Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
shake-upを科学する
Search
Jack
July 11, 2025
Technology
3.1k
13
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
shake-upを科学する
Jack
July 11, 2025
More Decks by Jack
See All by Jack
Feature Importanceによる特徴量選択とリーク
rsakata
7
9.1k
How to encode categorical features for GBDT
rsakata
8
16k
Kaggle Meetup #4 Lightning Talks
rsakata
8
5.7k
Santander Product RecommendationのアプローチとXGBoostの小ネタ
rsakata
29
52k
Other Decks in Technology
See All in Technology
“それは自分の仕事じゃない"を 越えて行け
yuukiyo
1
480
凡エンジニアがこの先生きのこるためには。〜TypeScript完全に理解したい〜
alchemy1115
2
310
実践!既存 Project への AI-Driven Development 適用〜 一ヶ月で Project 唯一のフロントエンドエンジニアを作り出せ〜
lycorptech_jp
PRO
0
230
SRE Next 2026 何でも屋からの脱却
bto
0
950
そのドキュメント、自動化しませんか?
yuksew
1
300
AI Agent SaaS を支える自社仮想化基盤への挑戦と実運用 / ai-agent-saas-virtualization
flatt_security
3
4.2k
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
2
390
アップデートで何が変わった?デモで学んで使いこなすIBM Bob2.0
muehara
0
120
Compose 新機能総まとめ / What's New in Jetpack Compose
yanzm
0
320
AI時代のYAGNI:「爆速で無駄になった機能」からの学び / 20260720 Naoki Takahashi
shift_evolve
PRO
2
320
SRE依存からの脱却 運用を開 発チームへ移す、 フルサイ クル開 発体制の実践
joooee0000
0
3.1k
Network Firewallやっていき!
news_it_enj
0
170
Featured
See All Featured
The Art of Programming - Codeland 2020
erikaheidi
57
14k
エンジニアに許された特別な時間の終わり
watany
108
250k
