Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
PyMongo入門
Search
MIKIO KUBO
July 10, 2025
Programming
0
40
PyMongo入門
PyMongo入門
## PythonからMongoDBを自由自在に操る
MIKIO KUBO
July 10, 2025
Tweet
Share
More Decks by MIKIO KUBO
See All by MIKIO KUBO
AIを使って最新研究 について調べて発表しよ う!
mickey_kubo
4
23
モダンWeb認証入門
mickey_kubo
1
17
Google Gemini (Gem) の育成方法
mickey_kubo
2
120
最適化ソリューション開発を加速する 数理最適化モデリングツール AMPL 活用セミナー
mickey_kubo
2
22
AMPLとその他のPythonモデラーの違いと優越性
mickey_kubo
3
67
AIエージェントのためのツール設計論 --Anthropic式・評価駆動開発手法の徹底解説
mickey_kubo
1
47
機械学習と数理最適化の融合 (MOAI) による革新
mickey_kubo
1
380
なぜ今最適化か?Agentic AI 時代に最適化 が必要な理由
mickey_kubo
1
70
Agentic AI Era におけるサプライチェーン最適化
mickey_kubo
0
69
Other Decks in Programming
See All in Programming
高度なUI/UXこそHotwireで作ろう Kaigi on Rails 2025
naofumi
4
3.6k
CSC509 Lecture 05
javiergs
PRO
0
300
iOSエンジニア向けの英語学習アプリを作る!
yukawashouhei
0
180
overlayPreferenceValue で実現する ピュア SwiftUI な AdMob ネイティブ広告
uhucream
0
170
Pythonスレッドとは結局何なのか? CPython実装から見るNoGIL時代の変化
curekoshimizu
5
1.5k
実践AIチャットボットUI実装入門
syumai
7
2.5k
