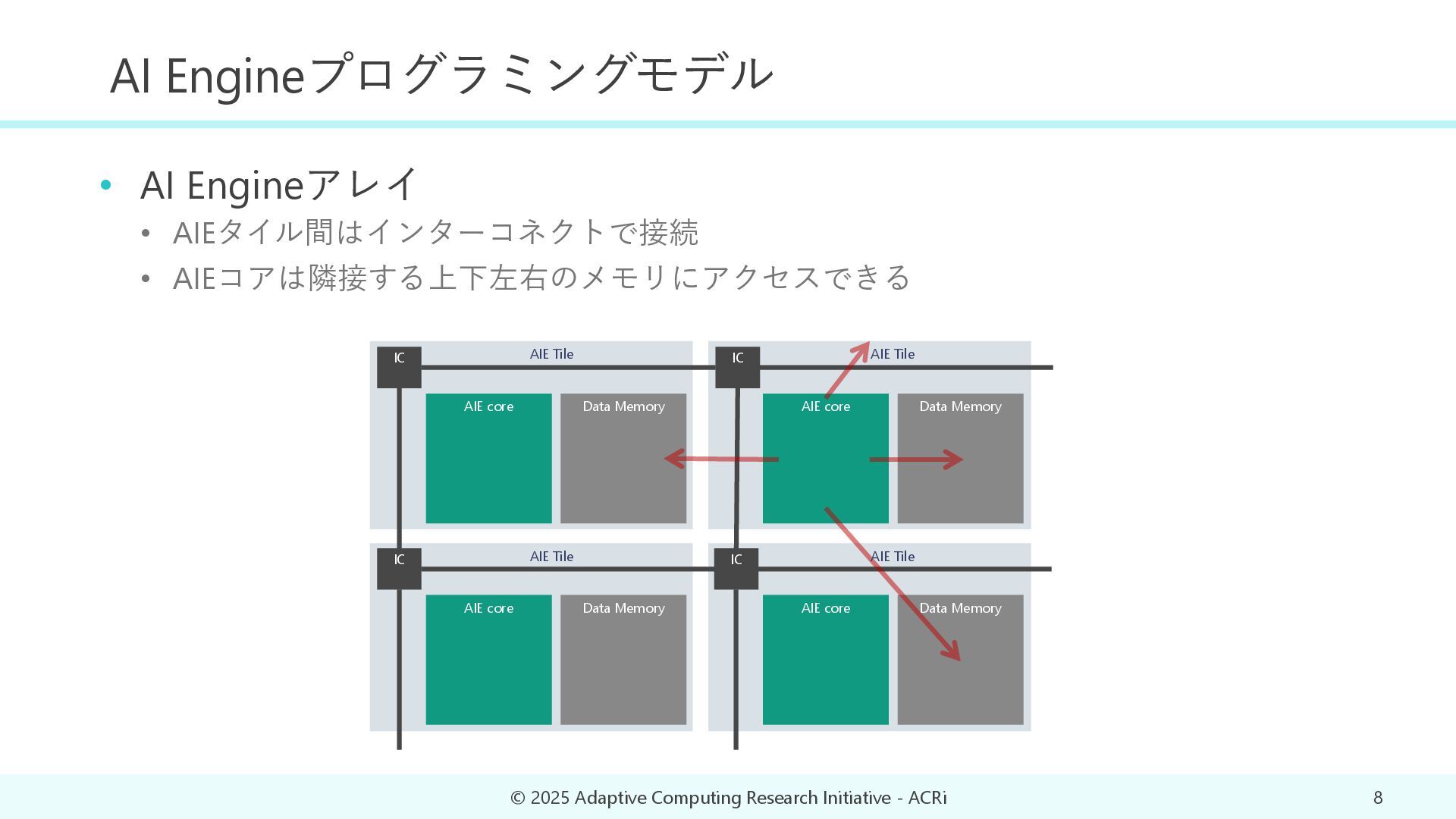
2025 Adaptive Computing Research Initiative - ACRi 8 AIE core Data Memory AIE core Data Memory AIE