no further distribution PoCと本番環境の差異(クラウドサービスの有無、使用可能なモデルの有無、実行環境の違い )により 開発工数が増大 課題となるパターン1 7 On-premise 顧客環境 AI Dev App Dev Infra Eng AI Application AI Application AI Application Customer A Production Customer A PoC Infra Eng 社内検証・開発環境 サービス実装・モデル再評価 環境構築・ツール選定 環境変更を吸収するための工数増大
no further distribution AIアプリの提供形態・使用技術の多様化 に伴うスキル・環境・アーキテクチャのサイロ化 による現場 のオーバーヘッドが増大 課題となるパターン2 8 On-premise 社内検証・開発環境 顧客環境 On-premise AI Dev App Dev Infra Eng Infra Eng Infra Eng Infra Eng AI Application AI Application AI Application AI Application AI Application AI Application AI Application AI Application Customer A Customer B Customer C Customer D オーバーヘッド大
no further distribution 場所を選ばずAIアプリケーションの価値の最大化 に注力できるプラットフォーム Red Hat AIプラットフォームが目指す世界 10 On-premise 社内検証・開発環境 顧客環境 On-premise AI Dev App Dev Infra Eng AI Application Customer A Customer B Customer C Customer D AI Application AI Application AI Application AI Application
ハードウェアアクセラレーション * NVIDIA, AMD, Intel, Google TPU supported in Red Hat AI. AWS Inferentia/Neuron IBM AIU are on our roadmap 推論エンジン 推論アプライアンス SW AI開発・運用基盤 SW Red Hat AI製品ラインナップ
Red Hat Enterprise Linux AI Red Hat OpenShift AI OS/ドライバ ユーザ用意 Red Hat提供 Red Hat・ベンダ提供 AIモデルによる推論実行 対応 対応 対応 モデルのチューニング 対応 スクラッチからのモデルの学習 対応 コンテナアプリケーションとの 連携開発 対応 分散処理 対応 推論エンジン AI開発・運用基盤 SW 推論アプライアンス SW
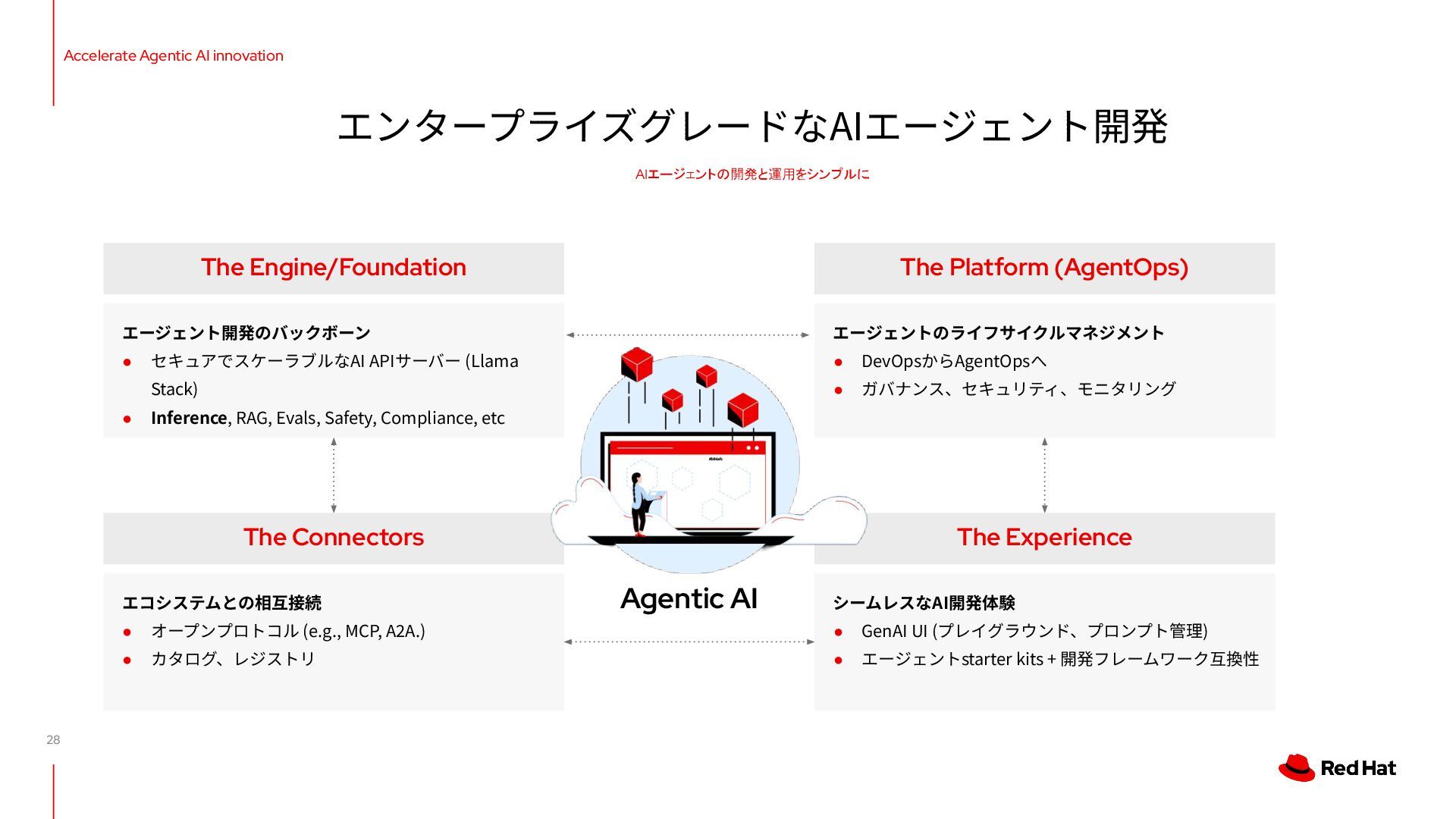
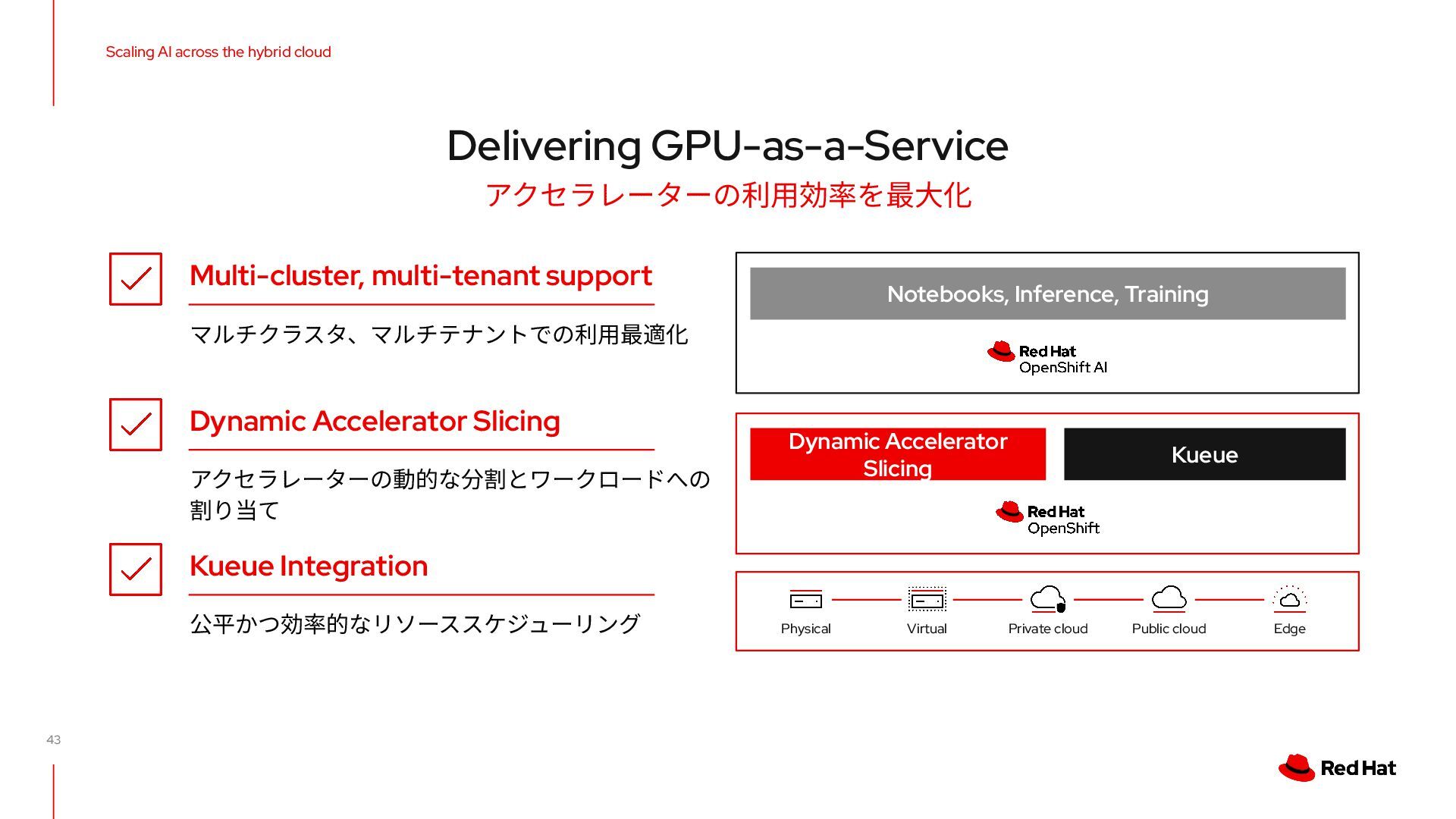