Documentation Writing (for coders)
carmenintech
77
5.4k
From π to Pie charts
rasagy
0
240
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3.3k
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.8k
Large-scale JavaScript Application Architecture
addyosmani
515
110k
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
Building a Scalable Design System with Sketch
lauravandoore
463
34k
Being A Developer After 40
akosma
91
590k
The Language of Interfaces
destraynor
162
27k
Optimizing for Happiness
mojombo
378
71k
Transcript
ALLPPT.com _ Free PowerPoint Templates, Diagrams and Charts ALLPPT.com _
Free PowerPoint Templates, Diagrams and Charts Jack (Japan) https://www.kaggle.com/rsakata shake-upを科学する 2025/7/11 関西Kaggler会 2025#2
主旨 「いかにコンペで勝つか」 ではなく 「いかにコンペでshake-upを狙うか」 という 半分ふざけたテーマを真面目に考察します (ネタとしてお聞きください) ※本来、shake-upは順位変動そのものを指す用語であり、そこには順位が「上がる」という意味 は含まれなかったものと思われますが、ここでは我が国の慣例に従い、順位変動自体をshake、 それにより順位が上がる、下がることをshake-up,
shake-downと表現します
過去のshake-up実績 Child Mind Institute — Problematic Internet Use (2024) CIBMTR
- Equity in post-HCT Survival Predictions (2024) M5 Forecasting – Accuracy (2020) 2019 Data Science Bowl (2019) Mercedes-Benz Greener Manufacturing (2017) Zillow Prize: Zillow’s Home Value Prediction (Zestimate) (2017)
過去のshake-down実績 Eedi - Mining Misconceptions in Mathematics (2024) Corporación Favorita