core Data Memory AIE core Data Memory IC IC IC IC AIE Tile AIE Tile AIE Tile AIE Tile
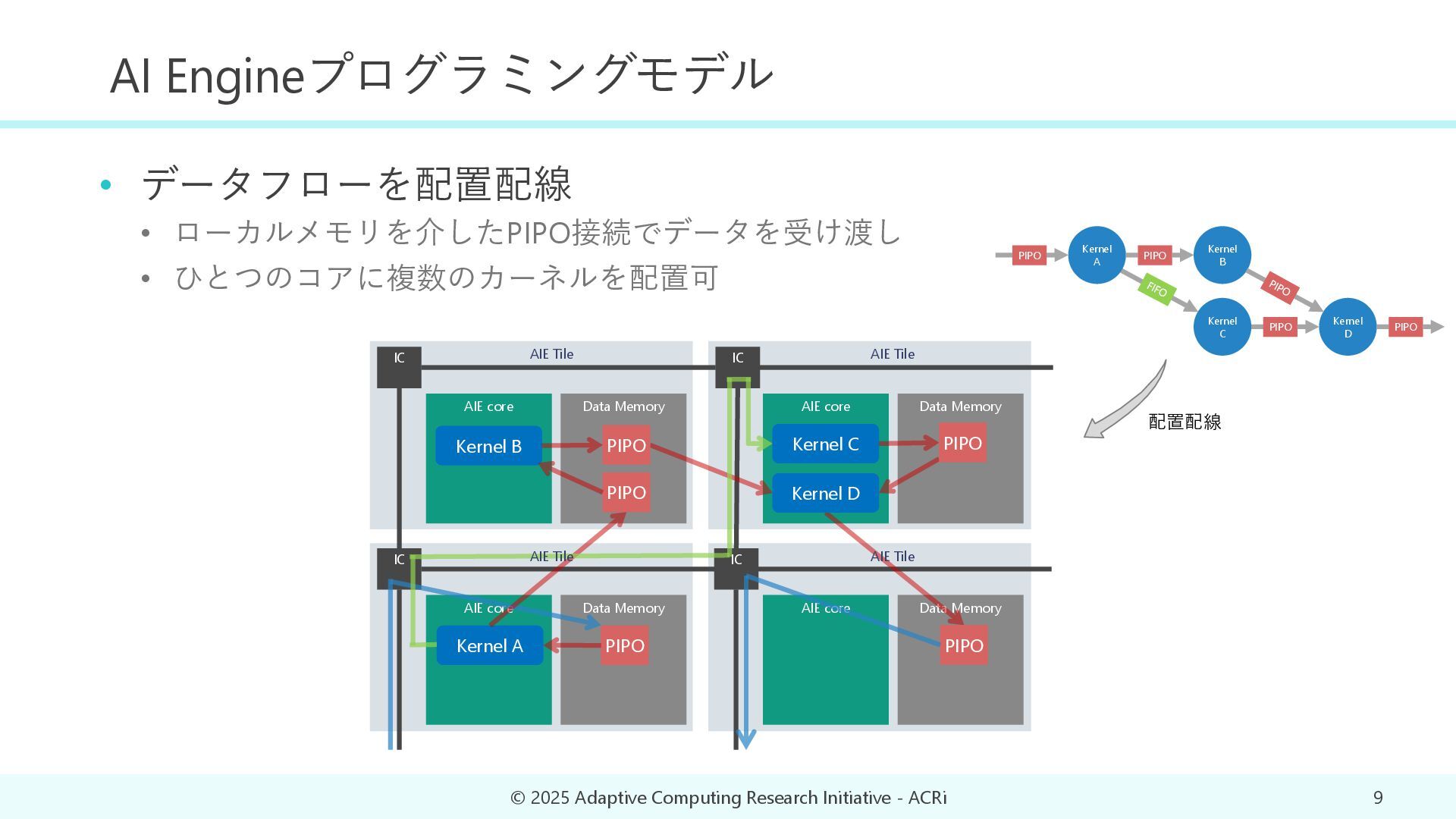