Hub / GenAI Studio • Llama Stack Operator • MCP開発ガイド • Model as a Service • llm-d • モデル最適化 • モデルカタログ 推論機能の更なる進化 柔軟なLLMチューニング • データ合成の多⾔語対応 • チューニング機能の汎⽤化 • KubeFlow Training v2 プラットフォーム機能強化 • 新たなアクセラレーター • OEM/クラウド対応拡充 • GPUaaS Accelerate Agentic AI innovation Fast, flexible and scalable inference Connecting models to data Scaling AI across the hybrid cloud
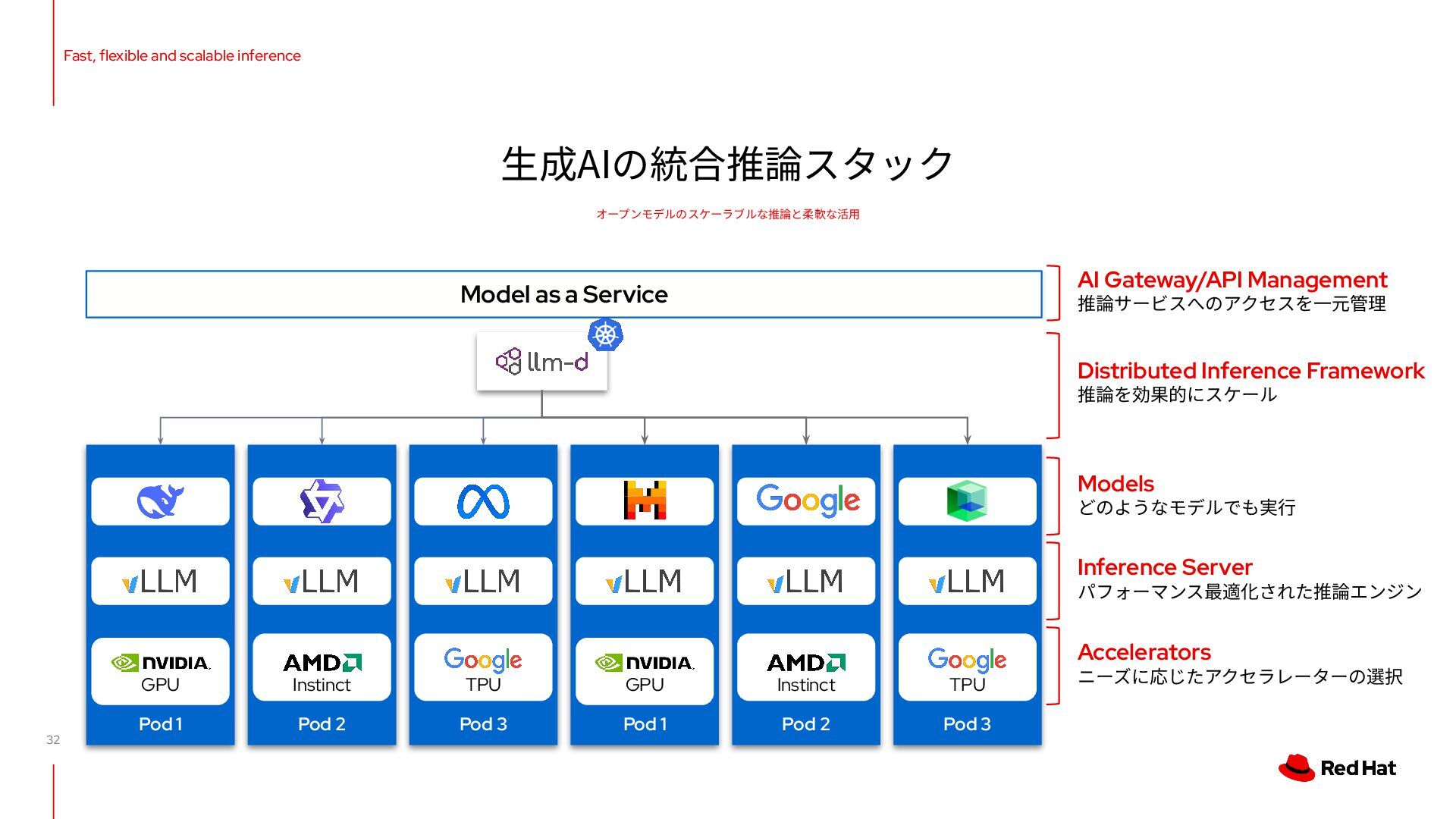
