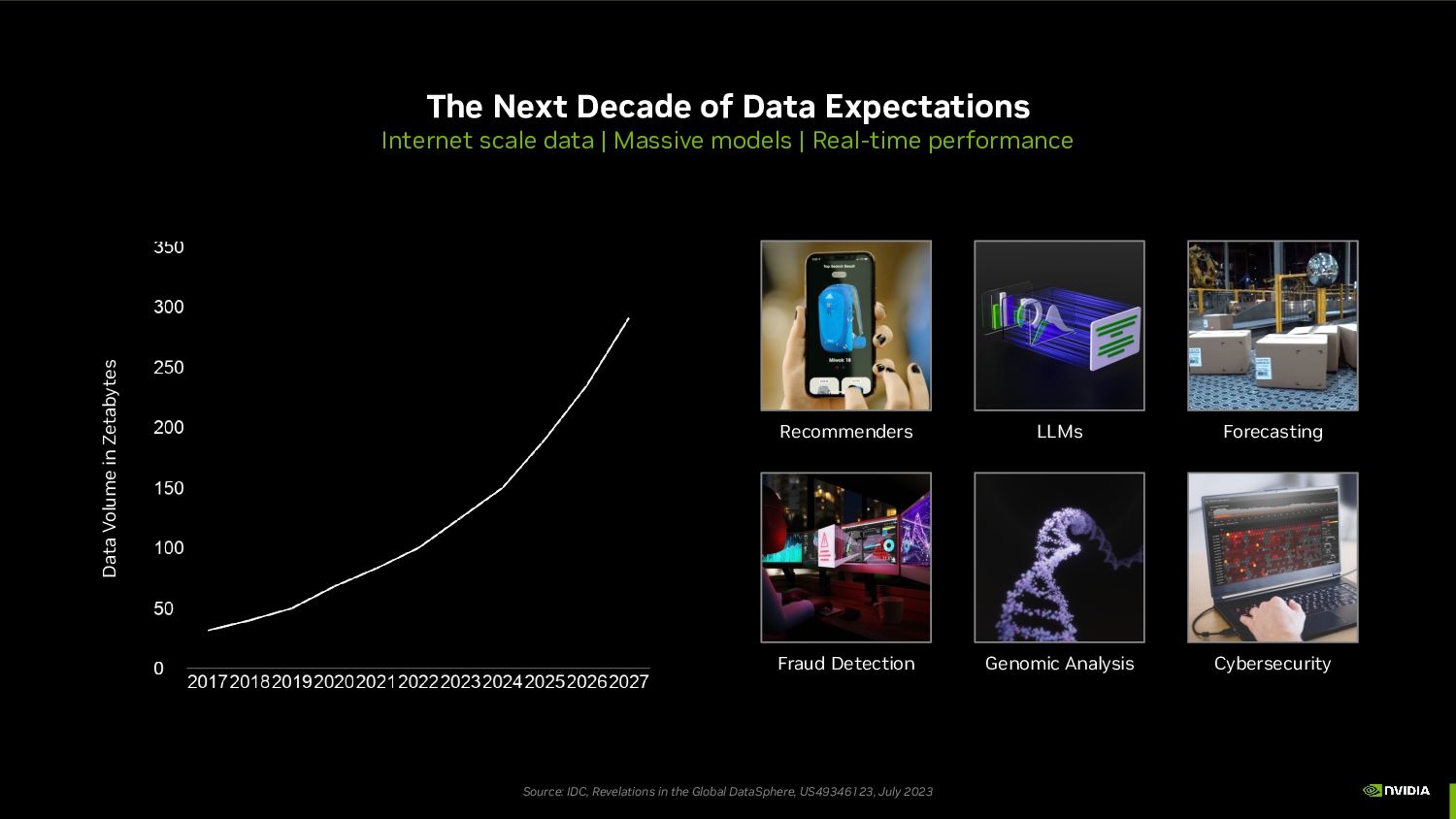
Massive models | Real-time performance Data Volume in Zetabytes Source: IDC, Revelations in the Global DataSphere, US49346123, July 2023 Recommenders Fraud Detection LLMs Genomic Analysis Forecasting Cybersecurity
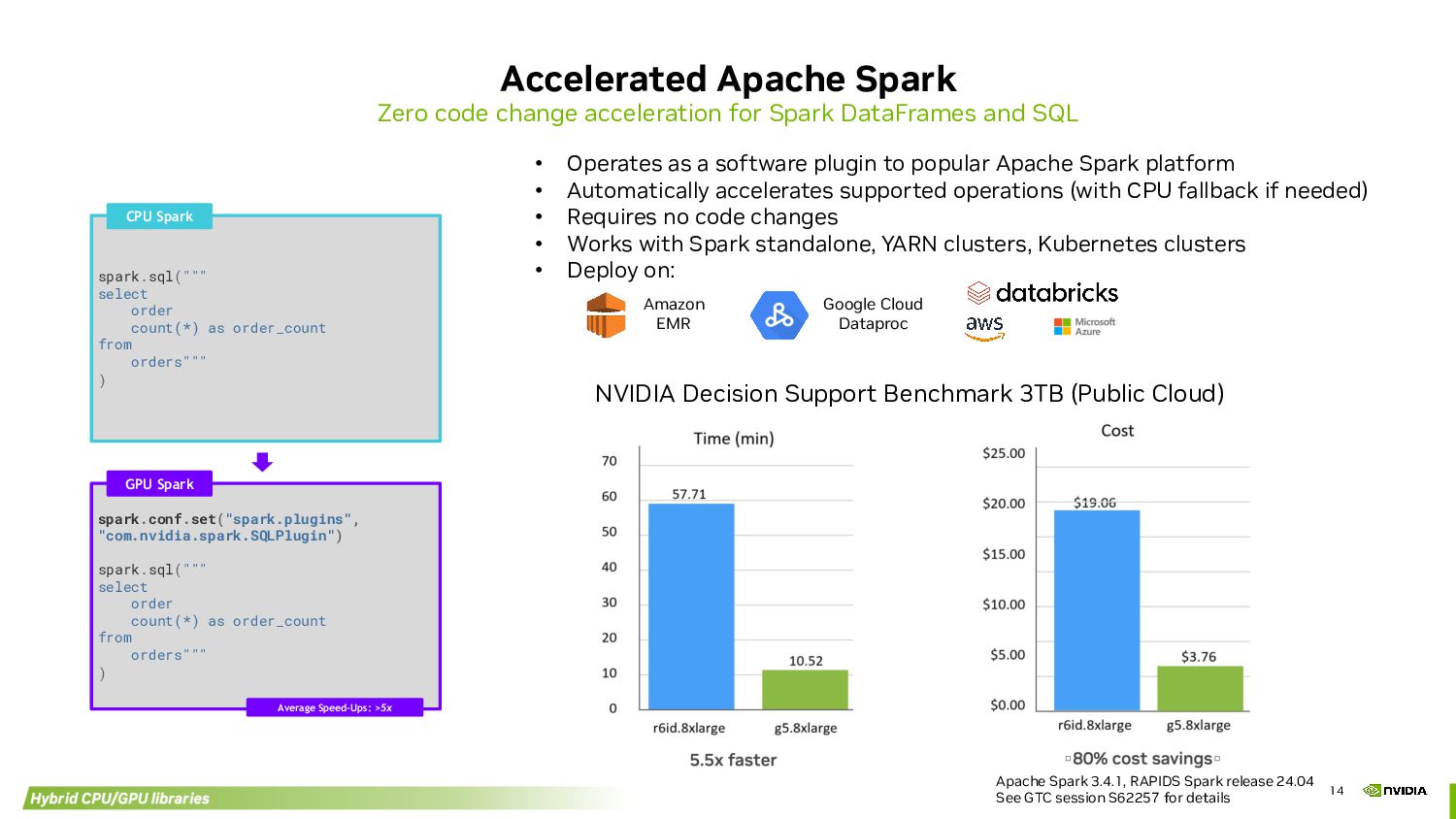
DataFrames and SQL spark.sql(""" select order count(*) as order_count from orders""" ) spark.conf.set("spark.plugins", "com.nvidia.spark.SQLPlugin") spark.sql(""" select order count(*) as order_count from orders""" ) CPU Spark GPU Spark Average Speed-Ups: >5x • Operates