Adaptive Computing Research Initiative - ACRi 9 配置配線 Kernel B Kernel C Kernel D PIPO PIPO Kernel A PIPO PIPO AIE core Data Memory AIE core Data Memory Kernel A AIE core Data Memory AIE core Data Memory IC IC IC IC PIPO AIE Tile AIE Tile AIE Tile AIE Tile Kernel B Kernel C Kernel D PIPO PIPO PIPO PIPO
{kind=link}
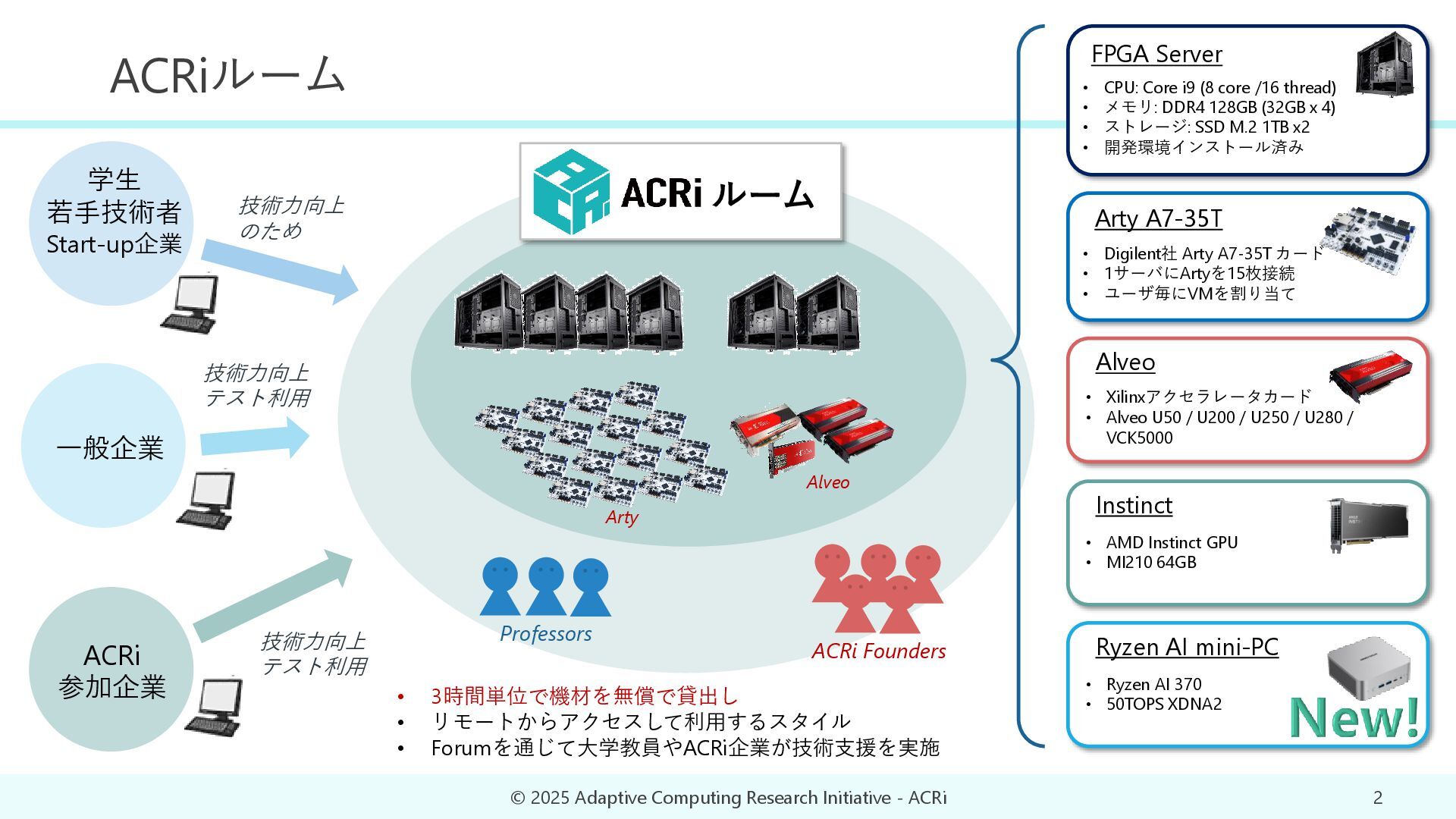{kind=link}
{kind=link}
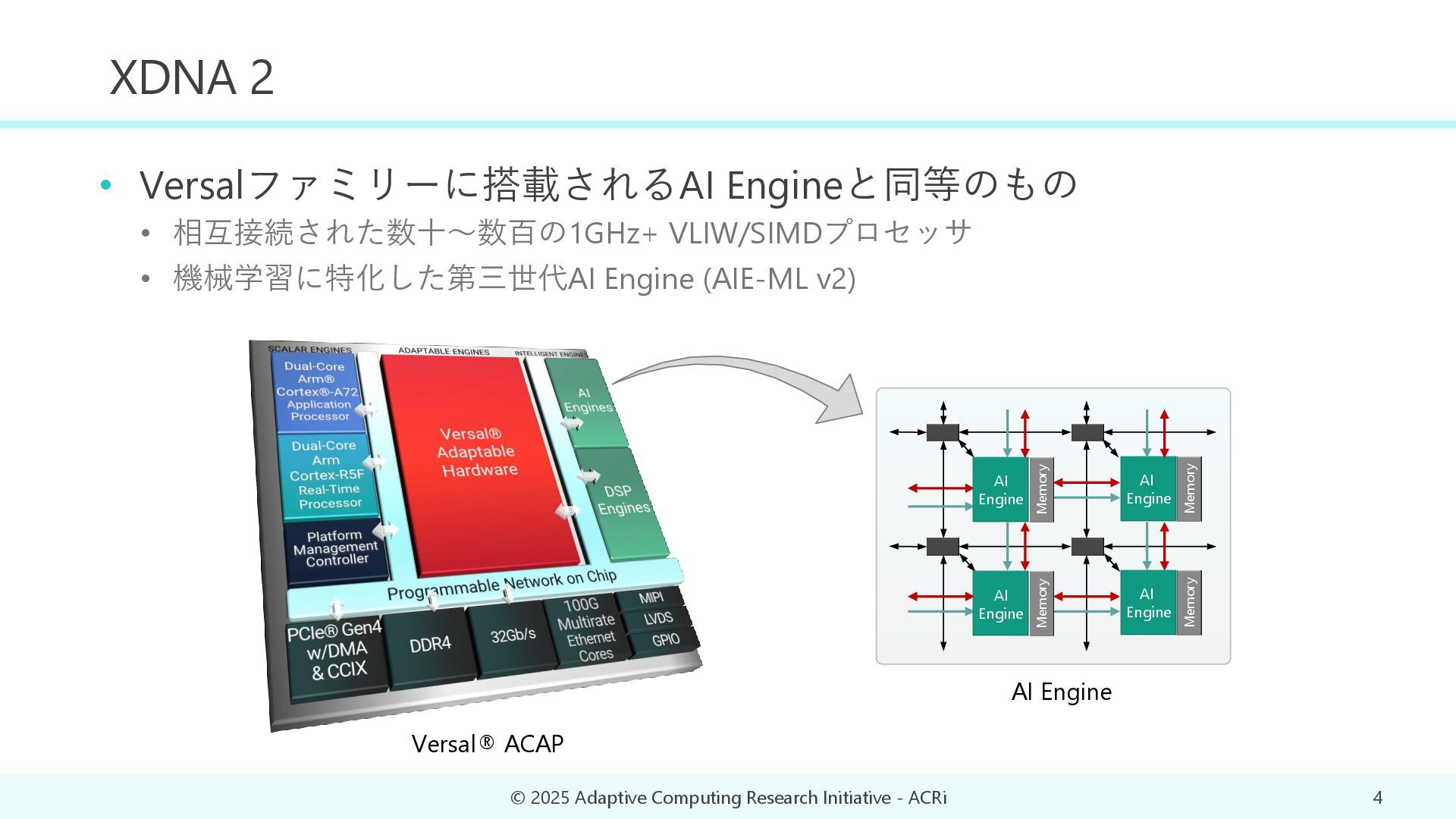{kind=link}