scalable inference ⽣成AIの統合推論スタック オープンモデルのスケーラブルな推論と柔軟な活⽤ GPU Instinct TPU Pod 2 Instinct Pod 1 GPU Pod 3 TPU Accelerators ニーズに応じたアクセラレーターの選択 Inference Server パフォーマンス最適化された推論エンジン Distributed Inference Framework 推論を効果的にスケール Models どのようなモデルでも実⾏ AI Gateway/API Management 推論サービスへのアクセスを⼀元管理 Model as a Service
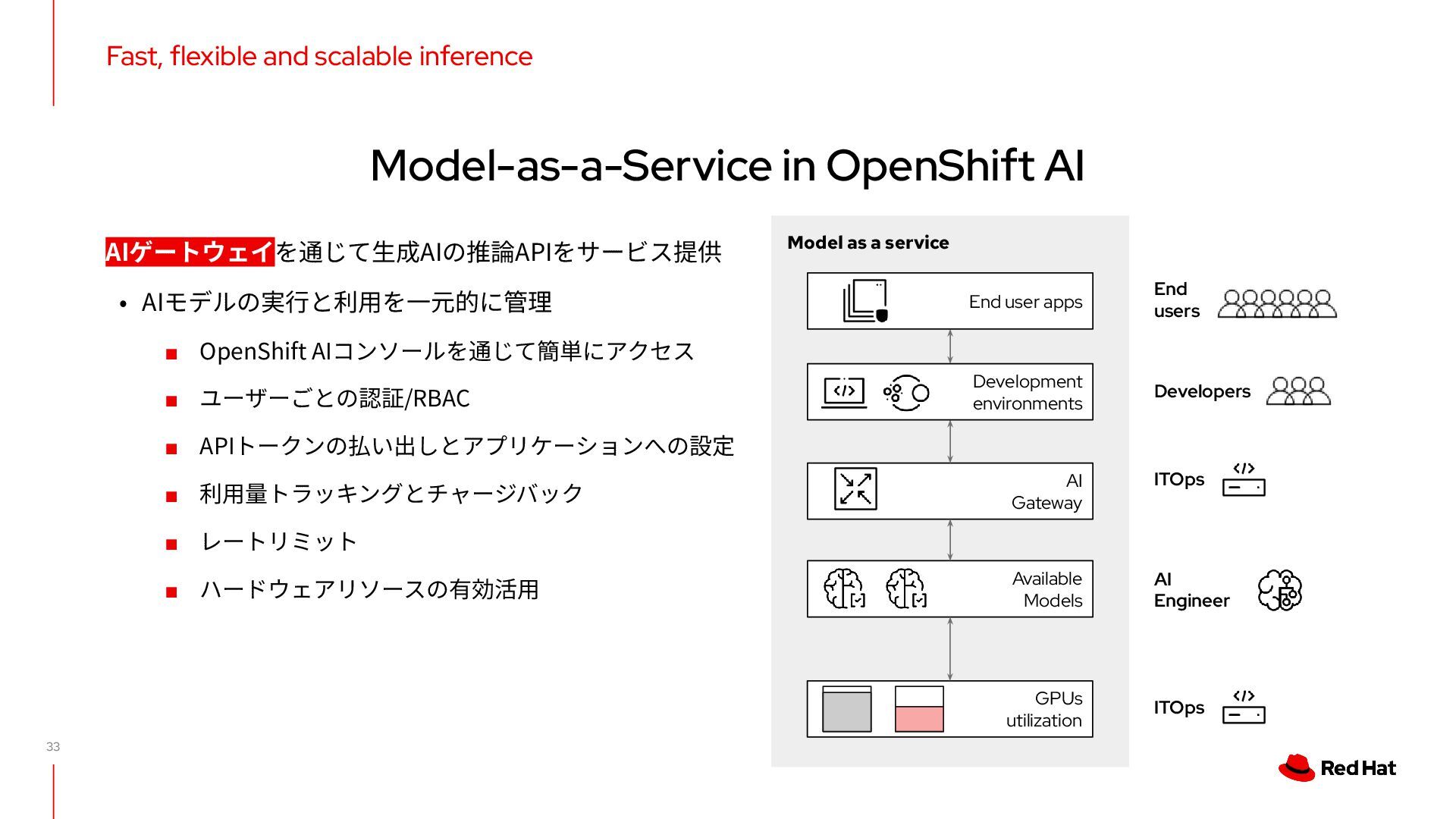
APIトークンの払い出しとアプリケーションへの設定 ▪ 利⽤量トラッキングとチャージバック ▪ レートリミット ▪ ハードウェアリソースの有効活⽤ Fast, flexible and scalable inference Model-as-a-Service in OpenShift AI Model as a service Developers