CI_CD「健康診断」のススメ。現場でのボトルネック特定から、健康診断を通じた組織的な改善手法
teamlab
PRO
0
190
CSC509 Lecture 02
javiergs
PRO
0
410
Model Pollution
hschwentner
1
190
Reduxモダナイズ 〜コードのモダン化を通して、将来のライブラリ移行に備える〜
pvcresin
2
690
iOSエンジニア向けの英語学習アプリを作る!
yukawashouhei
0
180
CSC305 Lecture 03
javiergs
PRO
0
240
Featured
See All Featured
Measuring & Analyzing Core Web Vitals
bluesmoon
9
610
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
30
2.9k
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
9
850
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
657
61k
Documentation Writing (for coders)
carmenintech
75
5k
Product Roadmaps are Hard
iamctodd
PRO
54
11k
Keith and Marios Guide to Fast Websites
keithpitt
411
22k
The Straight Up "How To Draw Better" Workshop
denniskardys
237
140k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
140
34k
For a Future-Friendly Web
brad_frost
180
9.9k
Building Adaptive Systems
keathley
43
2.8k
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
Transcript
PyMongo 入門 Python からMongoDB を自由自在に操る 1
PyMongo ってなに? Python からMongoDB を操作するための公式ドライバーです。 公式ドライバーとは? MongoDBの開発元が自ら開発・メンテナンスしています。 信頼性・安定性・安全性が高い! 最新のMongoDB機能にすぐ対応します。 何ができるの?
Pythonのコードから、MongoDBへの接続、データの追加・検索・更新・削除などができます。 2
なぜPyMongo を選ぶの? 圧倒的な信頼性 公式サポートなので、長期的に安心して使えます。 豊富なドキュメントと活発なコミュニティがあります。 優れた多用途性 Webアプリ、データ分析、バッチ処理など、どんなPythonプロジェクトでも活躍します。 データサイエンスとの連携 人気のデータ分析ライブラリ pandas
と相性抜群です。 MongoDBのデータを簡単に分析・機械学習のワークフローに組み込めます。 3
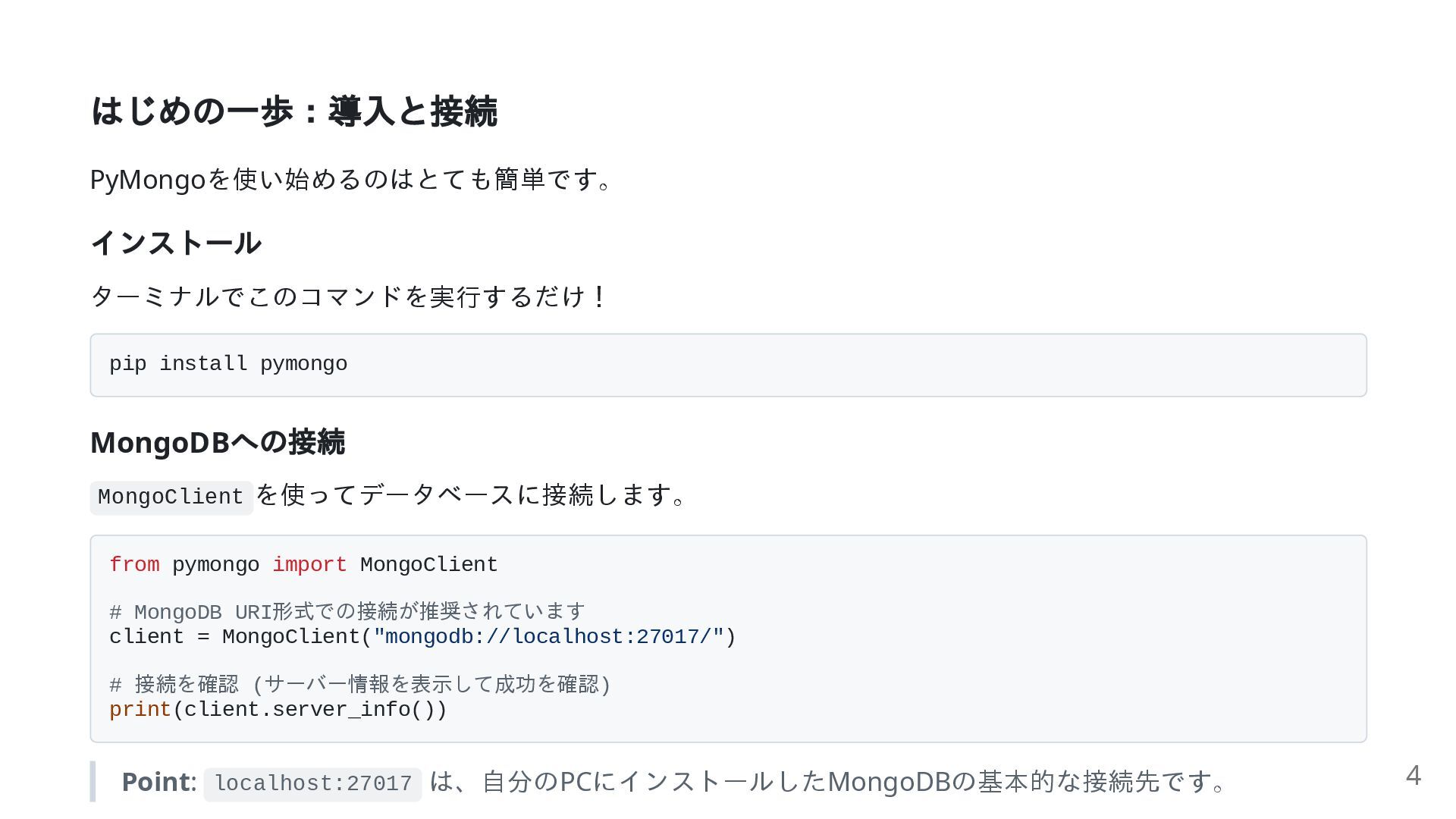
はじめの一歩:導入と接続 PyMongoを使い始めるのはとても簡単です。 インストール ターミナルでこのコマンドを実行するだけ! pip install pymongo MongoDB への接続 MongoClient
を使ってデータベースに接続します。 from pymongo import MongoClient # MongoDB URI形式での接続が推奨されています client = MongoClient("mongodb://localhost:27017/") # 接続を確認 (サーバー情報を表示して成功を確認) print(client.server_info()) Point: localhost:27017 は、自分のPCにインストールしたMongoDBの基本的な接続先です。 4
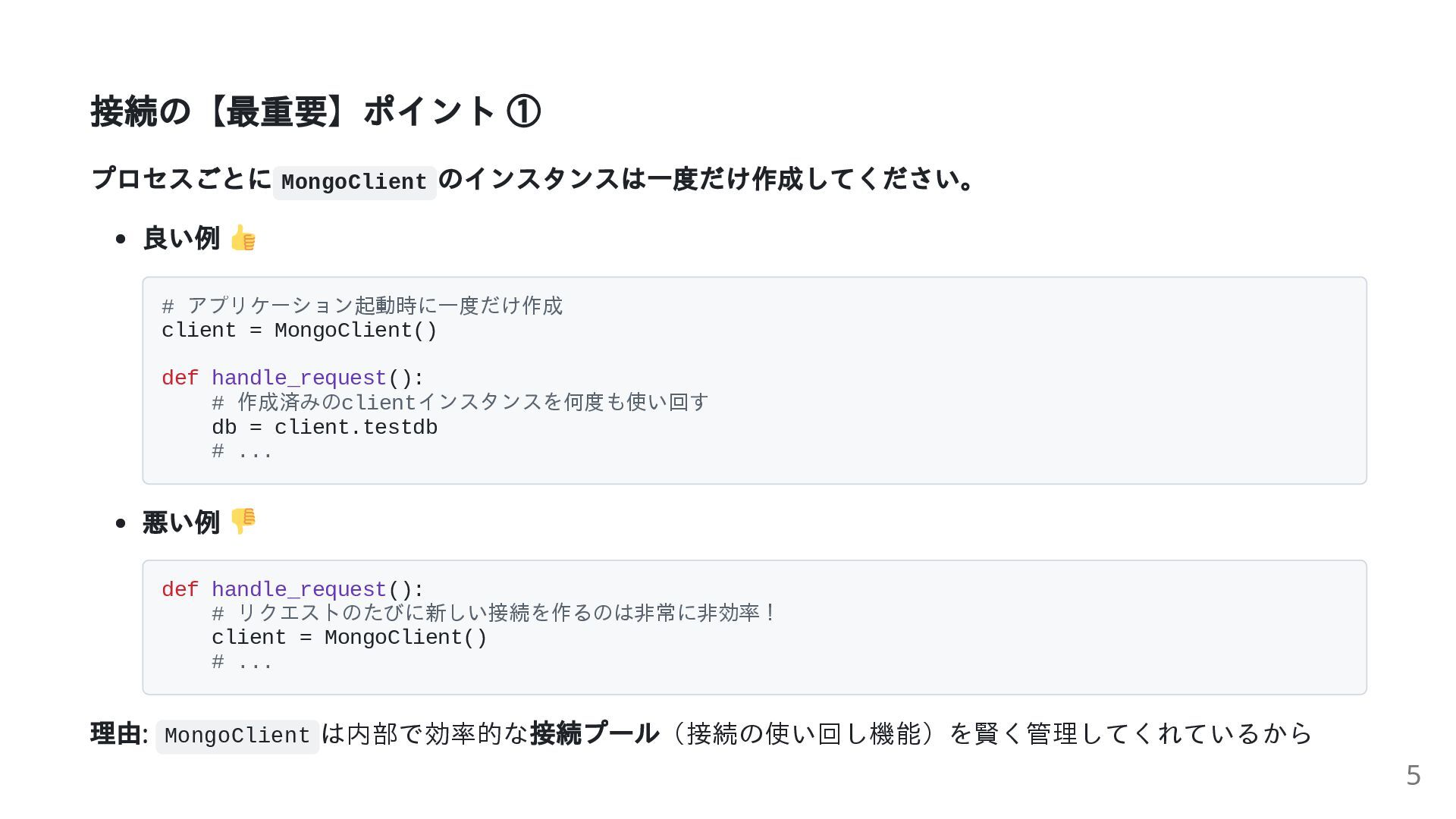
接続の【最重要】ポイント ① プロセスごとに MongoClient のインスタンスは一度だけ作成してください。 良い例 # アプリケーション起動時に一度だけ作成 client =
MongoClient() def handle_request(): # 作成済みのclientインスタンスを何度も使い回す db = client.testdb # ... 悪い例 def handle_request(): # リクエストのたびに新しい接続を作るのは非常に非効率! client = MongoClient() # ... 理由: MongoClient は内部で効率的な 接続プール(接続の使い回し機能)を賢く管理してくれているから 5
