Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Deploy your own Spark cluster in 4 minutes usin...
Search
Pishen Tsai
December 05, 2015
Programming
630
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Deploy your own Spark cluster in 4 minutes using sbt.
Pishen Tsai
December 05, 2015
More Decks by Pishen Tsai
See All by Pishen Tsai
Introduction to Minitime
pishen
1
170
都什麼時代了,你還在寫 while loop 嗎?
pishen
2
750
Pishen's Emacs Journey
pishen
0
160
Scala + Google Dataflow = Serverless Spark
pishen
6
880
Shapeless Introduction
pishen
2
930
ScalaKitchen
pishen
1
480
sbt-emr-spark
pishen
1
170
My Personal Report of Scala Kansai 2016
pishen
0
440
SBT Basic Concepts
pishen
1
670
Other Decks in Programming
See All in Programming
5分で問診!Composer セキュリティ健康診断
codmoninc
0
250
Creating Composable Callables in Contemporary C++
rollbear
0
210
SLOをサービス品質の共通言語にするために 取り組んできたこと
wakana0222
0
500
AI がコードを書く時代における新卒エンジニアの仕事風景 (2026) / New Graduate Engineers in the Era of AI Coding (2026)
sushichan044
0
220
共通化で考えるべきは、実装より公開する型だった
codeegg
0
240
鹿野さんに聞く!『TypeScriptコードレシピ集』で磨く実践力
tonkotsuboy_com
4
1.1k
才能?センス?知らん、 続けたもん勝ちだ。-- 結婚・出産・癌を越えてなお、私がプロダクトを創り続ける理由
16bitidol
2
860
これからAgentCoreを触る方へ トレンドはGatewayです
har1101
6
490