End users AI Gateway Available Models AI Engineer GPUs utilization End user apps Development environments ITOps ITOps
• マルチターンエージェント向けの⾼速なレスポンス • シンプルな運⽤管理 Deliver faster, cheaper, and more manageable AI systems for enterprise production Now includes llm-d reimagines how LLMs run on Kubernetes
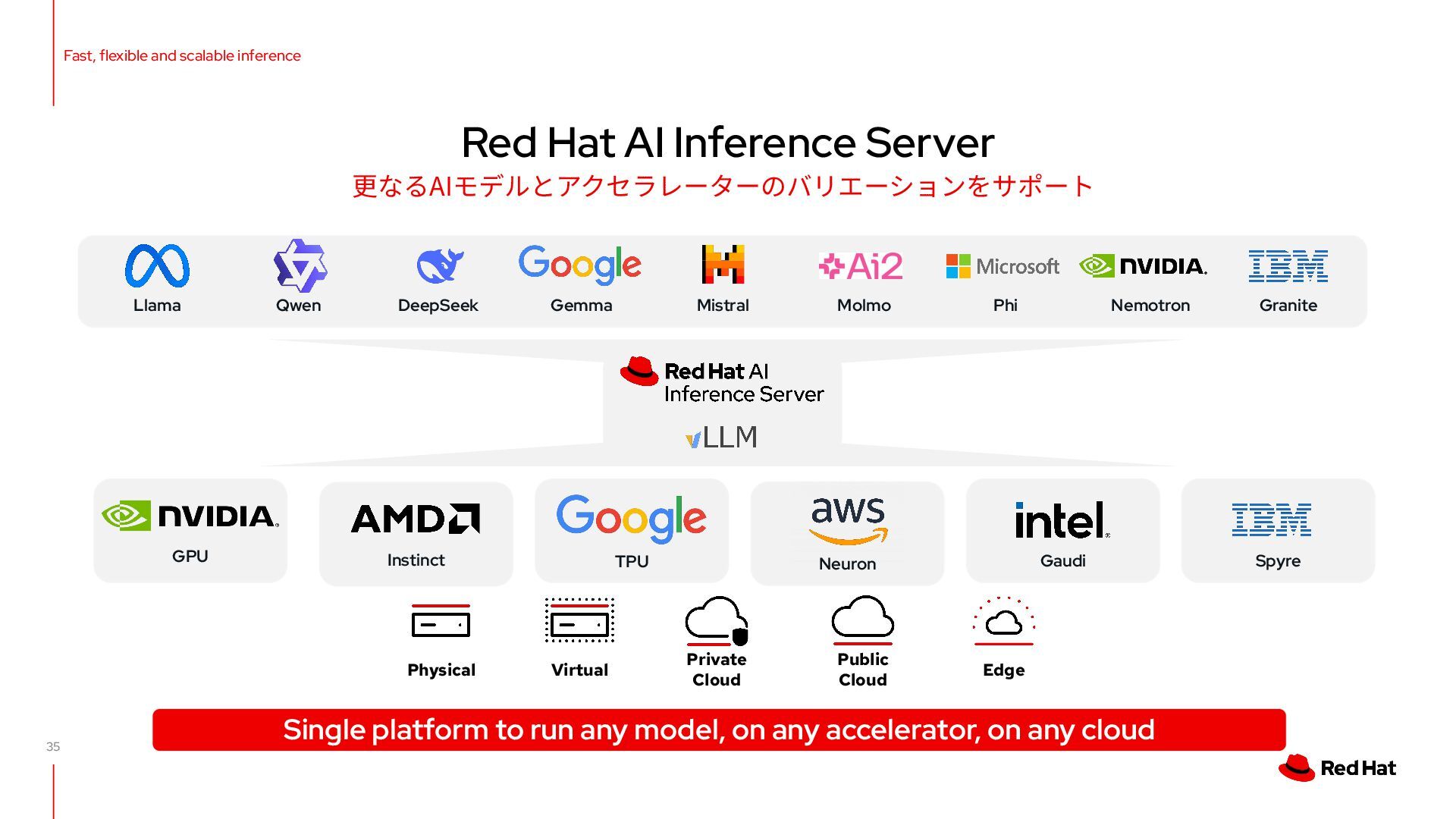
run any model, on any accelerator, on any cloud Edge Virtual Public Cloud Private Cloud Physical Neuron TPU Gaudi Instinct