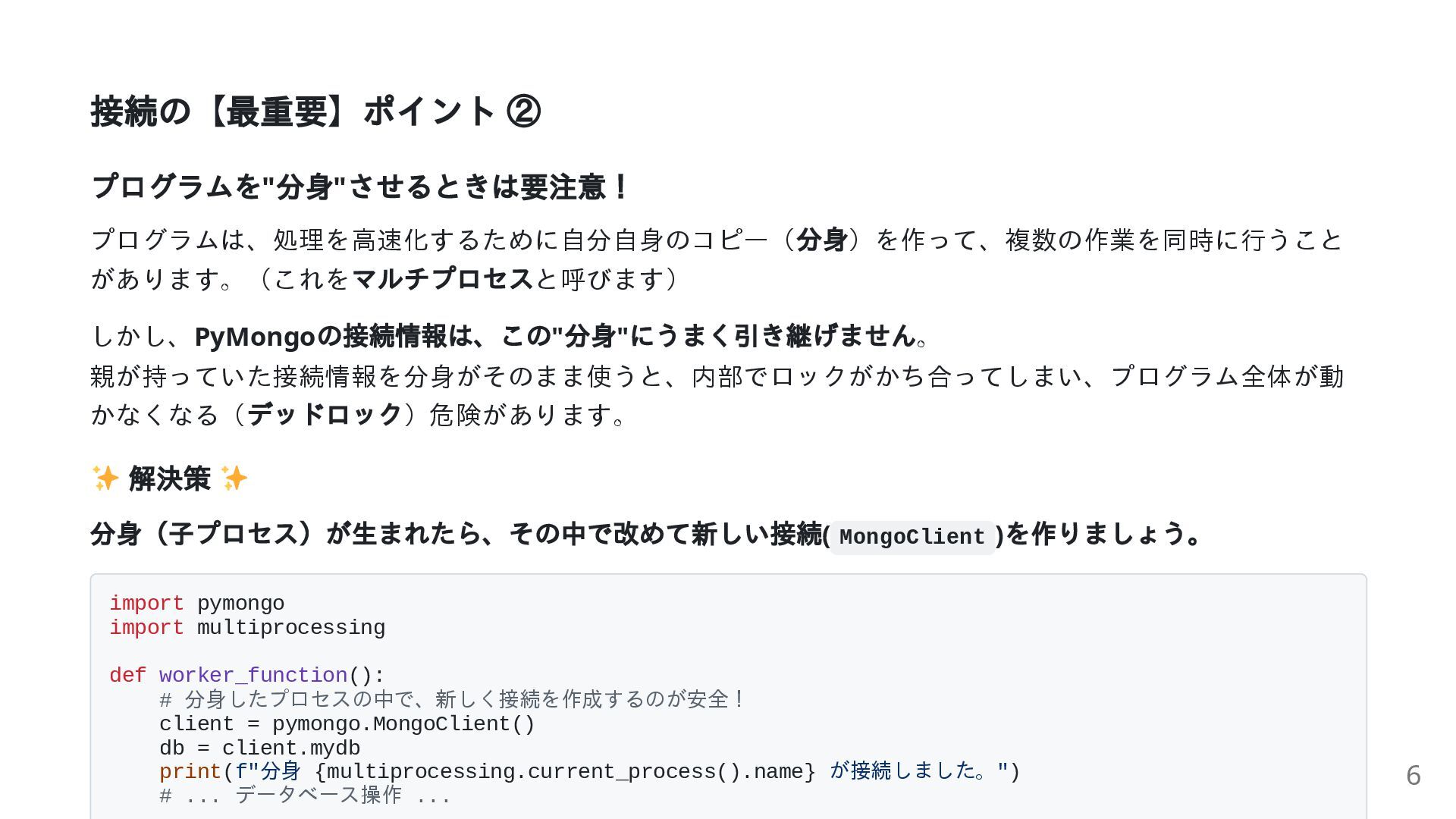
接続の【最重要】ポイント ② プログラムを" 分身" させるときは要注意! プログラムは、処理を高速化するために自分自身のコピー( 分身)を作って、複数の作業を同時に行うこと があります。(これを マルチプロセスと呼びます) しかし、PyMongo
の接続情報は、この" 分身" にうまく引き継げません。 親が持っていた接続情報を分身がそのまま使うと、内部でロックがかち合ってしまい、プログラム全体が動 かなくなる( デッドロック)危険があります。 解決策 分身(子プロセス)が生まれたら、その中で改めて新しい接続( MongoClient ) を作りましょう。 import pymongo import multiprocessing def worker_function(): # 分身したプロセスの中で、新しく接続を作成するのが安全! client = pymongo.MongoClient() db = client.mydb print(f"分身 {multiprocessing.current_process().name} が接続しました。") # ... データベース操作 ... 6
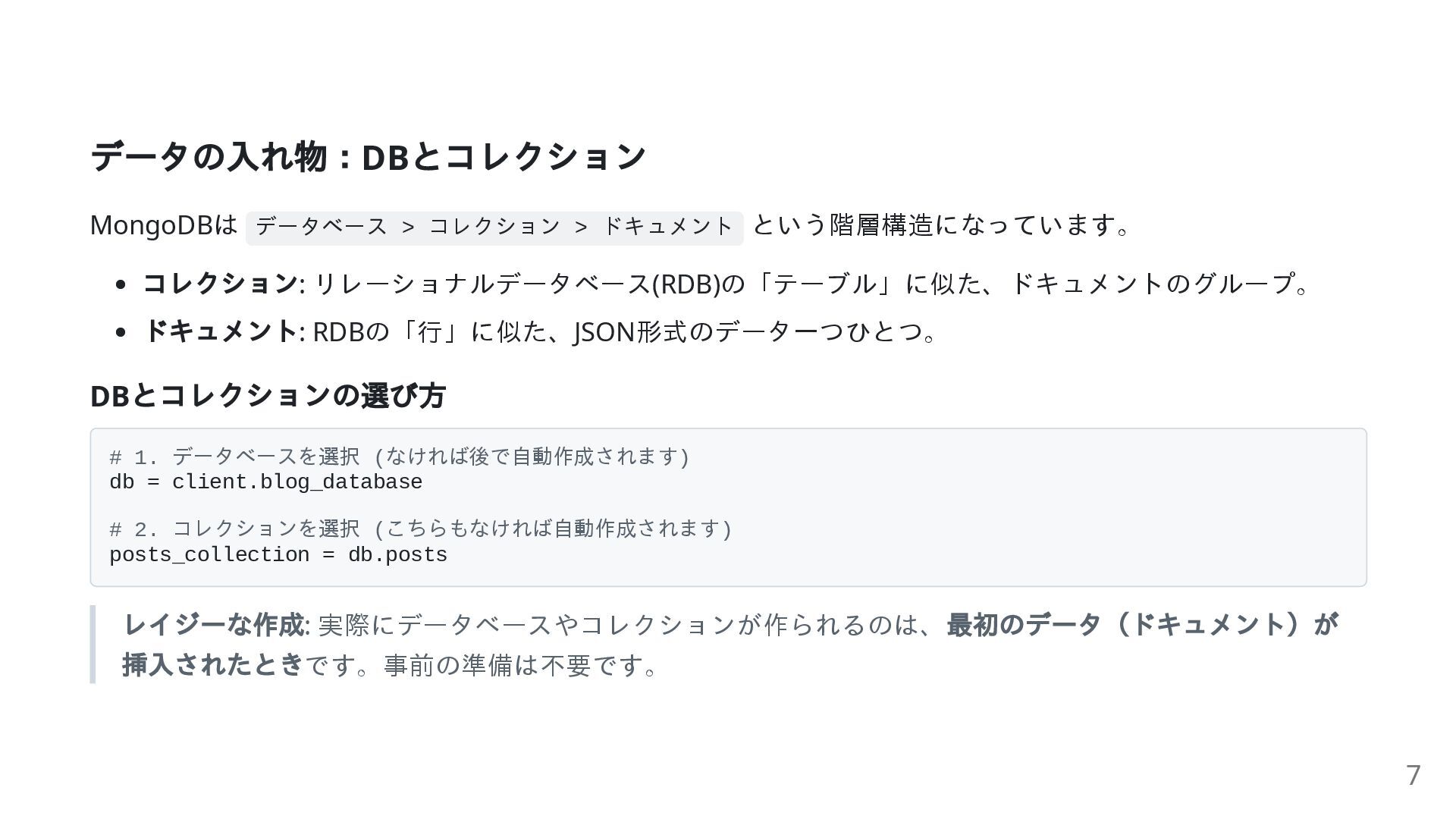
データの入れ物:DB とコレクション MongoDBは データベース > コレクション > ドキュメント という階層構造になっています。 コレクション:
リレーショナルデータベース(RDB)の「テーブル」に似た、ドキュメントのグループ。 ドキュメント: RDBの「行」に似た、JSON形式のデータ一つひとつ。 DB とコレクションの選び方 # 1. データベースを選択 (なければ後で自動作成されます) db = client.blog_database # 2. コレクションを選択 (こちらもなければ自動作成されます) posts_collection = db.posts レイジーな作成: 実際にデータベースやコレクションが作られるのは、 最初のデータ(ドキュメント)が 挿入されたときです。事前の準備は不要です。 7
