Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Idiosyncrasies in Large Language Models
Search
hajime kiyama
September 06, 2025
63
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Idiosyncrasies in Large Language Models
paper introduction for japanese.
hajime kiyama
September 06, 2025
More Decks by hajime kiyama
See All by hajime kiyama
通時的な類似度行列に基づく単語の意味変化の分析
rudorudo11
0
330
People who frequently use ChatGPT for writing tasks are accurate and robust detectors of AI-generated text
rudorudo11
0
280
Analyzing Continuous Semantic Shifts with Diachronic Word Similarity Matrices.
rudorudo11
0
230
Using Synchronic Definitions and Semantic Relations to Classify Semantic Change Types
rudorudo11
0
110
Analyzing Semantic Change through Lexical Replacements
rudorudo11
0
370
意味変化分析に向けた単語埋め込みの時系列パターン分析
rudorudo11
1
210
Bridging Continuous and Discrete Spaces: Interpretable Sentence Representation Learning via Compositional Operations
rudorudo11
0
340
Word Sense Extension
rudorudo11
0
160
Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
rudorudo11
0
230
Featured
See All Featured
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
610
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
970
Odyssey Design
rkendrick25
PRO
2
730
Build your cross-platform service in a week with App Engine
jlugia
234
18k
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Building AI with AI
inesmontani
PRO
1
1.1k
How to build a perfect <img>
jonoalderson
1
5.8k
Statistics for Hackers
jakevdp
799
230k
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2.1k
Are puppies a ranking factor?
jonoalderson
1
3.7k
Transcript
木山朔 D1 論文紹介 ICML2025 1 ※図表は論文からの引用です。 Idiosyncrasies in Large Language
Models Mingjie Sun, Yida Yin, Zhiqiu Xu, J. Zico Kolter, Zhuang Liu
