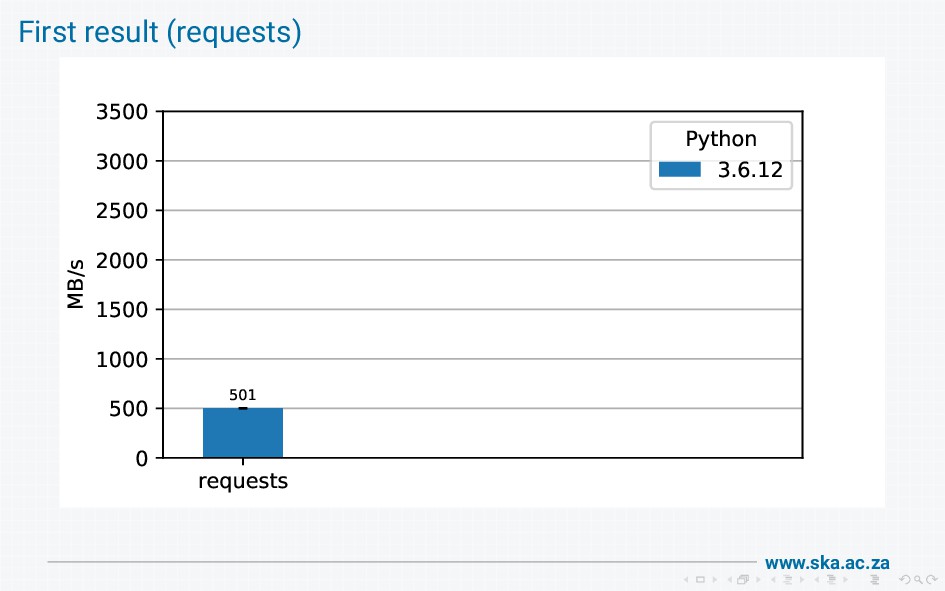
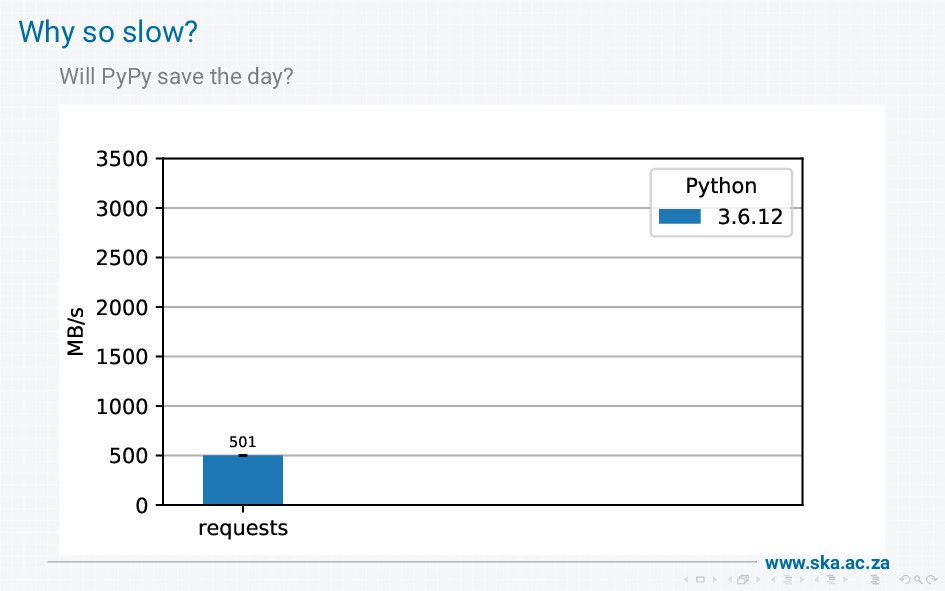
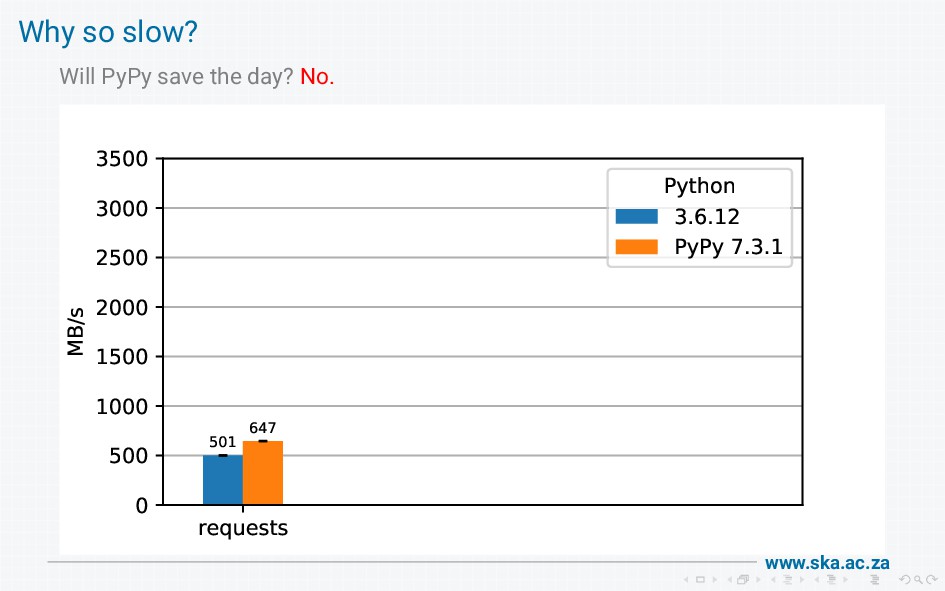
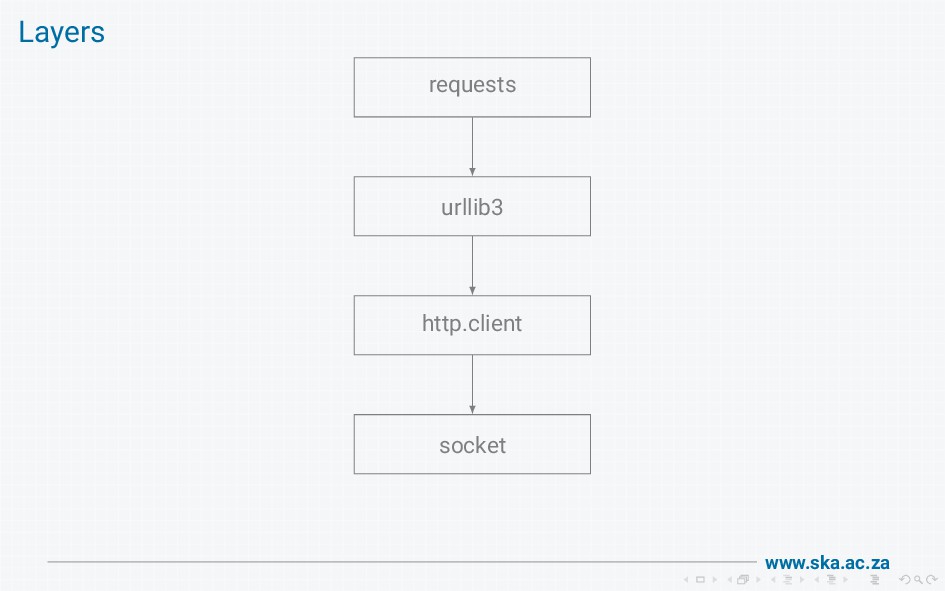
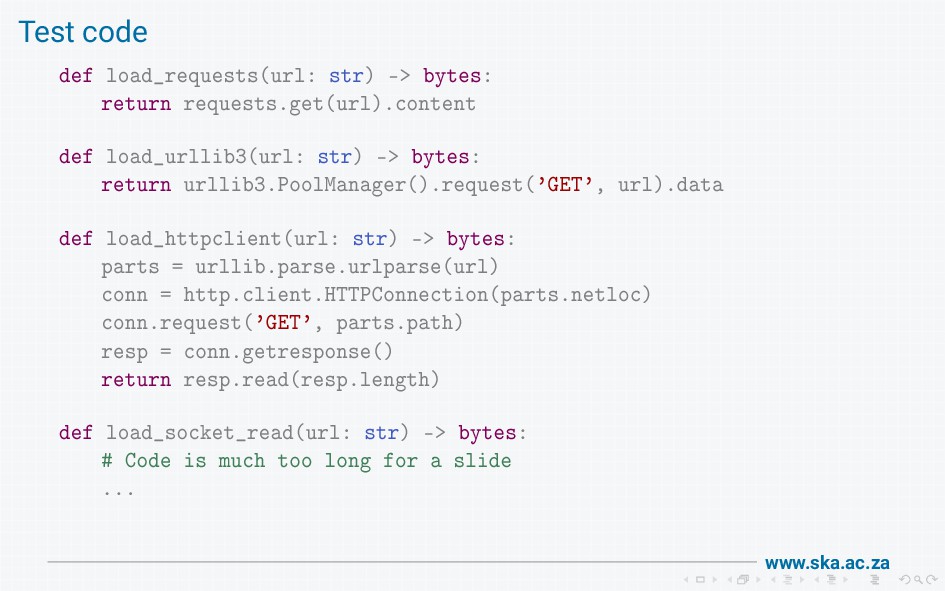