基本のキ:データの操作 (CRUD) データの Create(作成), Read(読込), Update(更新), Delete(削除) を見ていきましょう。 8
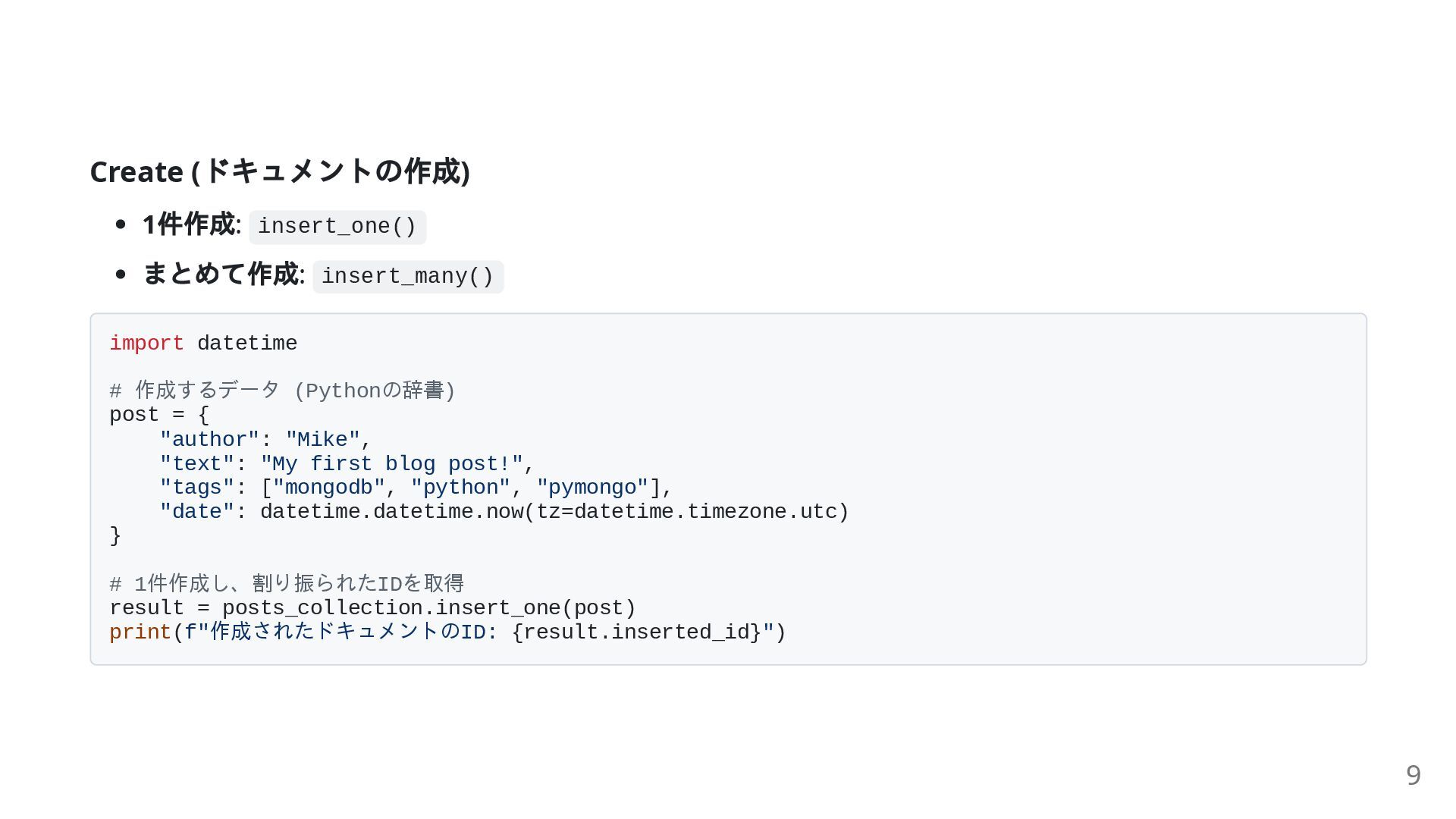
Create ( ドキュメントの作成) 1 件作成: insert_one() まとめて作成: insert_many() import datetime
# 作成するデータ (Pythonの辞書) post = { "author": "Mike", "text": "My first blog post!", "tags": ["mongodb", "python", "pymongo"], "date": datetime.datetime.now(tz=datetime.timezone.utc) } # 1件作成し、割り振られたIDを取得 result = posts_collection.insert_one(post) print(f"作成されたドキュメントのID: {result.inserted_id}") 9
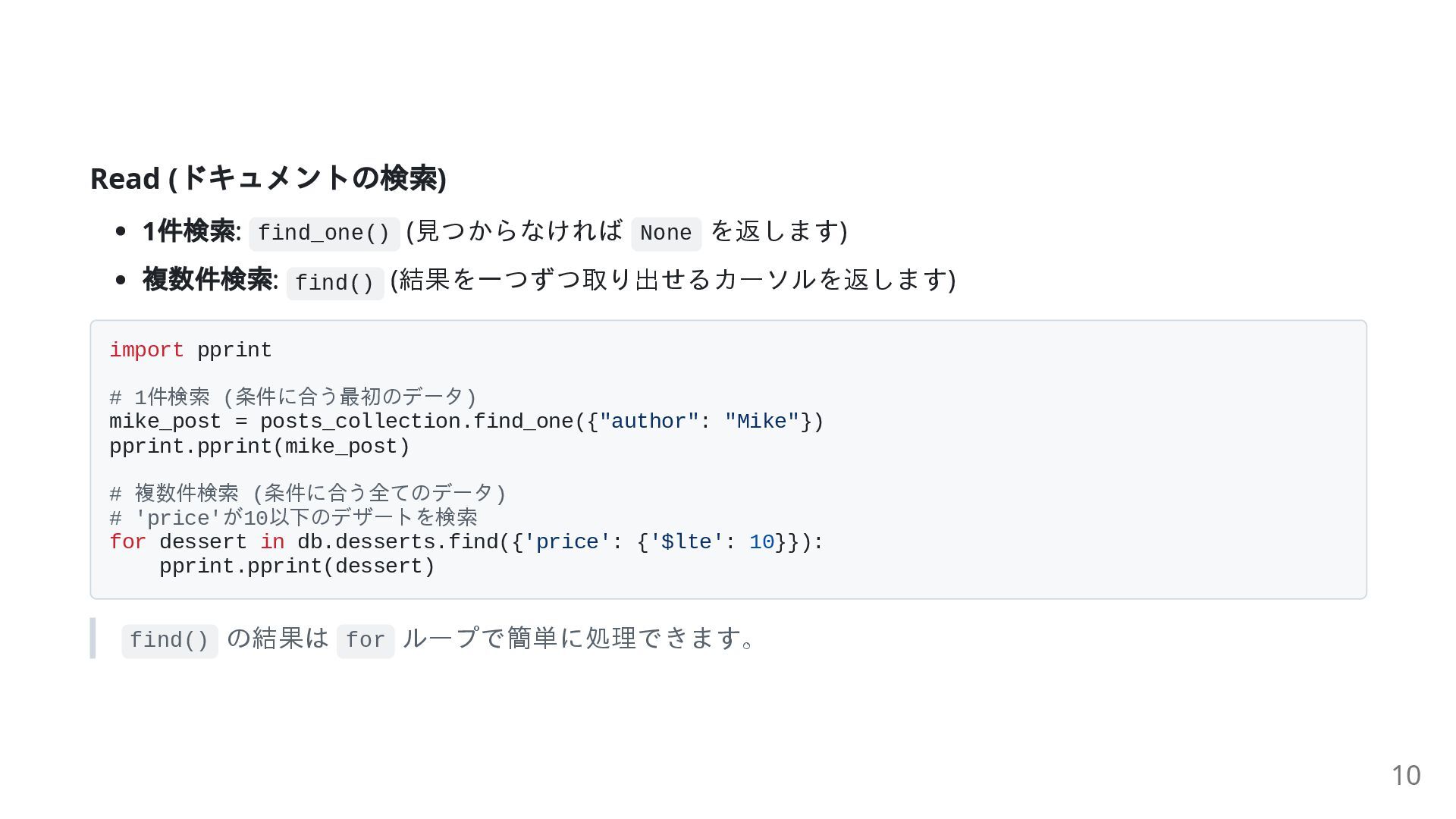
Read ( ドキュメントの検索) 1 件検索: find_one() (見つからなければ None を返します) 複数件検索:
find() (結果を一つずつ取り出せるカーソルを返します) import pprint # 1件検索 (条件に合う最初のデータ) mike_post = posts_collection.find_one({"author": "Mike"}) pprint.pprint(mike_post) # 複数件検索 (条件に合う全てのデータ) # 'price'が10以下のデザートを検索 for dessert in db.desserts.find({'price': {'$lte': 10}}): pprint.pprint(dessert) find() の結果は for ループで簡単に処理できます。 10
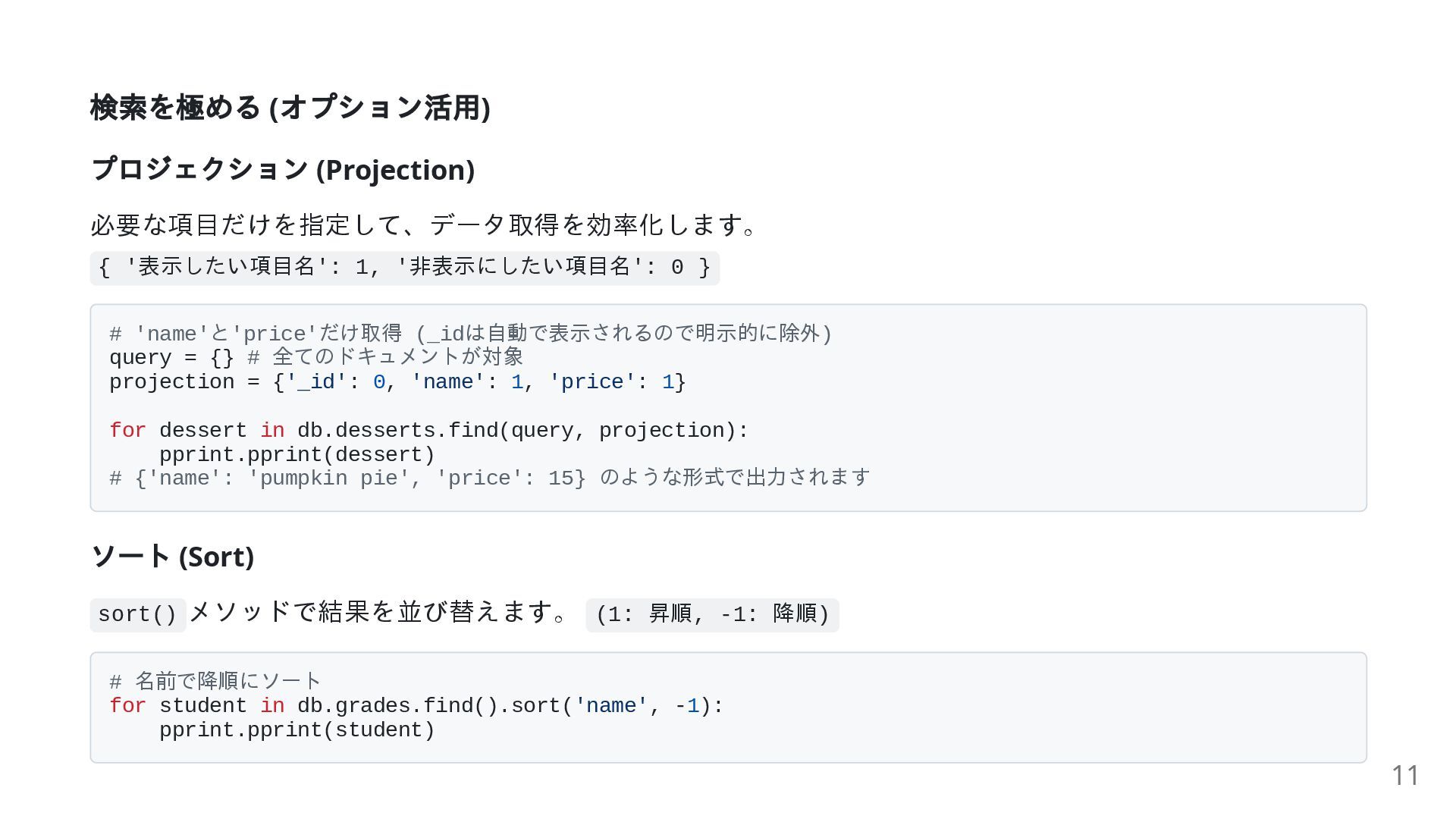
検索を極める ( オプション活用) プロジェクション (Projection) 必要な項目だけを指定して、データ取得を効率化します。 { '表示したい項目名': 1, '非表示にしたい項目名':
