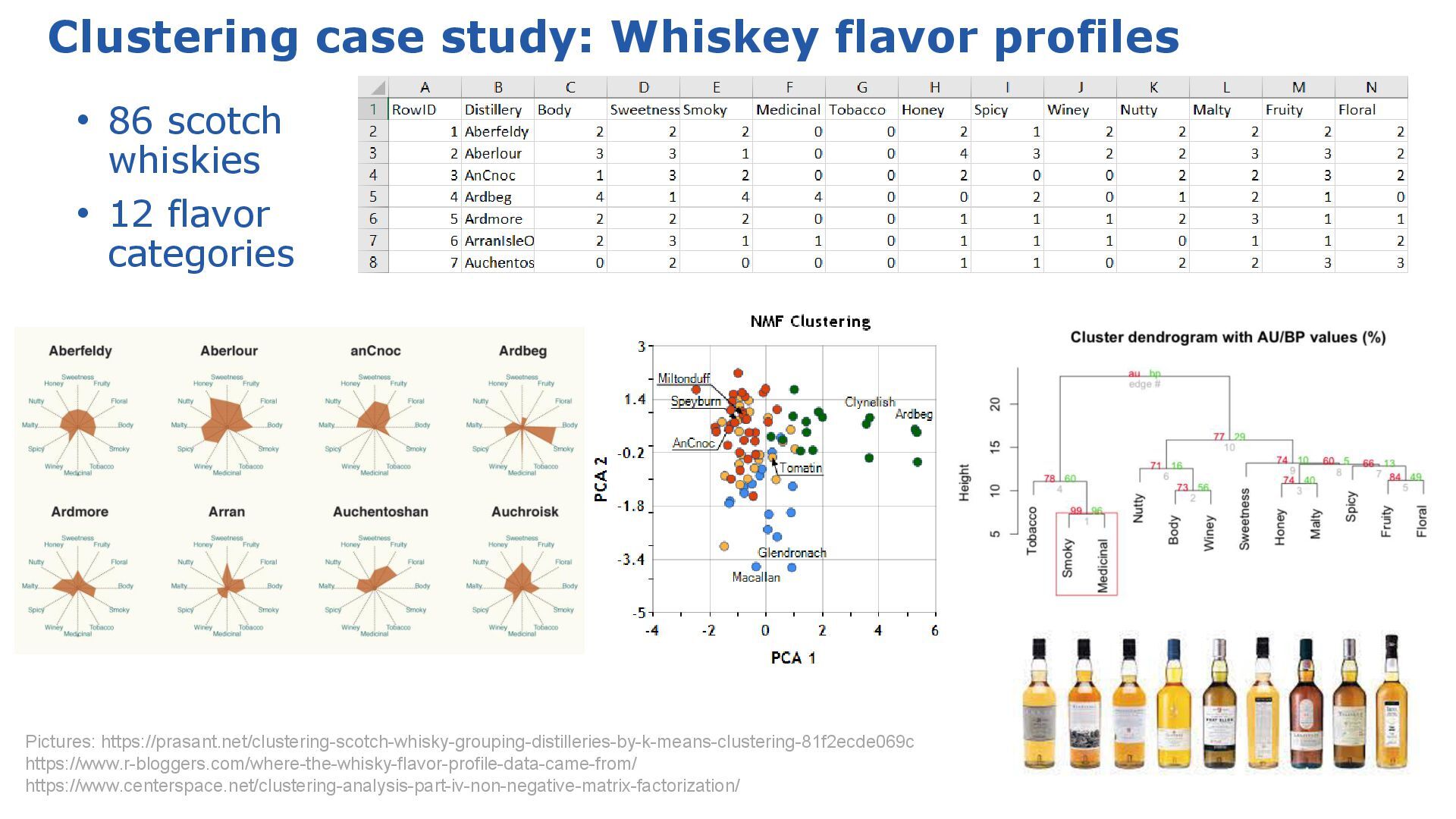
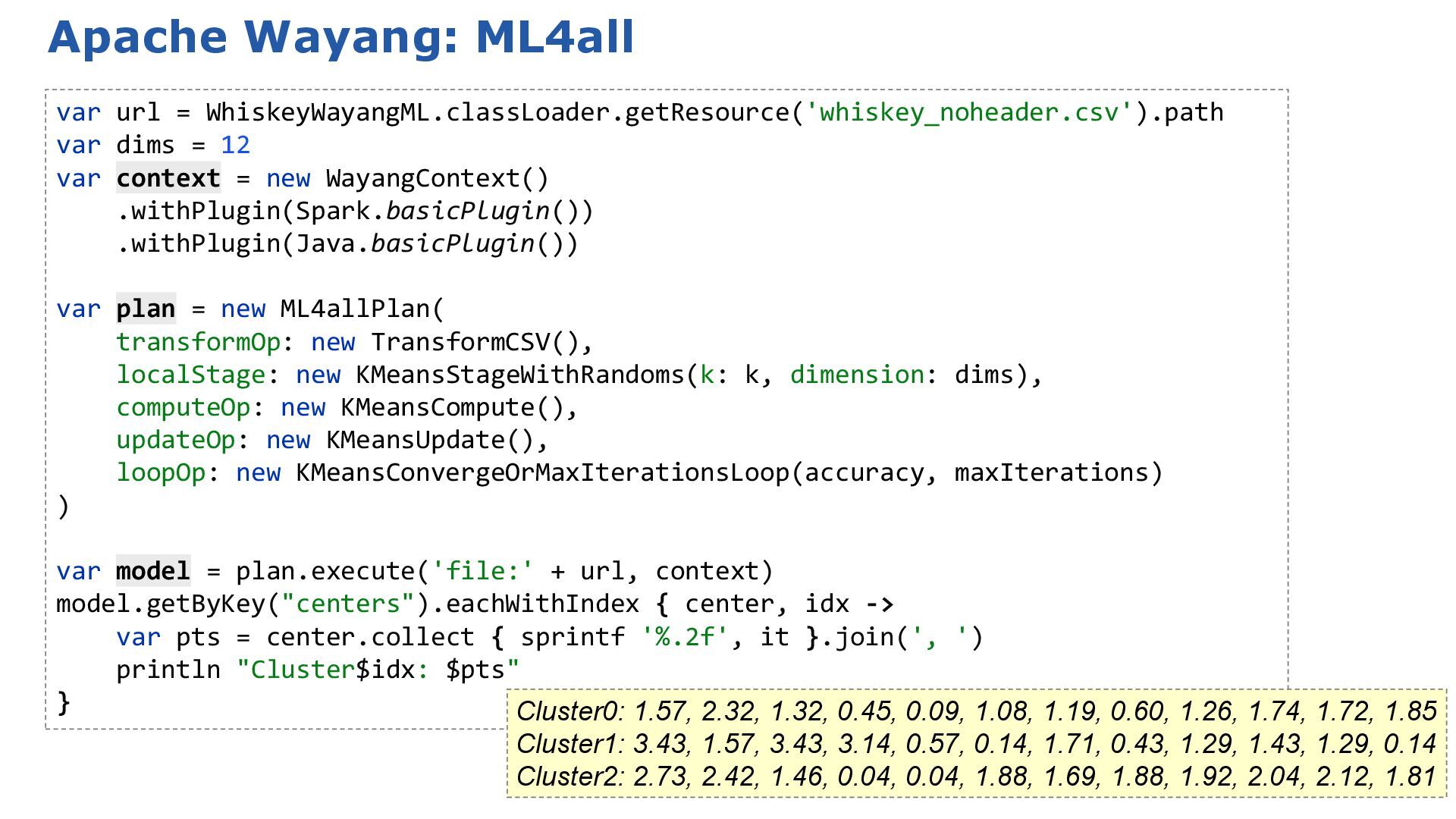
SelectNearestCentroid(centroids: finalCentroids) var allocations = pointsData.withIndex() .collect{ pt, idx -> [allocator.apply(pt).cluster, distilleries[idx]] } .groupBy{ cluster, ds -> "Cluster $cluster" } .collectValues{ v -> v.collect{ it[1] } } .sort{ e1, e2 -> e1.key <=> e2.key } allocations.each{ c, ds -> println "$c (${ds.size()} members): ${ds.join(', ')}" } Cluster 0 (17 members): Ardbeg, Balblair, Bowmore, Bruichladdich, Caol Ila, Clynelish, GlenGarioch, GlenScotia, Highland Park, Isle of Jura, Lagavulin, Laphroig, Oban, OldPulteney, Springbank, Talisker, Teaninich Cluster 2 (9 