Grocery Sales Forecasting (2017) Higgs Boson Machine Learning Challenge (2014)
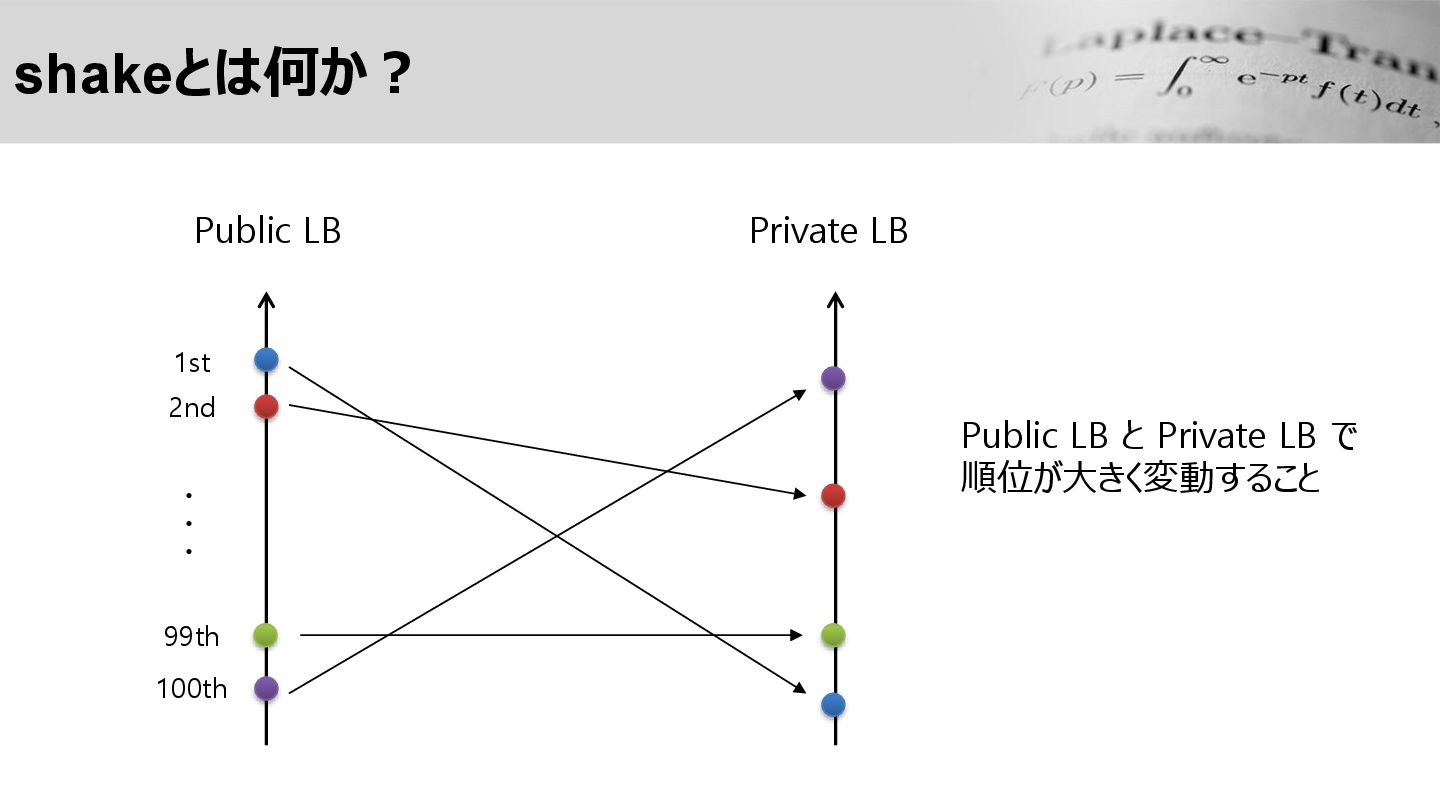
shakeとは何か? Public LB Private LB 1st 2nd 99th 100th ・
・ ・ Public LB と Private LB で 順位が大きく変動すること
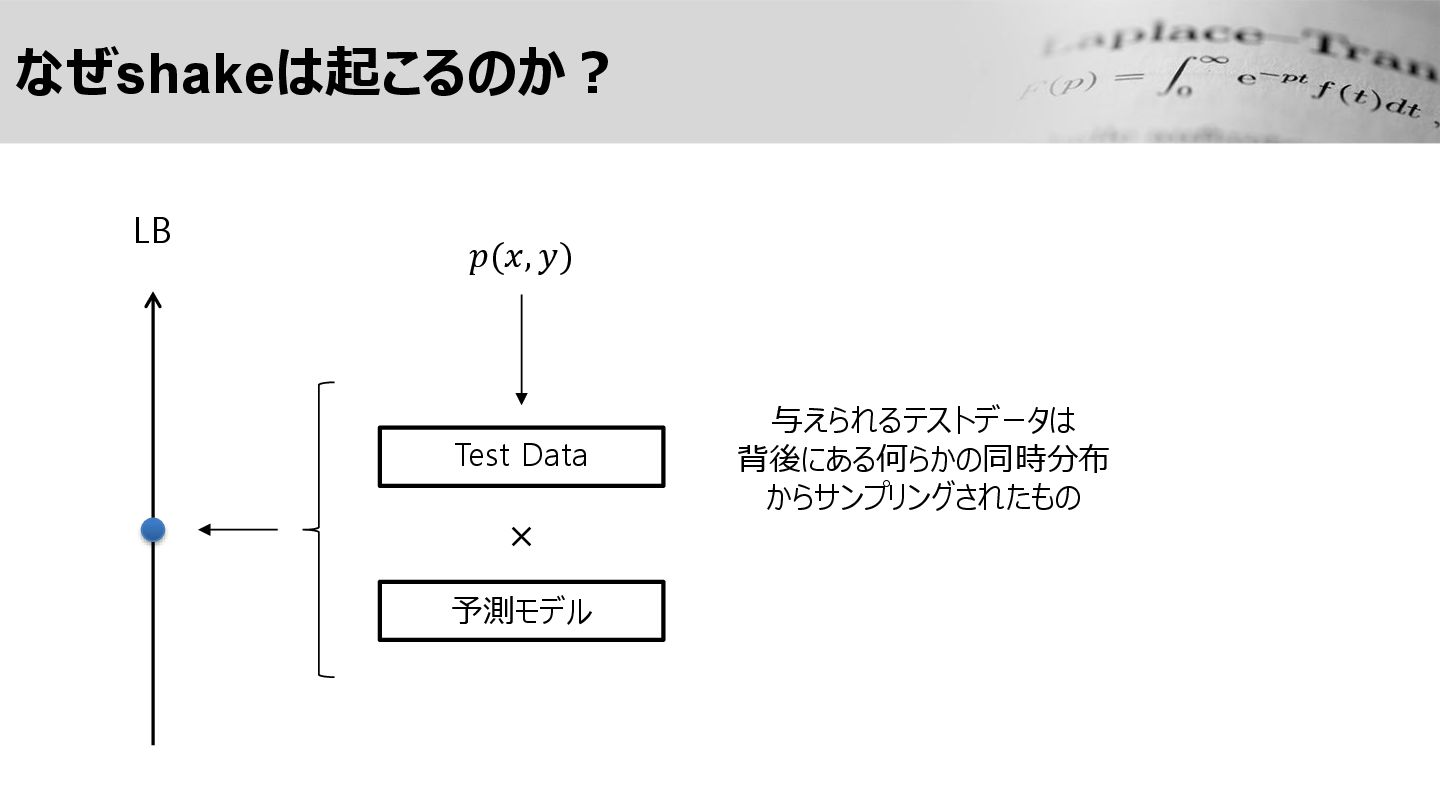
なぜshakeは起こるのか? LB Test Data × 予測モデル 𝑝(𝑥, 𝑦) 与えられるテストデータは 背後にある何らかの同時分布
からサンプリングされたもの
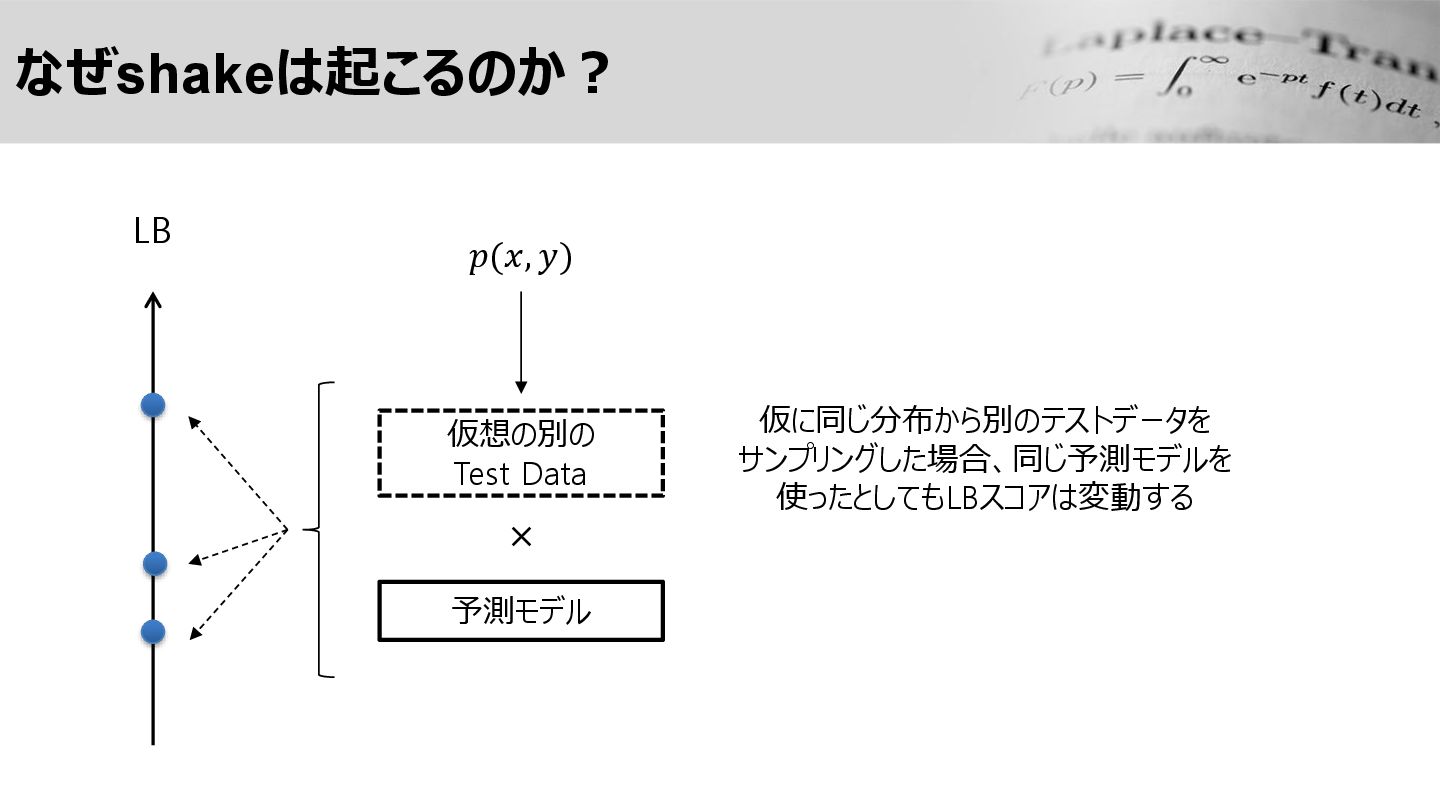
なぜshakeは起こるのか? LB 𝑝(𝑥, 𝑦) 仮想の別の Test Data × 予測モデル 仮に同じ分布から別のテストデータを
サンプリングした場合、同じ予測モデルを 使ったとしてもLBスコアは変動する
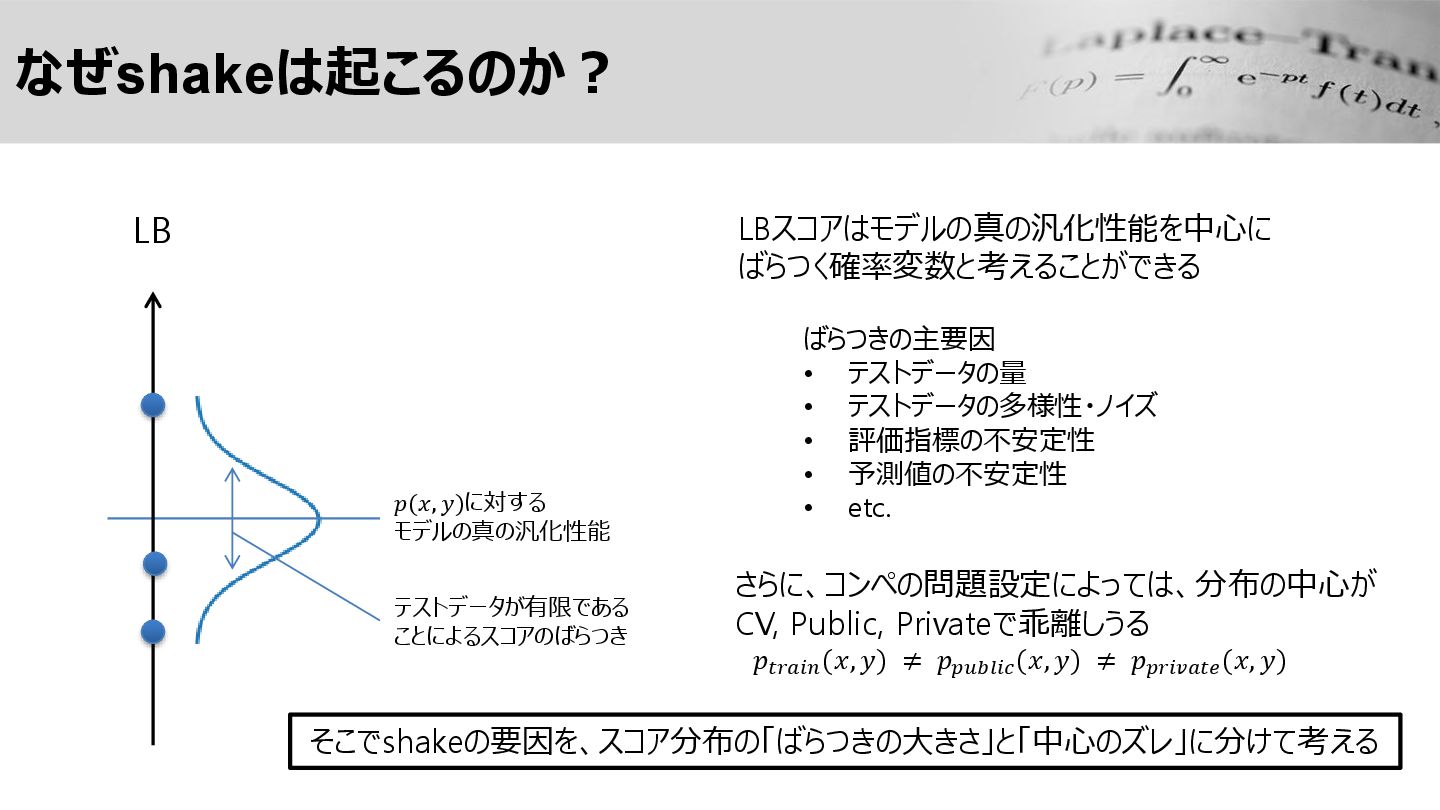
なぜshakeは起こるのか? LB LBスコアはモデルの真の汎化性能を中心に ばらつく確率変数と考えることができる 𝑝(𝑥, 𝑦)に対する モデルの真の汎化性能 ばらつきの主要因 • テストデータの量
• テストデータの多様性・ノイズ • 評価指標の不安定性 • 予測値の不安定性 • etc. さらに、コンペの問題設定によっては、分布の中心が CV, Public, Privateで乖離しうる 𝑝𝑡𝑟𝑎𝑖𝑛 (𝑥, 𝑦) ≠ 𝑝𝑝𝑢𝑏𝑙𝑖𝑐 (𝑥, 𝑦) ≠ 𝑝𝑝𝑟𝑖𝑣𝑎𝑡𝑒 (𝑥, 𝑦) そこでshakeの要因を、スコア分布の「ばらつきの大きさ」と「中心のズレ」に分けて考える テストデータが有限である ことによるスコアのばらつき
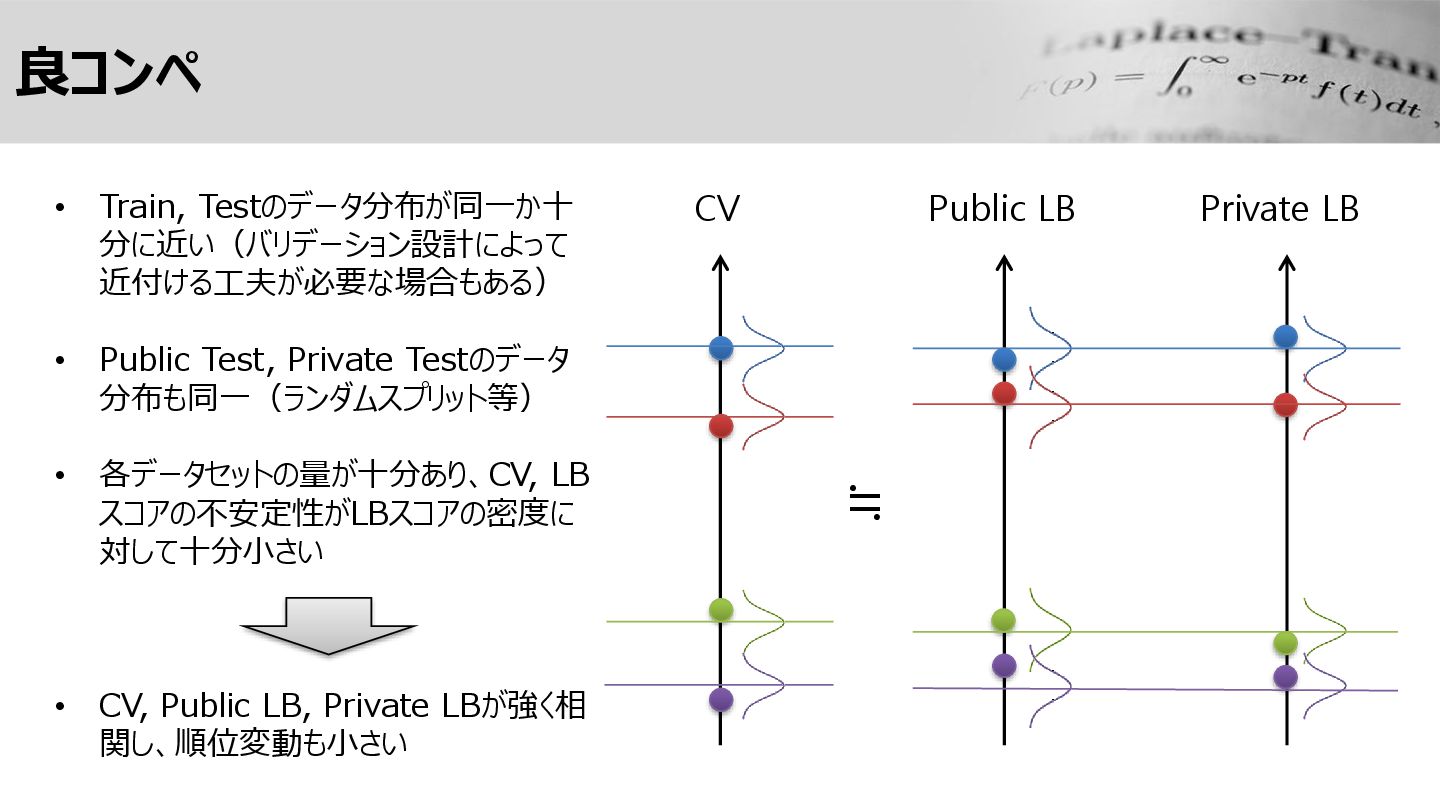
良コンペ Public LB CV Private LB • Train, Testのデータ分布が同一か十 分に近い(バリデーション設計によって
近付ける工夫が必要な場合もある) • Public Test, Private Testのデータ 分布も同一(ランダムスプリット等) • 各データセットの量が十分あり、CV, LB スコアの不安定性がLBスコアの密度に 対して十分小さい • CV, Public LB, Private LBが強く相 関し、順位変動も小さい ≒
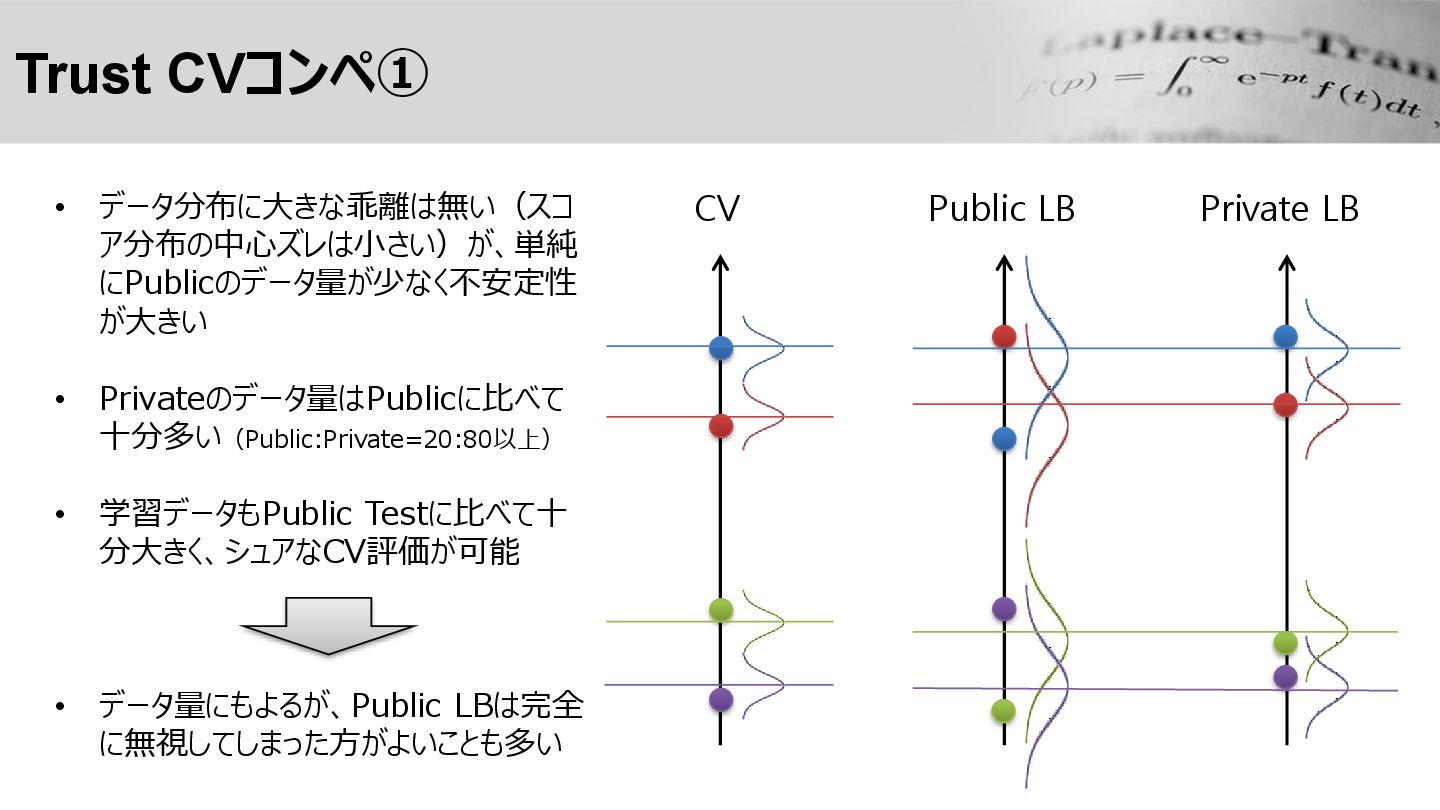
Trust CVコンペ① Public LB Private LB • データ分布に大きな乖離は無い(スコ ア分布の中心ズレは小さい)が、単純 にPublicのデータ量が少なく不安定性