0 } # 'name'と'price'だけ取得 (_idは自動で表示されるので明示的に除外) query = {} # 全てのドキュメントが対象 projection = {'_id': 0, 'name': 1, 'price': 1} for dessert in db.desserts.find(query, projection): pprint.pprint(dessert) # {'name': 'pumpkin pie', 'price': 15} のような形式で出力されます ソート (Sort) sort() メソッドで結果を並び替えます。 (1: 昇順, -1: 降順) # 名前で降順にソート for student in db.grades.find().sort('name', -1): pprint.pprint(student) 11
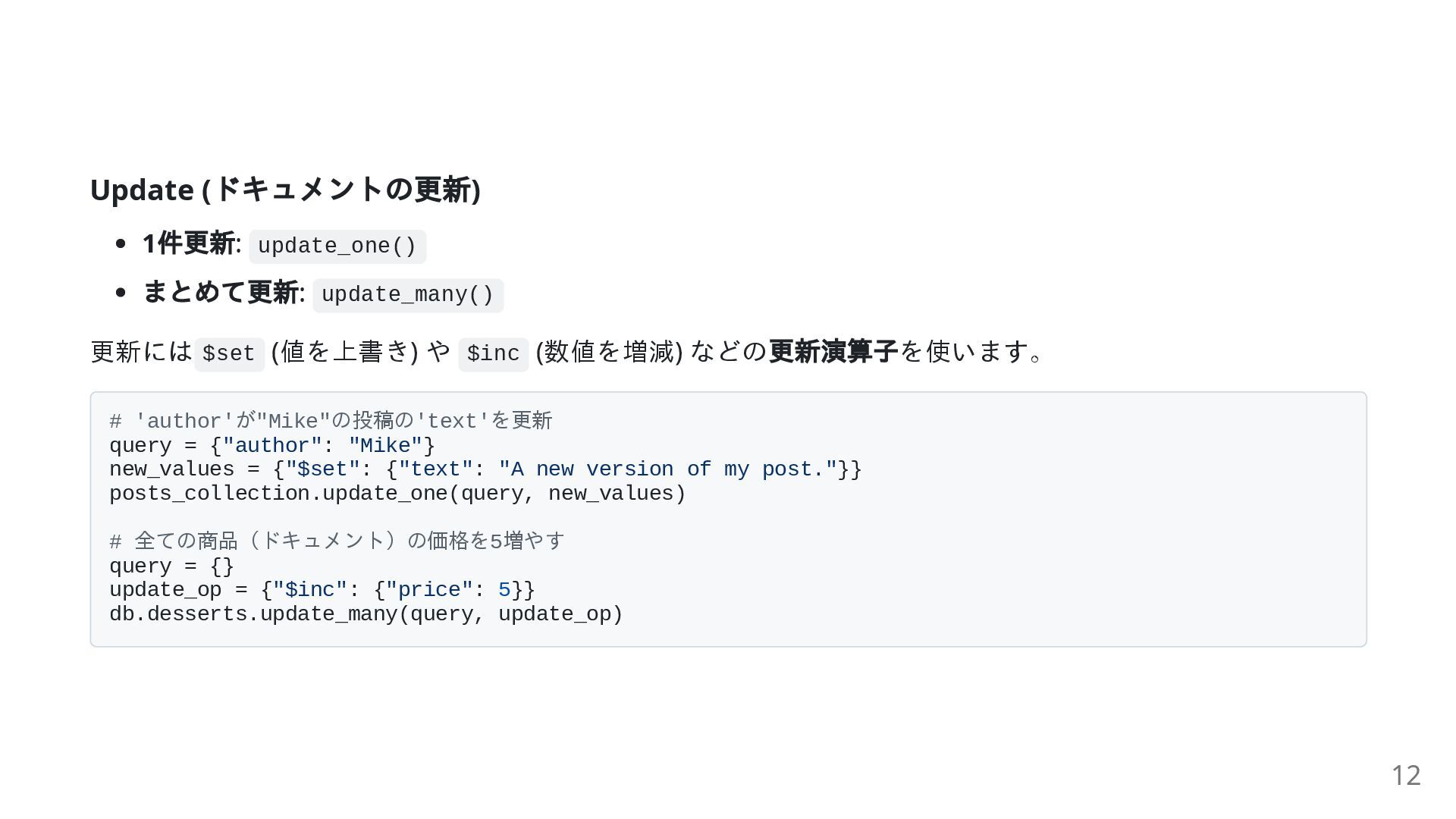
Update ( ドキュメントの更新) 1 件更新: update_one() まとめて更新: update_many() 更新には $set
(値を上書き) や $inc (数値を増減) などの 更新演算子を使います。 # 'author'が"Mike"の投稿の'text'を更新 query = {"author": "Mike"} new_values = {"$set": {"text": "A new version of my post."}} posts_collection.update_one(query, new_values) # 全ての商品(ドキュメント)の価格を5増やす query = {} update_op = {"$inc": {"price": 5}} db.desserts.update_many(query, update_op) 12
Delete ( ドキュメントの削除) 1 件削除: delete_one() まとめて削除: delete_many() # 'author'が"Mike"の投稿を1件削除