as a software plugin to popular Apache Spark platform • Automatically accelerates supported operations (with CPU fallback if needed) • Requires no code changes • Works with Spark standalone, YARN clusters, Kubernetes clusters • Deploy on: Apache Spark 3.4.1, RAPIDS Spark release 24.04 See GTC session S62257 for details NVIDIA Decision Support Benchmark 3TB (Public Cloud) Amazon EMR Google Cloud Dataproc
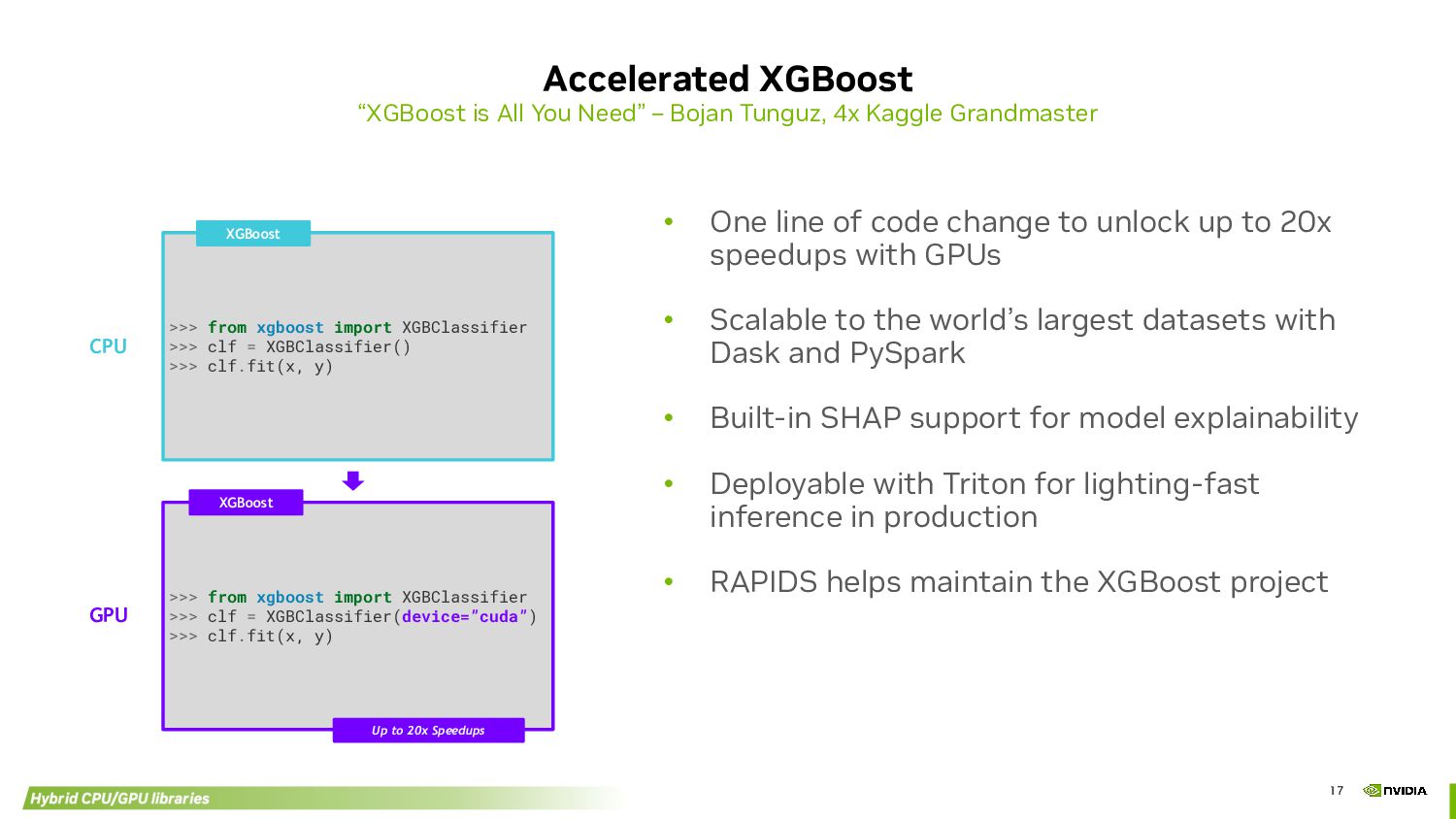
Tunguz, 4x Kaggle Grandmaster >>> from xgboost import XGBClassifier >>> clf = XGBClassifier() >>> clf.fit(x, y) >>> from