概要 • 大規模言語モデルの特異性を調査 ◦ 特異性:モデルの癖(独自の出力パターン) • 5つのLLMの出力の分類タスクを解く ◦ 指示チューニングされたものは高精度に分類可能 ◦
プロンプトを変えても分類精度は維持 • LLMごとの癖を分析 ◦ 単語レベルの出現分布が良い識別特徴 ◦ 意味的な言い換えをしても分類性能は下がらない 2
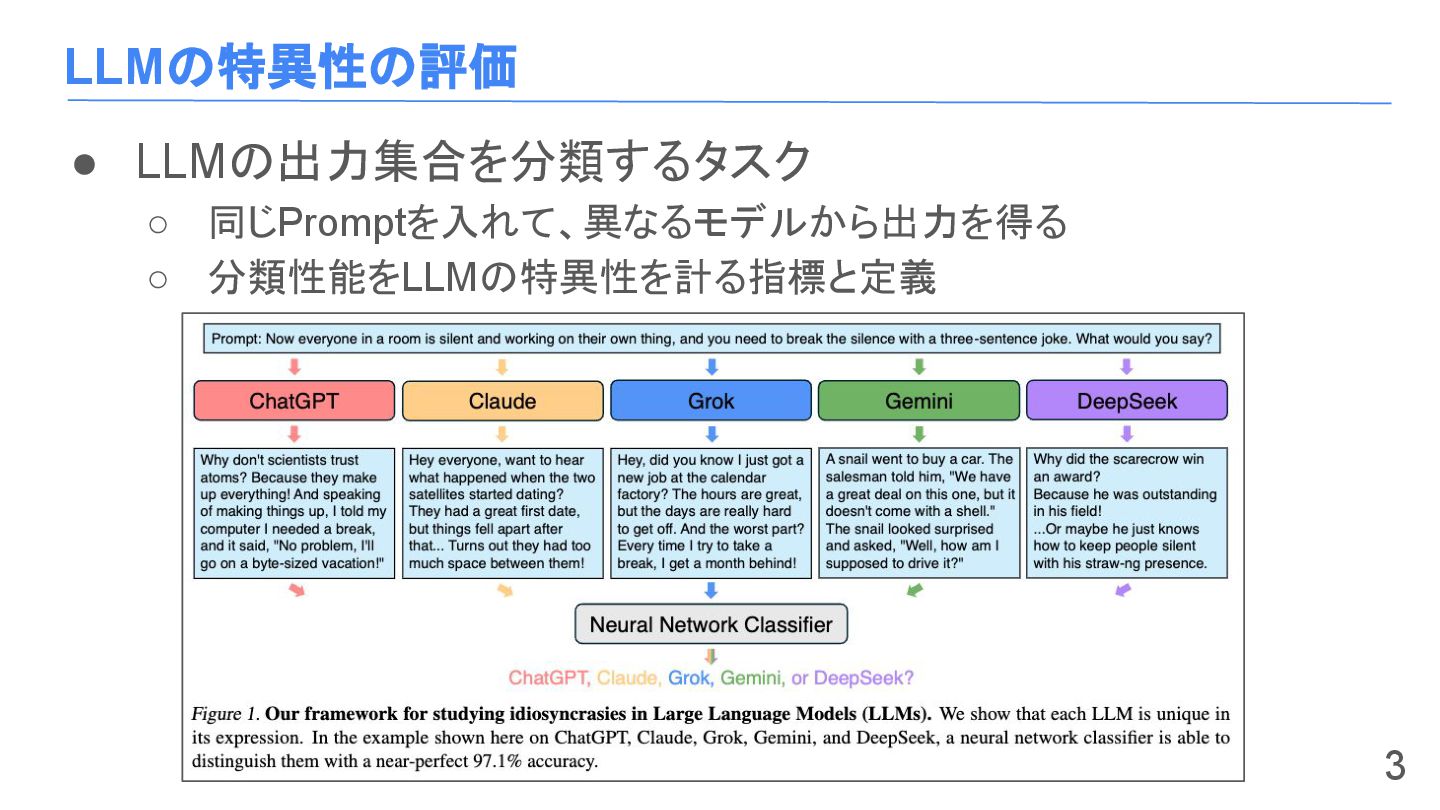
LLMの特異性の評価 • LLMの出力集合を分類するタスク ◦ 同じPromptを入れて、異なるモデルから出力を得る ◦ 分類性能をLLMの特異性を計る指標と定義 3
• 系列の分類タスク ◦ 埋め込みモデルをファインチューニングして精度をみる ◦ LLM2Vec の結果を記載 [Parishad+, COLM2024] •
データセット ◦ 同じプロンプト集合から11000件の出力を獲得 ◦ 10000を訓練用、1000を検証用に使用 LLMの分類手法 4 https://arxiv.org/abs/ 2404.05961
• 比較アーキテクチャ ◦ Chat API ▪ GPT-4o, Claude-3.5-Sonnet, Glok-2, Gemini-1.5-Pro,
DeepSeek-V3 ◦ Instruct/Base LLM ▪ Llama3.1-8b,Gemma2-9,Qwen2.5-7b,Mistral-v3-7b ◦ Qwen2.5 family ▪ 7B, 14B, 32B, 72B LLMの分類設定 5
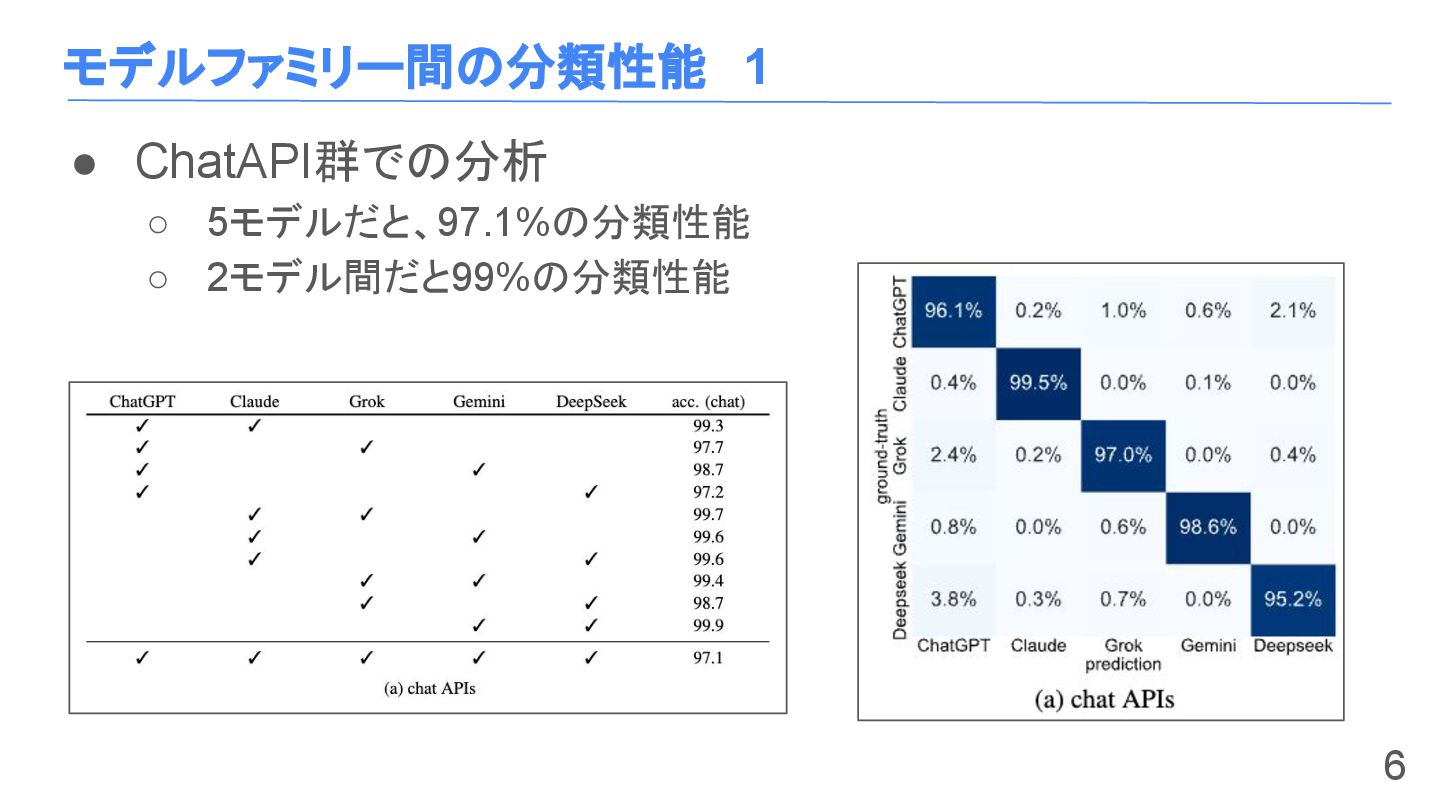
モデルファミリー間の分類性能 1 • ChatAPI群での分析 ◦ 5モデルだと、97.1%の分類性能 ◦ 2モデル間だと99%の分類性能 6
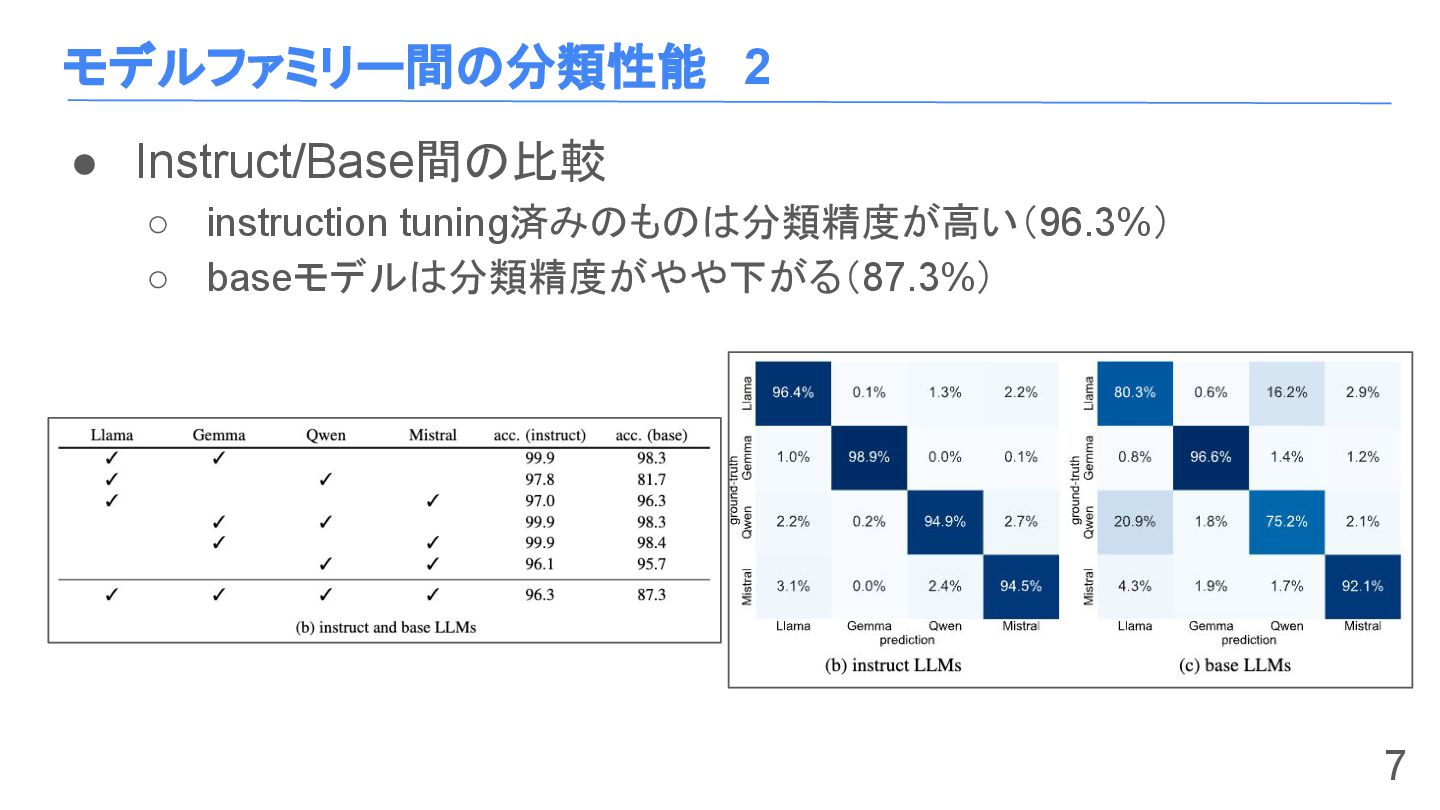
モデルファミリー間の分類性能 2 • Instruct/Base間の比較 ◦ instruction tuning済みのものは分類精度が高い(96.3%) ◦ baseモデルは分類精度がやや下がる(87.3%) 7