AIキャラアプリkaiwaの低遅延音声通話基盤をどう作ったか - AWS Gravitonで支える低遅延・低コストAI Agent基盤
mogamit
0
170
Prismを使った型安全な暗号化_関数型まつり2026
_fhhmm
0
130
ローカルLLMでどこまでコードが書けるか -拡張版 / How much code can be written on a local LLM Extended
kishida
12
4.8k
SREの積み重ねがAI駆動開発のガードレールになった ― 7つの実践/SRE Guardrails The 7
tomoyakitaura
8
4.3k
Featured
See All Featured
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
960
Statistics for Hackers
jakevdp
799
230k
How to Talk to Developers About Accessibility
jct
2
370
Ethics towards AI in product and experience design
skipperchong
2
330
Rails Girls Zürich Keynote
gr2m
96
14k
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
460
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.6k
The SEO identity crisis: Don't let AI make you average
varn
0
510
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
360
Music & Morning Musume
bryan
47
7.3k
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
220
Transcript
Pishen Tsai @ KKBOX Deploy your own Spark cluster in
4 minutes using sbt
KKBOX / spark-deployer • SBT plugin. • Productively used in
KKBOX. • 100% Scala. https://github.com/KKBOX/spark-deployer
None
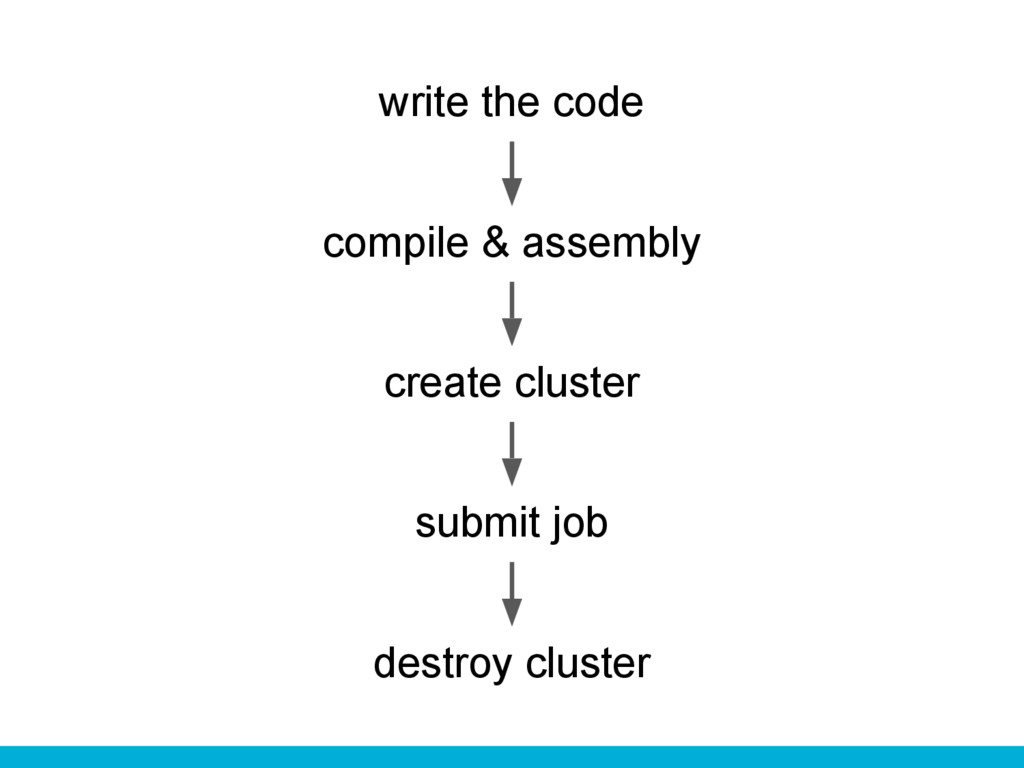
destroy cluster submit job create cluster write the code compile