GPU Llama Qwen DeepSeek Gemma Mistral Molmo Phi Nemotron Granite Spyre Fast, flexible and scalable inference
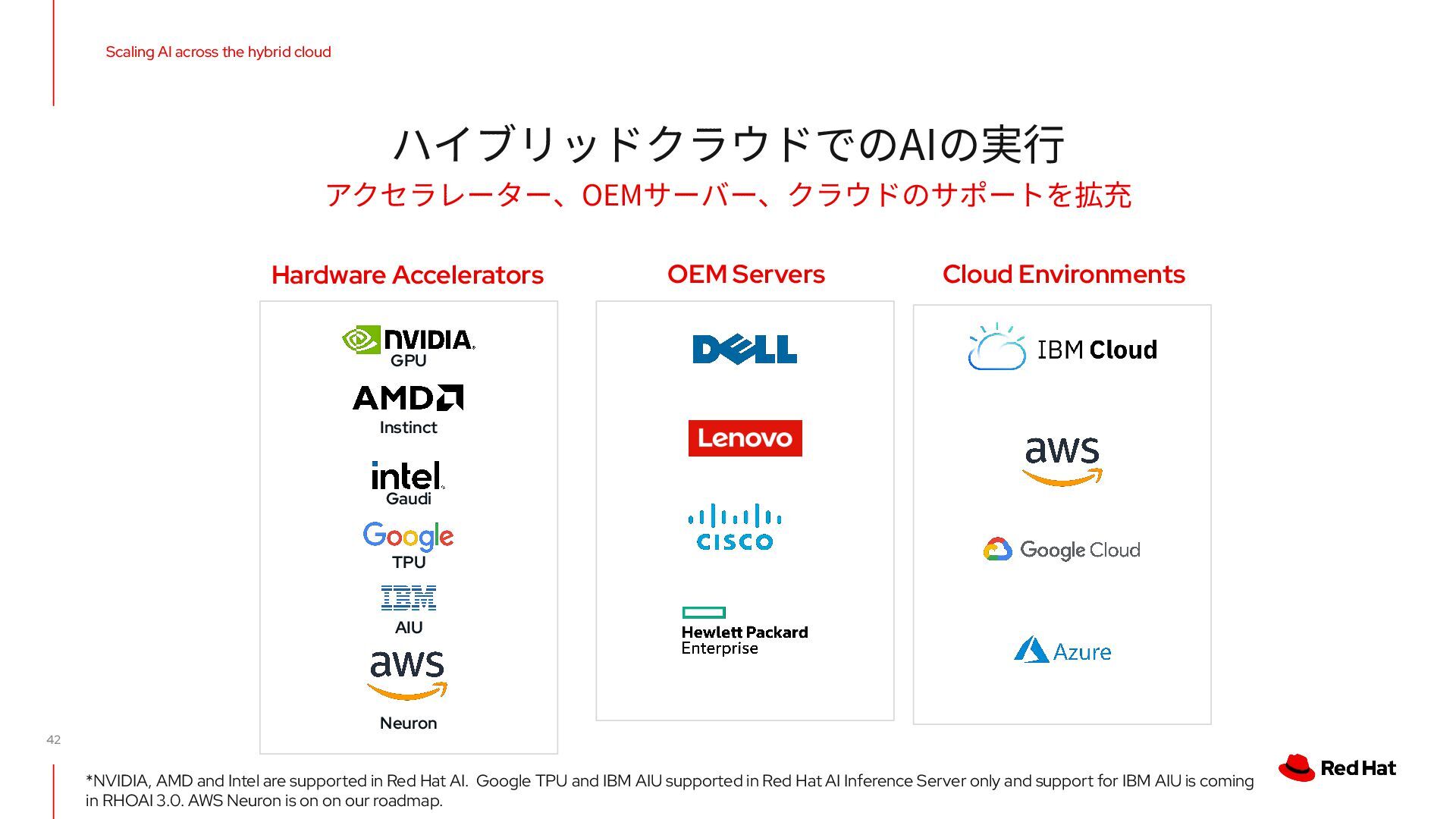
AMD and Intel are supported in Red Hat AI. Google TPU and IBM AIU supported in Red Hat AI Inference Server only and support for IBM AIU is coming in RHOAI 3.0. AWS Neuron is on on our roadmap. Scaling AI across the hybrid cloud Neuron Gaudi TPU GPU Instinct AIU