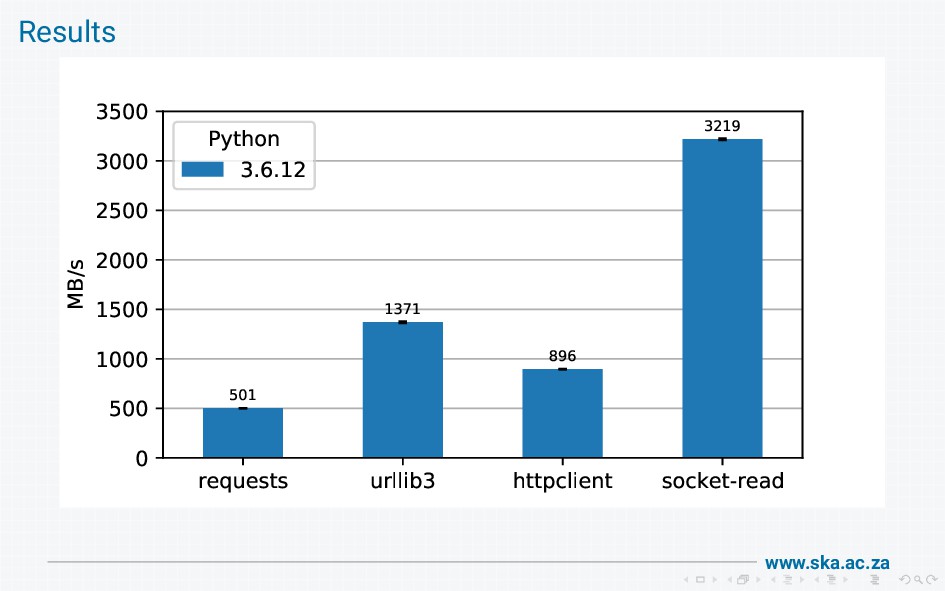
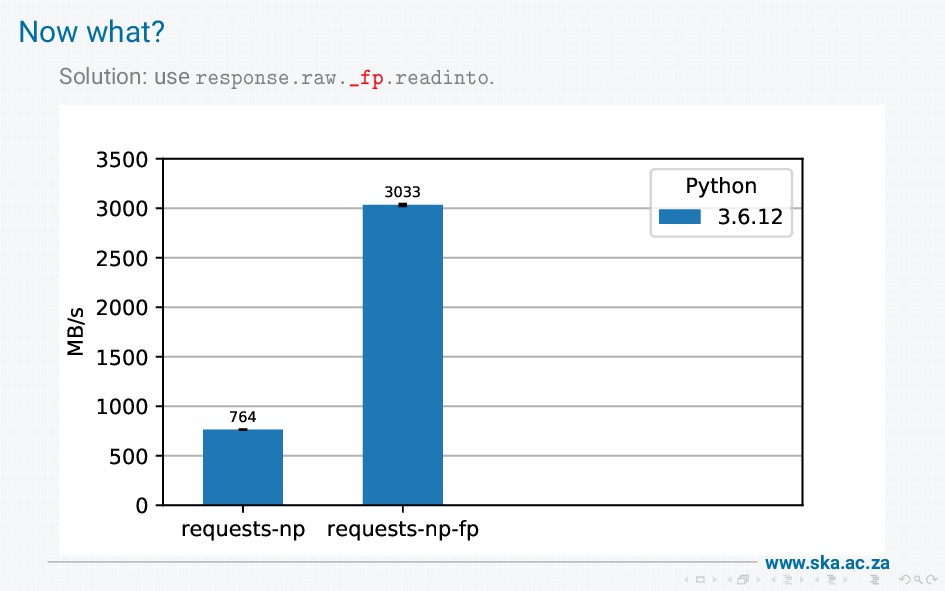
The MeerKAT radio telescope produces massive volumes of data. We provide a data access library for scientists to