members): Aberlour, Balmenach, Dailuaine, Dalmore, Glendronach, Glenfarclas, Macallan, Mortlach, RoyalLochnagar Cluster 3 (36 members): AnCnoc, ArranIsleOf, Auchentoshan, Aultmore, Benriach, Bladnoch, Bunnahabhain, Cardhu, Craigganmore, Dalwhinnie, Dufftown, GlenElgin, GlenGrant, GlenMoray, GlenSpey, Glenallachie, Glenfiddich, Glengoyne, Glenkinchie, Glenlossie, Glenmorangie, Inchgower, Linkwood, Loch Lomond, Mannochmore, Miltonduff, RoyalBrackla, Speyburn, Speyside, Strathmill, Tamdhu, Tamnavulin, Tobermory, Tomintoul, Tomore, Tullibardine Cluster 4 (24 members): Aberfeldy, Ardmore, Auchroisk, Belvenie, BenNevis, Benrinnes, Benromach, BlairAthol, Craigallechie, Deanston, Edradour, GlenDeveronMacduff, GlenKeith, GlenOrd, Glendullan, Glenlivet, Glenrothes, Glenturret, Knochando, Longmorn, OldFettercairn, Scapa, Strathisla, Tomatin
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Roll your own Kmeans: domain classes record Point(double[] pts) implements](https://files.speakerdeck.com/presentations/55ca56f25d6b401abd82843ce4de1a60/slide_27.jpg){kind=link}
![Roll your own Kmeans: domain classes record Point(double[] pts) implements](https://files.speakerdeck.com/presentations/55ca56f25d6b401abd82843ce4de1a60/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
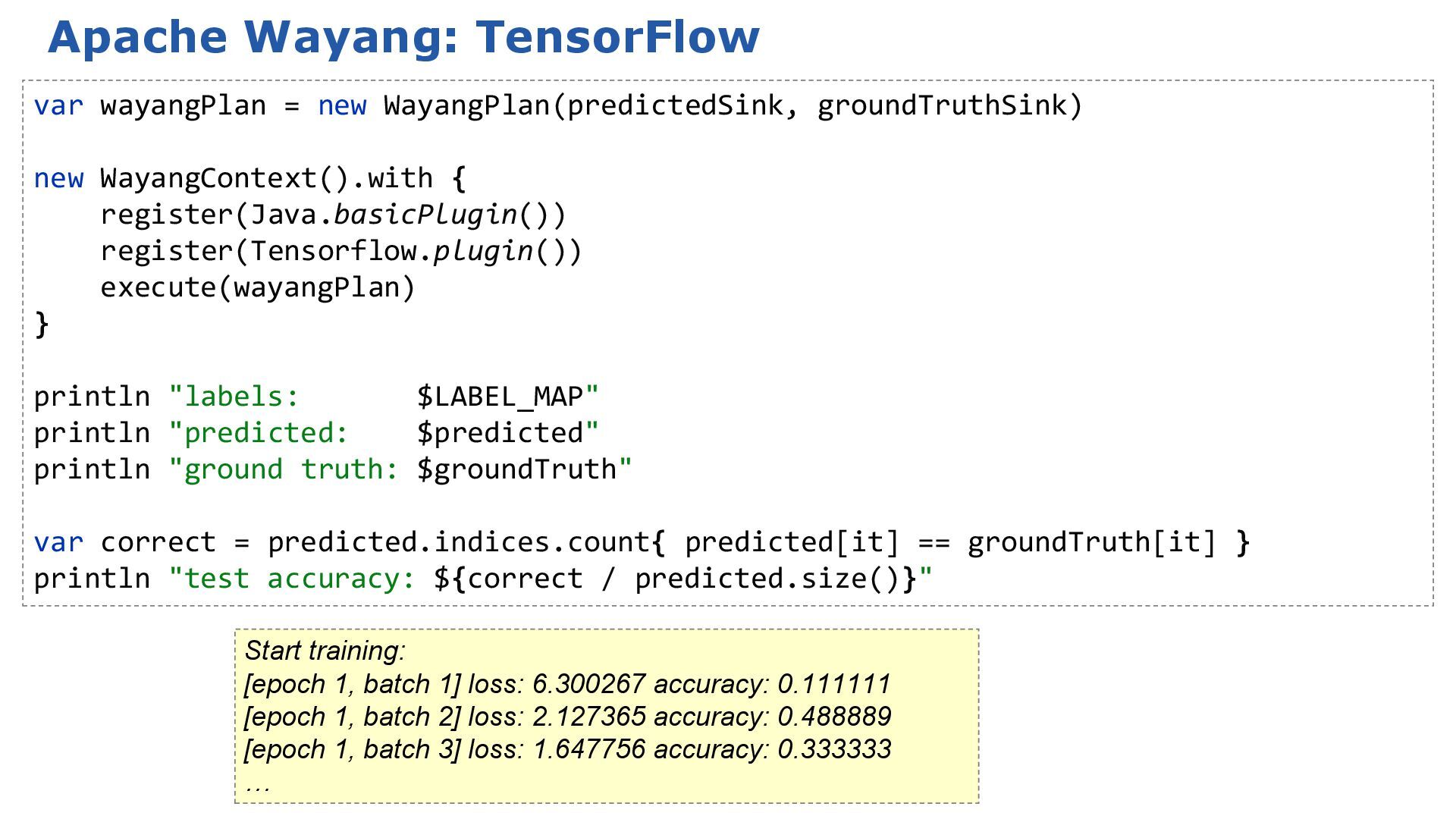
![Apache Wayang: TensorFlow … [epoch 2, batch 1] loss: 1.245312](https://files.speakerdeck.com/presentations/55ca56f25d6b401abd82843ce4de1a60/slide_47.jpg){kind=link}
{kind=link}