xgboost import XGBClassifier >>> clf = XGBClassifier(device=”cuda”) >>> clf.fit(x, y) GPU CPU XGBoost XGBoost Up to 20x Speedups • One line of code change to unlock up to 20x speedups with GPUs • Scalable to the world’s largest datasets with Dask and PySpark • Built-in SHAP support for model explainability • Deployable with Triton for lighting-fast inference in production • RAPIDS helps maintain the XGBoost project
NetworkX • Zero-code-change GPU-acceleration of for NetworkX code • Accelerates algorithms up to 600x, based on algorithm and graph size • Support for 60 popular graph algorithms and growing • Falls back to using CPU NetworkX for unsupported algorithms NetworkX 3.2, CPU: Intel(R) Xeon(R) Platinum 8480CL 2TB, GPU: NVIDIA H100 80GB pip install nx-cugraph-cu12 --extra-index-url https://pypi.nvidia.com conda install -c rapidsai -c conda-forge -c nvidia nx-cugraph
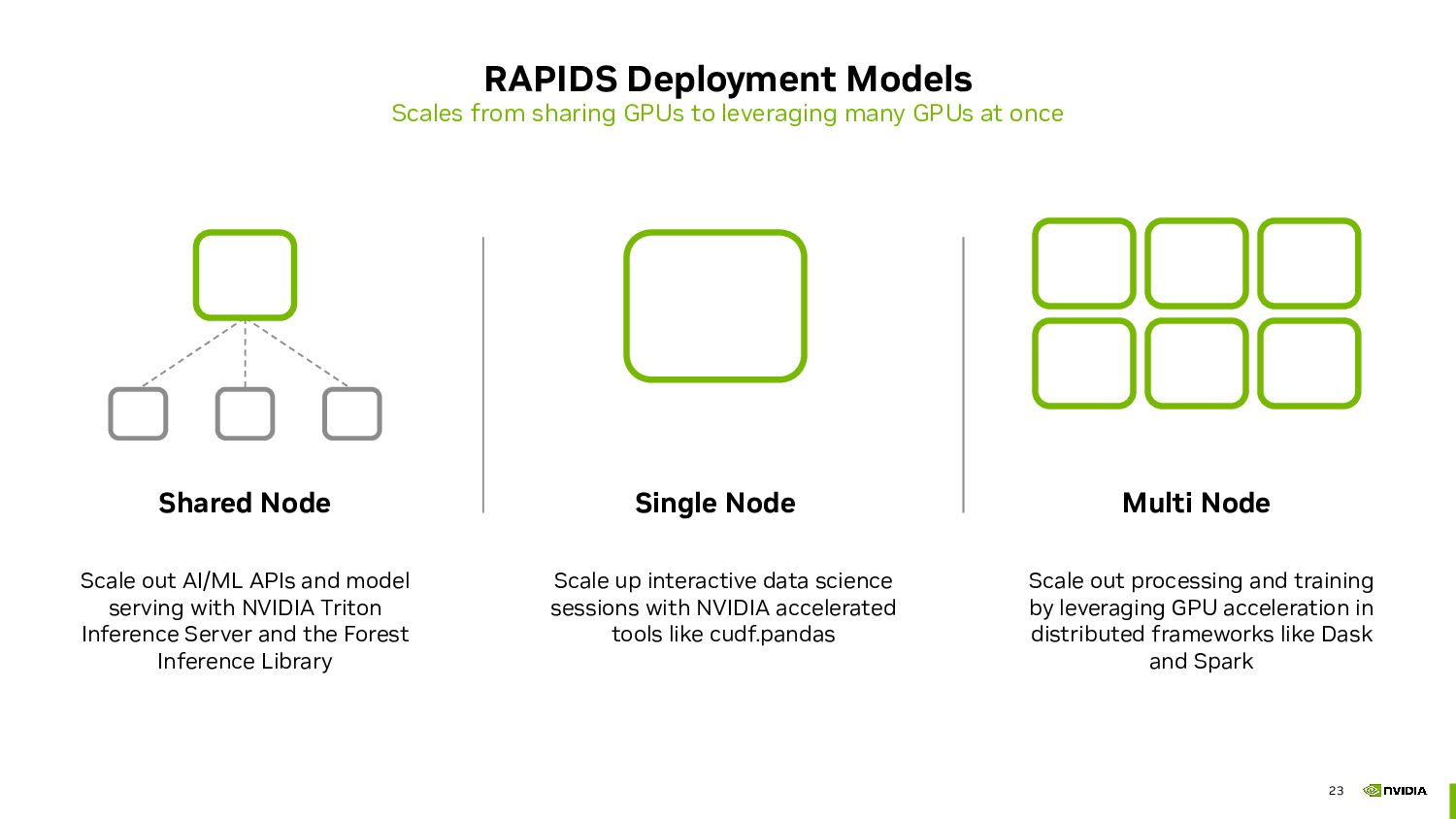
many GPUs at once Single Node Multi Node Shared Node Scale up interactive data science sessions with NVIDIA accelerated tools like cudf.pandas Scale out processing and training by leveraging GPU acceleration