が大きい • Privateのデータ量はPublicに比べて 十分多い(Public:Private=20:80以上) • 学習データもPublic Testに比べて十 分大きく、シュアなCV評価が可能 • データ量にもよるが、Public LBは完全 に無視してしまった方がよいことも多い CV
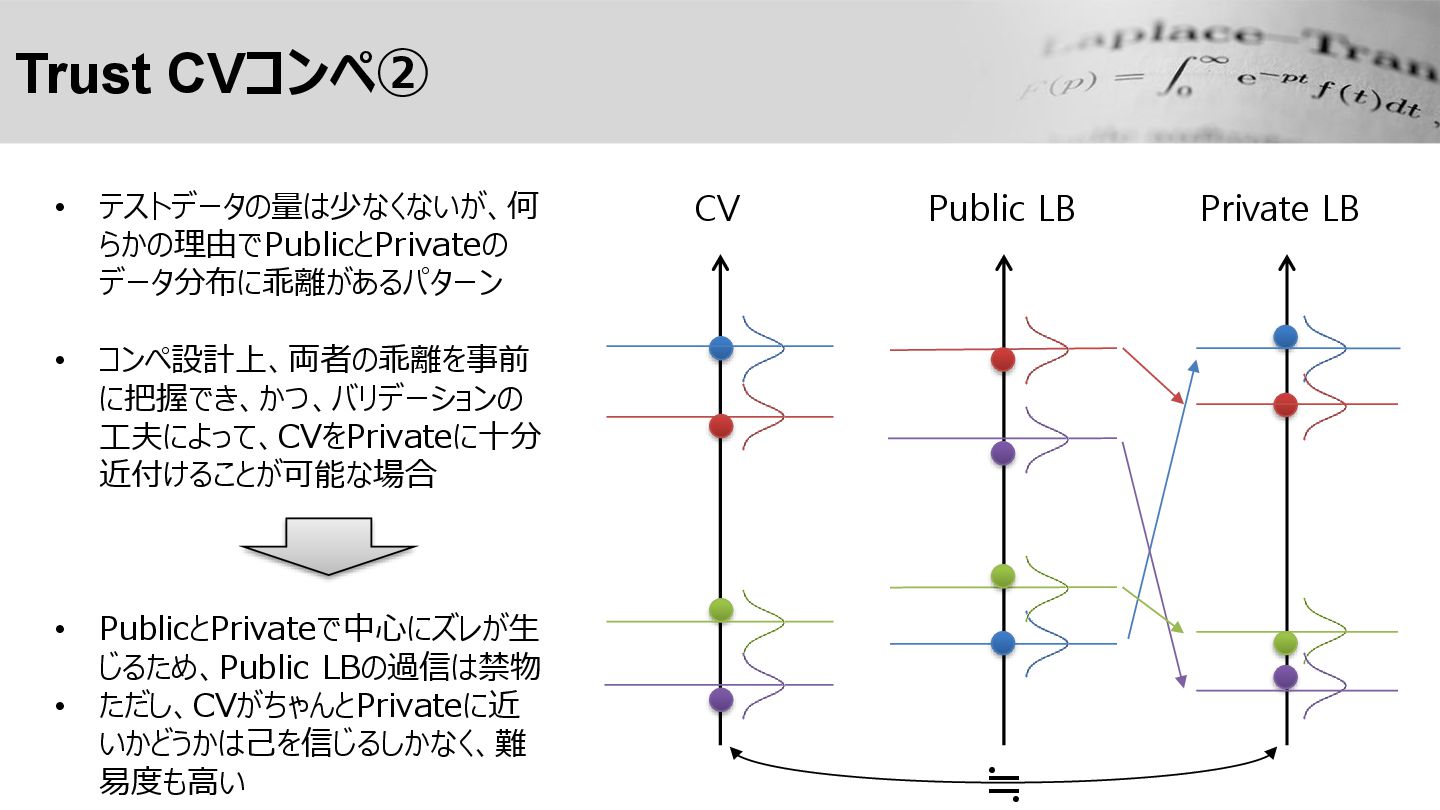
Trust CVコンペ② Private LB • テストデータの量は少なくないが、何 らかの理由でPublicとPrivateの データ分布に乖離があるパターン • コンペ設計上、両者の乖離を事前
に把握でき、かつ、バリデーションの 工夫によって、CVをPrivateに十分 近付けることが可能な場合 • PublicとPrivateで中心にズレが生 じるため、Public LBの過信は禁物 • ただし、CVがちゃんとPrivateに近 いかどうかは己を信じるしかなく、難 易度も高い Public LB ≒ CV
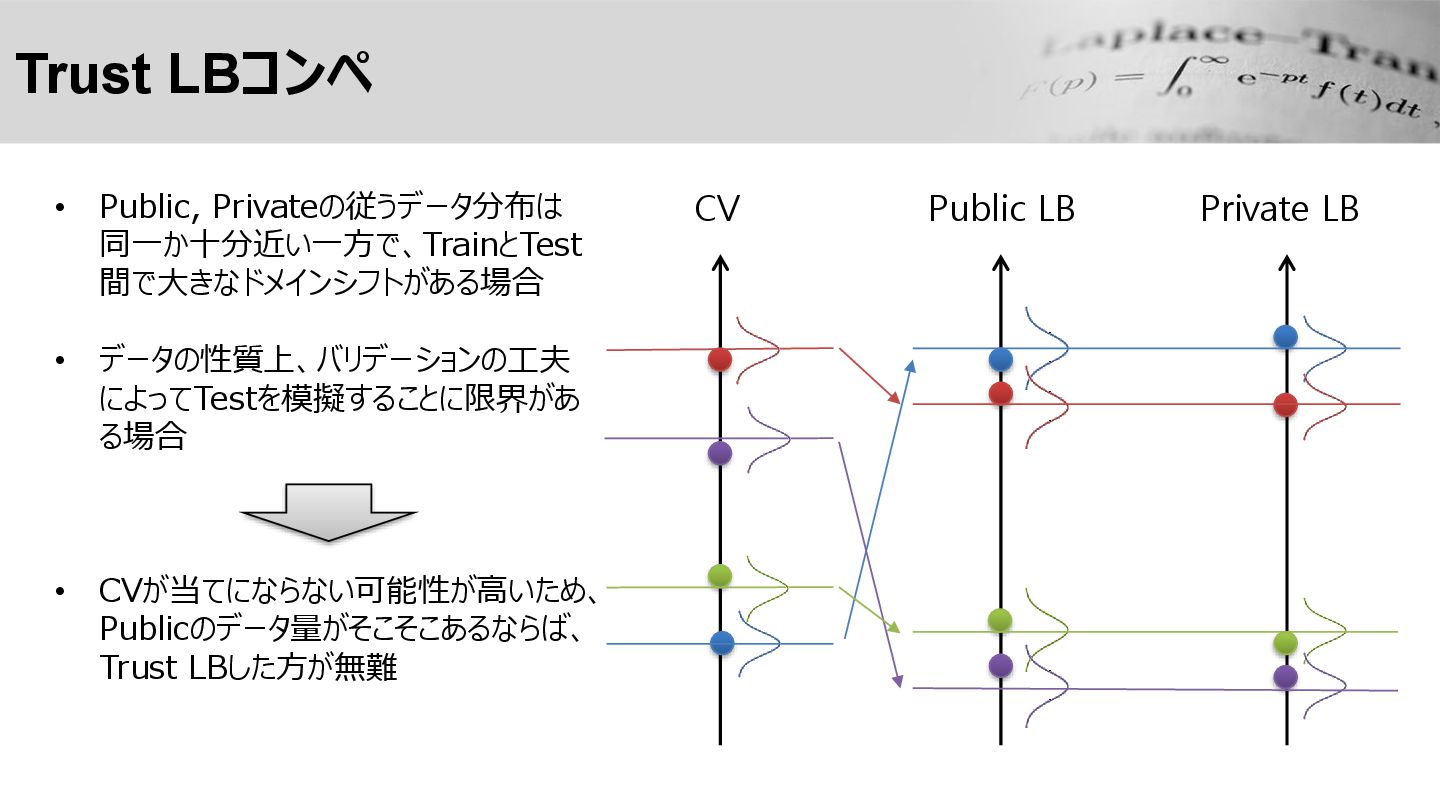
Trust LBコンペ Public LB CV Private LB • Public, Privateの従うデータ分布は
同一か十分近い一方で、TrainとTest 間で大きなドメインシフトがある場合 • データの性質上、バリデーションの工夫 によってTestを模擬することに限界があ る場合 • CVが当てにならない可能性が高いため、 Publicのデータ量がそこそこあるならば、 Trust LBした方が無難
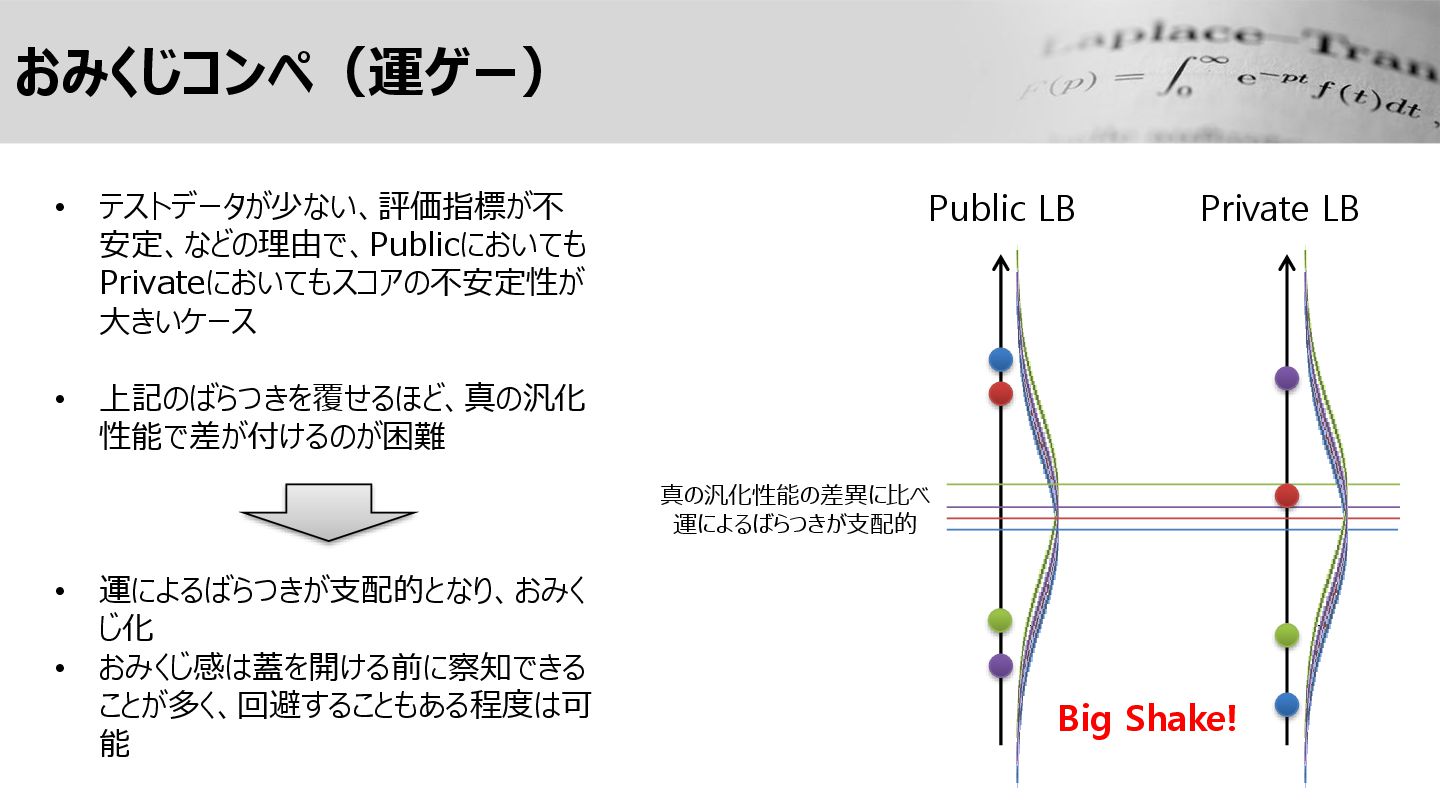
おみくじコンペ(運ゲー) Public LB Private LB • テストデータが少ない、評価指標が不 安定、などの理由で、Publicにおいても Privateにおいてもスコアの不安定性が 大きいケース
• 上記のばらつきを覆せるほど、真の汎化 性能で差が付けるのが困難 • 運によるばらつきが支配的となり、おみく じ化 • おみくじ感は蓋を開ける前に察知できる ことが多く、回避することもある程度は可 能 Big Shake! 真の汎化性能の差異に比べ 運によるばらつきが支配的
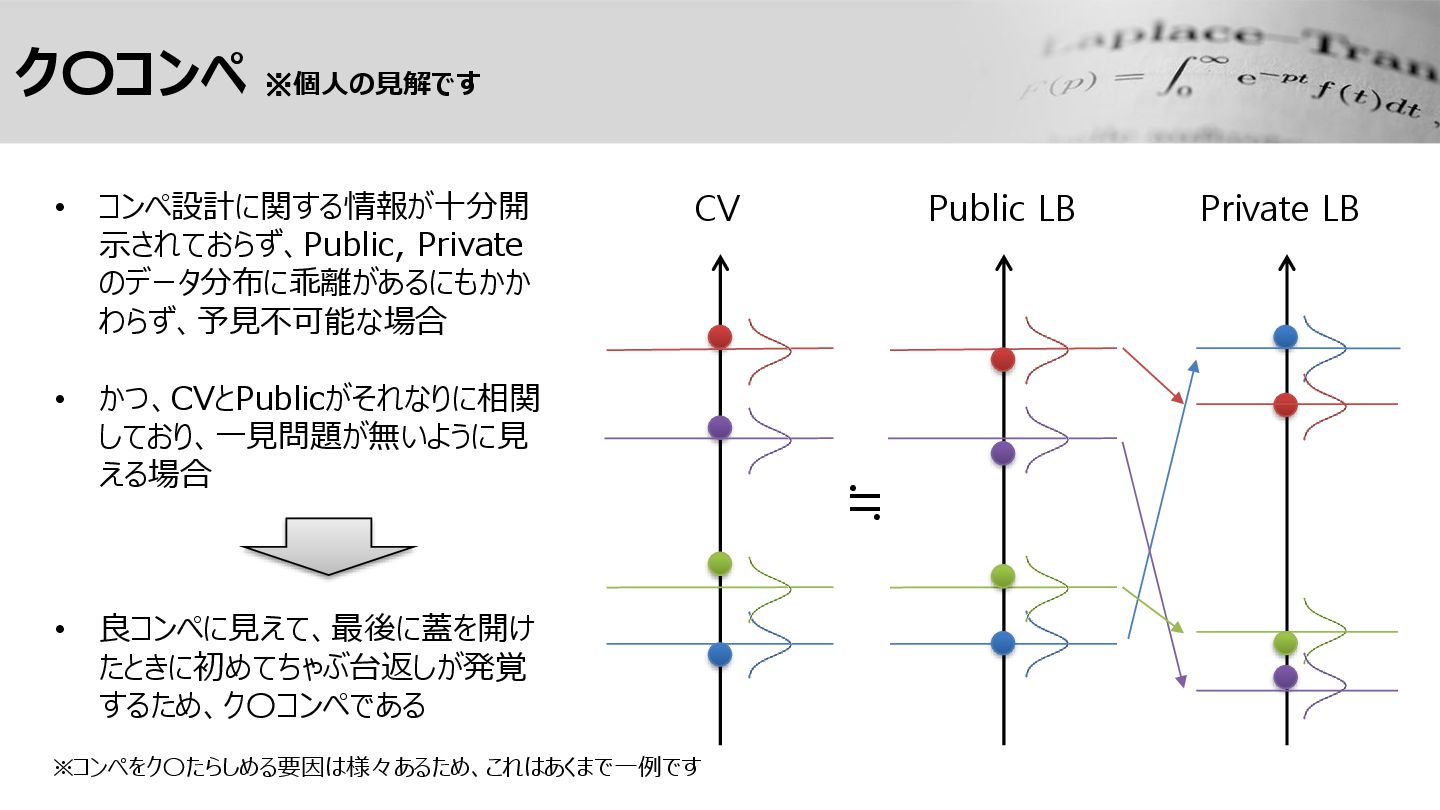
ク〇コンペ ※個人の見解です CV Private LB • コンペ設計に関する情報が十分開 示されておらず、Public, Private のデータ分布に乖離があるにもかか
わらず、予見不可能な場合 • かつ、CVとPublicがそれなりに相関 しており、一見問題が無いように見 える場合 • 良コンペに見えて、最後に蓋を開け たときに初めてちゃぶ台返しが発覚 するため、ク〇コンペである Public LB ≒ ※コンペをク〇たらしめる要因は様々あるため、これはあくまで一例です
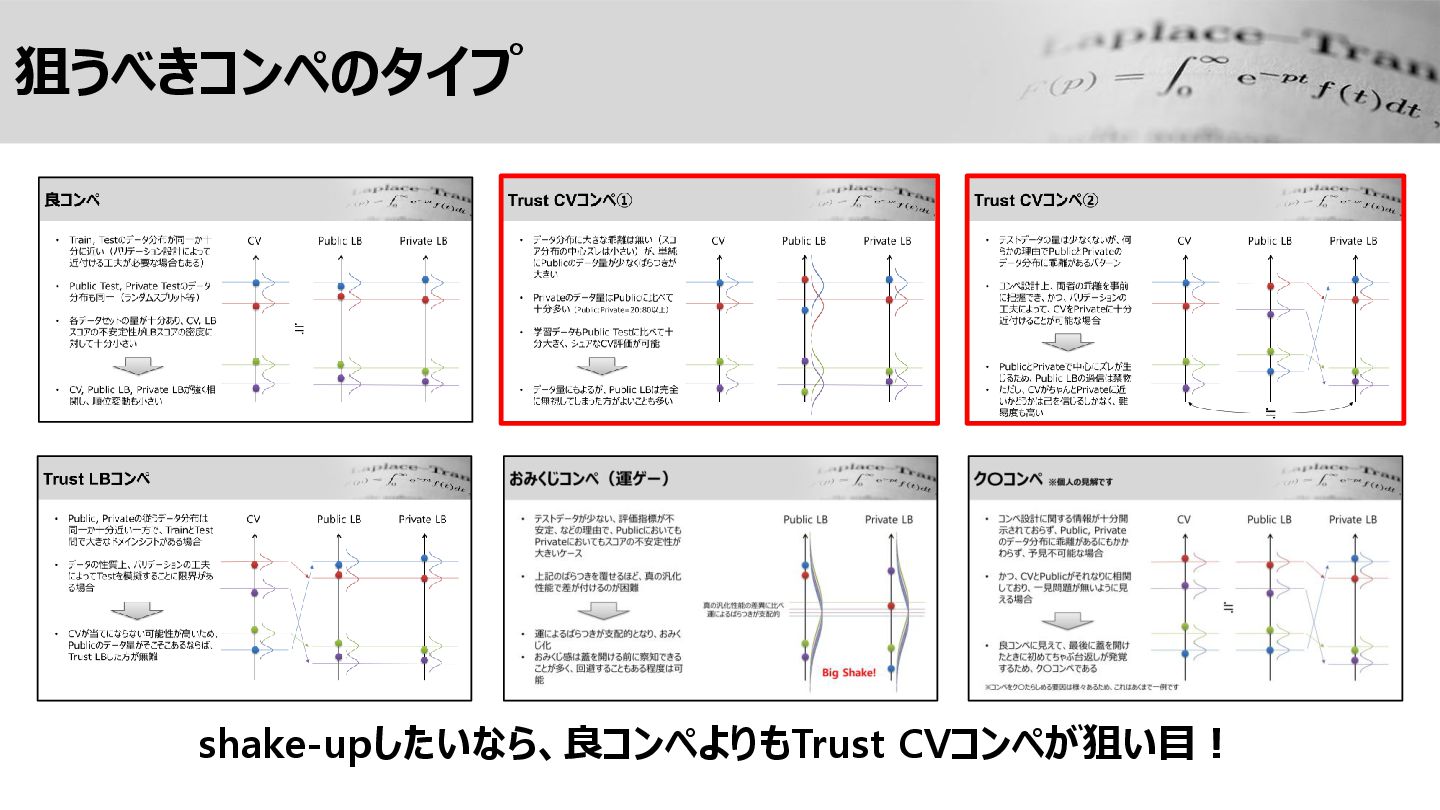
狙うべきコンペのタイプ shake-upしたいなら、良コンペよりもTrust CVコンペが狙い目!