モデルファミリー内の分類性能 • Qwen2のモデルサイズを変えた際の分類性能 ◦ 結構下がる(59.8%) ◦ 混同行列の図がないのが気になる... 8
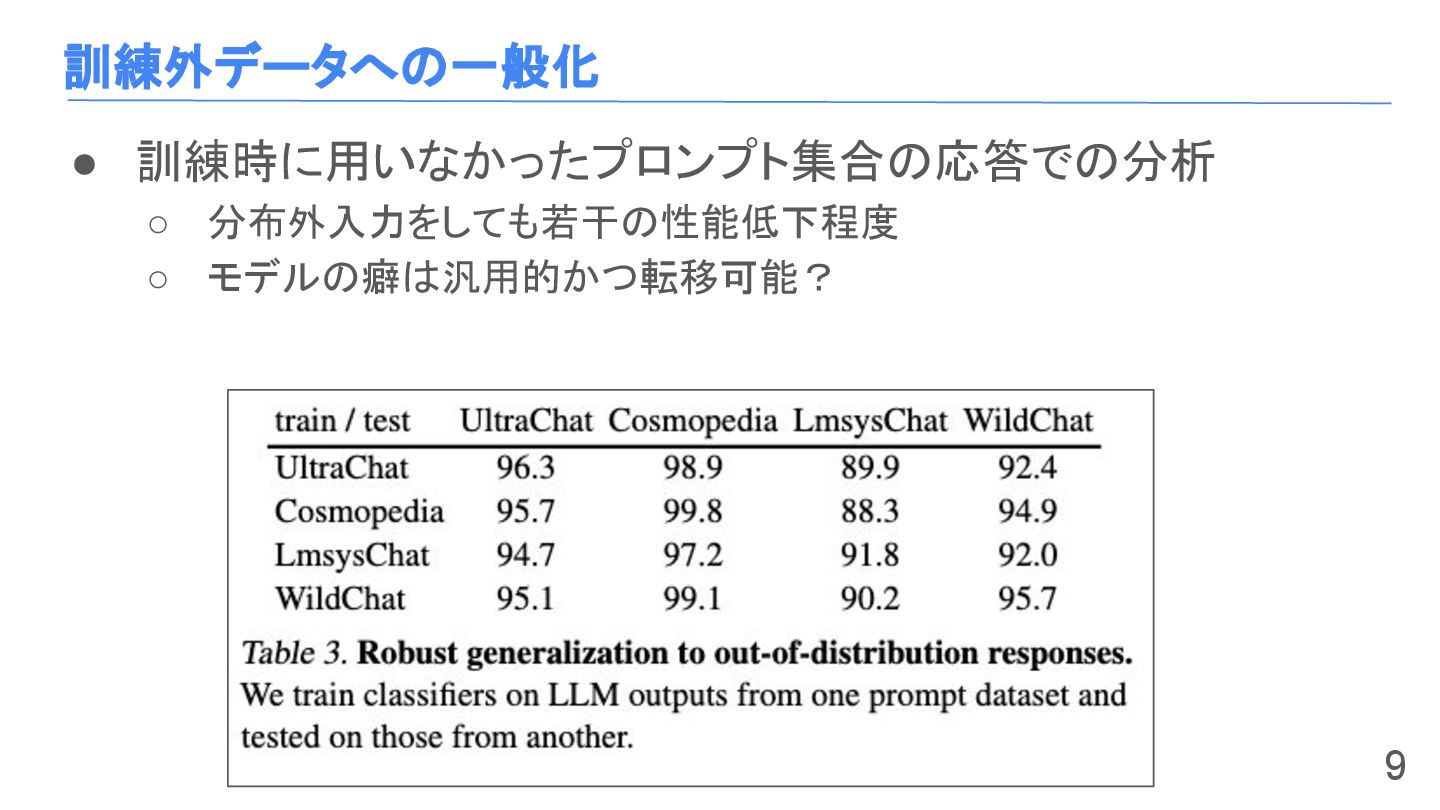
訓練外データへの一般化 • 訓練時に用いなかったプロンプト集合の応答での分析 ◦ 分布外入力をしても若干の性能低下程度 ◦ モデルの癖は汎用的かつ転移可能? 9
制御したLLMの分類タスク • 実験設定を制御して分析する(Ablation) ◦ プロンプト ◦ 埋め込みモデルでの入力長 ◦ サンプリング手法 ◦
埋め込みモデルの種類 ◦ 訓練データ量 10
制御したLLMの分類タスクープロンプト • プロンプトで出力を制御した時の傾向 ◦ length:100語いないの単一段落 ◦ format:プレーンテキストでのみ応答 ◦ 制御を加えても性能低下は微々たるもの ◦
長さやスタイルに現れないモデルの特異性がある 11
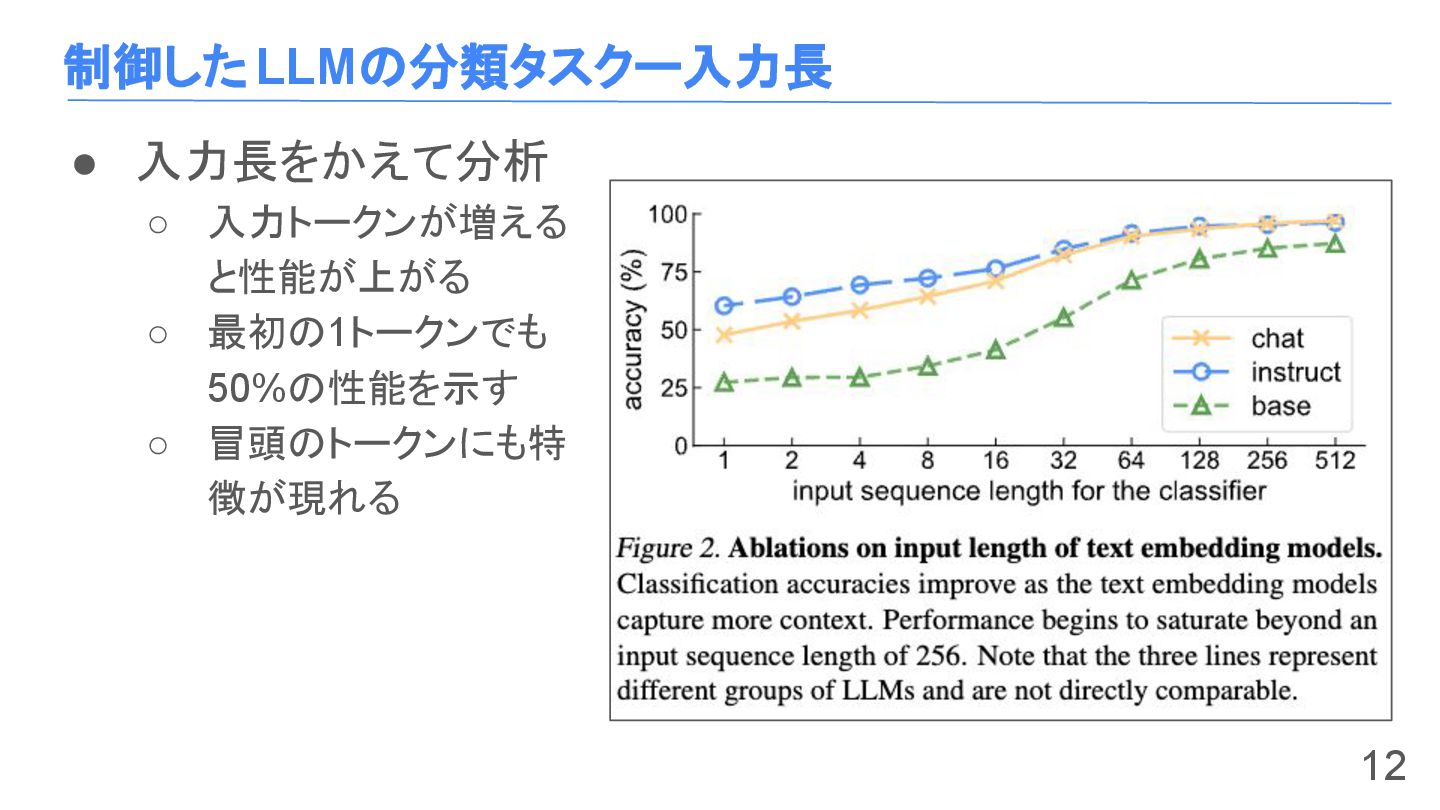
制御したLLMの分類タスクー入力長 • 入力長をかえて分析 ◦ 入力トークンが増える と性能が上がる ◦ 最初の1トークンでも 50%の性能を示す ◦
冒頭のトークンにも特 徴が現れる 12
制御したLLMの分類タスクーサンプリング手法 • モデルを固定し、出力のサンプリング手法を変える ◦ 二つのサンプリング手法で分類をする ◦ サンプリング手法を変えてもチャンスレート ◦ デコーディング手法によって同一LLMの出力は区別できない 13
制御したLLMの分類タスクー埋め込みモデル • テキストの埋め込みモデルを変えた場合の比較 ◦ LLM2Vecが一番良い ◦ (とはいってもモデルサイズが一番大きい) 14
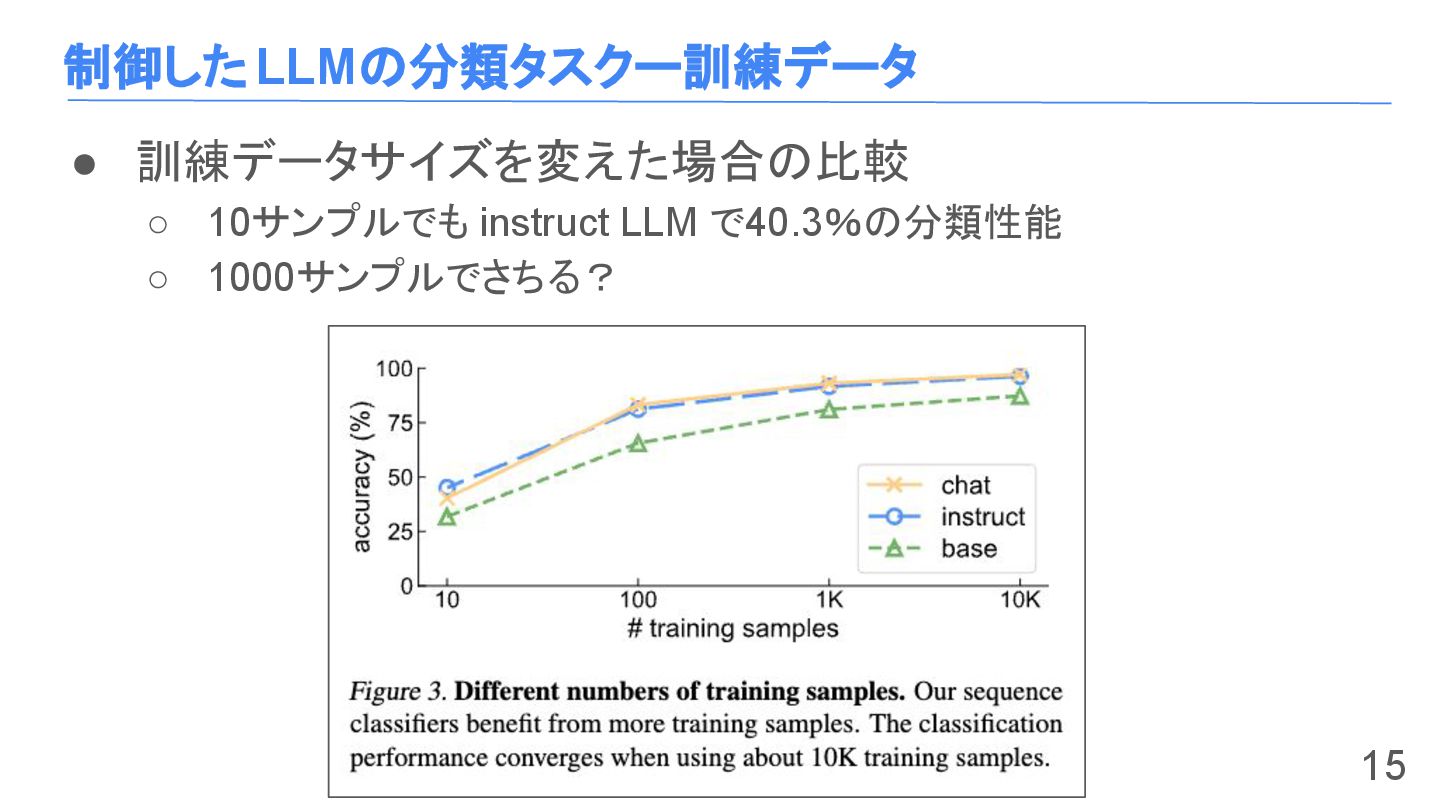
制御したLLMの分類タスクー訓練データ • 訓練データサイズを変えた場合の比較 ◦ 10サンプルでも instruct LLM で40.3%の分類性能 ◦ 1000サンプルでさちる?