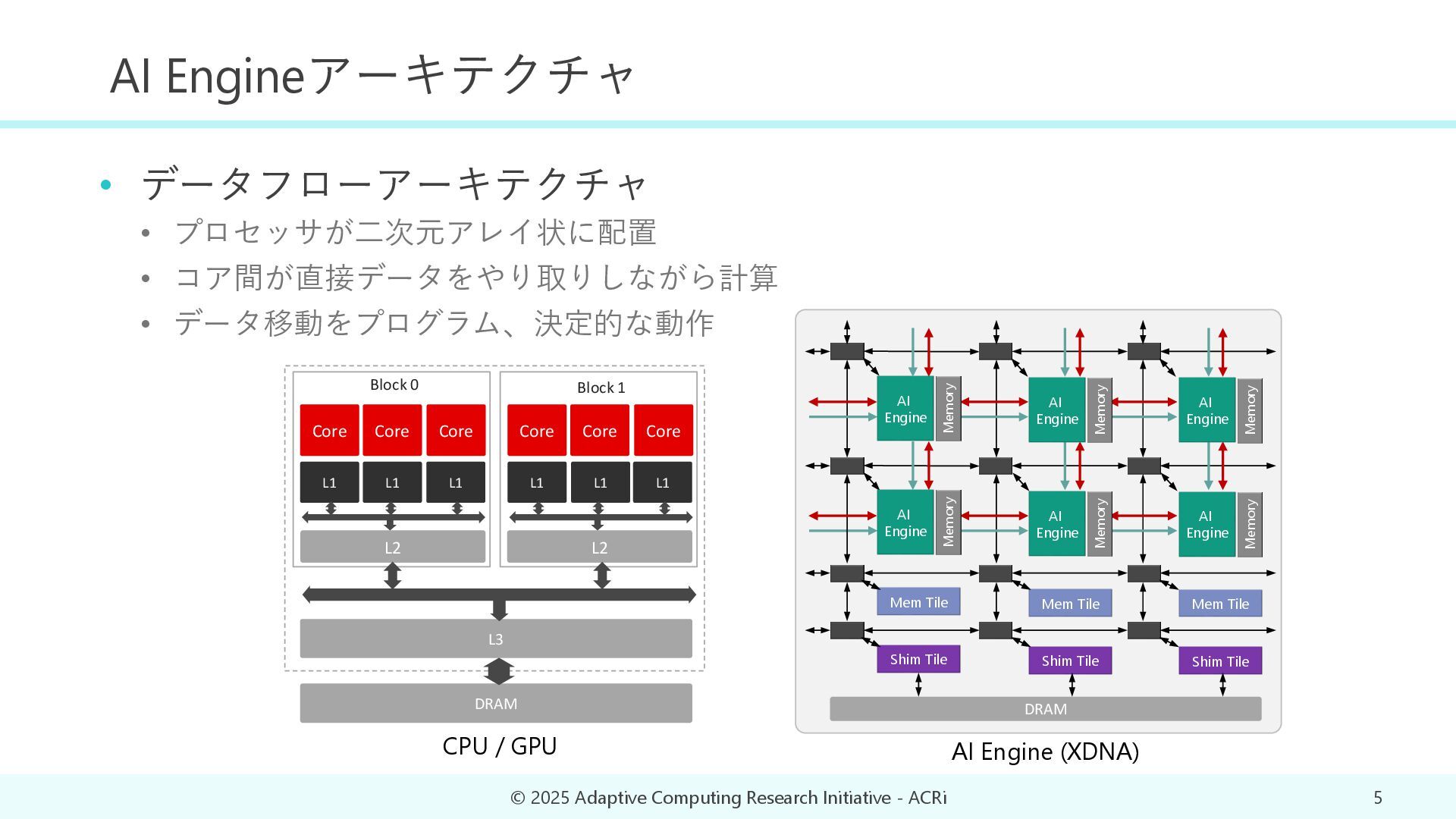{kind=link}
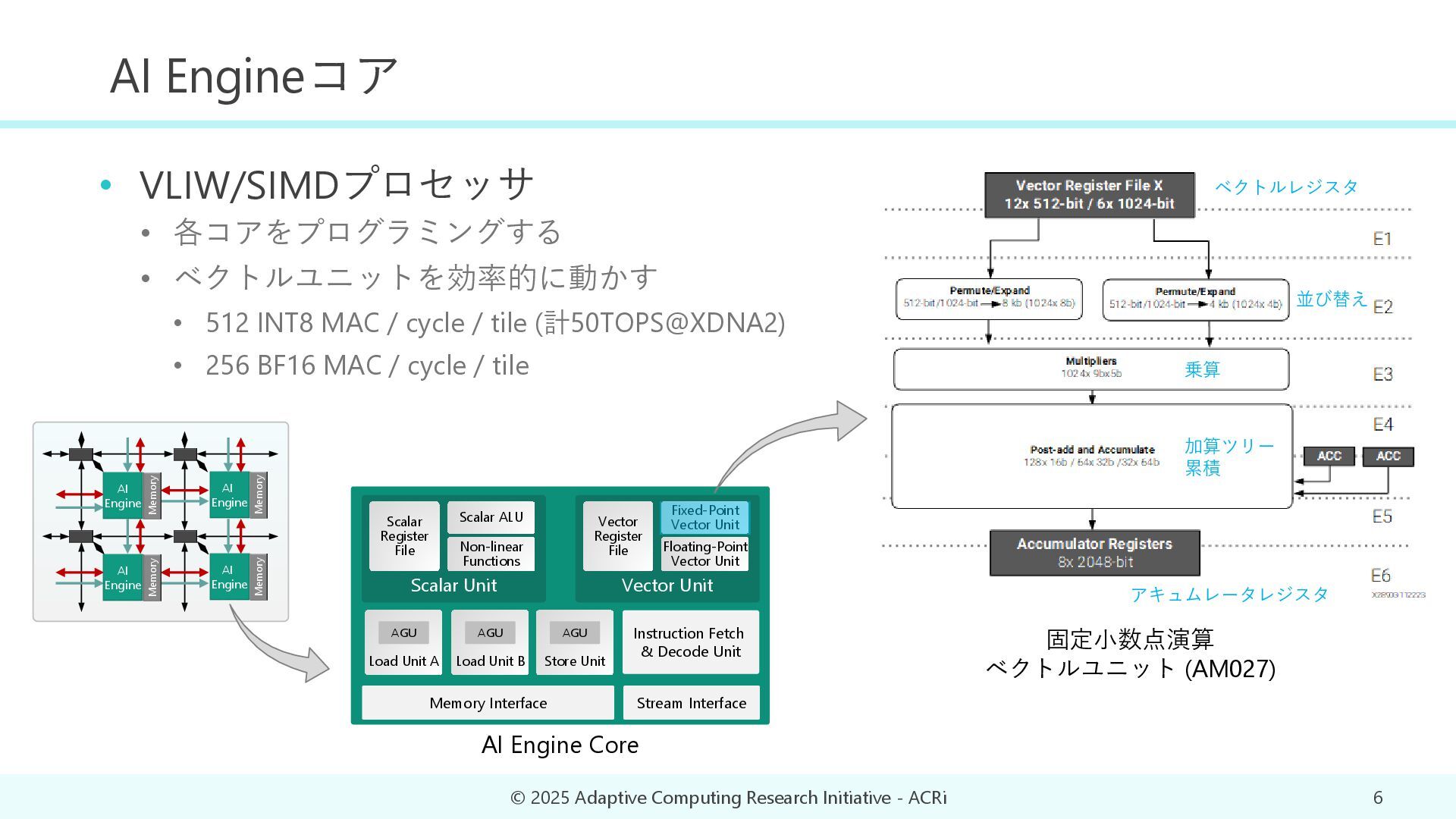{kind=link}
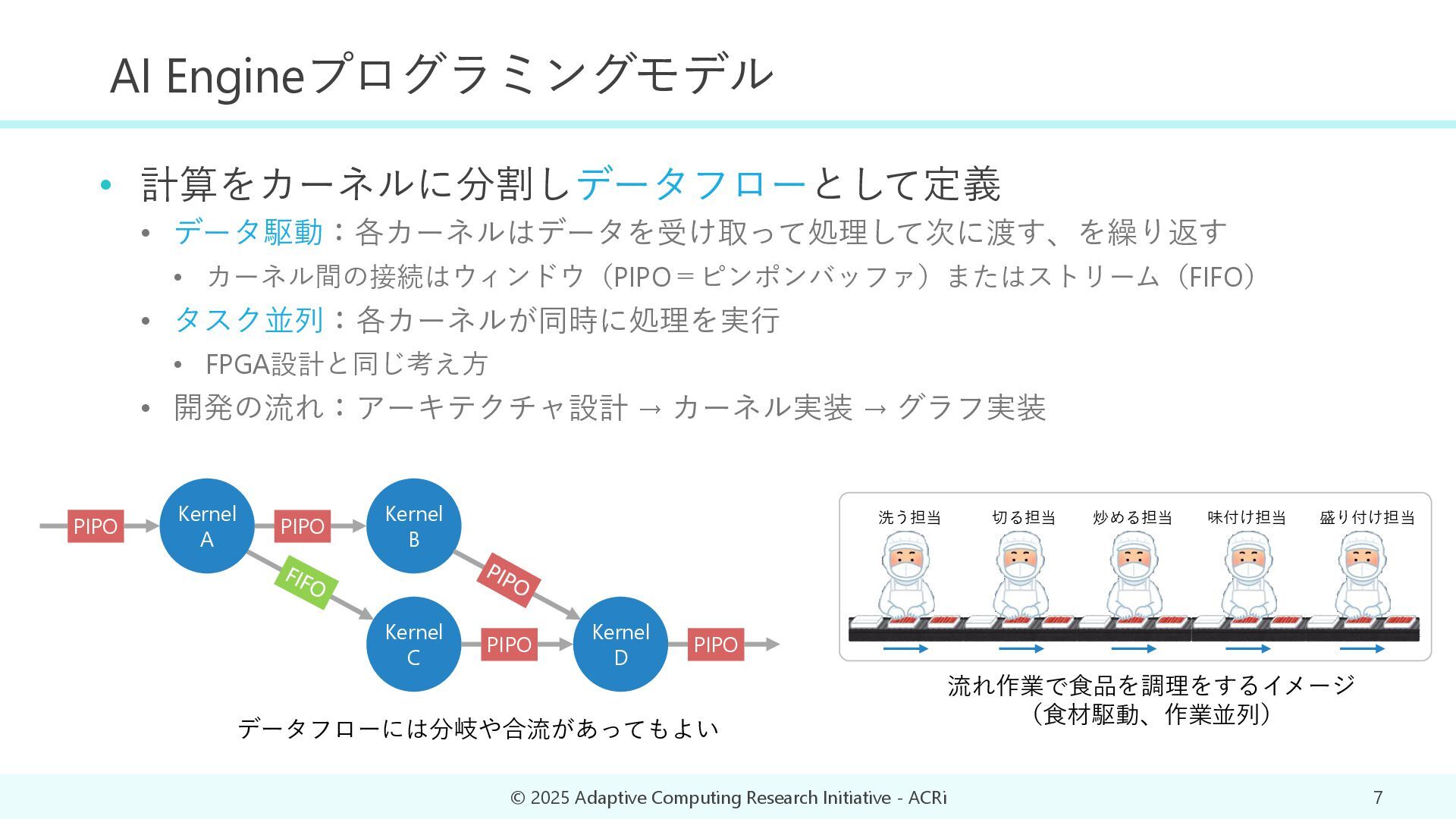{kind=link}
