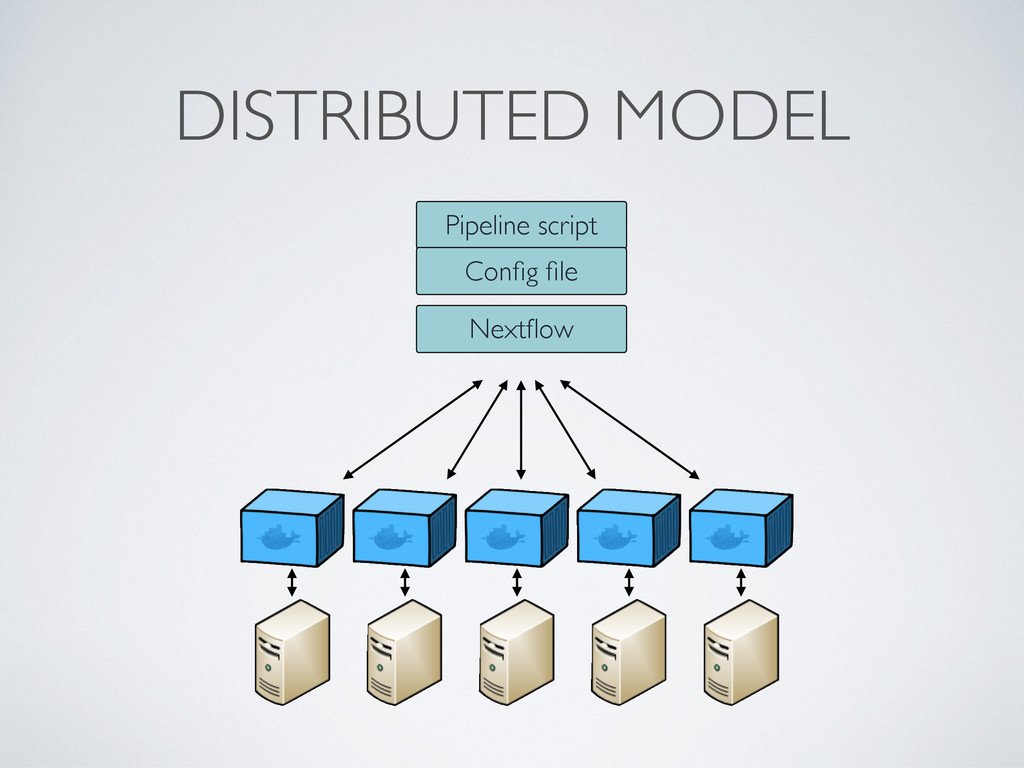
wait for data, when an input set is ready the process is executed • They communicate by using dataflow variables i.e. async stream of data called channels • Parallelisation and tasks dependencies are implicitly defined by process in/out declarations
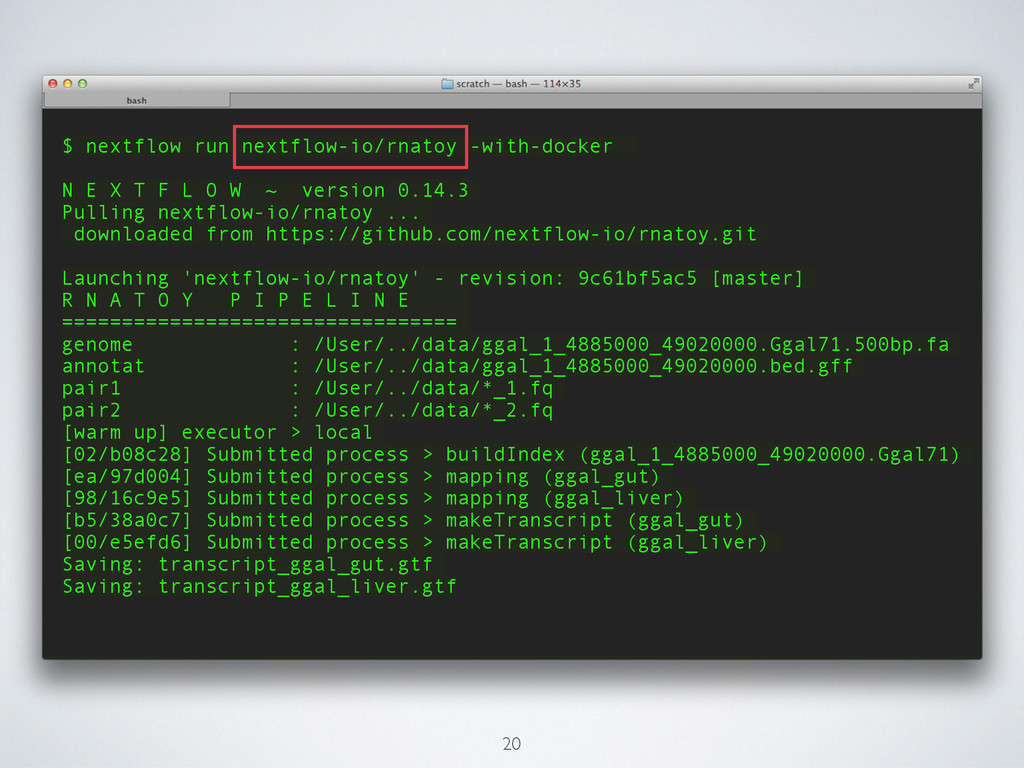
F L O W ~ version 0.14.3 Pulling nextflow-io/rnatoy ... downloaded from https://github.com/nextflow-io/rnatoy.git ! Launching 'nextflow-io/rnatoy' - revision: 9c61bf5ac5 [master] R N A T O Y P I P E L I N E ================================= genome : /User/../data/ggal_1_4885000_49020000.Ggal71.500bp.fa annotat : /User/../data/ggal_1_4885000_49020000.bed.gff pair1 : /User/../data/*_1.fq pair2 : /User/../data/*_2.fq [warm up] executor > local [02/b08c28] Submitted process > buildIndex (ggal_1_4885000_49020000.Ggal71) [ea/97d004] Submitted process > mapping (ggal_gut) [98/16c9e5] Submitted process > mapping (ggal_liver) [b5/38a0c7] Submitted process > makeTranscript (ggal_gut) [00/e5efd6] Submitted process > makeTranscript (ggal_liver) Saving: transcript_ggal_gut.gtf Saving: transcript_ggal_liver.gtf 20
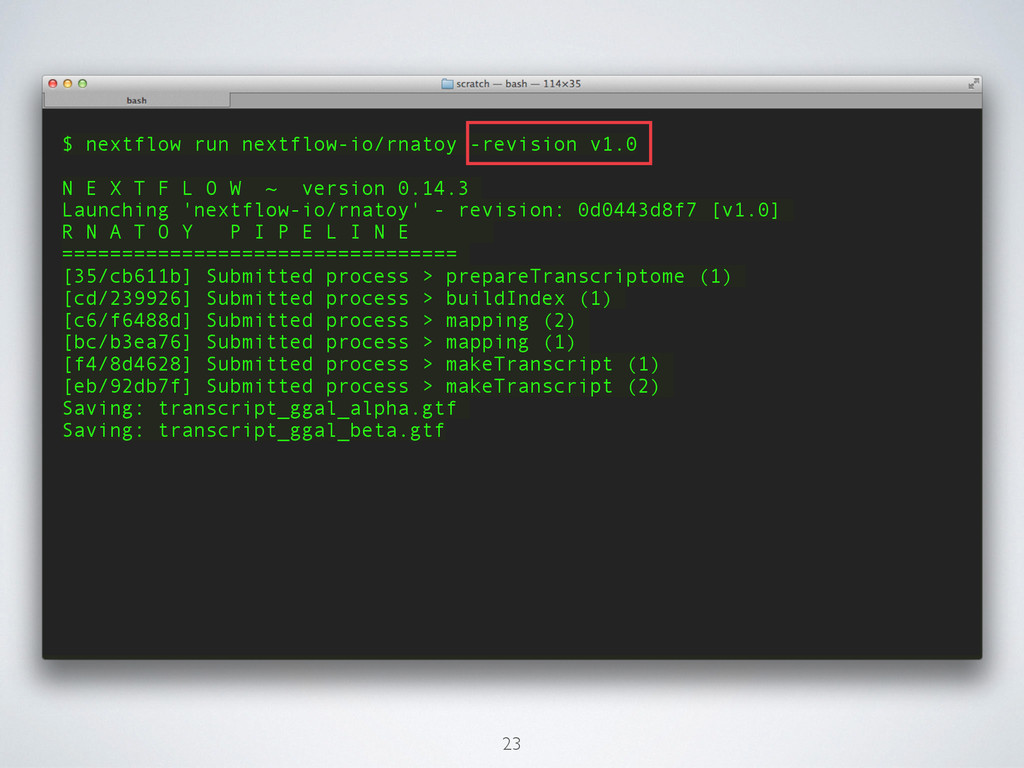