15
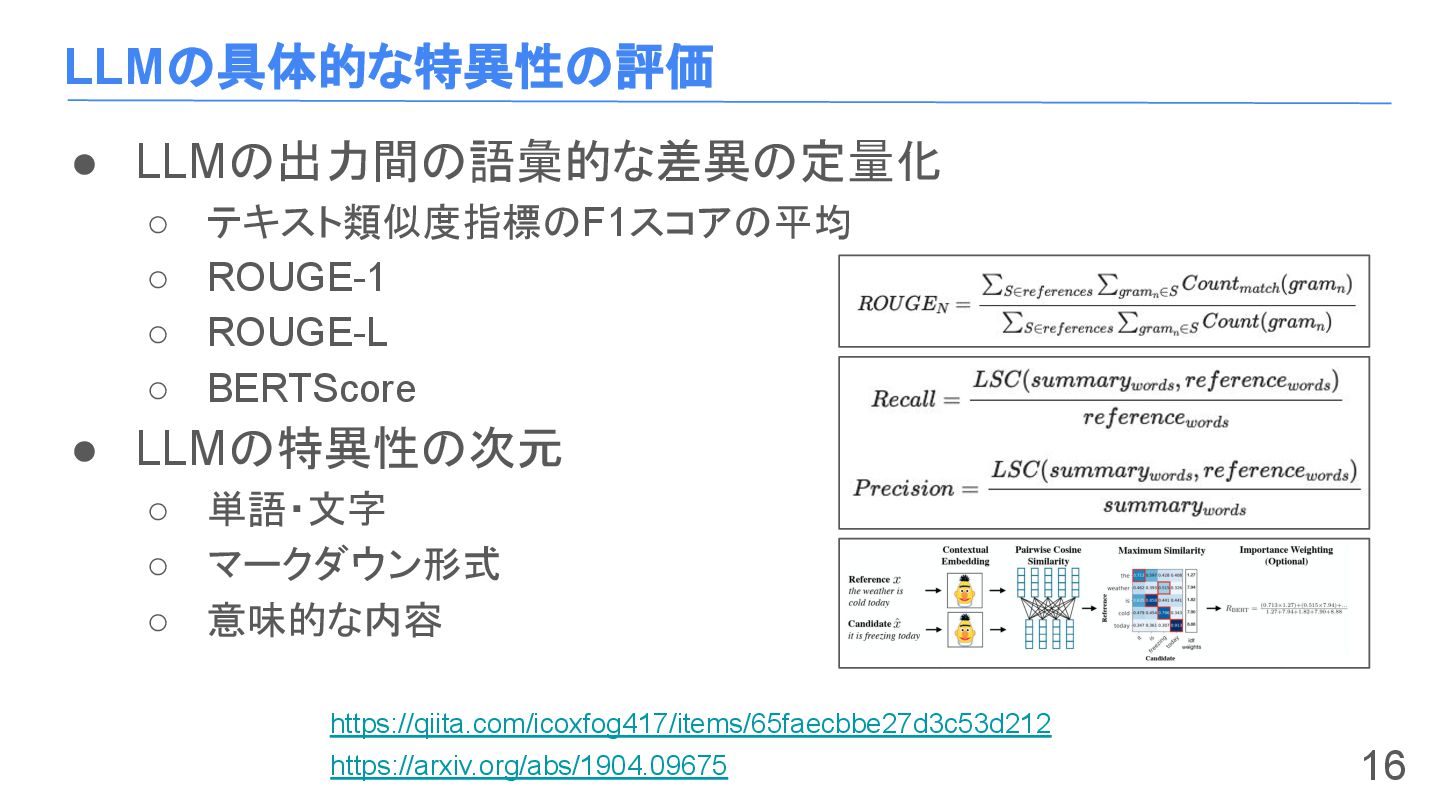
LLMの具体的な特異性の評価 • LLMの出力間の語彙的な差異の定量化 ◦ テキスト類似度指標のF1スコアの平均 ◦ ROUGE-1 ◦ ROUGE-L ◦
BERTScore • LLMの特異性の次元 ◦ 単語・文字 ◦ マークダウン形式 ◦ 意味的な内容 16 https://qiita.com/icoxfog417/items/65faecbbe27d3c53d212 https://arxiv.org/abs/1904.09675
LLMの特異性ー単語・文字 • テキストのシャッフルの効果 ◦ 単語レベルのシャッフルだとあまり下がらない ◦ 文字レベルのシャッフルだと大きく下がる ◦ LLMの特異性は単語レベルの分布に起因する? 17
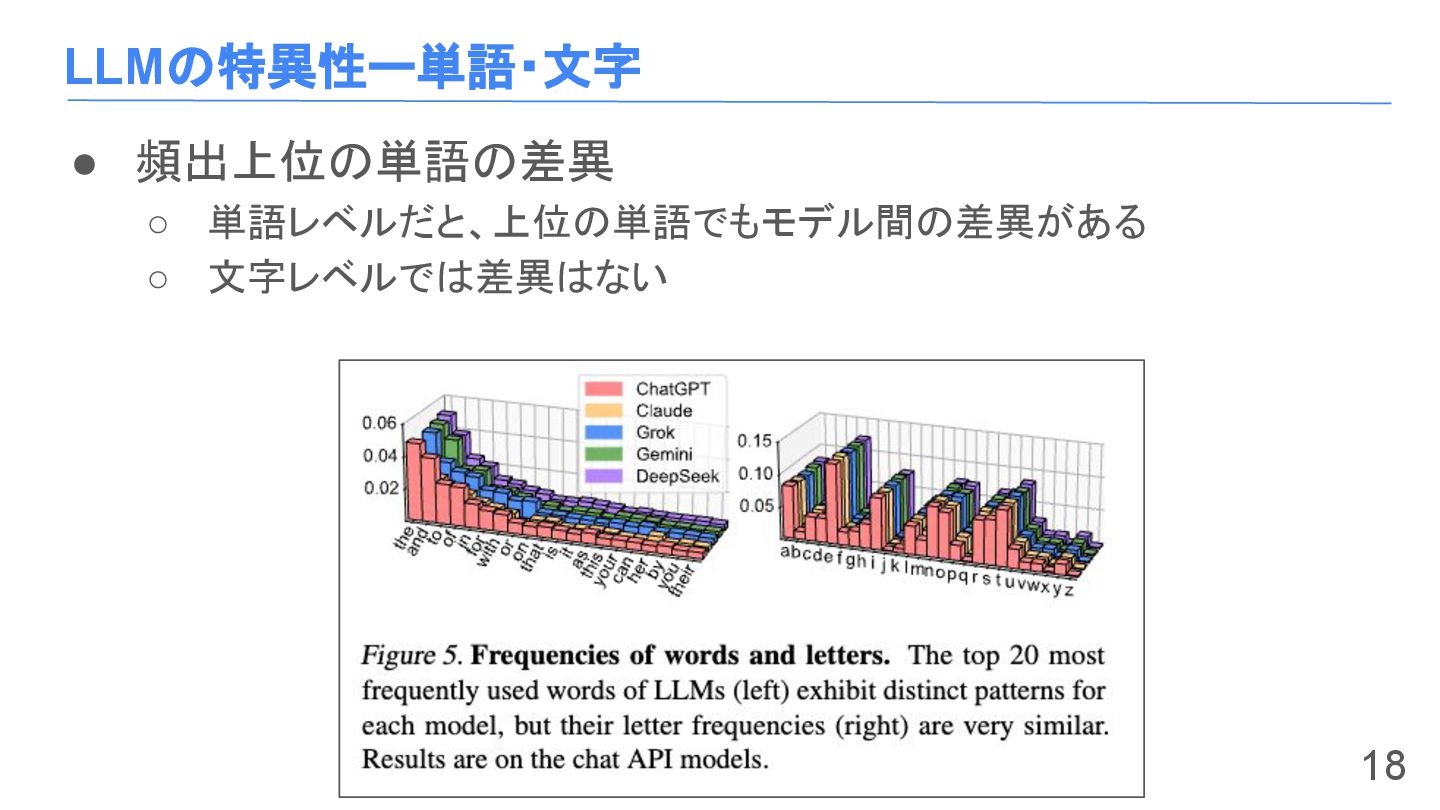
LLMの特異性ー単語・文字 • 頻出上位の単語の差異 ◦ 単語レベルだと、上位の単語でもモデル間の差異がある ◦ 文字レベルでは差異はない 18
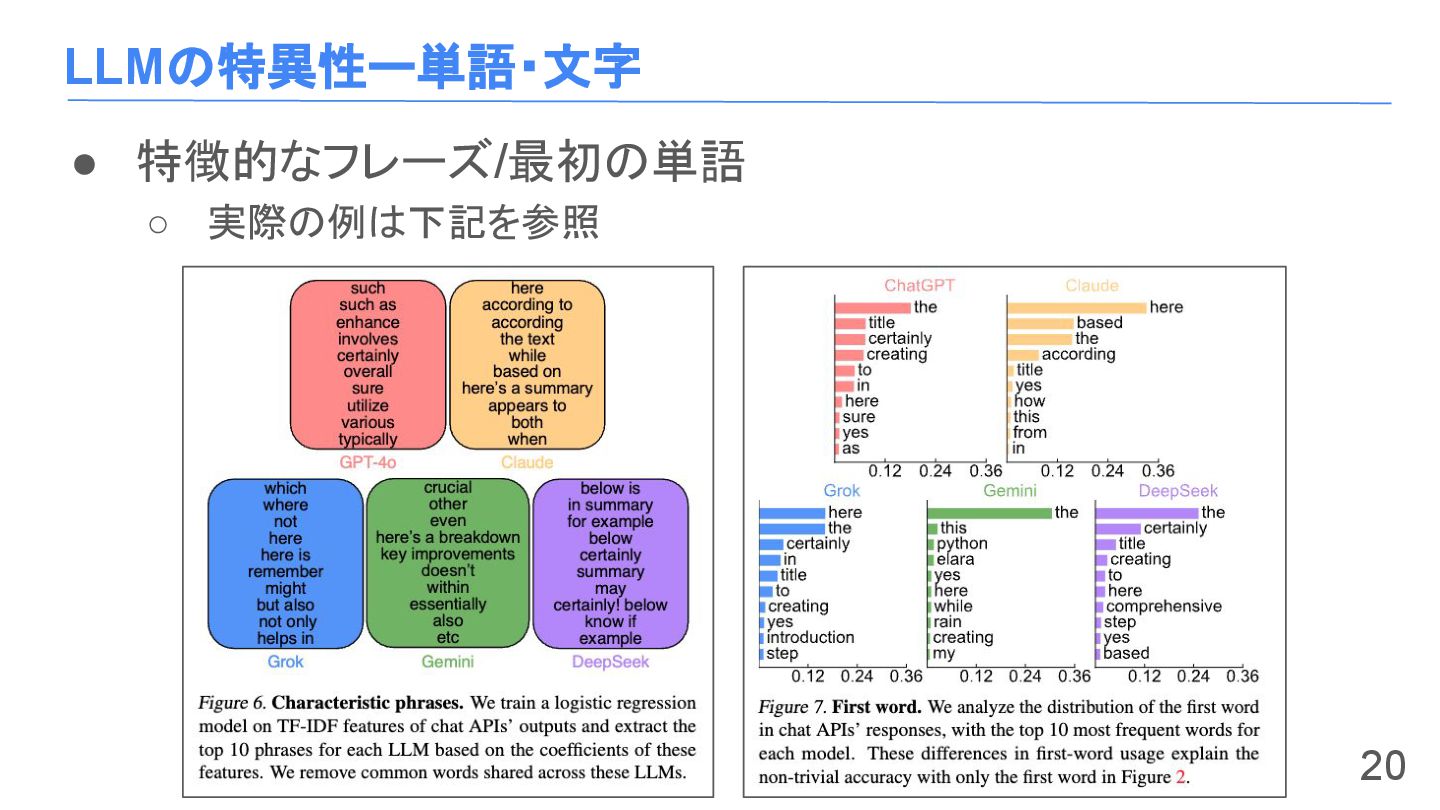
LLMの特異性ー単語・文字 • 特徴的なフレーズの分析設定 ◦ TF-IDFを使って1-gram,2-gramの特徴を抽出 ロジスティック回帰で分類 (removingの部分に対応) ◦ ロジスティック回帰の係数を用いて特徴量の重要度を分析 19