{kind=link}
{kind=link}
{kind=link}
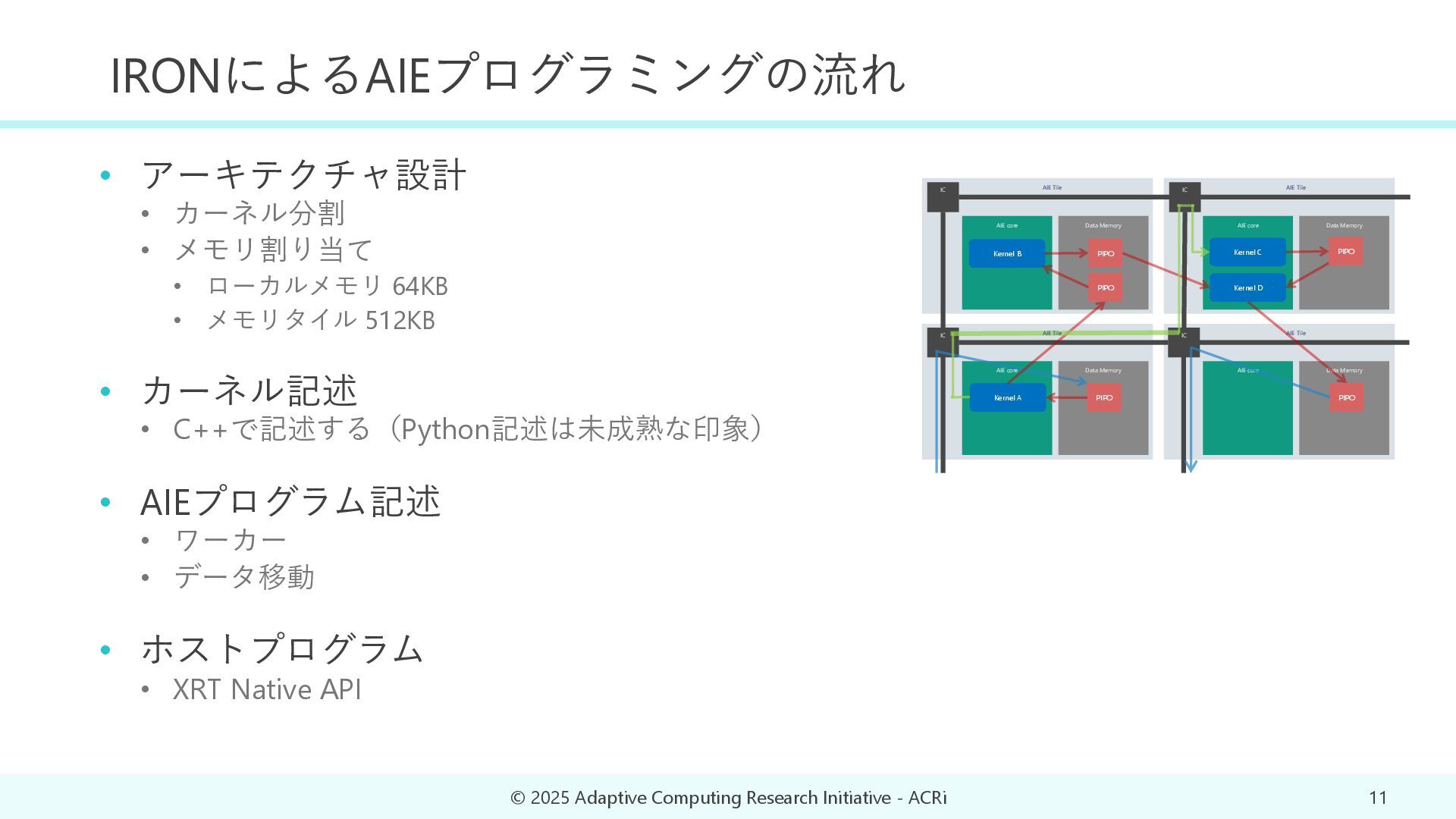{kind=link}
{kind=link}
{kind=link}
{kind=link}