in distributed frameworks like Dask and Spark Scale out AI/ML APIs and model serving with NVIDIA Triton Inference Server and the Forest Inference Library
to spend those gains? Reduce cost Reduce the amount of time you need to run servers. Beneficial for reducing cloud costs. Do more work Run more workloads for the same time/cost. Process things that were not possible before. Performance boost Get work done faster. May help give a competitive advantage or reduce pressure on SLAs. Environment impact Reduce power needed to perform the same calculation. Using less power produces less CO2. Reduce context switching Reduce time people need to wait for calculations to complete which helps avoid switching to a different task. Improve accuracy Acceleration could allow for more iterations or to process more data leading to improved model accuracy
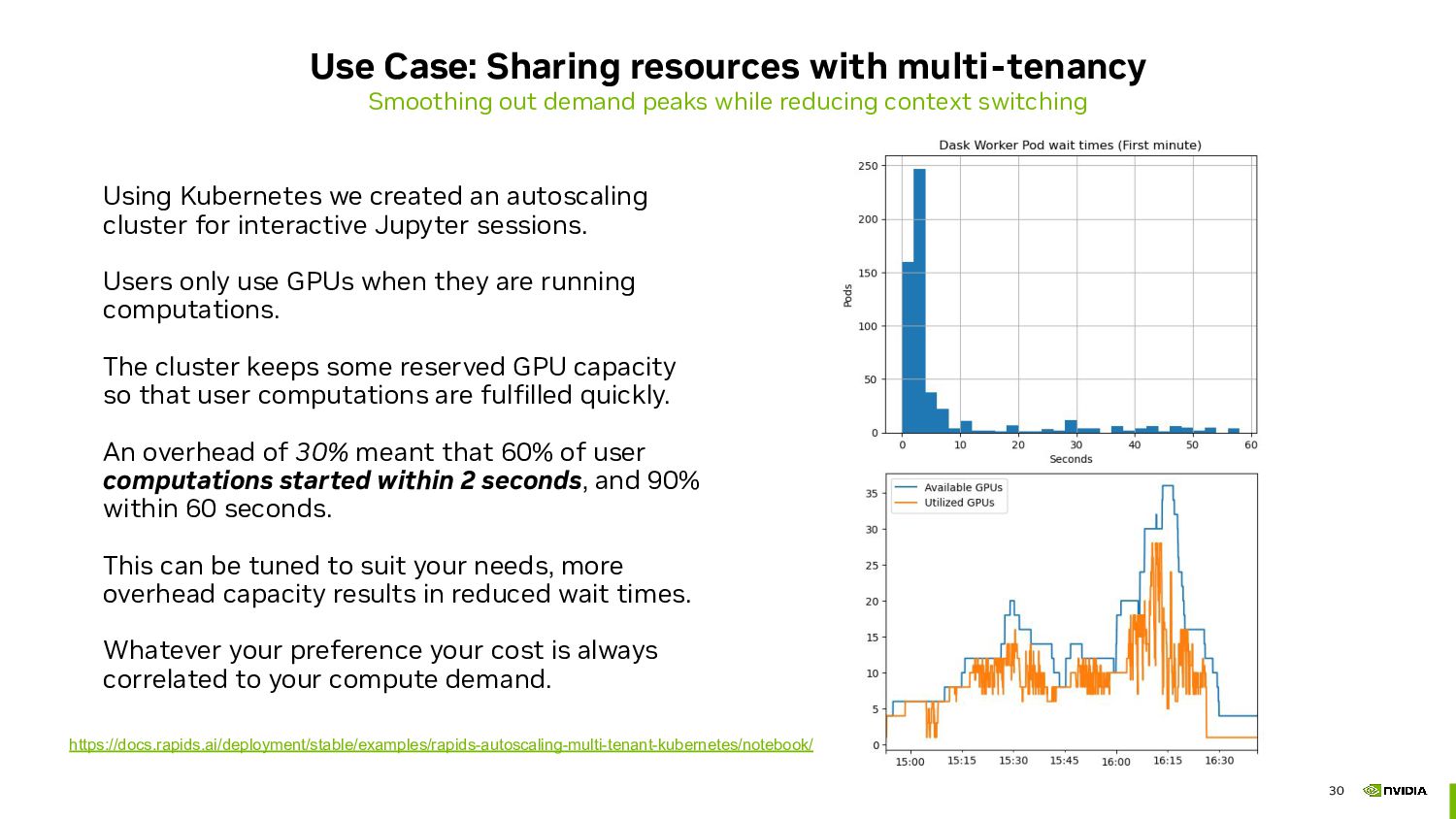
peaks while reducing context switching Using Kubernetes we created an autoscaling cluster for interactive Jupyter sessions. Users only use GPUs when they are running computations. The cluster keeps some reserved GPU capacity so that user