LLMの特異性ー単語・文字 • 特徴的なフレーズ/最初の単語 ◦ 実際の例は下記を参照 20
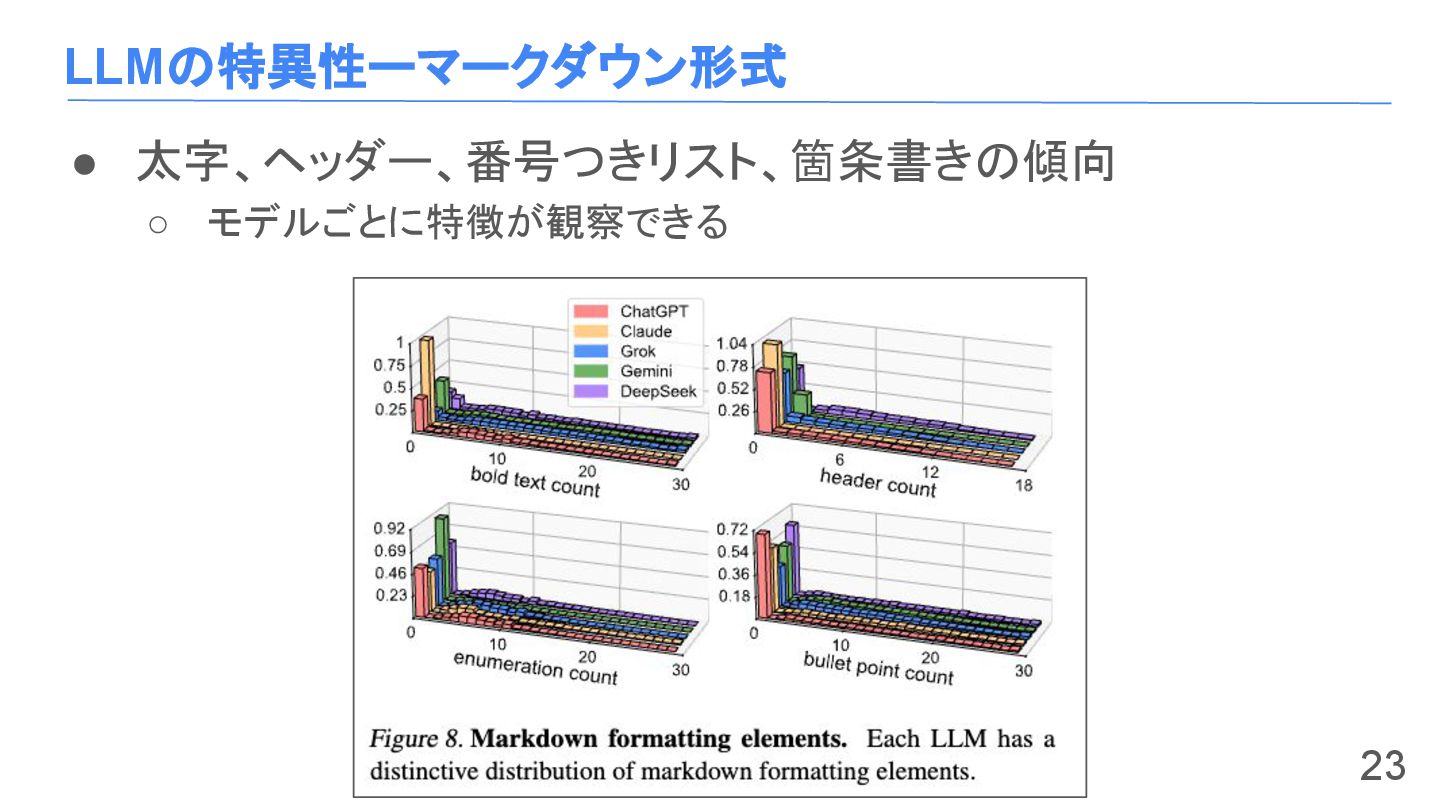
LLMの特異性ーマークダウン形式 • 各LLMのマークダウンの要素を分析 ◦ 太字 ◦ 斜体 ◦ 見出し ◦
番号付きリスト ◦ 箇条書き(バレット) ◦ コードブロック 21
LLMの特異性ーマークダウン形式 • 全データとマークダウンの比較 ◦ マークダウンでもある程度分類ができる ◦ baseモデルは全然できなくなる • モデルの癖の具体例 ◦
ChatGPTはboldをよく使う ◦ Claudeは箇条書きを使いがち 22
LLMの特異性ーマークダウン形式 • 太字、ヘッダー、番号つきリスト、箇条書きの傾向 ◦ モデルごとに特徴が観察できる 23
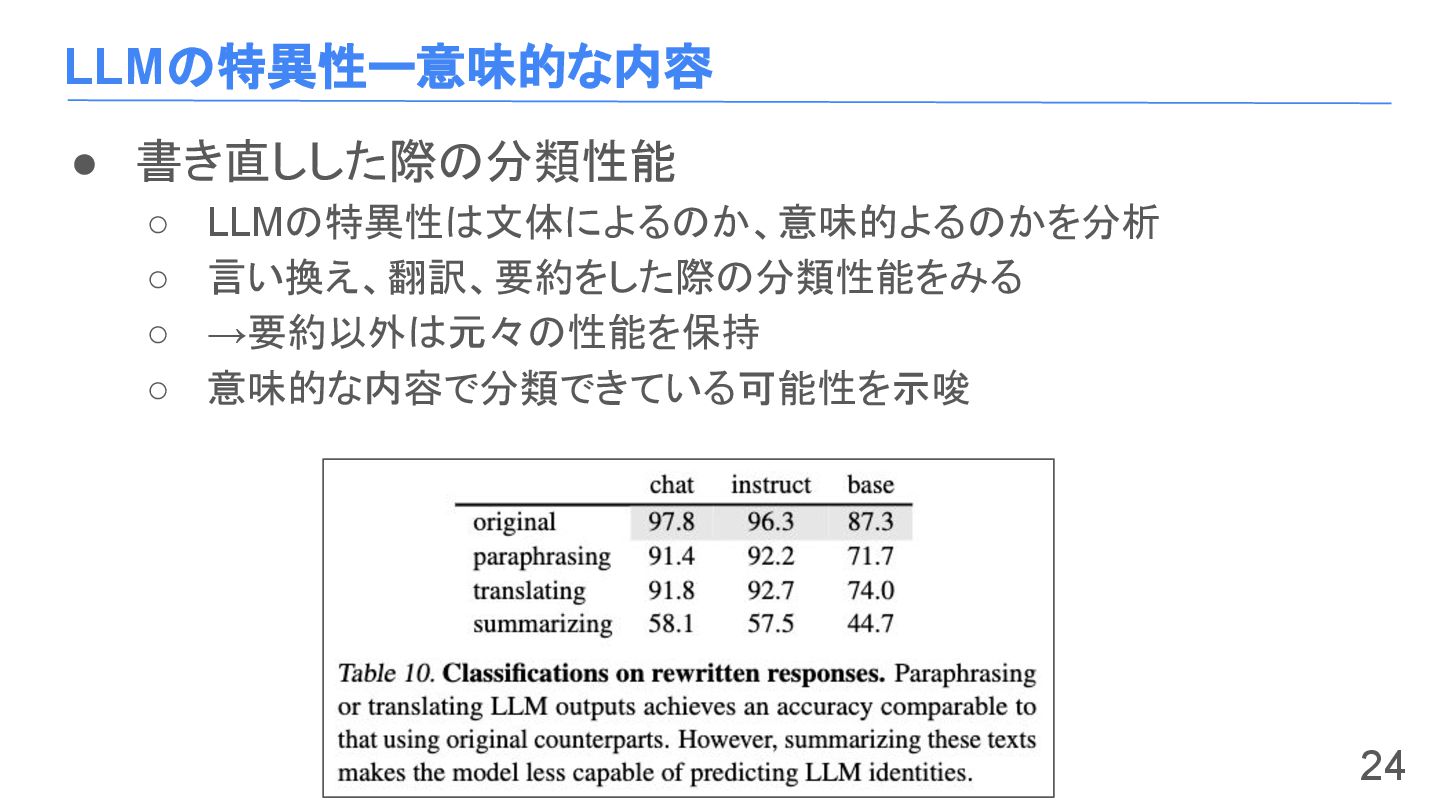
LLMの特異性ー意味的な内容 • 書き直しした際の分類性能 ◦ LLMの特異性は文体によるのか、意味的よるのかを分析 ◦ 言い換え、翻訳、要約をした際の分類性能をみる ◦ →要約以外は元々の性能を保持 ◦
意味的な内容で分類できている可能性を示唆 24