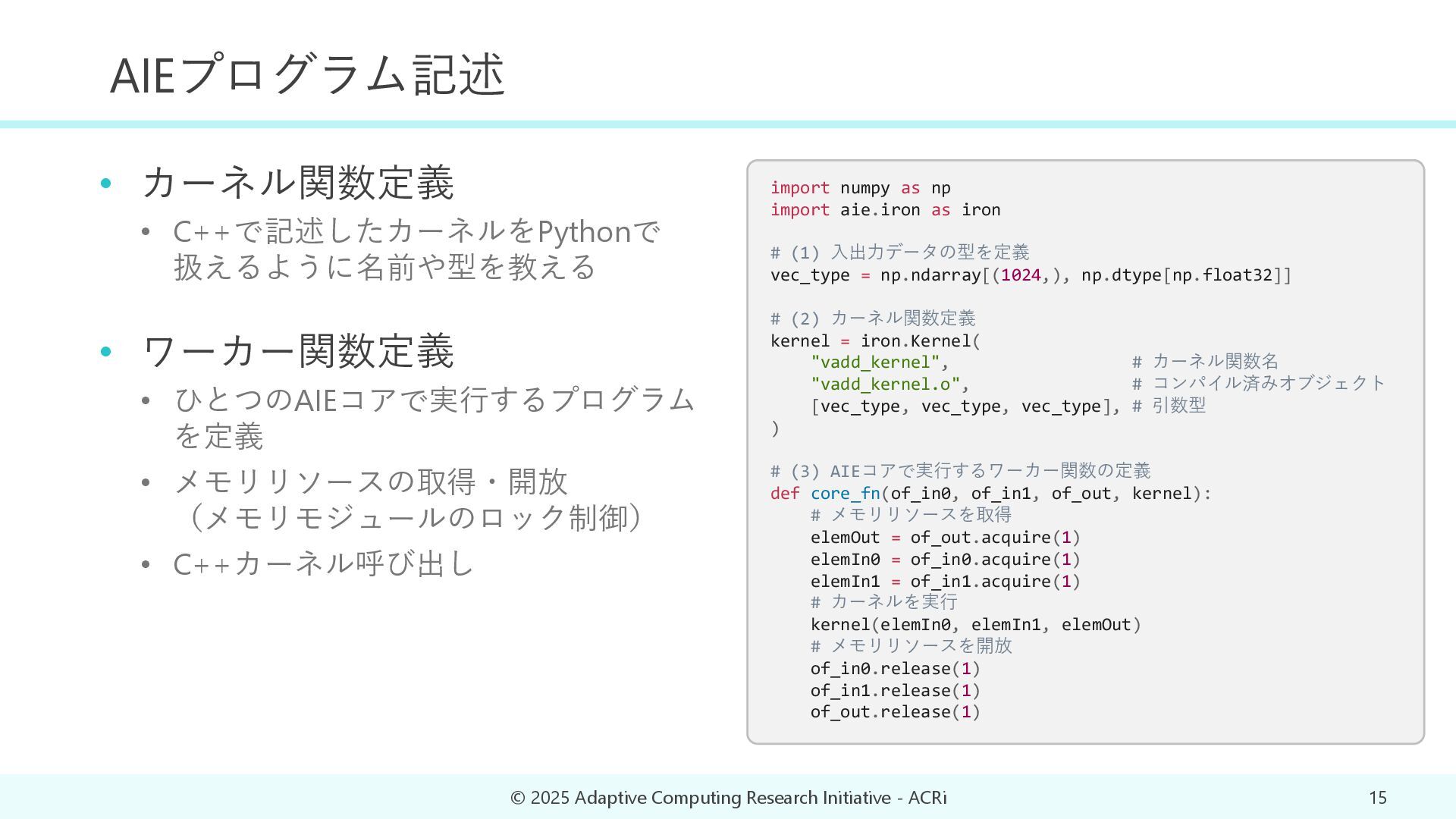{kind=link}
{kind=link}
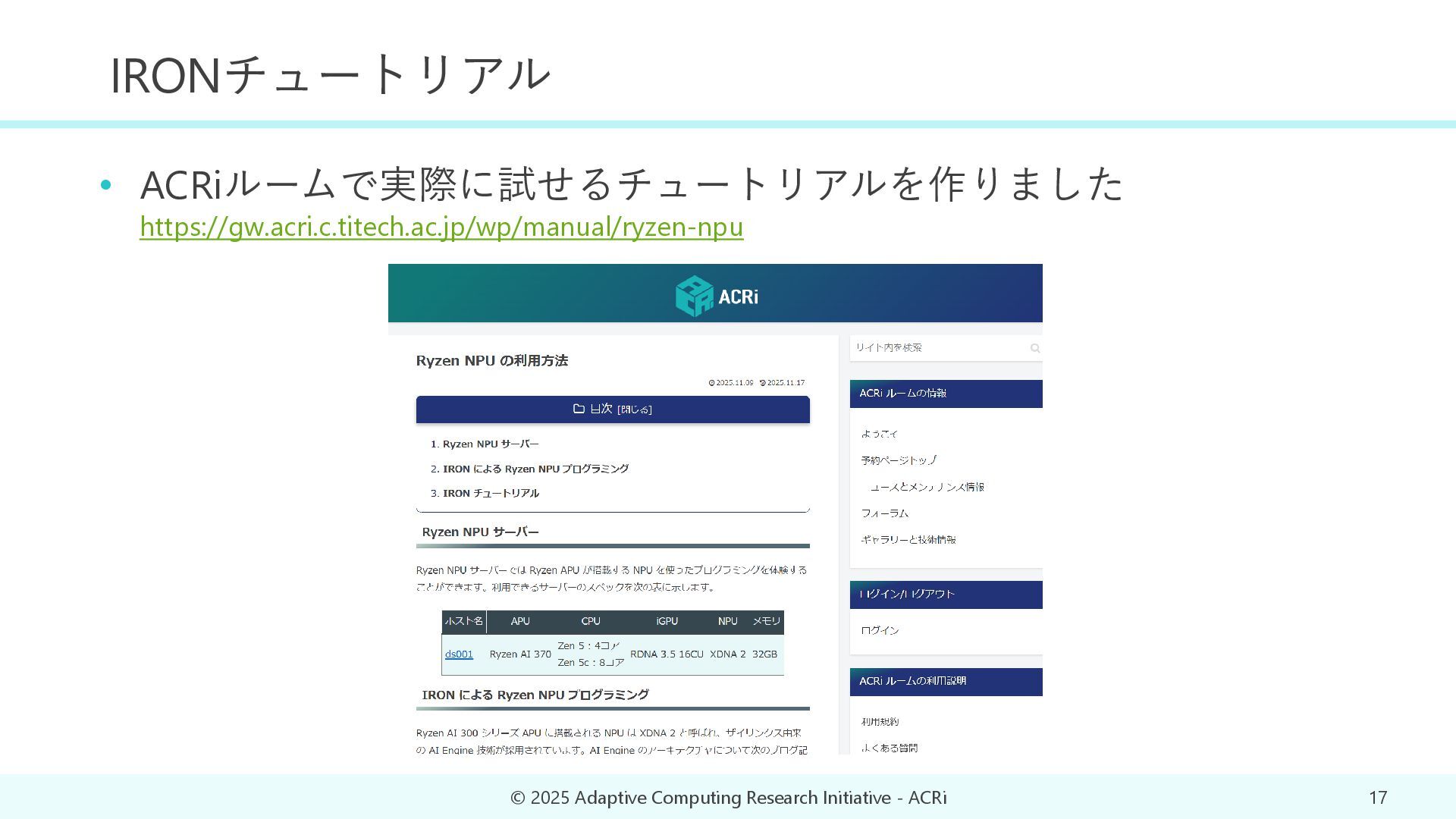{kind=link}
{kind=link}
{kind=link}
{kind=link}