T F L O W ~ version 0.14.3 Launching 'nextflow-io/rnatoy' - revision: 0d0443d8f7 [v1.0] R N A T O Y P I P E L I N E ================================= [35/cb611b] Submitted process > prepareTranscriptome (1) [cd/239926] Submitted process > buildIndex (1) [c6/f6488d] Submitted process > mapping (2) [bc/b3ea76] Submitted process > mapping (1) [f4/8d4628] Submitted process > makeTranscript (1) [eb/92db7f] Submitted process > makeTranscript (2) Saving: transcript_ggal_alpha.gtf Saving: transcript_ggal_beta.gtf 23
Emilio Palumbo, Center for Genomic Regulation • Georgios Pappas, University of Brasilia • Lukas Jelonek, Justus-Liebig-Universität Gießen • Matthieu Foll, International Agency for Research on Cancer • Michael L Heuer, National Marrow Donor Program • Rémi Planel, University Claude Bernard Lyon 1 • Rob Syme, CCDM, Curtin University • Sascha Steinbiss, Sanger Institute • Simon Ye, Broad Institute • Tobias Sargeant, The Walter and Eliza Hall Institute
• Support for Bioboxes project • Support for Git Large File Storage • Support for Rkt containers Long term • Graphical editor • Support for CWL / WDL (?) • Support for YARN / Spark clusters
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}