This talk will give an introduction to text analysis with Python by asking some questions about Shakespeare and discussing the quantitative methods that will go in to answering them. While we’ll use Shakespeare to illustrate our methodologies, we’ll also discuss how they can be ported over into more 21st century texts, like tweets or New York Times articles.
https://us.pycon.org/2015/schedule/presentation/339/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
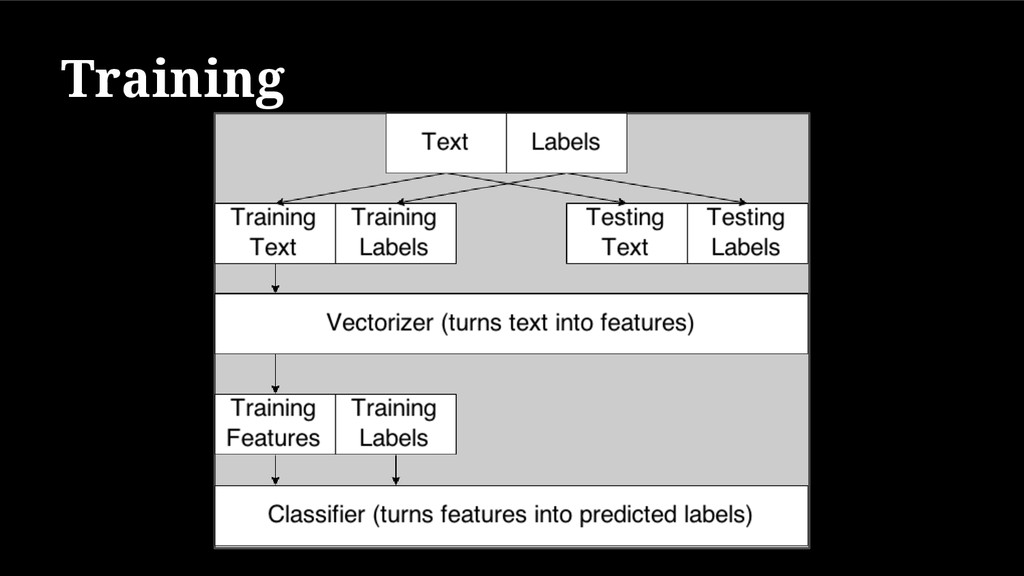{kind=link}
{kind=link}
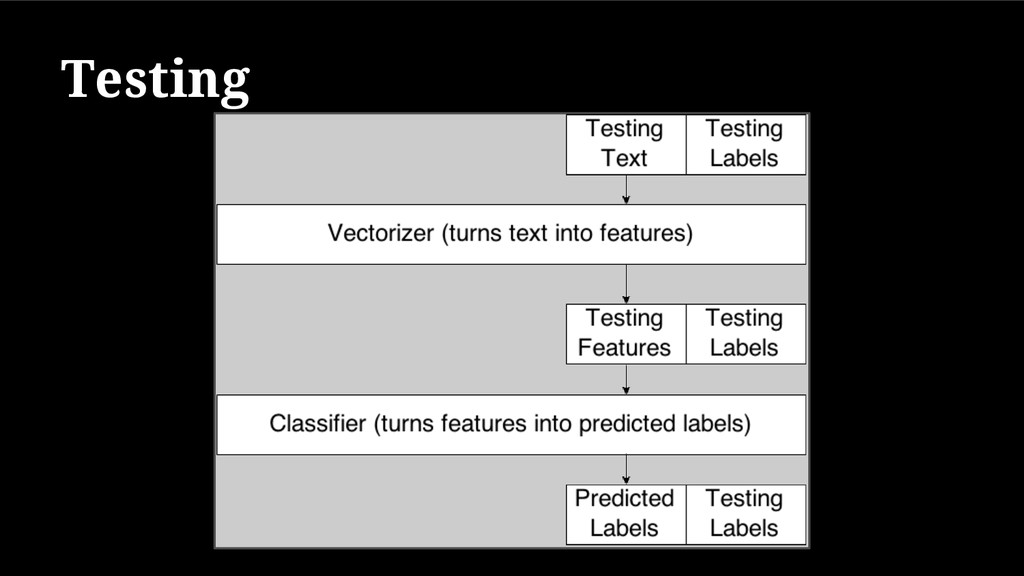{kind=link}
![test_speech = test_speeches[0] print test_speech Farewell, Andronicus, my noble father,](https://files.speakerdeck.com/presentations/1de6983c3d11406eabf1dbed7d0a6486/slide_45.jpg){kind=link}
![Classifier Testing test_speech = test_speeches[0] test_label = test_labels[0] test_features =](https://files.speakerdeck.com/presentations/1de6983c3d11406eabf1dbed7d0a6486/slide_46.jpg){kind=link}
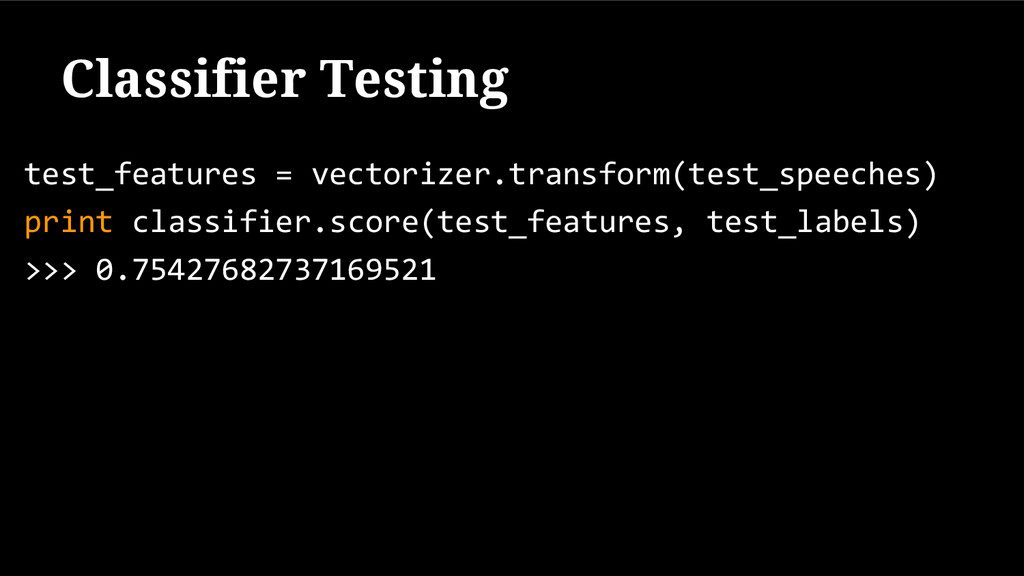{kind=link}
{kind=link}
{kind=link}
![[email protected] @adampalay www.adampalay.com Thank you!](https://files.speakerdeck.com/presentations/1de6983c3d11406eabf1dbed7d0a6486/slide_50.jpg){kind=link}