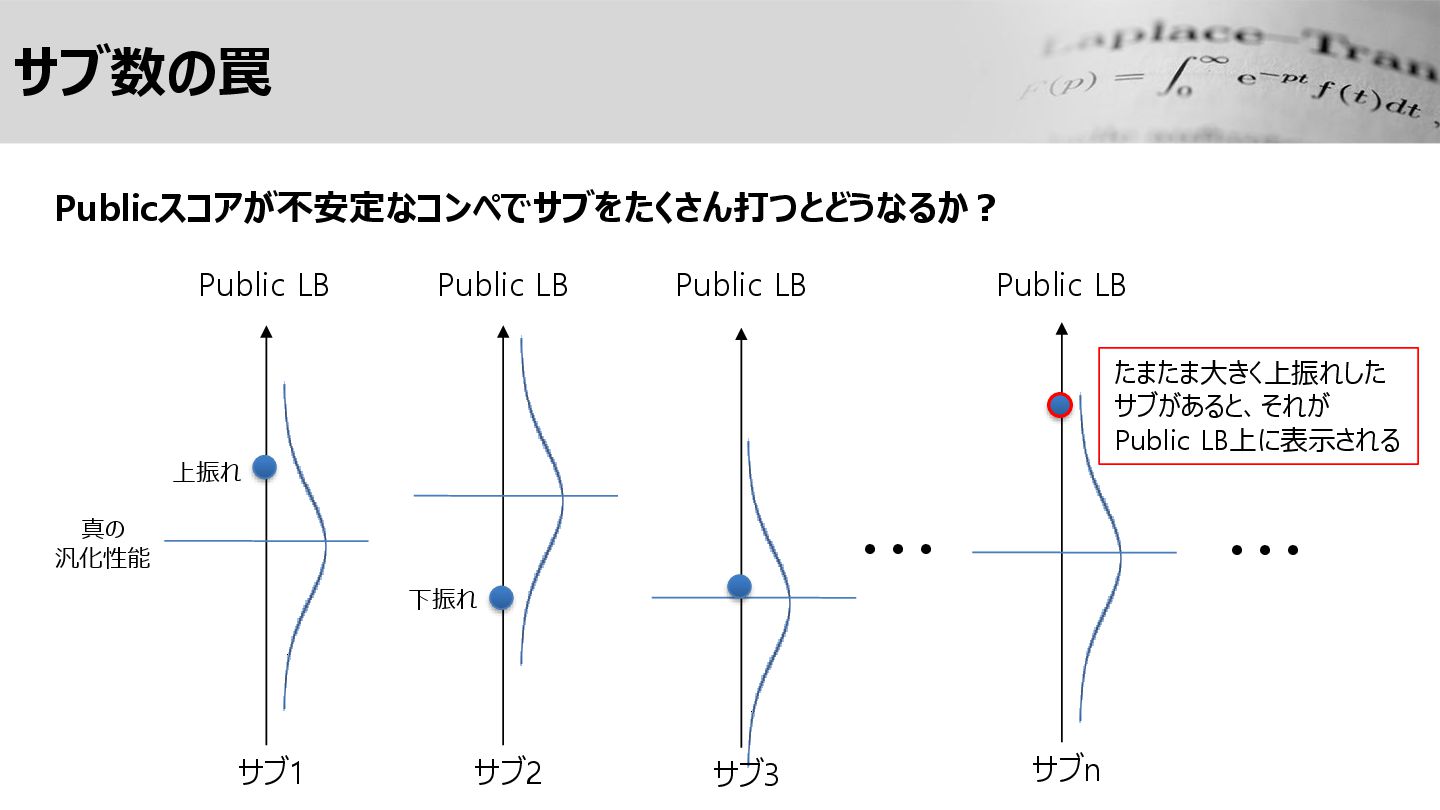
サブ数の罠 Publicスコアが不安定なコンペでサブをたくさん打つとどうなるか? Public LB 真の 汎化性能 上振れ サブ1 Public LB
サブ2 Public LB サブ3 Public LB サブn ・・・ ・・・ 下振れ たまたま大きく上振れした サブがあると、それが Public LB上に表示される
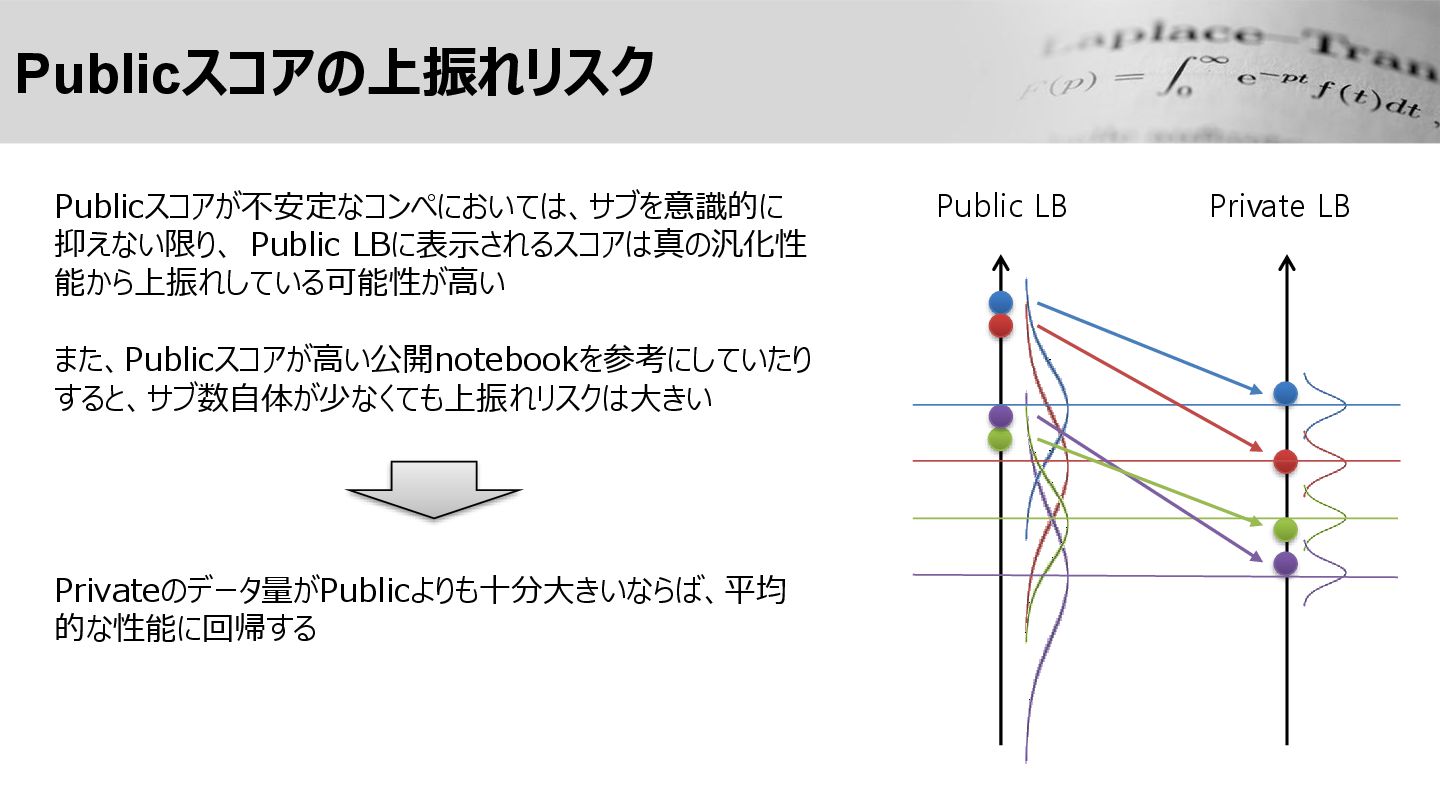
Public LB Publicスコアの上振れリスク Private LB Publicスコアが不安定なコンペにおいては、サブを意識的に 抑えない限り、 Public LBに表示されるスコアは真の汎化性 能から上振れしている可能性が高い
また、Publicスコアが高い公開notebookを参考にしていたり すると、サブ数自体が少なくても上振れリスクは大きい Privateのデータ量がPublicよりも十分大きいならば、平均 的な性能に回帰する
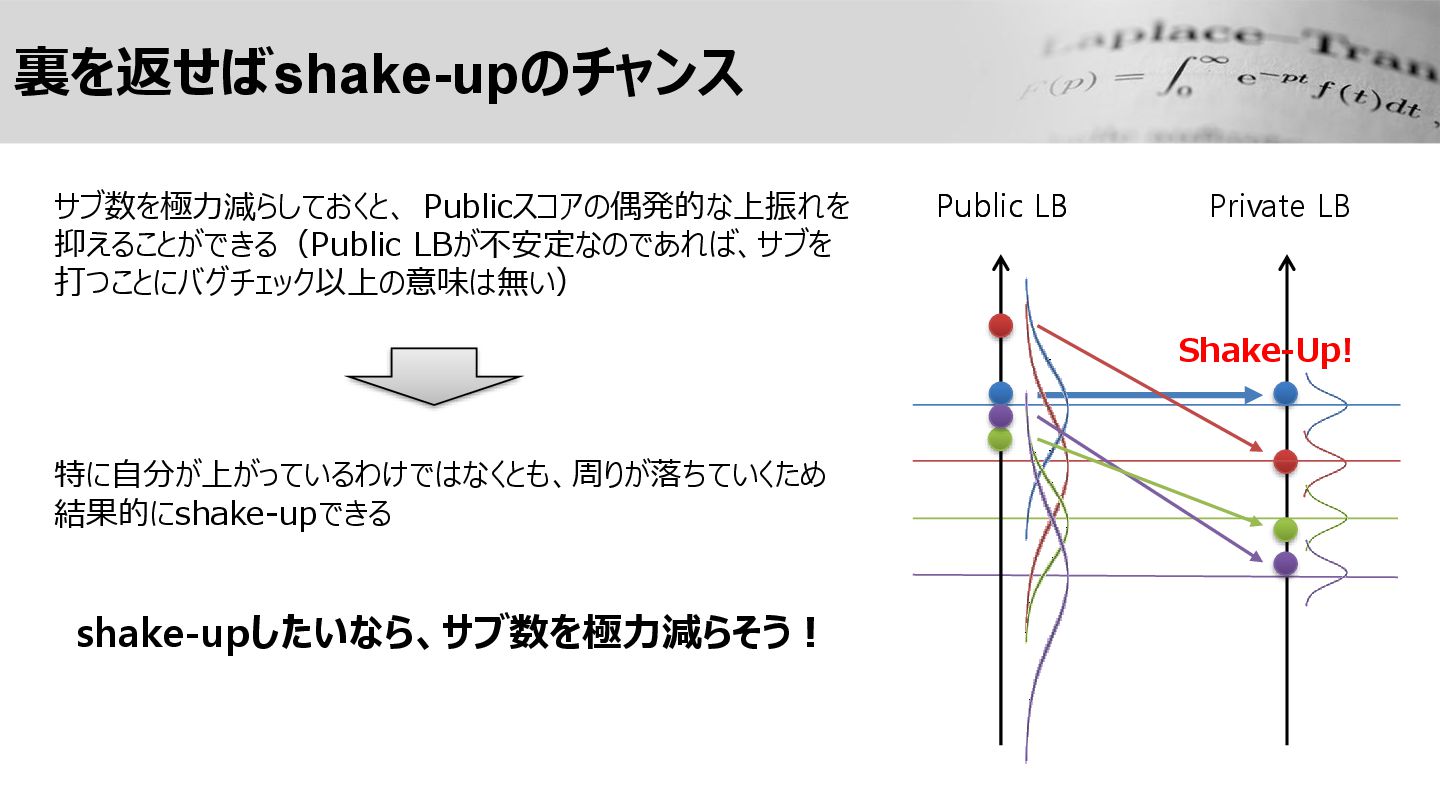
裏を返せばshake-upのチャンス Public LB Private LB サブ数を極力減らしておくと、 Publicスコアの偶発的な上振れを 抑えることができる(Public LBが不安定なのであれば、サブを 打つことにバグチェック以上の意味は無い)
特に自分が上がっているわけではなくとも、周りが落ちていくため 結果的にshake-upできる shake-upしたいなら、サブ数を極力減らそう! Shake-Up! Public LB
LBスコアの不安定性を把握する 先ほどは単純化してコンペを分類してみたものの、結局これらは程度問題であり、複合的な場 合もあるため、実際はそう単純ではない いずれにしても、Public, PrivateのLBスコアの不安定性を把握することは、参加するコンペを見 極める上でも、コンペを戦う中で今の自分の立ち位置を見誤らないためにも重要 LBスコアの不安定性を把握するための指針として、 評価データ量とスコアのばらつきがどのように関連するのかを実験
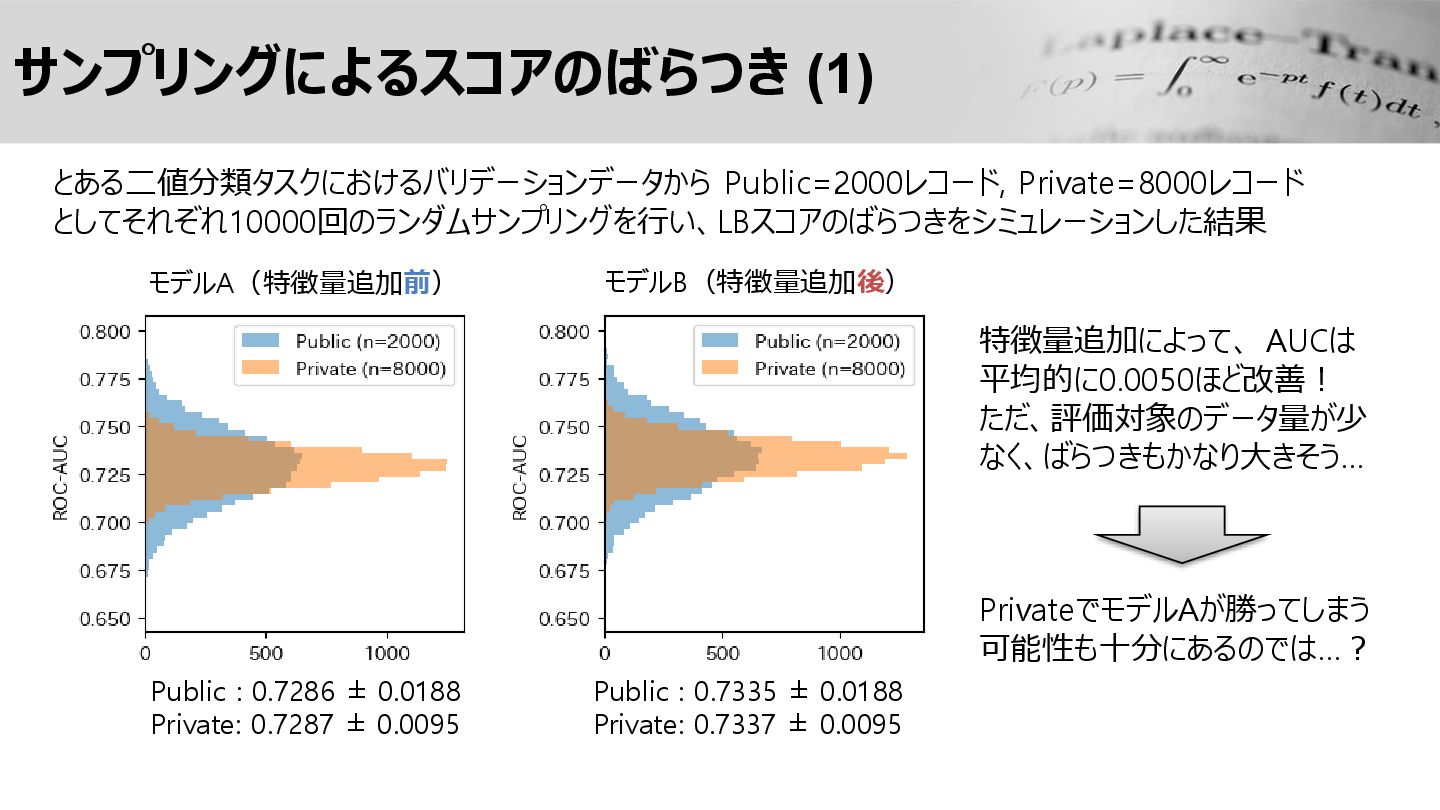