& assembly
• spark-ec2 • amazon emr (Elastic MapReduce) • spark-deployer Solutions
https://aws.amazon.com/elasticmapreduce/details/spark http://spark.apache.org/docs/latest/ec2-scripts.html spark-ec2: amazon emr:
• spark-ec2 • amazon emr (Elastic MapReduce) • spark-deployer Solutions
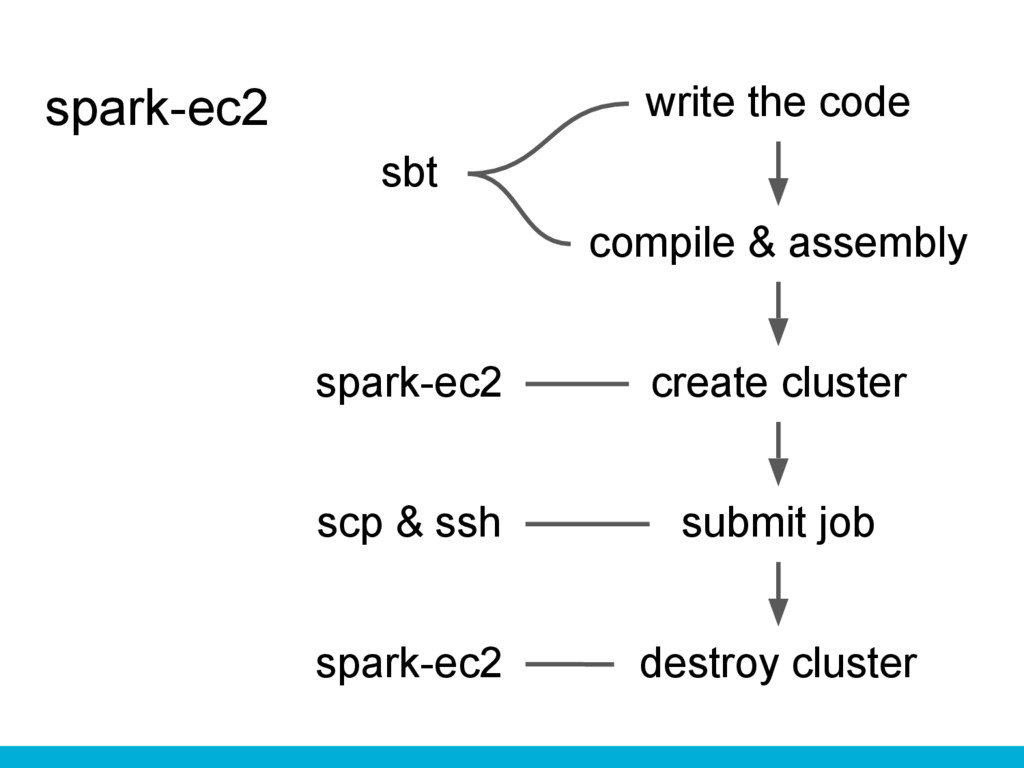
spark-ec2 write the code compile & assembly submit job create
cluster destroy cluster sbt scp & ssh spark-ec2 spark-ec2
spark-ec2’s commands $ sbt assembly $ spark-ec2 -k awskey -i
~/.ssh/awskey.pem -r us-west-2 -z us-west-2a --vpc-id=vpc-a28d24c7 -- subnet-id=subnet-4eb27b39 -s 2 -t c4.xlarge -m m4.large --spark-version=1.5.2 --copy-aws- credentials launch my-spark-cluster $ scp -i ~/.ssh/awskey.pem target/scala-2.10 /my_job-assembly-0.1.jar root@<copy-master-ip- by-yourself>:~/job.jar $ ssh -i ~/.ssh/awskey.pem root@<master-ip> '. /spark/bin/spark-submit --class mypackage.Main --master spark://<master-ip>:7077 --executor- memory 6G job.jar arg0' $ spark-ec2 -r us-west-2 destroy my-spark- cluster
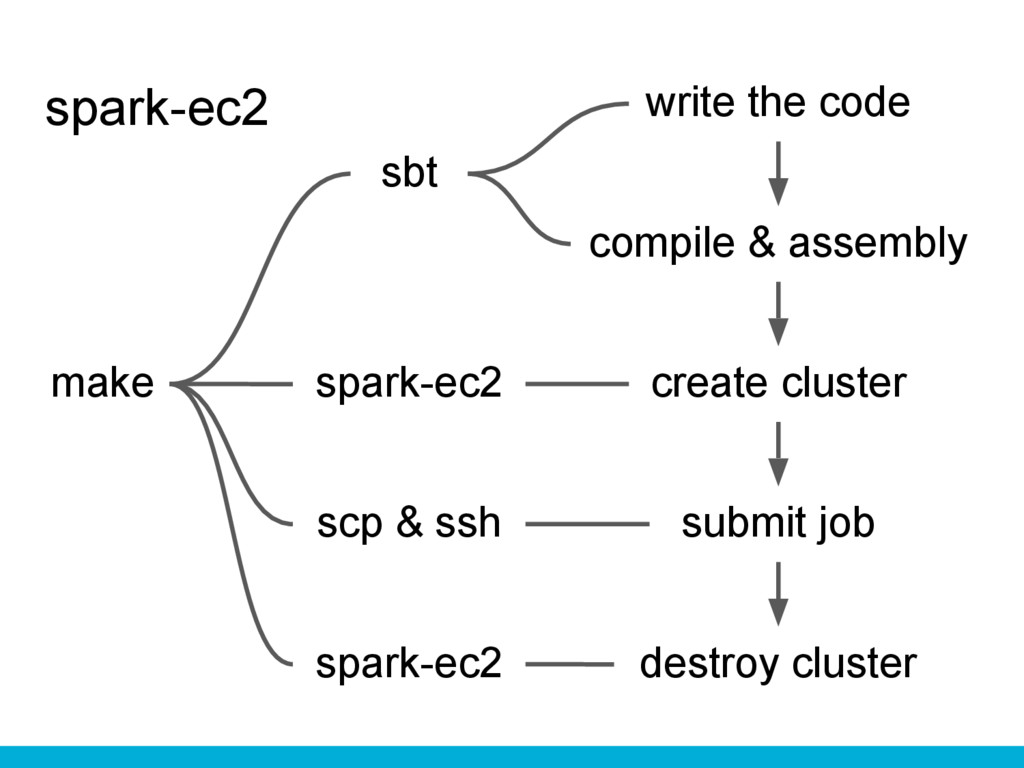
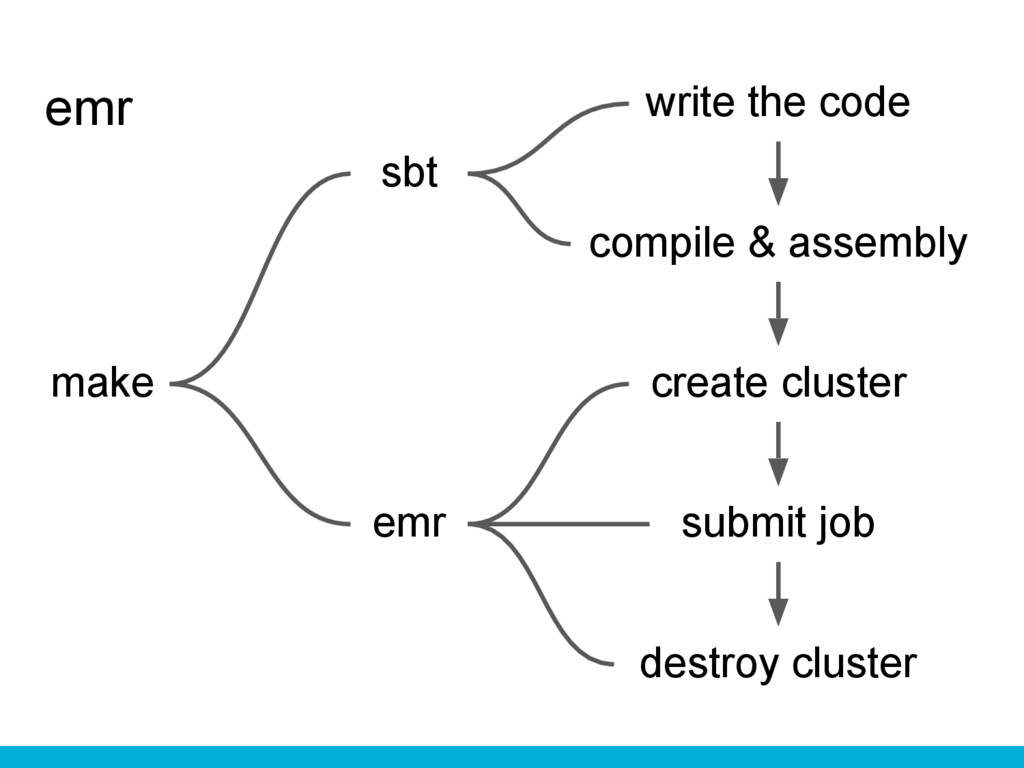
spark-ec2 write the code compile & assembly submit job create