the world’s leading provider of enterprise open source software solutions. Award-winning support, training, and consulting services make Red Hat a trusted adviser to the Fortune 500. Thank you
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
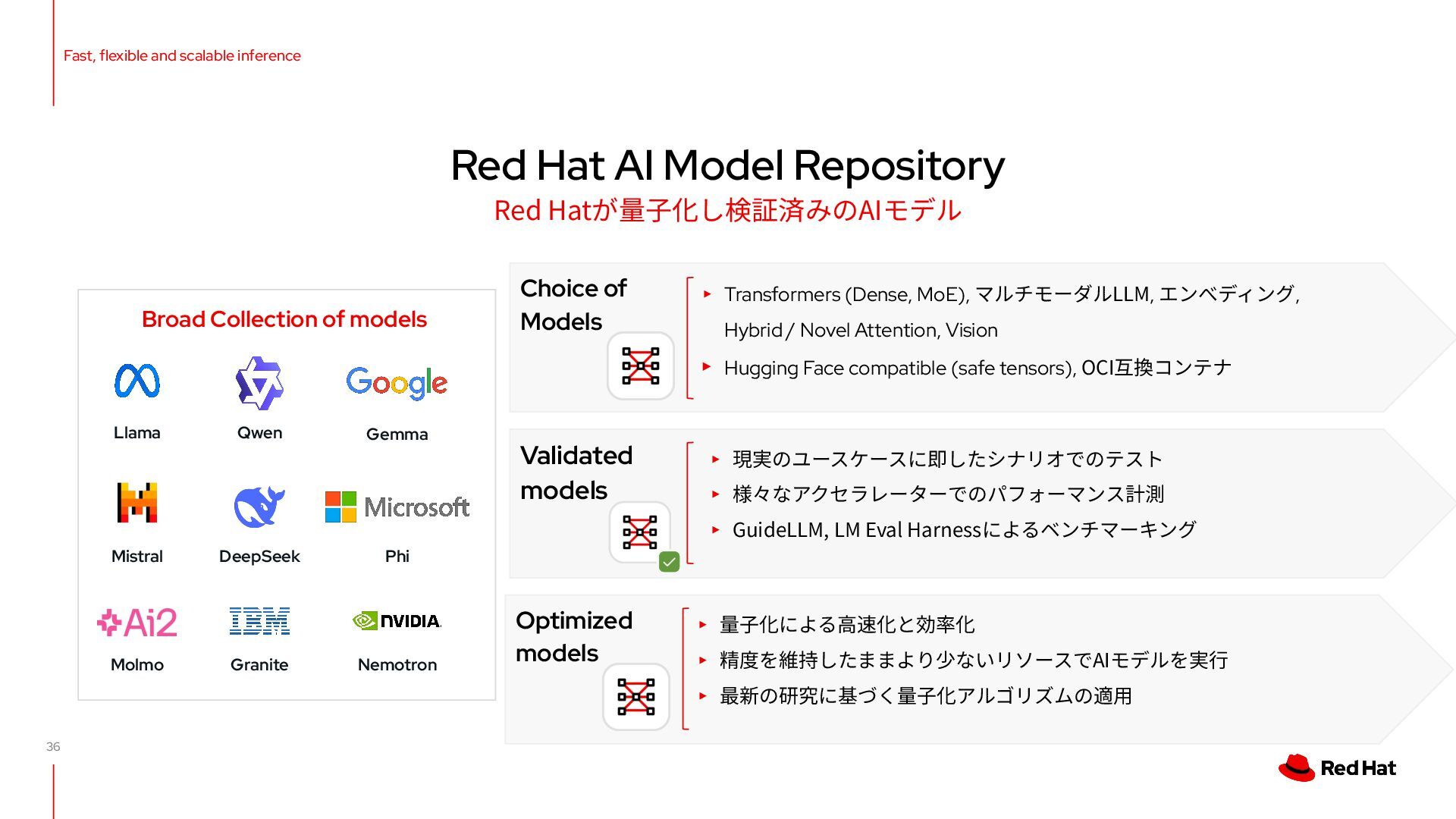{kind=link}
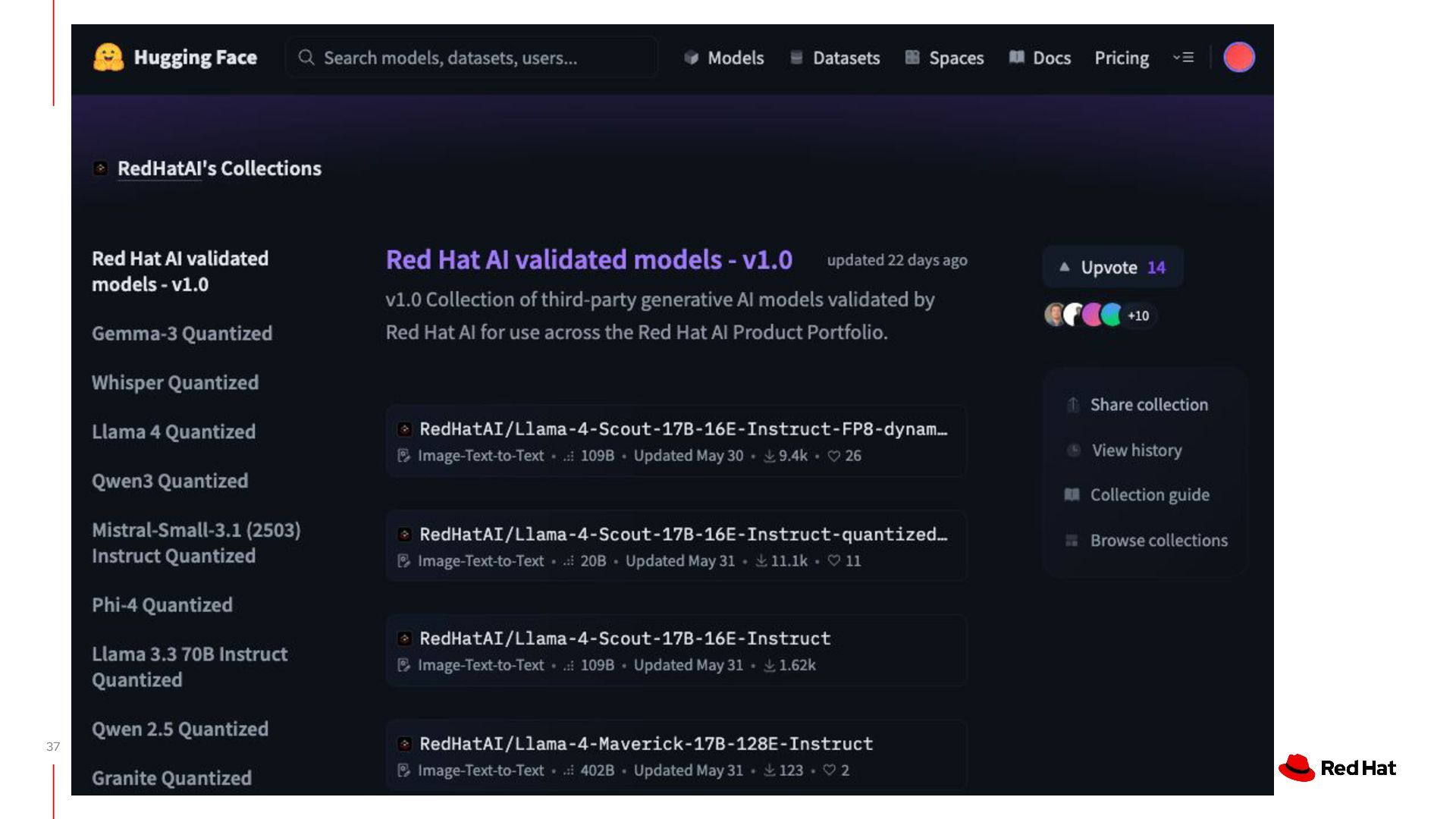{kind=link}
{kind=link}
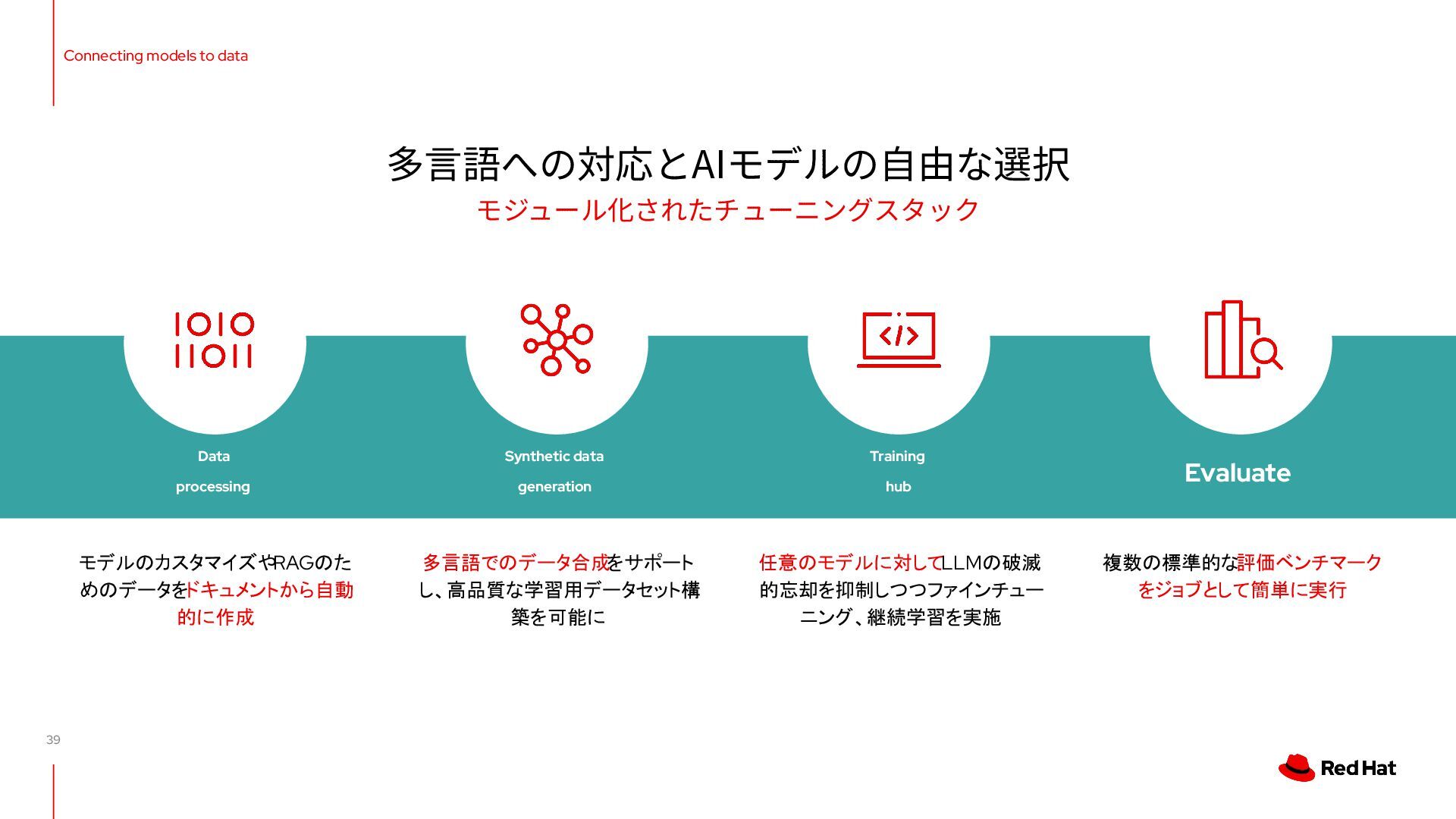{kind=link}
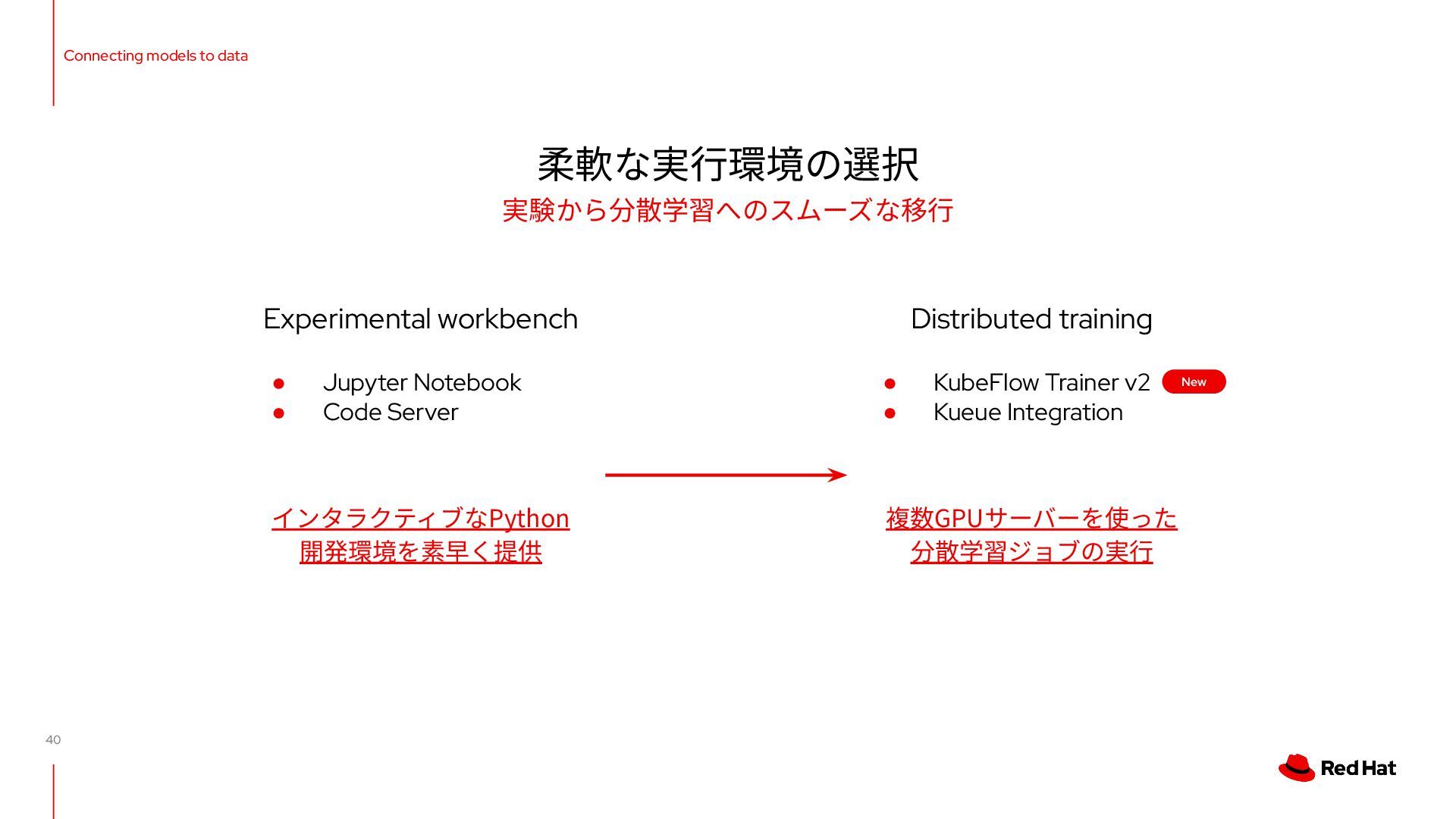{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}