LLMの特異性ー意味的な内容 • LLMによる各モデルの傾向評価 ◦ LLMに他のLLMの出力を入れて傾向を出させるタスク ◦ ChatGPT:説得力のある語り口で詳細かつ記述的な応答 ◦ Claude:要約を絞りシンプルで明快な表現 25
合成データによる特異性の伝播 • LLMの出力でSFTすると特異性が伝播する ◦ 比較モデル両方に別のLLMで生成した合成データでSFTする • 性能 ◦ Llama3.1-8b+ChatGPT vs
Gemma2-9b+ChatGPT ▪ SFT前:96.5% ▪ SFT後:59.8% ▪ 特異性は伝播する ◦ Qwen2.5-7b+Llama3.1-8b vs Qwen2.5-7b+Gemma2-9b ▪ 分類性能:98.9% ▪ 同じモデルに別の合成データを学習させることで分類可能 26
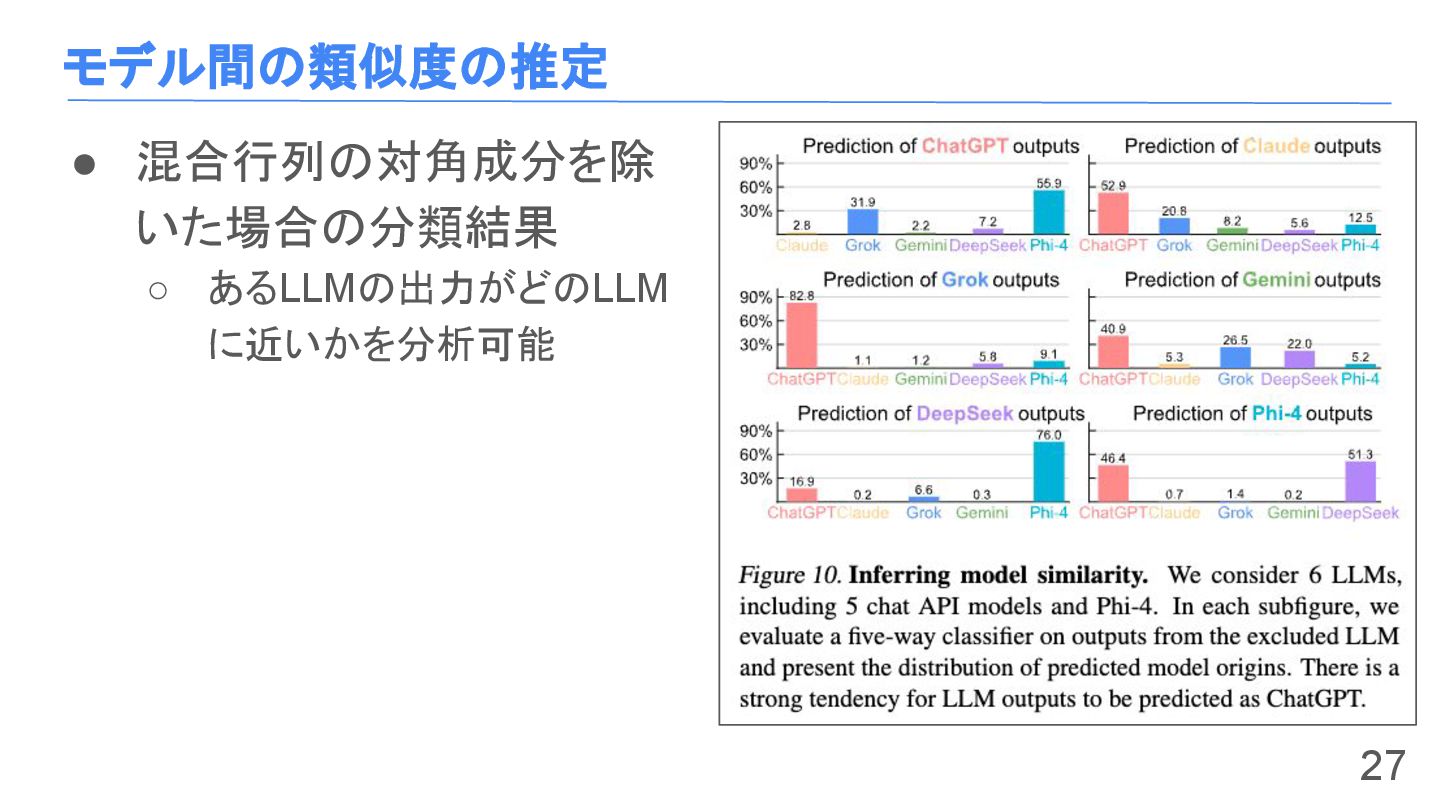
モデル間の類似度の推定 27 • 混合行列の対角成分を除 いた場合の分類結果 ◦ あるLLMの出力がどのLLM に近いかを分析可能
概要(再掲) • 大規模言語モデルの特異性を調査 ◦ 特異性:モデルの癖(独自の出力パターン) • 5つのLLMの出力の分類タスクを解く ◦ 指示チューニングされたものは高精度に分類可能 ◦
プロンプトを変えても分類精度は維持 • LLMごとの癖を分析 ◦ 単語レベルの出現分布が良い識別特徴 ◦ 意味的な言い換えをしても分類性能は下がらない 28
付録:LLM2Vec [Parishad+, COLM2024] • Decoder-onlyモデルを埋め込みモデルに拡張する手法 ◦ autoregressiveの部分をbi-directionalに変更 ◦ MLMタスクと対照学習を追加で実施する 29
https://github.com/McGill-NLP/llm2vec
{kind=link}
{kind=link}
{kind=link}
![• 系列の分類タスク ◦ 埋め込みモデルをファインチューニングして精度をみる ◦ LLM2Vec の結果を記載 [Parishad+, COLM2024] •](https://files.speakerdeck.com/presentations/f400f83c54ea4ee192897a2fd8c9dabd/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![付録:LLM2Vec [Parishad+, COLM2024] • Decoder-onlyモデルを埋め込みモデルに拡張する手法 ◦ autoregressiveの部分をbi-directionalに変更 ◦ MLMタスクと対照学習を追加で実施する 29](https://files.speakerdeck.com/presentations/f400f83c54ea4ee192897a2fd8c9dabd/slide_28.jpg){kind=link}