retrieve the data, but our initial implementation using boto had disappointing performance when used on a high-speed (25 Gb/s) network. On investigation, we found that boto wraps requests wraps urllib3 wraps http.client, and these wrapping layers introduce a lot of overheads that limit bandwidth. I'll walk through all the steps involved in getting data from the socket into a final response, show how this reduces throughput, and describe our solution to achieve bandwidths of multiple gigabytes per second.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
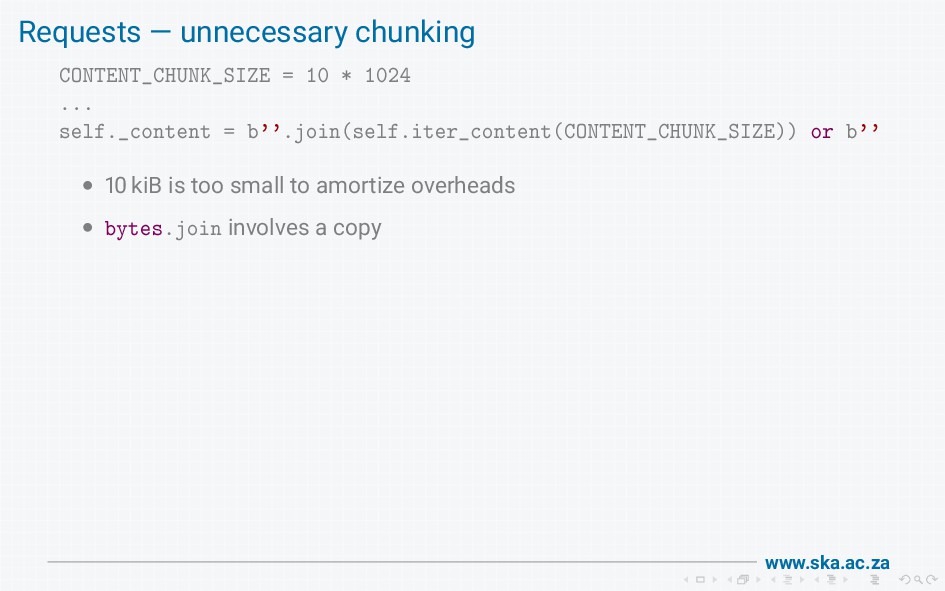{kind=link}