サンプリングによるスコアのばらつき (1) Public : 0.7286 ± 0.0188 Private: 0.7287 ±
0.0095 Public : 0.7335 ± 0.0188 Private: 0.7337 ± 0.0095 モデルA(特徴量追加前) モデルB(特徴量追加後) とある二値分類タスクにおけるバリデーションデータから Public=2000レコード, Private=8000レコード としてそれぞれ10000回のランダムサンプリングを行い、LBスコアのばらつきをシミュレーションした結果 特徴量追加によって、 AUCは 平均的に0.0050ほど改善! ただ、評価対象のデータ量が少 なく、ばらつきもかなり大きそう… PrivateでモデルAが勝ってしまう 可能性も十分にあるのでは…?
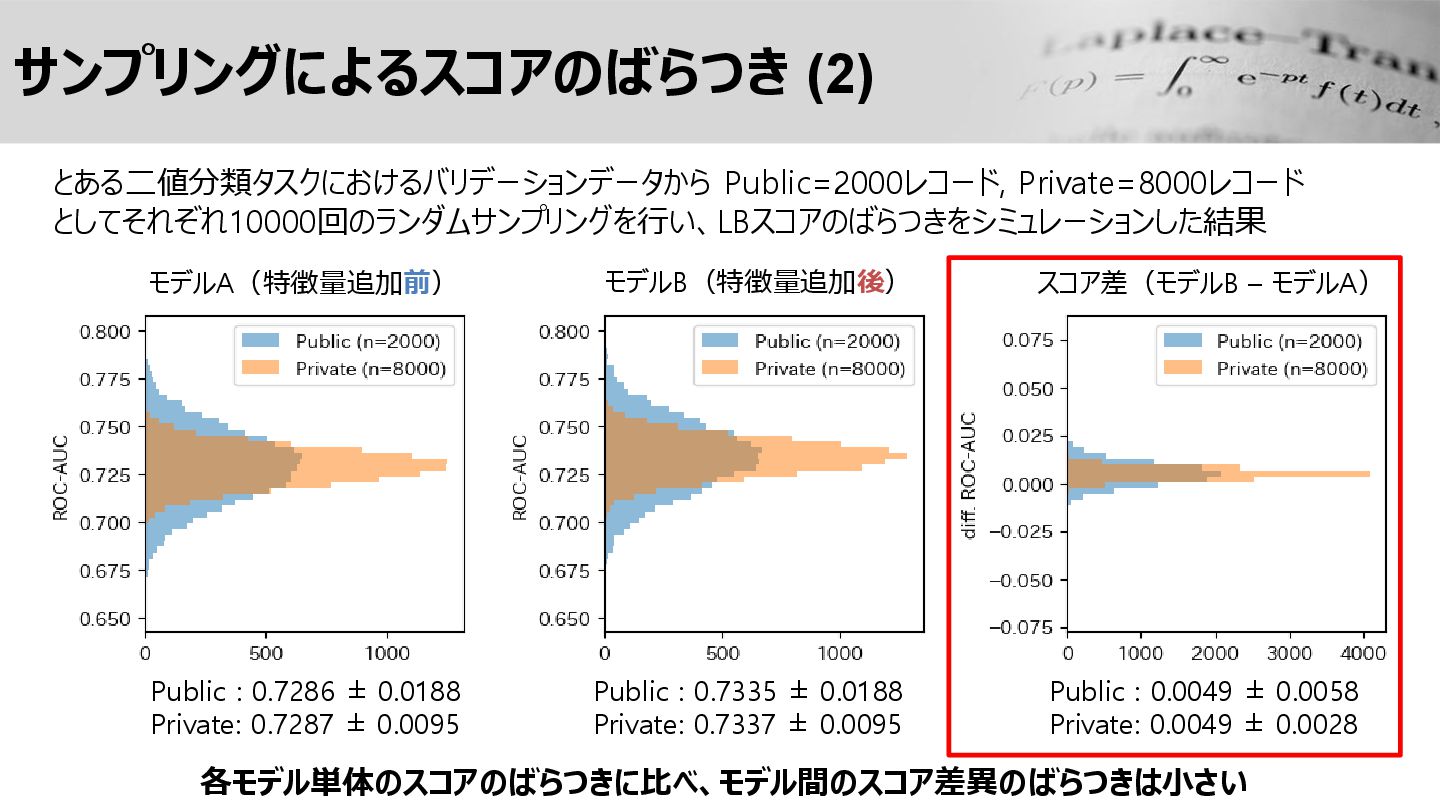
サンプリングによるスコアのばらつき (2) Public : 0.7286 ± 0.0188 Private: 0.7287 ±
0.0095 Public : 0.7335 ± 0.0188 Private: 0.7337 ± 0.0095 Public : 0.0049 ± 0.0058 Private: 0.0049 ± 0.0028 スコア差(モデルB – モデルA) とある二値分類タスクにおけるバリデーションデータから Public=2000レコード, Private=8000レコード としてそれぞれ10000回のランダムサンプリングを行い、LBスコアのばらつきをシミュレーションした結果 各モデル単体のスコアのばらつきに比べ、モデル間のスコア差異のばらつきは小さい モデルA(特徴量追加前) モデルB(特徴量追加後)
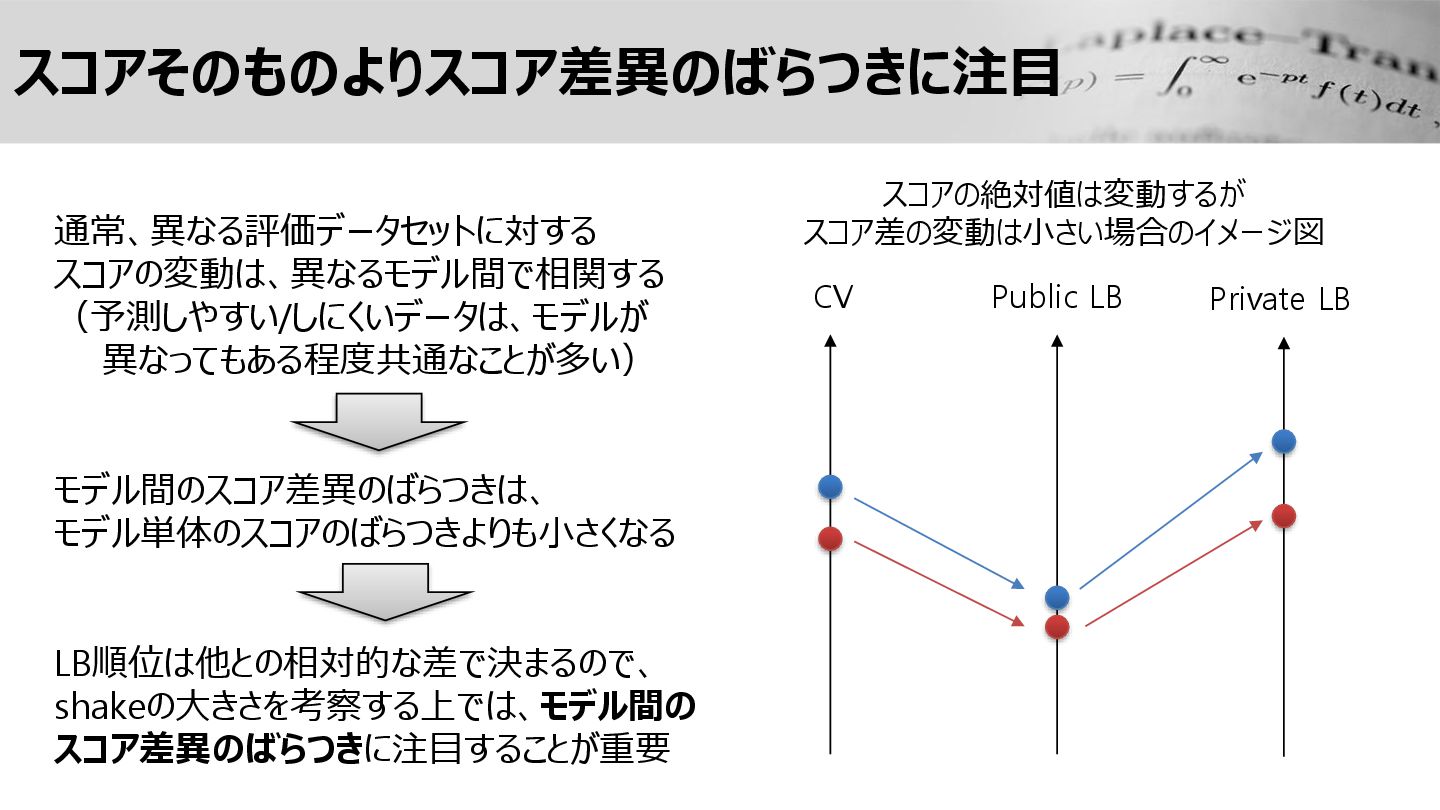
スコアそのものよりスコア差異のばらつきに注目 スコアの絶対値は変動するが スコア差の変動は小さい場合のイメージ図 CV Public LB Private LB 通常、異なる評価データセットに対する スコアの変動は、異なるモデル間で相関する
