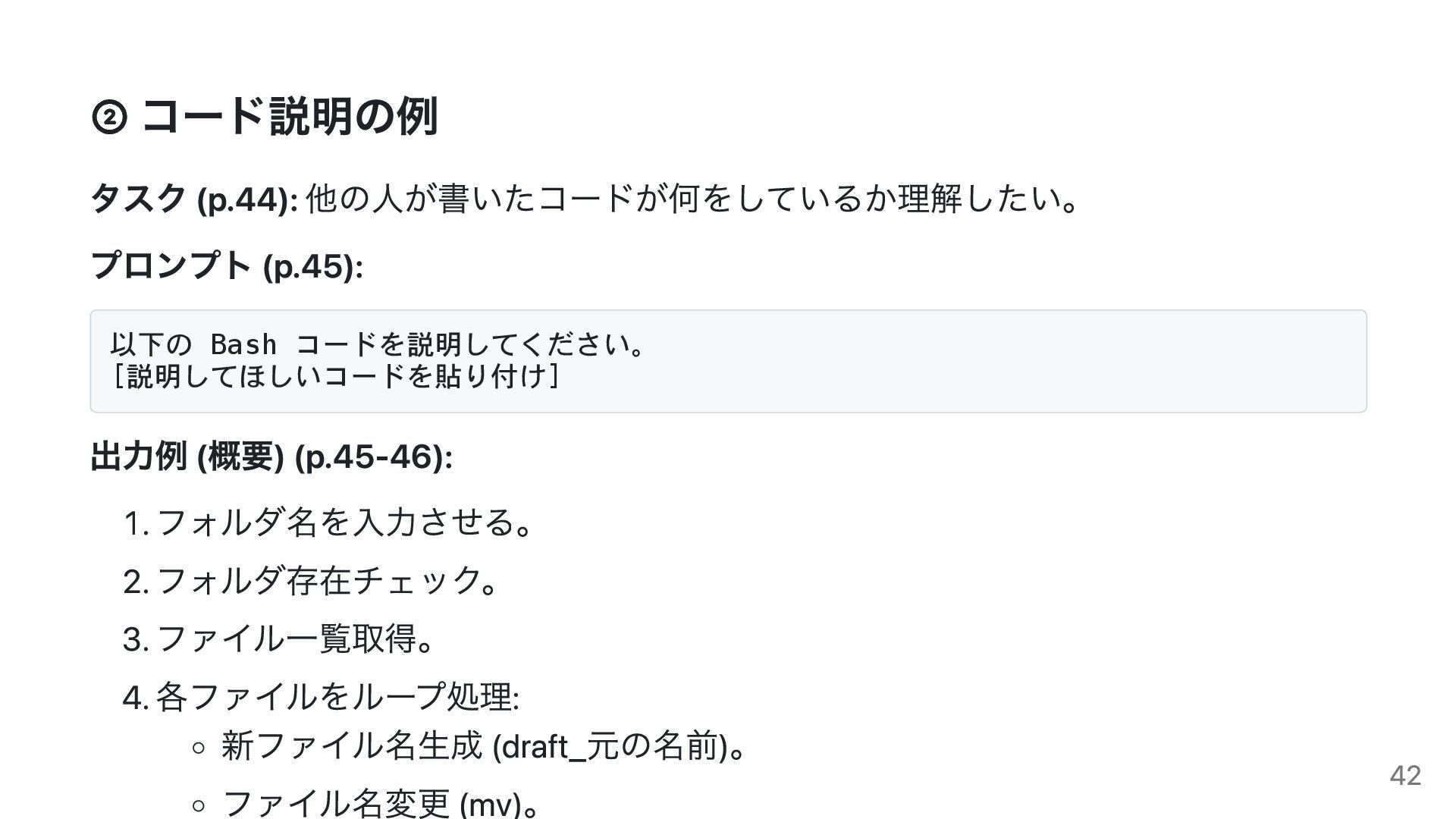{kind=link}
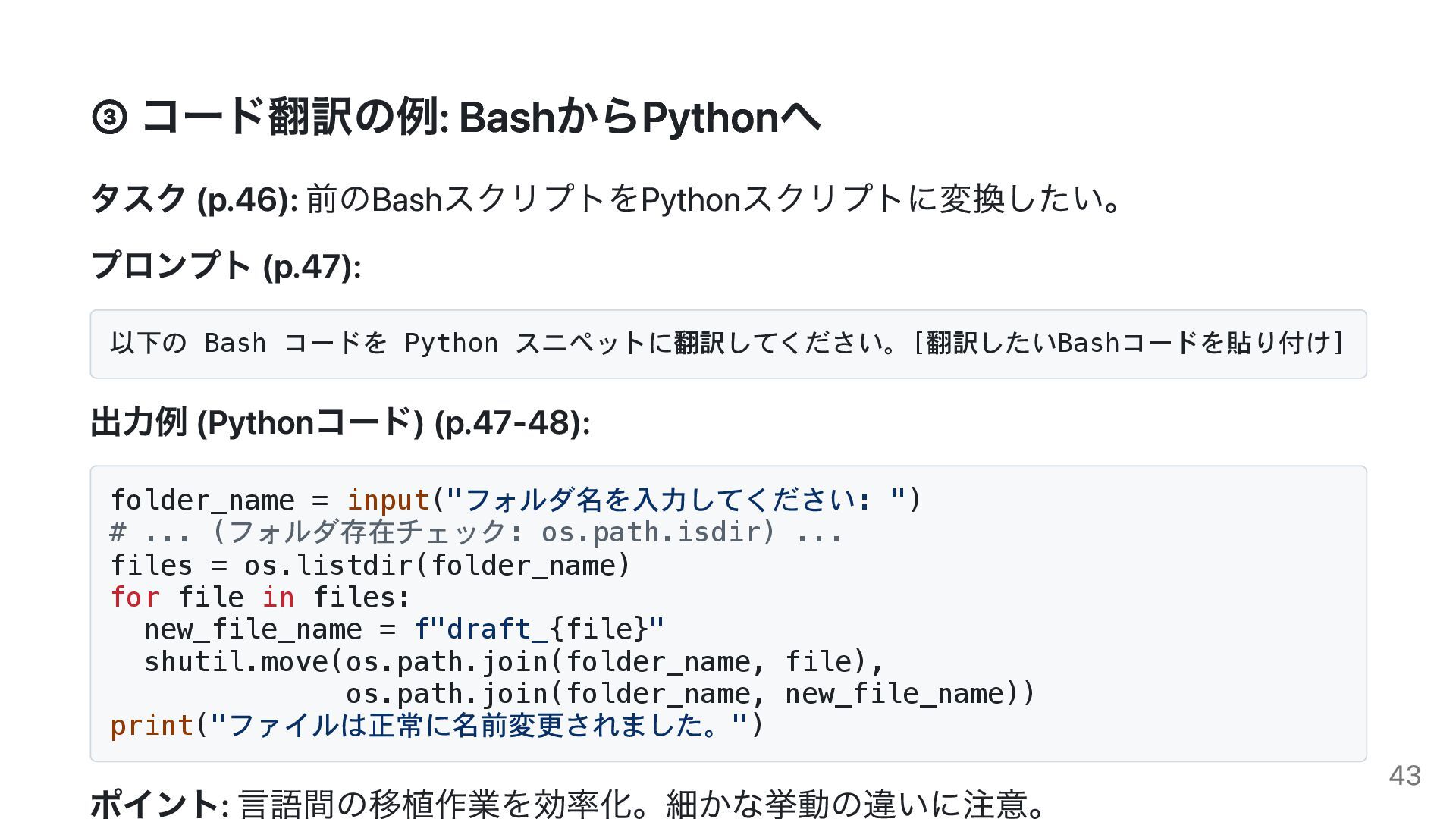{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}