cluster destroy cluster sbt spark-ec2 spark-ec2 scp & ssh make
spark-ec2’s bad parts Need to install sbt and spark-ec2. Need
to design and maintain Makefiles. Slow startup time (~20mins).
• spark-ec2 • amazon emr (Elastic MapReduce) • spark-deployer Solutions
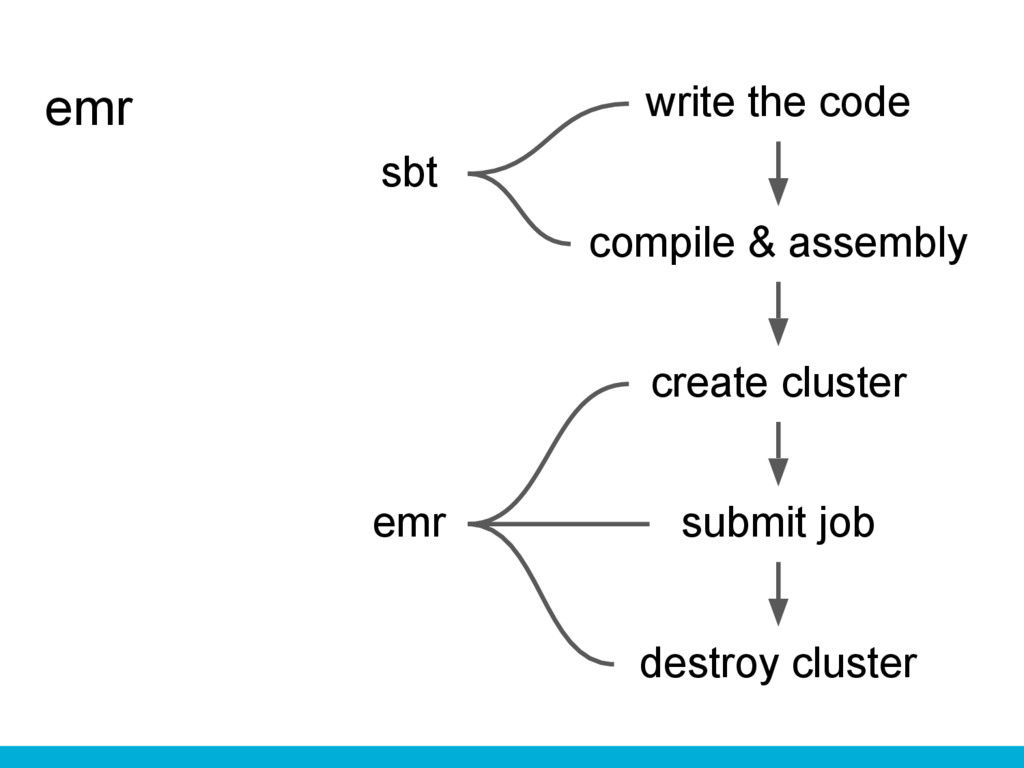
emr write the code compile & assembly submit job create
cluster destroy cluster sbt emr
emr’s commands $ sbt assembly $ aws emr create-cluster --name
my-spark-cluster --release-label emr-4.2.0 --instance-type m3. xlarge --instance-count 2 --applications Name=Spark --ec2-attributes KeyName=awskey --use- default-roles $ aws emr put --cluster-id j-2AXXXXXXGAPLF --key- pair-file ~/.ssh/mykey.pem --src target/scala- 2.10/my_job-assembly-0.1.jar --dest /home/hadoop/job.jar $ aws emr add-steps --cluster-id j-2AXXXXXXGAPLF --steps Type=Spark,Name=my-emr,ActionOnFailure= CONTINUE,Args=[--executor-memory,13G,--class, mypackage.Main,/home/hadoop/job.jar,arg0] $ aws emr terminate-clusters --cluster-id j-2AXX
emr write the code compile & assembly submit job create
cluster destroy cluster sbt emr make
emr’s bad parts Need to install sbt and emr. Need
to design and maintain Makefiles. Spark’s version is old. Restricted machine type.