computations are fulfilled quickly. An overhead of 30% meant that 60% of user computations started within 2 seconds, and 90% within 60 seconds. This can be tuned to suit your needs, more overhead capacity results in reduced wait times. Whatever your preference your cost is always correlated to your compute demand. https://docs.rapids.ai/deployment/stable/examples/rapids-autoscaling-multi-tenant-kubernetes/notebook/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
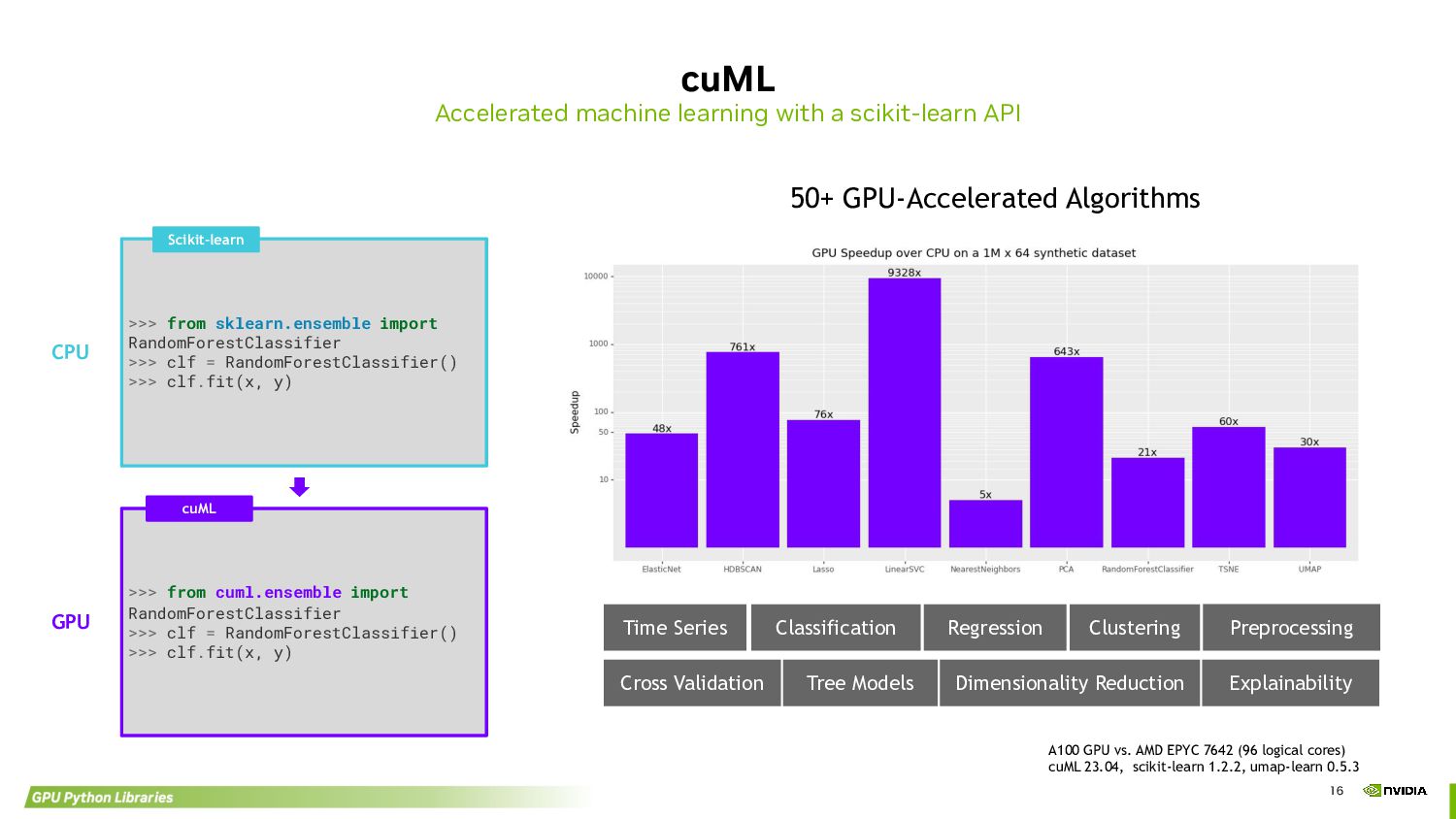{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}