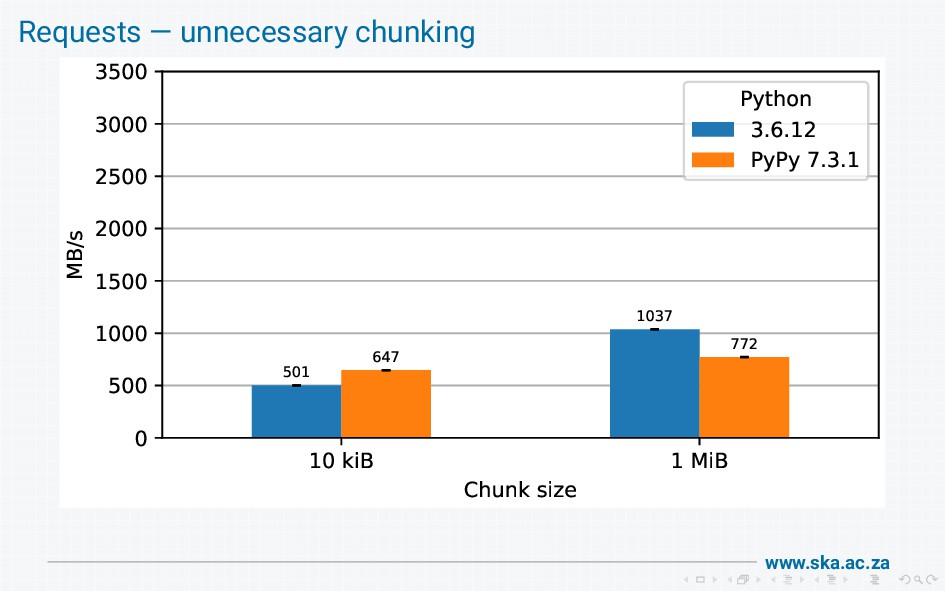{kind=link}
{kind=link}
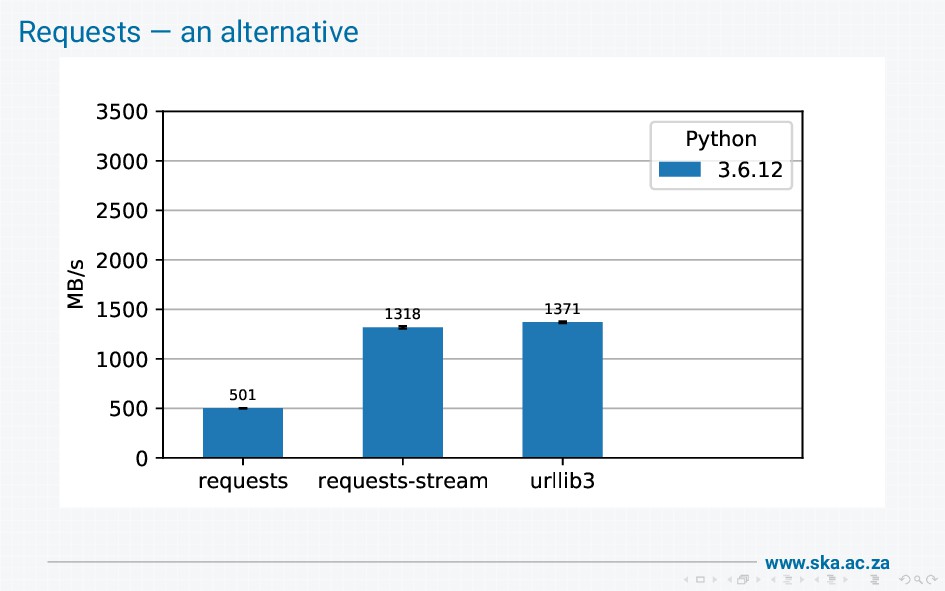{kind=link}
{kind=link}
{kind=link}
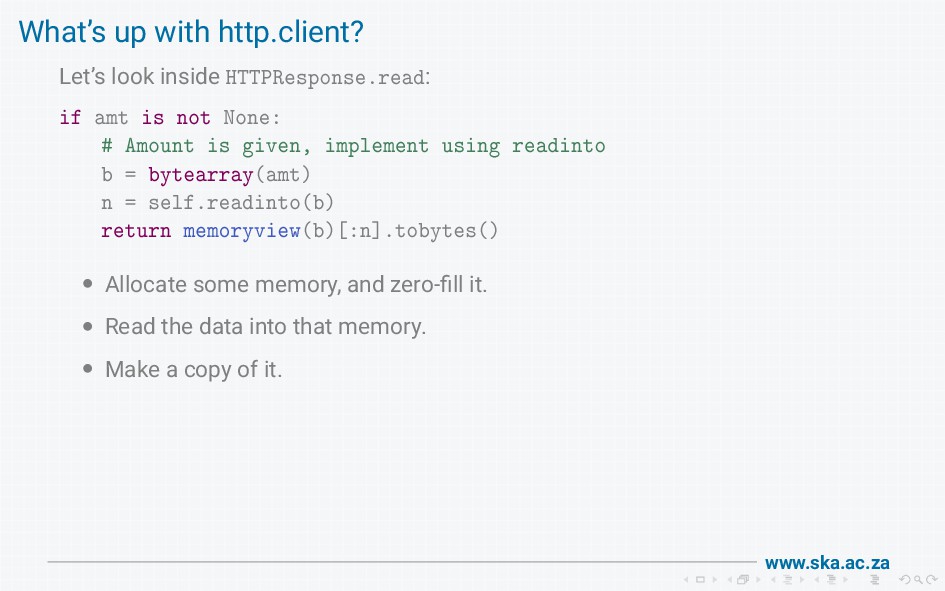{kind=link}
