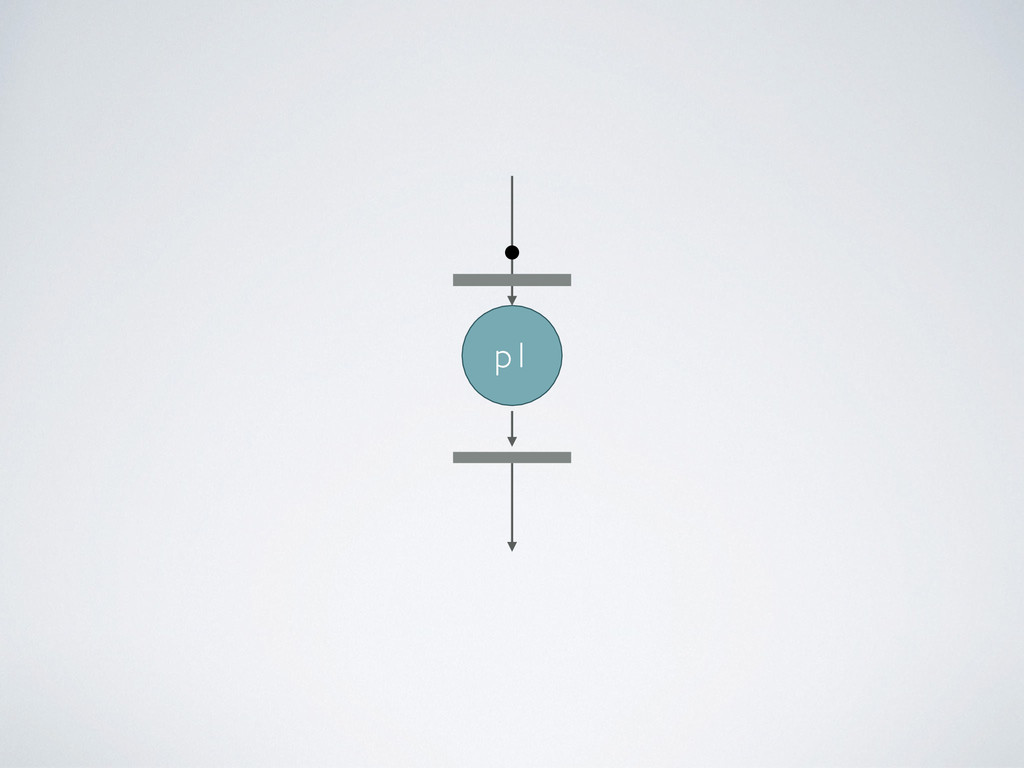
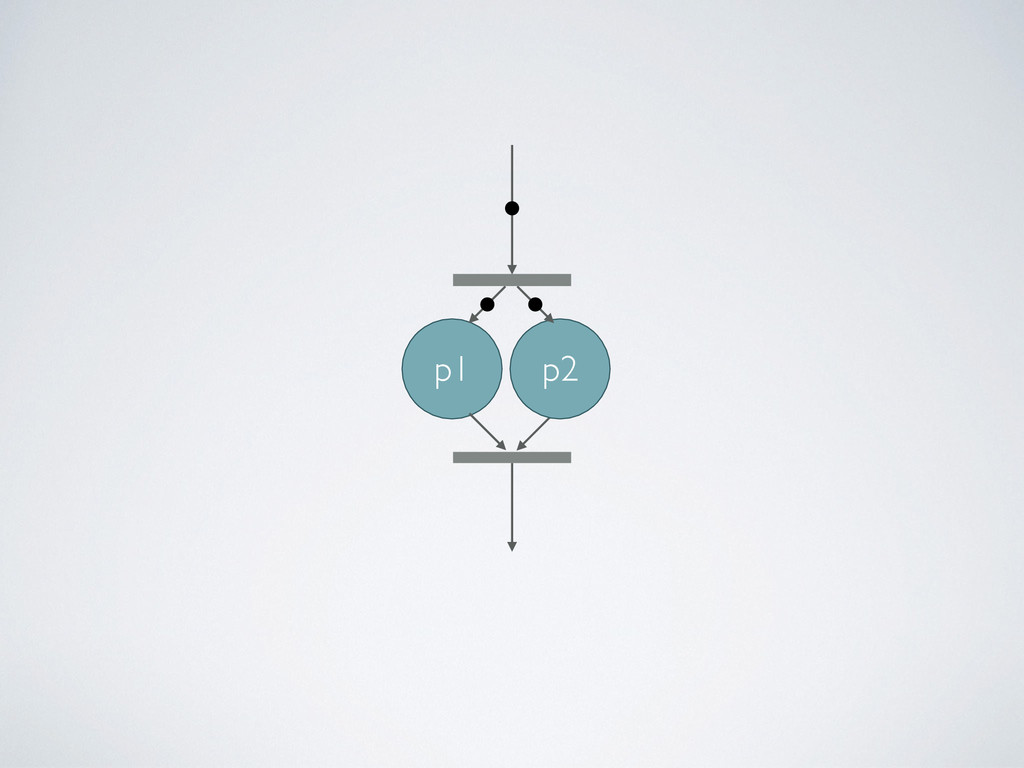
Processes wait for data, when an input set is ready the process is executed • They communicate by using dataflow variable i.e. async FIFO queues called channels • The synchronization is managed automatically
S. Tanenbaum. Programming languages for distributed computing systems (1989) “Dataflow variables are spectacularly expressive in concurrent programming when compared to explicit synchronisation”
file y from ch_2 file 'data.fa' from ch_3 stdin from from ch_4 set (x, 'file.txt') from ch_5 process procName { ! ! ! ! ! ! ! ! ! """ <your script> """ ! }
: Simply declares some variables prefixed by params When launching your script you can override the default values $ nextflow <script.nf> -‐-‐p1 'delta' -‐-‐p2 'gamma'
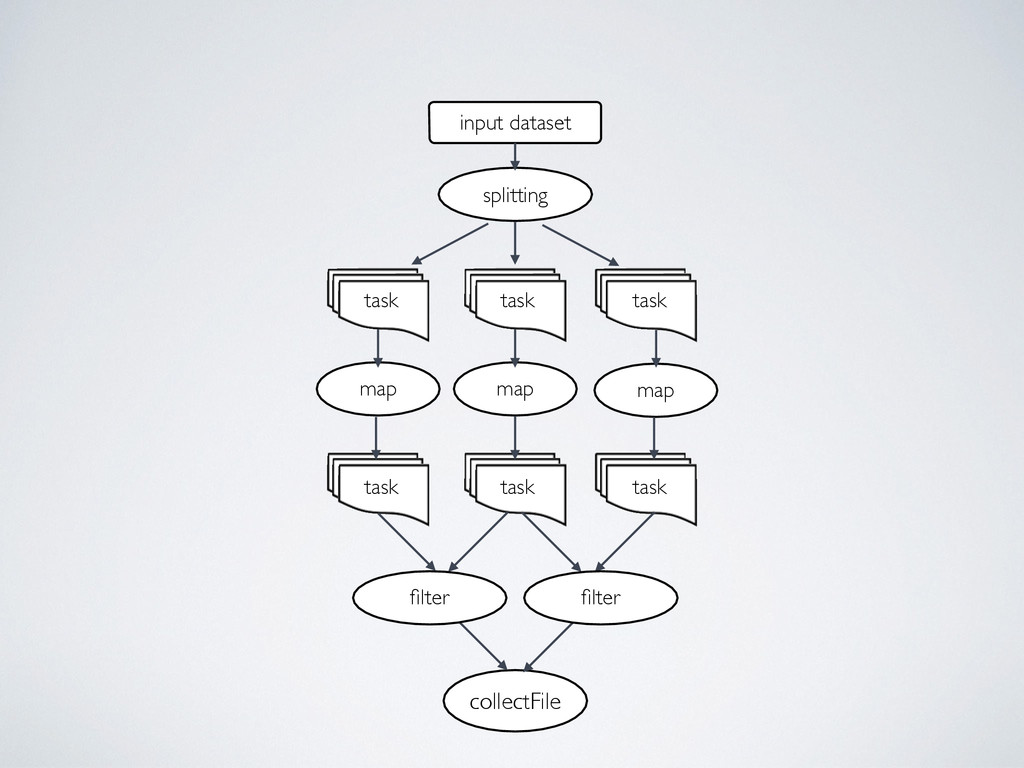
the splitting methods: • splitText - line by line • splitCsv - comma separated values format • splitFasta - by FASTA sequences • splitFastq - by FASTQ sequences
by upstream processes my_items.collectFile(storeDir:'path/name') { ! def key = getKeyByItem(it) def content = getContentByItem(it) [ key, content ] ! } Collect the items and group them into files having a names defined by a grouping criteria