(予測しやすい/しにくいデータは、モデルが 異なってもある程度共通なことが多い) モデル間のスコア差異のばらつきは、 モデル単体のスコアのばらつきよりも小さくなる LB順位は他との相対的な差で決まるので、 shakeの大きさを考察する上では、モデル間の スコア差異のばらつきに注目することが重要
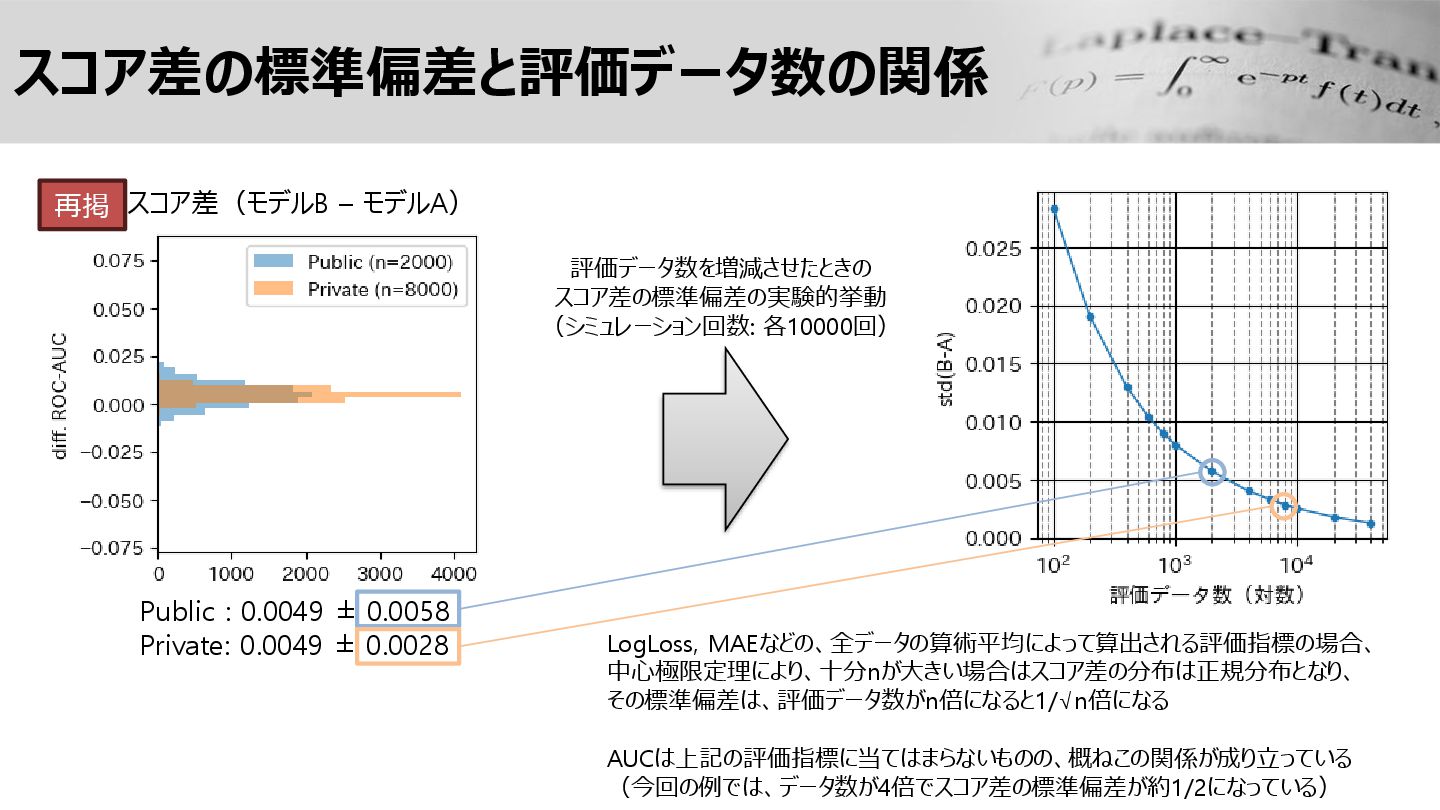
スコア差の標準偏差と評価データ数の関係 Public : 0.0049 ± 0.0058 Private: 0.0049 ± 0.0028
スコア差(モデルB – モデルA) 評価データ数を増減させたときの スコア差の標準偏差の実験的挙動 (シミュレーション回数: 各10000回) 再掲 LogLoss, MAEなどの、全データの算術平均によって算出される評価指標の場合、 中心極限定理により、十分nが大きい場合はスコア差の分布は正規分布となり、 その標準偏差は、評価データ数がn倍になると1/√n倍になる AUCは上記の評価指標に当てはまらないものの、概ねこの関係が成り立っている (今回の例では、データ数が4倍でスコア差の標準偏差が約1/2になっている)
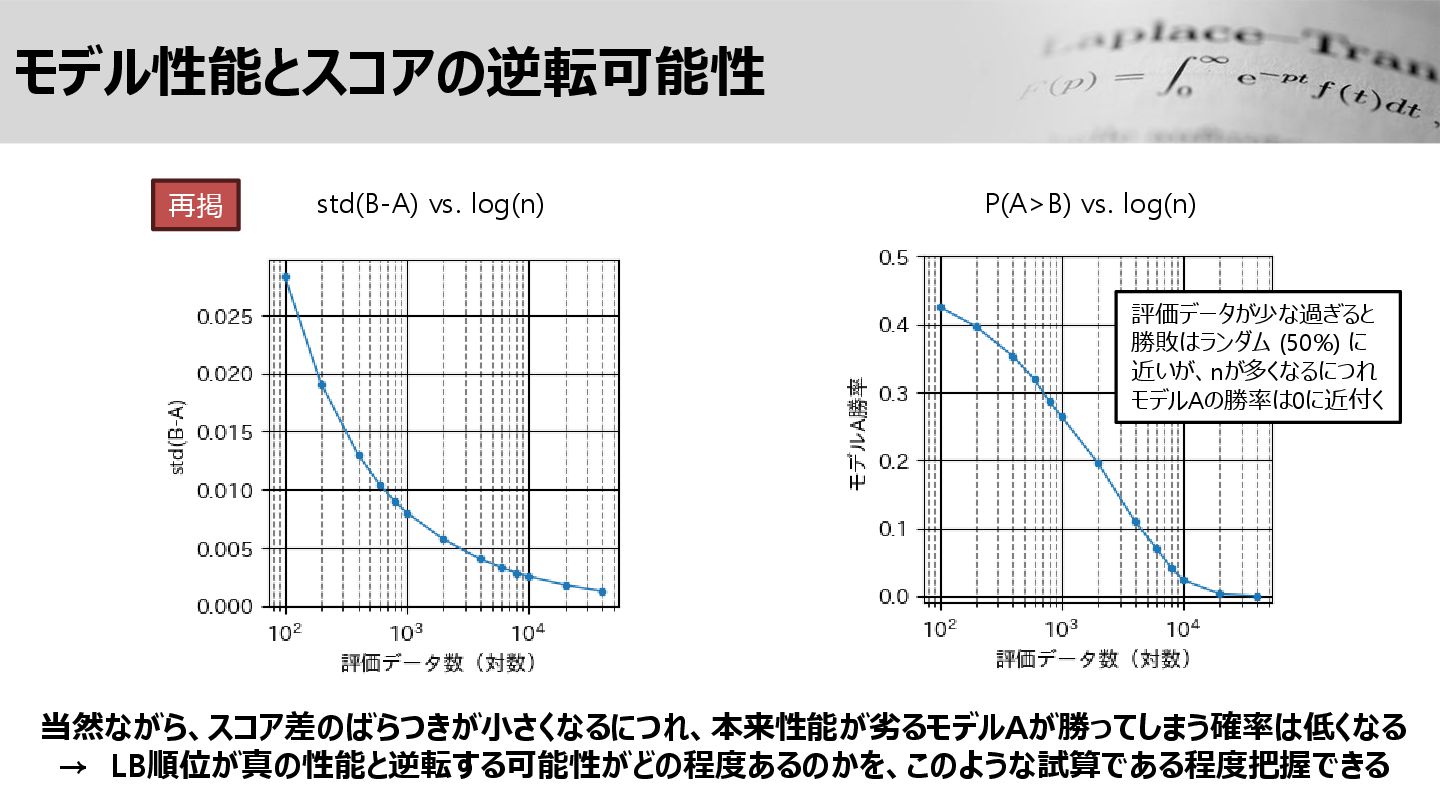
モデル性能とスコアの逆転可能性 std(B-A) vs. log(n) P(A>B) vs. log(n) 再掲 当然ながら、スコア差のばらつきが小さくなるにつれ、本来性能が劣るモデルAが勝ってしまう確率は低くなる →
LB順位が真の性能と逆転する可能性がどの程度あるのかを、このような試算である程度把握できる 評価データが少な過ぎると 勝敗はランダム (50%) に 近いが、nが多くなるにつれ モデルAの勝率は0に近付く
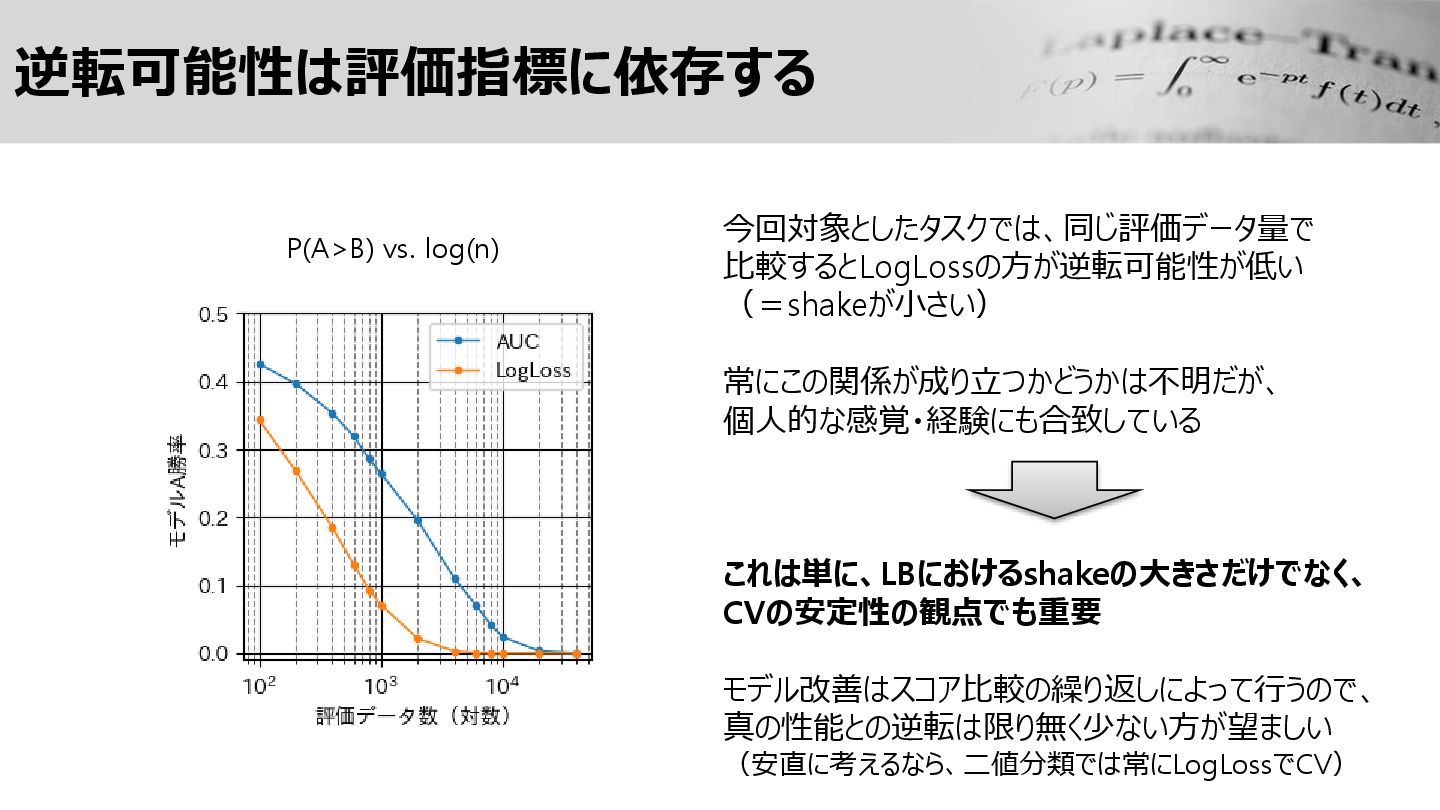
逆転可能性は評価指標に依存する P(A>B) vs. log(n) 今回対象としたタスクでは、同じ評価データ量で 比較するとLogLossの方が逆転可能性が低い (=shakeが小さい) 常にこの関係が成り立つかどうかは不明だが、 個人的な感覚・経験にも合致している これは単に、LBにおけるshakeの大きさだけでなく、
CVの安定性の観点でも重要 モデル改善はスコア比較の繰り返しによって行うので、 真の性能との逆転は限り無く少ない方が望ましい (安直に考えるなら、二値分類では常にLogLossでCV)