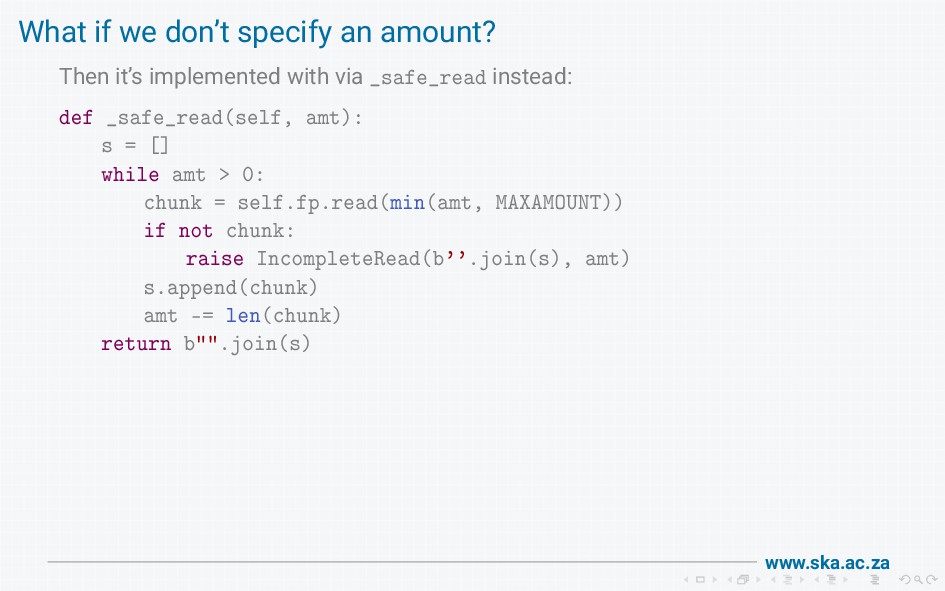{kind=link}
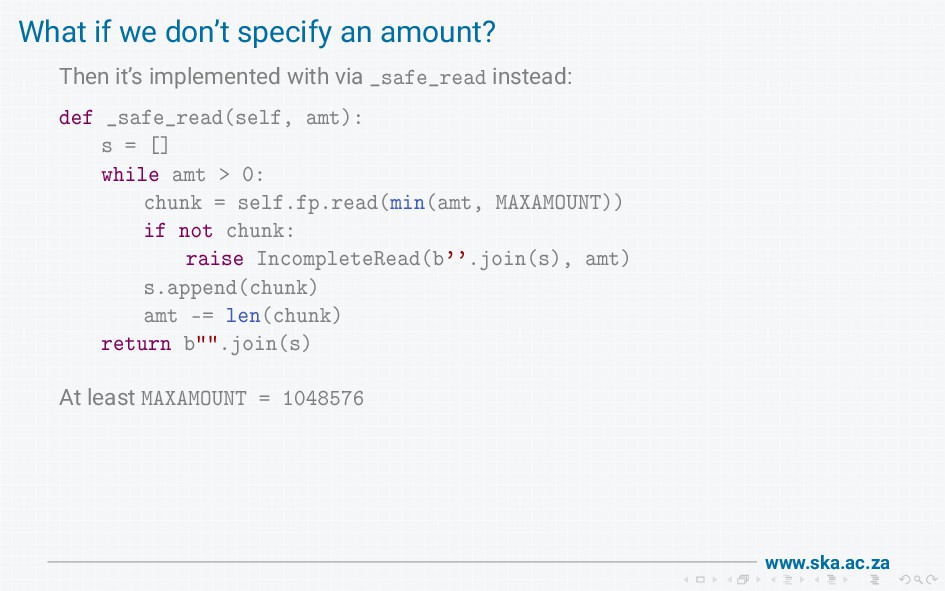{kind=link}
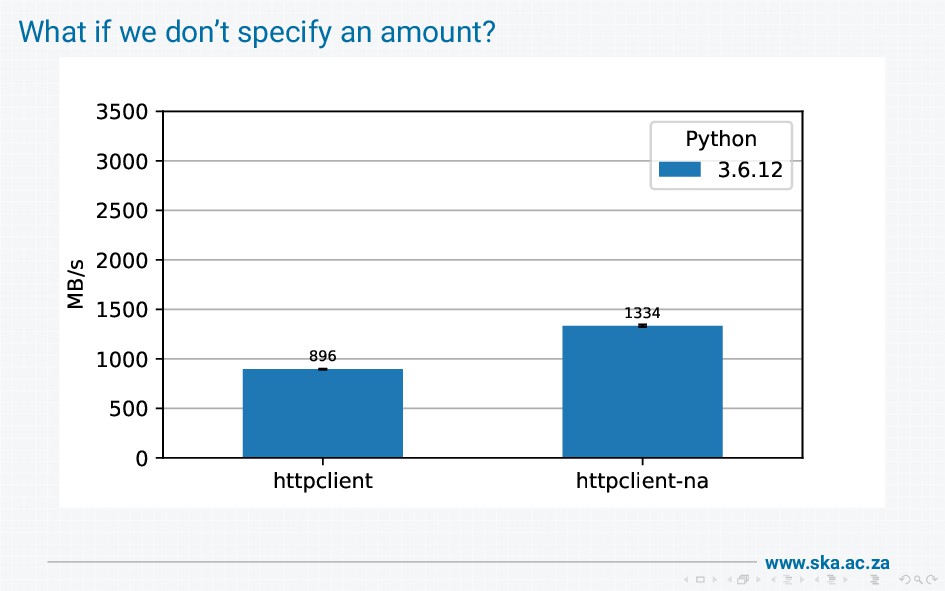{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}