Since sbt is a powerful build tool itself, why don’t
we let it handle all the dirty works for us?
• spark-ec2 • amazon emr (Elastic MapReduce) • spark-deployer Solutions
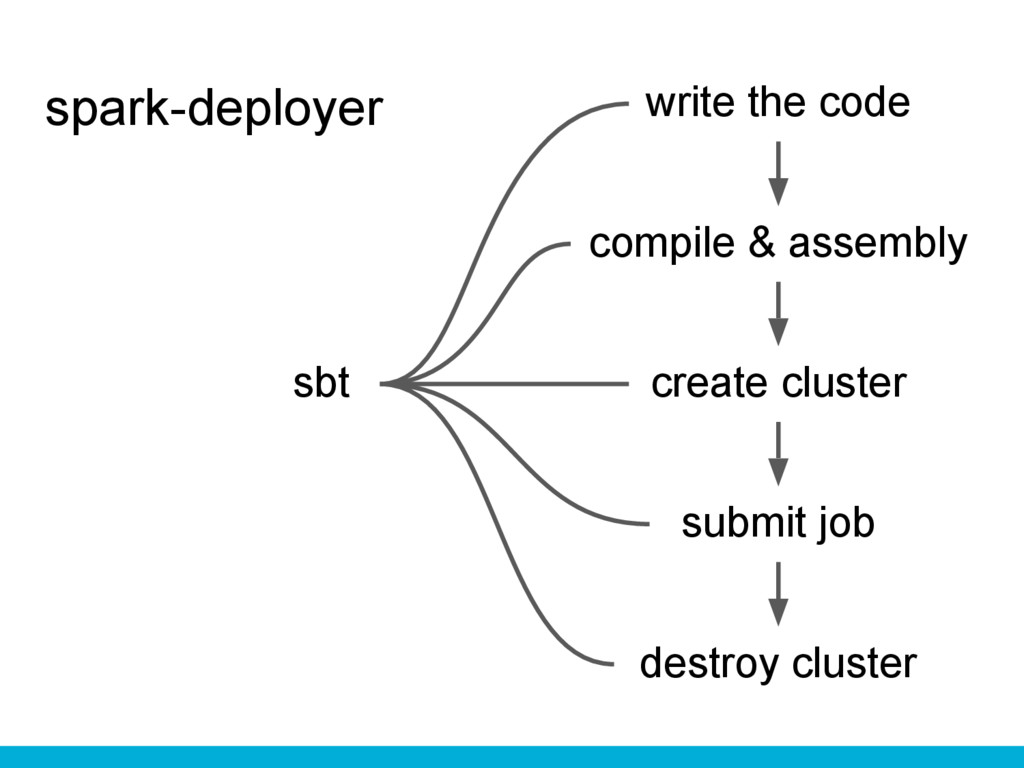
spark-deployer write the code compile & assembly submit job create
cluster destroy cluster sbt
spark-deployer’s commands $ sbt "sparkCreateCluster 2" $ sbt "sparkSubmitJob arg0"
$ sbt "sparkDestroyCluster"
spark-deployer’s good parts Need to install only sbt. No Makefile.
Easy to use. Let you focus on your code. Fast and parallel startup (~4mins). Dynamic scale out. Flexible design.
How to use it?
Prerequisites • java • sbt • export AWS_ACCESS_KEY_ID=... export AWS_SECRET_ACCESS_KEY=...
http://www.scala-sbt.org/0.13/tutorial/Manual-Installation.html#Unix sbt installation
Demo
• Report issues. • Join our gitter channel. • Send
pull requests. https://github.com/KKBOX/spark-deployer Give it a try, and share! KKBOX / spark-deployer
Thank you Pishen Tsai @ KKBOX KKBOX / spark-deployer
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}