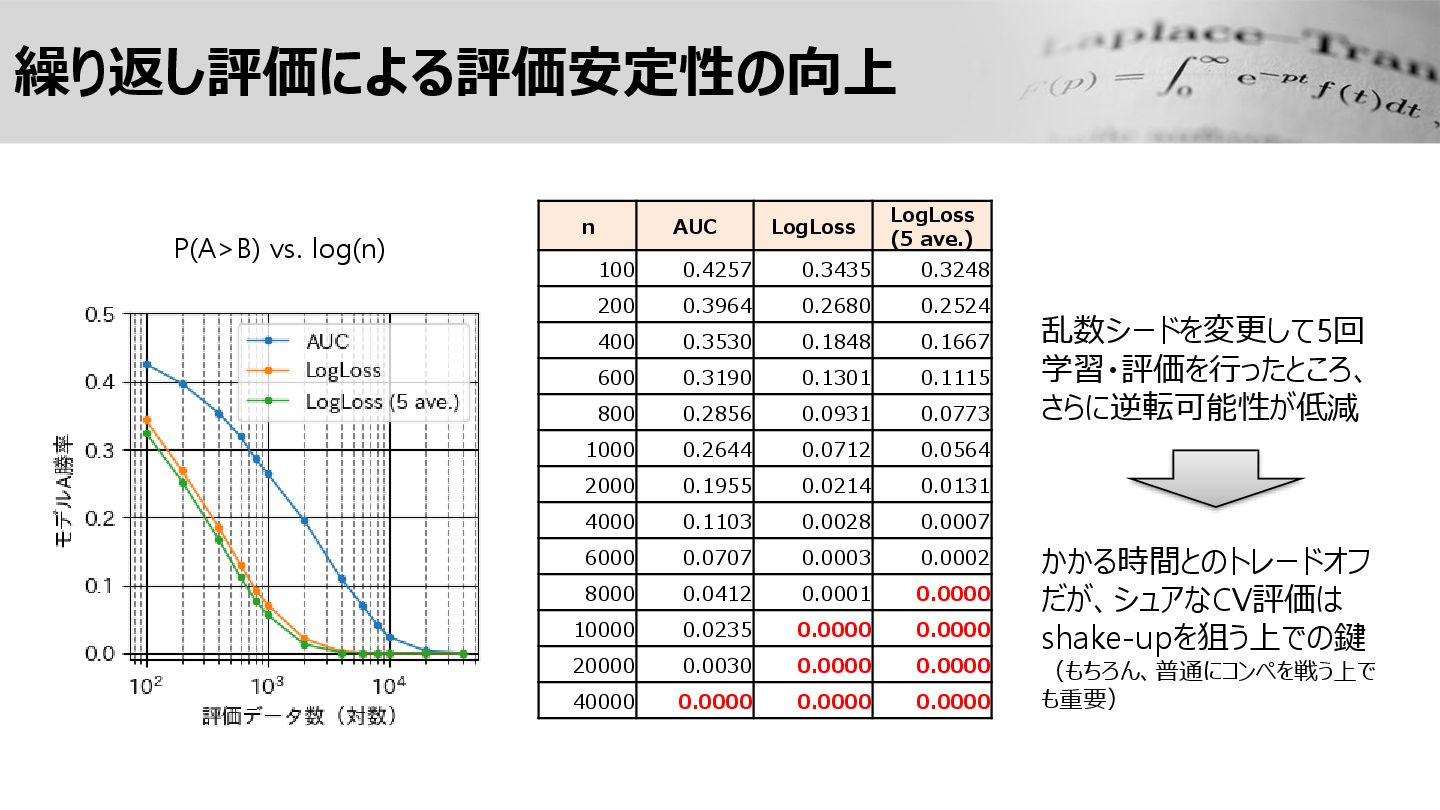
繰り返し評価による評価安定性の向上 P(A>B) vs. log(n) n AUC LogLoss LogLoss (5 ave.)
100 0.4257 0.3435 0.3248 200 0.3964 0.2680 0.2524 400 0.3530 0.1848 0.1667 600 0.3190 0.1301 0.1115 800 0.2856 0.0931 0.0773 1000 0.2644 0.0712 0.0564 2000 0.1955 0.0214 0.0131 4000 0.1103 0.0028 0.0007 6000 0.0707 0.0003 0.0002 8000 0.0412 0.0001 0.0000 10000 0.0235 0.0000 0.0000 20000 0.0030 0.0000 0.0000 40000 0.0000 0.0000 0.0000 乱数シードを変更して5回 学習・評価を行ったところ、 さらに逆転可能性が低減 かかる時間とのトレードオフ だが、シュアなCV評価は shake-upを狙う上での鍵 (もちろん、普通にコンペを戦う上で も重要)
結論 shake-upを狙うなら・・・ 1. LBスコアの不安定性を把握する! • Public LBが不安定なコンペこそ、shake-upの狙い目! • shake-upを狙わずとも、不安定性を把握しておけばLBに振り回されずに済む 2.
サブ数は極力少なく! • 非本質的なPublicスコアの上振れを回避し、周りが落ちていくのを眺めるべし! 3. Trustするに足るCVを! • 道を踏み外さないために、CVスコアの不安定性もしっかり把握しておくべし! • あえてコンペと異なる評価指標でCVするのも戦略の一つかも? • 時間が許すならば、繰り返し評価で少しでもCVの信頼性を上げよう ※今回は触れていないが、Privateを確実に模倣するCVの構築は絶対条件
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}