result = posts_collection.delete_one({"author": "Mike"}) print(f"削除された件数: {result.deleted_count}") # 'price'が10以下のデザートを全て削除 result = db.desserts.delete_many({"price": {"$lte": 10}}) print(f"削除された件数: {result.deleted_count}") 13
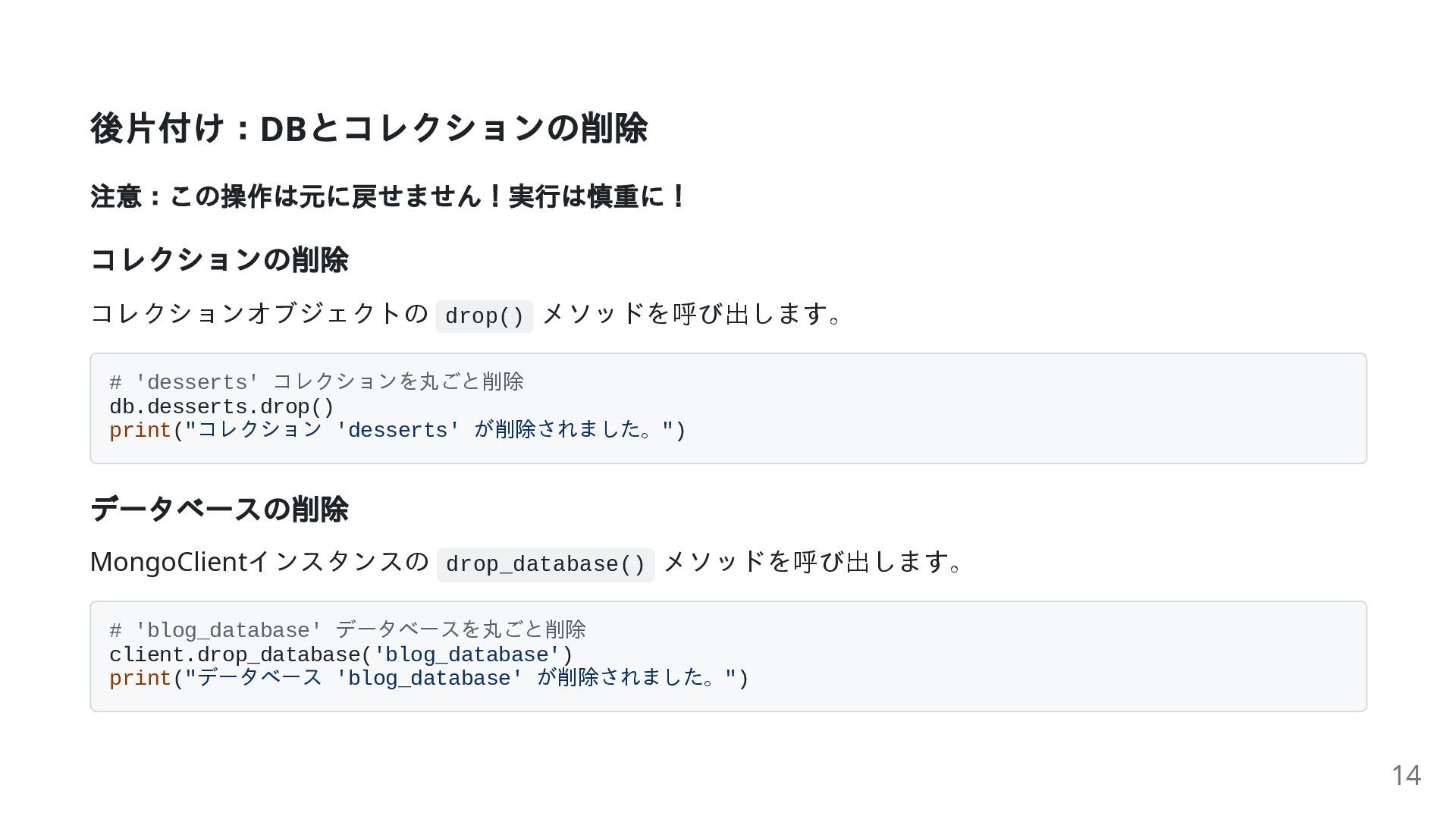
後片付け:DB とコレクションの削除 注意:この操作は元に戻せません!実行は慎重に! コレクションの削除 コレクションオブジェクトの drop() メソッドを呼び出します。 # 'desserts' コレクションを丸ごと削除
db.desserts.drop() print("コレクション 'desserts' が削除されました。") データベースの削除 MongoClientインスタンスの drop_database() メソッドを呼び出します。 # 'blog_database' データベースを丸ごと削除 client.drop_database('blog_database') print("データベース 'blog_database' が削除されました。") 14
転ばぬ先の杖:エラー処理 安定したアプリケーションには、適切なエラー処理が不可欠です。 try...except 文でPyMongoの様々なエラーを捕まえましょう。 from pymongo.errors import PyMongoError, ConnectionFailure, DuplicateKeyError
try: # 接続テスト client = MongoClient('localhost', 27017, serverSelectionTimeoutMS=2000) client.admin.command('ping') except ConnectionFailure as e: print(f"接続に失敗しました: {e}") except DuplicateKeyError as e: print(f"キーが重複しています(同じIDのデータを挿入しようとしました): {e}") except PyMongoError as e: print(f"MongoDBの予期せぬエラーが発生しました: {e}") finally: if 'client' in locals() and client: client.close() # 最後に必ず接続を閉じる 15