process.executor = 'sge' process.queue = 'short' process.clusterOptions = '-‐pe smp 2' process.scratch = true ! // specific process settings process.$procName.queue = 'long' process.$procName.clusterOptions = '-‐l h_rt=12:00:0' ! // set the max number SGE jobs executor.$sge.queueSize = 100 Simply define the SGE executor in nextflow.config
Operators can be used also to filter, fork and combine channels Moreover they can be chained in order to implement a custom behaviour Channel .fromPath('misc/sample.fa') .splitFasta( record: [id: true, seqString: true ]) .filter { record -‐> record.id =~ /^ENST0.*/ } .into(target1, target2)
• You can package and distribute a self-contained executable environment • Up today it runs only on Linux (partially OSX), Docker plans to support Windows as well.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MORE ON STRINGS str = 'bioinformatics' print str[0]](https://files.speakerdeck.com/presentations/82ec3620c99f0131718e1a4ec88f18b1/slide_21.jpg){kind=link}
![LISTS simpleList = [1,2,5] strList = ['a','z'] emptyList](https://files.speakerdeck.com/presentations/82ec3620c99f0131718e1a4ec88f18b1/slide_22.jpg){kind=link}
![MAPS map = [:] ! map = [ k1:](https://files.speakerdeck.com/presentations/82ec3620c99f0131718e1a4ec88f18b1/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}