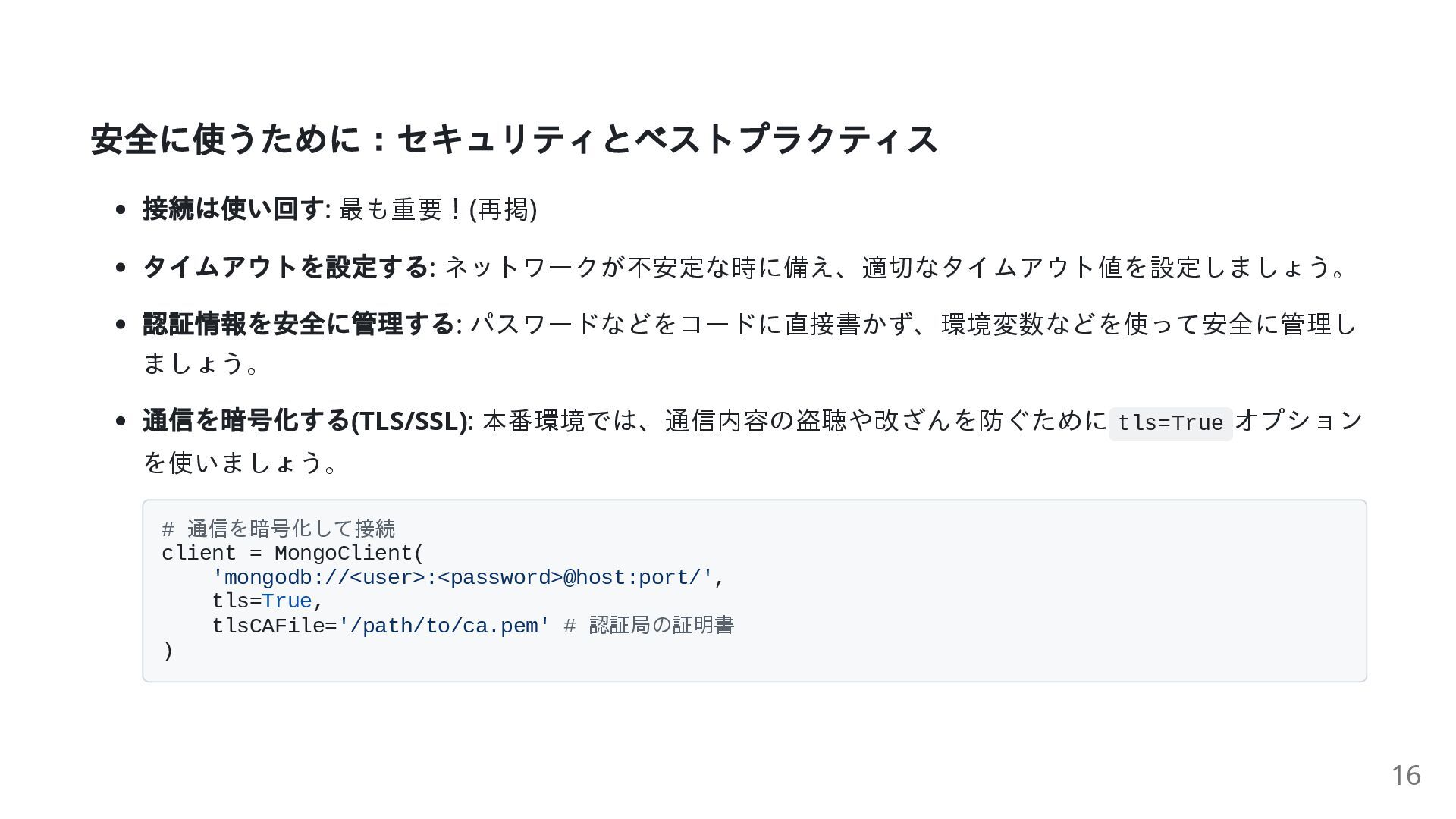
安全に使うために:セキュリティとベストプラクティス 接続は使い回す: 最も重要!(再掲) タイムアウトを設定する: ネットワークが不安定な時に備え、適切なタイムアウト値を設定しましょう。 認証情報を安全に管理する: パスワードなどをコードに直接書かず、環境変数などを使って安全に管理し ましょう。 通信を暗号化する(TLS/SSL): 本番環境では、通信内容の盗聴や改ざんを防ぐために
tls=True オプション を使いましょう。 # 通信を暗号化して接続 client = MongoClient( 'mongodb://<user>:<password>@host:port/', tls=True, tlsCAFile='/path/to/ca.pem' # 認証局の証明書 ) 16
まとめ PyMongoは、PythonでMongoDBを操作するための 公式で信頼性の高いドライバーです。 MongoClient で接続し、DBとコレクションを選択します。 insert , find , update
, delete 系のメソッドで直感的なCRUD 操作ができます。 より良いコードのためのポイント: MongoClient のインスタンスは 使い回す。 プログラムを 分身(マルチプロセス化)させるときは、分身の中で新しく接続する。 try-except で エラーを適切に処理する。 本番環境では セキュリティを強く意識する。 17
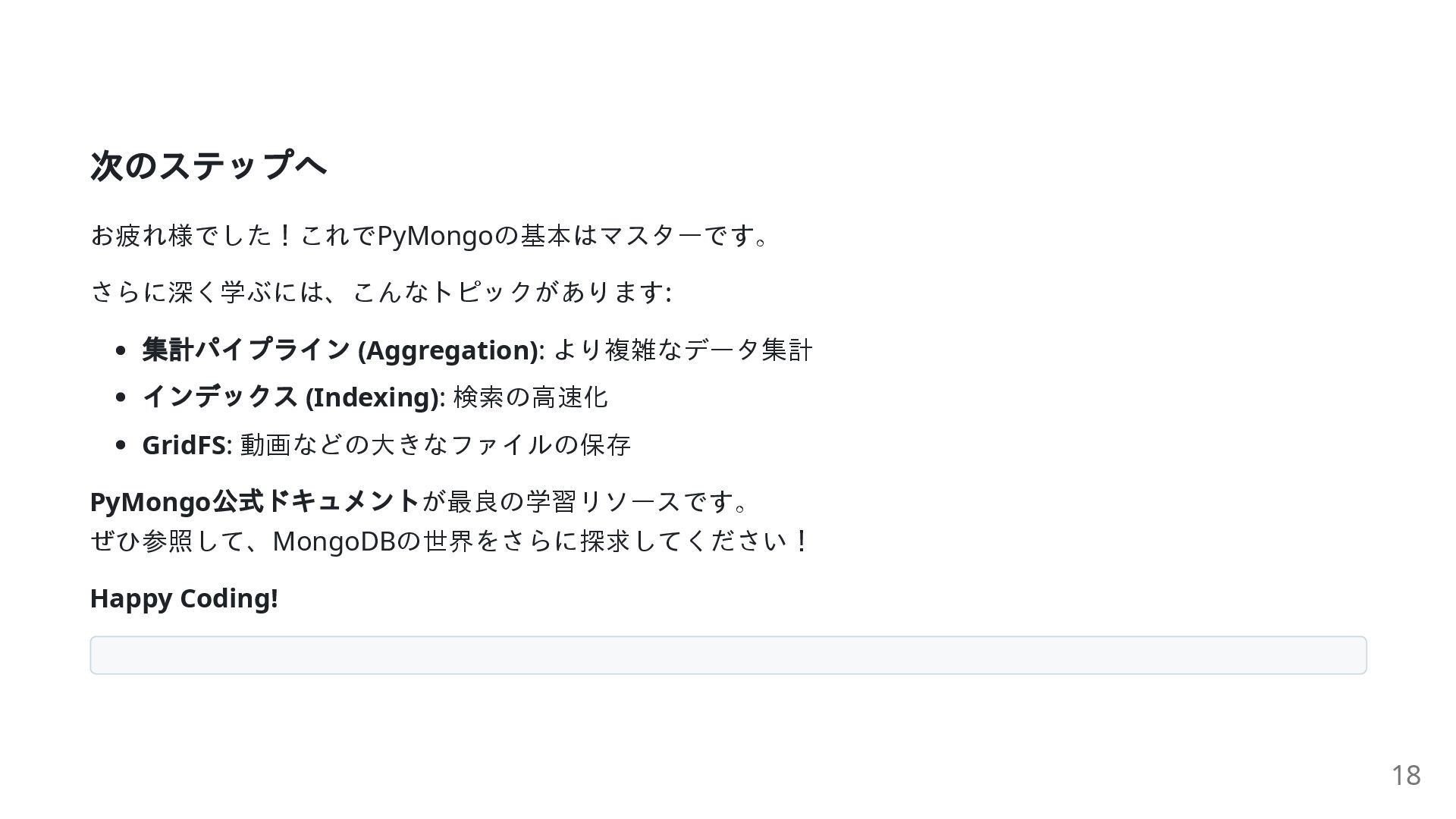
次のステップへ お疲れ様でした!これでPyMongoの基本はマスターです。 さらに深く学ぶには、こんなトピックがあります: 集計パイプライン (Aggregation): より複雑なデータ集計 インデックス (Indexing): 検索の高速化 GridFS:
動画などの大きなファイルの保存 PyMongo 公式ドキュメントが最良の学習リソースです。 ぜひ参照して、MongoDBの世界をさらに探求してください! Happy Coding! 18
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}